
基于注意力机制的车辆行为预测
2020-05-08 05:08蔡英凤朱南楠邰康盛刘擎超
江苏大学学报(自然科学版) 2020年2期
蔡英凤, 朱南楠, 邰康盛, 刘擎超, 王 海
(1. 江苏大学 汽车工程研究院, 江苏 镇江 212013; 2. 江苏大学 汽车与交通工程学院, 江苏 镇江 212013)
车辆换道时的碰撞以及跟车时的追尾事故在交通事故中所占比例较大.随着智能驾驶技术的兴起,需要提前预测自动驾驶车辆周边车辆的未来驾驶行为,以期规划安全的驾驶路径避免碰撞.目前主流的行为预测方法为规则法[1]和基于机器学习法.规则法主要建立一系列特定的决策树,并针对场景进行微调,虽然规则法的建模过程简单,但其泛化能力弱,且不便于优化,因此应用场景有限.基于机器学习法以车辆的历史轨迹特征信息作为输入,以车辆的未来驾驶行为、未来行驶轨迹作为输出.大多数方法涉及使用分类器,文献[2-5]使用基于运动特征(包括速度、加速度、偏航率)、上下文信息(包括车道位置、转向信号、与前方车辆的距离)等作为分类器的输入.文献[6]基于距最近标记车道的距离,将车辆的运动分为车道保持和车道变换机动,并通过车辆的当前运动状态和每个车辆的预估最终运动状态来拟合五次多项式以期预测未来轨迹.
DNN架构已应用于众多机器学习任务中,成功学习了可以很好概括实际数据中出现的各种情况的表征.递归神经网络(recurrent neural network, RNN)被广泛用于分析时间序列数据结构.一种流行的RNN变体是长短期记忆网络[7](long and short-term memory,LSTM),LSTM已经在各种任务中表现出优异的性能.最近,LSTM或类似的RNN变体也被用于分析车辆轨迹[4,8].文献[8]使用以测距传感器量测作为输入的LSTM来追踪物体的位置.文献[4]使用以轨迹数据作为输入的LSTM识别驾驶员的意图.但是他们都没有解决模型输入是固定时间步长这一问题.另外考虑到输入序列中,每个时间段的信息对最后预测结果的贡献各不相同,如在一段输入序列中,被预测目标车辆在较早时刻有尝试换道的经历,较晚时刻又有趋于跟驰的倾向,于是需要为各个时段对最后的预测结果分配不同的权重.在借鉴了自然语言处理领域基于注意力机制的LSTM结构后,笔者提出一种基于注意力机制的LSTM模型对车辆行为进行预测.为了充分了解自然驾驶行为,基于机器学习的算法需要大量真实可靠的自然驾驶轨迹数据.基于最新发布的HighD数据集来训练和验证算法,描述数据抽取和预处理的过程.分析网络结构,将提出的算法和已有的算法进行比较.
1 数据抽取和处理
预测的简单场景如图1所示.采用德国亚琛工业大学汽车工程研究所新近发布的HighD数据集[9],研究者提出一种从空中角度测量车辆数据新方法,用于满足基于场景的安全验证. 该数据集包括来自6个地点的11.5 h的测量时长和110 000辆车辆的位置、速度、加速度等信息,所测量的车辆总行驶里程为45 000 km,还包括了5 600条完整的变道记录.通过使用最先进的计算机视觉算法,定位误差小于10 cm.

图1 注意力机制在智能驾驶场景中的应用
图1中,红色车辆为具备环境感知功能的智能驾驶车辆,绿色车辆为即将发生换道的目标车辆,当绿色车辆接近高速公路入口坡道时,注意力机制会将较大的权重值分配给入口坡道这一信息.同时目标车辆的行驶信息,如横向速度也会给予较大的权重.而对于即将换入车道的前后环境车辆,模型会根据其前后距离分配权重,图中黄色三角形的大小代表权重的大小.当预测到目标车辆有较大概率将进行换道时,红色的智能驾驶车辆平稳减速,所以注意力机制与人类一样,它可以将注意力转移到当前场景中的某些重要方面.
不同于HighD数据集中对换道行为的划分,将换道行为的定义稍作调整,设定航向角临界值θb,当航向角θ落入临界值的范围内,并且车辆在之后完成了换道行为,认为满足临界条件的车辆处于换道行为当中,并以此确定换道的起点和终点,同时将车辆在换道过程中与车道虚线的交点称为车道变换点,如图2所示.点1和点3分别为换道的起点和终点,满足|θ|=θb;点2为车道变换点,满足|θ|>θb.

