
基于语言学特征的小学生作文流畅性自动评价
2020-03-31 01:39:46吴恩慈田俊华
教育测量与评价 2020年3期
吴恩慈 田俊华
一、问题提出
作文的流畅性反映了文章的通顺程度和作者语言的规范性,是写作能力及发展的一个基本组成部分,也是作文评价中的一项重要指标。因此,研究作文流畅性对于提高作文评价的有效性、提升学生写作水平来说意义重大。《义务教育语文课程标准(2011 年版)》[1]指出,小学生在作文写作方面主要处于写话(第一学段,1~2 年级)和习作(第二、三学段,3~6 年级)阶段,对学生的要求主要体现在语言通顺、表达清晰、正确使用标点等较为浅层的方面。因此在小学生作文评改工作中,作文的流畅程度是一个具有较高优先级的评价维度。
在现阶段的汉语作文教学中,作文的评改模式仍然以传统的教师人工评价为主。然而小学阶段写作练习量大、频率高的特点,导致了人工评价具有以下缺点:(1)工作量大,教师负担过重;(2)主观性强,容易促使“印象固化”效应产生,从而影响作文评价的准确性和客观性;(3)反馈周期较长,从而造成学生印象淡化、积极性降低等负面效应。
传统作文评价模式的不足和信息技术的进步,促成了作文自动化评价领域的产生和发展。作文自动评价(automated essay evaluation,以下简称AEE)是以自然语言处理(natural language processing,以下简称NLP)为主的人工智能技术在教育应用领域的一个研究分支,它的研究目标是实现作文评阅的自动化,从而有效减轻人工负担,并提升评价的客观性。AEE 的基本思想是:(1)筛选并提取作文文本中能够表征作文质量的一系列特征;(2)选取合适的评价模型;(3)利用抽取的特征训练评价模型;(4)使用构建的模型实现自动化的作文评阅。主流AEE 系统的架构如图1 所示。
然而,迄今为止,绝大多数作文自动评价的相关研究都以英语作文为研究对象,且主要以文章的整体质量为评价对象,少有对文章某一方面的深入探讨。正如前文所述,作文的语言流畅性是评价小学生作文质量的重要标准之一。而且,作为语言自动处理领域的一个重要指标,流畅性能够反映出文章作者的思考、组织和表达能力。[2]作文流畅性研究的核心问题在于如何将流畅性这样抽象的概念具体化,并用科学合理的方法对其进行测量。Latif 指出,“流畅性”这个术语在应用语言学研究中引起了很多争论,相比于阅读和言语流畅性,作文流畅性的定义更加多样化。