
基于证据推理和广义Shapley值的扩展概率语言多属性群决策方法
2020-03-09 09:52刘培德
中国管理科学 2020年11期
刘培德,滕 飞
(1.中国民航大学经济与管理学院,天津 300300;2.山东财经大学管理科学与工程学院,山东 济南 250014)
1 引言
随着大数据、云计算等科学技术的发展,越来越多的决策者参与到现实重大决策问题中。以北京市公共交通价格调整事件为例,北京市发展改革委和交通委就价格改革向社会公众征求意见,全市市民通过多种方式积极参与此次决策问题,此类包含众多决策者参与的决策问题被称为大群体决策问题。现实生活中还存在着大量的大群体决策问题,例如突发事件应急决策管理、城市地铁选址和路线规划、政府政策调整等。这促使大群体决策问题成为当今的研究热点。
由于决策对象的复杂性以及决策者思维的模糊性,决策者的真实体会难以用实数进行刻画。其尤是针对决策者的定性偏好信息,语言变量作为一种定性信息描述工具能够恰当地描述决策者的偏好信息。大群体决策中,决策者依据各自的利益可以被分为多个子群体,子群体中决策者给出的信息量巨大,如何将各个子群体中决策者给出的信息进行完整的呈现是一个值得探讨的问题。基于此,Wang Hai将多个决策者给出的语言变量信息进行汇总融合[1],提出了扩展犹豫模糊语言集的概念。Zhang Guiqing等考虑了每个语言变量在所有给出的语言变量中的支持度,从而定义了包含语言变量和相关支持度的分布语言评价集[2]。Chen Zhensong等提出了比例犹豫模糊语言词集的概念,它对每个语言变量提供了比例分量信息,其数学表达形式和分布语言评估信息相同,但潜在含义不同,可以看作是执行分布语言评估信息的特殊方法[3]。在收集决策者给出评价信息的过程中存在部分决策者未给出评价信息的情况,基于此,Pang Qi等提出了概率语言词集的概念用于描述评价信息过程中存在部分信息缺失的情况,其要求收集到的语言变量的概率和小于等于1[4]。然而,现实情况还存在一个决策者给出多个语言变量的情况,这会导致所有语言变量的概率和大于1。然而,上述语言信息表示模型都不能描述此类情况,因此本文探寻了一种新的信息表示模型,对语言变量的概率放宽限制,提出了扩展概率语言词集,其能够表示概率和大于1、小于1和等于1的情况。基于此,多属性大群体决策问题转化为扩展概率语言环境下的多属性群决策问题。
扩展概率语言词集通过概率的调整,能够退化为上述语言信息表示模型,因此可以被视为一种更广义的语言信息表示模型。如何对扩展概率语言词集进行有效处理是一个值得研究的问题。证据理论作为一种处理不确定性的理论,被广泛应用于决策领域,其主要思路是将大问题分解成小问题,大证据分解成小证据,然后利用证据理论组合规则对相关证据的信度进行融合,从而获得决策问题的最佳方案[5-7]。证据推理是由多属性决策和证据理论发展而来的不确定决策方法,已经形成完整、系统的决策过程和体系。与其他方法不同,证据推理以统一的信任函数结构描述评价信息,信息的集结通过基于合成规则的证据推理算法实现。证据推理能够合理高效地处理定性或定量的信息,并且能够对不精确、不确定、不完全甚至是冲突的信息进行组合[8]。因此,本文利用证据推理去融合扩展概率语言词集,扩展概率语言环境下的多属性群决策问题可以退化为扩展概率语言环境下的多属性决策问题。
为了处理多属性决策问题,许多经典的决策方法被相继提出。TODIM 方法相较于其他方法,避免因参考点选择不合理造成的决策偏差,并且考虑了决策者的心理行为[9]。虽然现有的TODIM 方法能够处理直觉语言数、犹豫模糊语言变量、概率语言词集等模糊信息,但是不能处理扩展概率语言环境下的决策问题,因此本文对TODIM 方法进行了改进,将其拓展到概率语言环境下。
在现实决策中,无论是专家间还是属性间都存在各种交互关系(互补关系、冗余关系、独立关系)。模糊测度和广义Shapley值都是描述交互关系的有效工具,广义Shapley值相较于模糊测度能够更加全面的反映专家间或者属性间的交互作用[10-11]。本文将广义Shapley值和证据推理相结合用于融合各个子群体给出的评价信息,将广义Shapley值与TODIM 方法相结合用于方案的排序。针对多属性群决策问题专家权重或属性权重为部分未知的情形,本文给出了基于灰色关联法的专家/属性权重确定模型用于确定专家集的广义Shapley值和属性集广义Shapley值。同时,为了验证本文提出方法的合理性和有效性,利用绿色供应商选择的算例进行分析,并通过与其他方法的比较说明本文提出方法的优越性。
2 基本理论
2.1 扩展概率语言词集相关理论
定义1 设X为一给定论域且∀x j∈X,L为一给定语言术语集,且∀l i≥L,则X上形如(p)称为扩展概率语言词集的集合,其中为语言术语l i及其概率分配。方便起见(p)被称为扩展概率语言词集。
在扩展概率语言词集中,概率分布的和可能大于1,这是因为部分评价者给出犹豫模糊语言词集。例如,3位评价者利用 {l1:很低,l2:低,l3:适中,l4:高,l5:很高 对汽车的油耗进行描述,1 位评价者认为油耗适中,1位在油耗适中和高之间犹豫,1位认为油耗是高的。可得每个语言变量的概率分布,即“适中”2/3,“高”2/3。这种矛盾现象在现实生活中是常见的,因此需要采取一种标准化方法对此类情况进行处理。
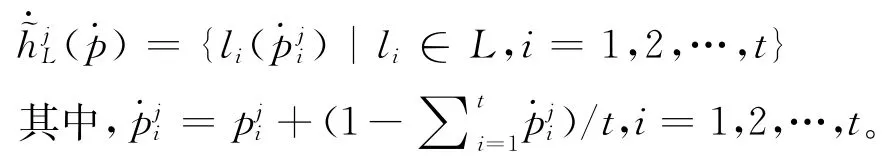
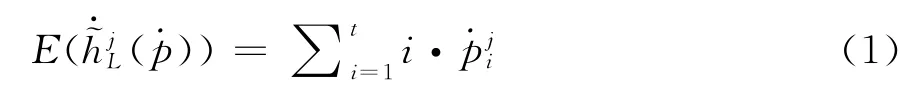
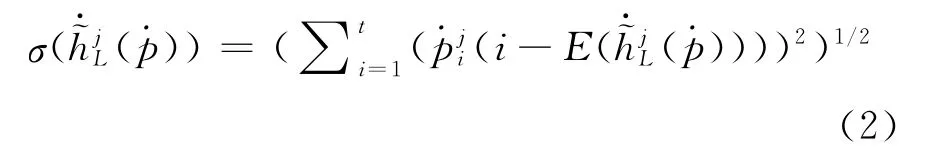
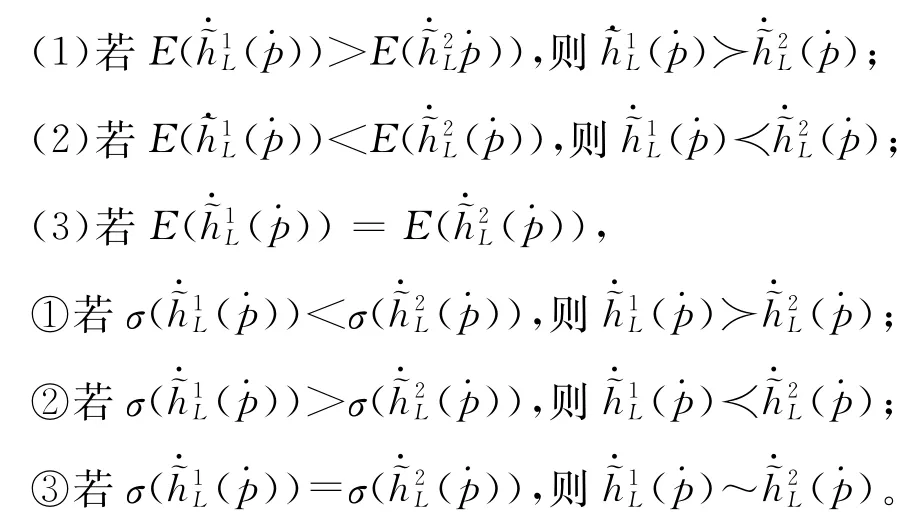