图2 换道起点和终点的确定
以第1个|θ|值满足换道条件的时间步为基点,以从基点倒退5个历史时间步作为算法输入序列的开始时刻,以当前时刻作为输入序列的结束时刻,当输入序列时间步超过12个时间步时,将序列截断,只保留最新的12个时间步的数据,最后以结束时刻后一时间步目标车辆所处行为作为标签.至此,突破了现有研究中输入时长为固定步长的限制,输入变为可变步长的序列.将车辆行为标记为向左换道、向右换道、跟驰,按7∶1∶2的比例将数据集划分为训练集、验证集、测试集.为了解决数据不平衡问题以防止训练过程中出现过拟合,在每个行为池中选取数量相同的序列,将它们混合在一起用于数据训练,然后在每个时间步预测车辆的行驶意图.同时,将预测换道的时刻与车辆到达车道变换点的时刻记为换道预测时间,作为提前预知车辆行为的性能指标.
2 基于注意力机制的LSTM模型
基于注意力机制的LSTM模型如图3所示,该模型主要由4个部分组成: ① 输入层,每个时间步目标车辆与其周车的行驶信息,由特征向量xt表示; ② LSTM层,利用LSTM模型获取历史时间序列(x1,x2,…,xT) (T为输入的历史序列的时间步数)的特征; ③ 注意力机制,加入注意力机制提取不同时间步信息的重要性; ④ 输出层,最后利用分类器进行预测.

图3 基于注意力机制的LSTM模型
2.1 输入特征
每个时间步的输入特征向量xt包含以下内容:
1) 目标车辆信息:车辆相对于左右车道线的距离;车辆相对于车道的航向角;车辆的速度;车辆的位置坐标.
2) 周边车辆(目标车辆本车道和相邻车道的车辆)信息:与本车道前方最近车辆的纵向距离;与本车道后方最近车辆的纵向距离;与左侧车道前方车辆的横纵向距离;与左侧车道后方车辆的横纵向距离;与右侧车道前方车辆的横纵向距离;与右侧车道后方车辆的横纵向距离.
3) 行驶环境信息:车道线、匝道入口出口等(每一特征都进行独立编码).
2.2 LSTM模型
RNN通过反向传播和记忆的机制,可以将信息按照时间状态进行传递,但是RNN存在明显的缺陷,是其存在梯度爆炸或消失的问题.为解决该问题,S.HOCHREITER等[10]提出了一种RNN的变种LSTM模型.LSTM用一个记忆单元对原RNN中的隐藏节点进行替换,可以学习长期依赖信息.这个记忆单元由长期记忆细胞、输入门、遗忘门和输出门组成,其中长期记忆细胞用来存储和更新历史信息,3个门结构通过Sigmoid函数来决定信息的保留程度.LSTM模型能够避免RNN的梯度问题,具有更强的记忆能力.LSTM内部结构如图4所示.

图4 LSTM模型内部结构
LSTM的计算公式如下:
it=σ(Wxixt+Whiht-1+Wcict-1+bi),
(1)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf),
(2)
(3)
(4)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo),
(5)
ht=ottanhct,
(6)
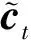
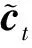
3种门的具体作用如下:
1) 输入门,用来控制当前隐藏层节点长期记忆的输入.可以判断是否将输入信息xt更新到当前时刻的长期记忆ct中,也就是判断输入中哪些部分是值得使用和保留的.输入门的输出是Sigmoid输出的0到1之间的值,1表示完全保留,0表示完全丢弃,可以看出LSTM中的输入门能够去除一些不需要的信息.
2) 遗忘门,用来控制上一时刻的隐藏层节点存储的历史信息.遗忘门会根据上一时间隐藏层的隐藏状态ht-1和当前时刻节点的输入xt计算得到0到1之间的值,作用于上一时刻的长期记忆ct-1,来确定需要保留和舍弃哪些信息.其中,1表示完全保留,0表示完全丢弃.通过遗忘门的处理可以对隐藏层的长期记忆ct(即历史信息)进行选择性处理.
3) 输出门,用来控制当前隐藏层节点的输出.确定是否输出给下一隐藏层或输出层.通过输出门的控制,可以将长期记忆专注于那些将会即可应用的信息上.它的状态也是0和1.输出门的控制功能作用于当前的长期记忆ct以得到当前时刻的隐藏状态(工作状态)ht.
2.3 注意力机制
基于注意力机制的神经网络结构,在机器问答、机器翻译、语音识别等各式自然语言处理任务中取得了成功.将基于注意力机制的LSTM模型用于车辆行为预测,令H是由LSTM层每一时间步输出的隐藏状态组成的矩阵(h1,h2,…,hT),由隐藏状态的加权和计算可得经过注意力机制的输出向量r.
M=tanhH,
(7)
α=softmax(wTM),
(8)
r=HαT,
(9)
式中:M为H经过tanh处理后的中间向量;α为注意力向量;w为训练的参数向量.
由此获得用于预测的最终表示h*为
h*=tanhr.
(10)
2.4 车辆行为预测
将注意力机制的输出h*作为softmax层的输入进行预测,预测结果为
(11)

