
Multi-block SSD based on small object detection for UAV railway scene surveillance
2020-06-22 06:57YundongLIHnDONGHonggungLIXuynZHANGBochngZHANGZhingXIAO
CHINESE JOURNAL OF AERONAUTICS 2020年6期
Yundong LI, Hn DONG, Honggung LI, Xuyn ZHANG,Bochng ZHANG, Zhing XIAO
a North China University of Technology, Beijing 100144, China
b Key Laboratory of Large Structure Health Monitoring and Control, Shijiazhuang 050043, China
c Unmanned System Research Institute, Beihang University, Beijing 100083, China
d Guangdong Provincial Key Laboratory of Computer Vision and Virtual Reality Technology, Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences, Shenzhen 518055, China
e School of Automation Science and Electrical Engineering, Beihang University, Beijing 100083, China
f State Key Laboratory of Information Engineering in Surveying, Wuhan University, Wuhan 430079, China
KEYWORDS Deep learning;Multi-block Single Shot MultiBox Detector (SSD);Objection detection;Railway scene;Unmanned aerial vehicle remote sensing
Abstract A method of multi-block Single Shot MultiBox Detector (SSD) based on small object detection is proposed to the railway scene of unmanned aerial vehicle surveillance. To address the limitation of small object detection, a multi-block SSD mechanism, which consists of three steps, is designed. First, the original input images are segmented into several overlapped patches.Second,each patch is separately fed into an SSD to detect the objects.Third,the patches are merged together through two stages.In the first stage,the truncated object of the sub-layer detection result is spliced.In the second stage,a sub-layer suppression and filtering algorithm applying the concept of non-maximum suppression is utilized to remove the overlapped boxes of sub-layers. The boxes that are not detected in the main-layer are retained.In addition,no sufficient labeled training samples of railway circumstance are available, thereby hindering the deployment of SSD. A two-stage training strategy leveraging to transfer learning is adopted to solve this issue. The deep learning model is preliminarily trained using labeled data of numerous auxiliaries,and then it is refined using only a few samples of railway scene.A railway spot in China,which is easily damaged by landslides,is investigated as a case study. Experimental results show that the proposed multi-block SSD method produces an overall accuracy of 96.6% and obtains an improvement of up to 9.2% compared with the traditional SSD.
1. Introduction
Unmanned Aerial Vehicle Remote Sensing (UAVRS) as a means of aerospace remote sensing is a strong complement of the satellite and aerial remote sensing of manned aircraft.1,2Given the exponential development of the sensors and instruments to be installed onboard, UAVRS applications exhibiting new potential are continuously increasing.3-6UAVRS has been widely utilized in various areas in the past decade owing to its real-time video transmission,detection of high-risk areas, low cost, high resolution, flexibility, and other advantages.7
A potentially valuable application is Unmanned Aerial Vehicle (UAV) surveillance of railway abnormal target intrusion. Intrusion of abnormal objects, such as pedestrians, falling rocks, animals, and vehicles, can impose great threats to the safe operation of trains and result in traffic accidents.8-11For instance, continuous rainfall induced a landslide that caused the severe derailment accident of a K859 passenger train on May 23, 2010. The accident, which occurred in a mountain area between Yujiang and Dongxiang in Jiangxi Province, led to the death of 19 people. Recently, with the rapid development of computer vision technology,UAV intelligent video surveillance has become popular in this field12,13due to its several advantages, such as convenience, low cost,and intuitive results.
2. Related work
In recent years, object detection algorithm based on deep learning has attracted excessive attention from researchers.Girshick et al14. proposed a R-CNN (Convolutional Neural Network) method adopting Selective Search,15which uses clustering methods to divide the images of several groups to obtain hierarchical groups of multiple candidate boxes.However, the R-CNN algorithm has shortcomings: The Selective Search algorithm extracts approximately 2000 candidate regions, which require numerous repeated calculations to process. Moreover, the Selective Search algorithm consumes a large amount of processing time for extracting candidate regions, thereby affecting the real-time performance of target detection. Spatial Pyramid Pooling (SPP)-Net16removes the crop/warp operation on the original image and replaces it with the SPP on the convolution features,thereby ignoring the size of the input image. Fast-RCNN17combines the essence of R-CNN and SPP-Net and adopts the function of multitasking loss, which makes the training and testing of the entire network convenient.Faster-R-CNN18introduces a region proposal network to replace Selective Search. Numerous attempts are performed to build fast detectors in the abovementioned algorithms.However, speed can only be attained at the cost of significantly decreased detection accuracy.
