
有遮挡人脸识别方法综述
2020-05-15 08:10董艳花张树美赵俊莉
计算机工程与应用 2020年9期
董艳花,张树美,赵俊莉
青岛大学 数据科学与软件工程学院,山东 青岛266071
1 引言
近几十年来,由于人脸图像中含有丰富的特征信息,人脸识别方法一直是最容易进行特征提取的生物识别方法,因此人脸识别顺势成为计算机视觉与模式识别领域内的一个研究热点。人脸识别是生物识别技术的一种形式,涉及到计算机视觉、机器学习、模式识别和心理学等多个方面,是基于人独特的特征进行身份验证的有效手段。人脸识别具有图像获取途径简单、成本较低,而且用于身份鉴定的过程中完全不需要接触目标等优点,所以人脸识别的应用范围越来越广,例如:罪犯识别、智能视频监控、人机交互、人证比对、社交和娱乐等领域。
早在1964 年和1965 年期间,Bledsoe 与Helen Chan等人就开始利用计算机数学旋转补偿姿势变化进行人脸识别。1987 年Sirovich 等人[1]最早将K-L 变换应用到人脸图像的最优表示中,通过特征面进行人脸识别。Turk等人[2]于1991年提出了主成分分析(Principal Component Analysis,PCA)的eigenface 方法,应用在人脸分类中。这些传统的人脸识别方法大大地提高了人脸识别的性能。发展至今,人脸识别技术随着计算机视觉的迅速发展变得日益成熟,在商业领域的约束环境下已经有了很高的识别率。
然而,相比于约束环境,在自然真实的环境下,人脸图像在采集时往往受到各种方式的遮挡等不利因素的影响,导致现有的人脸识别性能远远不能满足实用的要求,由于遮挡的大小、形状、种类等因素的不确定性,极大地阻碍了人脸识别的研究及应用。所以要想把人脸识别技术能够在真实环境中应用,必须解决面部遮挡问题。
近年来国内外研究者一直致力于有遮挡人脸有效识别问题的研究[3-7],提出许多有效的算法,主要包含处理遮挡问题的生成模型、判别模型及鲁棒特征提取三类方法。通过利用人脸图像的结构及遮挡固有的结构来表示、抑制或消除遮挡,并对遮挡人脸进行鲁棒特征提取,以此降低遮挡对人脸识别的影响,提高了有遮挡人脸识别的健壮性和精确性。
2 传统的人脸识别方法
较早的人脸识别算法主要是简单的基于边缘检测识别的算法,比如利用纹理、边缘及肤色等一些低层人脸特征[8-9],结合人脸局部器官的几何约束[10-11]定位人脸,大部分根据先验知识进行识别,即基于知识的方法进行识别,但是这种识别方法具有实时性差、识别效率低等缺点。针对这种识别方法所存在的缺点,研究人员又提出了利用统计学习的理论区分人脸和非人脸的识别方法。所以传统人脸识别的方法主要包含两类:基于知识的方法和基于统计的方法,如图1所示。

图1 传统人脸识别方法
2.1 基于知识的方法
基于知识的方法主要是根据人脸的先验知识找到简单的规则来描述人脸局部特征之间的相对位置关系。目前主要包含基于特征和基于模板匹配的方法。
(1)基于特征的方法
该方法主要利用眼睛、鼻子、嘴角等部位的肤色、灰度及纹理特征信息及它们之间结构位置的相对固定关系进行人脸识别。为了提高复杂背景和面部旋转的人脸识别性能,Ban 等人[12]将肤色信息仅用于肤色强调,进一步提高了复杂背景和面部旋转的人脸识别性能。Lucena 等人[13]使用直接且低复杂的皮肤百分比阈值约束来增强弱检测器的性能,实验对比表明该方法提高了人脸识别率。陆继凯等人[14]利用灰度积分投影确定眼睛、鼻子、嘴巴的特征点位置分布,并利用相同特征点之间的欧氏距离与待识别人脸进行相似度匹配,根据匹配程度判别两者是否是同一人,该方法在寻找失踪人口及违法分子探查等领域具有突出贡献。
基于特征的方法适合在局部特征点比较明显的情况下,具有速度快、模型简单和分类识别效果佳等特点,但处理存在遮挡、光照变化或者姿势变化等情况的人脸图像时鲁棒性较差,就很难达到较好的识别效果。
(2)基于模板匹配的方法
该方法将待识别人脸图像与人脸模板进行面部特征匹配,找到匹配度较高的人脸模板,并将待识别人脸图像归为该人脸模板的类别。为解决现实中通常只有一小部分面部图像可用的问题,Nikan[15]提出一种基于模板匹配的局部人脸识别策略,利用模板匹配技术在数据库的样本中找到与局部图像最匹配的人脸部分,但模板尺寸小于完整图像尺寸的6.25%时,会导致识别精度急剧下降。为了探索一种在彩色图像中进行人脸识别的方法,Wang[16]提出一种使用最小二乘和人脸模板的算法,利用最小二乘匹配方法操作每个检测图像和彩色面部模板,并利用阈值决策原理确定人脸或非人脸,该方法在实验图像中可以准确地对人脸进行判断。
基于模板匹配的方法虽然可以有效地检测到图像中的人脸,但模板都是专家先预定义的,是一种粗略的模型,因此该类方法识别精度不太高,而且计算量很大。
2.2 基于统计的方法
由于人脸图像的复杂性,利用对人脸的先验知识导出的规则进行人脸识别有一定的难度,并且基于知识的识别方法具有实时性差、识别效率低等缺点,因此提出了基于统计的方法来识别图像中人脸与非人脸的统计特征。目前主要包含基于线性子空间、基于支持向量机、基于人工神经网络三类方法。
(1)基于子空间的方法
基于子空间的方法是一种将人脸图像作为一个向量经某种空间变换算法,投影到低维的子空间中的方法,在低维子空间中,具有特征计算量少、计算复杂度低的优势,能更快地实现人脸和非人脸的分类。
