
融合多标签和双注意力机制的图像语义理解模型
2020-01-13 07:48黄影平杨海马胡文凯
智能计算机与应用 2020年1期
吴 倩, 应 捷, 黄影平, 杨海马, 胡文凯
(1 上海理工大学 光电信息与计算机工程学院, 上海 200093; 2 上海理工大学 测试技术与信息工程研究所, 上海 200093;3 上海市现代光学系统重点实验室(上海理工大学), 上海 200093)
0 引 言
图像语义理解融合了计算机视觉与自然语言处理两个方向,是利用人工智能算法解决多模态、跨领域问题的典型代表。通过计算机实现图像语义理解,再通过语音播报系统传送语义信息,不仅能够帮助视觉障碍者获取图像信息,而且能辅助驾驶,便利人们的日常生活。另外,图像语义理解的研究成果可用于图像检索、智能儿童早教机、智能机器人等方面[1-20],具有较为广泛的应用前景和现实意义。
随着深度学习的发展,人们提出了基于编码-解码的图像语义理解模型[5-19],这种模型通常采用卷积神经网络(Conventional Neural Networks, CNN)提取图像特征,再通过循环神经网络(Recurrent Neural Network, RNN)构建语言模型生成文本。Vinyals等人[7]提出了NIC 模型,该模型在m-RNN[5]的基础上将RNN部分替换成性能更好的长短期记忆网络(Long Short-Term Memory,LSTM),并且图像的特征只在LSTM的第一个时刻输入。这种改进不仅能够减少模型参数,而且还能够解决神经网络训练中的梯度消失和梯度爆炸问题。
单纯的编码-解码模型不能很好地解释生成的单词与图像中对象的位置关系,因此基于注意力机制的图像语义理解模型随之产生。Kelvin等人[8]首次将注意力机制引入图像语义理解模型,提出了soft-Attention和hard-Attention,并取得了较大的成果,为后续注意力的发展提供了基础。Qu等人[9]使用CNN提取了更加丰富的特征,如颜色,轮廓等,并且将这些额外的视觉特征加入注意力机制中,使得生成的描述更加准确。Chen等人[10]提出的SCA-CNN模型不仅考虑图像平面中物体的位置,而且将提取到的图像特征通道信息也加入其中,并且验证了先使用空间信息再使用通道信息的模型效果更好。Marcella等人[11]提出了一种结合显著图和上下文的注意力机制,并且验证了显著图在生成文本中的重要性。吕凡等人[12]引入注意力反馈机制,不断强化图像与文本的匹配关系,在一定程度上解决了注意力分散的问题。Jiang等人[13]改进了LSTM的内部结构,分别在输入门和输出门中增加存储单元,使得LSTM单元在必要的时候能够读取这些之前没有计算到网络中信息。此外,该模型还将前一时刻的attention信息引入下一时刻,解决了模型重复关注的问题。
为了解决传统编码-解码可能出现预测物体不正确的问题,You等人[14]首次提出了基于属性预测的图像语义理解模型,即首先使用多标签分类获取图像的视觉属性,再结合视觉属性和图像特征生成文本。随后,Zhe等人[15]基于标签检测提出了SCN-LSTM模型,该模型中LSTM每个时刻的权值矩阵被扩展为一个与标签相关的权值矩阵的集合,根据标签与图像的相关性来决策生成的单词。这种模型在语言概念被修改时,仍然能够生成正确且流畅的句子,但是整个模型的参数会随着标签数量的增大而增加,训练十分困难。Zhao等人[16]提出了一种多模型融合的图像语义理解方法,采用CNN提取图像的全局特征与图像的视觉属性,在LSTM的0时刻输入全局特征向量,在后续的每个时刻均输入前一时刻产生的单词编码向量、图像的视觉属性与时变的语句特征向量。这种方法解决了因时间的推移造成的信息丢失问题,但存在大量冗余信息。He等人[17]提出了一种融合视觉属性和注意力机制的图像语义理解模型,使用DenseNet提取图像的全局特征和视觉属性,并且将DenseNet网络的参数共享到注意力模块以及文本生成模块,该模型增强了属性预测模块与文本生成模块的关系,减小了模型的复杂度。
