
基于深度学习的癫痫发作预测方法研究
2020-01-13 08:19闵腾飞臧天仪
智能计算机与应用 2020年1期
闵腾飞, 臧天仪
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
0 引 言
癫痫是一种长期性的神经系统疾病,病症发作时癫痫抽搐,俗称羊角风。目前癫痫疾病不能治愈,对于多数患者,抽搐发作可由足够剂量的药物控制;如果药物无法控制,只能通过外科手术切除引起癫痫的组织。但是仍有许多患者虽已接受了最好的治疗方法,却还会面临间发性的癫痫抽搐发作病症。即使癫痫发作不会经常发生,也将导致癫痫患者由于可能发生的癫痫发作而经历持续的焦虑[1]。
通常,癫痫可由连续的脑电图监测确诊,但以前脑电图只能在住院治疗的环境下才能获得。近些年来,随着便携式脑电图系统的推出,脑电图记录变得非常普遍。然而,患者虽然获得了与住院治疗监控一样的脑电图,但如何利用记录的大量脑电图在癫痫发作之前提供可靠的预警信号成为非常有价值的研究问题[2]。
越来越多的人认识到,通过采用癫痫发作预警的闭环治疗策略,可以在一定程度上控制癫痫的发作[3]。早期癫痫发作预警系统还可以帮助患者寻求安全的环境,提醒患者避免驾驶或游泳等潜在的危险活动,从而降低伤害风险以及由看似不可预测的癫痫发作导致的无助感。通过这种早期癫痫发作自动预警系统,可以以速效药的形式触发药物干预,只有在需要预防即将出现的癫痫发作时才可以使用药物,从而减少总体副作用[4]。为了使基于EEG的癫痫发作预警系统能够有效地运行与工作,利用预测算法可靠地识别癫痫发作可能性增加的时期则将尤其显出其现实关键研究意义。
随着近些年数据量的急剧增长,计算机硬件设备GPU、CPU、存储设备的快速发展,以及现实世界中实际问题与日俱增的精度和复杂度的需求,深度学习持续成功地应用于越来越广泛的实际问题中。在许多计算机应用领域,如计算机视觉、语音和音频处理、自然语言处理、计算机技术、生物信息学和化学、电子游戏、搜索引擎和推荐、网络广告和金融,深度学习方法都取得了进步与突破[5]。
因此,利用深度学习方法分析处理巨量的脑电波数据是非常值得尝试的研究方向。本文的研究内容是把深度学习模型应用于癫痫发作预测问题上,探索基于深度学习的癫痫发作预测算法的设计,以及仿真测试其最终实验效果。
经过国内外文献调研发现,有不少研究学者基于深度学习方法已相继发表了不同的癫痫检测算法。例如Vidyaratne等人[6]提出了深度双向递归神经网络方法进行癫痫发作检测。Turner等人[7]提出利用深度信念网分层学习方法分析高分辨率多通道脑电图数据来检测癫痫发作。Ye等人[8]利用快速傅里叶变换预处理脑电波(EGG)提取多个特征利用深度学习方法进行癫痫发作检测。
本文采用Kaggle上美国癫痫协会癫痫预测竞赛的数据集及评估模型的标准,应用线性判别分析作为基线模型,提出基于CNN和GRU的深度学习模型解决癫痫预测问题。另外在此竞赛最后提交的结果中,并没有找到基于递归神经网络的模型,然而前人的不少研究表明,递归神经网络区分EGG数据片段是有效的;因而探索递归网络对癫痫预测问题是否有效是很有必要的。为此,本文将展开研究论述如下。
1 模型
1.1 线性判别分析
线性判别分析(Linear Discriminant Analysis,LDA),是一种监督学习方法。其原理是将给定的数据集投影到一条直线上,使得同类之间的距离尽可能地小,不同类之间的距离尽可能地大。
