
基于深度信念网与隐变量模型的用户偏好建模
2020-05-18 11:07潘良辰吴鑫然
计算机工程 2020年5期
潘良辰,吴鑫然,岳 昆
(云南大学 信息学院,昆明 650500)
0 概述
随着Web2.0、电子商务和社交网络的快速发展,越来越多的用户通过各种Web平台参与到互联网活动中,因此,产生了大量的用户行为数据。用户对电影或商品的评分是目前Web2.0应用中具有代表性的一类用户行为数据,这些数据一般包含用户属性、评分对象属性和用户评分等可以直接观测到的信息,也蕴含着一些无法被直接观测到的信息,如表示用户喜好或选择倾向性的偏好信息。用户评分数据反映了用户偏好,用户偏好决定了用户评分。例如,MovieLens数据集[1]包括用户信息、电影信息和评分,电影信息包括年代、类型、语言等多种属性,用户信息包括年龄、性别、职业等属性信息,不同用户对不同电影属性有相应的喜好,用户、电影以及评分等属性间存在依赖关系并具有不确定性。因此,从评分数据中建立描述相关属性之间依赖关系及其不确定性的用户偏好模型,为个性化推荐和用户行为建模等应用提供知识模型和计算框架,具有重要的现实意义。
贝叶斯网(Bayesian Network,BN)[2]是一种重要的概率图模型,其是由一组节点组成的有向无环图(Directed Acyclic Graph,DAG),每个节点都有一个条件概率表(Conditional Probability Table,CPT)[3]。BN可定量地描述属性间的依赖关系,因此,其被广泛应用于智能分析和推断决策等领域。含隐变量的BN称为隐变量模型(Latent Variable Model,LVM)。通过LVM可有效描述评分数据中能直接观测到和不能直接观测到的属性之间的依赖关系,并可进行有效的推理计算,从而为用户偏好模型的建立提供支持。例如,对于MovieLens数据而言,可使用隐变量表示用户对电影的偏好,基于LVM学习方法构建包括用户、电影、评分和偏好属性的模型。
本文提出一种基于深度信念网(Deep Belief Network,DBN)与隐变量模型的用户偏好建模方法。采用深度信念网对评分数据进行分类,利用类别变量扩展隐变量模型,同时基于评分数据的特点和隐变量模型构建的关键步骤,给出模型构建时需要满足的约束条件以及该约束条件下模型的参数学习和结构学习方法。
1 问题分析
由于隐变量的取值无法被直接观测到,可认为其数据缺失。期望最大(Expectation Maximization,EM)算法[4]是在不完整数据情况下对数据进行填充并用于模型参数最大似然估计的一种有效方法。结构期望最大(Structure Expectation Maximization,SEM)[5]算法是一种结合了EM算法和打分搜索的结构学习方法。EM算法的运行涉及大量迭代计算[6],计算复杂度较高。从BN的结构及特点来看,CPT中概率参数的规模由其父节点组合的取值数量决定,不同组合会带来较高的时间和空间复杂度。在实际应用中,用户评分数据具有海量、高维、稀疏、内部结构复杂等特征,从评分数据中构建LVM以有效描述用户偏好具有较高的难度,这也是本文拟解决的一个问题。