上述距离测度满足以下条件:
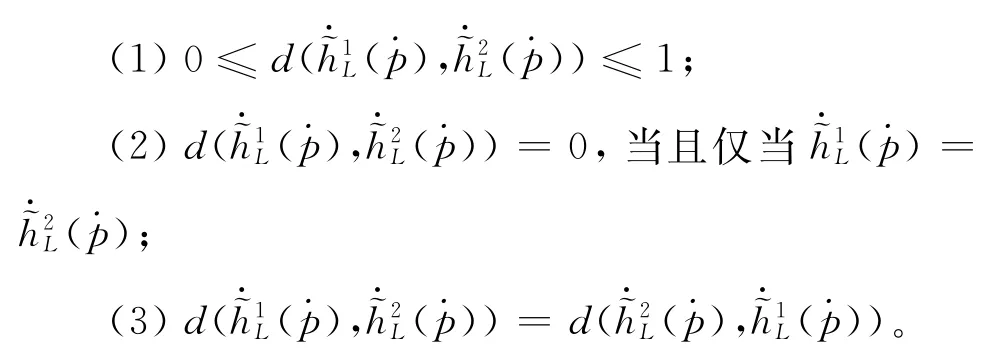
证明:
条件(2)和(3)容易证明,此处省略,条件(1)的证明如下:
证明完毕,条件(1)成立。
2.2 模糊测度和广义Shapley值
定义7[10]设P(X)为X={x1,x2,…,x n}的幂集,定义在X上的模糊测度μ:P(X)→ [0,1]满足如下条件:
(1)μ(∅)=0,μ(X)=1;
(2)若 ∀A,B∈P(X)且A⊆B,则μ(A)≤μ(B)。
模糊测度可被视为单调集函数,在X上的模糊测度具有如下特点:
(1)可加性:对于 ∀A,B∈P(X),μ(A∪B)=μ(A)+μ(B)。
(2)次可加性:对于 ∀A,B∈P(X),μ(A∪B)≤μ(A)+μ(B)。
(3)超可加性:对于 ∀A,B∈P(X),μ(A∪B)≥μ(A)+μ(B)。
在多属性决策框架中,μ(A)可视为属性子集A∈P(X)的重要程度,模糊测度的单调性意味着当新的属性被加入属性子集时,属性子集的重要程度不会减少[12]。非可加性是模糊测度的主要特征,能够更加灵活地表示决策属性之间从冗余(消极互动)到互补(积极互动)的各种关联关系[13,14]。
定义8[11]设P(X)为X={x1,x2,…,x n}的幂集,μ为定义在X上的模糊测度,则 ∀S∈P(X),广义Shapley值表示如下:
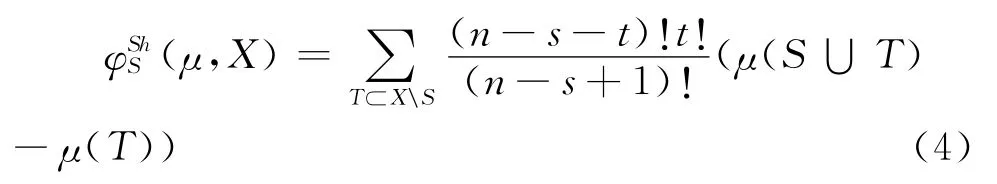
其中,n,t和s分别表示子集X,T和S中元素的个数。
从上述公式可以发现,当S中只有一个元素时,公式(4)可约简为Shapley值:
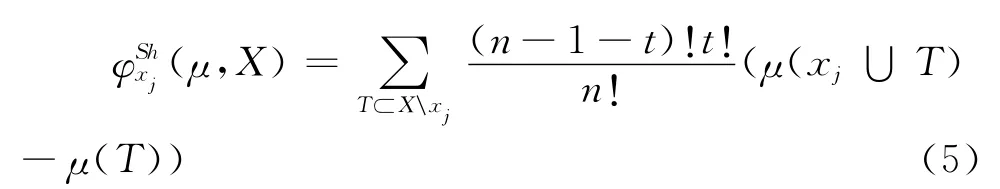
从公式(5)可知,Shapley 值(μ,X)可被视为单个属性x j的边际贡献加权平均值。∀x j∈X,X)}x j∈X是属性x j的权重向量,称为Shapley权重向量。若模糊测度μ是可加性测度,μ(x j),则x j和T⊆X\x j是相互独立的,Shapley向量退化为属性权重向量。若μ是次可加性测度,即存在冗余关系。若μ是超可加性测度,即,则x j和T⊆X\x j存在互补关系。因此,Shapley值不仅反映属性自身的重要性,而且反映与其他属性之间的交互特征。
2.3 证据理论和证据推理概述
定义9[6]令Θ= {H1,H2,…,H N}为相互独立且包含所有可能结果的集合,被称为识别框架。基本概率分配(BPA)为一个函数m:2Θ→ [0,1],也被称为mass函数,满足:
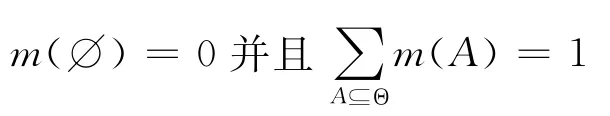
其中,∅为一个空集,A是 Θ 的子集,且2Θ是Θ的幂集包含 Θ 的所有子集,即2Θ= {∅,{H1},…,{H N},{H1∪H2},…,{H1∪H N},…,Θ}。基本概率分配m(A)测定的是精确分配给A的信度,表示证据直接支持A为真的强度。所有命题基本概率分配的总和为1,空集不产生任何信度,分配给Θ 的概率,即m(Θ),被称为未知度。任意子集A⊆Θ,若m(A)>0,则A被称为m的焦元。所有焦元的集合称为核。所有相关的焦点元素统称为证据主体。
定义10[6]设有两个完全独立的证据,它们在同一识别框架上的mass函数分别为m1和m2,D-S组合规则被定义为:

其中,A和B为焦元,[m1⊕m2](C)是基本概率分配被称作归一化因子,被称为冲突度,用来测 量 一 对 证 据 冲 突 的 程 度。 显 然,当∑A∩B=∅m1(A)m2(B)=1,完全冲突的证据合成不 适 用 此 公 式,即 [m1⊕m2](C)不 存 在;当,对高度冲突的证据合成 可 能 得 到 不 合 理 的 结 果; 当∑A∩B=∅m1(A)m2(B)<1,不完全冲突的两个证据通过上面的组合规则能够产生新的基本置信指派函数m(·)构成新的证据体。
证据推理于20世纪90年代初被首次应用到不确定环境下的决策问题,其通过设计一种新的信度决策矩阵对决策问题进行建模,并基于D-S理论的组合规则建立独特的属性聚合过程[15-17]。假设一个多属性决策问题有m个方案A( =1,2,…,m),高层次的属性被称为总属性,n个低层属性Cτ(τ=1,2,…,n)被称为基本属性。方案A在基本属性Cτ(τ=1,2,…,n)下被评价为等级H l,并且具有βl,τ(A)的信任度,可以表示为S(Cτ(A))={(H l,βl,τ(A)),l=1,2,…,N},其中βl,τ(A)≥0并且则为完全评价,如果,则为不完全评价,这些评价信息构成了信任决策矩阵D=[S(Cτ(A))]m×n。
在基本属性下备选方案的评价可被视为证据,总属性的评价等级被视作假设[15-17]。由于需要处理证据冲突,依据属性集成的基本规则对合成规则进行修正是有必要的。该过程简要描述如下:
首先,将信任度乘以属性权重可以将方案A在属性Cτ下评价等级为H n的信任度转化为BPA:
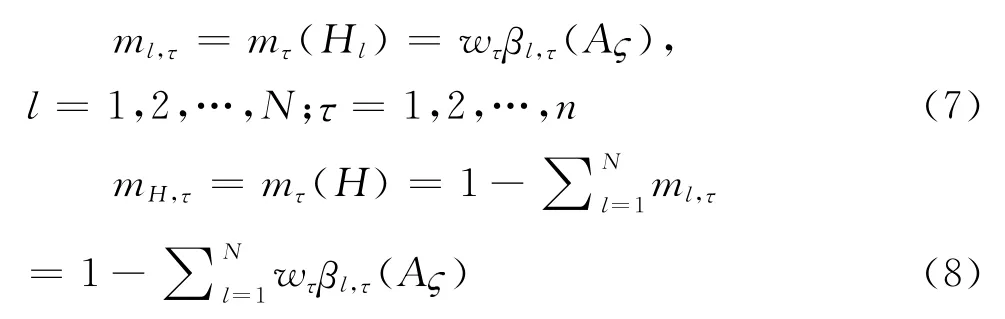
其次,依据上述获得的BPA 按照证据合成规则获得评价等级H l的综合概率分配函数。
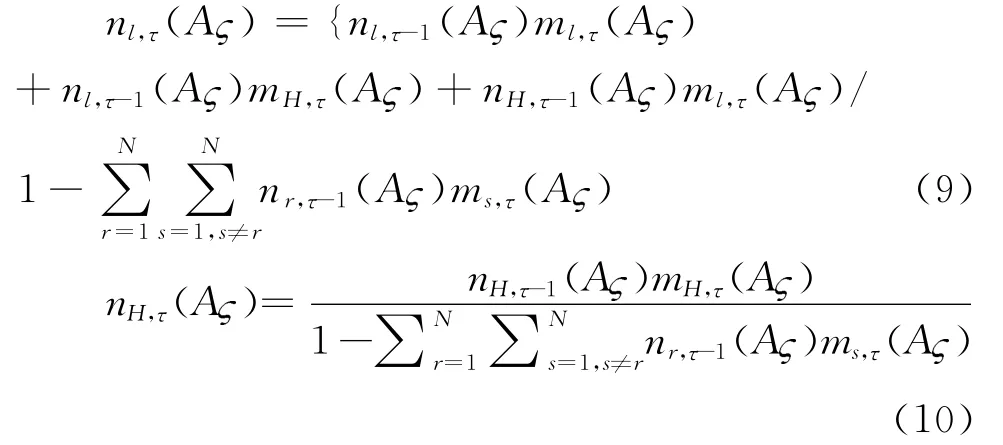
其中,nl,1(A)=ml,1(A),n H,1(A)=m H,1(A),l= 1,2,…,N, = 1,2,…,m,τ= 2,3,…,n.n l,τ(A)表示方案A前τ个属性下关于等级H l的综合BPA,n H,τ(A)表示剩余的综合BPA。
然后,计算A关于等级H l的信任度βl(A)。

