
基于自然语言处理的教学设计学科知识图谱自动构建研究
2020-05-11 11:49陈荟邓晖吴道婷
中国教育信息化·高教职教 2020年4期
陈荟 邓晖 吴道婷


摘 要:近几年,学科知识图谱成为知识可视化领域的研究热点。文章提出基于自然语言处理建立教学设计学科知识图谱,为该学科课程教学实践提供理论材料,同时也丰富学科知识图谱在教育领域的应用实践。首先采用基于字典的机器学习算法进行知识实体抽取,采用混合式实体关系抽取模型抽取非分类关系和学科行为动词关系,丰富关系类型;然后对抽取的知识信息进行实体对齐和实体消歧;最后在“Neo4j”可视化平台上实现了教学设计学科知识图谱的可视化。
关键词:知识图谱;教学设计;自然语言处理
中图分类号:TP391 文献标志码:A 文章编号:1673-8454(2020)07-0015-05
一、引言
学科知识图谱是一系列用来展示学科知识组织结构和内在逻辑的图形,属于垂直领域知识图谱的一个领域。至今国内外对学科知识图谱研究主要有音乐MusicBrainz[1]、地理GeoNames[2]、计算机科学等领域。教学设计作为教育技术专业的核心课程、免费师范生的教育必修课程,逐渐成为教育教学领域不可或缺的学科,有必要构建教学设计学科知识图谱,提高教学设计学科的教与学质量。教学设计学科知识图谱可以帮助广大教育领域学习者梳理教学设计学科知识关系,更高效地学习教学设计学科,同时也为知识管理与可视化提供了一种可能,为教学设计学习推荐系统、自动问答系统等研究的知识库基础系统。
学科知识图谱的建构主要有自底向上的学科知识图谱建构和自顶向下基于本体的学科知识图谱建构[3],大多研究采用自底向上的建构方法。目前学科知识图谱的构建研究还存在一些问题:基于依存句法模式匹配实体关系抽取精度还有待提高等[4];目前大多数研究的学科知识图谱实体关系为“匿名关系”或简单的分类关系,关系抽取实体关系种类不够丰富,导致学科知识关系查全率较低[5];因此有必要对学科知识图谱搭建中的“非匿名”关系抽取进行深入研究,进而提高学科知识图谱的精确度。
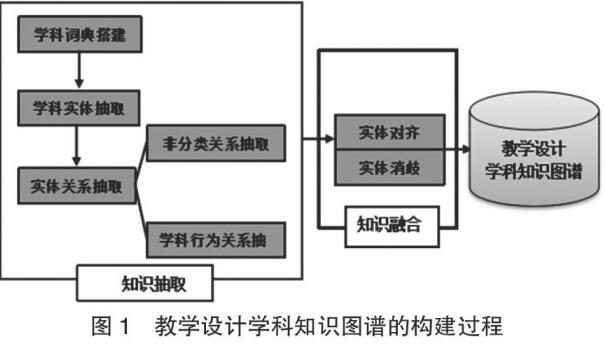
本文将基于自然语言处理技术,采用自底向上的学科知识图谱构建方法进行教学设计学科知识图谱的构建实验研究。重点搭建教学设计学科词典,提高教学设计文本分析处理的准确度,并提出混合式实体关系模型抽取非分类关系和学科行为动词关系两类学科知识关系,解决“非匿名”关系抽取难的问题,进而提高学科知识图谱精准度。教学设计学科知识图谱构建的具体步骤包括:基于bootstrapping算法进行词频统计,进而搭建教学设计学科词典;利用相关算法分析抽取出教学设计学科知识实体,并提出混合式实体关系模型抽取非分类关系和学科行为动词关系,对教学设计学科领域知识实体及知识实体关系进行修正和扩充;对数据进行融合,最终可视化完成教学设计知识图谱搭建。(见图1)
二、数据来源和研究方法
1.数据来源
为了建立高质量的学科知识图谱,知识数据需满足以下要求:①数据与该学科相关度高;②知识来源可靠,来自著名期刊或权威出版社;③在该学科领域公认度较高。基于这三个原则,最终选择中国国家图书馆、CADAL数字图书馆网站相关度高的书籍文献作为数据来源,使用Python爬取教学设计的书籍文献和各个学科教案;由于数据来源不同,需对这些原始数据进行去重,并对所有文本进行余弦相似度计算,去除相似度较低学科无关书籍文献,文本预处理除去不相关字符,最终得到45个待处理的原始文本数据和36份各学科教案。此外,选择在线教育资源信息中心(ERIC)数据库中的教育领域<教育过程:课堂观点>和<学习和感知>词数据库关键词(共计228词)作为初始教学设计学科词典。
2.研究方法与工具
本文主要采用词频统计法和自然语言处理法进行教学设计知识图谱搭建的实验研究。利用相关算法分析抽取出教学设计学科知识实体,并提出混合式实体关系模型抽取非分类关系和学科行为动词关系,对教学设计学科领域知识实体及知识实体关系进行修正和扩充。研究工具方面,分别采用anaconda Spyder的jieba库和Word2Vec库进行相关数据处理和抽取,最终使用neo4j可视化平台进行教学设计学科知识图谱可视化。
三、教学设计学科知识词典的构建
基于Bootstrapping算法思想,选择jieba分词最大匹配规则作为训练分类器,对获取的教学设计知识数据进行训练,訓练结果进行词频统计,高频词汇进行词向量相似度计算,选择置信度高的词汇加入初始教学设计学科词典,迭代此过程直到无新词生成或数据处理完毕,形成教学设计学科知识词典。
考虑到当某个词比较少见,但它在语料库中出现次数较多,那么它很有可能反映了该语料的特征,即不同词汇在同样高频的情况下其重要性是不同,故采用TF_IDF文档频率进行高频关键词的计算,其公式为:
TF_IDF=■·log(■)(1)
其中TS为某词在某个语料中出现的次数,MTS为语料中出现次数最多的词的出现次数,DS为语料库的文档总数,IDS为包含某个词汇的文档树。
