
基于Att_GCN模型的知识图谱推理算法
2020-05-15 08:11林海舟卢林燕
计算机工程与应用 2020年9期
王 红,林海舟,卢林燕
中国民航大学 计算机科学与技术学院,天津300300
1 引言
知识图谱(Knowledge Graph,KG)对事实性知识进行存储和管理,以实体(节点)及其之间的关系(边)进行表示,在问答、推荐和数据集成方面具有重要应用。DBPedia[1]等规模较大的KG,在维护方面花费了大量精力,但信息仍不完整,覆盖范围的不完整性限制了其延伸应用的发展。知识图谱推理旨在利用已有事实三元组信息,识别并推理出KG 中的缺失信息,进行KG 补全,从而丰富和扩展KG[2]。知识图谱推理包含实体解析、实体分类和链接预测三个关键技术,其中实体分类是判断实体所属的语义类别,链接预测是判断两个实体间是否存在某种特定关系。知识图谱推理对发现错误信息、挖掘隐藏信息起了很大的促进作用。然而由于KG 信息量的不断增大,实体间存在的关系也越来越丰富,传统的知识图谱推理方法已不能满足现有大规模KG 补全的需求[3]。现有的基于神经网络的KG 补全算法主要利用神经网络的学习能力和泛化能力建模KG事实元组,对三元组进行评分并对得分结果进行排序得到推理结果[4]。
2 相关工作
图作为一种数据结构,可用于表示社交网络、通信网络、蛋白分子网络等,图中的节点表示网络中的个体,边表示个体之间的连接关系。如何有效表示和利用图中的丰富信息,国内外学者进行了大量研究。图卷积神经网络框架GCN[5-8]利用谱聚类的思想,将传统的离散卷积应用在图结构数据上,卷积算子使用图中的位置信息,以允许对结构化数据进行端到端的学习,但其框架仅适用于无向图。基于此,Schlichtkrull 等人[9]提出R-GCN 模型,将GCN 扩展到有向图中,并首次证明了GCN 可用于解决关系型数据推理问题。该模型对实体特征的学习综合考虑了来自邻域实体的所有信息。但由于对邻域实体信息学习过程中使用了统一的归一化常数,未对实体间的相关性进行考虑,使得学习结果不能有效衡量邻域实体对当前实体的影响程度。
双线性对角线模型DistMult[10]将每种关系类型设置为对角阵,通过特征向量空间上的矩阵乘法和内积操作得到预测评分结果。该模型极大降低了模型复杂度并有利于处理多关系型数据。但DistMult 不能很好地处理非对称关系,因为实数向量之间的点积计算具有交换性,即如果向量表示下的(s,r,o)成立,那么(o,r,s)也必然成立,但在KG 中非对称关系的比例远多于对称关系的比例。因此,ComplEx[11]模型将DistMult 推广到复域中,利用复数之间的埃尔米特乘积不具交换性的特点,对非对称关系进行建模。ComplEx模型对非对称关系语义的捕捉以及预测效果说明显性地考虑KG 中的非对称关系,有利于提高推理效果。
Attention[12]机制由Bahdanau 等人在2015 年提出,对人类视觉所特有的大脑信号处理机制进行了模拟,能够处理可变大小的输入并关注最相关部分进而做出决策。程华[13]等利用注意力机制对拓扑图中的节点进行关注和加权,强化重要节点对链接预测任务的贡献。Petar[14]基于注意力机制,衡量相邻实体间的相关性问题,解决了关系图数据的节点分类问题,在大规模归纳数据集中取得了较好的效果。
基于此,本文提出一种基于注意力机制和图卷积神经网络的知识图谱推理模型Att_GCN,旨在解决利用神经网络进行知识图谱推理无法有效衡量实体间相关性的问题,并使用ComplEx 作为打分函数,通过显性考虑KG中的非对称关系,以提高KG推理的准确性。
3 基于Att_GCN的知识图谱推理模型
基于Att_GCN的知识图谱推理模型,首先利用注意力机制学习KG 中实体节点的邻域实体信息,隐式地为邻域中的不同实体指定不同权重,从而有效衡量不同邻域实体对当前实体的影响程度,达到多条路径信息传递的效果。接着采用GCN 的参数共享技术学习实体的相邻关系特征,进一步避免密集矩阵操作的计算。最后使用ComplEx作为模型预测的打分函数,通过分离实体特征和关系特征的实部和虚部来显性的考虑KG 中的非对称关系。模型框架图如图1所示。