PCA是基于子空间最常用的人脸识别方法,通过对图像进行K-L 变换消除原有向量之间的相关性,获得最大的若干个特征向量来表示原来的图像。为避免PCA受到外界干扰因素的影响,Ren 等人[17]提出将PCA 与Adaboost算法相结合的方法,提高了PCA的识别精度和抗干扰能力。Fan[18]等人通过构造一种弱机器单元生成一种新的综合相似子空间,使改进的PCA 不仅适用于训练样本数量小于数据维数的应用场景,还可以应用于人脸图像重建,具有强大的数据表示能力。
虽然PCA 在人脸图像降维和特征提取方面取得了显著的效果,但不能有效地消除光照、遮挡、表情等不利因素对人脸识别的影响,对遮挡没有较高的鲁棒性。
(2)基于支持向量机的方法
支持向量机(Support Vector Machines,SVM)主要思想是通过核函数把低维空间中线性不可分的数据映射到高维空间中,解决了低维空间线性不可分的问题。
胡沐晗等人[19]通过PCA 提取人脸图像的重要特征并降维,利用SVM 对人脸图像进行分类。Kortli等人[20]提出利用局部二值模式直方图和支持向量机相结合的方法,提高了人脸检测的效率和鲁棒性。
虽然基于支持向量机在表情和人脸识别领域中被广泛应用,但如何选择更为合适的核函数和参数,提高对遮挡人脸识别的性能仍是未来支持向量机研究的重点。
(3)基于人工神经网络的方法
人工神经网络(Artificial Neural Network,ANN)通过对样本的自动学习,将人脸图像的规则进行隐形表达,避免复杂的特征提取,具有较强的非线性和自适应能力,能够有效处理实际中很多非线性化问题。
Yu 等人[21]提出一种基于神经网络的人脸识别算法,利用BP神经网络分类器对人脸特征进行分类,降低了背景噪声的干扰,提高人脸识别精度和运算速度。Tao 等人[22]利用核组合的局部卷积神经网络和SVM 的鲁棒人脸检测算法,使人脸识别具有鲁棒性。
目前面向实时的遮挡人脸识别,人工神经网络由于运算时间较长,且需要人为调参,导致人脸识别效率较低,但基于深度学习的人脸识别通过大规模的数据训练,学习到大量具有代表性的特征信息,弥补了人工网络的缺陷,显著提高了人脸识别效率。传统人脸识别方法从计算量、运算速度及对遮挡人脸识别的鲁棒性等方面进行比较,各有其特点,见表1。
通过表1 对比得知传统人脸识别方法不能精确识别有遮挡的人脸,而现实生活中人们经常佩戴眼镜、口罩等装饰品,导致人的面部存在各种方式的遮挡,所以传统人脸识别方法不能满足现实应用的需求,因此有遮挡人脸识别仍是计算机视觉中的一个难题,未来科研工作者需加大对有遮挡人脸识别的研究。
3 有遮挡人脸的识别方法
现实中导致面部遮挡的原因大致分为:光照遮挡、物体遮挡和自遮挡三种。目前对遮挡人脸识别问题可以从是否需要考虑遮挡位置分为“深度”特征识别和“浅层”特征识别两个方面,目前由于深度学习的网络模型能自动学习人脸特征,仅需要对大量的遮挡人脸图像进行训练,所以不需要考虑遮挡的位置。但“浅层”特征识别却需要考虑遮挡的位置,通过判别遮挡位置,实现对遮挡位置的检测,然后将遮挡部分从原始图像中分离出来,对遮挡部分进行重构,或者将遮挡部分直接丢弃。所以根据遮挡识别重点解决的问题,可以从三方面讨论使用的主要方法:一是重点考虑如何对遮挡部分重构的生成模型;二是重点考虑如何检测遮挡位置的判别模型;三是重点考虑如何对遮挡人脸有效提取特征的鲁棒特征提取。
生成模型是将待识别有遮挡人脸图像看作是原始不含遮挡的人脸图像与遮挡部分或遮挡引起的误差的叠加,通过鲁棒子空间回归将待识别图像的不含遮挡的人脸图像和遮挡部分各自回归到它们所属的子空间,或利用鲁棒结构化误差编码对遮挡引起的误差进行编码操作,重点考虑如何将遮挡部分或者遮挡误差从待识别遮挡人脸图像中分离。判别模型是将待识别有遮挡人脸图像看作有遮挡部分和无遮挡部分的拼接,通常需要对遮挡误差的权重进行复杂的描述,重点考虑如何检测到遮挡位置及如何将有遮挡部分和无遮挡部分分离开。虽然生成模型和判别模型的识别方法在有遮挡人脸下取得显著效果,但近期大量的研究工作表明,鲁棒提取遮挡人脸的有效特征对有遮挡人脸图像识别仍是至关重要的,所以遮挡人脸识别过程中鲁棒特征提取必不可少。

表1 传统人脸识别方法
3.1 生成模型
生成模型是对遮挡人脸图像数据的鲁棒学习过程中,通过已有的字典原子、人脸图像自身的“低秩”结构和遮挡的结构来表示待识别图像的遮挡部分,通过重构遮挡等噪声对待识别人脸图像中的局部特征损失来校正其对识别性能的影响,并充分理解遮挡部分的内容,提升了识别效率。生成模型主要包含鲁棒子空间回归和鲁棒结构化误差编码两种。
3.1.1 鲁棒子空间回归
前面2.2 节介绍的PCA 主要描述的是人脸图像的全局特征信息,没有充分考虑到不同类别样本间的差异性,特别是对有遮挡人脸识别时,将会导致人脸局部特征信息存在一定程度的缺失,对有遮挡人脸识别没有较好的鲁棒性。
而鲁棒子空间回归是通过将不同类别的人脸图像的高维特征数据经过线性或非线性的方式投影到低维子空间中,并为遮挡部分建立独立的子空间,试图用已有的字典原子来表示人脸图像中的遮挡,对有遮挡人脸能达到鲁棒的识别效果。目前鲁棒子空间解决遮挡人脸识别问题主要有稀疏表示、协同表示和遮挡字典学习等方法。
(1)稀疏表示方法。2008 年,Wright 等人[23]首先将稀疏表示应用到人脸识别领域,提出基于稀疏表示分类(Sparse Representation-based Classification,SRC)方法,利用尽可能少的稀疏非零项原则选择最合适的稀疏矩阵更加灵活全面地表示待识别图像,实现人脸图像分类,可以统一处理由于遮挡和损坏引起的误差。假设待识别图像中的遮挡是稀疏的,提出的稀疏表示模型如下:

其中,y 表示待识别图像,A为过完备字典,x 为y 关于A的回归系数(也称为重构系数或编码系数),‖ x ‖1是x 的l1范数,表示x 中非零系数的个数。稀疏表示分类通过引入单位遮挡字典,对训练样本利用l1范数有效回归求得待识别图像在字典原子上的最稀疏的线性表示系数,并根据稀疏系数重构待识别图像,从而提高了图像存在局部遮挡的人脸识别性能。
为了进一步有效解决遮挡人脸识别问题Wright 又提出了鲁棒的SRC[23](Robust SRC,RSRC),模型如下:

其中,A0是遮挡字典,e 是y 中遮挡部分相对应的A0的编码。该方法利用单位矩阵、傅里叶基等标准正交基作为遮挡字典,对遮挡字典相关的遮挡成分进行编码,通过大量的训练样本提取特征,求得待测样本在训练样本上的稀疏系数进行人脸图像重构,并计算出重构图像和待测样本之间的误差值。实验证明[24],当选择单位矩阵作为遮挡字典时,待识别图像的像素即使接近100%受到噪声干扰,只要确保待识别图像的维数足够高,重构系数x 也是有可能精确恢复的,进而针对有遮挡的人脸图像也有可能精确重构,从而实现遮挡人脸有效识别。但在实际应用中,训练样本数量一般都有限,而用在稀疏表示分类的人脸特征大部分都是全局特征,而全局特征表示的图像数据并不能很好地代表有遮挡情况下的数据信息,针对该问题Nan 等人[25]提出一种基于多分辨率的自适应遮挡和稀疏表示算法,将人脸图像划分为连续但不重叠的子块,用稀疏表示对每个子块进行分类,并对遮挡部分进行重构,该算法有效地结合了人脸图像的局部特征和整体特征,对遮挡人脸识别具有较高的鲁棒性。由于遮挡会破坏人脸图像的低秩子空间的结构,影响稀疏表示的分类性能,针对该问题,胡正平等人[26]提出基于低秩子空间恢复的联合稀疏表示人脸图像识别算法,通过将具有遮挡的人脸图像的所有训练样本看作一个矩阵D,将D通过子空间回归的原理得到无遮挡的人脸低秩矩阵A和有遮挡部分的误差矩阵E,并利用稀疏表示将待识别图像重构为A和E 的联合稀疏线性组合,通过对具有遮挡的人脸图像识别时引入了低秩矩阵重构人脸子空间的思想,有效地提高了稀疏表示对遮挡人脸识别的鲁棒性。但SRC 需要计算测试样本与其他每一个样本的相似度,导致识别效率较低,针对该问题,徐静妹等人[27]提出将多分类支持向量机和基于稀疏表示方法相结合的人脸识别算法,通过设置稀疏阈值来控制稀疏系数的稀疏度,消除了非零系数出现在非样本所属类别的现象。
由于实际环境中训练样本很少,每类样本就会构成欠完备字典,所以稀疏表示分类方法会产生较大的残差,因此需要将其他类别共同的部分线性表示待测样本。
(2)协同表示分类。协同表示本质是利用所有类别中的训练样本来共同表示待识别图像。Zhang 等人[28]在通过分析SRC 方法能够有效增强分类区别能力的基础上,提出基于协同表示分类(Collaborative Rep‐resentation based Classification,CRC)的人脸识别方法,模型如下:

其中,λ是正则化参数,‖ x ‖p表示对回归系数采用lp范数进行约束。该方法通过l2范数对重构系数x 进行约束,可以在宽λ的范围内获得比l1范数更高的识别率,这意味着l1范数在面部分类问题中不起关键作用,关键的是所有类的训练样本对测试样本的协同表示,而且CRC方法不仅能增强待识别图像所属类别样本对其的表示能力,同时还能抑制非本类样本对其的“过分表示”。考虑到样本局部相似性先验信息对分类识别的不同贡献,施志刚[29]构建加权矩阵并将其嵌入到CRC 中,为进一步改善人脸识别性能,将加权CRC 与线性表示分类结合,在加权CRC 的第一阶段根据重构残差排序保留相关性较大的训练样本用于下一阶段的分类识别,从而缩小分类目标,提高人脸识别精度。
基于稀疏表示、协同表示的方法,不仅需要考虑回归系数的限制,还要重点考虑如何通过学习字典来增强遮挡字典的判别性,提升各种判别信息算法的鲁棒性,所以设计一种通用的鲁棒性较高的遮挡字典进行遮挡学习,是提高遮挡人脸识别性能的关键。
(3)遮挡字典学习。目的是从原始训练样本中学习到一组新的字典,并能够很好地表示原始训练样本的能力,然后用来进行图像处理及分类。赵雯等人[30]利用低秩矩阵恢复,从待识别人脸图像中训练得到相对干净的人脸图像作为新的特征字典,并结合Fisher 准则字典学习方法对该特征字典进行学习,确保新字典中待定类的子字典对同一类别的样本具有很好的表示能力,对其他类别的样本表示能力却相反,该方法能有效减少重构误差,提高有遮挡人脸识别性能。为充分考虑遮挡的空间局部连续性,Wei 等人[31]提出一种基于有监督遮挡字典的遮挡结构稀疏性人脸识别方法,模型如下:

其中,Ae是对单位矩阵字典局部原子压缩的固定块状结构的有监督遮挡字典。该方法对训练样本中具有局部连续性的遮挡字典原子做同类标签,并计算测试样本在遮挡字典上的重构系数及重构误差,对两者进行l2,1的最小范数约束,实现对重构系数和重构误差结构化聚类。但该模型由于遮挡字典原子大小固定,不适用于面向实时的遮挡人脸识别系统的问题,为有效提取图像多尺度多方向的人脸特征,Yang 等人[32-33]提出基于Gabor特征的鲁棒表示分类方法,模型如下:

其中,G(⋅)为Gabor 变换,利用图像Gabor 变换校正遮挡人脸识别中存在的误差,形成较为通用且高鲁棒性的Gabor遮挡字典,达到对遮挡区域更为自然的描述目的,从而实现遮挡人脸图像重构。但由于Gabor 遮挡字典是通过Gabor 特征多尺度多方向的变换得到的,存在遮挡字典维度较高,计算和存储开销较大的问题,所以Yang 等人[32-33]又通过利用K-SVD 字典学习和对G(y)、G(A)、G(I)进行δ 倍的一致性下采样处理,从冗余的Ga‐bor字典中得到更加紧凑表示的遮挡字典,实现对Gabor遮挡字典的压缩。该方法解决了固定大小遮挡字典对遮挡人脸识别的局限性。但压缩后的Gabor 遮挡字典其形状结构特别凌乱,而实际中自然的遮挡一般都是具有规则的结构形状,所以不适用于描述自然的遮挡。针对该问题,李小薪等人[34]提出基于奇异值分解(SVD)的Gabor 遮挡字典学习方法,实现对原有Gabor 遮挡字典的优化,优化模型如下:

其中,Z 为原始的Gabor遮挡字典,D为要学习的压缩后的Gabor 遮挡字典,Λ为Z 关于D的表示系数。由于视觉经验的影响,通常认为遮挡字典被稀疏性约束后得到的压缩字典能更有力地表达Z,所以Yang 等人[32-33]提出对Λ进行l1或l2的稀疏约束,实现对Z 的压缩,经研究发现,Z 只要可以被D 有力表示,原本能被Z 有力表示的遮挡区域也能够被D最有力的表示,所以对Λ的稀疏约束无关紧要,重要的是对D进行冗余性约束,所以利用奇异值分解求解(6),实现对D 的冗余性约束,实验表明[34],基于SVD 的Gabor 遮挡字典学习方法比基于KSVD 的Gabor 遮挡字典学习方法在处理遮挡人脸识别上具有更好的性能,适用于面向现实的具有光照、遮挡等不利因素场合下的人脸识别系统。为了克服遮挡对识别的影响同时减少稀疏表示分类的时间,黎明等人[35]提出一种融合HOG 特征和改进KC-FDDL(Kmeans Cluster and Fisher Discrimination Dictionary Learning)字典学习稀疏表示的方法,对训练集进行改进的K-均值聚类的Fisher判别字典学习,极大缩减了识别时间。
鲁棒子空间回归方法从实现机制的优点、缺点及适用范围等方面进行比较,各有其特点,见表2。

表2 鲁棒子空间回归方法
通过表2 对比分析,可以总结鲁棒子空间回归方法在局部遮挡、微表情变化、人脸认证等方面具有显著的识别效果,但该类方法是在假设属于同一类样本的单一个体的人脸图像均位于同一个低秩子空间下实现的,且人脸图像之间的强相关性使得各种人脸的子空间在空间中分布特别紧凑,所以利用人脸图像低秩结构去除没有遮挡的人脸子空间和被遮挡的人脸子空间的相关性,实现遮挡人脸鲁棒结构化误差编码仍是解决问题的关键。
3.1.2 鲁棒结构化误差编码
通过3.1.1 小节介绍的遮挡字典学习的人脸识别方法可知,遮挡存在空间连续性和局部性,遮挡区域引发的误差有其特定的空间结构,而且遮挡会破坏人脸图像的低秩结构,因此从被遮挡损坏的数据中有效、精确地将人脸图像的低秩结构重构出来,对提高遮挡人脸识别性能尤为关键,而鲁棒结构化误差编码就是利用人脸图像低秩结构对人脸进行识别。
自然环境下的人脸图像因受到不同种类的遮挡噪声的影响,导致实际的人脸图像低秩结构与经过PCA处理的低秩结构之间有很大的差异,为提高有遮挡人脸识别的鲁棒性。Candés 等人[36]提出鲁棒主成分分析(Robust PCA,RPCA)法,将所有的训练样本矩阵Y 通过低秩矩阵分解后,得到低秩内容矩阵Z 和稀疏内容矩阵E,实现对训练样本低秩子空间的恢复,该方法考虑到如何从含有较大误差但结构稀疏的训练样本中恢复其低秩结构,因而有效抑制了稀疏噪声的影响,具有较强的鲁棒性。为了增加不同类别人脸的低秩矩阵之间的类间信息,Wei 等人[37]将所有训练样本表示为观测矩阵D,经分解后得到不含遮挡的低秩矩阵A和稀疏误差矩阵E,将RPCA应用于低秩矩阵A,得到的子空间作为人脸图像的遮挡字典,再依据稀疏表示分类和遮挡字典对待识别图像重构并对误差大小进行分类,模型如下:

其中,Ai和Aj指不同类别人脸的低秩矩阵,Ei是指对应Ai的稀疏误差矩阵,λ是约束稀疏矩阵E 的权重参数,η是平衡低秩矩阵和结构不相干的参数,通过引入F 范数对低秩矩阵进行约束,抑制不同类别之间的共有特征,同时保留各类独自特征,增强了原始RPCA 对遮挡人脸的分类识别能力。Tang 等人[38]提出利用RPCA 对人脸样本进行分解得到低秩数据矩阵和稀疏误差矩阵,建立训练样本和测试样本的人脸图像,显著提高了被遮挡人脸的识别精度。由于人类大脑视觉皮层可以用Gabor变换很好的近似表示,所以采用Gabor 特征处理图像识别具有良好的视觉特性,为提高RPCA 对遮挡人脸识别的效率,杨方方等人[39]提出了基于低秩子空间投影和Gabor 特征的稀疏表示人脸识别算法,利用RPCA 算法得到训练样本的低秩结构和稀疏误差结构,将稀疏噪声从图像中分离出来,在计算出的低秩子空间上进行分类识别。该方法通过利用图像的局部特征表示人脸信息,对光照、遮挡、表情变化等噪声存在情况下的识别具有鲁棒性,提高了计算速度和遮挡人脸识别率,适用于围巾、眼镜随机遮挡下的人脸识别。
基于RPCA 的结构化误差编码,虽然显著地提高了遮挡人脸识别的鲁棒性,但其识别性能主要依赖于大量的训练样本的数量,若数量不足就会造成局部混叠问题,所以未来基于低秩结构的误差编码识别方法需要重点研究小样本条件下的识别效率。
