
TransP:一种基于WordNet中PartOf关系的知识图谱嵌入方法
2022-07-07 02:52李天宇周子力赵晓函陈丹华王凯莉
计算机应用与软件 2022年5期
李天宇 周子力 赵晓函 陈丹华 王凯莉
(曲阜师范大学软件学院 山东 济宁 273100)
0 引 言
知识图谱目的在于将人类知识组成机器可阅读的结构化知识库,知识图谱的出现实现了从字符串匹配到智能阅读理解的跃迁。Freebase、WordNet和YAGO等知识图谱目前已经成为搜索引擎、自动问答、机器阅读理解和个性化推荐等有关知识表示、学习、搜索和推理的基础构件[1]。
知识图谱是一个大型的多元关系图,节点表示实体,类型化的边表示关系[2]。知识图谱以三元组(h,r,t)的形式编码世界事实,其中:h表示头实体,t表示尾实体,r表示两者之间的关系。知识图谱嵌入则是把每个实体和关系映射为语义空间中的一个低维向量,这是一种解决知识图谱表示和推理问题的新方法[3]。它将实体和关系转换为连续的低维稠密向量,可用来完成知识图谱补全和三元组分类等任务[4]。
近年来,知识图谱嵌入方法层出不穷[5-21],如非结构化模型[5]、距离模型[6]、双线性模型[7]、NTN模型[8]和翻译模型等。其中,翻译模型以自身的简单高效性备受关注,主要包括TransE[9]、TransH[10]、TransR/CTransR[11]、TransD[12]、TransA[13]和TransC[14]等。TransE是将关系作为低维空间实体嵌入的翻译,它通过不断训练三元组(h,r,t)使得h+r≈t。之后提出的TransH、TransR/CTransR、TransD模型,致力于改进TransE[9]对1-N、N-1和N-N复杂关系处理上的不足。TransA则提出了一种自适应的度量标准,使知识图谱的嵌入更加灵活。上述模型主要研究实体空间和关系空间上的嵌入或投影,而忽略了嵌入过程中PartOf关系三元组中头实体和尾实体之间的区别。
本文针对WordNet中PartOf关系进行建模,使其保留更多的语义信息,能更好地完成链接预测及三元组分类等任务。世界上所有事物都可以分解为多个部分,整体则是由它的各个部分组成。同样地,对于知识图谱中的每个实体,一个实体可能是另一个实体的组成部分,也可能是由多个实体组成的整体。在进行知识图谱嵌入时,不能将PartOf关系三元组中具有这两个不同属性的实体同等地编码为语义空间中的低维向量。本文提出的TransP模型对WordNet知识图谱中具有PartOf关系三元组中的实体进行区分。具体过程为:将每个知识图谱中符合条件的实体看作一个球体,球心是实体所对应的低维向量,球体的半径是判断两个球体之间相对位置关系的条件,然后利用两个球体之间的相对位置关系判断两个实体之间是否存在PartOf关系。在WordNet数据集上完成了链接预测和三元组分类两个实验,实验结果表明:在不同的度量标准上,TransP相比于TransE和TransH有了一定程度的提升。
1 相关工作
知识图谱的嵌入学习一直是近几年的研究热门领域,各种各样的嵌入方法被提出。其中基于距离的翻译模型主要包括TransE、TransH、TransR和TransC等。其他嵌入方法有非结构化模型[5]、结构化嵌入模型[6]、张量神经网络模型[8]、双线性模型和学习外部信息的模型等。表1中展示了这些模型定义的关于h和t的评分函数fr(h,t)。

