
一元和二元函数的数据建模方法及其在火电机组中的应用
2020-07-01 08:06康英伟段松涛刘向伟梁正玉
上海电力大学学报 2020年3期
康英伟, 段松涛, 刘向伟, 朱 峰, 杨 平, 梁正玉
(1.上海电力大学, 上海 200090; 2.润电能源科学技术有限公司, 河南 郑州 450000)
目前,我国大多数火电厂都已安装了厂级监控信息系统(Supervisory Information System,SIS)。其历史数据库储存了火电机组运行的海量历史数据,其中包含机组特性的宝贵信息。如何有效地利用机组的历史数据实现控制和运行的优化便很自然地成为一个重要的研究课题[1-4]。相应地,关于数据建模方法及其在火电生产领域的应用近年来也受到越来越多的重视。
一元和二元函数分别指只有1个和2个自变量的静态函数模型。尽管这两类模型都较为简单,却具有相当广泛的代表性,在火电生产领域亦是如此,其重要性不容轻视。例如:锅炉的烟气含氧量是反映燃料燃烧充分程度的重要指标,若建立以烟气最优含氧量为因变量、以机组负荷为自变量的一元函数模型,并将其嵌入锅炉燃烧自动控制系统的控制策略中,就可以提升锅炉运行的热效率[5-8];汽轮机的阀门流量特性是调节汽门开度与通过汽门的蒸汽流量间的映射关系,若建立汽轮机阀门流量特性的一元函数模型(以蒸汽流量为因变量,调节汽门开度为自变量),就可以优化数字式电液(Digital Electro Hydraulic,DEH)调节系统的配汽曲线,有效避免机组一次调频性能下降、功率低频振荡等问题的发生[9-12];机组负荷受到调节汽门开度和主蒸汽压力2个因素的影响,若建立以机组负荷为因变量、以调节汽门开度和主蒸汽压力为自变量的二元函数模型,便可从根本上掌握机组的负荷特性,进而优化机组的运行方式。因此,基于火电机组的历史数据,研究并发展简单有效的一元和二元函数建模方法,对掌握机组特性、提升机组的安全性和经济性具有十分重要的作用。
SIS中火电机组的历史数据是时间序列数据。由于机组变负荷和其他扰动因素的存在,历史数据中包含有大量的非稳态过程数据,因此基于历史数据建立一元和二元函数模型需主要解决两个方面的问题:一是历史数据中稳态数据的检测与提取问题;二是一元和二元函数的数据建模问题,即如何根据提取出的稳态数据建立所需形式的一元和二元函数模型。对于问题一,根据检测原理的不同,目前已经提出了基于机理分析、统计分析和趋势提取等原理的多种稳态检测方法[13-17],部分方法已被应用于实际生产中。对于问题二,在统计学、数值分析和机器学习等领域已有十分丰富的建模方法,每种方法各有其特点及适用范围。由于实际应用场景的多样性,建模目的和建模要求各不相同,从而形成形式多样的数据建模问题,因此需要针对性地发展建模方法。