用36份学科教学设计案例进行分词检验教学设计学科词典的正确性,将教学设计学科词典中没有的高频词典加入补充进学科词典。最终获得668个教学设计学科词汇,将其保存为“TXT”文件,加入jieba的用户词典路径中完成教学设计学科词典的搭建。
四、教学设计学科知识实体抽取
知识实体抽取是指采用自然语言处理技术从学科知识数据源中抽取识别与知识主题相关的知识词汇,基于学科字典的处理和机器学习相结合的抽取方法一定程度上可以提高实体识别的精度[6]。为了得到全局的最优实体集解,选择条件随机场(CRF)机器学习模型[7],结合教学设计学科词典对文本数据进行教学设计学科词汇特征学习。
对教学设计学科词典进行特征格式转化,提取词汇特征,形成的词典特征集合加入训练语料进行训练得到识别模型,利用得到的识别模型迭代标记测试语料完成教学设计学科实体识别,最终得到教学设计学科知识实体145个。(见表1)
五、教学设计学科实体关系抽取
学科实体关系抽取是指利用信息抽取技术从学科文本数据中抽取实体之间的关系,是学科知识图谱搭建的一个重要环节。大众语义关系类型主要分为分类关系和非分类关系,目前大多数研究都集中在对外文本非分类关系的抽取[8]。本研究主要抽取学科知识的非分类关系,同时考虑到学科的特定领域性,抽取学科行为关系完善学科实体关系类型。
常见的非分类关系的抽取方法为模式匹配法、动词中心度量法、关联发现法。模式匹配法源于Hearst匹配方法,它使用正则表达式表示相应概念关系[9],是较为常见的非分类关系抽取方法。随着机器学习的不断发展,根据是否对语料进行人工标注将其分为有监督、半监督和无监督的领域概念间关系抽取方法[10]。各非分类关系抽取方法的优缺点如表2所示。
基于以上语义关系抽取方法的比对,为了得到准确的非匿名学科领域语义关系,本文提出混合式实体关系模型,如图2所示,其主要包括:基于模式匹配的关系语料库非分类关系语抽取、基于动词度量的学科行为动词关系抽取。
1.基于模式匹配的教学设计学科非分类关系语料库搭建
结合对语义关系以及学科知识的常见语义关系模式集的研究,确定了常见的7种模式关系,如整部关系、特征关系等;穷举出已知的具有该关系的句式结构。依据Hearst的理论,模式应当满足发生频率高、模式准确、模式易于识别等要求[11]。关系语料库如表3所示。
使用教学设计学科词典对文本进行分词,将语义关系模式集转化为正则表达集对文本的关系匹配;使用学科词典组成分词词典的jieba分词得到带有标记的语料集合;最后使用语义关系正则模式集匹配带有标记的语料集合得到模式匹配的非分类关系概念对集。
由于教学设计学科知识体系繁杂庞大,且知识间结构化的程度参差不齐,难以快速处理大量学科知识文本数据并分辨出较为准确的学科专业知识。受到郭芳[12]等人的启发,采用小文本数据分析处理得到教学设计学科知识子图知识实体关系,通过关系融合策略形成最终的教学设计学科知识图谱。
2.基于词度量的学科行为动词关系库搭建
学科行为关系词是指在特定学科领域中代表重要含义或学科专业行为表征的关系动词或名词。为了更好的描述教学设计各个实体之间的具体关系,使建立的教学设计学科知识图谱具备教学设计学科性,本研究通过抽取典型的教学设计学科行为动词来构建教学设计学科知识图谱的学科行为关系。
采用AE度量动词关系抽取算法抽取学科行为动词。该算法通过统计两个实体出现在同一句内时伴随出现的动词N的频率来度量动词关系,计算公式如下:
AE(■)=■(2)
通过对教学设计学科文本进行动词分析,词长度为1的“看”、“听”、“分”等不能表达出准确的学科领域知识关系,故只保留AE动词度量法识别结果中的长度大于等于2的行为动词。去除大众语义通用词,使用Word2Vec工具对包含这些动词的语料进行词向量训练和聚类扩充,最后对聚类集合进行筛选,得到学科词关系实体集。其算法描述如图3所示。
通过多轮调整阈值的取值,当获得的行为动词组与教学设计学科的相似度均值最大时,则此行为动词组为最终的教学设计行为动词关系组。最终获得了“分析”、“设计”、“开发”、“实施”、“评价”这五种教学设计行为动词关系。
六、教学设计学科知识数据融合
知识融合是针对不同源数据中获取的实体及实体关系进行融合过滤的过程,知识融合包括实体消歧和实体对齐[13]。
基于DeKang Lin[14]的共性语义相似度算法,提出VMI算法[15]进行知识的融合。VMI算法使用向量空间模型表示实体的描述信息,TF-IDF为每个分量设置权重,并为分量向量建立倒排索引,最后选择余弦相似性函数计算它们的相似度,其公式为:
Sim(is,it)=■(3)
经过数据预处理后,得到有效的知识关系集合;借助邻接矩阵运算构建知识关系融合策略,将知识关系转化为邻接矩阵形式(EK),其元素定义如下:
EK[i][j]=R,(ei,j∈Gk)∩(vj∈V0)∩(vj∈V0)0,ei,j?埸Gk,
R=整部 同义 开发 设计 r1 r2 r9 r10(4)
式中,如果Gk中包含邊ei,j,则在其邻接矩阵式Ek[i][j]中的值为对于关系在关系矩阵中的值,反之则值为0。如图4所示。
七、 教学设计学科知识图谱存储与可视化
