
基于多尺度的n-grams特征选择加权及匹配算法
2020-01-13 07:48刘世兴
智能计算机与应用 2020年1期
刘世兴
(辽宁机电职业技术学院 信息工程系, 辽宁 丹东 118009)
0 引 言
n-grams语言模型的基本思想是将文本按照词汇大小为n的滑动窗口进行操作,形成长度为n的词汇片段序列,具有拼写容错能力强、语种无关性[1-2]、不需词典规则[3]及特征维度低[4]等优点,因而广泛应用于大数据及人工智能领域,如:文本分类[5-6]、聚类[7]、拼音校验[8]、预测[9]、机器翻译[10]、语音识别[11]、情感分析[12]及恶意软件检测[13]等。
作为n-grams语言模型的应用前提,其选择、加权及匹配算法一直是研究人员关注的重点。Maipradit等人[14]提出一种基于逆文本频率的n-grams特征选择算法,用于解决情感分类问题。该算法仅注重特征的选择,没有加权过程,分类性能提升幅度较小。Zhou等人[15]将n-grams模型进行重构,以解决特征选择及加权问题。但重构后的n-grams特征语义结构遭到破坏,减少了原有特征包含的文本信息。Hwang等人[16]将n-grams特征的长度扩大到5,用于长文本及海量文本的分类。但该方法只能用于特定文本,在中、短文本中,5-grams特征会产生更多的稀疏数据。
为优化n-grams特征的选择、加权及匹配算法,在不破坏n-grams结构的前提下,增强n-grams特征的权值区分度,减少稀疏数据的产生,本文以词性、语义及词汇的内在偏序关系为基础,提出利用词性的类分布和语义近似度结合传统n-grams特征加权,达到区分特征权值的目的,通过权值过滤并选择n-grams特征,在匹配过程中引入语义近似度,减少匹配过程中产生的稀疏数据。在美国当代英语语料库和北京BBC汉语语料库中的实验结果表明,相比于引言中提到的3种算法,基于多尺度的n-grams特征选择加权及匹配算法得到的特征质量更高,并在分类器中的准确率大幅提升。
1 多尺度n-grams特征选择加权
传统特征加权一般建立在文本中特征出现的频率或概率的基础上,如tf-idf、卡方检验等。这类加权方法对于单独的词汇特征较为有效,但n-grams特征由多个词汇组成,假设n个词汇在文本中的出现概率为:p1,p2,……,pn,则这些词汇同时出现在同一文本的概率为:
P=p1p2……pn.
(1)
由于每个词汇的出现概率pk(1≤k≤n)值域为(0,1),故概率P会随着n的增加趋近于0,此时P为n个特征同时出现在同一文本中,并不考虑每个词汇的顺序和是否连续的情况,而n-grams特征是n个词汇连续出现且顺序不变,所以真正的n-grams特征出现概率要远远小于P甚至为0,而建立在此基础上的传统加权方法在训练集中会导致2个问题:
(1)特征权值都为趋于0的值,区分度不够,难以选择;
(2)在测试集中匹配时产生大量的0数据,即稀疏数据。
1.1 n-grams词性分布加权
性质1在文本中,n-grams特征在词性、语义及词汇三种状态下包含的文本信息量存在如下的偏序关系:
{词性语义词汇}
证明以“我爱香蕉”为例,首先,经过分词后会被切分为“我”、“爱”和“香蕉”,属于3-grams特征。当该特征以词性形式出现时,形式为“代词-动词-名词”,仅从该特征的词性结构来看,很难得到有用的文本信息。当该特征以近似的语义词出现时,以“我喜欢水果”为例,该3-grams特征与原特征近似度约为0.8,从中可以获得一定量的文本信息,但具体喜欢什么水果难以从中得出结论,还需通过原特征中的具体词汇做出准确判断,故词性、语义及词汇存在偏序关系,性质得证。