一种良好的投影方式就是利用不同类别的数据的中心来代表这类样本在空间中的位置。考虑一个两分类问题,两类的均值向量为:
(1)
同时保证让投影之后的中心距离尽可能地大,也就是:
(2)
尽可能大,其中,
(3)

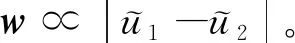
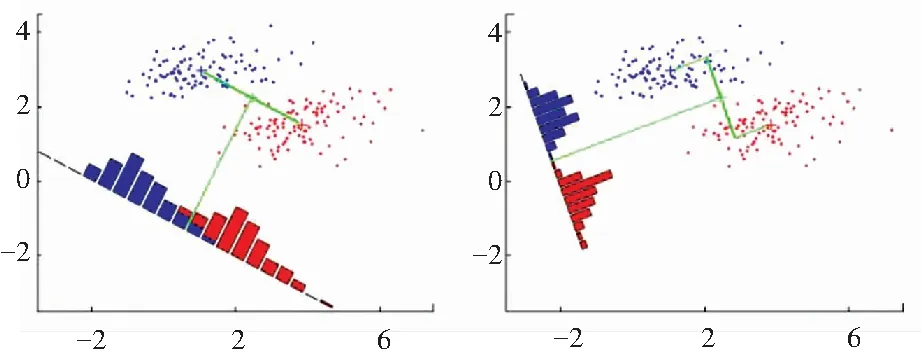
图1 LDA最大化问题
左图为最大间隔度量的降维结果,从图1中可以看出在原始数据空间,2类数据可以被完美分开,但是以2类数据的均值连线的垂直方向投影,会产生一定程度的重叠。因此,Fisher提出的LDA的优化目标为:最大化一个函数,这个函数能够让类均值的投影分开得较大,同时让每个类别内部的方差较小,从而最小化了类别的重叠(图1中右的结果)。这也是LDA的中心思想,即:最大化类间距离,最小化类内距离。
1.2 卷积神经网络
卷积神经网络的基础结构如图2所示。从图2中可以看出,二维矩阵或者三维矩阵作为输入数据送入卷积神经网络,通过卷积神经网络的卷积和池化自动提取数据特征,再用全连接层和Softmax进行分类[5]。卷积层和池化层的输出代表了输入传感器数据的高级特征,全连接层的目的就是用这些特征进行分类。全连接层(Fully Connected Layer)通常使用softmax激活函数作为输出层的多层感知机(Multi-Layer Perceptron), Softmax函数把任意实值的向量转变成元素取值0-1、且和为1的向量。
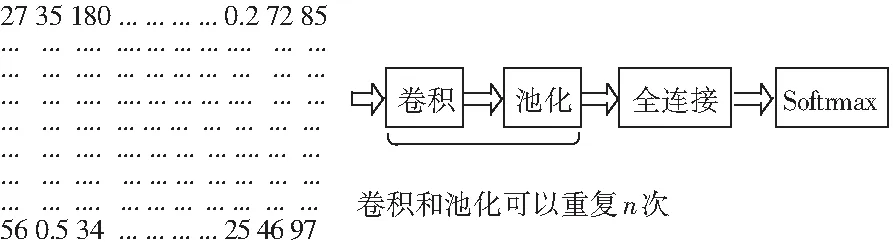
图2 卷积网络的基本结构
卷积和池化提取高维度的数据特征主要依靠4个特性,分别为:局部连接、权值共享、非线性、池化。如图3所示,图3中左侧表示卷积网络的局部连接的特性,输入数据为6*6的矩阵,利用3*3的卷积核经过步长为1的移动后,提取特征获得4*4的特征图。图3中右侧表示每次当卷积核扫描到神经网络的神经元时,每个神经网络边上的权值和偏移量是共享的。卷积网络的非线性就是在每个卷积操作之后,都有一个ReLU的附加操作。ReLU的全称是纠正线性单元(Rectified Linear Unit)。ReLU是以像素为单位生效的,可将所有负值像素替换为0。池化,也称为下采样,降低了每个特征映射的维度,但是保留了最重要的信息。池化可以有多种形式:最大(Max)、平均(Average)、求和(Sum)等等。目前,最大池化用得最多、也最广泛。池化的功能在于逐步减少输入特征的空间尺寸,从而减少网络中的参数与计算数量,并抑制过拟合[5]。

图3 卷积网络的局部连接和权值共享
Fig. 3 Local connection and weight sharing of Convolutional Neural Network
1.3 递归神经网络
如图4所示,左侧是时间维度展开前,回路方式表达方式的递归神经网络,其中x表示输入层,s表示隐藏层,o表示输出层。右侧为按照时间线展开后,可以看到当前时刻的St并不仅仅取决于当前时刻的输入xt,同时与上一时刻的St-1也存在某种相关,St同样也由xt经U的变化后的信息决定,此外这里包含另一份信息W·St-1,该信息是从上一时刻的隐藏状态St-1经过一个不同的W变换后得出的。递归神经网络(RNN)的计算公式为:
St=f(U·xt+W·St-1),Ot=g(V·St),
(4)
其中,f与g表示神经网络的激活函数。