[3]Wolfe 将写作流畅性描述为“语言输出的舒适度和语言复述的容易程度”[4];Yang 在进行二语写作流畅性自动评价的研究中,将作文流畅性定义为“作文的通顺程度及文章语言的规范度”[5];同样在二语习得领域,Polio 认为作文流畅性是指“文章语言与母语使用者写作用语的接近程度”[6]。从已有定义可以看出,多数研究对于作文流畅性的界定倾向于作文的通顺程度以及文章语言的规范性,因此本文将沿用这样的定义。
本文在借鉴AEE 的研究思路和方法的基础上,以小学生汉语作文为对象,采用文本分类的思想,筛选并提取能够表征小学生作文流畅程度的语言学特征,进一步借助机器学习算法构建分类模型,将文章按照流畅性分为三个等级,用“自动输出流畅性等级”的形式来实现作文流畅性的自动评价。

图1 主流AEE 系统架构图
二、研究背景
在写作研究或语言教学等人文学科领域中,与作文流畅性相关的研究重点关注语言特点的分析、评价指标的选取等理论层面。Latif 等[3]指出了作文流畅性(writing fluency)在很大程度上是基于语言流畅性(speaking fluency)来评价的,并总结了两者在评价指标选取上的异同,最后对作文流畅性的科学有效测量给出了相应的意见。Plakans 等人[7]从复杂性、准确性和流畅性(complexity、accuracy and fluency,以下简称 CAF)三个方面来评价学生作文,指出作文的流畅性与复杂性、准确性在评价指标的选取上互有重叠。安福勇[8]借鉴了英语中经典的T 单位测量方法,首次将T 单位作为CSL(Chinese as a second language,汉语作为第二语言)学习者作文流畅性测量指标,并通过实证研究证明了T 单位对于汉语作文流畅性的评价是有效的。
而在计算语言学(computational linguistics,CL)或NLP 领域,相关研究重点关注的是如何利用统计学思想或机器学习等方法来从技术上解决流畅性的自动评价问题。Yang[5]以英语作文为研究对象,以AEE 的基本理论和技术路线为基础,从词汇、句式多样性、句子复杂度和语法关系这几个方面选取流畅性特征,并取得了较为理想的效果。Mutton A 等[9]采用基于句法解析器评价句子流畅性的思想,提出了一种基于支持向量机(support vector machine,SVM)的流畅性评价方法GLEU,实验结果表明,GLEU 与人工评价结果的相关度高于各个独立解析器。