本研究使用neo4j图形数据库存储、Cypher编译进行学科知识图谱可视化。将融合后的知识实体和实体关系写入到nodes.csv和relationship.csv文件中,其中nodes文件包含实体ID和实体名称两个键,relationship文件中包含实体ID和实体关系两个键,其中实体ID需与nodes文件的对应实体ID一致。将文件导入至neo4j数据库中,最终得到教学设计的学科知识图谱,如图5所示。
八、结束语
本文提出了基于自然语言处理的教学设计学科知识图谱的构建方法,并以教学设计学科文献作为数据对其进行知识图谱的构建及可视化。在教学设计学科知识图谱构建的过程中,本文提出了混合式实体关系模型,抽取非分类关系和学科行为动词关系两类学科知识关系,解决了学科知识图谱构建中抽取“非匿名”关系的难题,进而提高了教学设计学科知识图谱的精准度。与此同时,教学设计学科知识图谱在一定程度上可以帮助教师在教学中更系统、更科学的组织教学内容的编排;同时教学设计学科知识图谱也为学生的知识结构化整理提供参考,帮助学生将离散碎片化的知识进行归纳总结,从而提高教学质量和学生的学习效率。最后教学设计学科知识图谱还可作为教学设计学习推荐系统、自动问答系统等研究的知识数据库基础,进而进行更为广泛的运用研究。
参考文献:
[1]Swartz A. Musicbrainz. A semantic web service[J]. IEEE Intelligent Systems, 2002,17(1):76-77.
[2]Goodwin J, Dolbear C, Hart G. Geographical Linked Data: The Administrative Geography of Great Britain on the Semantic Web[J]. Transactions in GIS, 2008,12(Supplement s1):19-30.
[3]Iannacone M, Bohn S, Nakamura G, et al. Developing an Ontology for Cyber Security Knowledge Graphs[J].2015:1-4.
[4]王良萸.基于web數据的碳交易领域知识图谱构建研究[D].安徽:安徽工业大学,2018.
[5]邢立栋.面向特定领域的知识图谱构建技术研究与应用[D].北京:北京化工大学,2018.
[6]Prasad G, Fousiya K K, Kumar M A, et al. Named Entity Recognition for Malayalam language: A CRF based approach[C].International Conference on Smart Technologies & Management for Computing. IEEE, 2015.
[7]Serra I, Girardi R, Novais P. The Problem of Learning Non-taxonomic Relationships of Ontologies from Text[J]. International Journal of Semantic Computing, 2013,6(4).
[8]梁吉震.基于领域概念知识的非分类关系学习研究[D].吉林:吉林大学,2012.
[9]刘雅梦.基于词向量的基础教育资源领域概念及关系抽取研究[D].湖北:武汉理工大学,2015.
[10]王舒琪,冯晓,张树武等.面向领域概念的语义关系抽取方法[J].中国传媒大学学报,2017(3):34-40.
[11]Hearst, Marti A .Automatic acquisition of hyponyms from large text corpora [J].1992(2):539.
[12]郭芳.基于众包的教育知识图谱构建与研究[D].郑州:郑州大学,2017.
[13]郝伟学.中医健康知识图谱的构建研究[D].北京:北京交通大学,2017.
[14]Lin D. An Information-Theoretic Definition of Similarity[C].International Conference on Machine Learning, 1998.
[15]Li J, Wang Z, Zhang X, et al. Large scale instance matching via multiple indexes and candidate selection[J]. Knowledge-Based Systems,2013,50(Complete):112-120.
(编辑:王晓明)
猜你喜欢
计算机应用(2016年12期)2017-01-13
中国教育信息化·基础教育(2016年9期)2016-10-18
考试周刊(2016年79期)2016-10-13
考试周刊(2016年77期)2016-10-09
考试周刊(2016年76期)2016-10-09