Except for the regional proposal detectors, several efficient algorithms are available, which can fully utilize the idea of regression and directly obtain the target position borders and categories at the multiple locations of the original image.YOLO19is a CNN that can simultaneously predict multiple box positions and categories,which achieves end-to-end object detection.YOLO is faster than Faster-R-CNN,but it has poor performance with regard to detecting box position, especially on small-volume or group-like objects. SSD20is a state-ofthe-art object detection system that can detect objects of images by using a single deep neural network. In comparison with previous object detection algorithms, SSD eliminates bounding box proposals and feature resampling and applies separate small convolutional filters to multiple feature maps.Thus, SSD achieves a significant improvement in terms of speed and accuracy.
In the research of detecting abnormal objects in a railway scene using deep learning,21,22Wang proposed a fast feature extraction algorithm for railway clearance intruding based on CNN. This method attempts to build a reliable detector,including applying a simplified fully connected network, pretraining convolutional kernels, and adding sparse parameters.However, this method is limited to detecting images with low resolution(picture size 64×64,128×128)and has a few false alarms in empty scene.Li et al.23proposed an intrusion detection algorithm for foreign objects based on deep belief networks and used the softmax classification network to train the image data.Although this algorithm only considers the situation of traveling train, it uses the train as the detection object to simulate the invasion of abnormal object of the real scene.
3. Work in this paper
This paper proposes a multi-block SSD method integrating object detection and classification based on deep learning.SSD has better detection performance than other state-ofthe-art algorithms. SSD has two advantages, namely, realtime processing and high accuracy. However, few problems are observed in SSD application to railway scenes, for example,small objects are difficult to detect,whereas model training requires numerous labeled data.
To improve the detection accuracy of small objects, the original image is sliced into several overlapped sub-images.Then,these sub-images are fed into the SSD network.The segmentation of sub-images can enhance the local contextual information and prevent the objects from being truncated.This study aims to improve object detection accuracy when only limited samples are available. A two-stage training strategy leveraging to transfer learning is adopted to solve this issue. The deep learning model is preliminarily trained using auxiliary labeled data and then refined using a few samples of railway scene.
4. Multi-block SSD based on small object detection
4.1. SSD architecture
VGG16 is adopted as the base network of SSD.Several convolutional layers with gradually decreasing sizes are added to the base network to generate multiscale pyramid feature maps.SSD applies default boxes with different aspect ratios. This process ensures that SSD can detect multiscale objects with high accuracy. As illustrated in Fig. 1,20SSD uses two 3×3 convolutional layers to predict the offsets of default boxes and the scores of categories.This method not only uses the last layer to process object detection but also utilizes some shallow layers of the base network and all of the newly added layers.In Fig. 1, after the convolution operation, the feature map contains three parameters:length,width,and number of channels.For example, after the fc6 layer convolution operation, the specification of the feature map is [19,19,1024].
SSD matches multiple default boxes in a single ground truth box of the best Jaccard overlap higher than the threshold. Thus, an object can have multiple highly overlapped boxes. Then, all confident boxes are iteratively postprocessed using Non-Maximum Suppression (NMS) to refine the final output box.
4.2. Multi-block SSD module
Among various object detection methods, SSD performs greatly in speed and detection accuracy. However, SSD has a limitation in which small objects are not detected well. For example, bottles and plants are typical small-sized objects,whereas the detection results of the SSD300 model generate mean Average Precision (mAP) values of 38.9% and 41.2%,20respectively. These values are generally poor compared with other categories.One of the most important factors is that the SSD network combines predictions from multiple feature maps with different resolutions to handle objects with various sizes naturally. However, the features extracted by deep layers are abstract and contain limited information on small objects. Thus, the effect of falling rock detection in the railway scene is unsatisfied.
