
基于细粒度多通道卷积神经网络的文本情感分析
2020-05-18 11:07戴月明
计算机工程 2020年5期
王 义,沈 洋,戴月明
(江南大学 物联网工程学院,江苏 无锡 214122)
0 概述
文本情感分析主要是通过对文本中前后内容的学习来判定该文本所对应的情感极性。对于传统的浅层模型而言,由于其特征表示方法限制,使得词与词之间相互独立,且拟合能力有限,因此会丢失较多的语言特征,无法充分学习上下文信息,而词向量的出现,为深度学习在自然语言处理领域的应用提供了技术基础。
文献[1]将循环神经网络(Recurrent Neural Network,RNN)用于文本情感分析,该方法在影评数据集上的分类性能比支持向量机(Support Vector Machine,SVM)和卷积神经网络(Convolutional Neural Network,CNN)有5%的提高。文献[2]建立将CNN用于句子分类,其模型主要分为4层:第1层为输入层,用词向量顺序排列表示模型的输入;第2层为卷积层,通过设置多个卷积核来学习词与词之间的关系;第3层为池化层,采用最大池化技术进行特征筛选,得到其中最重要信息;第4层为带有全连接的softmax层,用以计算每个类别的概率。实验结果证明将卷积神经网络用于情感分析任务是有效的,但文献[2]模型主要针对英文语料进行处理。文献[3]提出一种Seq_CNN模型,该模型以One-hot文本表示方法作为CNN通道的输入,但由于One-hot方法会导致数据维度过高,使得情感分类的效果不佳。文献[4]提出了双通道CNN模型,区别于传统的CNN模型,该模型使用词向量以及字向量2个通道作为CNN模型的输入。文献[5]提出以CNN的卷积层作为图像的特征提取层,将SVM分类器用于分类。CNN在文本情感分析中的实践和应用基本以单通道输入为主,这种单通道的输入会导致CNN模型的学习能力单一,无法充分学到语义信息。由于图像分别是由RGB 3个颜色的通道结合而成,因此CNN模型的多通道输入主要应用于计算机视觉方面。文献[6]则采用了动态和静态2个词向量的双通道作为CNN模型的输入。
结合中文文本的复杂性,本文构建细粒度多通道的卷积神经网络模型FG_MCCNN用于文本情感分析。以词性对向量和细粒度字向量辅助原始词向量作为模型的输入,使用原始词向量捕获句子间语义信息。通过词性对向量进行词义消歧,利用细粒度字向量得到句子更深层次的信息,同时选用不同尺寸的卷积核学习更优质的语义信息,以提高情感分类效果。
1 卷积神经网络