现有的研究成果表明,基于注意力机制的方法和基于属性预测的方法均能提高模型的预测效果。但现有的注意力模型只关注图像特征而没有考虑到之前生成的文本,也没有考虑前后注意力区域之间的联系,并且多采用单向LSTM,不能很好地结合未来的信息生成文本。此外,基于属性预测的方法均采用CNN进行多标签分类,选取概率最大的K个属性标签作为生成文本的前提,这种方法能够获得丰富的视觉信息但存在大量冗余信息。
为了解决上述问题,本文提出了一种带有视觉属性三元组且能够挖掘潜在信息的图像语义理解模型VT-BLSTM(Visual-text Bi-directional Long Short-Term Memory)。该算法使用VGG19的卷积层提取图像的全局特征,并且为每个图像选定<物体,动作,场景>三元组,训练多标签分类模型得到每张图像的属性三元组信息,减少额外视觉属性的引入。其次,构建双向LSTM神经网络,在传统视觉注意力的基础上,加入文本注意力机制,通过变量控制当前输入单词参与生成文本的比例,决定此时生成的单词更多地依靠图像视觉信息还是之前生成的文本,得到视觉语义上下文。另外,视觉注意力模型的输入向量在原有基础上扩展一个上一时刻注意力模型的中间状态,使得模型在选择关注区域时充分考虑历史信息。最后,融合视觉三元组属性、视觉语义上下文和LSTM隐含层特征,预测文本信息。经过实验研究证明,本文提出的VT-BLSTM模型不仅引入未来信息,改善了单向LSTM生成文本仅依靠之前生成单词的缺陷,使之生成更加丰富、更符合图像的描述,而且考虑之前关注的区域,增强了前后时刻关注区域的联系。同时,解决了视觉属性冗余的问题,在不降低模型正确率的同时减小了模型的复杂度。
1 基于注意力机制的图像语义理解模型VT-BLSTM
1.1 VT-BLSTM模型整体框架
本文提出的基于视觉注意力的图像语义理解模型VT-BLSTM包括图像视觉概念提取模块、视觉语义上下文提取模块和文本生成模块三个部分,如图1所示。视觉概念提取模块使用VGG19的卷积层提取图像的全局特征V,并且修改VGG19的最后一个全连接层,利用多示例学习获得<物体,动作,场景>三元组Vattr。视觉语义上下文提取模块由双向LSTM组成,图1中LSTM _f和LSTM_b分别表示前向LSTM和后向LSTM,att_unit表示注意力单元,用于获取图像的视觉语义上下文。文本生成模块由一个多模态融合层组成,其输入包括视觉属性三元组Vattr、LSTM的隐含状态h、视觉语义上下文CO和输入单词S,根据多模态层的输出计算模型VT-BLSTM的误差,利用反向传播更新模型权重。
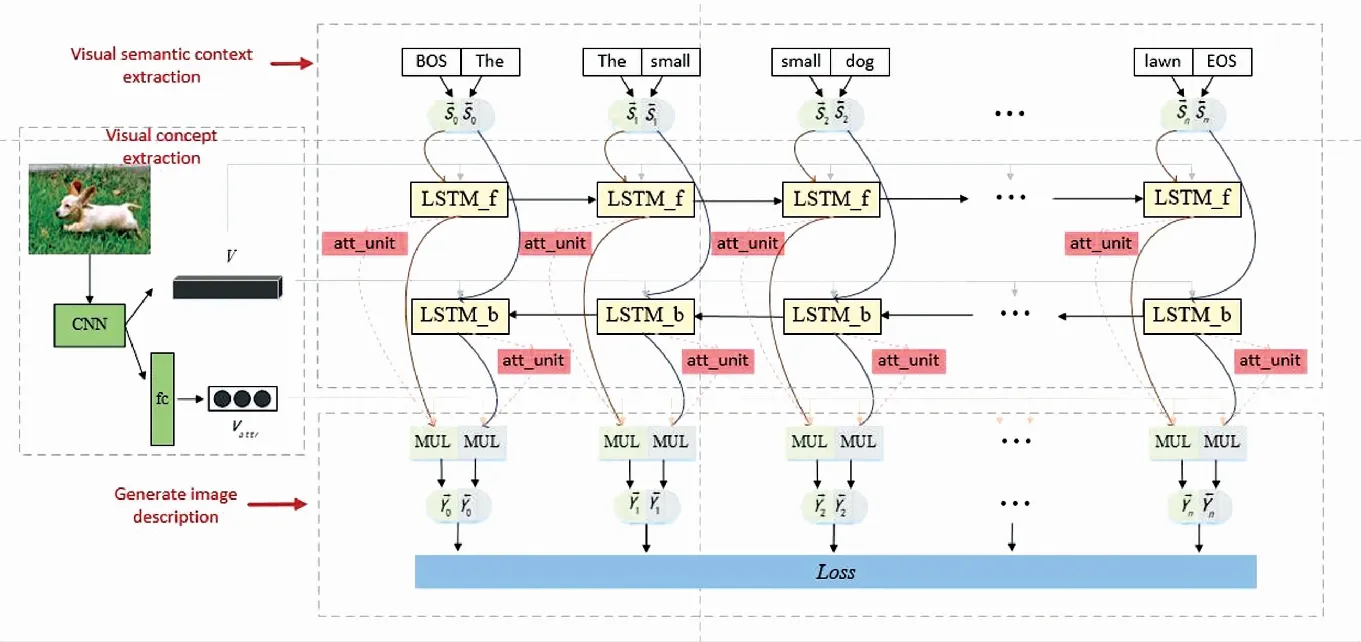
图1 VT-BLSTM模型框架图
1.2 图像视觉概念提取模块
本文的图像视觉概念是指图像的全局特征和图像的视觉属性三元组<物体,动作,场景>。图像语义理解模型中常使用在ImageNet上预训练的VGG19进行特征提取,将调整为2242243的图像输入VGG19,使用其第一个全连接层之前的网络提取图像全局视觉特征V,那么V={V1,V2,V3,…,VL},Vi∈RD,即将图像i划分为L(196)块区域,每个区域Vi都是一个D(512)维的向量。
图像的视觉属性提取通常由多示例学习完成[18-19],为了得到图像的视觉属性三元组,本文沿用文献[18]的思想,并在其基础上做相应的修改。文献[18]选取了出现次数最多的1 000个属性词构建属性词典,当测试图片对应的某个属性概率大于0.5时,该属性被认为是图片拥有的属性。这种方法能够获得丰富的图像视觉属性,但存在属性之间关联度过高,比如“green”和“grass”,以及仅依靠语法而不需要看图就能生成的单词,比如“in”、“the”。针对上述问题,本文提出了使用视觉属性<物体,动作,场景>作为属性前提,参与后续文本的生成。该方法不仅能够在视觉属性预测时极大地减少模型的训练参数,而且在生成文本时也减小了模型的复杂度。