图1 模型框架
该模型主要包括两部分:
(1)KG 数据的预处理。首先对KG 中的实体节点和带关系标签的边进行编号,接着将KG 表示成三元组形式并生成实体嵌入向量;再将任意实体节点的所有直接邻域节点分为以下两类:以当前节点作为尾实体的所有头实体集合和以当前节点作为头实体的所有尾实体集合,并通过查找嵌入矩阵获得相应的嵌入子矩阵;最后生成当前节点的关系稀疏矩阵。
(2)Att_GCN 模型的构建。首先采用注意力机制衡量不同邻域实体对当前实体的影响程度,获得当前实体的特征向量;接着设计关系共享权重矩阵,对当前实体的邻域实体集合的特征向量进行卷积运算,并融合其所有邻域实体特征及其相应的关系特征,得到该实体的隐性特征向量。最后利用生成的实体隐性特征向量进行实体分类和链接预测。
模型的构建是本文研究的核心内容,将注意力机制与图卷积神经网络结合并用于知识图谱推理是研究的难点。下面将详细介绍上述两部分内容。
4 模型求解
4.1 知识图谱数据的预处理
KG可以形式化描述为G={V,E,ℜ},其中V 表示KG中的实体节点集合vi∈V,E 表示带关系标签的边集合(vi,r,vj)∈E,ℜ是关系类型集合r ∈ℜ。
首先对KG 中的实体和关系类型进行编号,方便数据处理并保证其唯一性。例如三元组(4 512,52,546),其中4 512 和546 表示实体编号,52 表示关系编号,该三元组表示实体4 512 和546 间存在关系52。由于KG 中实体节点的表示是离散且没有顺序的,所以使用one-hot词袋模型对实体进行编码,并按实体编号顺序生成实体嵌入矩阵G。
接着将任意实体节点i 的所有邻域实体分为两类:以节点i作为尾实体的所有头实体集合,对应关系集合为r1;以节点i 作为头实体的所有尾实体集合,对应关系集合为r2,并通过查找嵌入矩阵G 获得相应的嵌入子矩阵g1、g2。
最后生成实体的关系稀疏矩阵p,根据节点i 的实体集合信息和关系集合信息,构造节点i 的关系稀疏矩阵,关系稀疏矩阵的行数代表KG 中的所有实体,列数代表与当前实体相关联的边数,值表示该边的关系类型。假设三元组(4 512,52,546)是实体节点546 的第2条边,则实体节点546 的前向稀疏矩阵p′中,第4 512行,第2列的值为52。
4.2 Att_GCN模型的构建
Att_GCN 模型的构建主要包括注意力层的设计、图卷积层的设计、特征融合、实体分类、链接预测这五步,构建Att_GCN模型并进行特征融合的过程如图2所示。
4.2.1 注意力层的设计
本文以单个实体节点i 为例,说明每个实体隐性特征向量的学习过程。由预处理过程可知,节点i 的头实 体集合相 对 应 的 one - hot 编 码 为,其中N 是集合中实体的个数,M 是每个实体嵌入向量的维数,M 设置为300。为了在注意力层获得足够有表达能力的特征信息,并在迭代训练中保持相同的维度,对模型输入的嵌入向量G 通过共享权重W ∈ℝM×D进行简单线性变换,接着使用注意力机制计算集合中的节点j 与节点i 之间的相关系数,并经过LeakyReLU 非线性转换:

图2 Att_GCN模型构建过程
其中,注意力机制a 是ℝD×ℝD→ℝ上的内积操作,衡量了集合中任意节点j 对节点i 的影响程度。为使eij系数在集合所有实体上易于比较,使用softmax 机制对所求的相关系数进行规范化。

则αij是邻域节点j对i的影响程度。最后使用规范化权重系数αij计算节点i的前向隐藏状态:

4.2.2 图卷积层的设计
图卷积神经网络借助图谱的理论来实现拓扑图上的卷积操作,用于提取空间特征。利用卷积神经网络的参数共享技术,可以在存有大量实体节点的知识图谱推理中减少特征学习所需要的参数,使参数在稀有关系和频繁关系之间共享,有效缓解稀有关系的过度拟合问题。与普通图卷积神经网络不同,本文使用特定于关系的共享权重机制,即卷积核权重的确定取决于边的类型和方向。在进行卷积操作过程中,为保证l 层到l+1层神经转换的正确性,对每个实体节点设置特殊的关系转换权重,保证消息的有效传递。则一般情况下,从l 层到l+1层的卷积过程表示为:


同理,使用相同的关系共享权重机制学习节点i 的后向隐藏状态输出,则节点i 的隐藏状态为
在模型的训练过程中,所有实体的隐性特征向量的学习过程是并行进行的,每个实体特征向量的更新,都会影响其相邻的所有实体的特征学习,因此,实体隐性特征向量的学习过程是循环迭代的,直到每个实体的状态趋于稳定为止。最后,由于每个实体的特征信息都融合了其相邻的所有实体信息,所以,模型可以解决多步信息的传递问题。
4.2.3 实体、关系特征融合
特征融合是将来源不同的特征融合到一起并去掉冗余信息,从而达到多种特征优势互补的目的。已知节点i 的邻域实体集合的隐藏状态为:,其中表示节点j 的隐藏状态。又因为节点i 的关系集合r1的关系稀疏矩阵为,通过融合节点i 的邻域实体集合的隐藏状态h′(l+1)和关系集合r1的关系稀疏矩阵,得到节点i的前向隐性特征向量:

4.3 模型训练
为了评估模型的有效性,本文通过两个实验进行验证:实体分类和链接预测。
实体分类任务旨在对任意给出的实体节点i,判断其所属的语义类别。本文模型通过最小化交叉熵损失函数对所有实体节点进行训练:
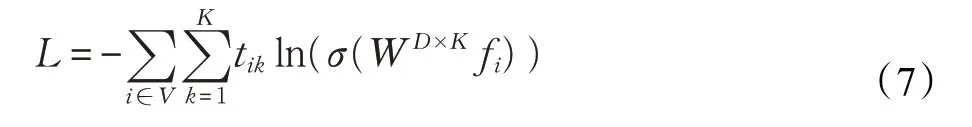
其中,tik表示节点i 属于第k 类语义类别的标记符,当节点i 属于第k 类时tik值为1,WD×K是简单线性变换权重矩阵,σ 为非线性转换函数ReLU。
链接预测任务可以描述为:给出边集合E 的部分子集e,设计一个打分函数f(s,r,o),对给定的任意边(s,r,o)∉e,判断该边属于E 的可能性。本文使用基于复域空间的ComplEx[11]分解模型作为打分函数,利用嵌入的复共轭处理KG 中的不对称关系。通过分离实体特征向量和关系特征向量的实部和虚部,能够准确描述实体间的对称关系和反对称关系,其最终的打分结果为:

其中,Re(wr)表示(s,r,o)中关系特征向量的对称实部,Im(wr)表示(s,r,o)中关系特征向量的反对称虚部。Re(fs)、Im(fs)是(s,r,o)中相对应的实体特征向量的实部和虚部。
在实验过程中随机修改某些正三元组的头实体或尾实体作为训练的负样本,使正负样本比例为1∶1,并通过交叉熵损失函数对模型结果进行优化:
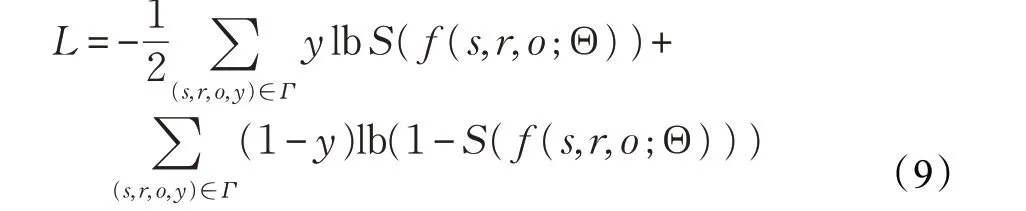
其中,Γ 是所有正负样本集合,用y 进行标识,y=1对应正三元组,y=0 对应负三元组,S 是logistic sigmoid 函数。
4.4 算法描述
Att_GCN 模型基于注意力机制和图卷积神经网络进行知识图谱推理,将KG 中的实体进行编号并通过embedding的方式嵌入到向量空间,形成嵌入向量矩阵。通过查找向量空间得到每个实体的邻域实体特征矩阵和关系稀疏矩阵。接着利用注意力机制衡量邻域实体对目标实体的影响程度,并使用图卷积神经网络学习每个实体的隐藏特征。最后在更新迭代过程中,通过最小化交叉损失函数优化实体特征向量,直到更新收敛于某个值或最大迭代次数。具体的算法描述如下所示。
算法Att_GCN
input:实体集X,关系集R,三元组集S,最大迭代次数T
output:更新后的实体集X
/*预处理*/
whilexi∈X
#将xi嵌入到w 维向量空间,实体集合X,实体嵌入维度w,shape为实体个数*每个实体的维度
xi←onehot_input(X,shape)
#获得节点i 的邻域实体矩阵,通过索引值i 在X 中查找得到每个实体的嵌入向量
end while
while ri∈R
#生成节点i的关系向量,权重参数符合标准正态分布,其中标准正态分布的均值mean,标准差variance,共享权重矩阵的形状为shape
ri←make_tf_variable(mean,variance,shape,'normal')
end while
while si∈S,xi∈X
#构造节点i关系稀疏矩阵,indices为二维张量( )n,ndims,n 为非零元素的个数,ndims 为稀疏矩阵维数;values:对应indices所指位置元素值;dense_shape:稀疏矩阵的维数
/*Att_GCN模型算法过程*/
for each xi∈X
#利用注意力机制获得邻域实体j 对节点i 的影响因子,W 为全连接层权重参数
αij=softmax(LeakyReLU(Wxi⋅Wxj))
#融合邻域实体对节点i的影响程度得到i的隐藏状态