本文专注于问题二的解决,将给出2种一元函数数据建模方法和1种二元函数数据建模方法。以下分别介绍这些数据建模方法,并给出这些方法在某600 MW超临界火电机组负荷特性建模中的应用实例。
1 一元函数数据建模方法
一元函数数据建模是数据建模中最基本的问题,解决此类问题的常用方法是曲线拟合[18-19]。根据选用的拟合基函数的不同,曲线拟合方法有多项式拟合、高斯拟合、傅里叶拟合等。这些曲线拟合方法均采用较为复杂的非线性函数形式,而一些应用场景却要求采用更为简单的分段直线模型形式。例如,目前火电机组控制系统的软件平台就普遍支持用分段直线模型逼近各种一元非线性函数关系。
在已有的分段直线拟合方法中,文献[20-23]的方法都是根据局部数据点的变化情况,自动进行分段,不仅直线分段数无法控制,而且无法保证分段直线拟合的整体最优;文献[24]的方法本质上是通过穷举搜索实现分段直线拟合的整体最优,但当拟合数据点较多时,计算复杂度会非常高。已有的这些分段直线拟合方法均适用于数据信噪比高、分布较均匀且变化较缓慢的情况,而从工业现场获得的数据往往含有噪声、疏密分布不均且变化较快。
因此,本节给出解决该问题的2种方法:基于给定间隔点横坐标和基于曲线拟合的分段直线拟合方法。这里对一元函数数据建模问题的提法为:给定稳态数据集S={xj,yj},j=1,2,3,…,n,其中xj彼此不同且按由小到大顺序排列,要求将一元函数关系y=f(x)以足够的精度建模为指定分段数的分段直线模型。
1.1 基于给定间隔点横坐标的分段直线拟合方法
该方法的基本思想为:首先,根据分段数的要求,通过观察数据点的分布情况和走向趋势,给定各段直线间隔点(也包括首段直线的起点和末段直线的终点)横坐标;然后,利用最小二乘方法,以总拟合误差平方和最小为优化目标,求得间隔点纵坐标,从而得到各分段直线方程。
该方法的具体步骤如下。
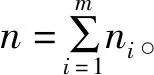
步骤2 根据间隔点坐标(Xi,Yi)(其中纵坐标Yi为待求量),可以得到各段直线方程的表达式。其中,第i段直线方程的表达式为
(1)
步骤3 利用步骤2得到的直线方程,推导出各段直线拟合的误差平方和ei以及总误差平方和e的表达式。ei和e分别定义如下