卷积神经网络是深度学习中的一种重要网络,是基于人工神经网络的经典前馈神经网络[7]。卷积神经网络自提出以来,在模式识别领域得到广泛应用,引起了学术界和工业届学者的巨大关注[8]。随着深度学习技术的发展,大量研究将卷积神经网络运用到自然语言处理中[9]。
卷积神经网络的结构主要由输入层、卷积层、池化层、全连接层和输出层组成[10]。其中,一般文本在输入层转化为Embedding,然后接入卷积层,通过卷积层来提取句子的特征,并通过池化层进行特征采样,一般采用下采样获得局部最优值,从而减少网络的规模[11]。由于CNN可以学习中文句子中的抽象特征并且不需要人工干预[12],得到的特征可以直接作为分类器的输入,而且利用CNN的多层结构可以发现句子内部更高层次的抽象特征[13],并且在一定时间范围内完成训练,因此卷积神经网络在自然语言处理中取得了较好的应用效果[14]。
2 细粒度的多通道卷积神经网络模型
2.1 词向量
在中文文本中,词语的表达语义是基本单元[15]。基于传统的文本特征表示方法只是停留在词语的表层进行处理,如One-hot的基本假设就是词之间的语义和语法关系是相互独立的,一方面无法捕捉到词与词之间的相似度[16],另一方面也存在维度爆炸问题,随着词典规模的增加,词袋模型的维度变得越来越大,矩阵也变得超稀疏[17],从而导致耗费大量计算资源。而词向量的出现,有效解决了文本特征表示的相关问题[18]。所谓的词向量就是采用神经网络来训练语言模型,并在训练中生成的一组向量。本文利用word2vec工具来训练文本词向量模型。词向量模型是考虑词语位置关系的一种模型,其利用大量语料数据集的训练,将每个词语映射到高维度的向量中,并且通过计算余弦判断2个词语之间的相似度[19]。由于卷积神经网络在训练时的参数量较大,因此容易导致训练出的模型过拟合。针对该问题,本文使用预先训练的词向量作为输入。
2.2 字向量
与英文文本不同,中文文本在训练前需要进行分词的预处理操作[20]。常用的分词工具有很多,然而这些分析工具不可避免地会存在一些分词不准确的问题。例如:“最近上映的电视剧大长今很火”分词后为“最近/上映/的/电视剧/大长/今/很/火”;“这幢建筑高大上”分词后为“这幢/建筑/高大/上”。在这两句中,“大长今”“高大上”均为一个词,然而经过分词后,切分为了“大长/今”“高大/上”,导致分词后改变了词的原义。这种情况主要来自于各类的专有名词,如人名、地名、缩写词、新增词等。为减少分词不准确对文本情感分析的影响,本文采用细粒度的字符划分方法,并用字向量作为模型的另一个通道的输入,用以辅助词向量学习深层次的语义信息。
2.3 词性对向量
