
专利新词发现的双向聚合度特征提取新方法
2020-06-06 02:07陈梅婕谢振平陈晓琪
计算机应用 2020年3期
陈梅婕,谢振平*,陈晓琪,许 鹏
(1. 江南大学数字媒体学院,江苏无锡214122; 2. 江苏省媒体设计与软件技术重点实验室(江南大学),江苏无锡214122;3. 常州佰腾科技有限公司,江苏常州213164)
(*通信作者电子邮箱xiezhenping@hotmail.com)
0 引言
据《专利法》第22 条中规定“授予专利权的发明和实用新型,应当具备新颖性、创造性和实用性”。由此可见新颖性是专利的重要原则,而由自然语言来表达专利所涉及的新颖技术或新颖概念时,新词成为专利文献中的关键要素,因此,新词发现是对专利文献智能分析的必要环节。
根据对专利文献的观察,上述新词在专利文献中通常表现为复合形式的长词语[1],同时,专利文献还普遍具有用词规范与叙述结构明确的特点。针对以上分析,研究提出一种基于双向聚合度特征的专利新词发现方法。新方法中,首先对于二元词,在引入双向条件概率的基础上,结合词频与词语搭配,构造了一种双向聚合度统计特征,再基于上述特征扩展提出词边界筛选规则,最后融合统计特征与规则设计了新词发现算法以提取出专利新词。
1 相关工作
新词发现是自然语言处理技术的重要组成[2],大量出现的新词对中文文档的分词、关键词提取及用户词典构建等诸多方面形成不利影响[3]。
目前用于中文新词发现的方法主要有:1)基于统计的方法;2)基于规则的方法;3)基于统计与规则相融合的方法[4]。基于统计的方法多指对实验语料中词串的组成及其特征表象进行统计[5],常见模型包括N-gram、支持向量机(Support Vector Machine,SVM)[6]、隐马尔可夫模型(Hidden Markov Model,HMM)[7]、最大熵(Maximum Entropy,ME)模型[8]以及条件随机场(Conditional Random Field,CRF)模型[9]等,但纯统计方法相对更适合查找较短词串;基于规则的方法多指利用词性特征来构建模板进行词串匹配[10],但基于规则的方法存在人工依赖问题并且通常存在规则局限性[11];基于统计与规则相融合的方法是当前主流方法,夭荣朋等[12]在N-gram 模型基础上提出了MBN-gram(N-gram based on Mutual information and Branch Entropy)算法,其中,采用改进的互信息进行候选项过滤,再使用邻接熵实施扩展与筛选;欧阳柳波等[13]针对不能有效识别领域组合词的问题,提出一种位置标签与词性相结合的组合词抽取方法;周霜霜等[14]利用互信息和邻接熵重构C/NC-value(C-value,NC-value)方法,融合人工构建的启发式规则库抽取新词并作为训练集;张华平等[15]在互信息特征中引入二元语法模型(Binary gram,Bi-gram)模型,提出了类互信息的计算方法,进一步使用Bi-gram 模型进行语料重切分,并结合统计特征提取新词。除上述三类方法外,还存在结合深度学习的序列标注方法,马建红等[16]融合卷积神经网络(Convolutional Neural Networks,CNN)、长短期记忆网络(Long Short-Term Memory,LSTM)抽取的字、词特征及引入的片段整体特征生成片段特征,再使用半马尔可夫条件随机场(Semi-Markov Conditional Random Field,SCRF)同时完成实体边界识别和分类;刘昱彤等[17]由改进的类Apriori 算法生成候选项集,通过Bi-LSTM-CRF(Bidirectional Long Short-Term Memory-Conditional Random Field)得到二字字串的切分概率,并利用候选项内部与边界切分概率的相关规则筛选出新词。
目前,针对中文专利的新词发现问题,相关的有监督模型研究需要大量数据作为先验知识[18-19],并且这些经验标注数据集或词库主要靠人工方式生成,也还较少有相关公开的标准知识素材库。因此,考虑大规模专利新词发现的实用性,专利新词发现算法应当更多地避免对先验监督知识的依赖[20]。相关的无监督模型研究中,赵飞龙等[21]首先对专利文档采用特定词性搭配模板得到候选项集,进一步将候选项内词的同现率作为特征来获取新词,一定程度地应对了分词结果的准确性问题;杨双龙等[1]提出从专利文档标题内自动提取的术语词性搭配规则,对正文部分采用词性规则得到候选术语,同时提出TermRank 排序算法截取一定数量的候选术语作为最终结果,并验证了该方法有效。
随着专利文献知识的大量产生,相关词汇的多样性与复杂性也将随之提升,词性规则的泛化能力必然受到局限。本文重点考虑中文专利新词发现的无监督方法,以专利新词统计特征的构造为核心,研究探索新的专利新词发现方法。
2 双向聚合度专利新词发现模型
针对专利新词具有通常具有较高复合度的特点,考虑构造一种基于双向条件概念的专利新词聚合度特征描述新方法,相应的新词发现框架如图1所示。

