
标签引导的生成对抗网络人脸表情识别域适应方法
2020-05-18 11:08孙冬梅张飞飞毛启容
计算机工程 2020年5期
孙冬梅,张飞飞,毛启容
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
0 概述
人脸表情识别(Facial Expression Recognition,FER)作为理解人类情感行为的重要手段[1],是计算机视觉中的主要任务之一。人脸表情识别的目标是将某个面部图像划分为多种情绪类型,如恐惧、愤怒、厌恶、悲伤、快乐和惊讶[2]等。近年来,人脸表情识别因其在人机交互、虚拟现实、数字娱乐等领域的潜在应用前景而受到广泛关注。
目前人脸表情识别方法包括3个部分[1],即人脸检测与预处理、表情相关特征提取与表示以及表情识别。根据特征提取的方式不同,情感相关特征分为手工特征和学习型特征。手工特征是利用手工设计的算法直接在一张人脸图像上提取的特征,如局部二值模式(Local Binary Pattern,LBP)算法提取的特征[3]、尺度不变特征(Scale-invariant Feature Transform,SIFT)算法提取的特征、Gabor特征、几何特征,以及基于各种手工特征得到的混合特征等,而学习型特征是通过训练好的机器模型对人脸中的情感特征自动进行学习得到的特征。目前获得学习型特征的方法主要有自动编码器(Auto-Encoder,AE)[4]、卷积神经网络(Convolutional Neural Network,CNN)[5]和深度神经网络(Deep Neural Network,DNN)[6]。表情识别方法[1-2,4-5]有很多,常用方法有人工神经网络(Artificial Neural Network,ANN)、支持向量机(Support Verctor Machine,SVM)[7]、K近邻算法(K-Nearest Neighbor,KNN)、贝叶斯模型、隐马尔科夫模型(Hidden Markov Model,HMM)以及混合分类器模型等。
传统的人脸表情识别主要针对实验室环境下基本典型表情的识别,但是这样的基本表情面部肌肉比较夸张,难以刻画和反映现实生活中人类情感变化的微妙性和复杂性。自然环境中的表情识别受光照变化、任意姿势变化、自发面部表情、不受约束的背景以及许多其他不可预测情况的影响,而且多数公开的自然环境下的人脸表情识别数据集都缺乏足够的训练数据。虽然有一些基于自然环境人脸表情数据库的研究,但是由于自然环境数据库的样本不足,人工标注又耗时耗力,因此目前主要还是基于实验室环境的数据库的研究。
近年来,生成对抗网络(Generative Adversarial Network,GAN)[8]在图像生成、图像到图像的翻译、风格转换等图像任务上有着良好表现。文献[9]利用生成对抗网络为图像中的遮挡区域生成上下文一致的补全图像,文献[10]模仿GAN的模式,提出模拟+无监督的学习方式,用无标注的真实数据将已有的合成图像美化成真实数据,提高了生成图像的真实性。文献[11]将域标签信息引入GAN实现多域的图像翻译,在人脸属性迁移和表情转换上取得了较好效果。