词向量模型能够将中文文本的单词映射为底维向量,避免传统BOW模型采用的One-hot编码带来的维度灾难[21]。在中文文本情感分析中,由于中文存在大量多义词,例如“他作为学生代表发表了讲话”“他代表小王参加比赛”,在这两句话中都存在“代表”一词,前一句中的“代表”是名词,后一句中的“代表”则是动词,这种现象在中文文本中极为常见,但传统词向量模型在训练时无法识别单词的歧义,当词向量作为模型的输入时会产生噪音。因此,本文假设一条长度为n的评论X={x1,x2,…,xn},利用词性标注技术获取分词后词语的词性P={p1,p2,…,pn},将词语与该词语词性进行结合,得到词性对序列W={(x1,p1),(x2,p2),…,(xn,pn)}。例如(代表,名词)、(代表,动词),将该序列作为词向量训练模型的输入,得到相应的词性对向量。本文将词向量与词性对向量共同作为模型的输入,一方面利用词向量保证模型可以学习到充分的语义间信息,另一方面以词性对向量辅助词向量避免多义词对词向量的噪声影响,从而改善文本情感分类的效果。词性标注实例如下:
例1他 r;作为 v;学生 n;代表 n;发表 v;了 ul;讲话 n。
例2他 r;代表 n;小王 nr;参加 v;比赛 vn。
2.4 FG_MCCNN模型
本文建立的FG_MCCNN模型主要包含以下3个部分:
1)使用京东等一些电商大平台的大量评论进行字向量和词向量的训练,以获得高质量的词向量。使用词向量、字向量以及词性对向量作为模型3个通道的输入,使用字向量和词性对向量辅助词向量,词向量可以更好地学习语义信息,细粒度的字向量更能刻画文本的基本特征,词性对向量则可以有效减少多义词的噪声影响。相同词向量由于语言模型的不同,词与词之间的相关性也不同,因此在卷积层采用不同尺寸的卷积核进行卷积操作,学习语句内部更深层次的特征,确保在不同通道可以获取相应的局部特征。
2)池化层采用最大池化进行特征筛选,最大池化可以使得在输入不同长度文本的情况下得到相同的输出长度。
3)在文本情感分析任务中,为避免传统卷积神经网络中的全连接层参数太大,导致过拟合的问题,FG-MCCNN模型直接使用最大池化后的特征作为分类器的输入,并输出文本情感分析分类的概率。
本文构建的细粒度多通道卷积神经网络模型结构如图1所示。
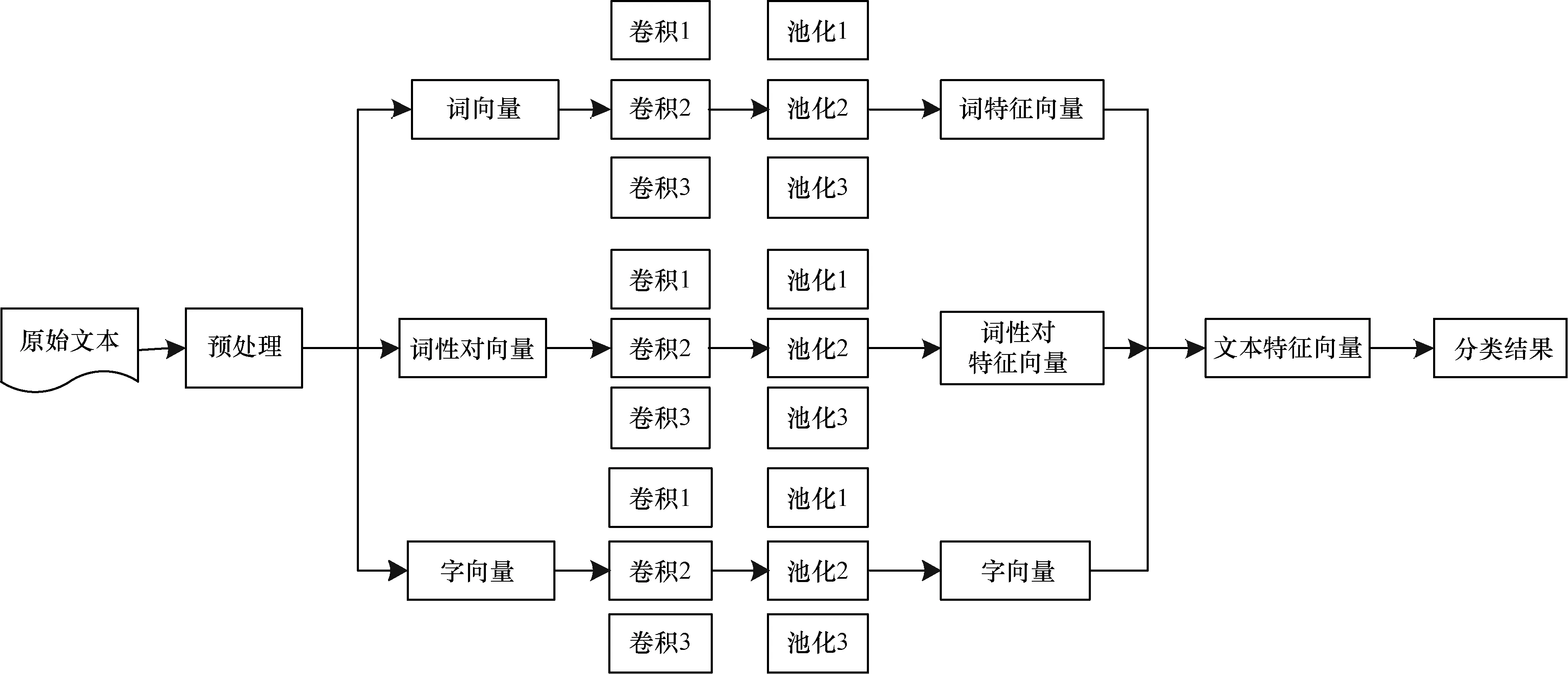
图1 FG_MCCNN模型结构
2.5 FG_MCCNN模型构建
细粒度的多通道卷积神经网络模型FG_MCCNN主要有以下4个部分组成:
1)输入层
采用word2vec训练词向量、字向量以及词性对向量,并通过预训练的词向量减少参数量过大的影响,以防止过拟合。假设词向量的维度为K,则一条长度为n的评论句可以描述为:
X1:n=X1⊕X2⊕…⊕Xn
(1)
根据2.3节中词性对向量的表示方法W={(x1,p1),(x2,p2),…,(xn,pn)},词性对向量的输入可描述为:
W1:n=W1⊕W2⊕…⊕Wn
(2)

2)卷积层
在文本情感分析中,卷积层的作用在于利用窗口滑动即卷积操作来提取文本数据的局部特征。一般采用h×k维大小的卷积核进行卷积操作,其中h为卷积核的高度,n为词向量的维度。为尽可能捕获更多的上下文信息,一般会设置多组高度不同的卷积核进行操作,但随着卷积核的增加,训练效率会随之下降,因此,本文选择使用3组卷积核,分别为h=3、h=5、h=7用来对输入的词向量D1、字向量D2以及词性对向量D3进行卷积运算,计算公式如下:
Chi=f(WhXi:i+h-1+b),h=3,5,7
(3)
(4)

当卷积核在长度为n的文本上滑动时,本文设置卷积步长S=1,因此,当卷积核在长度为n的文本评论中滑动完成后,可得到n-h+1个输出,最终得到的特征向量C为:
C=Ch,1,Ch,2,…,Ch,n-h+1,h=3,5,7
(5)
3)池化层
池化层主要负责对卷积层获得的特征进行二次筛选,同时输出一个固定大小的矩阵,降低输出结果的维度。由于在卷积层的计算中使用了不同尺寸的卷积核,会导致通过卷积层计算后得到的向量维度会不一致,因此在池化层的过程中,采用最大池化,即将每个特征向量最大池化成一个值,也就是选取每个特征向量的最大值用来表示该特征,而且认为这个最大值表示的是最重要的特征。假设C(2)为经过不同卷积核最大池化后的特征向量图,其计算公式如下:
C(2)=max(Ch,1,Ch,2,…,Ch,n-h+1),h=3,5,7
(6)
假设每组的卷积核的数量为m,最后池化层的输出为C(3),则C(3)可以表示为:

(7)
4)合并层
由于本文采用三通道的输入,需要将3个通道D1~D3经过最大池化提取的特征向量进行合并,从不同通道捕获更多信息。假设最终的文本特征向量集合为C(4),可表示为:
(8)
2.6 FG_MCCNN模型训练
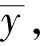
(9)
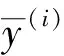
(10)

由此可知,当目标函数LLoss最小,函数的损失值接近0时,训练样本的值和实际输出值之间就越接近。同时,本文模型训练使用Adam算法最小化目标函数,并且利用反向传播算法进行实时参数的更新。
3 实验结果及分析
3.1 实验语料集