为增强n-grams特征权值区分度并减少稀疏数据,充分利用性质1中的偏序关系,提出多尺度加权的第一个尺度,即词性分布加权。虽然词性包含的文本分类信息非常有限,但当其作为n-grams特征的词性组合时,提供的文本分类信息要多于其单独存在的情况。例如在新闻分类中,体育类新闻经常出现某名运动员或球队的名字后面接诸如:射门、投篮、运球、击打、获胜、失利、退赛等词汇,组成2-grams特征。而转换为词性是“名词-动词”的形式,相比较于财经类新闻和科技类新闻中常见的“某公司股价或财报”、“某省房地产”、“某国央行”及“某形容词+某品牌手机”这类“名词-名词”或“形容词-名词”的形式,可见“名词-动词”的n-grams词性组合在体育类新闻的分布更为广泛。综上所述,使用标准差对词性分布进行衡量,如式(2)所示:
(2)
其中,n为待分类文本类别数;freqi为该词性组合在第i个类中的出现频率;freqavg为该词性组合在n个类别中出现的平均频率。由此给出尺度一,词性分布加权算法,详述如下。
算法1 词性分布加权算法
输入:待分类文本集合T{t1,t2,......,tm},待分类文本类别数n
输出:n-grams特征词性组合权值集合Wpos{pos1,pos2,......,posk}
begin
使用ICTCLAS分词接口对文本集合T进行分词
使用滑动窗口法得到n-grams特征集合,进行词性化处理得到Wpos
for eachi:1 tok
Wpos[i] =Weight(posi)
end for
end
1.2 n-grams语义加权及匹配
语义作为性质1中的偏序集元素,可以作为另一个尺度引入n-grams特征加权或匹配。在进行语义加权及匹配时遵循如下原则,即相同长度的n-grams特征进行语义加权或匹配。匹配过程中首先得到待加权的n-grams特征,如下所示:
word1-word2-……-wordn
从文本头部开始,以长度n为窗口,得到与待加权特征长度相同的文本段,如下所示:
word1’-word2’-……-wordn’
进行语义加权时,使用ICTCLAS语义计算接口,将word1与文本段中每个词汇做语义近似度计算,取语义近似最大值simmax(word1)。当出现如下两种情况时将simmax(word1)值赋0:
(1)simmax(word1)小于0.5,表明n-grams特征中第一个词汇与文本段不具备语义近似;
(2)word1为语义无关词集合中的词,如“的”、“了”、“地”等。
除上述两种情况外,将simmax(word1)保留,继续计算n-grams特征中第二个词汇word2的语义近似值simmax(word2)。n-grams特征与第一个文本段的语义近似度计算如式(3)所示:
(3)
其中,n为n-grams特征中的词汇个数,将特征中每个词的最大语义近似值求和后平均到每个词汇中,得到与文本段的最终语义近似结果。若文本t含有m个词汇,即长度为m,则其在与长度为n的n-grams特征加权时,会分为m-n+1个文本段,则在该文本中得到的加权值即为m-n+1个文本段权值和。若训练集或测试集T中存在k个文本,则n-grams特征在k个文本中重复上述操作,得到的结果Similarity(n-grams,t)既可以作为训练集的特征加权,用于后续特征选择,也可以作为测试集的匹配结果,避免稀疏数据。综上所述给出尺度二,即语义加权及匹配算法,详述如下。