目前已经有一些研究利用GAN进行自然环境下的人脸表情识别,主要针对GAN解决自然环境下样本不足的问题。文献[12]把自然环境下的人脸表情识别作为域适应问题,将实验室环境的数据集作为源域、自然环境下的数据集作为目标域,利用网络中大量无标记的自然环境的人脸图片作为辅助域,在GAN基础上嵌入注意力机制,引导将实验环境下的人脸表情样本合成为自然环境的人脸表情样本。文献[13]建立像素级域适应模型,对源域进行渲染,利用GAN对渲染图像进行修正,得到更贴近目标域的渲染图像,该模型的手写体识别准确率较高。文献[14]通过对抗训练学习域不变性特征以及残差迁移策略实现了鲁棒的跨域图像自适应分类问题。
由于GAN难以定量评估何时能生成高质量的样本,而人脸表情识别任务对样本要求更精细,生成的样本往往达不到情感分类的要求,因此本文提出一种标签引导的生成对抗网络表情识别域适应方法(Label-Guided Domain Adaptation method in Generative Adverasial Network,LDAGAN)用以生成自然环境人脸表情样本。
1 标签引导的生成对抗网络表情识别方法
LDAGAN模型主要包含3个模块,分别为生成器模型、判别器模型和任务分类器模型。本节首先对所提出的标签先验引导的生成对抗网络表情识别模型结构进行简要概述,然后详细描述各个模块的学习过程。
1.1 模型结构
如图1所示,在将图像送入模型之前,首先对图像进行预处理,即主要利用libfaceDetection[15]算法进行人脸检测并截取人脸,再将所有图片归一化到相同的尺寸。将实验室环境下采集的数据库作为源域,自然环境下的人脸表情数据库为目标域,对于给定的大量源域样本Xs及其对应的情感标签ys,以及少量目标域带标签的图像Xt和yt,将情感标签转化为one-hot编码,如图中源域示例样本为伤心的表情,对应one-hot编码ys为[0000001],同理,目标域示例样本为开心的表情,对应one-hot编码yt为[0000010]。
假定源域和目标域之间的差异主要是由于分辨率、光照、颜色等低级的差异,因此初始化时,将随机噪声z混合目标域的情感标签yt作为条件,再和源域图像一起送入生成模型G,如图1中虚线框所示,学习得到符合该表情标签的人脸表情图像Xf并以此来迷惑判别模型。此外,将生成的图像Xf再用生成模型生成新的图像Xr,以保证生成的新图像Xr可以映射回原始图像Xs,从而保留生成的面部图像的局部结构信息。
生成的图像Xf与目标域的图像Xt输入判别模型D,判别模型D将两者进行比较,以辨别输入的图像是否来自目标域,并将判别结果返回给生成模型,从而调整生成模型的内部参数。
在生成图像的同时训练分类器,生成模型生成的图像Xf连带着情感标签y送入分类器模型T,和真实图像Xt及其情感标签yt一起训练分类器,并将分类结果返回给生成模型G,以此提高生成图像的质量。因此生成的图像Xf就像是源域和目标域之间的桥梁,以此缓解源域和目标域之间的域鸿沟。训练完成后既得到新的类似目标域数据样本Xf,又得到可以直接用于人脸表情识别分类任务的分类器模型T。该模型不仅适用于人脸表情识别任务,而且可以应用于其他图像分类任务。