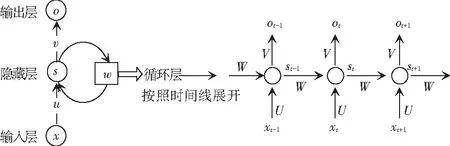
图4 递归神经网络(RNN)基本结构
但是普通的RNN结构却很难以传递相隔较远的信息。例如图4中的部分,研究只考虑黑色箭头的线性的传递过程,不考虑非线性部分,由此就会将式(4)简化为:
St=W·St-1,
(5)
如果将起始时刻的隐藏状态信息S0向t时刻传递,就会得到式(6):
St=Wt·S0,
(6)
此时,当W<1时,不断相乘的结果是Wt向0衰减;当W>1时,不断相乘的结果是Wt向∞扩增,导致S0中的信息会被覆盖掉,无法向t时刻传递。尤其对于某些复杂的问题,可能需要更早的一些信息,甚至是时间序列的初始的信息,但间隔太远的输入信息,RNN是难以记忆的[5]。因此,递归神经网络需要通过门(gates)控制,使不断相乘的梯度保持在接近1的数值是非常重要的。
如图5所示,LSTM的内部结构相比RNN更复杂,设计上包括了4层神经网络,其中小圆圈是point-wise的操作,比如向量加法、点乘等,而小矩形表示一层可学习参数的神经网络。LSTM单元上面的那条直线表示了LSTM的状态state,并且会贯穿所有串联在一起的LSTM单元,从第一个LSTM单元一直流向最后一个LSTM单元。状态state在这条通道中传递时,LSTM单元可以对其添加或删除信息,相应的对信息流的修改操作由LSTM中的gates控制。这些gates中包含了一个Sigmoid层和一个向量点乘的操作,继而研究可知Sigmoid层的输出是0~1之间的值,该值将直接控制信息传递的比例。因此在LSTM中,网络首先构建了3个gates,即(it,ft,Ot)来控制信息的流通量。对此设计可分述如下。

图5 递归神经网络(RNN)与长短时记忆网络(LSTM)基本结构
Fig. 5 The basic structure of Recurrent Neural Network (RNN) and long short term memory network(LSTM)
(1)输入门it:控制有多少信息可以流入memory cell,即如下方公式(10)求得的Ct。
(2)遗忘门ft:控制有多少上一时刻的memory cell中的信息可以累积到当前时刻的memory cell中。
(3)输出门Ot:控制有多少当前时刻的memory cell中的信息可以流入当前隐藏状态ht中。
研究中拟将用到的数学公式可表述如下:
it=Sigmoid(WxiXt+Whiht-1+bi);
(7)
ft=Sigmoid(WxfXt+Whfht-1+bf);
(8)
Ot=Sigmoid(WxoXt+Whoht-1+bo);
(9)
Ct=ft*Ct-1+it*tanh(WxcXt+Whcht-1+bc);
(10)
St=Ot*tanh(Ct).
(11)
但LSTM也因为引入了很多内容,使得参数增多,训练难度也因此加大了很多。故而很多时候研究中常会使用效果与LSTM相当、但参数更少的GRU来构建大训练量的模型。对此可解析得到如下数学公式:
zt=σ(Wz·[ht-1,xt]);
(12)
rt=σ(Wr·[ht-1,xt]);
(13)
(14)
(15)
如图6所示,首先是GRU的2个门,分别是update gate(zt)和reset gate(rt),计算方法和LSTM中门的计算方法一致,方法公式具体如下:
zt=σ(Wz·[ht-1,xt]),
(16)
rt=σ(Wr·[ht-1,xt]).