其中,βH(A)是未知信息产生的信任度,即βH(A)= 1-并且1≤l≤N。
3 基于证据推理和广义Shapley值的扩展概率语言多属性群决策方法
在一个多属性群决策问题中,存在m个备选方案,即 {A1,A2,…,Am},d个 子 群 组 {G1,G2,…,Gd},依据n个属性 {C1,C2,…,Cn}对备选方案进行评价。每一个子群组中包含很多参与者,参与者在属性下对备选方案A进行评价,评价信息为子群组Ge中的个参与者给出的评价信息可以转化为扩展概率语言词集(p)。值得注意的是当子群组中参与者的信息经过汇总后,子群组Ge为一个整体可以视为一个专家Ge,因此,可视为专家Ge(e=1,2,…,d)给出扩展概率语言词集(p)。此后,将扩展概率语言词集(p)转化为标准扩展概率语言词集)。
3.1 基于灰色关联法的权重确定模型
在多数情况下,无论是专家权重还是属性权重都是部分未知或者完全未知的,这就需要建立适当的模型来进一步明确权重。由于灰色关联法是获得权重信息的有效工具,因此,本节基于灰色关联法分别给出计算专家权重(广义Shapley值)和属性权重(广义Shapley值)的方法。
(1)利用灰色关联法获得专家的广义Shapley值
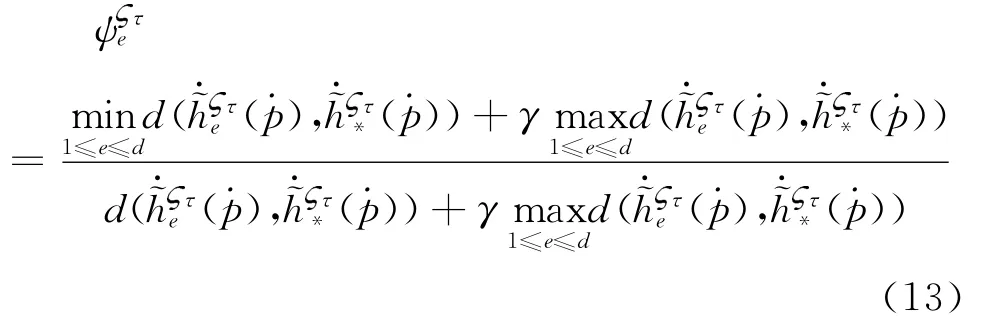
其中,γ=0.5为分辨系数。根据灰色关联法,建立一个非线性规划模型,从而获得相对于每一个属性下各个专家的Shapley值。
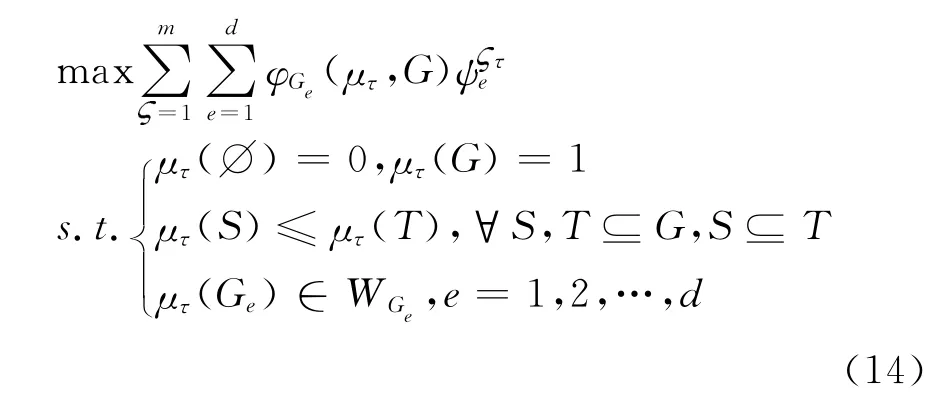
其中,φGe(μτ,G)是专家关于模糊测度μτ的Shapley值,W Ge是关于各个专家权重的范围。如果专家权重是完全未知的,则μτ(Ge)∈W Ge可以被省略。
(2)基于灰色关联系数获得属性广义Shapley值
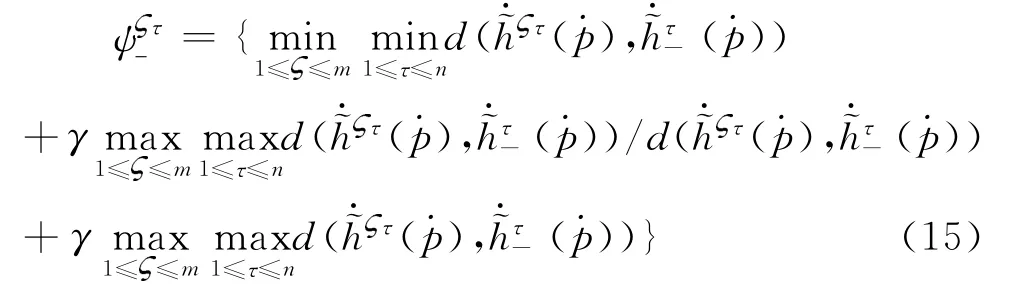
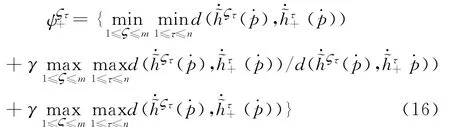
其中,γ=0.5为分辨系数。根据灰色关联法,建立非线性规划模型,从而获得属性的Shapley值。
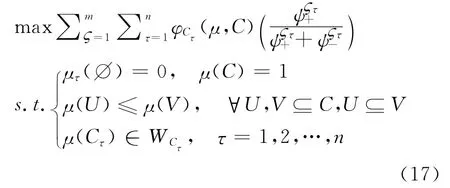
其中,φCτ(μ,C)为属性Cτ关于模糊测度μ的Shapley值,W Cτ为属性Cτ的权重范围。如果属性的权重是完全未知的,则限制条件μ(Cτ)∈,τ=1,2,…,n可省略。
3.2 多属性群决策方法具体步骤
为了解决上述多属性群决策问题,本节结合证据推理提出一种新的多属性群决策方法,具体步骤描述如下:
步骤一:由于实际决策中的属性存在成本型和效益型两种,为了消除不同量纲的影响,需将不同类型的属性转化为同一类型,即将成本型转换成效益型。简便起见,转换后的群决策矩阵仍表示为Y e=
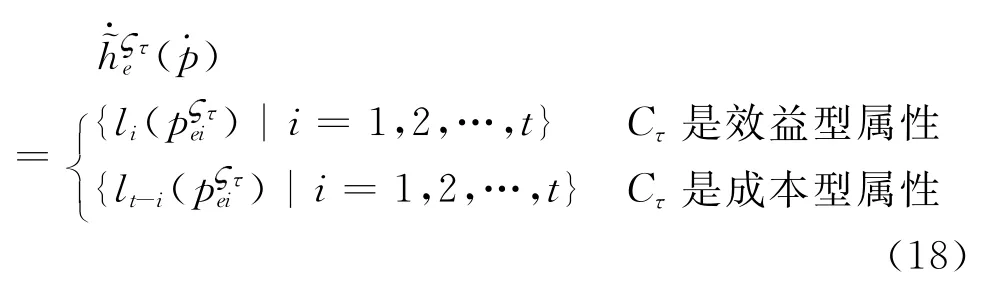
步骤二:依据广义Shapley值确定方法,确定各个专家子集的广义Shapley值。
步骤三:利用证据推理算法获得各个方案Aζ在每一个属性Cτ下的综合证据