生成模型通过对遮挡区域的处理进行图像重构,虽然能在一定程度上改善人脸识别效果,但也存在一些弊端:(1)对遮挡区域的重构只能尽量缩小误差,并不能完全消除。(2)对图像重构可能会延长整个识别过程的时间。(3)重构过程中可能会引入新的噪声。所以针对遮挡人脸图像通过误差度量或估计等方法检测到遮挡的位置,进而排除其对识别性能的影响是解决生成模型不足的关键。
3.2 判别模型
判别模型主要通过有遮挡图像和其原图像的局部相似性误差及遮挡引起的空间局部性误差来估计遮挡位置,将有遮挡的人脸图像看作是遮挡区域和无遮挡区域的拼接,对未遮挡区域赋予较大的权重进行编码,在识别过程中可能会直接丢弃遮挡区域或根据遮挡区域进行图像重构,但重点考虑的是如何精确检测到遮挡位置,而不用理解遮挡区域的内容,进而消除或抑制遮挡对人脸识别的影响,相比于生成模型,判别模型会节省许多重构的时间,避免重构时引入新的噪声等问题。判别模型主要包含基于局部相似性的误差权重度量和基于遮挡误差支撑估计两种。基于局部相似性的误差权重度量是通过比较有遮挡图像和其原图像的局部相似性,得到两者的误差信息,并对误差赋予不同的权重来度量遮挡的位置。基于遮挡误差支撑估计是针对遮挡引起的空间局部性误差结构,用误差支撑来估计遮挡位置。
3.2.1 基于局部相似性的误差权重度量
当人眼在判断两张图像的相似度时,眼睛只是判断它们相似的区域,对非相似的区域内容直接忽略,所以对于有遮挡人脸图像的识别,通过对比遮挡图像和其原图像之间的局部相似性,对得到的误差信息赋予不同的权重进行加权误差编码,进而估计出遮挡的位置,实现对遮挡区域的检测,仅对未遮挡区域进行识别。
(1)基于鲁棒稀疏编码的误差权重度量。鲁棒子空间回归模型(1)~(3)对误差的度量都是基于lp范数以同等程度对遮挡人脸图像和重构图像所有像素点的差异进行约束,不符合人眼对遮挡图像的识别机制,所以Yang等人[40]提出鲁棒稀疏编码(Robust Sparse Coding,RSC)的方法,以局部相似性误差来估计抑制待识别图像中遮挡特征的权重大小,根据权值度量待识别图像的遮挡区域,模型如下:

其中,α是待识别图像在字典上的稀疏编码系数向量,θ为描述遮挡分布的参数,pq=-ln fq(ei)为基于Logistic 函数的概率密度函数,ei代表遮挡编码误差e 的第i 元素,yi是针对待识别图像的编码向量,ri是构成稀疏编码字典的向量,σ 是大于零的常数。该方法利用最大似然估计得出待识别图像中遮挡部分相对于遮挡字典的误差编码,为了更加精确地逼近实际应用中的遮挡误差分布,假设遮挡误差服从概率密度分布,对误差绝对值大的像素点自适应赋予较小的权重,绝对值较小的像素点自适应赋予较大的权重,通过不断迭代更新权重,得到稀疏编码系数的最优解,有效检测出待识别图像的遮挡区域并将其去除。虽然RSC 对遮挡人脸识别达到了很好的识别效果,但对稀疏系数编码的l1范数约束使计算成本非常高,所以Yang 等人[41]又提出一种正则化鲁棒误差编码,假定误差编码和稀疏编码系数分别是独立且同分布的,通过设计合理的鲁棒人脸识别权重函数,并根据遮挡像素引起的误差进行自适应、迭代地分配其不同的权重,能够鲁棒地检测到遮挡区域,减少遮挡对鲁棒编码过程的影响,可用于解决随机遮挡情况下的人脸识别问题。
(2)基于相关熵的误差权重度量。鲁棒稀疏编码在处理遮挡人脸图像识别时,是从鲁棒回归的角度,利用两幅图像的局部相似性误差权重估计遮挡区域,而Liu等人[42]则提出用熵函数作为任意两个离散向量之间的局部相似性度量,熵直接指示两个随机变量在内核大小控制的特定“窗口”中的接近程度的概率密度,对于遮挡区域引起的误差赋予较低的权重,将遮挡区域逐渐从待识别图像中分离出来,从而消除遮挡对人脸识别准确率的影响。He 等人[43]基于相关熵的启示,提出了一种基于相关熵的稀疏表示模型,通过寻找稀疏表示编码向量,使数据库的线性表示向量可以在最大相关熵准则下尽可能地与待识别图像的表示向量相关,对遮挡的像素对熵具有较小的贡献,被赋予较小的权重,对非遮挡的像素赋予较大的权重,达到检测遮挡区域的目的,进而在相关熵的框架中统一处理遮挡噪声。Ruan 等人[44]利用核熵分量分析对待识别图像进行处理,并通过K 近邻对不同加权多分辨率人脸图像进行融合分类,使该方法具有较高的识别能力和稳定性,适用于光照、表情等引起的非线性高维人脸识别。
基于鲁棒稀疏编码和基于相关熵的误差权重度量模型都是通过两张图像的局部相似性的误差来度量遮挡区域并自适应地赋予遮挡特征权重,抑制或消除遮挡对人脸识别性能的影响。但两者仍存在一些不足:(1)两者都是通过自适应地根据遮挡引起的误差大小对其赋予不同的权重,但都没有提供任何技术来保证遮挡引起的误差一定是较大的。(2)两者在迭代加权过程中可能会引入新的噪声,降低了遮挡人脸识别效率。所以未来基于局部相似性误差度量的遮挡人脸识别研究中,应当重点考虑如何保证遮挡引起的误差是大是小,怎样有效排除迭代加权过程中新噪声对识别的影响。
3.2.2 基于遮挡误差支撑估计
由于实际人脸识别应用中有遮挡图像的原图像不一定都存在,所以大部分方法需要针对待识别的遮挡人脸图像重构其无遮挡的原图像,这将导致重构图像存在不确定性的重构误差,进而不能很好地检测到遮挡区域,所以要想准确直接地检测到遮挡区域,就需要充分利用遮挡误差的空间局部连续性。