从基于偏好模型的用户偏好或评分估算的角度来看,可利用基于BN的概率推理算法,根据观测到的用户或对象属性以及评分来估计用户偏好,或根据用户偏好来估算可能的评分。但是,针对CPT中并未包括的新用户或新对象信息,传统的BN模型难以进行有效的概率推理。例如,若利用基于样本集{(男,<18,Educator,R),(男,25~34,Admin,R),(女,>34,Other,R)}构建的BN来估算用户(男,>34,Farmer)的评分,由于该用户信息并未包含于模型的CPT中,因此无法进行有效的概率推理。综上,如何使得模型能有效支持新用户或新对象的偏好估计及评分估算,是用户偏好模型构建时面临的又一挑战。
图1所示为一个简单的隐变量模型,在实际情形中,Age和Profession等取值的个数远多于该例中变量取值的个数,因此,CPT存在组合爆炸的情况,从而导致LVM构建效率较低、所占存储空间较大等问题。

图1 简单的隐变量模型
本文在基于LVM的用户偏好建模方面,研究如何提升模型构建效率、克服模型构建过程中CPT组合爆炸等问题;在基于传统LVM的概率推理方面,研究对新用户或新对象信息进行概率推理的问题。具体而言,本文首先利用隐变量表示用户偏好,建立一种基于隐变量模型的用户偏好模型;然后通过深度信念网对评分数据进行分类,利用类别变量扩展隐变量模型,得到类别简化的贝叶斯网(Class Simplified BN,CSBN);接着给出模型构建时需满足的约束条件及该约束条件下的模型参数学习和结构学习方法;最后在MovieLens和大众点评数据集上进行实验,以验证本文方法的可行性和高效性。
2 相关工作
目前,从评分数据中构建用户偏好模型,有基于评分矩阵和项目流行度的推荐方法[7]、建立商品服务评估模型[8]和使用向量模型或主题模型来表示用户偏好[9-10]等方式。例如,结合LDA(Latent Dirichlet Allocation)[10]的主题分布描述用户偏好,利用SVD(Singular Value Decomposition)[11]等矩阵因式分解模型描述用户偏好,这些方法能够表达预先给定的依赖关系。但LDA是一种线性模型,SVD的分解矩阵可解释性较差,因此,两者均无法表述评分数据中属性间的依赖关系及其不确定性。
研究人员在基于BN或LVM的用户偏好建模方面进行了较多研究。文献[12]用隐变量表示用户的评价行为,文献[13-14]用隐变量描述用户对电影类型的偏好,文献[15]依据旅游的专家知识构建BN并估计用户的旅游偏好,文献[16]使用隐变量刻画用户兴趣并提出一种用以描述用户点击行为的动态贝叶斯网模型。但是,上述模型构建效率较低,难以适用于高维、稀疏的评分数据,因此,在评分数据上以隐变量模型为基础构建用户偏好模型,成为亟需解决的问题。
在提高模型构建效率方面,文献[17]采用决策树对观测数据进行分类,用分类后的变量构建BN,将观测值的类别作为证据变量进行概率推理,但该方法难以处理海量、稀疏、高维的评分数据集。文献[18-19]提出DBN以对数据进行分类和降维,DBN在很大程度上保存和还原了原始信息,可适用于海量、多维、内部结构复杂的评分数据。本文将DBN和隐变量模型进行结合,以构建用户偏好模型。