In this paper, we propose a multi-block SSD object detection method,as shown in Fig.2,V1-V4 represent the specific positions of the divided blocks,for example,V1 represents the upper left region. w1 and w2 represent the split width. First,the method slices a detection image into four overlapped patches, wherein the overlap ratios of width and height are woverand hover, respectively. In this way, local information can be increased and real objects can be prevented from being truncated as much as possible. Second, the main image and four sub-images are simultaneously processed with SSD detection. Finally, the model merging process is divided into two stages. In the first stage, the truncated object of the sub-layer detection result is spliced.In the second stage,a sub-layer suppression and filtering algorithm applying the NMS concept is utilized to remove the overlapped boxes of sub-layers. The boxes that are not detected in the main-layer are retained.Fig. 3 presents the multi-block SSD flowchart in this study.
The number of sub-blocks plays an important role in this method to balance the detection accuracy and speed. As the number of cutting blocks increases, the detection accuracy increases, whereas the detection speed decreases. When the number of detection blocks increases to a certain threshold dep ending on the size of the original detected image,the integrity of the object to be detected is destroyed,and the detection accuracy is decreased.In our method,we divide the image into four sub-blocks.In this way,the shapes of detected objects can be maintained, and the detection accuracy and speed can achieve good results.
4.2.1. Region merge splicing
Fig.4 shows the detection boxes of the truncated objects of the boundary area.For objects of the boundary,if their categories are the same and the coincidence of their boundary lines is greater than the threshold based on Eq. (1), the two boxes must be combined.

where L1represents the boundary line of the detected box in the certain area near the horizontal axis and L2represents that in another area.
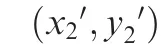
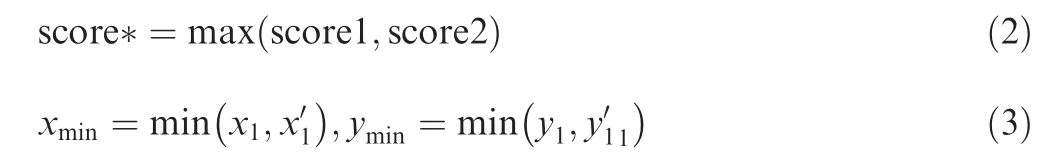
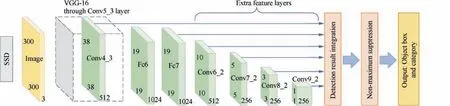
Fig. 1 Framework of SSD.
Fig. 2 Multi-block SSD module.
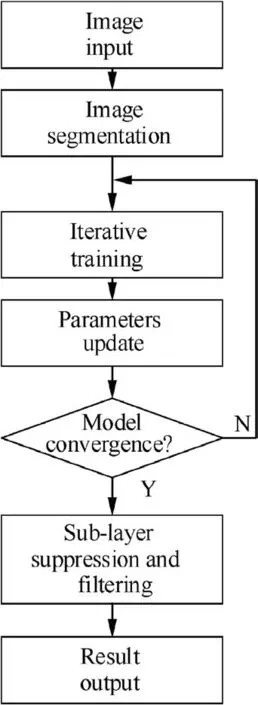
Fig. 3 Multi-block SSD flowchart.
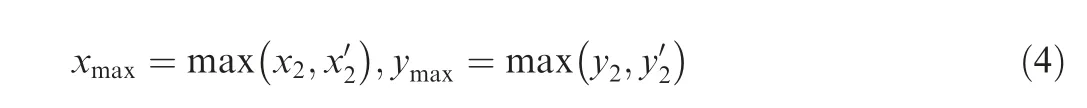
Prior to fusion splicing,the coordinates of boxes detected in sub-images must be initially converted into corresponding coordinates in the original image. These detection results are ranked in the order of prediction confidence.
4.2.2. Sub-layer suppression and filtering
When conducting object detection in an image, multiple highscore detection boxes may exist surrounding each target object.To remove the extra detection boxes, the NMS algorithm is required for subsequent processing to reserve one detection box of each object. As shown in Fig. 5(a), three detection boxes are observed around the face before NMS with scores of 0.79, 0.83, and 0.89. After the NMS is performed, the lower-score boxes of the IOU greater than the fixed threshold are suppressed, and the highest-score box is reserved. The result is shown in Fig. 5(b). The IOU is calculated as

During sub-layer suppression and filtering, the detection boxes of the sub-layer are matched and compared with the main-layer detection result by applying the NMS method.Moreover, the compared boxes will be removed if the IOU is higher than the threshold. Therefore, the overlapped boxes of sub-layers are removed, whereas the boxes that are not detected in the main-layer are retained.