Ahn E 等[10]使用基于规则的语法转换(rule-based grammatical transformation)结合概率句法解析(probabilistic parsing)的方法来提升文本(英文)的流畅性,该研究提出的领域无关性(domain-independent)语法转换规则为本研究选取作文流畅性特征提供了一定的借鉴意义。Liu D 等[11]提出了一种基于改进的n-gram 模型的、不依赖标准参照的统计学方法,实现了句子流畅性的自动评价。然而该研究虽不依赖标准参照,但有效的n-gram 模型仍需要大量且合适的语料去训练。类比于本研究,若想训练出一个性能良好的n-gram 模型用于计算作文中的句子概率,需要大规模地收集高质量的小学生作文语料,这将是一个长期而浩大的工程。YuH等[12]提出了一种基于熵(entropy-based)的方法来从句子层面对翻译结果的流畅性进行自动评价,用熵来表示机器翻译结果与标准译文之间匹配词的分布情况(熵越低,表明分布越集中,翻译结果越流畅)。
三、流畅性特征的分析与提取
由于本研究主要从语言形式的角度来评价作文流畅性,因此我们从总篇、段落、句子、短语、词汇和语法错误这几个层面选取了较多的语言学计量特征,并结合了少量的内容和语义特征,来共同构成流畅性特征集。
在特征的提取方法上,本文根据特征项的不同,将特征提取工作分为两个部分:基于LTP 的特征提取和基于CRIE 的特征提取,然后将这两部分的结果组合成为完整的特征数据,用于后续的筛选和建模。对于前者,基于LTP 的特征提取是指使用“语言技术平台”[13](language technology platform,LTP)对作文文本进行预处理,获得以XML 形式表示的作文数据。在此基础上,采用DOM 解析的方式编写程序进行相应计量特征的提取。对于后者,我们使用台湾师范大学E-learning 实验室所研发的“文本可读性指标自动化分析系统2.3”[14][15](Chinese readability index explorer,CRIE 2.3,CRIE)来获取部分与流畅性相关的文本可读性指标。
1.总篇特征
作文的总体特点代表了作文给人的第一印象,因此总篇特征在作文评价中占据着重要位置。本文主要从作文的整体篇幅、所用字的笔画分布、标点符号的使用这三个方面来选取作文总篇层次的评价指标。
作文的篇幅是衡量写作能力的重要方面,且不论是已正式投入使用的AEE 产品[16],还是国内外对于作文流畅性相关的理论和实证研究[17][18],都表明作文的长短是评价作文流畅程度的有效指标。因此,本文借鉴已有研究,结合小学生汉语作文的特点,选取了总字数、总标点数、总词数、总句数、总段落数这五项指标构成作文的总体篇幅特征。