(1)

(2)
其中,φ(bij)表示图像i中,第j区域的fc7输出向量,φ(bij)∈R4096,Vw和uw都是与单词w相关的权重和偏置。
最后,计算模型的交叉熵损失函数并更新权重,利用训练好的模型得到每张图片的<物体,动作,场景>属性。假设数据集含有N张图片,每张图片i的标签yi={yi1,yi2,yi3,……,yic},当yi包含属性k时,yik=1,否则,yik=0。那么,本模块中属性预测损失函数L(I)的计算公式为:
(3)
1.3 视觉语义上下文提取模块
传统的注意力机制单指视觉注意力[8,17]即前一时刻LSTM的隐含层状态决定当前关注图像的哪些区域,该机制极大地提高了生成文本的准确率。但是这种机制存在以下两点问题。一方面,某些单词的生成并不依靠图像,而是依靠之前生成的文本。比如已经生成某句子片段“A girl is sitting in front”,那么后面的“of”就可以根据前面生成的单词决定。另一方面,关注的图像区域之间可能存在某种联系。
针对上述问题,本文在文献[8]的基础上提出了一种新的注意力机制提取上下文信息,包含视觉注意力单元、语义注意力单元和融合单元,其生成上下文的结构与传统注意力的结构对比如图2所示。视觉注意力单元用于获取当前时刻每个图像区域的权重α,α={α1,α2,α3,…,αL},α∈R。语义注意力单元用于获取当前时刻保留文本信息的概率β,β∈(0,1)。融合单元先根据α和图像全局特征向量V得到视觉上下文CV,再根据“语义门”g和LSTM存储单元m得到语义上下文CT,最后融合CV、CT以及β得到视觉语义上下文CO。这种新的注意力机制不仅考虑了历史关注的区域,而且引入文本保留概率β,使得模型能够自主地选择多关注图像还是之前生成的文本。