(17)
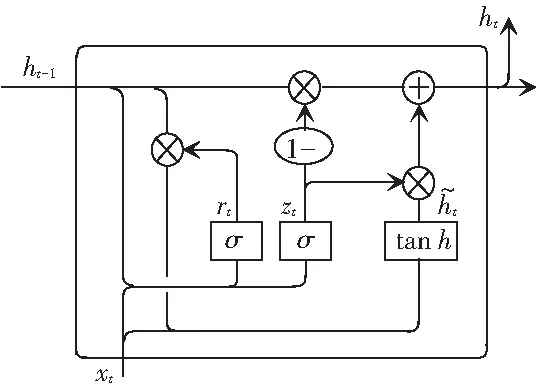
图6 门控循环单元(GRU)基本结构
(18)

2 实 验
2.1 数据集
Kaggle竞赛美国癫痫协会癫痫预测竞赛的颅内脑电图(iEEG)记录,采集自5条患有癫痫症的狗和2个接受iEEG 监测的人。狗的iEEG 记录以400 Hz通过16个电极采样得到,记录每组电极电压组的平均值。这些iEEG数据记录有的延至数月,有的长达一年,并且在一些狗的记录中有多达100次的癫痫发作。研究中基于植入装置(A)的癫痫警告系统如图7所示。通过植入装置(A),获得16个电极上的iEEG数据(B);并将数据无线传输到个人警告系统设备上;个人警告系统设备将其存储在闪存驱动器中,再通过互联网每周上传到中央数据存储服务器上。(C)展示了癫痫发作的时间和阈值分布,该阈值定义了癫痫发作概率增加时期(发作前状态)。当预测的概率超过定义的阈值时,会触发警告[9]。

图7 患癫痫病犬的癫痫发作预警系统
除了狗的数据外,此次竞赛数据集还包括有,2位人类癫痫患者少于一周的颅内脑电图监测,其以5 000Hz频率进行采样,记录的电压来自大脑外部的电极的电压值。
众所周知,癫痫发作会聚集在一起,或者以组的形式出现。通常具有癫痫发作集群的患者从预测后续癫痫发作中获益甚微,而区分出癫痫发作前状态,就能为患者做出及时预警以及适当治疗。此竞赛的挑战是区分前1 h的10 min长的数据片段和发作间活动的10 min iEEG片段。在这次竞赛中,定义癫痫发作前为癫痫发作开始前的4 h,发作间为任何癫痫发作之前或之后至少4 h[10]。
数据集中每条数据为10 min长的EGG时序数据片段,来自癫痫对象的发作前或者发作后时期。训练数据中1 h的数据片段将按照编号顺序存储,测试数据片段则是随机的。如图8所示,1 h发作前片段定义为癫痫发作前1:05至0:05,这即确保了可以预测癫痫发作时间足够长,以允许快速作用下优选用药。

图8 癫痫发作前1 h的5个电极上的EEG信号
Fig. 8 EEG signals on 5 electrodes which are 1 hour before seizure
2.2 数据预处理
对于每一个10 min的EGG脑电图数据片段,一些特定的特征从每个电极上的时域电压值中提取。主要的提取数据特征方法可参考文献[9,11],方法步骤详见如下。
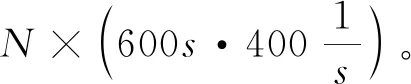
(2)过滤。使用巴特沃斯带通滤波器过滤掉低频(小于0.1 Hz)和高频(高于180 Hz)的采样点数据。这一步可运用scipy包中的signal模块的butter和lfilter来实现。
(3)离散傅里叶变换(DFT)。:每10 min的数据片段被分割为20个不重叠的30 s的小片段,每个小片段应用离散傅里叶变换从时域信号变成频域信号。傅里叶变换的公式为:
(19)
(4)划分频率带。每个10 min的数据片段被分割成20个小片段的频域信号后,把频域从0.1 Hz至180 Hz划分为8个互不相交的频率带,这些区间分别是:delta(0.1 Hz~4 Hz)、theta(4 Hz~8 Hz)、alpha(8 Hz~12 Hz)、beta(12 Hz~30 Hz)、low-gamma-0(30 Hz~50 Hz)、low-gamma-1(50 Hz~70 Hz)、high-gamma-0(70 Hz~100 Hz)、high-gamma-1(100 Hz~180 Hz)。

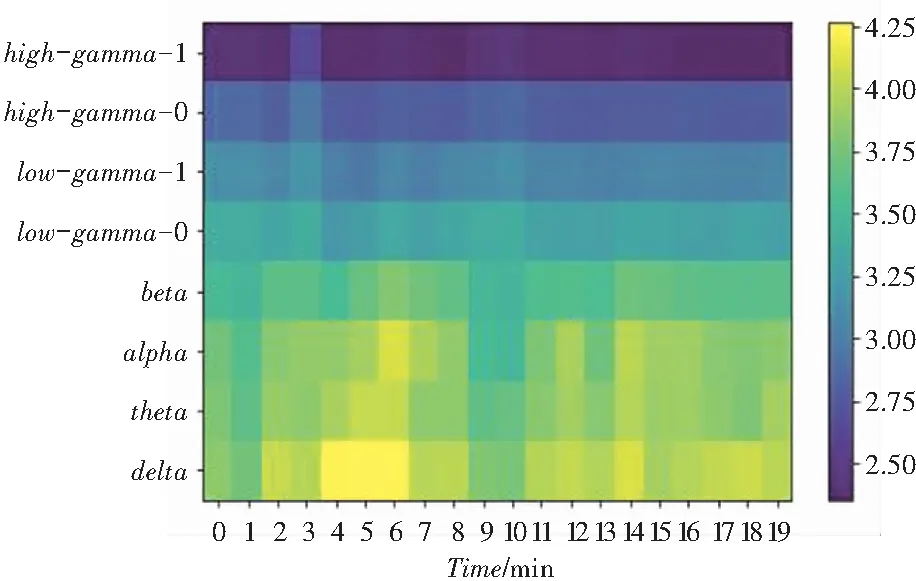
图9 数据预处理后的幅度谱
(5)正则化。本实验一共有2种标准化方法,一种是把每个数据片段上每个电极的频率谱上8×20特征矩阵压缩成一维,进行标准化;另一种是把每个8×20的频率谱特征矩阵,视为20个样例的8个特征,开始对这20个长度为8的向量进行标准化。这2种标准化中,前者考虑到了特征在时域和频域的位置,而后者没有考虑时域。
综合前述的数据预处理步骤提取信息,数据集大小从最开始竞赛提供的总共111 G,增长至当下191 M的数据量,从而为后续实验减少了许多训练模型的时间。
2.3 评估标准
本文的实验任务是区分出测试集中给定的数据片段是属于发作前、还是属于发作中。由于癫痫病的特性,癫痫发作间隔时间长,即使得数据集中属于发作中的片段占据了大多数。对此,研究使用ROC曲线下的面积AUC来评估,并且是在所有7个对象测试数据集的预测概率的ROC曲线下的面积AUC来评估各模型的运行性能,而这同时也是竞赛的评判打分排名标准。
2.4 基于线性判别分析的方法
基于线性判别分析的方法,在数据预处理中与2.2节探讨的不同之处就在于,窗口大小为60 s,步长为30 s,这样10 min的数据被划分成了19个60 s的有重叠的小片段数据,那么每个60 s的片段共有N×8个数据特征,其中N代表电极的数目。模型结构如图10所示,模型用所有片段的19个小片段进行线性判别分析训练,选取这19个小片段的预测平均值作为整个片段的预测值,在如前描述的数据预处理条件下,研究得到了最好的结果是整体的AUC为0.747 66。

图10 基于LDA的预测模型
2.5 基于CNN的方法
在EGG数据采集的过程中,由于脑电信号非常不平稳,在整个10 min的片段中或许并不存在发作前活动的迹象。这可能是因为发作前特征出现在片段的开头或者最后,也有可能发作前的癫痫患者许多位置的电极和平常一样,根本没有癫痫预警症状。为了使本文设计的模型尽可能多地掌握患者脑部各处电压的异样,研究考虑先合并所有电极上的处理后的频域信息,而后合并不同时间片段的信息。研究中可通过卷积神经网络实现这一设计。设计的网络通过时间执行一维卷积,从而分别从每个时间片段中提取相同类型的特征,继而在较高层中跨时间轴来组合有关信息。此外,在Mirowski等人[12]的研究中提出脑电图各电极上的信息之间的关系对癫痫的预测非常重要;在此竞赛中也有不少参赛者,把这个特征扩展到了各自的数据集中。在本文研发的网络中,研究旨在运用第一个卷积层中的滤波器在相同的时间片段内看到所有电极上的数据特征信息,这样可使其学习彼此之间的互相关关系。基于此,下面将给出本文网络结构设计详述如下。