算法2 语义加权及匹配算法
输入:训练集或测试集文本T{t1,t2,......,tm}
输出:语义加权或匹配后的n-grams特征值集合Wsim{w1,w2,......,wk}
begin
对文本T使用ICTCLAS分词接口进行分词
使用滑动窗口法得到n-grams特征集合F
for eachi:1 toF.size
for eachj:1 toT.size
Wsim(F[i]) =Wsim(F[i]) +Similarly(F[i],T[j])
end for
end for
end
1.3 多尺度的n-grams特征选择加权及匹配算法
在给出前两种尺度的n-grams特征加权方法后,结合传统的tf-idf加权特征值,将3种尺度得到的权值求和,若结果小于阈值β,则舍弃该n-grams特征,否则保留。综上所述,给出基于多尺度的n-grams特征选择加权算法,详述如下。
算法3 多尺度的n-grams特征选择加权算法
输入:训练集或测试集文本T{t1,t2,......,tm}
输出:语义加权或匹配后的n-grams特征值集合W{w1,w2,......,wk}
begin
对文本T使用ICTCLAS分词接口进行分词
使用滑动窗口法得到n-grams特征集合F
根据词性分布加权,得到n-grams词性组合权值Wpos{pos1,pos2,......,posk}
根据语义加权,得到n-grams权值集合Wsim{sim1,sim2,......,simk}
根据传统tf-idf加权方法得到权值集合Wtfidf{td1,td2,......tdk}
for eachi:1 tok
W[i] =Wpos[i] +Wsim[i] +Wtfidf[i]
ifW[i] <β
deleteW[i]
end if
end for
end
2 实验
本文研究采用的实验数据集分中英文两种,即北京BBC汉语语料库和美国当代英语语料库。使用支持向量机(Support Vector Machine,SVM)进行分类性能评价,评价指标包括准确率(P)、召回率(R)和F值(F)。
2.1 北京BBC汉语语料库实验
北京BBC汉语语料库实验中,n-grams文本分类特征采用5-grams。在特征数分别为200、500、1 000、1 500、2 000、2 500和3 000时,对比引言中提到的3种n-grams特征选择加权方法和本文方法的分类准确率、召回率及F值,如图1~图3所示。从图1~图3中可以看到,4种方法在5-grams特征数不超过1 000时,准确率、召回率和F值都呈上升趋势。当5-grams特征数量超过1 000时,逆文本频率法和重构法的分类性能呈现断崖式下降,究其原因在于当5-grams特征数量增多时,产生的稀疏数据也在增加,且增加速率相比于非稀疏数据要快,导致在特征数量达到3 000时,二者的准确率不足70%。扩展的5-grams方法由于其针对5-grams特征设计,在数量超过1 500后分类性能逐渐下降,但相比于逆文本频率和重构法,性能下降幅度较小,在5-grams特征数达到3 000时准确率为82%。而本文方法由于从词性、语义和词汇三个尺度对n-grams特征进行选择加权及匹配,使得稀疏数据大幅减少,从图3中可以看到,特征数量超过2 000时分类性能才开始下降,在特征数达到3 000时准确率达到89%。

图1 3种引言方法与本文方法在SVM中的准确率