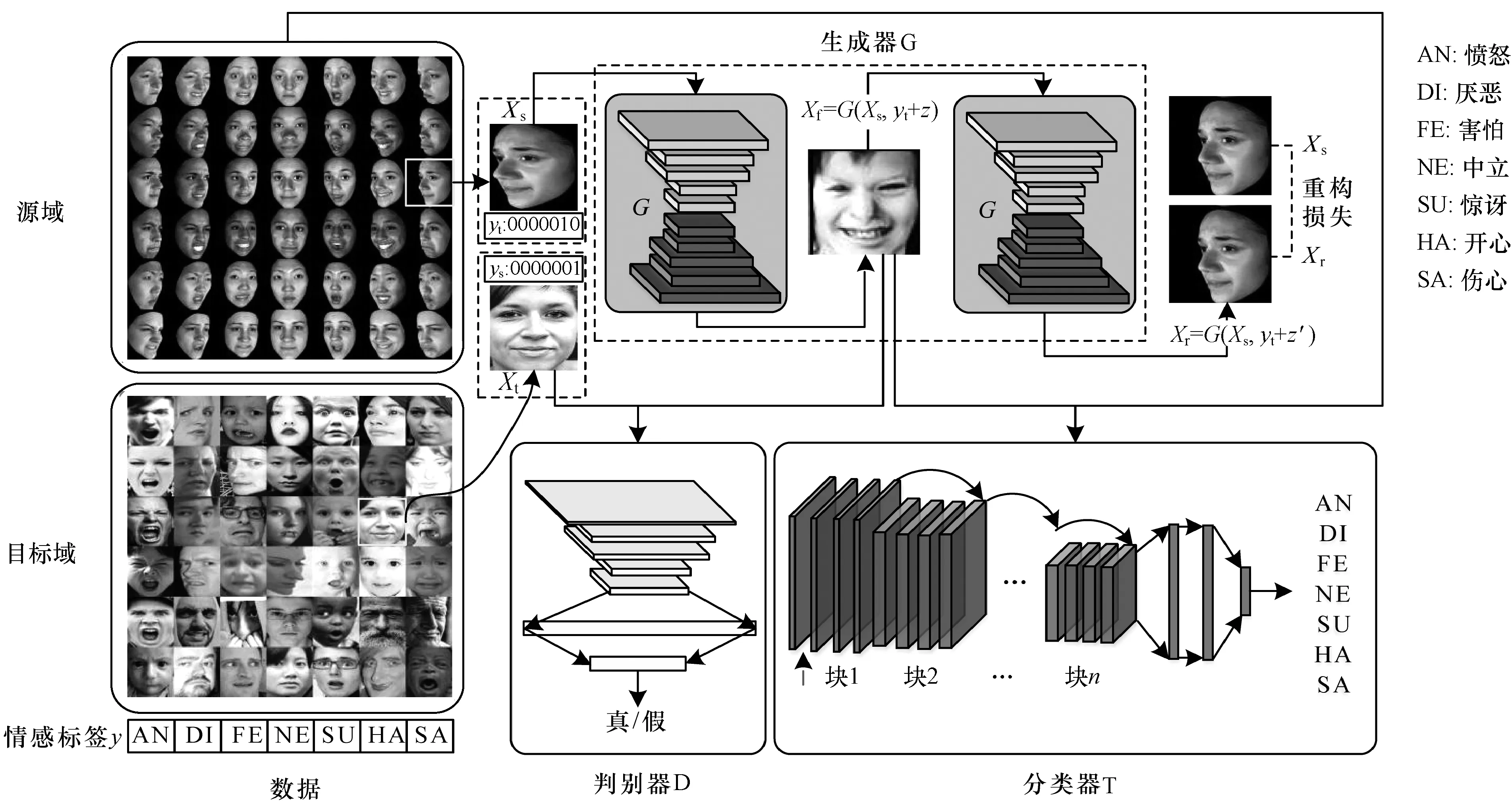
图1 LDAGAN模型结构
1.2 学习过程
1.2.1 生成模型与分类器
生成模型的目标是训练一个生成器G来学习2个域之间的映射,生成器模型G的主要作用是生成与目标域类似的图像,为此,随机选取源域Xs和目标域Xt的图像以及相应的情感标签ys、yt,用目标域情感标签yt混合随机噪声z为条件训练生成器G,将源域图像Xs翻译为符合目标域情感标签yt的图像Xf。要想生成的样本Xf足够像目标域的图像Xt,就要迷惑判别器D,使得判别模型D以更大的概率将其Xf判定为真实的目标域样本Xt。
为使生成模型生成的样本尽可能地保持源域样本的局部信息,同时生成的图像Xf可以直接用于表情分类任务,在对抗损失的基础上加入重构损失和分类任务损失,并将这三部分损失结合在一起作为最后的损失函数。
1)对抗损失。与以往的对抗网络相同,生成器为使生成的样本能够得到判别器最大的认可,将其生成的样本输入到判别器中,判别器能够给予更高的评分,同时,采用源域图像作为条件加入到生成器的输入中。对抗损失表示为:
Ladv=EXs~ps(xs)[logaD(G(xs,z+yt;θG);θD)]
(1)
2)重构损失。为使生成的图像Xf尽可能地接近目标域图像Xt并保持真实性,同时人脸内容尽可能保留源域图像的局部结构信息,本文将生成的图像Xf又送入生成模型再次生成新的图像Xr,并期望这个生成模型能够使得这个图像Xr能够与原始的源域图像Xs相同,因此,计算重构图像Xr与源域图像Xs像素之间的L1范数,并以此作为重构损失。重构损失表示为:
(2)
3)分类任务损失。分类器的主要是用于完成人脸表情识别分类任务,利用生成的图像和目标域图像训练分类器,目标是基于生成的数据训练分类器,并且这个分类器可以推广到目标域。分类器将任务分类损失传递给生成模型,从而指导分类模型生成的图像更接近真实目标域的图像。对于生成的图像,希望尽可能生成符合表情标签的人脸表情图像,这样的生成图像才能作为自然环境下带标签的人脸表情图像,以便今后使用。基于此考虑,本文设置了分类器的人脸表情识别的分类任务损失,用softmax交叉熵损失。任务损失表示为:
LT(G,T)=
EXs,yt,z[-yTlogaT(G(xf)-yTlogaT(xt)]=
EXs,yt,z′[-yTlogayt-yTlogayt]
(3)
综合以上三部分的损失函数,生成器的损失函数为:
LG=αLadv+βLrec+γLT(G,T)
(4)
其中,α、β、γ是三者之间的权重系数。
1.2.2 判别模型
判别模型的主要作用在于与生成模型进行对抗学习,不断提升自己的判别能力,以提高真假目标域样本的识别准确率。在LDAGAN模型中,判别模型由一系列卷积层构成。判别器有2种类型的输入,即生成模型生成的图像以及目标域图像。同时采用条件对抗网络的思想,以目标图像(图1中左下方的目标域图像)和相应的情感标签为条件,通过简单的通道拼接来将条件与原输入拼接作为判别器的最终输入。网络输出一个标量来表示判别器对输入的评分。在判别器中加入目标域图像以及相应的情感标签作为条件的目的,在于只有当生成样本足够真实并与目标域图像匹配时,判别模型才给予其更高的分数,即要求生成图像与目标域图像尽量保持风格一致。