其中,i=1,2,…,t;=1,2,…,m;τ=1,2,…,n;e=1,2,…,d。
(2)依据上述获得的BPA 按照证据合成规则获得综合概率分配函数。
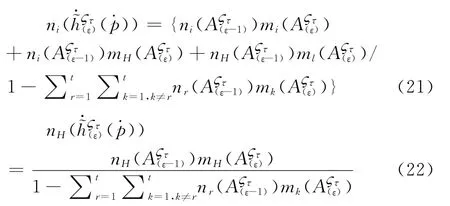
(3)计算ε个专家组针对方案Aζ在属性Cτ下关于评价等级l i的信任度
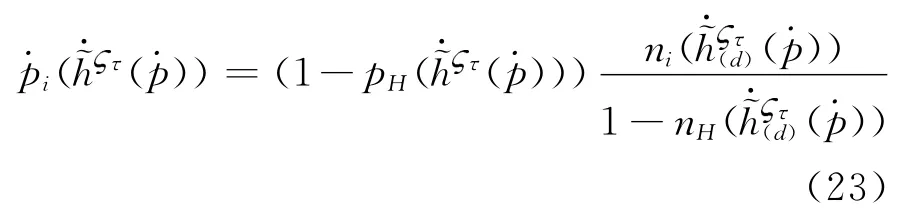

步骤四:依据广义Shapley值确定方法,确定各个属性子集的广义Shapley值。
步骤五:计算每一个方案A关于其他方案在属性Cτ(τ=1,2,…,n)下的收益-损失矩阵Dτ=。
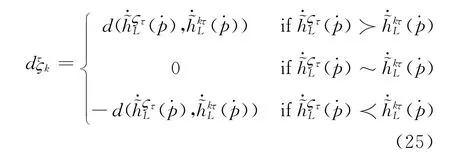
将属性Cτ下方案Aζ相对于方案A k的收益-损失值按照从小到大的顺序进行排序,从而得到2,…,m)按照从小到大顺序排在第τ个位置上的收益或损失值,其对应的属性为C(τ)。
步骤六:计算所有属性下方案A相较于方案Ak的优势度。
若方案A相较于方案Ak在属性C(1),C(2),…,C(q)下是损失的,则方案A相较于方案A k在属性C(1),C(2),…,C(q)下为 负 感 知 优 势 度,表 示 为。反之,如果方案A相较于方案A k在属性C(q+1),C(q+2),…,C(n)下是收益的,则方案A相较于方案A k在属性C(q+1),C(q+2),…,C(n)下为正感知优势度,表示为。具体公式如下所示:
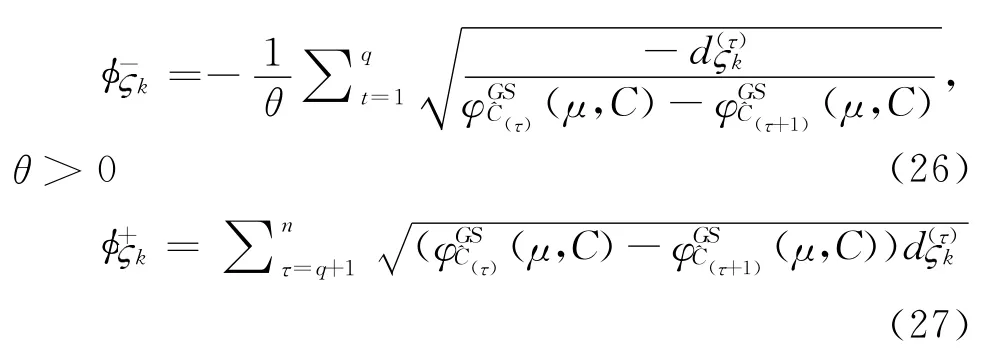
其中,θ为损失衰减系数,θ越小决策者的损失规避程度越 大。其中为属性关于模糊测度μ的广义Shapley值。
基于此,计算方案A相较于方案A k在所有属性下的个体感知优势度…,m。
步骤七:计算方案A的总体感知优势度,具体公式如下所示:
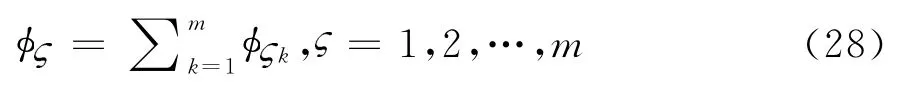
步骤八:计算方案A的标准化总体感知优势度,具体公式如下所示:

步骤九:依据前景值δ的大小对A(=1,2,…,m)进行排序,δ的值越大,相应的方案Aζ就越好。
4 算例分析
知名家居集团A 为了挑选最为适宜的产品供应商,贸易代表处的工作人员根据公司的采购理念评估供应商。其采购理念及对供应商的评估主要包括4个方面:持续的价格改进(C1);严格的供货表现(C2);质量好且健康的产品(C3);环保及社会责任(C4)。根据公司的采购需求和绿色供应商的要求,位于中国的贸易代表需要对分布在华南区、华中区和华北区的纺织品供应商进行详细调查。经初步筛选有4家供应商入选,即A1,A2,A3,A4,需要从中选择最符合公司需求的绿色供应商作为长期合作伙伴。贸易代表处分别从华北、华南、华中三个区域召集采购专员组成三个决策团队 {G1,G2,G3}依据绿色供应商评价的4项要求 {C1,C2,C3,C4}对4个备选供应商 {A1,A2,A3,A4}进行评价,各个团队中的采购专员从 {l1:很差,l2:差,l3:一般,l4:好,l5:很好}中选择恰当的语言词进行描述,由于知识的局限性,可以使用犹豫模糊语言词集(也可以不评价或者只给出一个语言词,这两种形式也是特殊的犹豫模糊语言词集)表示评价信息。通过对三个决策团队的初步了解,可以获知各个决策团队在4个评价要求下的权威性是不同的,因此分别给出三个决策团队在每一个评价要求下的权重,w G1= {[0.3,0.4],[0.3,0.5],[0.2,0.3],[0.2,0.3]};w G2={[0.2,0.3],[0.2,0.4],[0.2,0.3],[0.3,0.5]};w G3= {[0.2,0.4],[0.2,0.3],[0.3,0.4],[0.3,0.4]}。贸易代表处对4个评价要求的侧重也是不同的,因此分别给出4个评价要求 {C1,C2,C3,C4}的重要性程度(权重),即w C= {[0.3,0.4],[0.2,0.3],[0.2,0.4],[0.3,0.5]}。综合各个团队采购专员给出的评价信息可以获得三个扩展概率语言词集决策矩阵,如表1-表3(见附录),由于对信息进行了汇总,每个决策团队可以视为一个整体,三个扩展概率语言词集决策矩阵可以视为三个不同区域的专家 {G1,G2,G3}给出的。为了计算方便,将扩展概率语言词集决策矩阵转化为标准扩展概率语言词集决策矩阵,如表4-表6(见附录)。
因此,依据本文提出的多属性群决策方法的决策步骤,可获得如下结果:
步骤一:决策矩阵的规范化。由于此算例中4个属性都是效益型的,因此矩阵规范化可以省略。
步骤二:依据灰色关联分析模型计算属性下Cτ(τ=1,2,3,4)各个专家子集的广义Shapley值。
(2)计算Cτ(τ=1,2,3,4)下各专家子集的广义Shapley值