(a) 传统方法
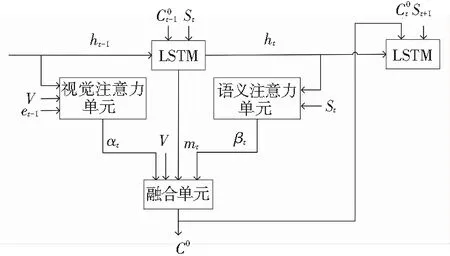
(b) 本文方法
Fig. 2 Traditional and the proposed attention visual context extraction graph
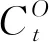
(4)
(5)
(6)

在本文的视觉注意力单元中,t时刻图像区域权重at计算公式如下:
(7)
at=softmax(Weet)
(8)
其中,et表示t时刻关注区域权重的中间状态,t=0时刻的状态由全局图像特征得到,t>0时,该中间状态由全局图像特征V、前一时刻LSTM隐含层ht-1和前一时刻的中间状态决定。这种改进的视觉注意力机制将中间状态et看成一种记忆单元,能够记忆历史时刻关注的区域信息。公式(7)中的W0、W1和b,以及公式(8)中的We,均是可训练参数。在t=0时刻,LSTM的隐含层状态h0和存储细胞状态c0由输入图像的平均全局特征决定:
(9)
(10)
语义注意力单元在t时刻生成文本保留概率βt的计算公式如公式(11)所示:
βt=softmax(We(WsSt+Whht)),
(11)
其中,We与公式(8)中的We相同;Wh与公式(7)中的Wh相同;Ws是与语句相关的可训练参数。

(12)
其中,mt表示当前时刻LSTM的存储单元;σ表示sigmoid激活函数;gt表示一个“语义门”,用来控制当前单词遗留下来的概率,计算时会用到如下公式:
(13)
(14)
本文提出的注意力机制引入了视觉注意力存储单元和语义注意力模块,视觉注意力存储单元能够保留历史时刻关注的区域,语义注意力模块能够自主地选择关注之前生成的文本,使得模型的在每个时刻关注的区域更加准确,生成更符合图像的描述。
1.4 文本生成模块
文本生成模块由一个多模态融合层组成,根据输入单词S、LSTM的隐含状态h、视觉语义上下文CO和视觉属性三元组Vattr,预测图像对应的文本。由于本文采用了双层LSTM,因此会从2个方向生成文本。在训练时,根据前向LSTM和后向LSTM的预测损失之和更新权重。在测试时,分别计算前后向LSTM生成文本的概率和,选择概率和最大的文本作为模型最终的输出。以训练过程中前向LSTM为例,文本生成模块的实现流程如下:
过程中,ot表示wt的独热编码,ot∈RV,V表示词汇库的大小;使用word embedding降维,得到St,St∈RM,其中M表示词嵌入向量的维度。
(2)LSTM的隐含层状态更新。其中ht表示t时刻LSTM单元的隐含层向量,ht∈RH。用公式表示为:
(15)
(16)
(17)
mt=ft*mt-1+it*mi;
(18)
(19)
ht=ot*tanh (mt).
(20)
其中,mt-1和mt分别表示t-1时刻和t时刻的细胞状态;σ表示sigmoid函数;ft表示遗忘门函数,用于控制前一时刻细胞保留下来的信息;it表示输入门函数,用于更新当前时刻的信息;ot表示输出门函数,控制更新后细胞状态的输出。Wf、Wi、Wo分别表示遗忘门、输入门、输出门的参数矩阵,bf、bi、bo分别为对应的偏置。*表示矩阵点乘。
(3)根据上述得到的单词编码向量S、LSTM的隐含状态h、视觉语义上下文CO和视觉属性三元组Vattr生成文本Yt。其过程如下:
在单词编码阶段,先采用独热编码得到V维向量,后采用embedding得到M维向量,因此生成Yt需要经过3个步骤。首先,将上述4个特征向量输入多模态层,得到一个M维向量rt,其计算方法如公式(21)所示:
(21)
其中,Ww_h、Wc2t和Wattr都是可学习参数。
其次,经过一个全连接层fc得到一个V维的向量yt。最后,yt经过归一化得到每个单词的概率pt,pt∈RV,在词汇表中取pt的最大值所对应单词作为最终输出Yt。
针对一张图像I,训练模型的最终目的是得到模型中的最优参数θ*,即:
(22)
其中,S表示图像I的标定描述,θ是模型中的自学习参数,训练时模型的损失函数为:
(23)
公式(23)的第一部分和第二部分分别表示前向和后向LSTM的交叉熵损失函数,其中N为训练图像的大小,wt表示t时刻生成发单词,最后一项表示视觉语义上下文提取模块中前向和后向LSTM每个时刻α的正则项。
本文训练好的图像语义理解模型能分别根据前向LSTM和后向LSTM生成文本,最终生成的句子由最大概率和决定,如式(24)所示:

2 实验结果与分析
2.1 实验参数设置和评价指标
本文中使用Flickr8K和Flickr30K数据集进行实验。Flickr8K图像集中含有6 000张训练图像,1 000张验证图像,1 000张测试图像,其中每张图像对应有5个人工标定的描述信息。Flickr30K数据集包含31 783 张图片,每张图片也对应5条标注文本,本文参考文献[6]的分割方法,将数据集分割为29 000张训练图像、1 000张验证图像和1 000张测试图像。使用VGG 提取图像特征时,得到特征的维度是196*512,即L=196,D=512。在文本预处理部分,首先删除标定语句中所有的标点符号,其次将单词全部转换成小写字母,设置句子最大长度是20。使用Flickr8K数据集时,得到有效的29 318条语句,其中包含7 224个单词,根据这些单词建立词汇库。使用Flickr30K数据集时,词汇库包含18 344个单词。在训练时使用Adam优化算法更新参数,Adam的参数设定为alpha=0.001、beta1=0.9、beta2=0.999,同时使用dropout防止模型过拟合。
实验中采用了BLEU(Bilingual Evaluation understudy)和METEOR两种方法对生成的语句进行评价。BLEU表示候选语句与标定语句中n元组共同出现的程度,是一种基于精确度的评估方法,包括BLEU-1、BLEU-2、BLEU-3和BLEU-4。METEOR指标同时考虑了整个语料库上的准确率和召回率,其结果和人工判断的结果有较高相关性。这两种评价指标得分越高表示模型能够对图像进行更加准确的语义理解,生成的语句质量越好。
2.2 视觉属性三元组提取结果
使用NLTK处理文本数据,选取出现次数最多的属性单词组成数据集的属性词典,其<物体,动作,场景>三元组属性词云如图3所示。

(a) 物体词云 (b) 动作词云 (c) 场景词云
根据上述属性词构建每个图像的属性标签,通过多示例学习得到图像的视觉三元组属性如图4所示。图4中右上角的单词分别表示图像对应的属性,属性后的数字表示为该属性的概率。如图4(a)所示,该图像生成的<物体,动作,场景>三元组为

(a)视觉三元组1 (b)视觉三元组2 (c)视觉三元组3 (d)视觉三元组4
(a)Visual triple 1 (b) Visual triple 2 (c) Visual triple 3 (d) Visual triple 4
图4 视觉属性生成示意图
Fig. 4 Visual attributes schematic
为了验证视觉三元组的有效性,本文分别对比使用视觉三元组、传统视觉属性提取[18]和不使用视觉属性三种方法,实现图像的语义理解,并使用BLEU和METEOR评价指数对生成的句子进行评价。表1记录了上述三种不同的方法在Flickr8K数据集和Flickr30K数据集上生成文本的结果,B@1~B@4分别表示BLEU-1~BLEU-4评价指标,M表示METEOR评价指标。
通过对比可以看出,使用了属性特征的模型效果最好,另外,在Flickr8K数据集下,使用传统属性提取方法和使用视觉属性三元组方法生成文本的正确率相差不大,但是在Flickr30K数据集下,带有视觉属性三元组的模型效果更好。不带属性特征的模型是端到端的模型,仅根据文本预测得到的句子可能会导致图像主体预测出错,在模型中引入视觉属性能够在一定程度上减小这样的错误。而传统的属性预测往往包含十几个单词,这些单词之间可能存在包含关系或者单词意思相近,会引入冗余属性,而且使得模型的参数增加。视觉属性三元组不仅能够准确预测出图像主要属性,还能减小模型的参数,降低模型训练的复杂度。
综合以上分析,得到结论:使用视觉属性三元组的模型能够在减小模型参数的情况下,有效地引导文本生成,且不降低模型生成文本的正确率。

表1 不同视觉属性生成文本的结果
2.3 VT-BLSTM模型结果与分析
设置batch为64,迭代次数为15K,随着迭代次数的增加,本文提出的VT-BLSTM模型在Flickr30K上的loss变化曲线如图5所示,由loss的变化趋势可知,VT-BLSTM是可训练的、并且有效的。BLEU和METEOR评价分数随着迭代次数的变化曲线如图6所示。这五种评价分数总体来说都随着迭代次数的增加呈现上升的趋势,并且在迭代到10 000次左右时,能达到稳定值。