本文所采用的语料集主要包含手机、电脑等相关产品的中文评论,以及谭松波老师所整理的当当网书评以及酒店评价等。经过数据的整合后,共采用25 000条评论,其中包含12 500条正向评论和12 500条负向评论。本文所采用的数据集网址为https://pan.baidu.com/s/1o9pYXYi。此外,为验证模型的有效性,本文将数据集中的80%作为训练语料集,20%作为测试语料集。FG_MCCNN模型的参数设置如表1所示。
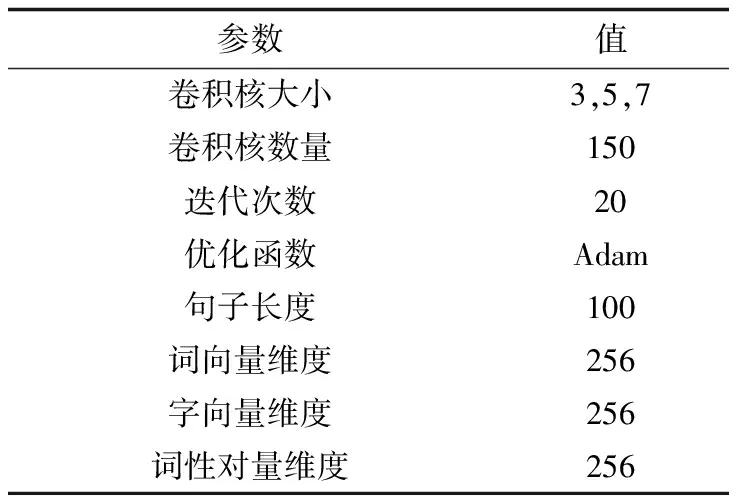
表1 FG_MCCNN模型参数设置
3.2 实验步骤
本文采用预训练的词向量和字向量进行卷积计算,具体的实验步骤如下:
1)对原始文本采用jieba分词以及去除停用词操作。此外,为训练词性对向量,对文本进行词性标注以获取相对性词性对。
2)使用word2vec预训练词向量以及词性对向量,训练的语料选用爬虫获得的京东、美的等各大电商的评论数据。
3)将分词后的结果转换为词序列以及词性对序列,使每个词都有相应的索引值。
4)将具有唯一索引的词序列以及词性对序列输入到词向量以及词性对向量表中,找出相对应的词向量和词性对向量作为本文模型2个通道的输入。
5)将原始文本处理为单个字符。
6)使用word2vec预训练字向量。
7)将分词后的字符转化为具有相应索引值的字符序列。
8)将具有唯一索引值的字符序列输入到字向量表中,找到对应的字向量,生成相应的矩阵作为模型另一个通道的输入。
9)使用式(8)所示的目标函数训练模型。
10)基于测试语料集测试模型性能并对结果进行分析。
3.3 结果分析
对比实验1为验证FG-MCCNN模型的有效性,本文将其与以下经典模型进行对比:
1)逻辑回归模型(LR):使用word2vec训练词向量,用逻辑回归分类器进行文本情感分类。
2)静态词向量模型(Static_CNN):模型训练时,词向量维持不变。
3)非静态词向量模型(Non_Static_CNN):模型训练时,词向量会进行微调。
4)双通道卷积神经网络模型(DC_CNN):采用双通道即用非静态词向量和静态词向量2个通道进行卷积计算。
5)One_Hot_CNN模型:采用One_hot作为CNN模型的输入进行卷积计算。
6)CNN+SVM模型:利用CNN进行特征提取,利用SVM分类器进行文本情感分类。
本文主要采用准确率以及F1值作为评价指标衡量各个模型的效果,针对实验结果,选取测试集准确率最高的作为相应模型的准确率和F1值,如表2所示。
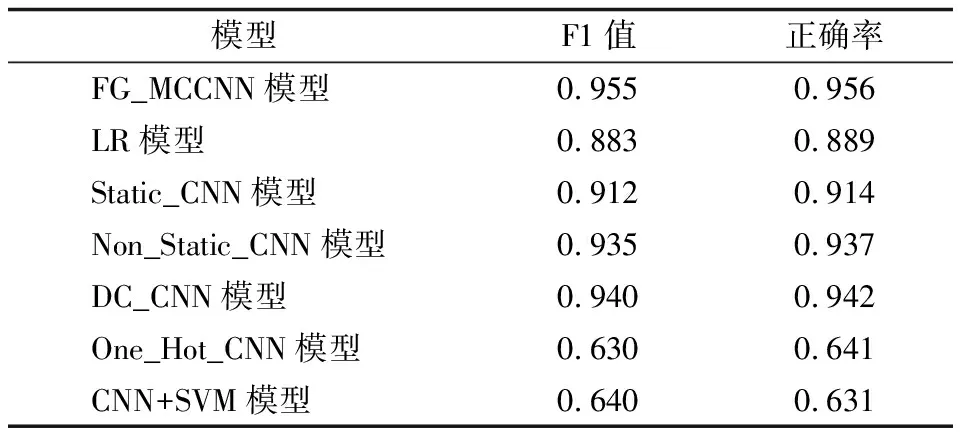