步骤三:计算方案A( =1,2,3,4)在属性Cτ(τ=1,2,3,4)下的综合证据。
由于这一步计算量较大,为简便起见,以三个专家Ge(e=1,2,3)对方案A1在属性C1的评价信息为例进行介绍。
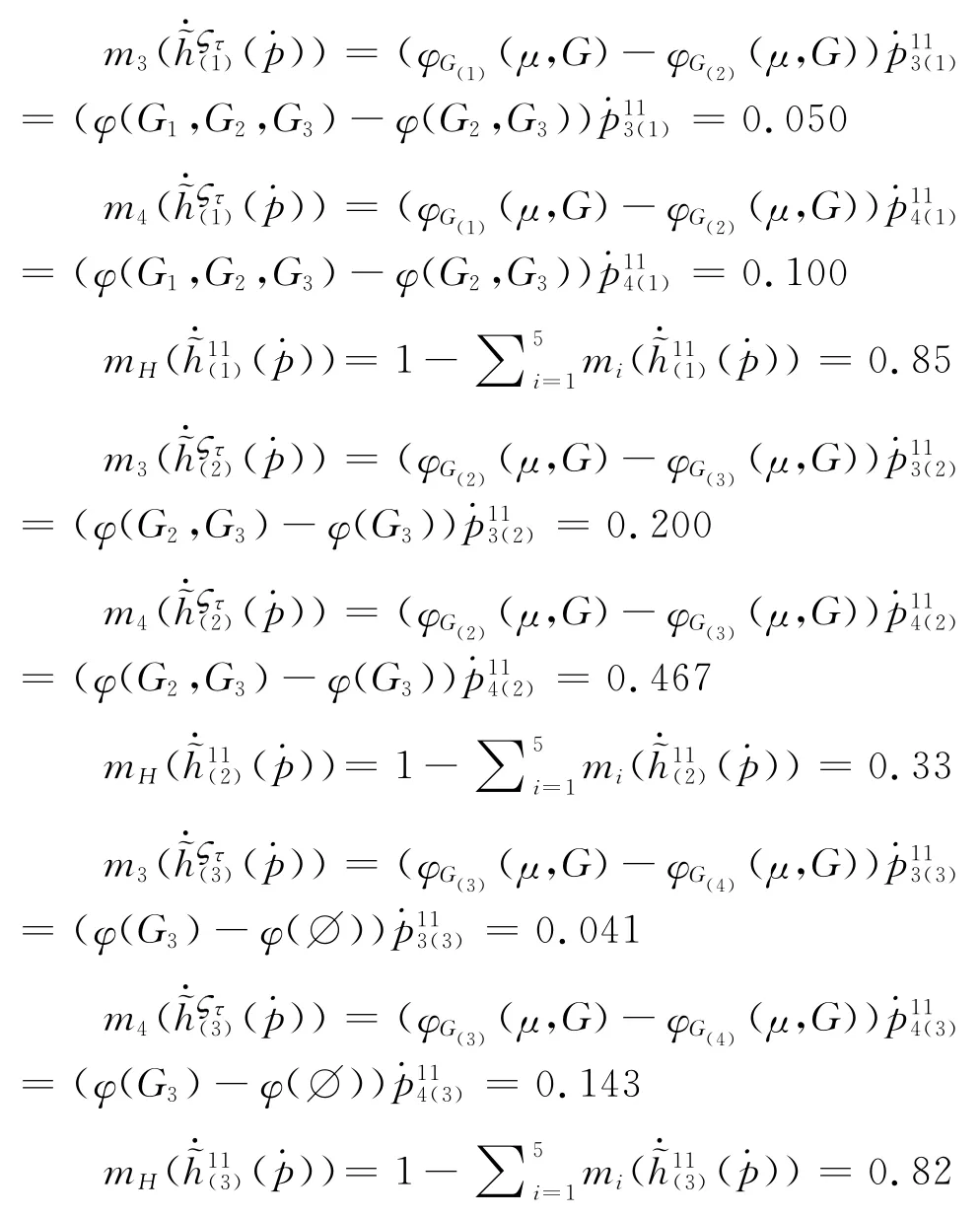
(2)其次,依据上述获得的BPA 按照证据合成规则获得综合概率分配函数。

(3)计算方案A1在属性C1下关于等级l i,i=1,2,3,4,5的信任度
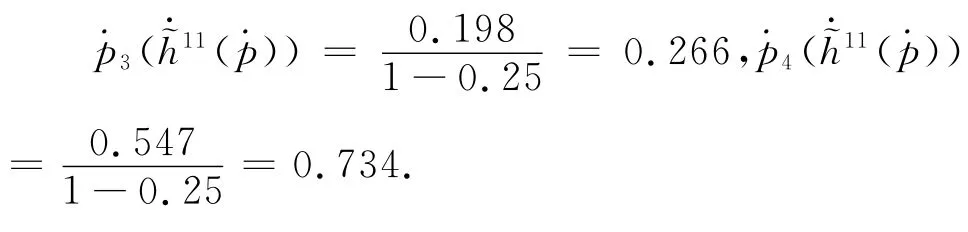
因此,将三个专家Ge(e=1,2,3)在属性C1对方案A1进行评价给出的信息进行合成,得到的结果表示为
同上所述,可以将3个专家给出的所有方案在各个属性下的评价信息按照上述方法合成,得到的综合评价信息如表7所示(见附件)。
步骤四:依据灰色关联分析模型计算属性子集的广义Shapley值。
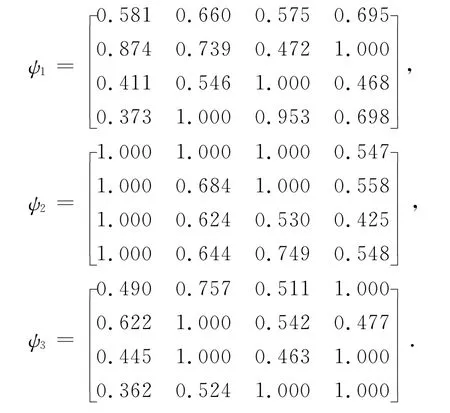
(1)计算灰色关联系数ψ-和ψ+
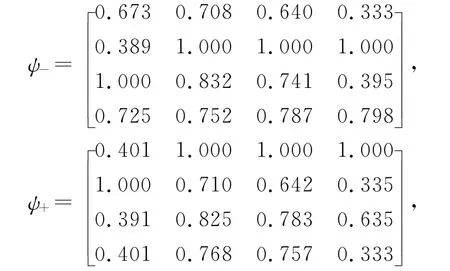
(2)计算属性子集的广义Shapley值

步骤五:计算方案A(=1,2,3,4)关于其他方案在属性Cτ(τ=1,2,3,4)下的收益-损失矩阵


步骤六:计算所有属性下方案A相较于方案A k的个体感知优势度矩阵φ= [φk4×4。
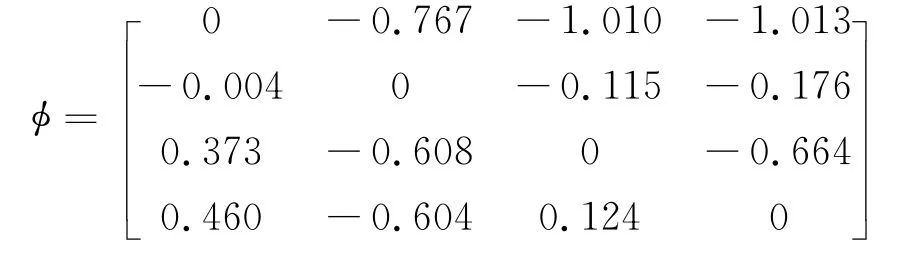
步骤七:依据所得的个体感知优势度计算方案A的总体感知优势度。
φ1=0.829,φ2=-1.979,φ3=-1.001,φ4=-1.854
步骤八:计算方案A的规范化总体感知优势度。
δ1=1,δ2=0,δ3=0.348,δ4=0.045
步骤九:按照δ大小,对备选绿色供应商排序。
由于δ1>δ3>δ4>δ2,可知A1≻A3≻A4≻A2。
4.1 参数敏感性分析
由于本文提出的方法是一种包含参数的决策方法,为了分析参数对决策结果的影响,即决策结果是否会随着参数值的变化而发生变化,因此对参数(损失衰减系数)进行敏感性分析。当θ<1,损失的影响增加;当θ>1,损失的影响减少。Kahneman和Tversky认为θ应 介 于1 和2.5 之 间[18]。 因 此,θ从(0,2.5]之间取值,分析决策结果的变化,变化趋势如图1所示。