字符类特征的选取主要是受到语言研究中词长效应(word length effect)的启发:对于英语等西方语言来说,词长会影响文本阅读的流畅性;而对于中文来说,用字的复杂程度会在一定程度上影响文章流畅性。本研究中,我们选取单字的笔画数作为字符类特征,用来测量作文用字的复杂程度,并将其纳入流畅性特征集。
对于标点符号方面的特征,在小学生作文中,逗号误用现象是最为常见的标点问题之一。由于本文的研究属于较宏观的层次,且在不同的语料上,逗号误用的形式也不尽相同,因此,本文结合小学生作文常见的“一逗到底”等逗号误用现象,选取了一个粗粒度的特征——逗号比例,作为总体的标点特征。
综上所述,表1 给出了总篇特征的类型、抽取方法等详细信息。

表1 总篇特征信息
2.段落特征
段落在内容上能表述相对完整的意思,段落的划分和篇幅的分布反映了作者谋篇布局和把握文章总体的能力,进而能在一定程度上体现出文章的流畅程度。由于段落由句子组成,因此我们选取段落的平均句数来衡量段落的篇幅,如表2 所示。

表2 段落特征信息
3.句子特征
句子是作文中表达完整意义的最小单位,也是形式、内容最多样化的单位。因此,对于接触写作不久的小学生来说,句子层面的特征是拉开作文水平的重要因素,也是衡量作文流畅性的重要指标。
在篇幅类特征方面,Chae 等在机器翻译语料上的研究表明,文本句子的长度与其流畅性呈负相关。[19]基于此,我们选取了语言学领域较为通用的几个指标:平均句长、平均分句长、句平均词数、T 单位个数、T 单位平均长度,进行句子长度的测量。
在学生的实际作文中,单、复句分布不当会影响句子本身乃至全文的流畅性。例如,图2 所示的作文片段展示了小学生作文中经典的“一逗到底”现象(已进行错误标注),该片段中一个自然段只包含了一个句号,句中许多逗号的使用是不符合语法规范的,评阅者在阅读这样的段落时会明显感到不流畅。因此,本研究选取了所有句子中分句数和单句数所占的比例,将其作为比例类特征来衡量句子流畅性。

图2 “一逗到底”作文片段
除了与句子长度和比例相关的特征,某些较深层次的句子特征也可能反映出作文的流畅性。Nenkova[20]在研究句子流畅度的自动评价时,提出了衡量句子复杂度的“句法树深度”特征,且该研究表明,当句子的长度相当时,越复杂的句子流畅度越低。因此,本文将探讨此特征在预测汉语文本流畅性中的表现。