在众多不同结构的对抗网络中,判别器的损失函数基本都保持一致,本文所使用的损失函数形式也相同。判别器共接受2种可能的输入:1)目标域样本,对于目标域样本而言,判别器的目的是给予其更高的评分,即EXt~pt(xt)logaD(xt)足够大;2)生成样本,对于生成样本而言,判别器的目的是给予其较低的评分,即Ex~pG(xs)D(G(xs,z+yt;θG))足够小。因此,损失函数可表示为:
LD=EXt[logaD(xt;θD)]+
EXs~ps(xs)[loga(1-D(G(xs,z+yt;θG);θD))]
(5)
2 实验与结果分析
2.1 数据库
为验证本文方法的有效性,本文在以下实验室环境数据库和自然环境数据库上进行实验。数据集具体描述如下:
1)BU-3DFE[16]。BU-3DFE数据库采集了实验室环境下的100个人物样本,其中56个女性样本和44个男性样本,每个人物样本有7种基本表情(中立、愤怒、厌恶、害怕、开心、伤心、惊讶),除了中立表情之外,其他6类表情都有4种表情强度,每种表情有5种姿态(0°、30°、45°、60°、90°)。本文中选取30°、45°、60°、90°4种姿态,以其中80%为训练样本(45个女性样本和11个男性样本),共8 000张图片,20%为测试样本(11个女性样本和9个男性样本),共2 000张图片。
2)RAF-DB[17]。Real-world Affect database(RAF-DB)是从网页爬取的真实情感数据库,有15 339张7种基本表情(中立,愤怒,厌恶,害怕,开心,伤心,惊讶)图片和3 954张11种混合表情图片。本文中只用7种基本表情,采用数据库提供的12 271张训练集图片和3 068张图片。
3)SFEW[18]。The Static Facial Expression in the Wild (SFEW)是从电影中截取的真实表情数据库,分为中立、愤怒、厌恶、害怕、开心、伤心、惊讶7种基本表情,作为自然环境下情感识别挑战Emotion Recognition in the Wild Challenge (EmotiW2015 Challenge)的官方比赛数据库,只提供了训练集、验证集、而测试集的情感类别标签未知。因此,本文中将891张训练集图片用来训练,431张验证集图片作为测试集。
4)CK+[19]。Cohn-Kanade(CK)的扩充版数据库包含实验室环境下控制的123个人物样本,包含7种基本表情(愤怒、蔑视、厌恶、害怕、开心、伤心、惊讶),本文采用其中6种基本表情图片(愤怒、厌恶、害怕、开心、伤心、惊讶),共927图片作为训练集。
2.2 实验设置
本文主要以RAF-DB数据库为目标域设计了多组对比实验,由于RAF-DB数据库存在严重的样本失衡问题,如:开心的样本有5 957张,而害怕的表情只有355张,因此本文用混淆矩阵的对角线的平均值代替识别率,作为判别标准。