如图11所示,研究把数据分成了20个小片段以及8个频率带,其第一层卷积C1在相同时间帧上的所有电极的频带上执行卷积,第一层为16个过滤器的大小为(8·N)×1的卷积核,一共有(16·8·N+16)个参数。通过第一层得到了16×20的矩阵;第二层卷积C2是32个过滤器大小为16×12的卷积核,一共有(32·16·12+32)=6 176个参数;第三层是全连接层F3,通过2个卷积层提取32×9的特征矩阵与F3的512个神经元全连接,把所有特征信息提取到512个神经单元中用来分类,共32×9×512+512=147 968个参数;最后一层是一个逻辑回归单元。由此计算可得模型的总参数共有15万个,巨量的参数给后续模型的参数寻找带来了很大的困难,因此必须尽可能在此结构上加以优化,从而降低模型的参数总量。
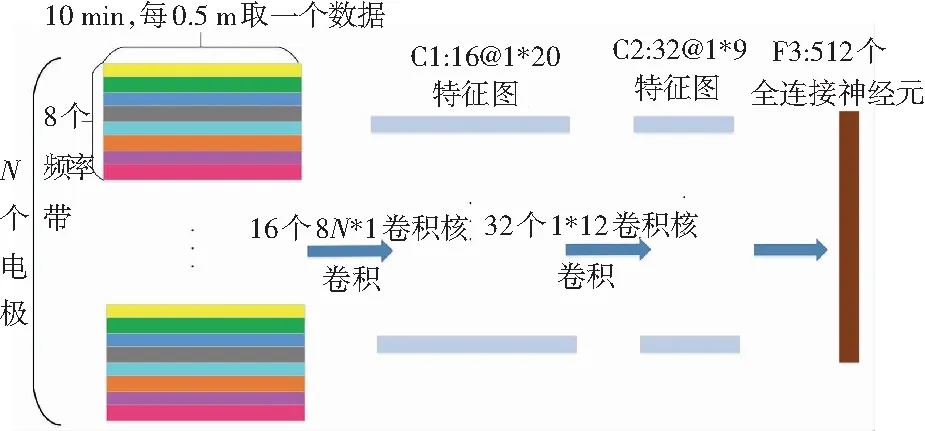
图11 基于CNN的模型
为了减少参数的数量,研究即在C2与F3直接引入全连接池化层GP3,如图12所示,池化层在C2层得到的1×9矩阵上计算了均值、最大、最小、方差、L2正则化值、几何平均值,这样得到32个1×6的矩阵与具有512个单元的全连接层连接。如此一来池化层和全连接层只有(192·512+512)=98 816个。由于加入的池化层,参数在数目上就大约减少了5万个。
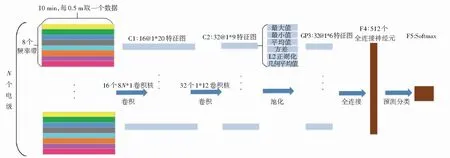
图12 卷积和池化的CNN模型
研究中又设置了不同的数据预处理参数,并对预测的原始结果,分别进行了Softmax、minmax、median标准化,应用此模型得到的结果见表1。
表1 不同数据预处理参数下模型的结果
Tab. 1 Results of the model under different data preprocessing parameters

数据AUCSoftmax AUCMinmax AUCMedian AUC6频率带30 s窗口0.770 60.770 70.781 10.769 56频率带120 s窗口0.763 20.786 00.775 20.753 48频率带30 s窗口0.766 80.743 70.773 70.780 8
由表1可以看出,经过如上的标准化处理对最终的预测结果有一定的修正,但是尚未确定哪种标准化处理会得到比原始预测更好的收益;同时,也可以看出本模型效果明显超出基线模型大约3%左右,并且最好的结果能在504个队伍的竞赛排行榜上取得排名第11位的成绩,可以说基于卷积深度学习方法对于癫痫前期症状的预测是有用的。