图5 训练时模型的损失变化

图6 不同迭代次数下VT-BLSTM的性能
图7是采用VT-BLSTM模型实现图像的语义理解,并且可视化每个时刻聚焦的区域以及视觉语义上下文模块中“视觉门”1-β的示意图。图7(a)~(d)的上半部分均表示每个时刻生成的文本以及对应的关注区域,高亮的部分表示关注度更高,下半部分表示生成文本时“视觉门”的变化曲线。
图7(a)生成文本描述“Two people are shoveling snow on a snowy hill.”,在生成单词“people”、“snow”的时候能够准确定位到人和雪地的部位。并且在“people”、“shoveling”、“snow”和“hill”对应时刻,1-β数值较大,表明该模型更多地关注图像而不是文本,而在生成“are”这种无视觉的信息时,1-β较小。另外,图7(a)显示,该图像生成的属性单词为
由此可见,VT-BLSTM模型能够很好地识别出图中的主要目标和属性信息,选择性地关注图像或之前生成的文本,并且结合未来信息生成更丰富的、具有多样性的图像描述,实现图像的语义理解。

(a) 生成文本描述1

(c) 生成文本描述3

(b) 生成文本描述2

(d) 生成文本描述4
图7 可视化注意力机制
Fig. 7 Visual attention mechanism
2.4 对比实验设置
为了验证模型VT-BLSTM的有效性,本文选择了近3年图像语义理解领域中具有代表性且性能优越的模型进行对比实验。具体对比模型如下:
(1)DeepVS[6]。Karpathy 等人将图像中的多个局部区域和文本描述片段相对应,再使用RNN生成图像的文本描述。
(2)GoogleNIC[7]。Vinyals 等人提出基于 CNN 和LSTM的图像语义描述模型,为了减少模型参数,图像的特征只在LSTM的第一个时刻输入,但性能并没有降低。
(3)Hard-Attention[8]。Kelvin等人提出了Soft Attention和Hard Attention机制。前者是对每个局部区域计算注意力权值,不会设置筛选条件。后者会在得到权重后筛选出不符合条件的权重,并将其置0,使得每个时刻只注意到更小的区域。文献[12]中指出Hard-Attention比Soft-Attention生成的句子准确率更高,因此本文将Hard-Attention作为对比模型。
(4)VA-LSTM[9]。Qu等人建立了一个大小为6的颜色词典,并且预测物体边框,在注意力机制中加入图像的颜色信息和物体的轮廓信息,从而生成更加准确的文本描述。
(5)Saliency+Context Att[11]。Marcella等人提出了一种结合显著图和上下文的注意力机制。首先使用SAM[20]获得图像的显著图,再将显著图与图像全局特征结合,分别输入显著图注意力模型和上下文注意力模型,最后根据LSTM得到图像对应的文本。
(6)CNN-RNN-f3[12]。吕凡等人在传统的CNN-RNN结构上加入了生成文本的反馈信息,并且配合循环迭代结构,通过不停循环使得关注信息得到强化。
(7)LSTM-EM-DA[13]。Jiang等人在LSTM的输入门和输出门中分别增加存储单元和门控信号,并且使用上一时刻的attention信息来获得当前的关注区域。文献[13]指出,这种使用额外记忆信息的注意力模型比soft -attention更能从不同的角度生成图像的文本描述。
(8)ATT-FCN[14]。You等人提出了一种将图像视觉属性参与LSTM更新以及单词解码的方法,并且对比分析了3种产生视觉属性的方式和3种属性与模型的结合方式,文献[14]指出,ATT-FCN模型效果最好,因此本文将ATT-FCN作为对比模型。
(9)SCN-LSTM[15]。Gan等人为每个视觉属性都扩展了一个LSTM参数,使得每个属性都对应一个概率,根据加权视觉属性计算每个时刻生成的单词。
(10)LSTMp+ATTssd+CNNm[16]。Zhao等人提出了一种多模型融合的图像语义理解模型,该模型分为图像特征提取模块、属性预测模块、语句特征提取模块和文本生成模块。文本生成模块的输入包含前一时刻生成的单词、预测的属性以及时变的语句特征。
(11)VD-SAN[17]。He等人提出了一种包含共享参数的图像语义理解模型,DenseNet中的参数不仅用于图像特征提取、视觉属性预测,而且用于注意力模型和LSTM。
2.5 对比实验结果与分析
在Flickr8K和Flickr30K数据集中,VT-BLSTM与该领域其它模型的性能对比结果见表2。在Flickr8K数据集中,除了BLEU-1分数比LSTM-EM-DA低,其余的评价得分与对比模型相比均有较大的提升,尤其是在METEOR上,比其它基于注意力的模型性能平均提升了7.7%。在Flickr30K数据集下,BLEU-3和BLEU-4指数相比于其它模型有较大提升。