根据图1构建的模型结构,首先,对于数据库没有提供截好的人脸图片,利用libfaceDetection算法[15]截取人脸,对于算法不能截取的人脸,手动截取人脸,并将所有的人脸图片归一化到64×64的尺寸,然后用Pytorch0.4.1框架构建如图1所示的网络模型,为了使人脸合成模型训练的更稳定,参考文献[11]中图像合成网络的相关的生成模块结构,设计生成器的编码器包含6个残差块,每个残差块内包含2个卷积层,每个卷积层后使用ReLU作为激活函数;解码器包含6个反卷积层,同样使用ReLU作为激活函数。判别器参考文献[13]中的判别器模型,包含4个卷积层、2个全连接层,Kernel大小为5,步长为2,每层滤波器个数依次为16、32、64、128。每个卷积层后使用批归一化以及ReLU激活函数。第一个全连接层,使用批归一化以及LReLU作为激活函数。分类器模型为Resnet50,在最后一层之后增加2个全连接层。每个全连接层滤波器个数为512 7。
实验中由于是源域和目标域一起训练,因此每一次训练周期随意选取的样本批次为两者的公约数,每一批次都训练一次判别器、生成器和分类器,训练中采用Adam优化算法,经过调优之后确定训练批次(batchsize)为32,利用网格搜索方法确定Adam优化算法参数b1为0.5,b2为0.999,式(4)中的对抗损失、分类任务损失和重构损失的权重参数分别为1、0.1和0.1,迭代次数设为500。
2.3 分类器模型选择
为选择合适的分类器模型,在RAF-DB数据库上对比几种典型的传统特征以及目前流行的深度学习模型的识别准确率,其中传统手工特征的识别方法为SVM,常用的深度学习模型包括卷积神经网络(VGG16、VGG19[21]、Resnet18和Resnet50[22])和RAF-DB数据库给出的基准方法DLP-CNN[17],目前较为先进的方法Boosting-POOF[20]。DLP-CNN模型是在深度卷积神经网络里增加局部保留损失以提高识别深度特征的能力。Boosting-POOF方法主要是利用训练集上人脸局部区域的低层次特征提取可鉴别性的中层特征,从而在测试集上进行识别。所有模型均利用RAF-DB数据集中的训练数据进行训练,然后在其测试集上进行测试,结果如表1所示,其中最后一列展示了平均表情识别率,基于手工特征的人脸表情识别方法LBP、HOG、Gabor以及以及深度方法DLP-CNN的相关结果由文献[17]提供,Boosting-POOF方法的结果由文献[20]提供。由表1可以看出,深度学习的方法比传统手工提取特征的方法识别率都要高,其中Resnet50结果最好,VGG16,VGG19模型识别率略有下降,因此,后续实验中以Resnet50作为分类器模型。

表1 不同分类模型在RAF-DB数据库上的识别率对比
2.4 学习性能比较
为验证LDAGAN方法的学习性能,在RAF-DB数据集上设置了3组对比实验。以BU-3DFE作为源域辅助数据集,RAF-DB作为目标域,首先验证重构损失对模型学习结果的影响;其次比较不同标签引导时的性能并可视化出不同标签引导的生成图片结果。
1)重构损失项的重要性比较