4.3. Using multi-block SSD for railway abnormal object detection
Fig.6(a)shows one of the typical railway scenes investigated in this study. In comparison with VOC2007 dataset, which includes 20 categories, only objects of relatively high appearance probabilities are detected. Three categories of objects,namely, a person, a train, and stones, are used in the current scene.Fig.6(b)shows a train passing through the investigated spot.
The impressive performance of deep learning comes at the expense of numerous labeled training samples; otherwise, it is prone to overfitting and falling into a local minimum. No sufficient labeled samples of railway scene are available.Therefore,we initially apply the VGG16 base network20pre-trained on the ILSVRC CLS-LOC dataset,wherein the weights of the previous layers are retained to shorten the training time significantly.The newly added layers are initialized using the Xavier method to allow the gradient values to maintain approximately the same proportion at each layer of the network.Then, a two-stage training strategy leveraging to transfer learning is adopted to solve shortage of training data. After pre-training using the normal scene dataset, the railway scene dataset is used to fine-tune the multi-block SSD model.Section 5.3 presents the details.

Fig. 4 Region merge splicing in multi-block SSD.
5. Experimental results and discussion
The proposed model is built on the conventional SSD20implemented based on Caffe. We select SSD300 to conduct the experiments, which can be found at the website: https://github.com/weiliu89/caffe/tree/ssd. Furthermore, the computer used to train the model has a single NVIDIA GTX 1080 GPU. We evaluate object detection accuracy in terms of mAP, as used in most literature. However, the calculation principle of mAP involves averaging the correct rates of different recall rates, which cannot efficiently reflect the advantages of sub-layers’ suppression and filtering. Therefore, we apply mF1 index to compare the performance of multi-block, conventional, and other SSDs. The mF1 index is defined as

where F1 is expressed as

Fig. 5 NMS examples.

Fig. 6 Railway scene.

where n, TP,Prediction and GroundTruth are the number of detection categories, true predictions, predictions, and true labels, respectively.
5.1. Dataset
Dataset preparation is a preliminary work for training deep networks. Some images, including people, trains, and stones,are collected under railway scenarios.Considering security reasons for railway operation,obtaining a large number of images is difficult. Therefore, we create two datasets inspired by the idea of transfer learning. The first dataset is composed of 5000 images collected from normal scenarios,whereas the second dataset is composed of 2000 images collected from railway scenarios.The normal dataset is used to pre-train the SSD network, and the special dataset is used to fine-tune the network.The test dataset is a collection of samples of the railway scene,which includes 1500 images.
5.2. Training method using auxiliary dataset
We conduct the experiments on two datasets:One for the normal scene and the other for the railway scene. First, the SSD model is trained using the normal scene dataset. The VGG16 pre-training model, which is derived from SSD20trained on ILSVRC CLS-LOC dataset, is loaded during training, and the initial learning rate is set to 10-4. The initial learning rate depends on the size of datasets and empirical selections in SSD-related papers20,24. As shown in Fig. 7, the loss tends to converge after 120000 iterations,and the accuracy tends to stabilize in the training process.Second,we use the railway scene dataset to train the model continually for 60000 iterations,30000 each of which is conducted for learning rates 10-5and 10-6, respectively. The model parameters are fine-tuned to adapt to a railway scene after 60000 iterations using the railway scene dataset. Finally, we accomplish model training in the railway scene, wherein the batch size of the training is set to 16.
Fig. 7 presents the loss of training and the test accuracy of the model based on the log file during the training of multiblock SSD. As shown in Fig. 7, the losses of normal and railway scenes are gradually decreased as the number of iterations increases, and the overall performance exhibits a state of convergence. The test accuracy of the normal scenario fluctuates up and down before 120000 iterations and then gradually stabilizes as the learning rate decreases. The final accuracy is 54.9% mAP based on the training log file. The accuracy of the railway scene is gradually moving upward and tends to stabilize.Furthermore,the final resulting accuracy is 88.9%mAP based on the training log file,thereby improving the results.In summary, the model refined using a few samples of railway scene after preliminarily training using auxiliary labeled data has enhanced performance.