图1 本文模型框架Fig. 1 Framework of the proposed model
2.1 双向条件概率
专利二元词指两个单文字组成的二字词,对于任意二元词wiwj,传统条件概率遵循Bi-gram 模型思想,即认为当前字仅与前一个字相关,该模型中的条件概率表示为

其中:fi为wi的频次,fij为wiwj的频次。
但通常地,首字wi和尾字wj并不相同,则fi和fj也有所不同,而式(1)中只考虑了fi作为条件。由此,首先引入二元词的双向条件概率统计描述[22],分别为前向条件概率与后向条件概率:
1)前向条件概率可表示为式(1)
2)后向条件概率可表示为式(2)

2.2 双向聚合度特征
通过对专利文档观察可得:1)条件概率仅可视作二元词的局部特征;2)大部分停用字的前后搭配较丰富,对应文字的搭配数量较多。因此,针对1),可将二元词词频作为全局特征弥补条件概率的局限性,但其缺陷在于“高频错词”问题,即该特征会突出“的是”“有一”等无意义的高频错误词串,然而通过观察可知,此类高频词串大多包含停用字,根据2),可利用搭配数量特征削弱“高频错词”问题的影响。
综上所述,在定义了双向条件概率的基础上,本文结合词频及搭配数量特征,设计二元词的双向聚合度,分别为前向聚合度与后向聚合度:
1)前向聚合度可表示为式(3):

其中:α→为如式(5)的归一化因子,di→为首字wi的搭配数量,即有di→种具有相同首字wi的不同二元词。
2)后向聚合度可表示为式(4):

其中:α←为如式(6)的归一化因子,dj←为尾字wj的搭配数量,即有dj←种具有相同尾字wj的不同二元词。


其中:dmax→为各首字搭配数量中的最大值,dmax←为各尾字搭配数量中的最大值,fmax为文档样本内二元词词频的最大值。
2.3 词边界筛选规则
借鉴邻接熵思想,本文利用前、后向聚合度差值解析新词词边界特征,设计提出可作用于新词候选项过滤筛选的词边界规则。
首先,将单个文字分为左边界文字、右边界文字以及非边界文字。具体地,假设一字串为wiwjwk,则对于wj有如下3 种情况:
1)当b(wiwj)-b(wjwk)≥θ时,wj为右边界文字;
2)当b(wiwj)-b(wjwk)≤-θ时,wj为左边界文字;
3)否则,wj为非边界文字。
其中θ为词边界筛选阈值,且对于任意wiwj,b(wiwj)的定义如式(7):
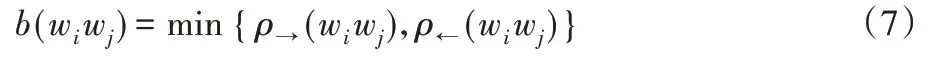
此外:若wj本身处于句首,则默认其为左边界文字;若本身处于句尾,则默认其为右边界文字。
最后,将词边界规则定义为:当候选项字串同时满足以下条件1)、2)时,保留此候选项,否则过滤此候选项:
1)候选项字串的第一个文字为左边界文字;
2)候选项字串的最后一个文字为右边界文字。
2.4 新词发现算法
首先,对文本进行预处理操作,即在文本中匹配停用词,进而使用停用词作为切分符,对文本进行粗切分,得到由一系列文本片段组成的文本片段集。本文中,停用词由手工抽取,部分停用词如表1所示。