(2)
(3)
式中:下标i,k代表第i段数据中的第k个数据点;上标^代表预测值。
步骤4 为使分段直线预测的总误差平方和e最小,须满足e对Yi的偏导数为零的条件,即
(4)
根据分段直线拟合的总误差平方和的表达式,可以得到e对Yi的偏导数的表达式如下。
当i=0时,
(5)
当i=1,2,3,…,(m-1)时,
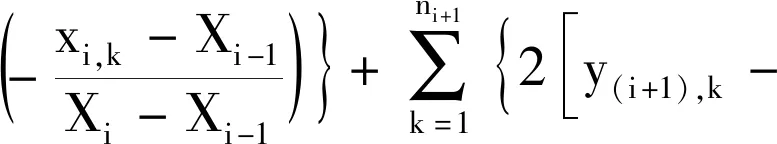
(6)
当i=m时,
(7)
将式(5)~式(7)代入式(4)中,整理后得到以间隔点纵坐标Yi为未知数的线性方程组,其中包含(m+1)个方程、(m+1)个未知数,具体表达式为
AY=B
(8)
式中Y=[Y0,…,Yi,…,Ym]T,进而解得Yi。
步骤5 将步骤4得到的间隔点坐标(Xi,Yi)代入式(1)中,即可得到m段连续的分段拟合的直线方程。
1.2 基于曲线拟合的分段直线拟合方法
该方法的基本思想为:通过“曲线拟合+分段直线逼近”的方式建立分段直线模型,即先利用成熟的曲线拟合方法对离散数据点进行拟合,再对拟合曲线进行分段直线逼近。
该方法的具体步骤如下。
步骤1 选择合适的曲线拟合方法对离散数据点进行曲线拟合,以达到要求的拟合效果。常用的曲线拟合方法有多项式拟合、高斯拟合、傅里叶拟合等,但不局限于此。曲线拟合方法的选择以取得好的拟合效果为依据。该步骤的目的在于通过曲线拟合捕捉数据点变化的主要特征。
步骤2 采用多段直线去逼近步骤1中得到的拟合曲线,最终得到分段直线模型。分段直线逼近策略具体为:以拟合曲线的起点和终点作为两个初始节点确定1条直线,并找到该直线与拟合曲线的最大误差点作为新添加节点,得到2段直线,再找到该2段直线与拟合曲线的最大误差点作为新添加节点,得到3段直线,以此类推,不断添加下去,直到直线分段数达到指定的分段数m为止。
步骤3 将步骤2得到的各节点坐标(Xi,Yi)代入式(1)中,即可得到m段连续的分段拟合的直线方程。
2 二元函数数据建模方法
解决二元函数数据建模问题的常用方法是曲面拟合[18-19]。曲面拟合方法能较好地克服数据中噪声的影响,反映数据变化的整体趋势,但是面对不同的非线性映射关系,如何确定二元拟合函数的形式尚缺乏有效的方法,则大大降低了该方法的通用性。基于上述一元函数数据建模方法,本文给出一种简单实用的二元函数数据建模方法,即分段直线拟合-插值混合型方法。