表8 不同损失衰减系数对应的排序结果

图1 不同参数对应的排序结果变化图
从表8和图1可以发现,随着损失衰减系数由0.25变化到2.5,备选方案的排序结果是一致的,没有发生变化。这说明备选方案的最终排序结果对参数θ的取值并不敏感。
4.2 对比分析
为了进一步说明本文提出方法的有效性和优越性,选取其他几种方法与本文方法所得结果进行对比。由于概率语言词集是扩展概率语言词集的特例,因此选取Liu 等提出的PL-TODIM 方法[19](简称方法一),Zhang提出的方法(简称方法二)[20]来对本文的算例进行分析。按照方法一和方法二的决策步骤,可以得到方案的排序,具体结果如下表所示:

表9 不同方法的排序结果
从表9可以发现,本文提出方法所得结果与方法一和方法二所得结果有些许差别,即由A4≻A2变为A2≻A4。主要原因是在此算例中属性间是存在关联关系的,并且属性间的关联关系是不同的,可以通过模糊测度具体体现出来:μ(C1)+μ(C2)>μ(C1,C2),表示属性C1和属性C2间存在冗余关系;μ(C2)+μ(C3)<μ(C2,C3),表示属性C2和属性C3间存在互补关系;μ(C3)+μ(C4)>μ(C3,C4),表示属性C3和C4间存在冗余关系;μ(C1,C2)+μ(C3)<μ(C1,C2,C3),即属性集 {C1,C2}与属性C3间存在互补关系;μ(C1,C2,C3)+μ(C4)>μ(C1,C2,C3,C4),即属性集 {C1,C2,C3}与属性C4间存在冗余关系。由于方法一和方法二未考虑这种复杂属性关系,因此,这两种方法的排序结果与本文的方法略有不同,这也说明本文所提方法在处理此类问题的优越性。
因为方法一和方法二能够处理专家/属性独立的决策问题,为了证明本文提出的方法同样适于处理独立的决策问题。接下来,对上述算例进行少许改变,假设专家间是独立的,属性间是不相关的,专家权重分别为ω1=1/3,ω2=1/3,ω3=1/3,属性权重为w1=0.3,w2=0.2,w3=0.2,w4=0.3,评价信息和上述算例一致,因此采用上述三种方法分别对方案进行排序,得到的结果如表10所示。

表10 不同方法的排序结果
从表10可知,三种方法的排序结果是一致的,即A1≻A3≻A2≻A4。因为方法一和方法二擅长处理独立的情况,相同排序结果间接说明本文所提方法能够处理独立的情况。综合表9和表10能够说明,本文提出的方法相较于方法一和方法二具有更广泛的适用范围,既能处理关联情形下的多属性群决策问题又能处理独立情形下的群决策问题。此外,本文提出的方法是基于扩展概率语言词集,扩展概率语言词集是不确定语言变量、扩展犹豫模糊语言词集、分布语言评估信息、概率语言词集等信息表示模型的广义形式,因此本文提出方法同样适合于处理不确定语言信息、扩展犹豫模糊语言集、分布语言评估信息、概率语言词集环境下的多属性群决策问题。
5 结语
本文借用证据推理在融合不精确、不确定、不完全甚至冲突信息方面的优势,利用证据推理算法去处理扩展概率语言信息,对来自不同专家的评价信息进行有效集成,从而将多属性群决策问题退化为多属性决策问题,从而利用扩展广义Shapley-TODIM 方法对备选方案进行排序。因此,本文首先定义了扩展概率语言词集的定义及相关理论,奠定了本文的理论基础。其次,提出一种基于证据推理的扩展概率语言多属性群决策方法。在提出群决策方法的过程中,考虑到多数实际问题中决策团队间和属性间可能分别存在交互作用,将灰色关联系数和广义Shapley值相结合,给出了确定专家子集和属性子集广义Shapley值的数学规划模型。并利用专家子集广义Shapley值的差值来替代专家权重,从而对证据推理进行了扩充,促使证据推理能够处理各种交互情形。此外,为了验证本文提出方法的实用性,采用绿色供应商选择的算例进行分析,并对决策方法中存在的参数进行分析,检验损失衰减系数对决策结果的影响。为了进一步说明本文提出方法的优点,从已有决策方法中选择几个典型方法并与本文提出的方法进行对比分析。
附录:

表1 华北决策团队(专家G1 )的扩展概率语言词集决策矩阵

表2 华南决策团队(专家G2 )的扩展概率语言词集决策矩阵

表3 华中决策团队(专家G3 )的扩展概率语言词集决策矩阵

表4 专家G 1 的标准扩展概率语言词集决策矩阵

表5 专家G 2 的标准扩展概率语言词集决策矩阵

表6 专家G 3 的标准扩展概率语言词集决策矩阵

表7 综合评价信息矩阵
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
纺织科学研究(2021年9期)2021-10-14
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
决策(2018年8期)2018-12-10
决策(2018年11期)2018-11-28
小天使·四年级语数英综合(2018年1期)2018-07-04
幼儿智力世界(2016年6期)2016-05-14
祝你幸福·知心(2016年3期)2016-03-29