3 符号定义
将包含用户属性、对象属性和评分值等信息的评分数据记为D,U=(U1,U2,…,U|U|)表示用户属性集合,I∈{i1,i2,…,i|I|}表示对象属性,R表示用户评分。用户偏好由用户对评分对象各个属性的喜好构成,表示为L∈{l1,l2,…,l|L|},其中,ix=lx(1≤x≤|I|),lx称为第x维的偏好。例如,某一评分数据为U1(性别)=“男性”、U2(年龄)=“18岁~24岁”、U3(职业)=“学生”、i1(电影类别)=“动作片”、R(评分)=“4”,表示该用户对某动作片的评分为4,l1=il表示用户喜好“动作片”。
利用DBN分别对U和I数据进行分类,得到分别表示用户属性和对象属性的类别变量UC和IC,分类后的评分数据DC包含UC、IC和R的信息。
定义1BN是有向无环图(Directed Acyclic Graph,DAG),记为G=(V,E,θ),其满足如下4个性质:
1)V是一组多维随机变量集合,其构成了G中的节点,每一个节点对应一个变量。
2)含隐变量的BN简称隐变量模型,记为G=(V,L,E,θ),其中,L是描述用户偏好的隐变量节点。
3)E是连接各节点有向边的集合,表示各节点间的依赖关系。若存在从节点u指向节点v的有向边u→v(u、v∈V,u≠v),则称u是v的父节点。每个节点v在给定其父节点集π(v)时独立于其非子孙节点。
4)θ为各节点条件概率参数的集合,表示为P(v|π(v))。
定义2类别简化的贝叶斯网(CSBN)记为G=(V,L,E,θ),其满足如下3个性质:
1)V={UC,IC,R}是包括用户类别、对象类别和评分的变量集合。
2)L为隐变量,L=lj表示用户对评分对象属性第j个类别的偏好,其中,1≤j≤|IC|。
3)E和θ分别为G中有向边和条件概率参数的集合。
图2所示为一个简单的CSBN模型,在采用分类变量UC替代图1中的Age、Gender、Profession变量构建隐变量模型时,模型中的依赖关系得以简化,且CPT的组合数量也大幅降低,便于计算和存储。因此,采用分类变量构建隐变量模型,可以简化模型并提高模型构建效率。
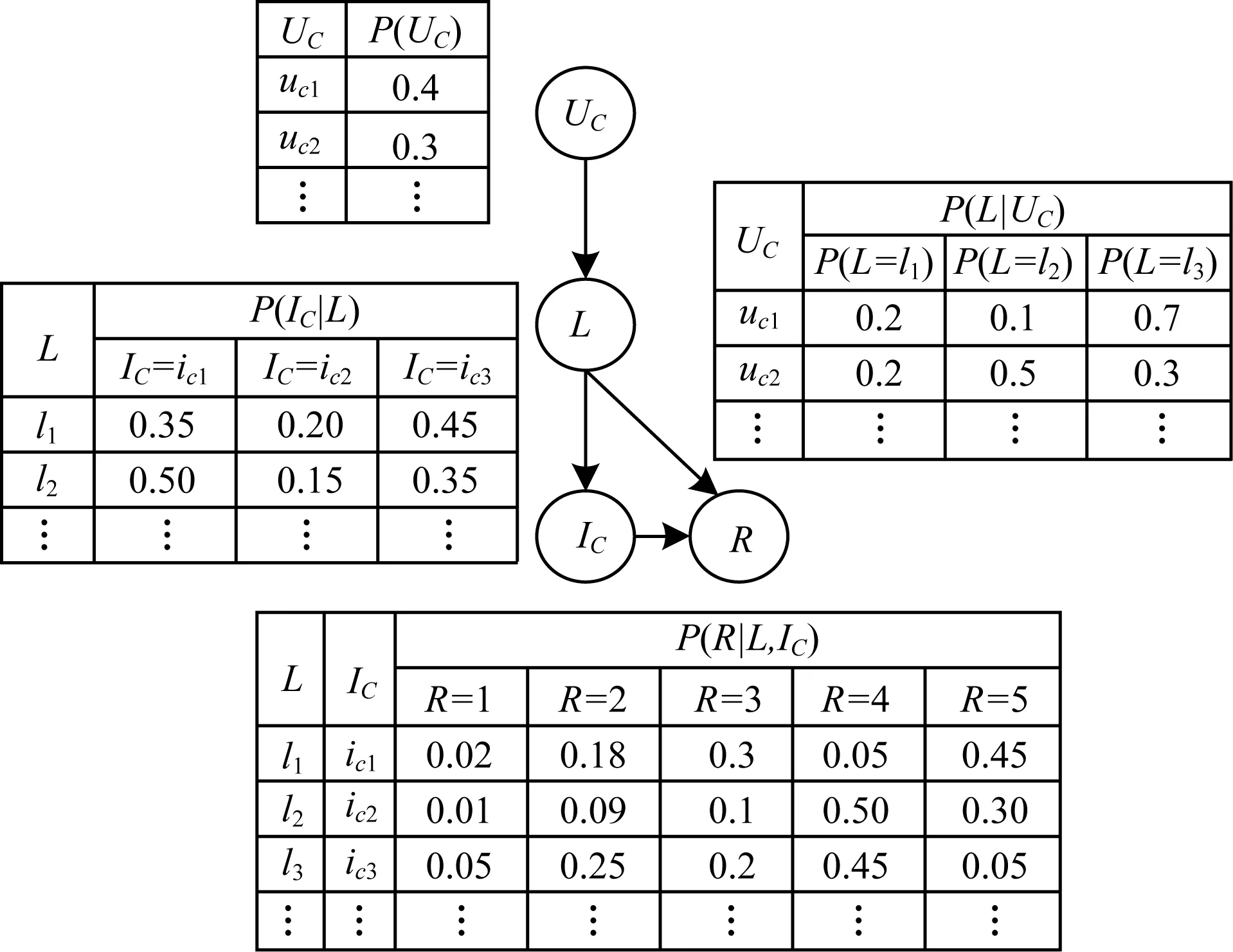
图2 CSBN模型示例
4 基于DBN的评分数据分类
根据定义2,本文使用DBN分别对用户属性数据和评分对象属性数据进行分类。分类后的评分数据维度降低,CPT中不同取值的组合也相应减少,从而提高了模型构建效率。此外,可以对训练集中未出现的变量组合进行分类,从而实现对这类取值的概率推理。DBN分类算法[18-19]将DBN看作一个特殊的多层感知器,是由多个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)[20]叠加构成的深度学习结构,预训练阶段通过逐层训练得到各个RBM的权值,下一层的输出作为更高一层的输入。DBN训练分为预训练和微调2个步骤,最后将DBN模型输入softmax回归分类器[21]得到用户属性类别数据集。以用户属性数据的分类为例,基于DBN的评分数据分类算法R-DBN-Classification步骤如下:
算法1R-DBN-Classification算法
输入用户属性数据D,迭代次数上限gn,学习率η
输出带有分类标签的评分数据集Dc
1.η←0.01,gn←2 000
(学习率、迭代次数由经验值确定)
2.初始化DBN分类器模型,RBMs层数为3,隐层单元分别设置为18、36、18//最后一层隐层单元个数为输出的类别数
3.令n为输入层神经元个数 //例如,针对性别、年龄和//职业,设置n=3
4.初始化DBN网络的权值W=[W′1,W′2,W′3]为0矩阵,随机初始化偏重b和c
5.W,b,c←DBN_train(n,v,gn)
(使用文献[18-19]中的DBN_train算法)
6.UC←softmax(W,b,c,D)
算法1采用非监督贪婪逐层训练的方法,即对比散度(Contrastive Divergence,CD)算法[20]获取权值,只需单个步骤就可以接近最大似然学习,因此,可显著缩短训练时间,提高收敛速度。
以用户属性信息为例设计的DBN分类器模型结构如图3所示,其中,输入为用户属性,包括性别(Gender)、年龄(Age)和职业(Profession)。Gender取值为0、1,分别代表男、女,Age取值为年龄段,Profession取值为职业对应的编号。虽然输入神经元个数为3,输出神经元个数为18,但输入神经元的3个节点取值组合数为2×7×21=294,相当于经过DBN分类器后用户属性组合从294降到了18,大幅降低了EM算法中间结果规模以及CSBN中节点的CPT规模,进而提高了BN的学习效率。

图3 DBN分类器模型
5 带分类变量的隐变量模型构建
5.1 约束条件
为保证模型构建的有效性,根据用户偏好、隐变量在评分数据中的特定含义,本文给出如下约束:
约束1第j维的偏好lj表达用户对评分对象属性类别节点IC的第j个取值icj的倾向(1≤j≤|IC|),用户属性UC不依赖于其他变量。
约束2P(ic1|l1)>P(ic2|l1),当用户偏好为l1时,该用户偏好ic1的概率大于ic2;P(R=r2|ic1,l1)>P(R=r1|ic1,l1),用户更可能对倾向或喜好的对象评高分(r2>r1),反之评低分(r1>r2)。
5.2 基于约束的CSBN参数学习
将引入分类变量后的用户属性类别数据集、评分对象属性类别数据集以及评分数据,处理为带有分类标签的评分数据集Dc,Dc中一次用户评分记录为一个样本Dcy∈{Dc1,Dc2,…,Dc|Dc|},包括ID、用户属性类别、评分属性类别以及评分,用户偏好L的取值个数为|I|,L∈{l1,l2,…,l|I|}。然后,随机生成一组满足约束条件的初始参数,对数据集中隐变量的值进行填充,再计算并更新参数,直至收敛或达到迭代次数上限,所得参数优化结果即为最终参数学习结果。基于第t次迭代得到的参数估计θt,第t+1次迭代过程如下:

(1)
(2)

(3)

(4)
EM算法不断迭代直至收敛,基于约束的CSBN参数学习算法Parameter_learning描述如下:
算法2Parameter_learning算法
输入带有分类标签的评分数据集Dc,收敛阈值δ,迭代次数上限T
输出CSBN模型参数θ
1.随机产生一组满足约束2的初始参数θ′
2.for t←0 to T do
E步:

M步:

5.end for
例如,表1给出了利用DBN分类的用户评分类别数据的片段示例,以图2结构作为当前模型结构,执行算法2迭代一次修补后的样本数据如表2所示。假设数据集大小为|Dc|,L的取值个数为|I|,则每次EM过程修补后的数据有|I|×|Dc|条,计算最大似然估计|I|×|Dc|次,EM迭代次数最多为T次,因此,需要计算T×|I|×|Dc|次最大似然估计,算法2的时间复杂度为O(T×|I|×|Dc|)。可见,EM算法的执行效率与修补后的数据量、输入数据集以及隐变量取值个数呈负相关[22],即采用类别变量构建CSBN后数据量下降,从而提高了算法效率。
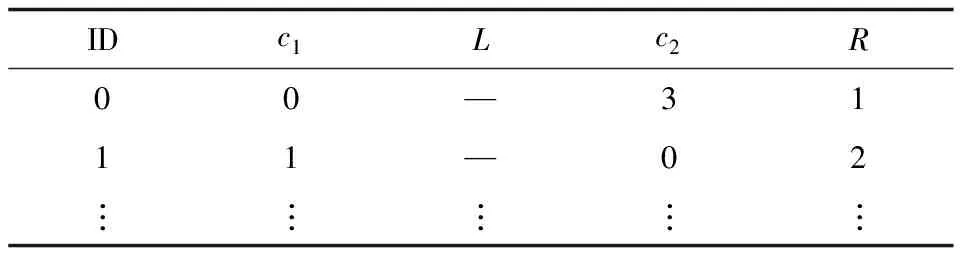
表1 数据集片段

表2 修补后的数据
5.3 基于约束的CSBN结构学习
贝叶斯信息准则(Bayesian Information Criterion,BIC)是一种常用的打分标准,能在缺值样本前提下对结构进行打分,为本文学习CSBN结构提供了模型选择基准。模型结构ζ的BIC评分计算公式如下:
(5)
式(5)右侧第1项是模型ζ的优参对数似然度,其度量结构ζ数据D的拟合程度;第2项是一个关于模型复杂度的罚项,其能够有效避免依据优参似然度选择模型导致的过拟合现象。本文使用SEM算法结合BIC打分准则作为CSBN结构学习方法的基础。首先根据约束1和约束2,随机生成一组满足约束1的初始结构和一组满足约束2的初始参数,以生成的初始结构与初始参数作为SEM算法的初始值进行参数学习;然后计算初始结构的BIC评分,通过当前结构边的变化得出一系列的候选结构,根据当前修补的数据集学习候选结构的参数并进行BIC打分,选出局部最优候选模型并与当前模型作对比,选其中评分较高者作为当前模型继续进行参数学习,重复迭代上述步骤。
从初始CSBN模型出发进行参数学习,基于约束的CSBN结构学习算法Structure_learning描述如算法3所示。
算法3Structure_learning算法
输入带有分类标签的评分数据集Dc,收敛阈值δ,迭代次数上限T,节点个数C_num
输出CSBN模型结构G,CSBN模型参数θ
1.随机生成满足约束1的BN结构G′和满足约束2的初始参数θ′

3.for i←0 to (C_num-1) do
4.令G_set为当前节点加、减或转边得到的候选结构
5.θi,Di←EM(Gi,D′i,θi,δ,1)//参数计算
6.temp←θi,Di,tempBIC←BIC(G,θ|D′)
7.if tempBIC>newscore then
8.θi,Di←temp,newscore←tempBIC