(12)

2.5 预测模型训练
损失函数J(θ)为真实标签的负对数似然函数,定义如下:
(13)
式中:m为目标类的数量;t为用独立向量表示的真值;Y是通过softmax函数得到的每个行为类别的估计概率;λ为L2正则化超参数;θ为参数集.将drop-out与L2正则化结合起来以减轻过拟合,正则化强度设置为10-5,同时将dropout率设置为0.5,此时模型具有较好的性能.
3 试验结果与分析
3.1 软硬件平台
实车试验在“江大智能行”号智能驾驶汽车(图5)上进行.该智能驾驶车辆能够对整车的转向系统、制动系统和油门系统实现线控.其软件平台具备环境感知、地图构建、决策规划和底层控制等模块.

图5 “江大智能行”号智能汽车
3.1.1定位系统
“江大智能行”号的定位功能通过采用CORS(continuously operating reference stations)差分技术的GPS(global positioning system)和IMU(inertial measurement unit)共同实现.GPS和惯性导航技术充分结合在一起,提供准确的位置、速度信息以及姿态解算结果.CORS系统是基于多基站网络RTK技术创建的连续运行卫星定位服务系统,在城区行驶的过程中,能够对GPS 数据进行差分解算以提供更加精准的定位.
3.1.2感知系统
“江大智能行”号的感知系统包括了velodyne64线激光雷达、ibeo4线激光雷达、delphi毫米波雷达,sick单线激光雷达以及gige融合工业相机.其中,64线激光雷达布置在车顶位置,它能够识别车身60 m内的各个障碍物.2台4线激光雷达部置在大灯下方,和车辆纵轴线方向成45°,其作用是识别车辆前方110°,100 m范围内的障碍物.毫米波雷达布置在保险杠偏上方的位置,其作用是识别车辆前方90°,60 m或者20°,170 m的障碍物,常用在自适应巡航时,对跟车条件进行判断.sick单线雷达布置在车牌下方、保险杠中间位置,其作用是检测小范围内的路面信息,比如坑洼、斑马线等.2台gige融合相机分布在车辆挡风玻璃上,负责采集车道线、交通灯、标志牌等信息,且经过传感器融合,感知系统能够实现同频数据采集.各传感器安装效果如图6所示.
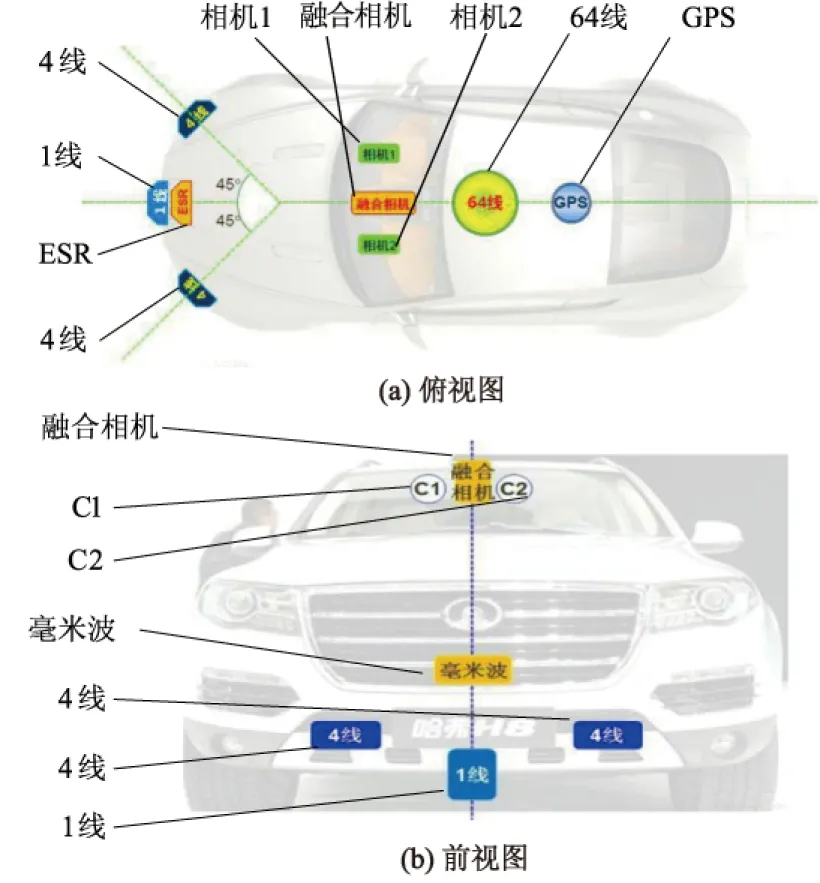
图6 传感器实车安装图
3.2 与其他算法的比较
将得到的结果与逻辑回归、前向神经网络、LSTM的结果进行比较,如图7所示,提出的基于注意力机制的LSTM算法相较于其他算法,在向左换道、车辆跟驰、向右换道的预测准确率方面都优于其他模型.