“平均句子通顺度”是“百度AI 开放平台”NLP 模块中,DNN 语言模型接口的一项输出,该特征用一个float 型的参数“ppl”来表示一个句子符合客观语言表达习惯的程度,该数值越低,则表示句子越通顺、流畅[21],这与前文对于流畅性的定义有很大的相似度,因此我们将其纳入特征集中。
“复杂语义句数”是宋曜廷等[22]在中文文本可读性研究中纳入的语义类特征。郑锦全[23]认为,复杂语义的句子会影响文章的可读性和流畅性。因此,我们将基于CRIE 抽取的复杂语义句数特征纳入流畅性特征集。
上述分析并选取的包括篇幅、比例和进阶三种类型的所有句子特征信息如表3所示。
4.短语特征
短语是由语法上或意义上可搭配的词语组合起来的语言单位。虽然在通常情况下,短语表达的意义没有整个句子那么完整,但短语类型、短语数量等的合理使用能在一定程度上反映出行文的流畅程度。
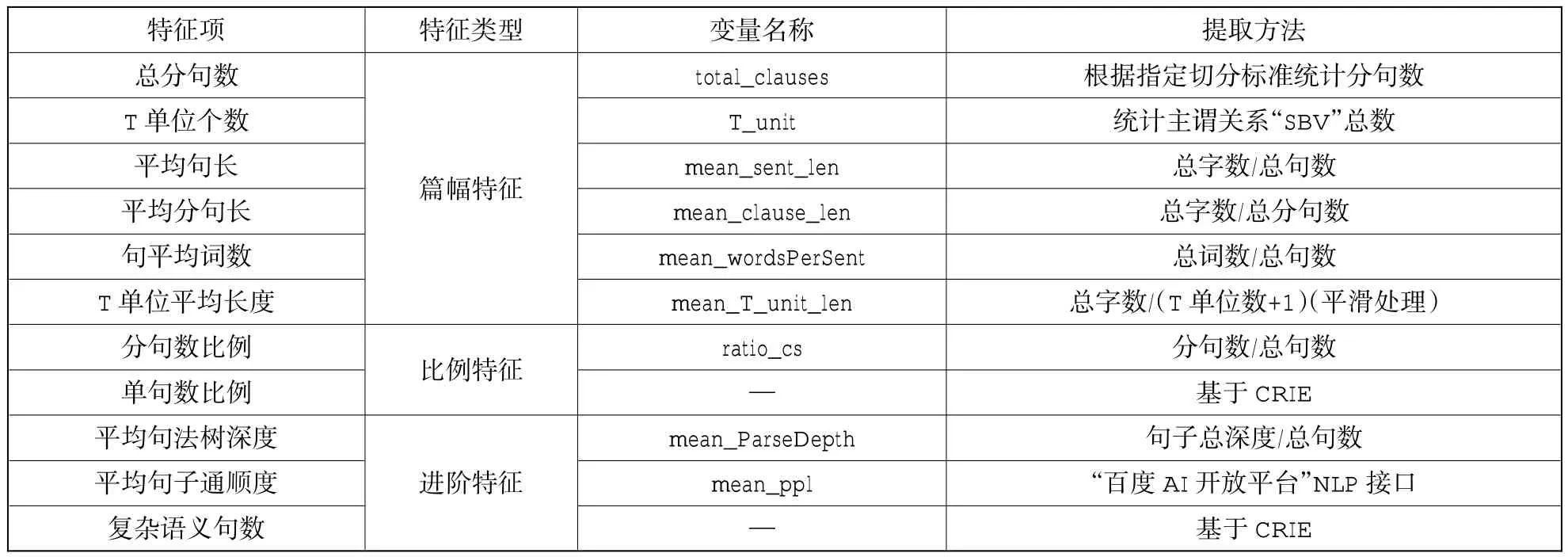
表3 句子特征信息
名词是实词中语义最明确的词类,一个句子中的名词短语越多,概念和信息也就越多。同时,名词短语修饰语的长度或数量的增加,会加大句子的理解难度。[24]因此,文章中名词短语的比例以及平均修饰语数会影响句子的流畅性。
Nenkova[20]的研究表明,在机器翻译和人工文本中,动词短语间的平均距离与句子的流畅度呈负相关。鉴于此,我们通过计算小学生作文中动词短语间平均距离(即两个动词短语之间的平均词数)来预测其流畅性,该特征的提取方法如下伪码所示:



本研究所纳入的短语特征信息如 表4 所示。
5.词汇特征
不论是在英语作文还是汉语作文评价的相关研究中,词汇类的指标都是重点探讨对象。对于小学生作文来说,词汇量的掌握情况、词汇组合和合理运用的能力等更是拉开作文等级的重要因素。
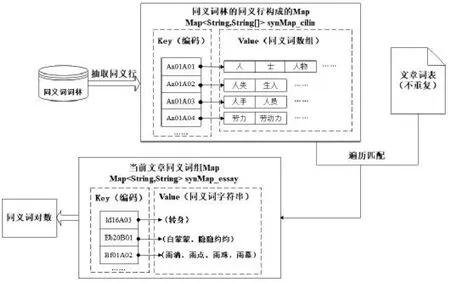
图3 同义词对数提取方法示意图
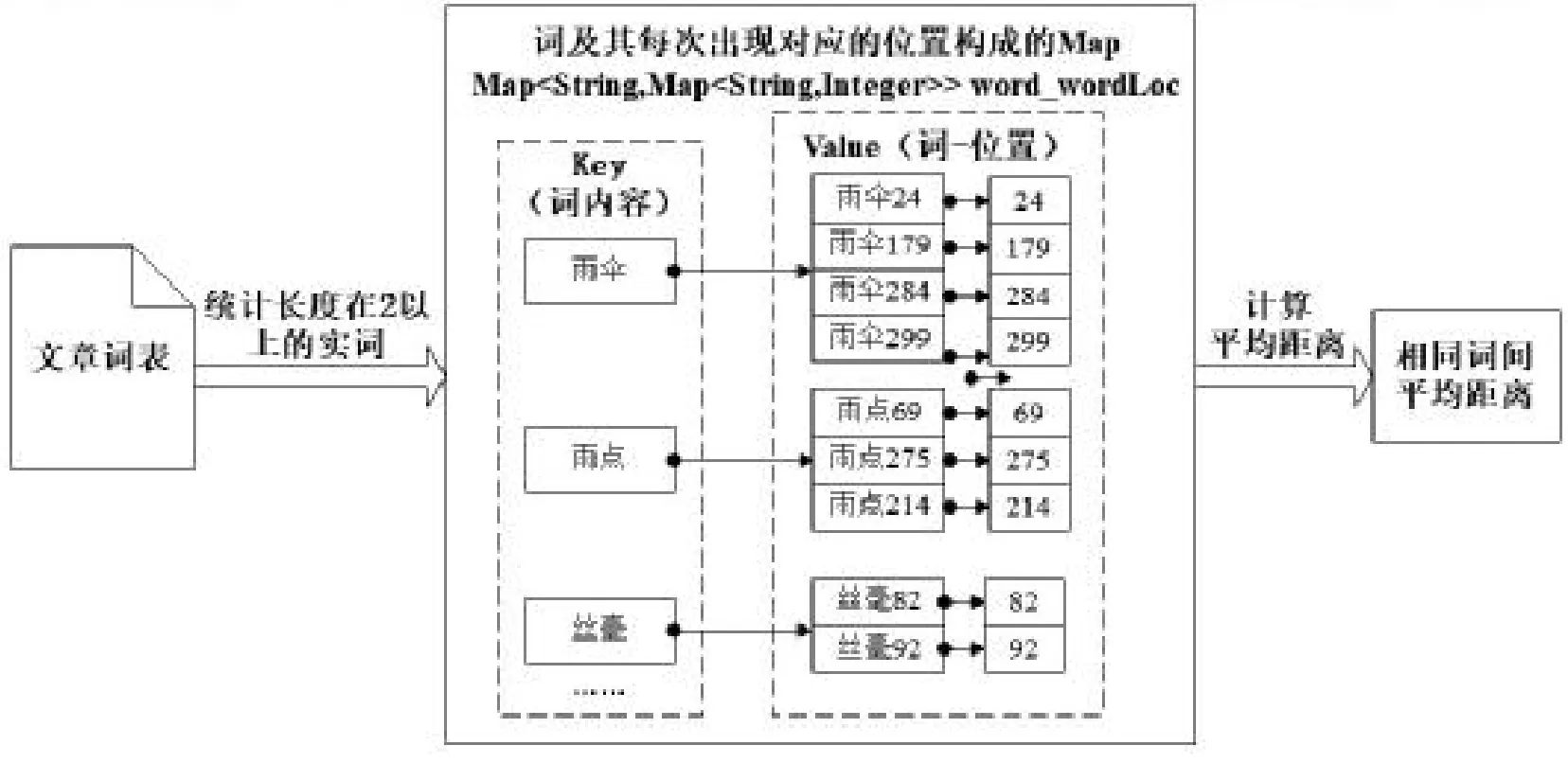
图4 相同词间平均距离提取方法示意图

表4 短语特征信息
在词汇的篇幅类特征方面,“不重复词汇数”反映了文章用词的变化度和词汇丰富度。Burstein 和Wolska 的研究表明,相同词的过度重复使用会显著影响文章的流畅性[25],且小学生由于词汇量有限,词汇的重复使用现象出现较为频繁,因此,“不重复词汇数”理论上对作文的流畅度具有较强的区分能力。宋曜廷等[22]认为,“词汇的字元数”(即组成词汇的字数)和“难词数”能够有效分辨文章难度。