9.end if
10.if newscore>oldscore then
11.θi+1,Di+1←EM(Gi,D′i,θi,δ,T)
12.(G,θ)←(Gi+1,θi+1)
13.oldscore←BIC(G,θ|Dt+1)
14.else
return (G,θ)
15.end if
16.end for
假设模型的节点数为C_num,一次结构学习过程产生的候选结构个数为z,对所有候选结构执行一次EM算法,得出当前最优候选结构并对其执行EM算法直至收敛或达到迭代次数上限T,候选结构选择的时间开销远低于EM算法的执行时间开销,则SEM算法需要执行z×C_num次EM算法,C_num在算法开始时就给定,z由初始结构决定,则算法3的时间复杂度为O(T×|I|×|Dc|)。
6 实验结果与分析
6.1 实验设置
本文实验采用GroupLens提供的MovieLens-1M数据集[1],其包括6 040条用户属性数据、3 952条电影属性数据、1 000 209条电影评分数据。此外,在大众点评网利用爬虫爬取20个城市各100个用户的评分数据,该数据集包括2 000条用户属性数据、5 162家餐厅属性数据以及114 023条评分数据。2个数据集经过预处理后,每行数据对应一次用户评分记录,每个记录分别由3个用户属性信息、1个电影/餐厅属性信息和1个评分值组成。
实验环境如下:Intel Core i7-6700 @ 3.40 GHz处理器,12 GB DDR4内存,Nvidia GeForce GTX 750 Ti显卡,Windows 10(64位)操作系统,Python作为开发语言。
本文主要针对模型构建效率、所构建模型有效性等方面进行实验分析。首先,分别在MovieLens和大众点评数据集上对LVM和CSBN的模型构建时间进行对比,经测试DBN分类算法执行时间在CSBN模型构建时间中占比较小,因此,本文效率测试部分忽略DBN分类算法带来的时间开销。然后,基于CSBN模型的结构和参数,计算条件概率P(Q|e),其中,e是由用户属性构成的证据变量取值,Q是电影类型的查询变量,计算具有最大后验概率的电影类型并作为用户偏好。本文对计算出的用户偏好电影类型和统计出的真实用户偏好电影类型进行对比,估计召回率(Recall)、准确率(Precision)以及F值。三者计算公式分别如下:
其中,num(inference)是推理出用户有倾向观看的电影类型数目,num(ture)是推理出有倾向且实际也有倾向观看的电影类型数目,num(sample)是实际用户有倾向观看的电影类型数目。
6.2 效率测试
本文在MovieLens数据集上选取不同用户数,分别测试CSBN和LVM的模型构建执行时间,结果如图4所示。从图4可以看出,随着数据量的增加,CSBN和LVM的执行时间均增加,在同样大小的数据集下,CSBN的执行效率高于LVM,并且随着数据量的增加,CSBN更能有效地提升用户偏好模型构建效率。

图4 MovieLens数据集上模型构建执行时间对比