5.3. Experimental results
To verify the effectiveness of our method,experiments are conducted on the railway test dataset. The values of Precision,Recall, F1, and mF1 in Tables 1 and 2 are calculated using Eqs. (6)-(9).
The conventional SSD algorithm is implemented on the basis of extant literature.19Table 1 displays the detection results on the test set.
As shown in Table 1,the accuracy rate of conventional SSD is good.However,the recall rate is insufficient. The recall rate of stones is only 56.4%,and the degree of missed inspection is evident. In general, the conventional SSD detection effect is average.
The improved SSD algorithm is implemented on the basis of extant literature24. Table 2 presents the detection results on the test set.
As shown in Table 2, the difference between the precision values of the improved and traditional SSDs is not evident,and the average reduction is only 0.8%. However, the algorithm has insufficient performance due to the large reduction in the recall rate of the improved SSD and the high missed detection rate.
In multi-block SSD experiments, woverand hover(Section 4.2) are set to one-twentieth of the width and one-tenth of the height of the test image, respectively. Table 3 depicts the detection results of multi-block SSD on the test set.
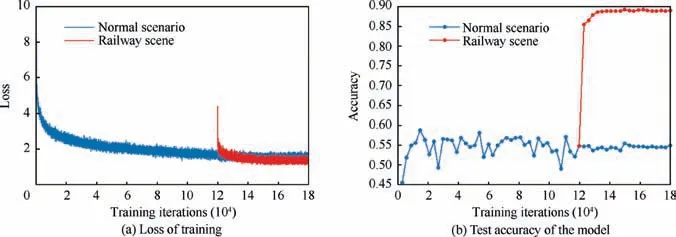
Fig. 7 Training loss and test accuracy of multi-block SSD model.
As shown in Table 3, multi-block SSD has good performance in precision and recall, especially for the recall rate of stones, which reaches 92.1%.
To compare different methods further directly,we integrate the above methods into Table 4.
As shown in Table 4, the precision of multi-block SSD is slightly lower than that of conventional and improved SSD.However, the recall of the former is considerably higher than that of the others. mF1 of the proposed method is 96.6%.An improvement of up to 9.2%is obtained against the conventional SSD and an improvement of up to 25.1% is obtained against the improved SSD.

Fig. 8 Comparison of detection results between conventional SDD and multi-block SSD methods.
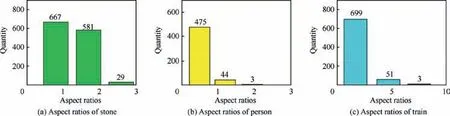
Fig. 9 Aspect ratios of objects in training dataset of railway scene.
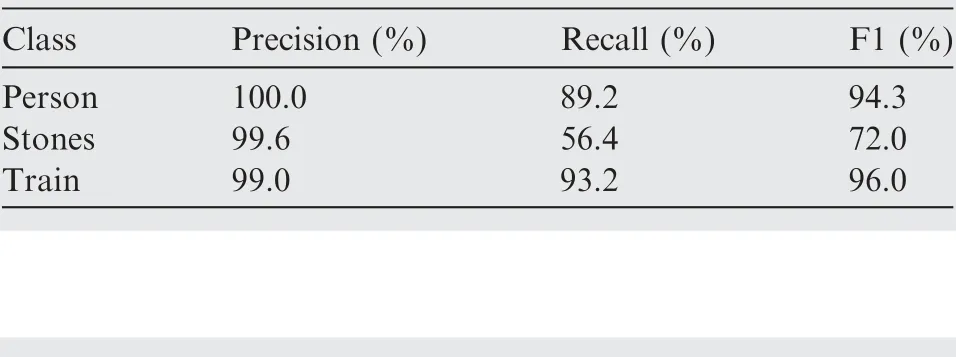
Table 1 Conventional SSD detection results.