2.6 基于RNN的方法
脑电波(EGG)原始数据是时序的,可以直接利用RNN网络的持续性和记忆性特点直接处理,但通过前面提及的预处理步骤将使所得的信息既有时间特性、又有频率大小的位置特性,因此本次研究拟尝试运用卷积神经网络解决发作前预测问题。
首先,研究对数据应用基础的RNN、LSTM、GRU模型,探索其性能,其中GRU结构如图13所示,输入数据先通过一层20个节点的GRU单元,其上各单元以0.2随机失活,再全连接到一个逻辑回归单元上输出预测值。在其它基础的递归神经网络模型的结构中只有第一层的GRU不同,分别为LSTM、SimpleRNN。

图13 简单的GRU模型
这些简单模型在频率带为8,窗口长度为30 s,步长为30 s数据预处理设置下,得到的结果见表2。
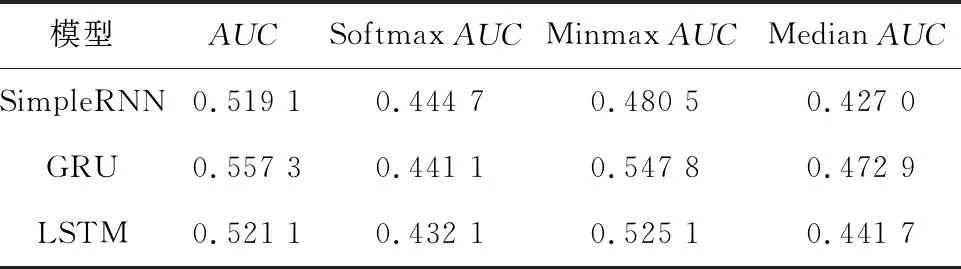
表2 不同RNN模型的结果
由表2可知,此时得到的结果远远低于LDA的基线模型,甚至比随机猜得的效果更差。这一仿真结果表明:虽然基于RNN的方法在癫痫发作片段的诊断上效果明显,但在预测发作前片段的任务上,效果并不好。
3 结论与展望
本文以LDA为基线模型,探索了基于CNN和RNN的模型,对 EGG数据预测癫痫发作前状态概率的问题进行了实验性的研究。本文发现EGG数据从时域信号转换到频率信号后,利用卷积神经网络提取整合特征的能力,能较成功地预测癫痫发作前的数据片段。虽然基于RNN的模型在EGG数据片段属于癫痫发作、非癫痫发作和健康人的分类问题上得到了好的效果,但在癫痫发作前的预测问题上效果并未臻至理想,当然这也许是本文的RNN实验模型偏于基础简单,参数设置或者数据预处理也有待进一步改善的原因。后续工作可以考虑直接对原始的EGG数据,按照电极上采样数据量平均划分为n个时间步,以每个时间步的采样数据作为RNN的输入,或许在这样的情况下RNN就能提取出有效的特征信息。
4 结束语
本文讨论了癫痫发作前片段预测任务的背景及意义,并基于具体的数据集说明了任务评估标准。研究即以LDA为基线模型,探讨了基本RNN模型对此任务的有效性,并提出了基于CNN模型的深度学习方法,较为成功地对癫痫发作前片段进行了预测。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
癫痫与神经电生理学杂志(2022年2期)2022-06-07
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康必读·下旬刊(2019年8期)2019-08-16
家庭百事通·健康一点通(2017年11期)2017-11-29
饮食科学(2017年5期)2017-05-20
家庭医药(2016年8期)2016-09-28
意林(2013年15期)2013-05-14