为验证重构损失项对实验结果的影响,设置以下实验,将随机噪声作为条件融入源域图片一起输入到生成模型去学习,对比有无重构损失项时的识别率,结果如表2所示,其中第1行z-r0代表没有重构损失项,第2行z代表采用了重构损失项。

表2 重构损失项的识别率对比
对比表2的第1行和第2行的结果可以发现,LDAGAN方法采用重构损失的识别率达到83.44%,相比不采用重构损失的识别结果提升了0.85%,验证了重构损失项的重要性。
2)不同标签引导对情感识别的影响
为验证不同标签引导对实验结果的影响,本文设置了4种不同的标签条件,分别是z代表随机噪声,实验中用随机均匀分布来制造随机噪声,org+z代表源域情感标签和随机噪声的混合,trg+z代表目标域情感标签和随机噪声的混合,org+trg+mask代表源域情感标签、目标域情感标签和掩码的混合,此处掩码是二维的掩码,具体表示方法为:[1 0]代表源域情感标签起作用,而忽略目标域情感标签,[0 1]代表目标域情感标签起作用,而忽略源域情感标签,结果如表3所示。
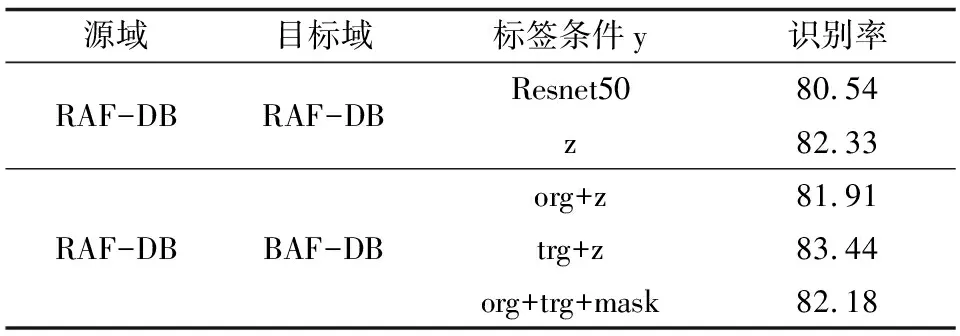
表3 不同标签条件对情感识别性能的影响
对比表3可以看出,LDAGAN模型识别结果比Resnet50的结果提升了0.94%~2.22%,表明LDAGAN模型从源域生成的样本有助于提高目标域的表情识别率,说明生成的样本非常接近目标域样本。另外,由表2可以看出,以目标域的情感标签与随机噪声混合(trg+z)作为先验条件融入源域图像相比其他的条件输入可以得到更好的识别效果,说明所提方法LDAGAN模型学习到了如何生成符合目标域情感标签的样本。
3)不同的标签引导时的可视化结果展示
为展示LDAGAN方法在不同的标签引导时随着迭代次数的而变化的生成图片,将生成图片以及对应的源域和目标域的图片可视化出来,结果如图2所示,其中第一部分是源域情感标签混合随机噪声的条件,即org+z;第二部分是目标域情感标签混合随机噪声的条件,即trg+z;第三部分是源域情感标签、目标域情感标签和掩码的混合的条件,即org+trg+mask。每一部分的第1行是源域图片,第2行是生成的图片,第3行是目标域图片。

图2 不同标签条件下的可视化结果
由图2可以看出,随着迭代次数的增加,LDAGAN模型生成的图片从源域的图像开始变化,逐渐越来越像目标域的图像,尤其是当迭代500次时,trg+z条件甚至学到了目标域遮挡的眼镜,说明LDAGAN的生成模型慢慢学习到目标域的背景、姿态和光照的信息。
4)与其他方法的比较
为验证LDAGAN方法的鲁棒性,本文将其与当前主流方法进行了对比,结果如表4所示。其中第1行是直接在RAF-DB数据集上训练的Resnet50模型在测试集上的识别结果。PixelDA[13]方法原来是做无监督的跨域方法,为与LDAGAN模型进行比较,此处将PixelDA改成监督的域适应方法,即将分类器模型的训练数据由源域和生成样本改成目标域和生成样本,经过多次实验,确定迭代次数为350,batchsize为32,学习率为0.000 1。Boosting-POOF[20]利用源域(CK+、SFEW、BU-3DFE、RAF-DB)人脸局部区域的低层次特征提取可鉴别性的中层特征,从而在目标域(RAF-DB数据集)上进行识别,Boosting-POOF方法的结果由文献[20]提供。