表2 实验结果
表2中的Deep VS和Google NIC都只在文本生成模块的开始输入图像信息,后面的任何一个时刻,均不输入与图像信息有关的数据。因此随着时间的推移,图像中的有效信息会逐渐减小,即使生成的句子通顺,但有时候与图像关系不大,从而导致模型效果不好,准确率不高。而基于时序信息的VT-BLSTM能够定位到具体区域,结合图像深层特征对图像进行理解,与Deep VS和Google NIC相比,在Flickr8K数据集下,BLEU-1、BLEU-2和BLEU-3指数平均提升13.4、21.5、31.2,在Flickr30K数据集下,BLEU-1、BLEU-2和BLEU-3指数平均提升了10.8、23.3、35.3,证明注意力机制能够大幅度提升语义理解模型的准确性。
在具有注意力机制的模型中,本文提出的VT-BLSTM模型除了BLEU-1得分略低于LSTM-EM-DA,在METEOR指数上略低于CNN-RNN-f3之外,在其它得分上均超过这五个模型。Hard-Attention模型通过前一时刻LSTM隐含层的全连接层来预测当前关注的区域,即是通过语义特征预测图像特征,并且通过设置阈值得到更小的注意力区域,但文献[8]的可视化结果显示,注意的区域常与生成的单词没有直接关系。VA-LSTM在原本的LSTM单元中,融入图像的颜色特征和轮廓,更新了原有的输入门、遗忘门和输出门的信息,但并没有考虑当前生成单词与前文的关系。Saliency+Context Attention模型通过两路注意力机制预测文本,显著图注意力机制能够聚焦图像局部区别,上下文注意力机制使得生成的文本更加自然,但该模型不能用未来信息预测潜在的视觉单词。CNN-RNN-f3模型通过引入循环结构更新网络参数,能够在一定程度上解决注意力分散的问题,但是对于复杂的图像,该模型不能进行准确矫正。LSTM-EM-DA模型通过门控信号使用额外的记忆信息,能够更加全面地关注图像,但存在聚焦区域分散的问题。而本文提出的VT-BLSTM不仅使用图像局部特征和之前生成的文本作为视觉语义信息,而且使用双向LSTM,关注历史信息与未来信息,改善了注意力机制中没有考虑时序这一缺陷,使得生成的注意力区域更加准确,并且能够预测图像中的潜在视觉单词。
在具有属性特征的ATT-FCN、SCN-LSTM、LSTMp+ATTssd+CNNm和VT-BLSTM中,除了本文提出的VT-BLSTM用到了注意力机制,其它的均没有使用注意力机制。并且除了评价指数BLEU3和BLEU4指数比SCN-LSTM低,其它指数均比这三个模型高,说明了模型在属性特征的基础上增加注意力机制能在一定程度上提高模型的性能。
由以上实验数据以及分析可知,本文提出的VT-BLSTM模型在考虑关注已生成文本和聚焦区域的时序基础上,能够联系历史和未来的信息使得模型定位更加准确,并且生成更加丰富多样的句子,有效地提升图像语义理解的准确率。
3 结束语
本文分析了现有图像语义理解模型存在的问题,提出了一种新的注意力模型VT-BLSTM,首先通过VGG19提取图像的特征和视觉属性三元组,再使用双向LSTM获得当前时刻的视觉语义上下文,该视觉语义上下文和视觉属性三元组引导模型实现图像的语义理解。VT-BLSTM在传统注意力机制的基础上,充分考虑了对生成文本的关注和聚焦的时序信息,使得每个时刻聚焦区域更加准确,从而生成更加符合人类描述的文本。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机应用与软件(2022年5期)2022-07-07
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
计算机应用与软件(2021年4期)2021-04-15
河北科技大学学报(2020年4期)2020-09-10
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
小学阅读指南·高年级版(2014年2期)2014-05-27