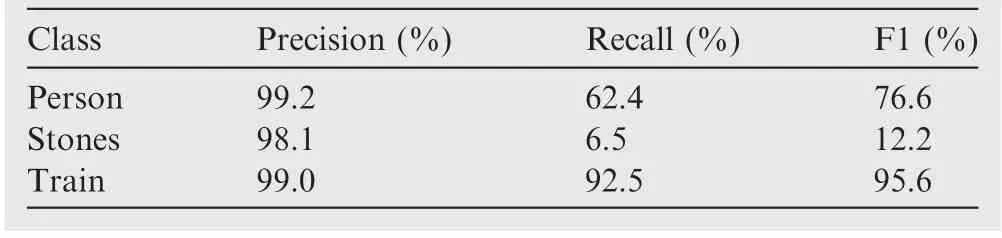
Table 2 Improved SSD detection results.
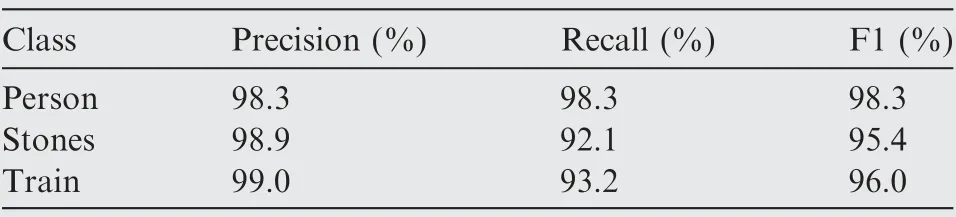
Table 3 Multi-block SSD detection results.

Table 4 Results comparison of different methods.
In particular, Fig. 8 presents some detection results. More stones are detected using the proposed multi-block SSD than using traditional SSD. Multi-block SSD can predict more objects, especially stones, and determine more accurate locations of objects’ boxes than the other methods. Some stones are not detected in the traditional SSD model, but multiblock SSD models can accurately detect them. In addition,multi-block SSD can efficiently detect a person at the edge of the picture and determine its location with a high degree of confidence.
5.4. Consideration of object aspect ratios
Fig. 9 shows the architecture of the SSD300 model in detail.The vertical coordinate is the number of samples.The horizontal coordinate is the aspect ratio of the sample. We use conv4_3, conv7 (fc7), conv6_2, conv7_2, conv8_2, and conv9_2 to predict locations and confidences. However, conv4_3, conv8_2, and conv9_2 can only associate four default boxes -omitting aspect ratio of 1/31/3 and 3 at each feature map location,which is different from the other layers.Accordingly,the aspect ratios of the objects must be considered in our dataset.Fig. 9 shows the statistical results.
The stone’s aspect ratios are{1,2}whereas the person’s and train’s aspect ratios are {1/2} and {1,2,3} respectively. These ratios are considered in the original SSD model. Therefore,we can impose the same aspect ratios for the default boxes as that of extant literature.20
6. Conclusions
UAV-based abnormal object intrusion into railway surveillance is one of the most important issues in railway operation security. Among various object detection methods, SSD performs efficiently in speed and detection accuracy. However,SSD has a limitation in which small objects are not detected well. To address this issue, we propose a novel method,namely, multi-block SSD, which adds sub-layers’ detection and increases local contextual information. The detection results of multi-block SSD and conventional SSD were compared. The proposed algorithm improves the detection rate of small objects by 23.2%. The overall detection capability of the proposed method outperforms that of conventional SSD framework.
Acknowledgements
This work is supported by Beijing Natural Science Foundation, China (No. 4182020), Open Fund of State Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing, Wuhan University, China (No. 17E01), and Key Laboratory for Health Monitoring and Control of Large Structures, Shijiazhuang, China (No. KLLSHMC1901).
 CHINESE JOURNAL OF AERONAUTICS2020年6期
CHINESE JOURNAL OF AERONAUTICS2020年6期
- CHINESE JOURNAL OF AERONAUTICS的其它文章
- A novel variable structure multi-model approach based on error-ambiguity decomposition
- A new online modelling method for aircraft engine state space model
- Cross-sectional deformation of H96 brass double-ridged rectangular tube in rotary draw bending process with diあerent yield criteria
- Application of a PCA-DBN-based surrogate model to robust aerodynamic design optimization
- Numerical exploration on the thermal invasion characteristics of two typical gap-cavity structures subjected to hypersonic airflow
- Experimental study on plasma jet deflection and energy extraction with MHD control