表4 与其他主流方法的识别率对比
由表4可以看出,LDAGAN方法比其他两种方法Boosting-POOF和PixelDA在相应的数据集上识别效果都要高出12%~13%,并且识别效果比单纯只用Resnet50模型有近3%的提升。相比以BU-3DFE为源域,以SFEW和CK+为源域的结果普遍要低一些,这可以归结为SFEW和CK+数据库的样本数量较BU-3DFE的样本数量少很多,模型很有可能已经过拟合,因此,在测试集上的识别结果最差。
5)跨库的比较
为验证LDAGAN方法在跨域实验上的性能,分别在SFEW和RAF-DB数据集上设计2组实验进行比较,结果如表5所示,其中每一块的第一行是没有用任何域适应方法,Resnet50表示在源域上训练的Resnet50模型直接用于目标域的识别测试。经过多次实验,确定PixelDA方法[13]在(BU-3DFE→SFEW)的跨库实验中的的迭代次数为200,batchsize为16,学习率为0.001。在(BU-3DFE→RAF-DB)的跨库实验中的的迭代次数为240,batchsize为32,学习率为0.001。

表5 跨域方法的识别率对比
由表5可知,PixelDA模型尽管在手写体任务上达到98%的跨域识别率[13],但是在人脸表情识别这种更精细的识别任务上表现效果较差。LDAGAN方法相比PixelDA模型在SFEW和RAF-DB数据库上的跨库识别率都要高,甚至在RAF-DB数据集上有7.68%的提升。
3 结束语
对于自然环境下的人脸表情识别,本文提出一种标签引导的生成对抗网络表情识别域适应方法。利用大量实验室环境下的数据库样本,将情感标签作为条件融入生成对抗网络,生成与自然环境下的人脸表情数据库样本相似的样本,以扩充自然环境的人脸表情数据库。该方法在生成图像的同时训练表情识别分类器,使分类器能够同时学到实验室环境以及自然环境的情感相关特征,从而提升表情识别率,而无须生成图像后再额外训练分类器。实验结果表明,本文方法在生成自然环境下人脸表情数据库样本和完成表情识别任务上均取得了良好的效果。针对当前主流方法在跨域识别任务上效果都不理想、生成的人脸在一些复杂结构的精细部分(如眼角等)仍存在明显模糊现象的问题,后续将提高本文方法生成图片的分辨率,进一步提升跨域人脸表情识别的准确率。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
计算机技术与发展(2020年11期)2020-12-04
动漫星空(2018年9期)2018-10-26
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
青年文学家(2015年29期)2016-05-09
航天返回与遥感(2014年5期)2014-07-31
奇闻怪事(2014年5期)2014-05-13
中原工学院学报(2014年4期)2014-04-01
