
基于注意力模型的混合推荐系统
2020-07-06 13:35谭台哲晏家斌
计算机工程与应用 2020年13期
谭台哲,晏家斌
广东工业大学 计算机学院,广州 510006
1 引言
随着信息技术,尤其是大数据技术的快速发展,用户获取信息的方式已经发生了很大的改变,面对信息的爆炸式增长,“信息过载”问题日益突出,而推荐系统作为一种解决信息过载问题的有效方法引起了广泛的关注[1-9]。
推荐系统是指在海量的数据中,经过筛选过滤处理,为用户提供最需要、最关注、最具吸引力的项目(如视频、音频、新闻资讯等等),以缓解信息过载问题[10]。目前,推荐系统主要有三大类[11]:基于协同过滤算法的推荐系统、基于网络结构的推荐以及这两种算法相结合的混合推荐。协同过滤(Collaborative Filtering,CF)算法是目前推荐系统中应用最广的算法[11],它主要是基于用户的历史数据,通过建模分析,来预测特定用户的内容偏好[12],它可以分为基于用户的协同过滤(User-based CF)和基于内容的协同过滤(Item-based CF)。基于网络结构的推荐系统不考虑用户和内容的特征,而仅仅把它们看成抽象的节点,因此算法利用的信息都藏在用户和内容的选择关系中。比较著名的是文献[13]中所提出网络推断算法(Network-Based Inference,NBI),该算法利用二部图进行资源分配,取得了比协同过滤算法更好的效果。混合推荐系统是指将多种算法融合到一个系统中,使其充分发挥各个算法的优势[14]。
随着机器学习,尤其是深度学习算法的兴起,将传统的推荐系统与机器学习、深度学习融合到一起的新型混合推荐系统正在成为一个研究的热点。例如,在文献[15]中Ning 等人提出将协同过滤算法与机器学习融合,通过优化推荐感知目标函数从数据中学习项目相似性。在文献[16]中Silva 等人提出了一种新的机器学习进化方法,通过自动选取技术将不同推荐技术的结果进行筛选,增强了推荐系统的准确性。文献[17]提出将协同过滤算法与表示学习及排序学习进行深度融合集成一个统一框架,利用这一框架进行推荐。文献[18]提出利用矩阵分解和多层感知机相结合,通过神经网络来学习用户特征,从而提高推荐系统的准确性。
随着注意力机制在图像分类任务中的成功应用[19],结合注意力机制的神经网络已成为研究热点。文献[20]抛弃了传统的CNN 和RNN,提出完全用由Attention 机制组成的网络结构,并在当时的机器翻译中取得了最高的BLEU 值。注意力机制不仅在机器视觉和自然语言处理领域获得了成就,在推荐系统领域也受到了广泛的关注。文献[21]提出利用注意力机制来考察用户历史信息中不同属性对于用户偏好的影响。文献[22]在总结前人经验的基础上提出了融合注意力机制的深度协同过滤推荐算法,但是文章中所用到的特征都是比较低级的特征,对性能的提升有限。
本文在总结当前主流算法的基础上,提出了注意力模型与神经网络相结合的方式,提取高阶特征,对特定推荐商品的物品属性进行加权分配,增大相似商品的权重,减少非相似商品的权重,得到的推荐商品的认可度评分。其次,采用了自适应增强学习模型对推荐结果进行优选,提高了推荐结果的准确性。最后,在现有推荐系统评价指标的基础上,本文首次引入了用户群体评价认可度指标,通过认可度指标可以在用户体验维度对推荐系统性能给出更精确的评价。
2 相关知识
2.1 协同过滤算法
协同过滤算法是诞生最早的推荐算法[23],也是到目前为止应用最为广泛的推荐算法之一[24]。它主要通过对目标用户历史行为数据的深度挖掘来发现其特殊偏好,基于不同的偏好对用户进行群组划分,在群组里面寻找品味相似的商品并推荐给目标用户。
在引言中已经提到,协同过滤算法主要分为基于用户的协同过滤及基于内容的协同过滤。在这两种算法中,以基于用户的协同过滤算法应用最为广泛[25],下面将重点介绍下这种算法的实现过程。
基于用户的协同过滤算法分为两类,分别是基于KNN 模型的在线推荐与基于模型的离线推荐[26]。由于前者存在数据稀疏性以及用户兴趣标签时常变化的问题,因此基于模型的离线推荐方式拥有更好的可扩展性和数据整合性。其难点在于构造模型与保证离线推荐准确度。基于模型的离线方式User-based CF算法主要包含以下三个步骤:
(1)寻找与目标用户行为习惯相似的用户,生成近似用户组,再根据相似度最高的近邻用户进行推荐。寻找相似用户时常用的算法有余弦相似度、修正的余弦相似度算法等。
余弦相似度算法:

式中,u表示目标用户评分向量,v表示数据集中近邻用户的评分向量。
修正余弦相似度算法就是在余弦相似度的基础上加入了已评分向量的算术平均值,如公式(2)所示:

在计算用户相似度时,考虑到两个用户间可能完全没有观看过相似的电影(物品),使用上述相似性矩阵浪费计算资源,使用物品-用户倒排表可以容易看出哪些用户观看过相似的电影。构造两个用户的协同矩阵c[u][v],如果两个用户在的同一部电影的用户表格中出现,则将协同矩阵计算为c[u][v]+1,从而得到所有用户之间不为零的c[u][v]。如图1所示。
(2)对于计算出的余弦相似度,通过用户的偏爱程度对其进行加权:
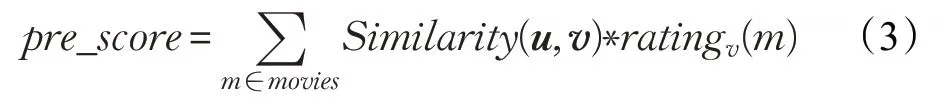
式中,ratingv(m)表示用户v对物品m的喜爱程度。
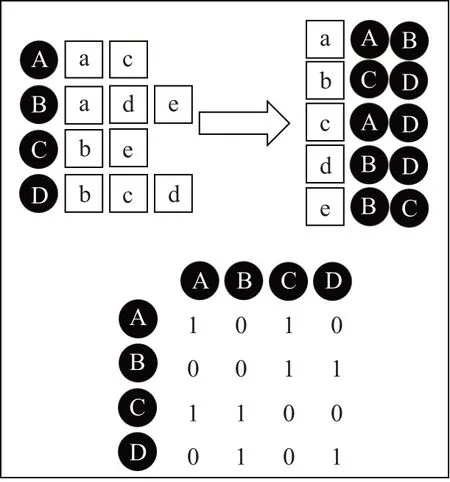
图1 物品-用户倒排表
(3)根据预测分数进行排序,选取前k个推荐给目标用户:
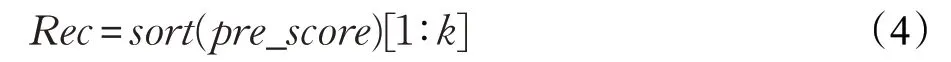
这种基于协同过滤的传统推荐算法,主要有两个方面的缺陷:
(1)针对于某个特定商品,目标用户是否喜欢,只与同种类别的物品强相关,而与其他物品弱相关。不同品类物品的偏好数据与推荐物品品类的强关联性将影响实际推荐物品的命中率。
(2)在选取推荐结果时,通过简单的排序算法,将用户之间的相似度与相似用户的偏好程度放到一起,弱化了用户相似度、不同用户偏好程度这两个不同维度特征对于推荐系统的影响,降低了推荐结果的准确性。
2.2 推荐系统的评价指标
常用的用于评价推荐系统的性能指标主要有两个[27]:准确度(Precision)和召回率(Recall Ratio)。
准确度,反映了推荐结果中发生过用户-物品评分记录的所占比例。

召回率,又称查全率,反映了推荐结果对于用户喜爱电影的覆盖情况。
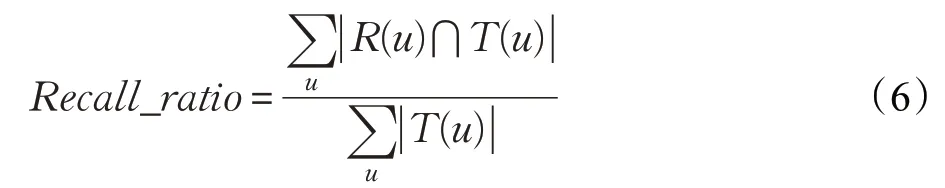
上述公式中,R(u)表示对用户u所推荐的电影列表,T(u)表示用户u真实喜欢的电影列表。
准确率、召回率作为模型的通用评价标准,主要关注推荐结果的优劣,而未考虑相似用户集的划分是否准确。在此基础上,本文提出了一种新的评价指标:相似用户的平均认可度(Average Recognition Degree of similar users,ARD)。该指标表示一个相似用户集内,用户对于特定推荐商品的实际评分均值。其计算公式如下:

其中,I表示相似用户集,R表示推荐列表,Mi(r)表示相似用户集I中的用户i对于推荐列表中的第r部电影的实际评分,分别表示相似用户数和推荐列表数。
通过计算公式可以知道,当给定相似用户集时,推荐系统的精度越高,则平均认可度越大;当给定推荐列表时,相似用户组划分越准确,则平均认可度越大。该指标能够综合、全面地反映推荐系统的性能。
3 混合推荐系统算法
3.1 Attention算法
近年来,注意力模型(Attention Model)[28]被广泛地应用于自然语言处理、语音识别、图像识别等多种不同类型的深度学习任务中,并取得了令人瞩目的成绩。
注意力模型也称资源分配模型,它借鉴了人类的选择注意力机制,其核心思想是对目标数据进行加权变换。目前,注意力机制的原理结构[29]如图2所示。
将需要处理的数据称为源数据,用S来表示。将S中的元素构造成一系列的键值对,K表示属性,V表示对应属性的值,此时给定目标中的某个需求元素Q,通过计算Q和各个K的相似性或者相关性,得到每个K对应V的权重系数,然后对V进行加权求和,即得到了最终的Attention 数值。本质上注意力机制是对S中元素的V值进行加权求和,而Q和K则用来计算对应V的权重系数。

其中αi表示Q与S中对应键值K的权重系数,其计算公式如下:

式中,sim表示相似度算法,常用的相似算法有四种:
(1)MLP算法

式中vT、W、U为MLP模型的参数,可通过学习获得。
(2)点乘算法

(3)缩放点乘算法

式中d表示向量维度。
(4)双线性算法

注意力模型可以通过对不同特征所占权重的重新分配,使得重点突出,弱化不相关因素对结果的影响,从而增强结果的可靠性。
3.2 Ada-Boosting算法
Ada-Boosting是英文“Adaptive Boosting”(自适应增强)的缩写,该算法是对Boosting 算法的改进。Boosting也称为增强学习算法或提升算法,是一种重要的集成学习技术,它通过对简单的弱分类器进行加权组合获得强分类器,从而极大提升分类器的预测精度,而这在直接构造强分类器非常困难的情况下,为机器学习算法的设计提供了一种有效的新思路和新方法。其中最为成功应用的是,Freund等人提出的Ada-Boosting算法[30]。
Ada-Boosting 的自适应在于:前一轮迭代中,分类错误的基本分类器,它的样本权值会增大;而正确分类的分类器其样本权值会减小,并再次用来训练下一个基本分类器。同时,在每一轮迭代中,都会加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数,最后将每一轮中的弱分类器进行加权组合,得到最终的强分类器。
本文中相关符号定义。
Dt(i):第t轮的样本权值分布;
wi:每个训练样本的权值;
hk:第k个弱分类器;
Ht:第t轮的基本分类器;
Hfinal:最终的强分类器;
e:误差率;
αt:基本分类器的权重。
可以把Ada-Boosting算法可以简述为三个步骤:
(1)初始化训练数据的权值分布D1
假设有N个训练样本数据,则每一个训练样本最开始时,都被赋予相同的权值:wi=1/N,则N个训练样本的初始权值分布为D1(i):

(2)进行迭代t=1,2,…,T
①计算当前每个弱分类器的误差率et:

选取误差率最低的h作为第t轮迭代的基本分类器Ht:

②计算每一个简单分类器在最终的分类器中所占的权重:

③更新训练样本的权重分布:

其中Zt是一个归一化常数:

(3)按每一轮基本分类器的权重值αt进行组合,得到f(x)

再将函数f(x)通过符号函数sign进行处理,得到最终的分类器Hfinal:

最后将通过该式生成的分类器用于分类任务。
这种自适应增强算法,能够以简单的分类器获取比较好的分类效果,这对于推荐结果的最终确定有很好的辅助作用。
3.3 混合推荐系统
本文针对传统推荐算法的两个缺陷进行了改进,得到了一个混合推荐系统,主要步骤如下:
(1)推荐结果预估
根据相似用户组,找出目标用户可能喜欢的若干商品,得到商品预推荐组。再利用注意力模型根据每个推荐商品自身的属性去计算目标用户对于推荐商品的评价,得到推荐商品认可度评分。
商品属性我们通过一个深度神经网络来生成。如图3所示。

图3 神经网络
这里,以商品的基本信息作为输入数据,以商品的类别信息作为输出标签。以电影推荐为例,电影的基本信息包括上映时间、导演、编剧、题材、演员等等,类别信息为喜剧、悬疑、综艺、纪录片等等。
将商品属性向量通过Self-Attention模型,流程如图4所示。