因此本文将探讨二字词数、三字词数和难词数与文章流畅性的关系。一些高频的功能性虚词,如否定词、代词、连词等,在文章中主要起到连接内容的作用,因而此类虚词与文章的凝聚性(cohesion)、连贯性(coherence)关系密切[26],而流畅性与上述两种文本特性在定义和测量上具有高度的相关和重叠,因此我们在篇幅特征中纳入了一系列虚词数量特征。
本文所选取的“词汇密度”和“词汇变化度”这两项比例特征,与“不重复词汇数”类似,都是衡量词汇丰富度的指标。
Yang[5]在英文作文流畅性的自动评价研究中发现,“同义词对数”和“相同词间平均距离”特征的引入使得模型效果提升明显。因此本文将借鉴Yang 的研究,在特征集中加入上述两项特征,具体如下。
(1)同义词对数
本文采用基于语料库的方法进行作文同义词特征的提取,选用的同义词语料为《哈工大信息检索研究室同义词词林扩展版》,特征提取思路如图3 所示。
(2)相同词间平均距离
文章中相同词间平均距离的提取方法与上文动词短语间平均距离的算法类似,思路如图4所示。
词汇特征信息汇总如表5 所示。
6.语法错误特征
前文所分析的特征都是基于“作文语言符合语法规范”这个假设的,但在实际的小学生作文语料中,语法不规范乃至语法错误现象屡见不鲜,而错误特征会显著影响文章的流畅性。因此,本文将根据依存句法分析结果和语言学相关知识,采用基于规则的方法,对主语缺失、未断句和指代不明这三类语法错误进行自动识别并统计频次。
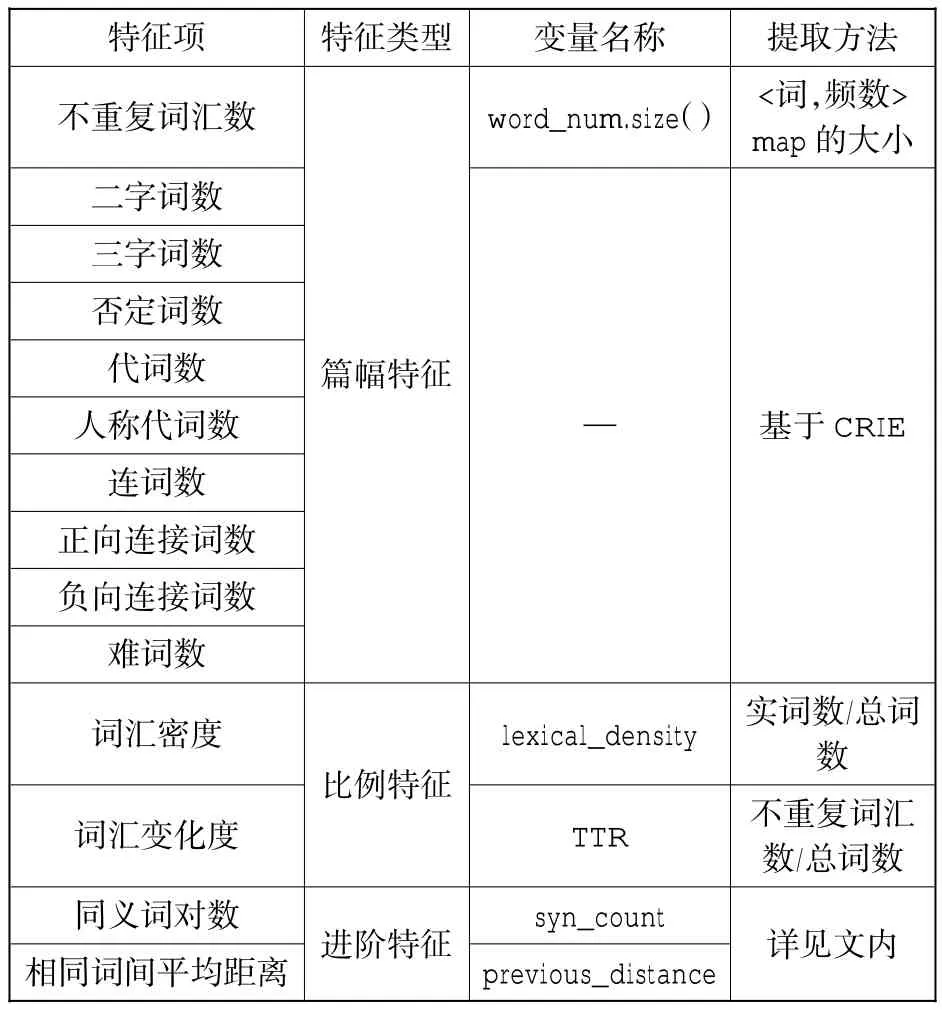
表5 词汇特征信息
(1)主语缺失
主语缺失是指整个句子中缺少主语成分,是小学生写作中常犯错误之一。在使用LTP 对语料进行预处理的基础上,我们将识别主语缺失的启发式规则总结如下:如果一个句子中处于核心关系的词结点不包含类型为“A0”的arg 子结点,且整句中没有出现主谓关系(以“SBV”标识),则判定该句存在主语缺失问题。例如,表6 给出了主语缺失的一个样例。
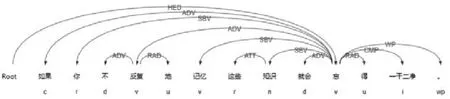
图5 未断句—错误例句依存句法分析

图6 未断句—正确例句依存句法分析

表6 主语缺失样例
(2)未断句
未断句是指句子没有按照标准的语法规范进行分割,而将句子错误地表达成为一个单句,从而影响句子的流畅度。本节实现了如下类型未断句错误的自动识别:如果一个单句或子句中出现两个及以上主谓关系(“SBV”),说明当前句内出现未断句现象,表7 给出了未断句现象的例句,图5 和图6 是错误和正确例句的依存句法分析图。