Fig.4 Comparison of model construction execution time on MovieLens dataset
图5所示为大众点评数据集上LVM和CSBN的模型构建时间对比,由于大众点评数据集在每个城市均爬取了100个用户的数据,从中随机选取30%、50%、80%的数据来测试算法3的效率。从图5可以看出,随着数据集的增大,LVM和CSBN的执行时间均增加,在相同比例的数据集下,CSBN的执行时间远低于LVM,原因在于数据量增加时,LVM模型中间结果规模以|I|倍增长,导致其执行时间增长更快。
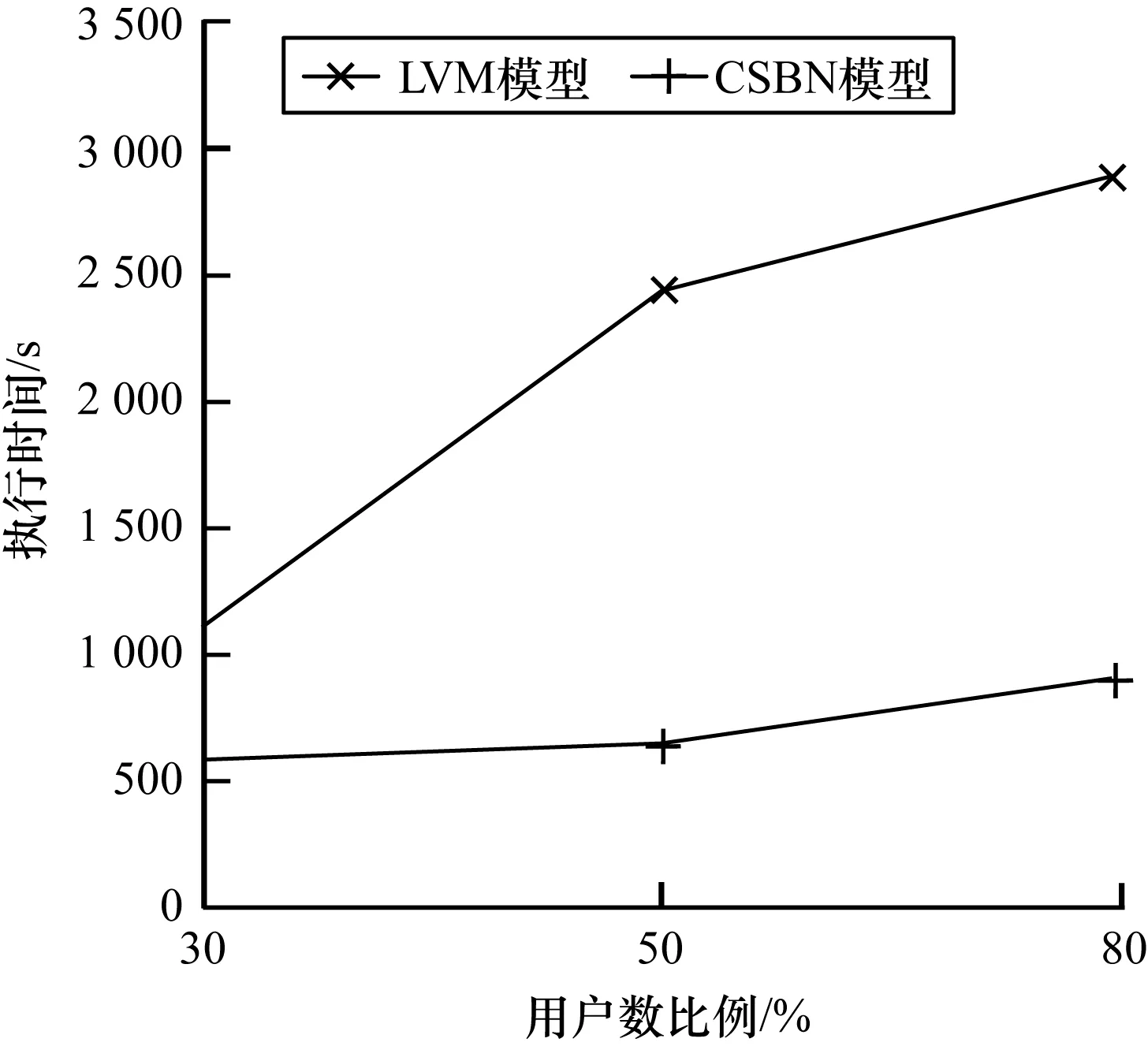
图5 大众点评数据集上模型构建时间对比
Fig.5 Comparison of model construction time on DianPing dataset
此外,本文进一步比较不同数据集下LVM和CSBN模型构建时的中间结果规模,以反映算法执行过程中所需要的内存空间大小。表3和表4分别为MovieLens和大众点评数据集上构建LVM和CSBN模型时一次迭代计算的中间结果规模,可以看出,在相同数据量时,CSBN构建时中间结果规模比LVM模型低1个数量级,随着数据量的增加,LVM构建时中间结果规模以接近60%的比例快速增长,而CSBN模型增长较为平缓,这说明本文通过对评分数据进行分类再构建隐变量模型的方法,大幅减少了模型构建中的中间结果数量,且保证了模型构建的高效性。
表3 MovieLens数据集上模型构建的中间结果规模比较
Table 3 Comparison of intermediate result size in model construction on MovieLens dataset
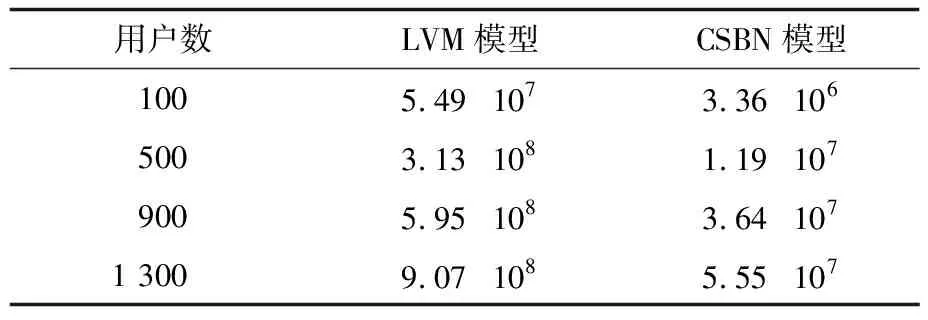
表4 大众点评数据集上模型构建的中间结果规模比较
Table 4 Comparison of intermediate result size in model construction on DianPing dataset
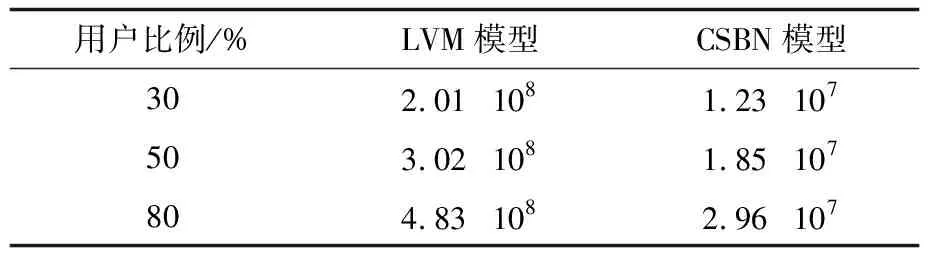
6.3 有效性测试
为了测试模型的有效性,本文在1 300个用户的MovieLens数据集和80%大众点评数据集上,测试基于CSBN和LVM模型估计的不同top-k用户偏好的召回率、准确率和F值,结果分别如图6和图7所示。

图6 MovieLens数据集上基于LVM和CSBN模型的用户偏好对比
Fig.6 Comparison of user preferences based on LVM and CSBN models on MovieLens dataset

图7 大众点评数据集上基于LVM和CSBN模型的用户偏好对比
Fig.7 Comparison of user preferences based on LVM and CSBN models on DianPing dataset