表2 FG_MCCNN模型与经典模型的分类性能对比
从表2可以看出,与其他模型相比,FG_MCCNN在F1值和准确率上具有优势,分别为0.955和0.956,其中Non_Static_CNN相对于Static_CNN取得了较好的分类效果,说明微调的词向量有助于提高分类效果,DC_CNN取得了仅次于FG_MCCNN的效果,而One_Hot_CNN与CNN+SVM的F1值以及准确率相对较低,这主要由于SVM对于卷积操作后所产生的大量特征的学习能力不强,而One_Hot_CNN的输入特征则忽略了评论句的语义信息。本文的FG_MCCNN模型在F1和正确率上相较于DC_CNN提高了0.015和0.014,其通过引入细粒度的字向量以及词性对向量增强了模型的学习能力。
对比实验2为验证FG_MCCNN模型的性能,本文分别采用字向量的单通道卷积神经网络模型(Word_CNN)、词向量的单通道卷积神经网络模型(Char_CNN)以及词性对向量的单通道卷积神经网络模型(WP_CNN)进行对比实验,在不同迭代次数下,各个模型的分类正确率和F1值如图2和图3所示。
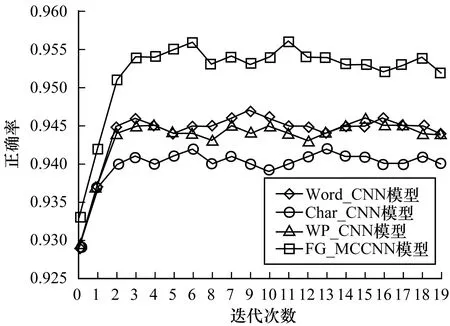
图2 FG_MCCNN模型与单通道CNN模型的正确率对比
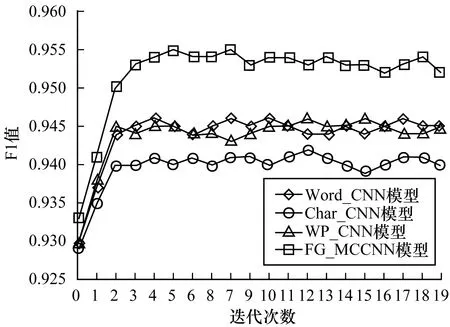
图3 FG_MCCNN模型与单通道CNN模型的F1值对比
由图2以及图3可以看出,FG_MCCNN模型与单通道卷积神经网络模型相比,正确率和F1值均有明显的提高。与基于词向量和词性对向量的单通道卷积神经网络模型相比,FG_MCCNN模型在正确率和F1值这两个指标上均提高了约1%左右,与基于字向量的单通道卷积神经网络模型相比,FG_MCCNN算法在这两个指标上均提升了约1.5%。实验结果表明,FG_MCCNN算法通过整合不同通道获取的特征信息,使得模型学习到更有丰富的信息,从而得到比单通道模型更好的结果。
对比实验3为进一步验证FG_MCCNN模型的性能,本文设计3组双通道对比实验,分别采用词向量与字向量的双通道卷积神经网络模型(Word_char_CNN)、词向量与词性对向量的双通道卷积神经网络模型(Word_WP_CNN )以及字向量与词性对向量结合的卷积神经网络模型(Char_WP_CNN)3组双通道实验,进行实验结果进行比较,选取不同的迭代次数,对比实验结果如图4和图5所示。
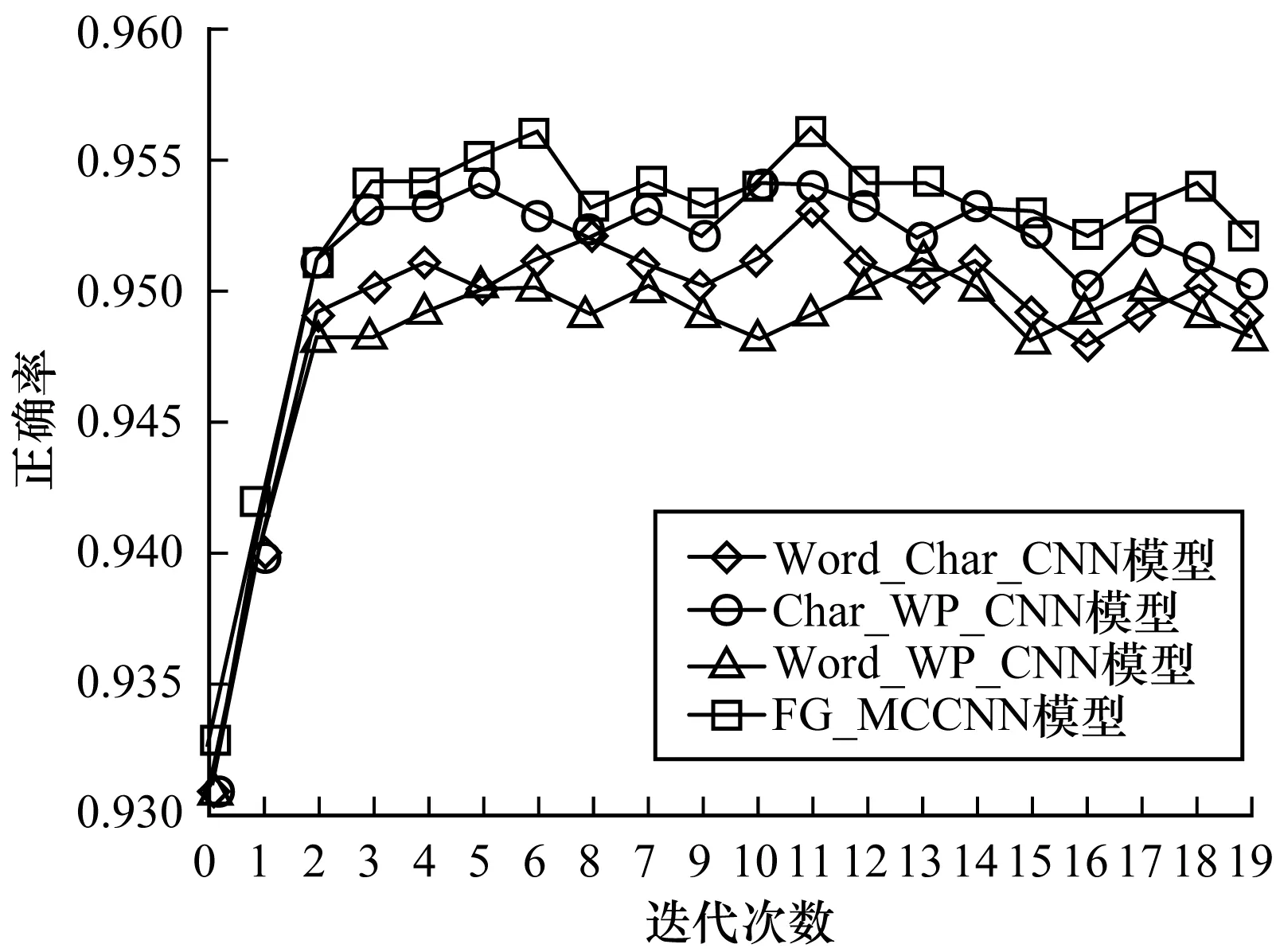
图4 FG_MCCNN模型与双通道CNN模型的正确率对比