表7 未断句错误样例
(3)指代不明
指代不明主要指文中出现的代词的指向不明或有歧义,小学生作文中出现的指代不明现象主要是由于断句不当造成的句首代词指向不明。由于技术和语料限制,本文仅提取了以下情况的指代不明现象:若句首词为除第一人称代词(“我”“我们”)以外的代词,则判定该句出现了指代不明现象,如表8 中的例句所示。

表8 指代不明例句
四、流畅性评价模型的构建与实验
1.数据来源
本研究的实验数据来源于从“小荷作文网”爬取的小学生实际作文语料(以3~5 年级为主,共181 篇作文),每篇作文都已人工标注了流畅性等级(F1、F2、F3),并存储在 SQLite 数据库中。
2.特征筛选
我们把作文的流畅性等级作为预测变量,把原始流畅性特征集中的所有元素作为待筛选特征项,然后将信息增益和信息增益比大于0 的特征项由大到小进行排序,结果如表9 所示。
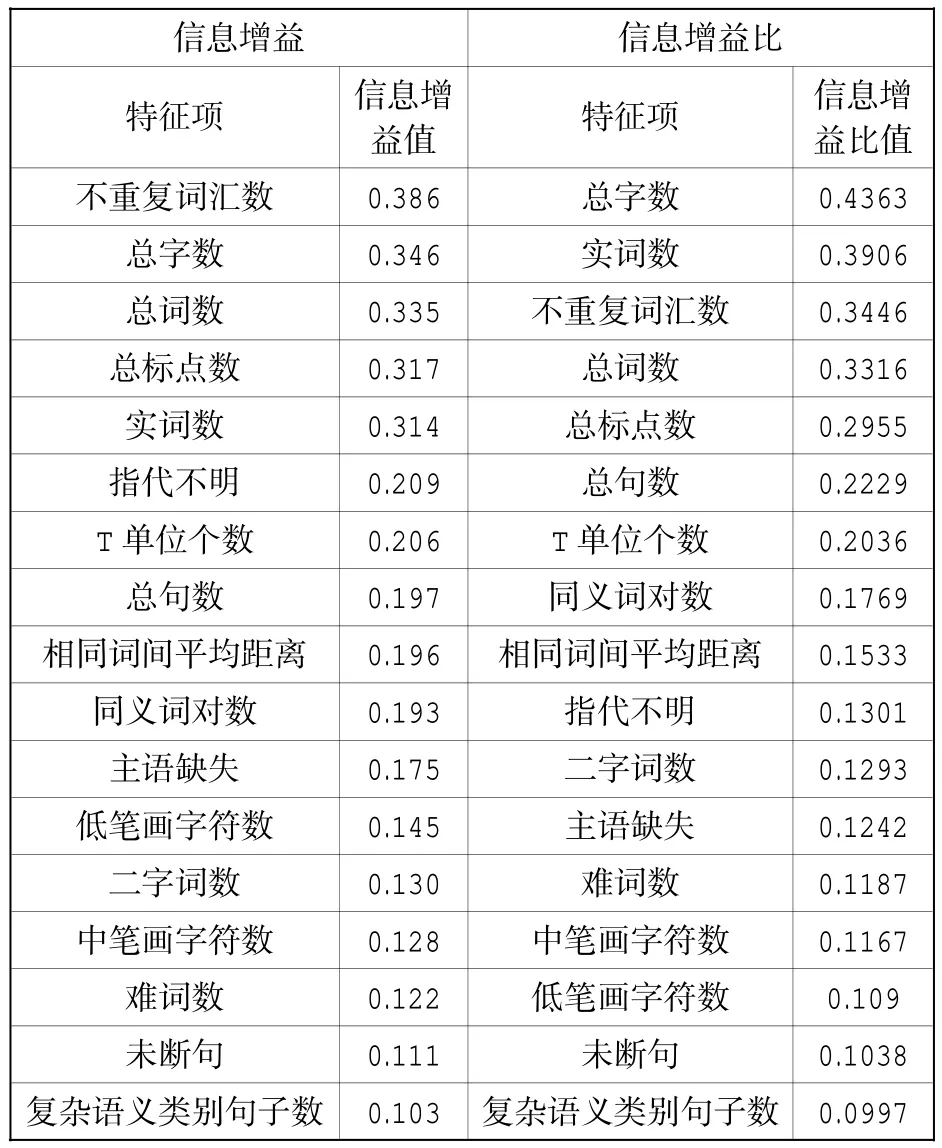
表9 特征筛选结果
从特征筛选结果可以发现,信息增益和信息增益比这两种方法筛选出的最优特征子集包含了17 个相同的特征项,只是特征项的排序稍有差别,说明这17 项特征对于作文流畅性的区分能力来说是较为稳定的。因此我们将表9 中的17 项特征视为最优的筛选特征集,将其用于模型训练。
3.模型分类实验
为了更客观地评估本文特征集对于作文流畅性的区分能力,我们分别选取了逻辑回归、决策树(J48)和支持向量机(SMO)这三种经典分类模型,以及逻辑模型树(logistic model trees,以下简称 LMT)、SimpleLogistic 和随机子空间(random subspace method,RSM)三种集成模型,并基于这六种算法训练出六个分类器,将作文按照流畅性等级进行分类,最后比较它们的分类效果。各分类器的性能指标如表10 所示,分类准确率的对比如图7 所示。
实验结果显示,集成了逻辑回归和决策树模型的LMT 和SimpleLogistic 在作文流畅性分类中表现较好。这主要是由于本研究所提取的特征都为连续型变量,决策树虽分类性能强,但其不擅长处理连续型数据,而逻辑回归的引入能够弥补该缺陷,从而让分类效果更加理想。
从上述各模型的分类结果我们可以看出,本研究所建立的特征集对于作文流畅性具有较好的区分度,最优的分类精度达到了85%以上。在实际作文教学中,流畅性自动评价模型可作为作文评价的辅助手段,帮助教师按照流畅程度对作文进行分档,进而更有针对性地评改作文和指导写作,这对提高作文评价效率、减轻教师压力具有一定的实际意义。