由于遮挡人脸图像中某像素点是否为遮挡,只跟其相邻区域像素点的状态有关,所以通常利用遮挡支撑来描述遮挡人脸图像中各像素点的状态。Zhou 等人[45]提出了基于Markov随机场(Markov Random Field,MRF)的稀疏误差校正(Sparse Error Correction with MRF,SEC-MRF)模型,根据遮挡引起的误差的局部空间连续性对遮挡进行检测,进而得到遮挡支撑消除遮挡特征,选择无遮挡特征进行分类识别,通过l1范数将第k 类待识别图像中的遮挡误差e∗最小化,寻找到线性回归系数,并利用ê=y-Ax̂k(第k 类待识别图像的回归系数)估计出完整地遮挡误差e。将遮挡误差支撑映射到结构图上,利用MRF 对遮挡损坏的像素及未损坏的像素之间的空间连续性进行建模,同时对遮挡误差支撑进行估计,通过实验发现[48],该方法经过大约5、6 次迭代会达到收敛,从而获得遮挡误差支撑、遮挡的全局误差和线性回归系数的确定值,实现对遮挡区域的去除,最终选择无遮挡特征进行人脸识别分类,提高了遮挡人脸识别的鲁棒性。但SEC-MRF 当遮挡面积过大时,识别率就会降低,所以Li等人[46]提出针对遮挡人脸识别的结构稀疏误差编码(Structured Sparse Error Coding,SSEC)算法,将MRF 映射到形态图模型上来描述遮挡误差支撑,对应的遮挡检测模型如下:
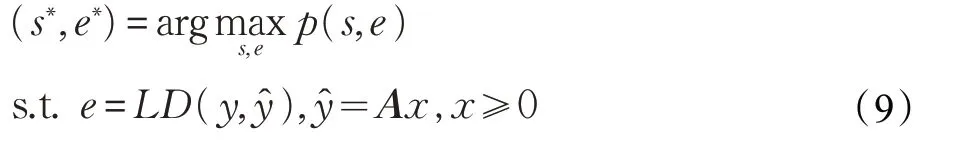
其中,s为遮挡支撑,令s ∈{- 1,1}m,si=-1表示像素yi为无遮挡部分,si=1,表示像素yi为有遮挡部分,LD 表示遮挡与未遮挡部分的误差度量算子,p(s,e)表示估计遮挡误差支撑和真实误差支撑的联合概率密度函数,p(s,e)越高,s与e 的联合概率也越高,SSEC 方法利用形态学算子检测遮挡位置的边缘轮廓,然后利用局部误差相关熵度量和伸缩不变性度量联合的误差算子LD来度量未遮挡部分的误差和遮挡部分的误差,由于LD 算子在无遮挡部分和有遮挡部分的误差度量分布服从独立的指数分布,所以SSEC 经过LD 算子度量得到的全局误差有利于在高遮挡率的情况下检测到遮挡位置,进而能够将遮挡区域从待识别图像中分离出来,适用于高遮挡率下的人脸识别。
SEC-MRF 和SEEC 都是利用MRF 对遮挡本身的局部空间连续性进行描述,获得遮挡误差支撑,从而有效检测到遮挡位置,被广泛应用于面部存在连续遮挡的场合中。但SEC-MRF 将MRF 映射到传统的图模型上,不仅解决了小误差遮挡点的难题,还降低了计算成本;而SEEC 将MRF 映射到形态图模型上,利用形态学算子有效检测到遮挡边缘轮廓,实现了大面积遮挡情况下的有效人脸识别。
生成模型和判别模型都能够针对有遮挡人脸图像进行特征选择和编码,通过挑选最具有代表性、较好分类性的人脸特征,提高遮挡人脸识别效率。而Wright等人[41]提出的稀疏表示分类生成模型则认为特征提取对识别的鲁棒性并不重要,但如果不进行特征提取,这种方法就需要大量的训练数据构造超完备字典,将增加计算开销,降低识别效率,所以选择和提取鲁棒的特征,有效降低特征维数,仍是提高遮挡人脸识别的有效途径。
3.3 鲁棒特征提取
鲁棒特征提取就是对人脸图像中诸如颜色、纹理、亮度等低阶特征和表情、年龄、性别等高阶特征进行多尺度多方向的分解,避免各种特征之间相互干扰,有效提取人脸图像中与遮挡无关的特征,抑制或消除遮挡特征对识别性能的影响,达到鲁棒的识别效果。现有的用于遮挡人脸识别的鲁棒特征提取方法法主要包含“浅层”特征提取和“深度”特征提取。
3.3.1“浅层”特征提取
“浅层”的鲁棒特征提取就是将传统的鲁棒提取方法应用到遮挡情况下,提取最有效、最有代表性、与遮挡无关的特征,实现对遮挡人脸图像的鲁棒特征提取。
基于图像梯度方向(Image Gradient Orientation,IGO)的特征提取因能较好地测量遮挡人脸图像之间的相关性,所以为解决实际连续遮挡人脸识别问题,Wu等人[47]提出一种基于梯度方向的自适应稀疏低阶模型,通过广义图像梯度方向提取有效特征,增强模型对连续遮挡人脸识别的鲁棒性。Tzimiropoulos 等人[48]提出图像梯度方向子空间学习框架,将有遮挡的测试样本与训练样本映射到梯度脸子空间中,由于在梯度脸子空间中,图像梯度特征对图像噪声具有鲁棒性,能在较大程度上不受遮挡影响提取到鲁棒的人脸特征,把测试样本映射到图像梯度PCA 子空间里将会得到几乎没有遮挡的重构图像,从而可以实现对遮挡人脸图像的鲁棒特征提取,并利用提取到的特征进行识别分类,但该方法是在两张完全不同图像相对应的遮挡区域差值近似服从均匀分布的条件下实现的,实际应用中,有遮挡图像和其原图像之间的差值并不都服从均匀分布,其面向实际环境中遮挡人脸识别性能不佳,所以该方法不能适用于有任意遮挡的人脸图像识别中。
基于Weber 局部特征(Weber Local Descriptor,WLD)的特征提取方法,最初由根据韦伯定律提出的,是一种能够有效描述图像灰度变化的局部纹理特征,通过计算WLD 的差分激励,判断图像当前像素和其邻域像素之间的灰度值变化,并求出图像的当前像素点的梯度方向,较好地反映图像纹理变化的方向信息,从而提高局部遮挡识别的鲁棒性。但WLD不能有效提取不同尺度的纹理特征,仅适用于小面积局部遮挡下的人脸识别,所以李昆明等人[50]提出一种融合多模式韦伯局部特征的人脸识别方法,首先利用韦伯局部特征算子提取人脸图像的差分激励和梯度方向信息,对差分激励进行多方向块内累积分解,获得差分激励方向累积图,然后利用局部直方图、韦伯方向和差分激励有效提取累积图像多个方向和多个尺度上的特征,接着对韦伯方向进行差分二值编码,并在特征层融合韦伯局部差分激励和方向特征,然后利用Fisher 线性判别进行特征降维,最后计算当前像素点和其邻域像素点的方向余弦相似度,有效提取图像局部的方向信息,通过融合韦伯局部多特征的方式,更有力地表征图像特征,且适用于传统线性判别中出现小样本问题的场景。