#通过图卷积操作学习节点i的邻域实体特征

#融合邻域实体和关系特征得到节点i 的隐性特征向量,将节点i的邻域实体特征与稀疏矩阵信息融合

#更新节点i的特征向量,将节点i的前向信息与后向信息融合得到整体信息
end for
5 实验结果与分析
5.1 实体分类实验过程
数据集:本文的实体分类实验采用4个RDF 格式的数据集(http://dws.informatik.unimannheim.de/en/research/acollection-of-benchmark-datasets-for-ml),包括AIFB、MUTAG、BGS 和AM。其中AIFB 数据集描述了AIFB研究所的员工、研究组和出版物,用于预测数据集中人员的从属关系。MUTAG 包含可能致癌的复杂分子图数据集,其中的关系表示原子键,或者表示某个特性的存在,将分子的属性作为预测目标。BGS是具有层次化特征描述的岩石类型数据集,其中关系表示了岩石的特征或特征层次,将岩石的特性作为预测目标。AM 数据集包含有关阿姆斯特丹博物馆中的文物信息,数据集中每个制品都链接到其他工件以及有关其生产、材料和内容的详细信息,将工件类别作为预测目标。在每个数据集中,要进行分类的是作为节点表示的实体属性,数据的精确统计如表1 所示。数据集中移除了用于判断实体语义类型的关系:AIFB 中的employs 和affiliation,MUTAG 中的isMutagenic,BGS 中的hasLithogenesis,以及AM中的objectCategory和material。
实验评价指标:实体分类实验采用正确率(precision)作为模型性能的评价指标:

表1 实体分类数据集
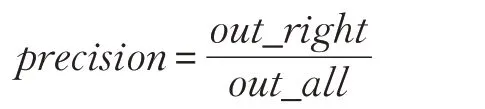
其中,out_right 表示输出结果中分类正确的实体个数,out_all 表示用于实体分类的所有实体个数。
参数设置:本文使用500 维的实体训练维度,与R-GCN 模型保持一致的维度以保证实验的公平性。同时通过不同实体嵌入维度的实验对比可知,取实体维度为500 维时训练效果最佳。为了加速训练并避免训练过程中出现过拟合现象,利用L2正则化对关系共享权重参数进行约束,因为L2正则假设参数的先验分布是Gaussian 分布,可以保证模型的稳定性和参数的值不会太大或太小,惩罚值L2范围为{0,0.000 5,0.001};并使用dropout 策略,设置范围为d={0.3,0.4,0.5,0.6,0.7};迭代过程中每批次送入训练数据的大小参数为{50,100,150,200};在模型训练过程中使用全批量梯度下降技术。所有训练只对训练集进行超参数优化,基于验证集的性能,设置L2=0.000 5,注意力层d=0.6,图卷积层d=0.4,每批次送入训练数据的大小50。
实验结果:实验选取以上数据集进行模型训练,其中训练集和测试集的比例为4∶1,验证集占训练集的1/4,实验结果对比了本文直接优化的R-GCN 模型。对比模型的结果直接从论文获取,其评估结果如表2所示。
实验分析:由表2可得,对4个数据集而言,Att_GCN对比改进的R-GCN 模型分类结果上均提高了2%左右,实验结果说明对来自相邻实体的消息进行不同程度的学习,对影响程度大的邻域实体投入更多的注意力,并削弱一些无用信息,使学出来的实体特征向量更符合实际情况。

表2 实体分类结果对比
5.2 链接预测实验过程
数据集:实验选取具有挑战的FB15K-237数据集[15]作为评估对象,由于WN18k[15]和FB15K[15]数据集上存在大量的逆三元组,基于规则的简单线性转换模型LinkFeat[15]利用逆三元组信息就可以得到很好的预测结果。FB15K-237 数据集是在FB15K 的基础上去掉了所有逆三元组,通过该数据集可以更好地评估模型的性能。FB15K-237包含14 541个实体,237个关系类型。
实验评价指标:实验采用平均倒数排名(MRR)的原始设置和过滤设置[16],Hits@1、Hits@3、Hits@10 在过滤设置情况下的得分作为模型性能评价指标,指标的描述如下:

其中,out_right 表示前n%个预测结果中正确结果的个数,M 表示预测结果的总个数。

其中,out_rank 表示期望输出结果在实际结果中的排名,M 表示预测结果的总个数。
参数设置:实验选取的实体训练维度为500 维,使用L2 正则化对打分函数进行约束,惩罚值L2 范围为{0,0.005,0.01,0.015,0.02},学习率为{0,0.001,0.01},堆叠图卷积层数可取值为c={1,2,3},迭代次数为{3 000,4 000,5 000,6 000}。通过验证集实验效果,选取L2=0.01,注意力层d=0.6,图卷积层数c=2,图卷积层d=0.5,迭代次数为6 000。
实验过程中的训练迭代次数、实体训练维度、图卷积层数的参数设置实验对比如表3所示。
实验结果:实验结果比较了DisMult模型,本文直接优化的ComplEx 模型和R-GCN 模型,对比模型的结果直接从相应论文获取,实验结果如表4所示。
实验分析:由表4 可知,Att_GCN 的实验结果均高于DisMult 模型,直接改进的ComplEx 模型、R-GCN 模型的结果,说明Att_GCN模型将注意力机制与图卷积神经网络相结合,使用注意力机制进行实体间相关性学习,并显性地考虑KG 中的非对称关系有明显的优势,可以提高链接预测任务的性能。

表3 链接预测参数对比实验Hits@10结果
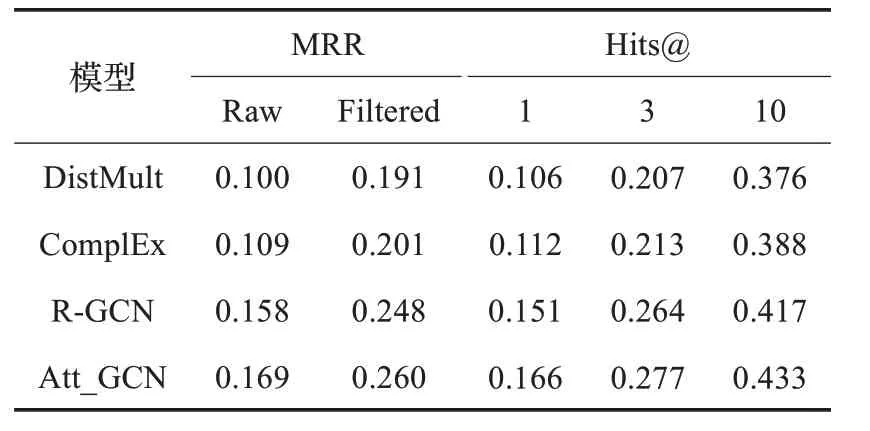
表4 链接预测结果对比
6 结束语
本文针对基于神经网络(GCN)的知识图谱推理无法有效学习KG 中实体间的相关性问题,提出了一种Att_GCN 的知识图谱推理方法,在公共语料库上的实验结果表明,该方法在KG 的实体分类任务中获得了较先进的实验效果,同时在KG 的实体链接预测中优于现有模型。本文的创新点在于采用注意力机制学习KG中实体的邻域实体对当前实体的影响程度,并利用图卷积神经网络的参数共享技术缓解传统神经网络参数指数增长的问题,最后利用ComplEx 模型的复共轭技术处理KG 中的非对称关系。通过有效编码每个实体的邻域实体信息,可以提取更丰富的实体特征,实现多路径的实体和关系特征学习,提高知识图谱推理的准确率。
该方法由于KG 中的每个实体都需要学习其相应的邻域实体集合信息,故对于每个实体而言,均需进行多次卷积操作,所以在时间复杂度上很难大幅度的减小,未来考虑采用将头实体、关系视为一个整体,将数据集中所有的实体视为尾实体进行链接预测,从而达到减少卷积操作次数的目的。其次,推理的对象是封闭的KG,即KG 的关系和实体种类是固定的,不能添加新的实体和关系,如何将深度学习的方法用到开放领域进行知识推理、自动发现新的关系还有待进一步研究。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
农业工程学报(2022年7期)2022-07-09
保定学院学报(2022年2期)2022-04-07
山西大学学报(自然科学版)(2021年1期)2021-04-21
吉林大学学报(理学版)(2020年3期)2020-05-29
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
自动化学报(2018年7期)2018-08-20
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