图4 Self-Attention模型流程图
图4中,Qi表示第i个预推荐商品的属性向量,Ki表示目标用户第i个评分物品的属性向量,sim表示相似度算法,S表示相似度值,a表示对应向量的权重,V表示目标用户的真实评分,A-value表示预推荐商品的认可度评分。
(2)推荐结果优选
利用Ada-Boosting 分类器对用户相似度及对应的推荐商品认可度进行分类判别。Ada-Boosting 模型训练流程如图5所示。
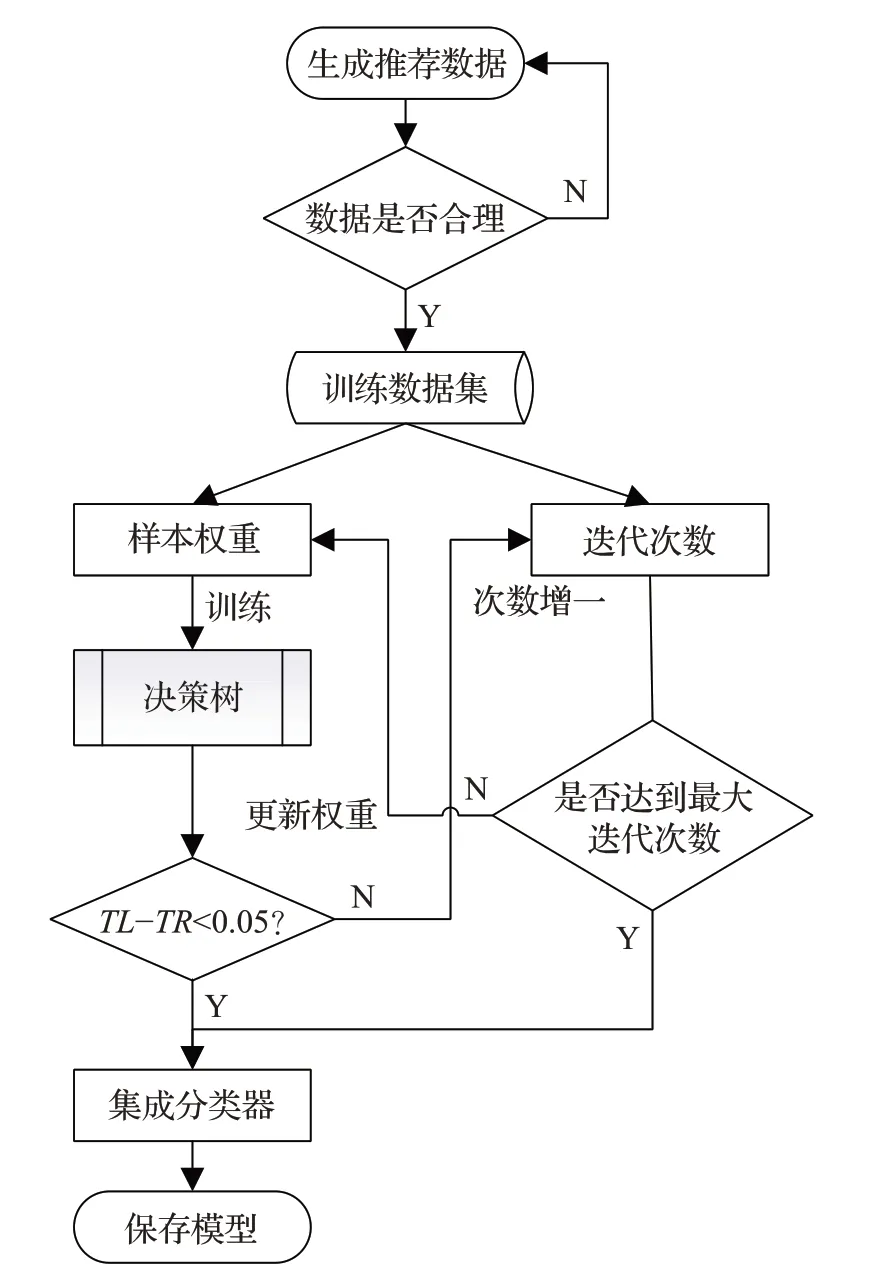
图5 分类器训练流程图
①利用原始推荐系统生成训练样本的数据,将用户相似度、用户喜爱程度作为两个维度的特征,以目标用户是否喜爱作为数据标签。
②校验、整理数据,将一些不合理的数据删除。
③初始化分类器,样本权重均一化,设置迭代次数。
④迭代,利用决策树寻找每一轮的基本分类器。
⑤当左右子树的概率差值小于0.05,或者到达最大迭代次数时,结束训练。
⑥保存训练好的集成分类器模型。
(3)模型导入及应用
将前面两步中训练好的模型导入推荐系统,分别替代传统推荐系统中的相应模块。传统推荐系统的流程,如图6所示。
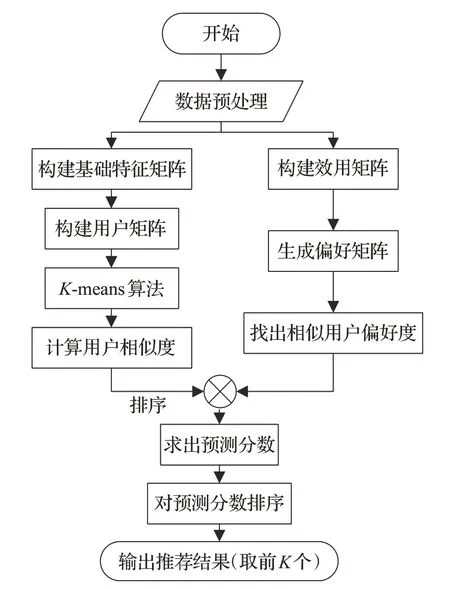
图6 传统推荐系统的算法流程