该方法的基本思想为:将拟合和插值方法融合起来,通过“分段直线拟合+插值”的方式实现二元函数的数据建模,即利用分段直线拟合方法表示因变量随其中一个自变量的变化情况,再利用插值方法表示因变量随另一个自变量的变化情况,从而完成对二元函数的建模。
这里对二元函数数据建模问题的提法为:给定原始稳态数据集T={xf,yf,zf},f=1,2,3,…,N,其中,x和z为自变量,y为因变量,要求以足够的精度建立二元函数模型y=f(x,z)。
该方法的具体步骤如下。
步骤1 对原始稳态数据集T做简单的统计处理及排序处理,得到q个稳态数据集Th={xg,h,yg,h,zh},g=1,2,3,…,Nh,h=1,2,3,…,q。其中,Nh为zh所对应的数据点数,q为T中相异z的数目,xg,h彼此不同且已按由小到大顺序排列,下标g,h代表稳态数据集Th中的第g个数据点。
步骤2 从q个zh中选择并确定p个z的插值节点zH,H=1,2,3,…,p。z的插值节点主要根据zh所对应的数据点数、点分布情况以及xg,h覆盖的数值范围选定。为获得更好的建模效果,插值节点zH的具体选定原则为:zH应尽量均匀覆盖变量z的整个取值范围;zH所对应的数据点(xg,H,yg,H)应尽量多且沿x方向有良好的分布特性;zH所对应数据点的xg,H覆盖的数值范围应尽可能宽。
步骤3 分别利用稳态数据集TH,H=1,2,3,…,p,对一元函数y=f(x,zH)进行分段直线拟合。
步骤4 在自变量z方向上,通过插值方法计算二元函数y=f(x,z)的值。
3 应用实例
火电机组的负荷特性可以表示为二元函数关系
y=f(x,z)
(9)
x——调节汽门开度,%;
z——主蒸汽压力,MPa。
当主蒸汽压力保持恒定时,负荷特性简化为一元函数关系
y=f(x)
(10)
建模数据均取自某600 MW超临界火电机组现场数据。由于原始数据是时间序列数据,为了获得稳态数据集,采用一种基于分段曲线拟合的稳态检测方法进行稳态数据的检测。该稳态检测方法的原理是对原始时间序列数据进行分段曲线拟合,利用重叠数据加权来保证各段边界的连续性和光滑性,根据拟合曲线各点的一阶导数和二阶导数信息来判断各时刻点是否处于稳定状态。关于该方法的细节可以参阅文献[16]。
3.1 一元函数建模实例
原始数据为机组主蒸汽压力24.25 MPa条件下的时间序列数据。对原始数据进行稳态检测和提取,并进行排序和统计处理后,得到稳态数据集S={xj,yj},j=1,2,3,…,86,其中xj彼此不同且已按由小到大顺序排列。分别采用基于给定间隔点横坐标和基于曲线拟合的分段直线拟合方法对一元函数关系y=f(x)建模。