表1 停用词示例Tab. 1 Examples of stop words
然后,对文本片段集中的每个文本片段,采用滑动窗法计算n元词权重,计算方法如式(8)、(9):
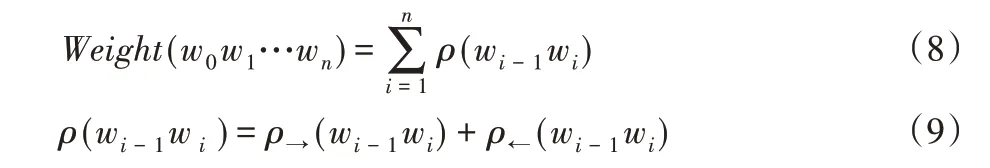
其中:n为窗口大小,同时,结合词边界规则提取候选项。
进一步地,引入词频阈值δ1与集合容量阈值δ2,设计形成如下的专利新词发现新算法。
算法1 本文专利新词发现算法。


最后,将由新词发现算法抽取的候选新词与词库中的已有词项进行比较,最终输出未记录的专利术语新词。
3 实验设计及结果分析
3.1 实验语料说明
本文实验所采用的专利文档语料由江苏佰腾科技有限公司提供。实验中单篇专利文档由对应专利文献中的6 个部分(专利名称、摘要、权利要求、技术领域、背景技术、发明目的)组合而成。
专利文献中的技术特征对专利新颖性判断具有重要作用[23],在专利法律制度中,技术特征是构成发明或者实用新型专利技术方案的组成要素,也包括要素之间的相互关系[24]。同时,在《专利法实施细则》第十九条中规定“权利要求书应当记载发明或者实用新型的技术特征”以及“权利要求中的技术特征可以引用说明书附图中相应的标记,该标记应当放在相应的技术特征后并置于括号内,便于理解权利要求。附图标记不得解释为对权利要求的限制”。因此,为考虑实验的可比较性与合理性,本文依据上述规范,在语料库中抽取一定数量的专利文档以构建实验数据集。所抽取文档的附图说明中均包含具有对应附图标记的技术特征词(如图2 所示),并在其权利要求书中均含有相应的引用,进一步地,在上述技术特征词中提取长度不超过9 字的词语,作为相应实验文档的标准新词结果,并在现有词库中对以上词语的匹配项进行剔除。具体地,本实验在语料库中抽取2 300 篇专利文档,其中标准新词总计22 762 个,并将这些专利文档随机地均匀划分为参数训练集和应用测试集。

图2 实验所用专利文献的附图说明示例Fig. 2 Example of appended drawing in patent document in experiments
3.2 实验方法
实验采用常用的3 个测评指标作为评价标准,分别为新词发现的准确率(Precision)、召回率(Recall)和F-测度值(Fscore),相应定义如下:

其中:M为新词发现模型判别生成的新词结果集合,B为标准结果集。准确率能够衡量模型评估新词的精确度,召回率能够衡量模型对新词发现的信息覆盖率,F-测度值能够平衡准确率和召回率影响,较为全面地评价模型性能。
3.3 参数分析
使用参数训练集对本文模型进行参数分析,需要分析的参数分别为滑动窗口最大值、词频阈值δ1、集合容量阈值δ2及词边界筛选阈值θ,各参数相互独立。其中,模型生成的新词数量与δ1、δ2及θ的参数值呈负相关,因此,本实验中均以最优的F-测度值结果来确定其最优参数值,实验结果如图3(a)~(c)所示。具体分析如下:
1)滑动窗口最大值。
由于本实验针对长度不超过9 字的专利词语,因此考虑滑动窗口最大值为9。
2)词频阈值δ1。
在设置δ2为3、θ为0.2 的情况下,实验将δ1分别设置为1、2、3、4、5、相应文本中二元词词频均值,其中,相应文本中二元词词频均值的策略主要考虑不同专利文本的篇幅情况各异,单纯数值参数可能缺乏自适应性。
由图3(a)可见,当δ1为相应文本中二元词词频均值时,模型具有相对最高的F-测度值。
3)集合容量阈值δ2。
在设置δ1为相应文本中二元词词频均值、θ为0.2的情况下,实验将δ2分别设置为1、2、3、4、5、6。
由图3(b)可见,当δ2为3 时,模型具有相对最高的F-测度值。
4)词边界筛选阈值θ。
在设置δ1为相应文本中二元词词频均值、δ2为3 的情况下,实验将θ分别设置为0.1、0.2、0.3、0.4、0.5、0.6。
由图3(c)可见,当θ取值0.4 或0.5 时,模型的F-测度值相对最高,由于在θ为0.4时,已达到F-测度值上升临界点,本文考虑θ为0.4时得到最优测评结果。
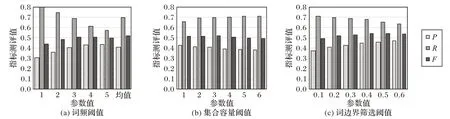
图3 不同参数的模型性能影响情况Fig. 3 Performance results of model with different parameters
综上所述,得到δ1为相应文本中二元词词频均值、δ2为3、θ为0.4的最优参数设置结果。
3.4 对比分析
基于3.3 节的模型参数结果,进一步使用应用测试集,将3 个相关方法作为对比方法,与本文模型进行新词发现结果对比实验分析。具体地,对比方法Ⅰ为中科院北京计算所汉语词法分析系统(Institute of Computing Technology,Chinese Lexical Analysis System,ICTCLAS)的新词发现工具,对比方法Ⅱ为文献[1]中提出的新词发现方法,对比方法Ⅲ为文献[21]中提出的新词发现方法。对比实验中,对比方法Ⅱ、对比方法Ⅲ所需的分词结果均使用ICTCLAS分词系统生成。
首先,对应用测试集中的每篇文档,将不同算法的全部新词结果作基准进行性能分析;其次,对比分析各模型在不同长度新词上的性能结果。在应用测试集中,不同词长l的新词数量分布如表2所示,其中l∈[2,9]。