图7 不同模型预测准确率比较
3.3 序列长度对算法准确率的影响
比较了在设置不同的最大序列长度下算法的预测准确率.具体来说,将基于注意力机制的LSTM结构的历史轨迹长度,即其输入序列的最大长度设置为6,9,12,15,并将它们的结果进行比较,结果如图8所示.
从图8可以看出:随着历史长度的增加,预测的准确率在增加,但是从长度12到长度15的提升并不明显,在尝试比15更长的序列后,预测准确率几乎没有提升,说明将历史轨迹长度设置为12已经能够提供足够多的信息来保证注意力机制能够去关注重要信息,设置最大长度为12的可变步长时间序列数据划分方法可以保持数据长度方面的灵活性,减少长序列带来的时间复杂度的增加、计算资源消耗过大的问题,同时注意力机制会把权重分配给场景下相对重要的信息,保证预测准确性.
图8 不同的最大序列长度对算法准确率的影响
3.4 换道预测时间的比较
换道预测时间被定义为模型预测换道的时间与车辆实际到达车道变换点之间的时间差,时间差越长,则说明预测越有用.不同模型换道预测时间的比较如图9所示,其中,a1,a2,a3,a4分别为逻辑回归、前向神经网络、LSTM、基于注意力机制的LSTM模型.基于注意力机制的LSTM模型平均预测时间为1.68 s,相较于其他模型,预测时间更长,说明其进行提前预测的效果更好.

图9 不同模型换道预测时间的比较
4 结 论
提出了一种基于注意力机制的LSTM网络结构,并提出了一种新的可变长度的序列划分方法,以预测真实交通场景下,特别是直线道路上的车辆行为.将基于注意力机制的LSTM算法与现有的算法(逻辑回归、前向神经网络、LSTM)相比较,以显示添加了注意力机制之后在预测准确性方面的优势.通过对比,可变长度的序列划分和注意力机制能够使得模型在预测准确度和计算资源的消耗上取得良好的平衡.下一阶段的工作主要集中在完善算法在复杂工况下的表现,例如城市拥堵道路、十字路口、没有车道线的乡村道路等,力求能在各种工况下都保持良好的性能.
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
中国交通信息化(2020年11期)2021-01-14
小太阳画报(2018年3期)2018-05-14
传媒评论(2017年3期)2017-06-13
阅读与作文(小学低年级版)(2016年12期)2016-12-22
第二课堂(课外活动版)(2016年2期)2016-10-21
汽车文摘(2015年11期)2015-12-02
中国交通信息化(2015年10期)2015-06-06