通过图6 可以看到,传统推荐系统中,在最后给出推荐列表时是将用户相似度、相似用户偏好度进行求积操作,得到预测分数,再对预测分数进行排序处理,选取前K个推荐给用户。这种处理方式没有考虑到特定推荐商品只与类似商品具有强相关性,而与其他商品是弱相关或者不相关的,同时,在最后进行结果优选时,只对预测分数进行排序,弱化了用户相似度、用户偏好度对于推荐结果的不同影响,造成推荐精度不高、推荐结果不能被用户认可等多方面的问题。
本文提出了一个基于注意力模型SAA(Self-Attention with Ada-Boosting model)混合推荐系统。SAA首先增加了一个预推荐商品认可度评价模块,该模块兼顾了物品属性对于推荐结果造成的影响,通过增加Self-Attention模型进行权重的重新分配,从而得到更准确的推荐信息。其次,从多维特征出发,将用户相似度、预推荐商品认可度作为两个维度的特征,分别考虑其对于最后预测结果的影响,使用SAA 模型进行了处理。改进的推荐系统算法流程如图7 所示。需要注意的是在本文中,使用SAA 模型进行处理之前对相似用户进行了一个排序处理,选取前N个。
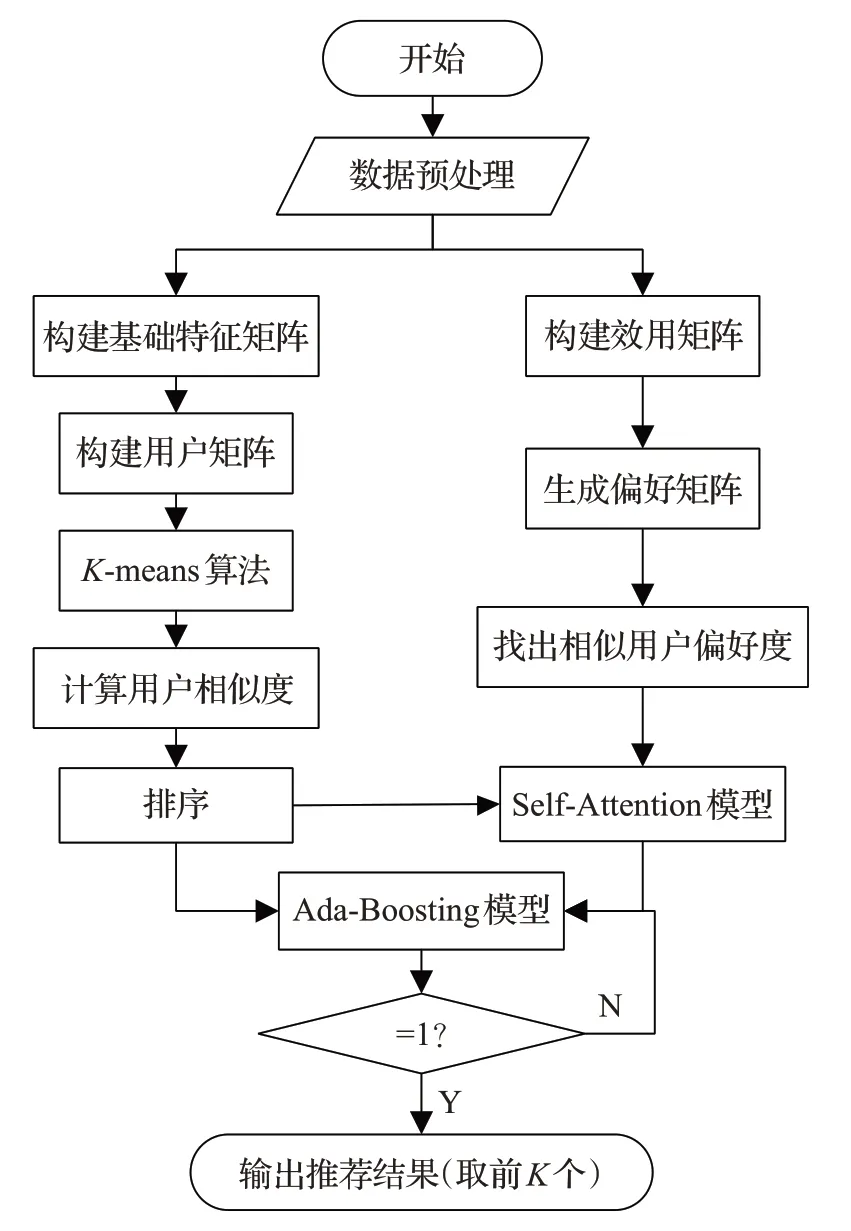
图7 SAA混合推荐系统算法流程
通过以上两个算法,使得推荐系统的性能得到了较大的提升。这里以推荐系统中最经典的电影推荐系统为例,使用本文的混合推荐模型与各个主流的电影推荐系统[31]进行了性能对比,如表1所示。