应用基于给定间隔点横坐标的分段直线拟合方法的建模过程如下。
(1) 观察该数据集中数据点的分布情况和走向趋势,将数据分为5段,并给定直线间隔点的横坐标X=[X0,X1,X2,X3,X4,X5]T=[82.50,85.00,87.00,89.00,90.00,92.00]T。
(2) 根据分段间隔点坐标(Xi,Yi),i=0,1,2,…,5,得到各段直线方程的表达式,并推导出分段直线拟合的总误差平方和e的表达式。
(3) 将e对Yi求偏导,并令偏导数为零,得到以间隔点纵坐标Yi为未知数的线性方程组AY=B,其中:
排课相关方法包括医生工作强度计算以及医生工作强度调整方法。医生工作强度计算方法主要用于计算医生医疗和教学的综合工作强度,医生工作强度调整方法用于调整医生医疗和教学的工作安排,均衡医生医疗和教学的综合工作强度。
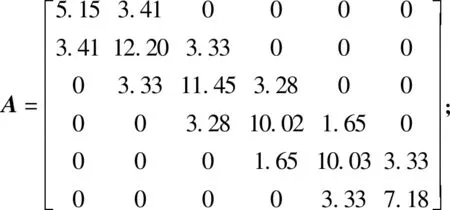

求解以上线性方程组,得到间隔点纵坐标Y=[Y0,Y1,Y2,Y3,Y4,Y5]T=[511.37,543.49,564.55,588.42,603.92,618.17]T。从而得到直线分5段时各节点的坐标:(82.50,511.37),(85.00,543.49),(87.00,564.55),(89.00,588.42),(90.00,603.92),(92.00,618.17)。
(4) 将各节点坐标代入式(1)即可得到各段直线方程。分段直线拟合效果(分5段)如图1所示。
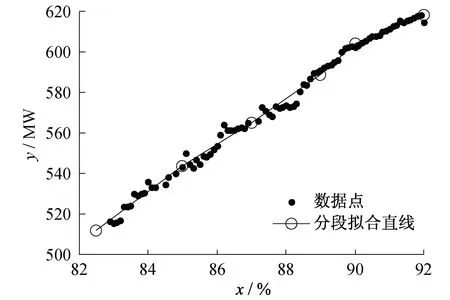
图1 基于给定间隔点横坐标方法的拟合效果
应用基于曲线拟合的分段直线拟合方法的建模过程如下。
(1) 选择合适的曲线拟合方法对离散数据点进行曲线拟合。经尝试发现,采用如下的6阶高斯函数拟合这些离散的数据点,可获得令人满意的拟合效果。
(11)
式中:al,bl,cl——高斯函数的3个参数,具体取值见表1。

表1 6阶高斯拟合的参数取值
(2) 对所得的6阶高斯曲线进行分段直线逼近。以拟合曲线的起点和终点作为分段直线的两个初始节点,并将分段直线与拟合曲线的最大误差点作为新添加节点,不断添加下去,直到达到指定的分段数5为止。从而得到直线分5段时各节点的坐标:(82.90,513.16),(85.60,545.63),(86.24,560.50),(88.02,572.15),(89.48,597.05),(92.00,615.36)。