表2 按词语长度划分的新词数量分布Tab. 2 Distribution on word length of new words in experimental dataset
对于全部新词,各模型识别结果对应的准确率、召回率和F-测度值如图4所示,纵轴为测评指标值。

图4 对比算法在全部新词上的发现性能Fig. 4 Discovery performance of the algorithms for comparison on all new words
图4 显示,本文模型基于使用参数训练集得到的模型参数,在应用测试集上也达到了相对稳定的测评结果,表明本文模型具备良好的泛化能力。同时,与其他3 种方法相比,本文在准确率方面分别提高了4.1、20.7及16.8个百分点,在召回率方面分别提高了9.1、7.6 及11.4 个百分点,在F-测度值方面分别提高了6.7、19.2 及17.2 个百分点。可见本文模型在各测评指标值上都获得了一定的性能提高,达到了相对更优的效果,初步说明了本文模型的有效性。
对于不同长度的新词,各模型识别结果对应的准确率、召回率和F-测度值分别如图5(a)~(c)所示,图中横轴均为词语所含字数,纵轴为测评指标值。

图5 对比算法在不同长度新词上的发现性能Fig. 5 Discovery performance of the algorithms for comparison on new words with different lengths
图5(a)~(c)显示,由于本模型中的权重计算对于短词语的独立抽取具有一定抑制性,因此对短词的测评结果不突出,但对长词的测评结果明显良好。具体地,本文模型在2 字新词的评测结果上低于对比方法Ⅰ,但优于对比方法Ⅱ、对比方法Ⅲ,而对比方法Ⅱ、对比方法Ⅲ在4 字新词的召回率上有明显优势,但其准确率与F-测度值均低于对比方法Ⅰ与本文模型;同时,根据F-测度值结果,本文模型明显提升了发现4~8字新词的综合性能,并且在5~8 字新词的各评测结果上均保持一定优势,说明本文模型对长专利新词具有较优兼顾能力,对比方法Ⅱ的长专利新词发现结果也相对较优,尤其在9 字新词的准确率与F-测度值上均高于其他模型,但在召回率上低于对比方法Ⅰ与本文模型,而本文模型能够在识别9 字新词的总体性能上高于对比方法Ⅰ。同时,对比方法Ⅰ与本文模型对词长的敏感性相对较弱,体现出了统计特征的自适应能力。
为进一步说明本文模型的有效性,对于5~8 字新词,各模型识别结果对应的准确率、召回率和F-测度值如图6 所示,纵轴为测评指标值。
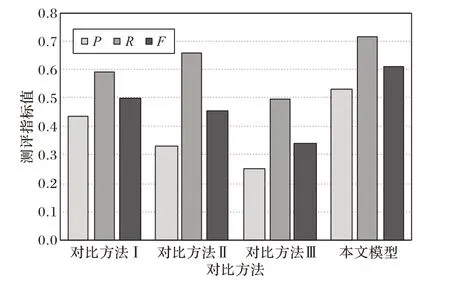
图6 对比算法在5-8字新词上的发现性能Fig. 6 Discovery performance of the algorithms for comparison on new words with 5-8 characters
图6 显示,本文模型相比于其他方法具有显著优势,说明本文模型对于5~8 字新词的发现更加具备有效性,也体现了本文模型在专利新词发现任务中的适用性特点。
最后,本实验在标准结果集中抽选10 个具有5 字及以上长度的新词作为实例分析对象,由表3 列出文中对比模型的相应识别结果,其首列为标准新词项,其余五列分别为对应模型结果中能够覆盖标准项的最长词串。其中,使用粗体标出的词项表示与标准项完全匹配;其他词项表示与标准项部分匹配;“—”表示没有覆盖到标准项中的任何部分。