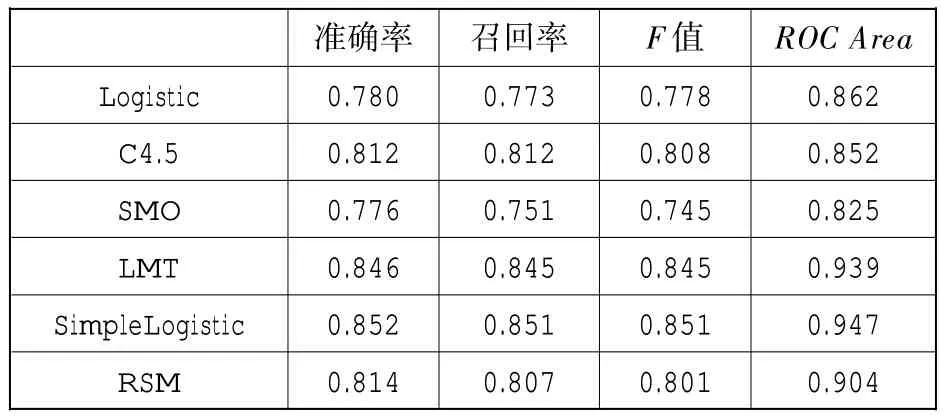
表10 各分类器性能指标
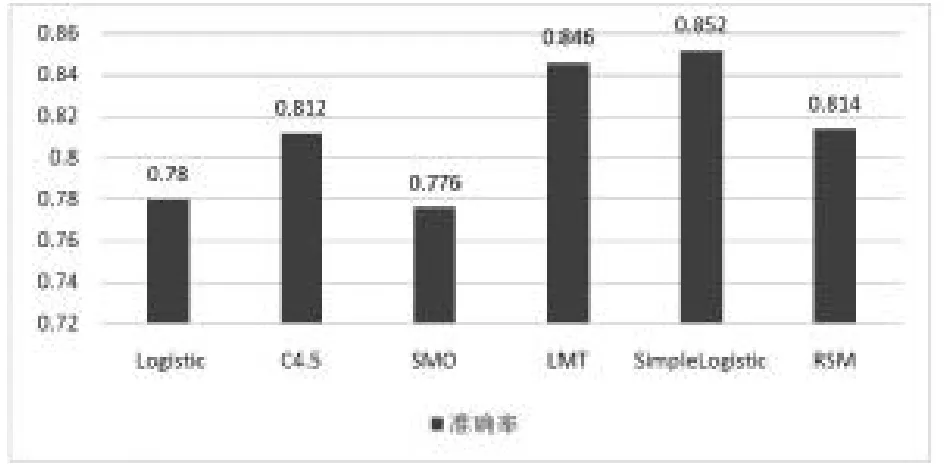
图7 各模型分类准确率对比
五、结语
本文的主要工作分为两部分,首先是分析并抽取一系列能够有效区分作文流畅度的特征,然后利用特征数据训练不同的流畅性分类器,分析效果并得出结论。本文的研究证明:(1)沿用AEE的思想实现作文流畅性的自动评价是可行的;(2)英文作文自动评价相关研究中的部分特征对于汉语作文来说同样适用;(3)用分类思想代替回归进行作文评价,能够克服线性模型的部分缺陷,增加模型的可选择范围。
从特征筛选的结果来看,对于小学生作文的自动评价来说,总体的篇幅类特征(如总字数、总词数等)、词汇特征(不重复词汇数、同义词对数等)和语法错误特征在流畅性方面具有较好的区分度。有效特征的数量虽然可观,但抽取的大多为表层的语言学特征,且特征的数据类型单一,因此从自动评价的结果来看,虽然各模型的分类准确率较为理想,但仍有一定的提升空间。
从样本的规模来看,本研究的数据集仅限于小学三、四年级的作文,且数量和题材有限,从而限制了模型的泛化性能。
基于本文的研究结果,我们对小学生作文流畅性的自动评价提出以下几点建议。(1)进一步抽取篇幅、词汇、语法等方面的具有较强区分度的语言学特征,并增加离散型特征,如“是否分段”“是否离题”等。同时,根据实际的作文教学和评价工作,结合中文信息处理的新技术,挖掘出与语言连贯性、逻辑性和人物情感等方面相关的深层语义特征。(2)广泛搜集优质作文数据,建立具有一定量级的、主题覆盖较广的作文语料库,结合深度学习模型,训练出高泛化能力和通用性的评价模型。
猜你喜欢
中华胰腺病杂志(2021年1期)2021-02-26 11:28:36
山东医药(2020年34期)2020-12-09 01:22:24
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
中华胰腺病杂志(2019年4期)2019-08-29 08:52:20
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
河南科技(2014年23期)2014-02-27 14:19:15
中华胰腺病杂志(2012年3期)2012-11-07 05:18:45