表1 推荐系统性能对比 %
4 仿真分析
4.1 仿真环境
操作系统:AWS AMI Linux;环境配置:m5ad.2xlarge(8vCPU,内存32 GB,1*300 GB SSD);数据集:Movielens-1M、Movielens-10M。
4.2 仿真结果及分析
本文在传统的用户协同过滤算法基础上,引入了注意力模型与自适应增强学习算法。注意力模型关注物品本身属性对于推荐结果造成的影响;自适应增强学习针对用户相似度及目标用户对预推荐商品认可度的多维度精确分类。这种混合推荐系统(UserCF-SAA)综合分析了相似度和认可度两个不同维度特征对于推荐结果的影响,从图8、9中可以看到,在1M和10M数据集上本文所采用的UserCF-SAA 方法精确度都获得了明显的提升,最高提升达到了18%。

图8 改进推荐系统的精确率对比-1M(Model=MovieLens-1M,Test size=0.4,Number of Users=3 587)
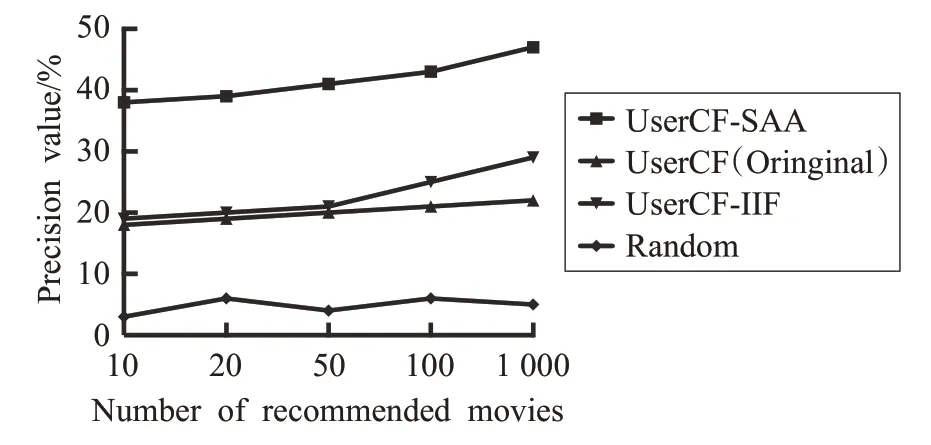
图9 改进推荐系统的精确率对比-10M(Model=MovieLens-10M,Test size=0.4,Number of Users=3 587)
召回率反映了推荐结果对于用户喜爱电影的覆盖情况,召回率越高,表示推荐系统越全面。从图10、11中可以看到,无论是在1M数据集还是在最新的10M数据集上,加入SAA 的UserCF 召回率明显高于其他两种UserCF 算法。图 9 中,SAA 方式与其他两种 UserCF 方式都在相似用户数量为400 名时达到峰值。当相似用户数量超过400 时,不管是SAA 方式还是其他的两种UserCF方式,其召回率都呈现递减趋势,这个主要是因为相似用户数量的增大,会引起噪声数据、无效用户评分数据的大量增加,从而对推荐结果造成干扰。图11中,SAA的算法的曲线下降缓慢,而其他两中UserCF算法下降更快,说明加入SAA 之后,在训练数据足够大时,模型的抗干扰性能获得了提升。
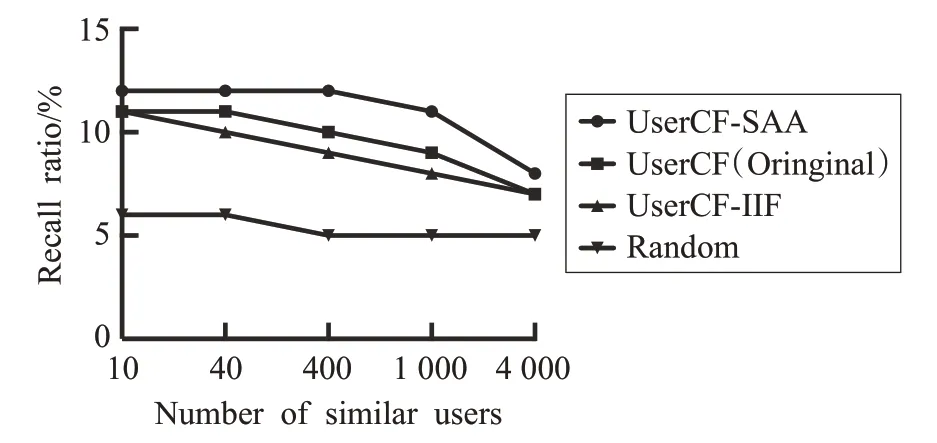
图10 改进推荐系统的召回率对比-1M(Model=MovieLens-1M,Test size=0.4,Number of Movies=1 000)