图5 FG_MCCNN模型与双通道CNN模型的F1值对比
由图4和图5可以看出,FG_MCCNN模型相对于其他3种双通道组合的卷积神经网络算法,性能均有小幅度的提升:与基于词向量和词性对向量的双通道卷积神经网络模型相比,正确率和F1值提升约0.5%;与基于词向量和字向量的双通道卷积神经网络模型相比,正确率和F1值提升约0.3%;与基于字向量和词性对向量的双通道卷积神经网络模型相比,正确率和F1值提升约0.2%。可以看出,加入细粒度的字向量以及词性对向量作为模型的输入,对于模型分类效果的提高均有一定的作用。
对比实验4为验证FG_MCCNN模型在较大数据集下相对于浅层机器学习算法具有较好的分类效果,本文分别采用词袋模型(BOW)+SVM以及Word2vec+SVM进行对比实验,实验结果如图6所示。

图6 FG_MCCNN模型与SVM模型的分类性能对比
由图6可以看出,在使用SVM算法的2种分类模型中,采用word2vec进行词向量训练的分类模型效果优于采用BOW词袋模型进行文本表示的方法,这主要由于传统的词袋模型忽略了评论语句中的语义信息,而通过word2vec训练词向量捕获评论语句中的语义信息,使得SVM分类效果得到提高。本文FG_MCCNN模型在正确率和F1值上都明显高于采用SVM的2种模型,说明在大数据集的评论语句情感分析中,浅层机器学习方法的拟合能力欠佳,分类效果一般,而本文提出的FG_MCCNN模型表现则较好。
4 结束语
本文结合中文评论语料的特点,针对传统CNN模型无法充分利用文本特征信息和识别中文文本多义词的问题,构建一种新的文本情感分析模型FG_MCCNN。该模型分别通过词向量、词性对向量和字向量3个通道进行卷积计算,利用词性对向量消除多义词的干扰,采用细粒度的字向量学习更深层次的语义信息。实验对比结果表明,FG_MCCNN在中文文本情感分类上相较于对比模型具有更好的表现。下一步将研究如何提高该模型在不同领域评论语料中的分类准确性。
猜你喜欢
红外技术(2022年11期)2022-11-25
心理学探新(2022年1期)2022-06-07
北京航空航天大学学报(2021年9期)2021-11-02
昆明医科大学学报(2021年4期)2021-07-23
安阳工学院学报(2020年2期)2020-06-05
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子制作(2018年10期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
电脑知识与技术(2017年26期)2017-11-20