表3 长串新词发现实验结果示例Tab. 3 Some examples of discovery results on long new words
对比分析表3 中的各结果可得,对比方法Ⅱ、对比方法Ⅲ方法体现出的问题均由词性规则的局限性导致,例如,“有机/b 复合/vn 绝缘/vn 外套/n”未能被上述方法中的任何模板所覆盖,然而表3 可说明,部分类似问题在本文模型中已得到有效改善。同时,以第2 行为例,本文模型未能有效提取该词项,其原因在于,该词项在文本中相对低频,此文本中又同时存在另一独立名词“处理单元”,间接削弱了词串“信息处理单元”的特征性,而对比方法Ⅱ、对比方法Ⅲ方法又可在一定程度上避免此问题。
3.5 扩展实验分析
为进一步分析本文模型的泛化能力,考虑专利领域术语也具备一定复合形式特点,因此,将模型直接迁移至领域术语抽取的扩展应用实验中,同时对于不同方法的领域术语抽取结果进行对比分析。
实验首先获取搜狗细胞词库中开放下载的《电力词汇大全》词库,再利用该词库对专利文档语料进行匹配,提取包含上述电力词汇且不同于3.1 节实验数据集的专利文档作为实验文档,然后将相应电力词汇作为该文档的标准领域术语结果,并在现有词库中对以上电力词汇的匹配项进行剔除。具体地,本实验在语料库中抽取2 000 篇专利文档,其中标准领域术语数量总计28 316。
扩展应用实验中,各模型抽取结果对应的准确率、召回率和F-测度值如图7所示,纵轴为测评指标值。
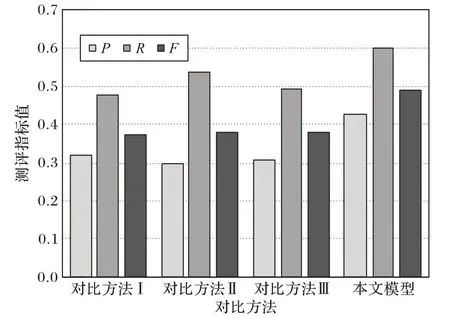
图7 对比算法在领域术语上的发现性能Fig. 7 Discovery performance of the algorithms for comparison on domain terms
图7 所示,在使用3.3 节描述的参数设置条件下,本文模型在扩展应用实验中也获得了更优的结果,与其他3 种方法相比,本文在准确率方面分别提高了10.6、12.7 及11.6 个百分点,在召回率方面分别提高了12.0、6.2 及10.6 个百分点,在F-测度值方面分别提高了11.6、11.0 及10.9 个百分点,显现了本文模型的良好泛化能力。
4 结语
本文通过引入二元词的双向条件概率信息,构造了一种新颖的双向聚合度统计特征,再由此特征扩展提出词边界筛选规则,最后融合统计特征与规则设计了新的专利新词发现算法。实验结果表明,新模型能够有效提升较长专利新词的识别发现能力,且模型计算简单,对预先监督训练的依赖性较弱,具有良好的实用性。研究中也发现,对于中文专利新词发现问题,如何更有效地识别新词中的深层语义嵌套问题,是探索更先进方法的关键所在。
猜你喜欢
东北师大学报(自然科学版)(2022年2期)2022-07-23
中学生天地(B版)(2022年4期)2022-05-17
福州大学学报(自然科学版)(2021年6期)2021-12-31
经济与管理(2020年4期)2020-12-28
亚太教育(2018年5期)2018-12-01
周末·校园文学(2017年35期)2018-02-06
数学教学通讯·高中版(2017年3期)2017-04-17
读者·校园版(2015年7期)2015-05-14
心理学报(2014年4期)2014-02-02
疯狂英语·原声版(2013年6期)2013-07-16