图11 改进推荐系统的召回率对比-10M(Model=MovieLens-10M,Test size=0.4,Number of Movies=1 000)
相似用户平均认可度可以直观反映相似用户对于推荐电影的认可程度,认可度越高表示推荐系统在相似用户间进行推荐时越精准。从图12、13可以看出,三种UserCF的平均认可度都随着相似用户数量的增加而提高。
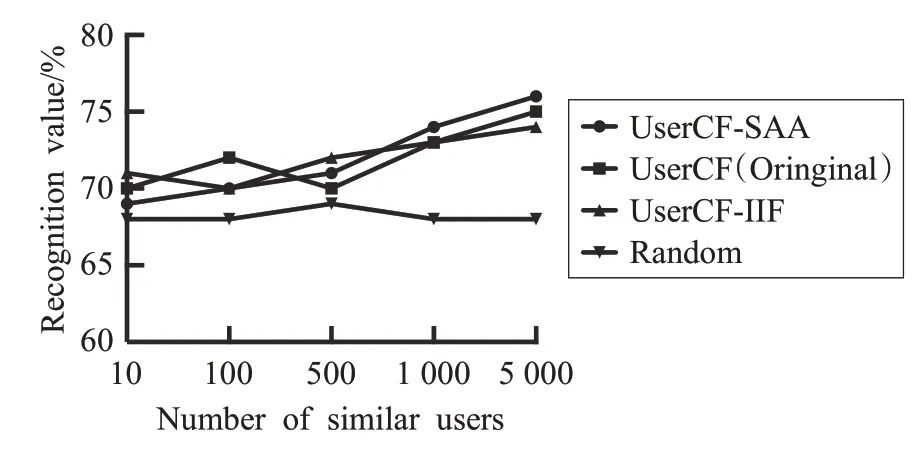
图12 改进推荐系统的平均认可度对比-1M(Model=MovieLens-1M,Test size=0.4,Number of Movies=1 000)