(3) 将各节点坐标代入式(1)即可得到各段直线方程。分段直线拟合效果(分5段)如图2所示。
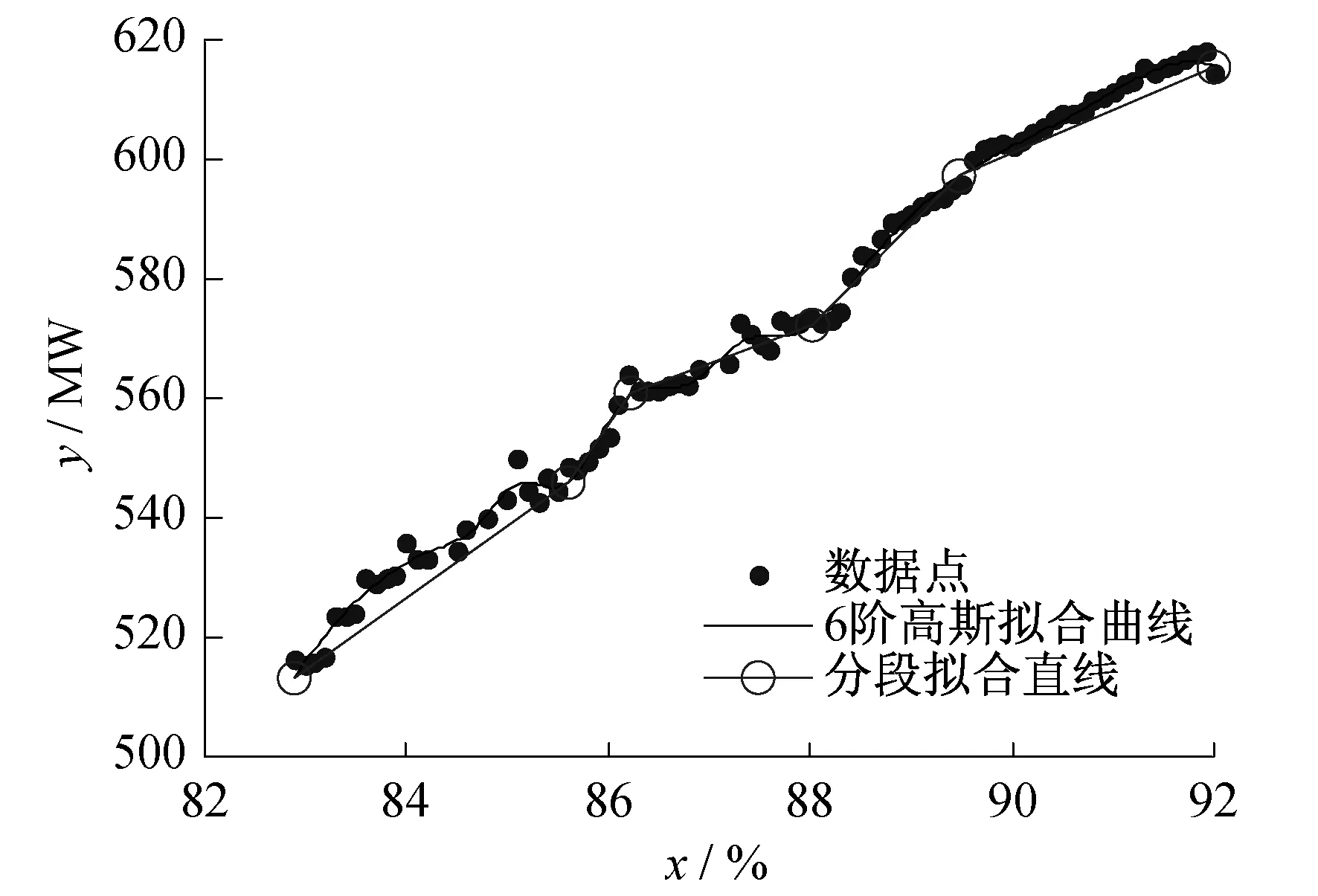
图2 基于曲线拟合方法的拟合效果
以上应用实例说明了这两种一元函数数据建模方法的有效性。通过以上应用实例,可以看出两种方法的特点。这两种方法均具有直线分段数可控、数据适用性广等优点,对于不均匀分布、变化较快的数据都可以有效建模。第1种方法的算法在分段数比较多时会变得很复杂,且对数据点的人工分段影响了此方法的准确性、简单性和实用性。相比第1种方法,第2种方法的优势是完全自动地确定分段节点且算法十分简单,实现方便,实用性强。但这是以放弃拟合总误差平方和最小为代价的。考虑到绝大多数应用场景并不严格要求总误差平方和最小,因此这一点完全可以接受。此外,值得指出的是,第2种方法在分段直线逼近之前,先要对数据进行曲线拟合,相当于对数据进行了平滑处理,因此该方法可以在一定程度上克服数据噪声的影响。
3.2 二元函数建模实例
原始数据为某600 MW超临界火电机组各种主蒸汽压力条件下的时间序列数据。对原始数据进行稳态检测和提取,得到原始稳态数据集T={xf,yf,zf},f=1,2,3,…,801 408。采用分段直线拟合-插值混合型的二元函数数据建模方法,建立二元函数模型y=f(x,z)。建模过程如下。
(1) 统计出T中相异z的数目为148,按z对T进行划分并作简单的统计处理及排序处理后,得到148个稳态数据集Th={xg,h,yg,h,zh},g=1,2,3,…,Nh,h=1,2,3,…,148,其中,xg,h已经按由小到大顺序排列。
(2) 根据每个zh所对应的数据点数、点分布情况以及xg,h覆盖的数值范围,从148个zh中选择并确定了8个z的插值节点,写成向量形式为[14.80,16.50,17.90,18.60,20.20,21.80,23.70,24.40]T。这8个z的插值节点基本均匀地覆盖了变量z的整个取值范围,所对应的数据点数分别为51,90,89,83,75,64,128,126,并且数据点沿x方向的分布特性良好。
(3) 分别利用z插值节点所对应的稳态数据集TH,H=1,2,3,…,8,对一元函数y=f(x,zH)进行分段直线拟合。这里采用基于曲线拟合的分段直线拟合方法,得到各分段节点的坐标。当zH=14.80 MPa时,对一元函数y=f(x,zH)拟合的直线分段数为1;当zH取其他值时,直线分段数均为12。图3给出了z节点选取及分段直线拟合效果图。