WLD 特征提取仅仅反映人脸中酒窝、疤痕等细微的局部特征变化,不能很好地帮助识别,所以还需要面部的全局特征提取。岳震等人[51]将全局和局部的特征信息相结合,对待识别图像进行线性重构得到误差图像,并提取人脸图像的全局特征信息和重构图像的误差特征信息,同时利用HOG 算子提取面部局部特征,最后利用分类器将全局的双属性特征和局部的HOG 特征进行分类识别,该方法解决了局部遮挡条件下人脸识别和提取特征时丢失必要信息的问题,且适用于一定的光照及随机遮挡识别的场合。
尽管以上传统的“浅层”鲁棒特征提取方法能够提取与遮挡无关的特征,但以上的方法仍是按照人工设计的“浅层”特征来提取相关的识别特征,这将引发在图像预处理过程中易丢失人脸的细节信息,尤其当光照和遮挡混合时,遮挡比例会特别高,导致人脸识别的鲁棒性差。所以为有效降低遮挡特征对识别效果的影响,需要结合深度学习的优势,提取图像的“深度”特征。
3.3.2“深度”特征提取
近年来深度学习由于能够自动学习特征的特点,而且提取的“深度”特征比人工设计的特征具有表达能力更强,稳定性好等优势,所以通过深度学习底层特征来获取更抽象更具有表达性的深层特征,期望通过多层的高阶特征来表示数据的抽象语义信息,获得鲁棒性特征,被认为是克服人工设计“浅层”特征局限性的一个好方法。
一个鲁棒的“深度”特征应同时满足图像最小化类内差异和最大化类间差异,为了识别多张人脸图像是否属于同一个人,Sun等人[52]提出DeepID2神经网络结构,利用卷积神经网络进行特征学习,通过人脸识别信号提取不同人脸特征,增大不同人脸图像间的类间差异;并通过人脸验证信号提取同一个人脸的特征,减小类内差异,从而学习到区分能力较强的特征。但由于学习的特征数太大,Sun等人[52]采用前向、后向贪心算法来选择一些有效互补的DeepID2 向量,将降维后的特征输入到联合贝叶斯模型中进行人脸分类识别,尽管该网络结构在设计时不是用来区分遮挡和非遮挡人脸,但深度学习的特征对遮挡却自适应的具有较强的鲁棒性。为进一步提取较好的面部特征,Sun 等人[53]在DeepID2 的网络基础上做了改进,提出DeepID2+网络结构,在每层卷积层增加监督信号,通过使用阈值对最后输出的512 维特征进行二值化处理,既保证识别的精确度又提高了人脸检索速度。通过实验自下往上和不同大小黑块对人脸进行多种尺度的遮挡,发现DeepID2+能够自动地对遮挡表现较好的鲁棒性,并验证了遮挡在20%以内,块在30×30 以内,DeepID2+的输出量的验证正确率几乎不变,进一步为处理有遮挡的人脸识别提供新思路。
DeepID2 与DeepID2+都是通过将人脸图像按多尺度多通道多区域进行划分训练,增加了训练样本,把训练到的向量连接起来得到最后的向量,使得卷积神经网络训练的更加充分,可以较好地过滤局部异常特征(如遮挡),有效提取了人脸图像的鲁棒特征,主要应用在判断多张图像是否是同一个人,如考勤签到的场合。然而该网络的深度特征学习过于依赖大规模的训练样本和参数调整的知识,所以Chan 等人[54]结合了卷积神经网络与局部二值模式(Local Binary Patterns,LBP)的特征提取框架,提出一种较简单的深度卷积神经网络(PCANet),通过局部零均值化预处理和PCA 滤波器提取主成分特征,极大地过滤掉图像中的遮挡特征,从而对遮挡人脸识别具有鲁棒性,通过实验证明PCANet 域的特征维度高于原始图像的像素域的特征维度,因此在高维的特征空间中,被PCANet 过滤的遮挡特征又进一步被“稀释”了,在一定程度上又极大地消除了遮挡对识别性能的影响,这意味着提升遮挡的过滤能力和特征的冗余性是鲁棒特征提取的关键。但当遮挡面积较大时,局部零均值预处理及PCA 滤波器过滤得到的“深度”特征大部分由于遮挡特征被置为零附近的较小值,所以整体特征集中分布在零附近,遮挡噪声的存在一般会导致PCANet 特征丧失冗余性,因此李小薪等人[55]提出局部球面规范化(Local Sphere Normalization,LSN)方法,将其嵌入到PCANet 的前两个卷积层之后,即特征图生成阶段,使特征图的各个局部区域的特征值都位于同一个球面,从而提升较小特征值的作用,同时抑制较大特征值的影响,实现PCANet 特征均衡化。结构如图2所示。

图2 LSN嵌入PCANet结构图
由于PCANet的卷积层通过局部零均值预处理提取的特征大部分分布在零值附近,导致特征非常稀疏,可能造成一些判别性的特征丢失,所以需要对PCANet 进行LSN,但对输入图像直接施加LSN会造成识别性能不稳定,而且PCANet 的哈希编码是对卷积层得到的特征进行离散化编码,为进一步提取柱状图特征做准备,嵌入LSN 会破坏其离散性,加之LSN 是针对二维结构的图像,局部柱状图不具备二维结构,又经实验分析[55],在理想情况下,LSN 特征将具有单峰、双峰或三峰分布,且峰值集中分布0 和±0.11 附近,将LSN 嵌入PCANet两个卷积层之后,呈现更接近理想情况的多峰值分布,而将LSN 嵌入PCANet 两个卷积层前后的峰值分布却不显著,完全不嵌入LSN 的PCANet 只出现单峰的情况,一方面意味着将LSN 嵌入PCANet 两个卷积层之后的网络能更好地消除噪声的影响,另一方面意味着嵌入卷积层之后的网络生成的特征更加丰富,具有更好的冗余性,所以最终将LSN 嵌入前两个卷积层之后,提升特征的冗余性,达到鲁棒特征提取的目的。除了DeepID 和PCANet 在遮挡人脸识别中具有显著效果外,还有如GoogleNet 和ResNet 等深度神经网络相较于传统方法均有明显优势,为克服传统神经网络参数太多,容易产生过拟合等问题,徐迅[56]结合GoogleNet和ResNet,提出深度卷积神经网络Inception-ResNet-v1 框架进行人脸识别,并利用Triplet Loss 损失函数直接学习人脸特征间的可分性,经实验发现遮挡比例在20%~30%左右时,人脸识别率为98.2%,表明该网络模型具有较强的抗遮挡性。