图13 改进推荐系统的平均认可度对比-10M(Model=MovieLens-10M,Test size=0.4,Number of Movies=1 000)
通过图 12 可以看到,在 1M 数据集上,UserCF 和UserCF-IIF都出现了一段先下降再上升的趋势,这是因为它们在给出推荐列表时,将用户相似度与喜好程度做了一个简单的求积排序,弱化了相似用户的共有特征,在相似用户数较少时共有特征不显著,用户偏好就会成为一个影响推荐结果的重要因子,相似用户的增大,会加剧这种负面影响,从而造成了认可度的下降;随着相似用户数的增大,起主导作用就变成了用户间的共有特征,因此认可度也随着相似用户数量的增大而增大;因为UserCF-IIF中引入了流行商品惩罚机制,它的回落出现得更早且更明显。而对于图13,由于训练数据的增加,模型能够更好地拟合相似用户的偏好特征,找出其共性,使得曲线更贴近真实情况。
SAA 方式较其他两种方式对于相似用户的数量更为敏感,几乎呈现出线性增长的趋势,这是因为本文在做推荐时,将用户相似度和目标用户认可度分别进行了处理,这样不仅能够挖掘出相似用户之间的共有特征,同时也考虑了目标用户对于电影本身的认可度,随着相似用户数的增加,相似用户之间的共有特征提取得就更准确,推荐电影的认可度也就相应提高了。从图12、13中可以看到,当相似用户数量到达400之后这种线性增长更为明显。值得关注的是,当用户数量超过1 000后,由于相似用户群中的用户评价行为趋于相似,推荐系统平均认可度提升也趋于平缓。SAA 方式在用户数为5 000时,平均认可度最高达到了76.7%。
图14、15展示了1 000个相似用户在不同推荐系统下,对于推荐电影的实际评分分布,横轴表示不同的推荐电影数量。由上面两图可看出,基于SAA 算法(右侧)的推荐电影实际评分最高达到了3.41 分(满分为5分),而传统的User-CF 推荐系统(左侧)的最高评分为3.09分。由此可知,使用SAA改进算法的推荐系统可以获得更高的用户评分,从另一个方面印证了本算法对于推荐精确率性能的提升。

图14 SAA与传统推荐系统用户评分对比-1M(Model=MovieLens-1M)
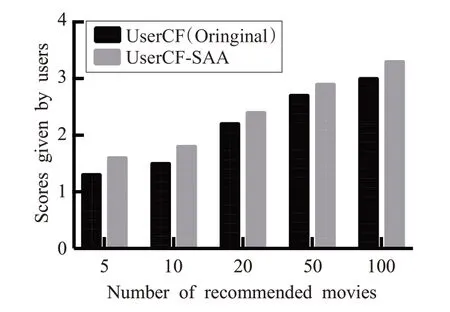
图15 SAA与传统推荐系统用户评分对比-10M(Model=MovieLens-10M)
MAE 是计算预测评分与用户实际评分的差值,从而衡量推荐系统的准确度,是目前较为广泛的评价推荐系统的性能指标之一。MAE与推荐系统的推荐精度呈负相关,推荐精度越高则MAE 值越小。本文采用步长为20,迭代20 次的方式评价了SAA 方式与文献[32]中的MAE 指标。T-ICF 表示传统协同过滤算法,P-ICF 为文献[32]中改进的协同过滤算法。由图16 的仿真结果可以看出,电影最近邻数目在50~70 之间Ada-Boosting方式呈现逐渐减少的趋势,而在超过70后MAE值呈现出不变甚至缓慢上升的趋势,与改进的P-ICF呈现的变化趋势一致,但较之提升了1.2%~1.5%,从而带来更高的推荐准确度。由于电影邻居数目较大时会引入噪声数据造成原本相似度较小的电影被误判成电影邻居,这一现象表明应合理设置邻居数目以获取较高的推荐准确度。图17中在10M数据集下表现出了相似的变化规律,在近邻数量大于70 之后,其变化趋势与P-ICF 更接近。

图16 MAE指标对比-1M(Data set∶Test set=4∶1,Number of iteration=20,Model=MovieLens-1M)

图17 MAE指标对比-10M(Data set∶Test set=4∶1,Number of iteration=20,Model=MovieLens-10M)
5 结语
本文在传统UserCF 算法的基础上,提出了注意力模型与神经网络相结合的方式,通过神经网络提取高阶特征,针对特定推荐商品的属性进行加权分配,增大相似商品的权重,减少非相似商品的权重,得到目标用户对推荐商品的认可度评分。再通过自适应增强学习模型对推荐结果进行优选,提高了推荐结果的准确性。同时,本文首次引入了相似用户平均认可度的概念,用来评价推荐物品在相似用户集中的平均认可程度。最后通过系统仿真验证了本算法的正确性和可行性,并给出了改进算法与当前主流的协同过滤推荐算法的性能对比及分析。
猜你喜欢
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
都市家教·上半月(2017年4期)2017-05-15
江苏教育·职业教育(2017年4期)2017-05-08
课程教育研究·学法教法研究(2017年1期)2017-03-21
中国卫生(2016年5期)2016-11-12
教学研究(2016年2期)2016-05-14