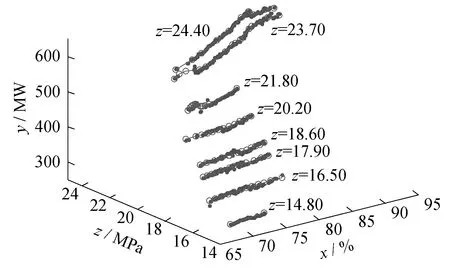
图3 z节点选取及分段直线拟合效果
(4) 在自变量z方向上,采用线性插值方法计算二元函数y=f(x,z)的值。图4给出了当23.70 MPa≤z<24.40 MPa时,在z方向上线性插值的示意图(取x=85%截面)。
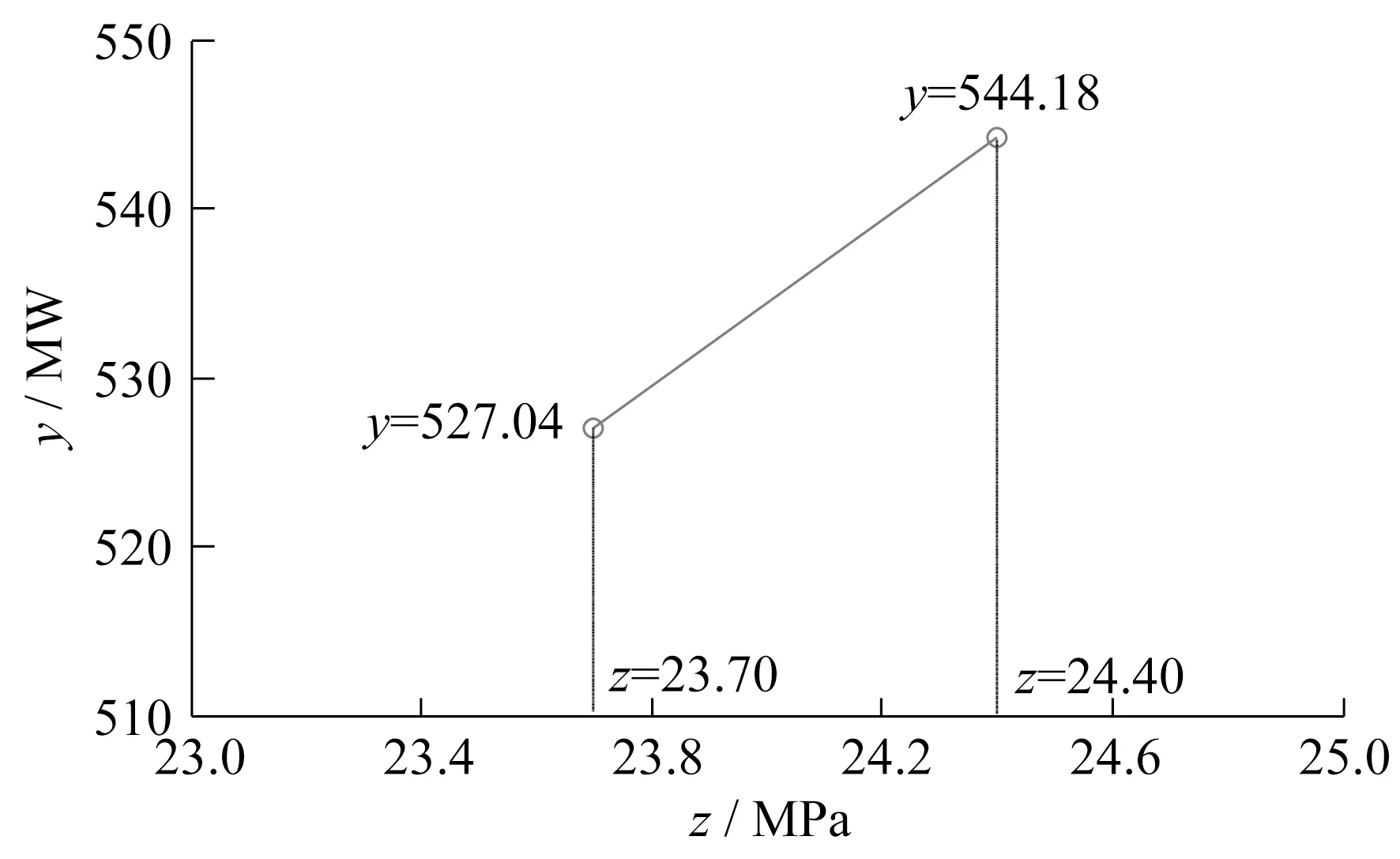
图4 z方向上线性插值示意

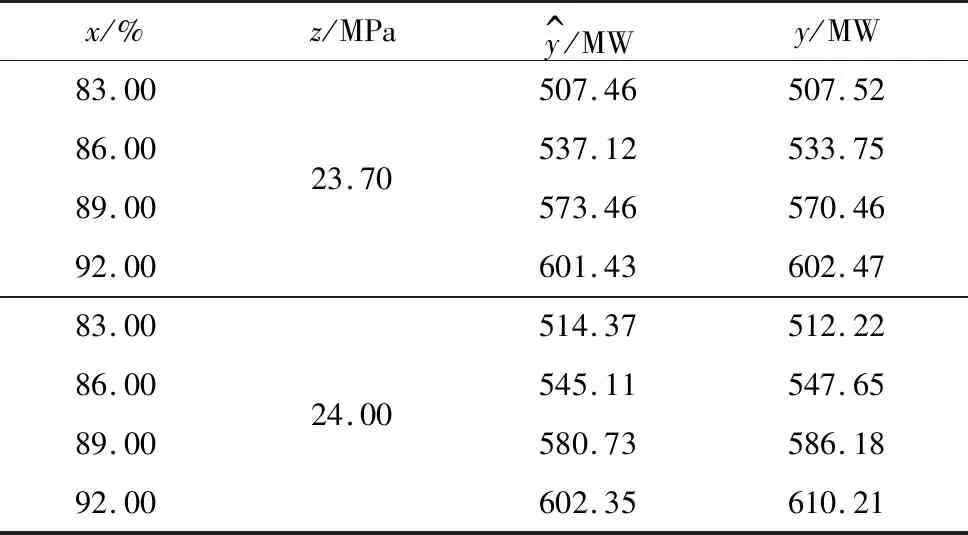
表3 二元函数模型预测结果
由表3可以看出,所建立的二元函数模型无论是在x方向上还是在z方向上都能较好地反映数据的变化趋势,并取得较好的预测效果。需要指出的是,建模精度可通过改变拟合和插值节点的数量加以调整。
以上应用实例说明了该二元函数数据建模方法的有效性。
4 结 语
本文给出了2种一元函数数据建模方法和1种二元函数数据建模方法,并通过某600 MW超临界火电机组负荷特性的建模实例验证了这些方法的有效性。
2种一元函数数据建模方法(基于给定间隔点横坐标和基于曲线拟合的分段直线拟合方法)均具有直线分段数可控、数据适用性广等优点。相比基于给定间隔点横坐标的分段直线拟合方法,基于曲线拟合的分段直线拟合方法具有算法简单、可自动确定分段节点等优点,实用性较强,而这是以放弃拟合总误差平方和最小为代价的。
相比已有的二元函数数据建模方法,分段直线拟合-插值混合型的二元函数数据建模方法具有灵活性高、通用性强、模型形式简单等优点。
将本文所给出的数据建模方法开发成软件,可以通过交互的方式十分方便地完成从历史数据到一元或二元函数模型的建模全过程。
猜你喜欢
遗传(2022年9期)2022-10-10
大电机技术(2022年3期)2022-08-06
煤气与热力(2021年4期)2021-06-09
气象学报(2021年2期)2021-05-13
现代计算机(2020年31期)2020-12-28
数学小灵通·3-4年级(2020年4期)2020-06-24
数学大世界(2020年2期)2020-03-07
中华戏曲(2020年1期)2020-02-12
小学生学习指导(低年级)(2018年11期)2018-12-03
中学生数理化·高一版(2018年1期)2018-02-10