Fig. 1 Accuracy of three introduction methods and the proposed methods in SVM

图2 3种引言方法与本文方法在SVM中的召回率
Fig. 2 The recall rate of three introduction methods and the proposed method in SVM

图3 3种引言方法与本文方法在SVM中的F值
Fig. 3 TheFvalue of three introduction methods and the proposed method in SVM
2.2 美国当代英语语料库
在美国当代英语语料库中,分别对比引言中的3种方法和本文方法在2-、3-、4-及5-grams特征时产生的稀疏数据数量和占比,见表1~表4。从表1~表4中可以明显看出,当特征为2-grams且特征数量不超过2 000时,引言中的2种方法稀疏数据并不严重,占比不超过20%,当特征数量达到3 000时,稀疏数据逐渐增加,分别达到32.7%和28.4%。而本文方法在稀疏数据的抑制上效果较好,在2-grams特征数量达到3 000时,占比仅为11.9%。当n-grams特征中n值分别为3时,逆文本频率法在特征数为200时,稀疏数据的占比就达到了20%以上,重构法在特征数为500时稀疏数据占比超过20%,而当特征数量达到3 000时,2种引言方法的稀疏数据占比接近50%,已经不适合作为分类特征。相比而言,本文方法在特征数达到3 000时,稀疏数据占比仍然保持在20%以下。当n值达到4和5时,引言方法在特征数量超过1 000后都产生了占比接近于50%的稀疏数据,无法作为分类特征进行分类建模。而本文方法在特征数达到3 000的情况下,4-grams和5-grams时的稀疏数据占比分别为23.3%和29.4%,远低于引言方法。

表1 3种方法在2-grams特征时的稀疏数据量及所占比例
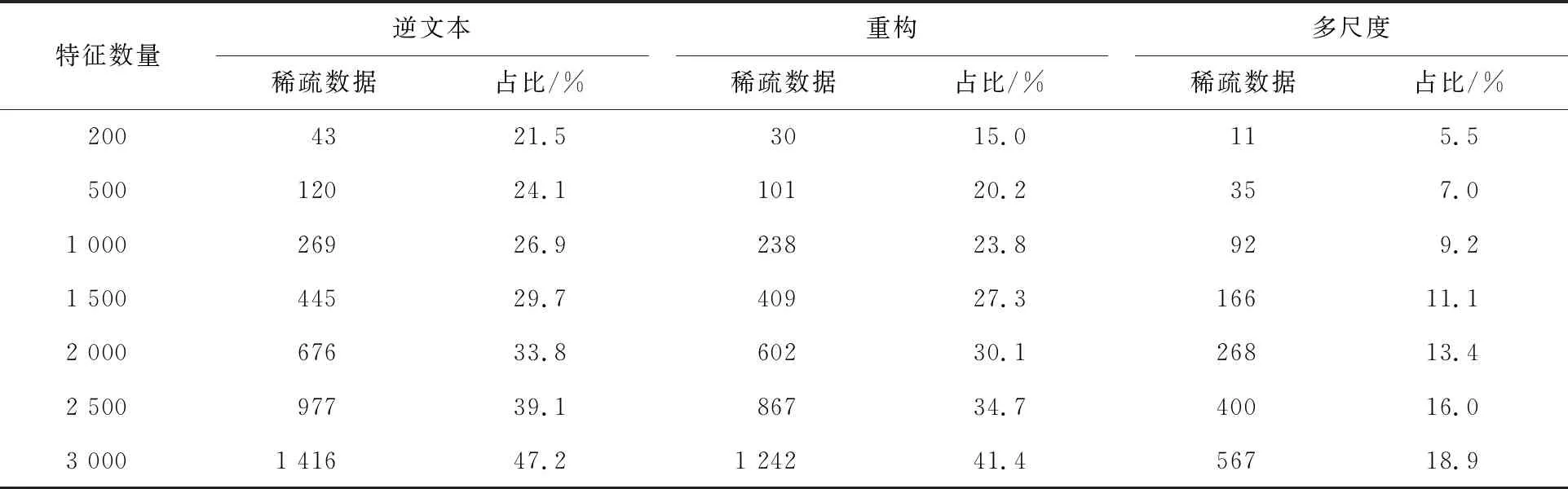
表2 3种方法在3-grams特征时的稀疏数据量及所占比例
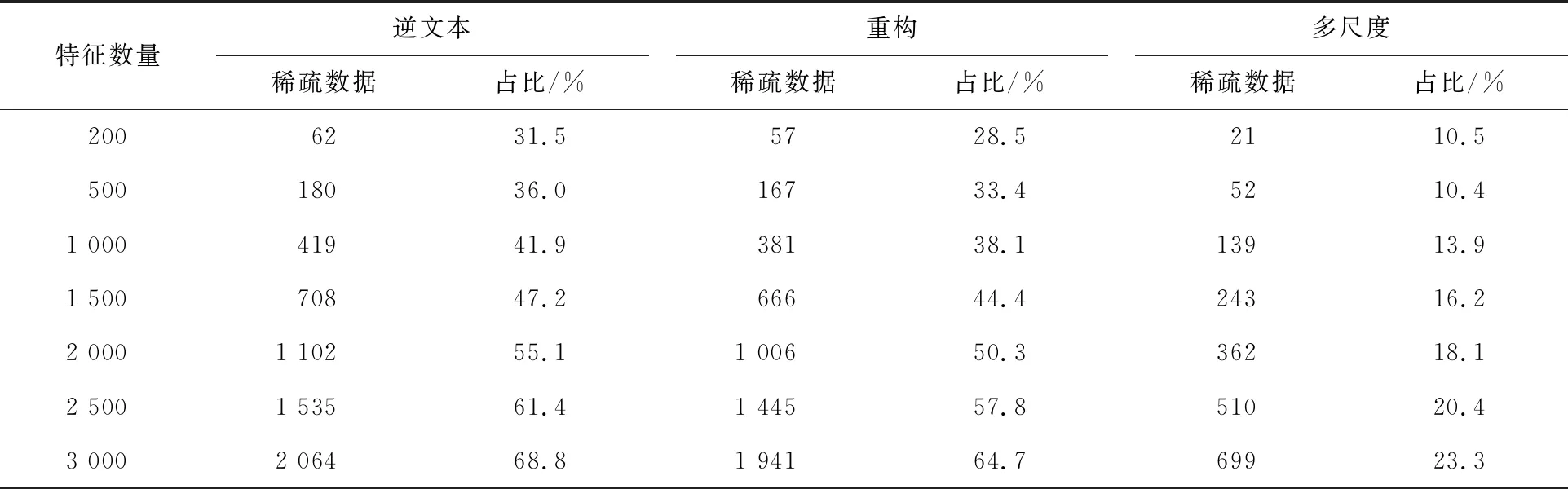
表3 3种方法在4-grams特征时的稀疏数据量及所占比例

表4 4种方法在5-grams特征时的稀疏数据量及所占比例
3 结束语
针对n-grams特征选择加权及匹配过程中的权值区分度低和稀疏数据多的问题,本文利用词性、语义和词汇的内在偏序关系,提出使用词性分布、语义和词汇的多尺度n-grams特征选择加权及匹配算法。该算法在有效降低稀疏数据量的同时,能够在特征加权过程中增强权值区分度,便于选择优质特征。对比实验结果表明,本文方法得到的n-grams特征在分类性能和稀疏数据控制上均有大幅提升,有利于进一步推广n-grams特征的应用领域。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
成都信息工程大学学报(2022年3期)2022-07-21
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
科技视界(2016年1期)2016-03-30
长江学术(2016年4期)2016-03-11
物联网技术(2015年7期)2015-07-21
长江学术(2015年1期)2015-02-27