深度特征提取用于遮挡人脸识别的方法从特征维数、网络层数及识别率等方面进行对比,见表3。
通过表3对比分析,可以看出PCANet相比于DeepID2、DeepID2+、Inception-ResNet-v1 的识别率较低,但其网络层数最少,更具简单的结构,虽然增加网络深度可以使用更少的网络参数达到更强的表达能力,但过度增加网络层数会引发梯度消失、性能退化等问题,所以基于深度学习的“深度”特征提取网络模型未来应减少网络参数的同时更加简化网络结构,从而提高计算性能并减少存储空间。

表3 用于遮挡人脸识别的卷积神经网络
4 存在的问题及未来研究方向
随着人工智能与计算机视觉技术迅猛发展,使得面向现实的有遮挡人脸识别系统的需求急剧增加,处理好面部遮挡问题对未来人脸识别领域具有重要贡献,通过分析和研究对有遮挡人脸识别的各种方法,目前该领域尚存在许多问题,这些问题及未来发展总结如下。
(1)无法准确检测遮挡存在的位置,识别率受到很大影响。通过李小薪[57]利用狒狒脸0%~90%的随机遮挡的实验,可以证明:已知遮挡支撑并在识别过程中丢弃遮挡区域特征的NS 分类器,就算只是和“浅层”的IGO 和Weber 及LBP 特征相结合,在遮挡比例达到80%左右时,也可以达到接近100%的识别率。但利用不知道遮挡支撑的NN 分类器,即不知道遮挡的具体位置,即使和“深层”的PCANet 特征相结合,在遮挡比例达到90%时,识别率也会急剧下降。这表明准确检测遮挡的位置对人脸识别的重要性,但现实的人脸识别系统中,遮挡具有随机性、复杂性,可能会影响人脸图像的任何部分,但现实的人脸识别系统中,遮挡具有随机性、复杂性,可能会影响人脸图像的任何部分,而且遮挡幅度可能会很大,因此准确检测遮挡位置仍未来研究的重点。
(2)计算机感知遮挡仍是难题。人眼在识别一张有遮挡的图像时,由于视觉感知是否是遮挡,可以自动忽略遮挡区域,只根据未遮挡区域进行识别,但计算机需要大量的训练样本进行大规模训练,却仍不能准确感知到遮挡是否存在,而且训练样本也有限,导致有遮挡人脸识别效果不能达到最佳,所以如何让计算机准确感知到遮挡区域是未来遮挡人脸识别着重研究的方向。
(3)缺乏相关数据集。目前大部分研究实验都在AR 数据集上进行的,该数据集中只有眼镜和围巾两种遮挡类型,而且采集方式也都是在人为控制的环境下进行的,与现实复杂遮挡模式具有较大的差距,因此未来需要关注该领域数据集的研究。
(4)基于深度网络的人脸识别系统,在小样本存在光照、表情等遮挡情况下,如何训练检测遮挡的网络仍是难题。尽管深度学习利用人类视觉原理进行大规模样本的训练学习,但人眼识别有光照、表情、遮挡等异常因素的人脸图像时,并不需要大规模训练,只是需要几张图像就可以判断另外一张图像是否是人脸及是否存在遮挡,所以未来需要加大力度研究如何训练小样本检测遮挡的网络。
5 结束语
人脸识别是人工智能研究领域的热点,在实际应用中要解决的问题还有很多,而图像遮挡就是这其中亟待解决的重要问题,针对该问题,本文通过回顾传统的人脸识别的相关方法,总结了图像遮挡的典型处理方法,综述了针对遮挡图像如何重构的生成模型、如何检测遮挡位置的判别模型及鲁棒特征提取等方法的相关技术。通过对比分析可知,协同表示比稀疏表示对遮挡人脸表示能力更强,能有效解决实时的人脸识别问题,但需要利用所有类别训练样本共同表示待识别图像,导致其计算量较大;又通过介绍类似于人眼识别机制的局部相似性的误差权重度量和基于遮挡自身结构的误差支撑来估计遮挡位置,总结两者适应问题和局限性;并通过总结分析可知”深度”特征提取由于复杂的网络结构和过多的网络参数,导致遮挡人脸识别的计算量较大,但由于其较强的自主学习特征的特性,较“浅层”特征提取及传统人脸识别方法具有较高的识别效率,可适用于实时的人脸识别系统。最后总结分析了目前有遮挡人脸识别存在的问题和未来研究方向,希望通过本文针对面部遮挡人脸识别问题的描述及相关方法的介绍,能够使有遮挡人脸识别问题越来越受关注,为以后研究有遮挡人脸识别提供理论依据。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
电子制作(2019年15期)2019-08-27
小学阅读指南·低年级版(2019年11期)2019-07-01
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
小天使·一年级语数英综合(2017年11期)2017-12-05
自动化学报(2017年11期)2017-04-04
读者(2016年14期)2016-06-29
噪声与振动控制(2015年4期)2015-01-01