从图6、图7可以看出,在2种数据集上基于CSBN和LVM估计的偏好的召回率、精确率和F值基本相同,随着k值的增加,基于CSBN和LVM的召回率、F值随之上升,精确率随之下降,并且相差不大。在k=7和k=3时,两者的F值基本相同,说明此时CSBN和LVM的召回率和精确率达到了平衡,这在一定程度上说明了本文方法有效。
本文在不同数据量的2种数据集上,分别测试基于CSBN模型估计的偏好的召回率、精确率和F值,结果如图8和图9所示。可以看出,在MovieLens数据集上,随着k值的增加,CSBN的召回率上升,精确率下降,而F值趋于稳定,在不同用户个数下训练的模型结果几乎相同,说明了本文方法的稳定性。但在大众点评数据集上,不同数据量的召回率、精确率和F值差距较MovieLens上偏大,原因在于大众点评数据量较小,仅为MovieLens的10%,导致模型的结构和参数并未达到最优,这也符合大众点评数据集的真实情况。
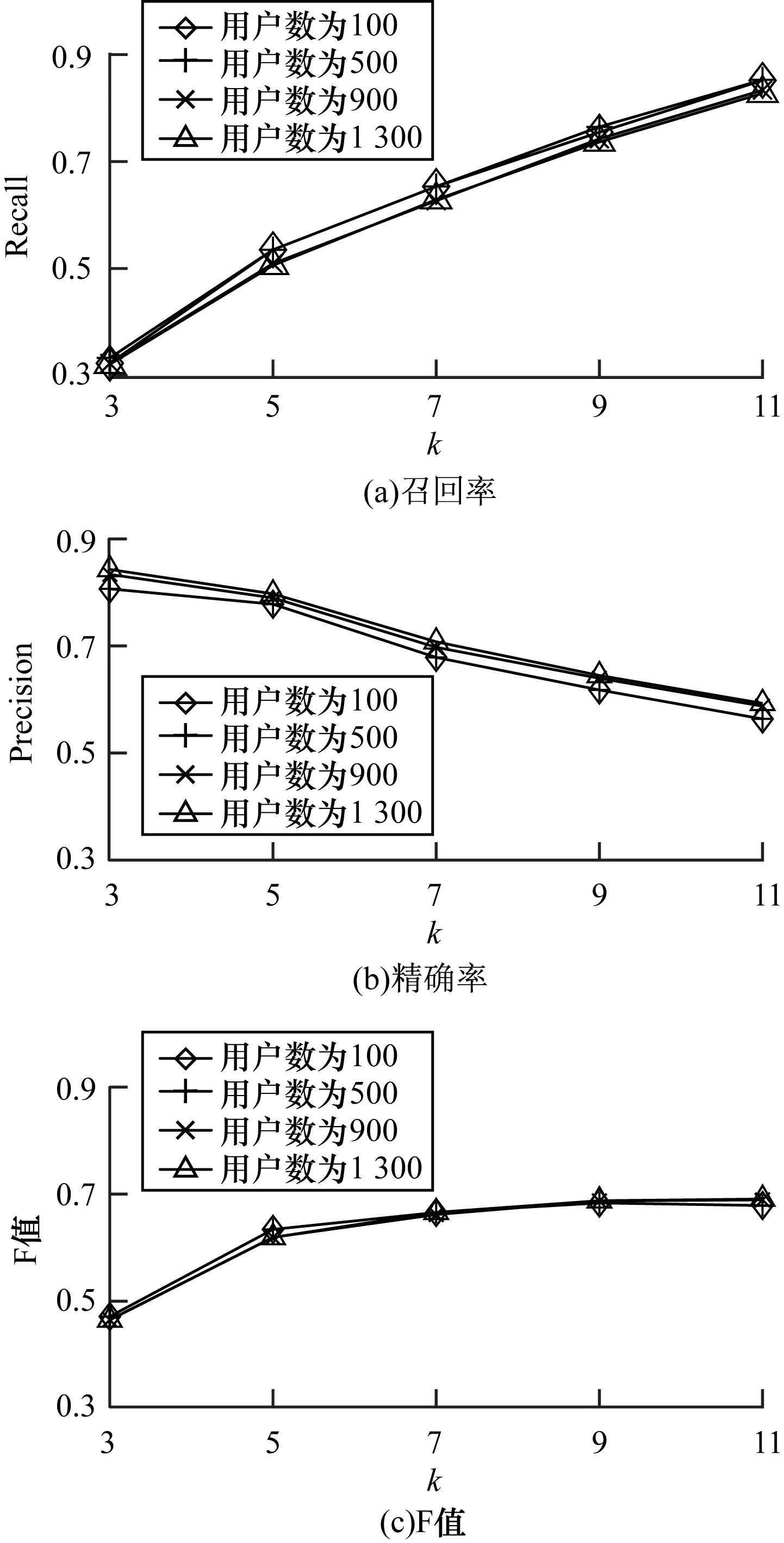
图8 MovieLens数据集上CSBN模型的用户偏好发现结果
Fig.8 User preference discovery results of CSBN model on MovieLens dataset
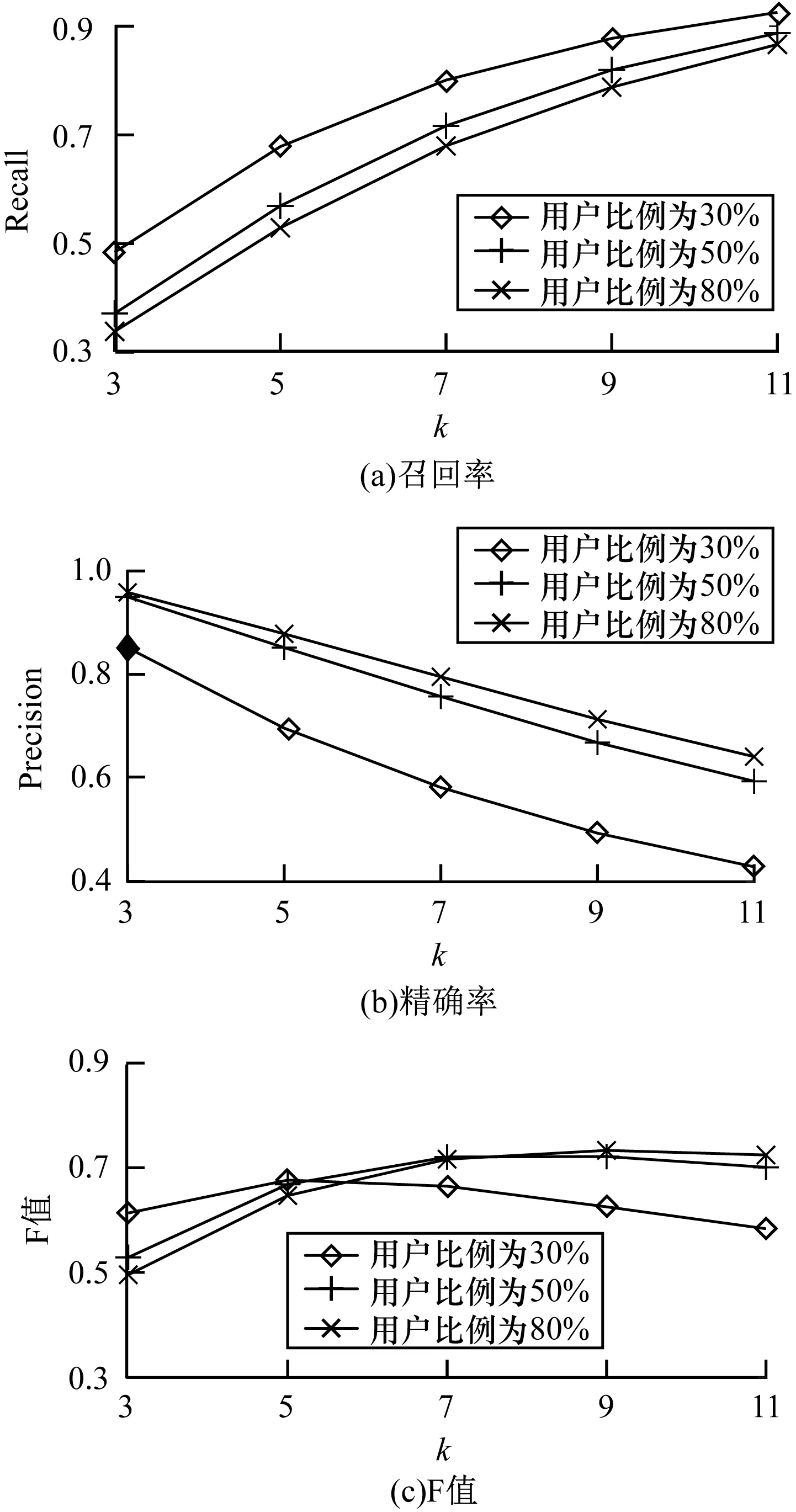
图9 大众点评数据集上CSBN模型的用户偏好发现结果
Fig.9 User preference discovery results of CSBN model on DianPing dataset
大众点评数据集上偏好估计的精确率高于MovieLens数据集,原因在于用户喜好的“餐饮”类型比“电影”类型更加明显。上述实验结果说明了CSBN模型构建方法在真实数据集上的有效性,并且没有因为提高效率而降低有效性。
7 结束语
本文提出一种基于深度信念网和隐变量模型的用户偏好发现方法,该方法既可以描述隐含的用户偏好,又可以反映用户评分数据中各属性间的任意不确定性依赖关系,且能够提高模型构建效率,克服传统隐变量模型构建过程中迭代计算多、中间结果规模大等问题。但是,本文方法是在静态数据中构建CSBN模型,实际应用的评分数据是动态变化且不断增加的。因此,下一步将以增量学习的方式在动态数据上构建CSBN模型。此外,用户的偏好也随着时间发生变化,建立动态的模型对不断变化的偏好进行预测,也是今后的研究方向。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
小学生学习指导(高年级)(2021年4期)2021-04-29
装备制造技术(2020年2期)2020-12-14
河北理科教学研究(2020年2期)2020-09-11
数学年刊A辑(中文版)(2020年2期)2020-07-25
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
中国卫生(2015年12期)2015-11-10
新高考·高二数学(2014年7期)2014-09-18