表1 相关模型及其得分函数

续表1
1.1 基于翻译的模型
TransE的基本思想是,将实体之间的关系表示为实体之间嵌入的翻译,即对于正确的三元组(h,r,t),满足h+r≈t,表明(t)应该是(h+r)的最近邻。因此,TransE的评分函数为:
(1)
若fr(h,t)的值很小,则说明(h,r,t)是正确的三元组。
TransE主要用于处理1-1关系,对于1-N、N-1、N-N关系的处理还存在一些问题。例如,当TransE处理1-N关系时,对于∀i∈{0,1,…,m},(hi,r,t)∈S,TransE认为h0=h1…=hm。
TransH用于解决TransE中存在的问题,即实体在涉及不同关系时表现出不同的嵌入特征。基本思想为,对于知识图谱中的一个关系,TransH将这个关系建模在一个以wr为法向量的超平面上,用r来表示。对于一个三元组(h,r,t),实体h和t首先被投影到以wr为法向量的超平面上,表示为h⊥和t⊥。TransH的评分函数为:
(2)

TransR认为TransE和TransH模型仅仅是简单地假设实体和关系处于一个相同的语义空间。事实上,知识图谱中的每个实体都具有多种属性,单纯在一个语义空间中对实体和关系建立模型无法表示出实体的多种属性。其主要思想为:分别在实体空间和关系空间构建实体和关系的嵌入,然后进行嵌入学习。对于每个三元组(h,r,t),将实体和关系分别嵌入到两个不同的向量空间。对每个关系r,为其设置一个投影矩阵Mr,然后将实体从实体空间投影到关系空间。在此投影矩阵下,实体向量被定义为:hr=hMr,tr=tMr,相应的评分函数被定义为:
(3)
TransC认为之前的模型将实体和关系同等地编码为低维语义空间中的向量,忽略了实体中概念与实例的差异。因此考虑在同一空间中以不同的方式表示概念、实例和关系。具体而言,TransC把知识图谱中的每个概念编码为球体,同时将每个实例编码为语义空间中的向量。然后使用两个球体之间的相对位置模拟概念和实例之间的关系及概念和子概念之间的关系。TransC定义了不同评分函数来优化相对位置嵌入空间,然后基于翻译的模型共同学习概念、实例和关系的表示。
1.2 其他模型
非结构化模型(UM)[5]是TransE模型的一个前身,通过设定所有的r=0,定义评分函数为:
(4)
此模型并未考虑到关系的差异性。
结构化嵌入模型(SE)[6]为头实体和尾实体设计了两个特定的关系矩阵Mr1、Mr2,评分函数为:
fr(h,t)=‖Mr1h-Mr2t‖1
(5)
尽管SE模型使用两个不同的矩阵来进行优化,但它无法捕获到实体和关系之间的精确联系。
张量神经网络模型(NTN)[8]为知识图谱嵌入定义的评分函数为:
(6)
式中:ur是一个与关系相关的线性层;g(·)是tanh函数;Mr是一个三阶张量;Mr1、Mr2是与关系r有关的投影矩阵。该模型的复杂度比较高,很难处理大规模的知识图谱。
RESCAL模型是第一个双线性模型。它将每个实体与向量相关联以此来捕获潜在的语义。模型损失函数在表1中列出:其中,es表示主语s的嵌入向量,eo表示主语o的嵌入向量,Wr表示关系矩阵。它把每个关系都表示为一个矩阵,来模拟潜在因素之间的相互作用。近年来,通过限制双线性损失函数,提出了RESCAL的许多扩展。例如,DistMult模型[15]把三元组(关系,主语,宾语)的嵌入向量分别表示为ωr、es、eo,通过将表示关系的矩阵限制为对角矩阵来简化RESCAL。HolE模型[16]将RESCAL的表达能力与DistMult的效率和简便性相结合,其中F(·)和F-1(·)表示快速傅里叶变换及其逆函数。ComplEx模型[17]通过引入复数值嵌入扩展了DistMult,以便更好地对非对称关系建模,它的损失函数Re(x)表示取x的实部。

2 TransP模型
2.1 问题描述
图1给出了PartOf关系三元组中整体属性实体和部分属性实体的示例,例如图中三元组(Labial_vein, PartOf, lip),其中头实体Labial_vein具有部分属性,尾实体lip具有整体属性,它们之间存在PartOf关系。在进行知识图谱嵌入时,针对PartOf关系三元组,应以不同的方式学习实体、关系的嵌入。
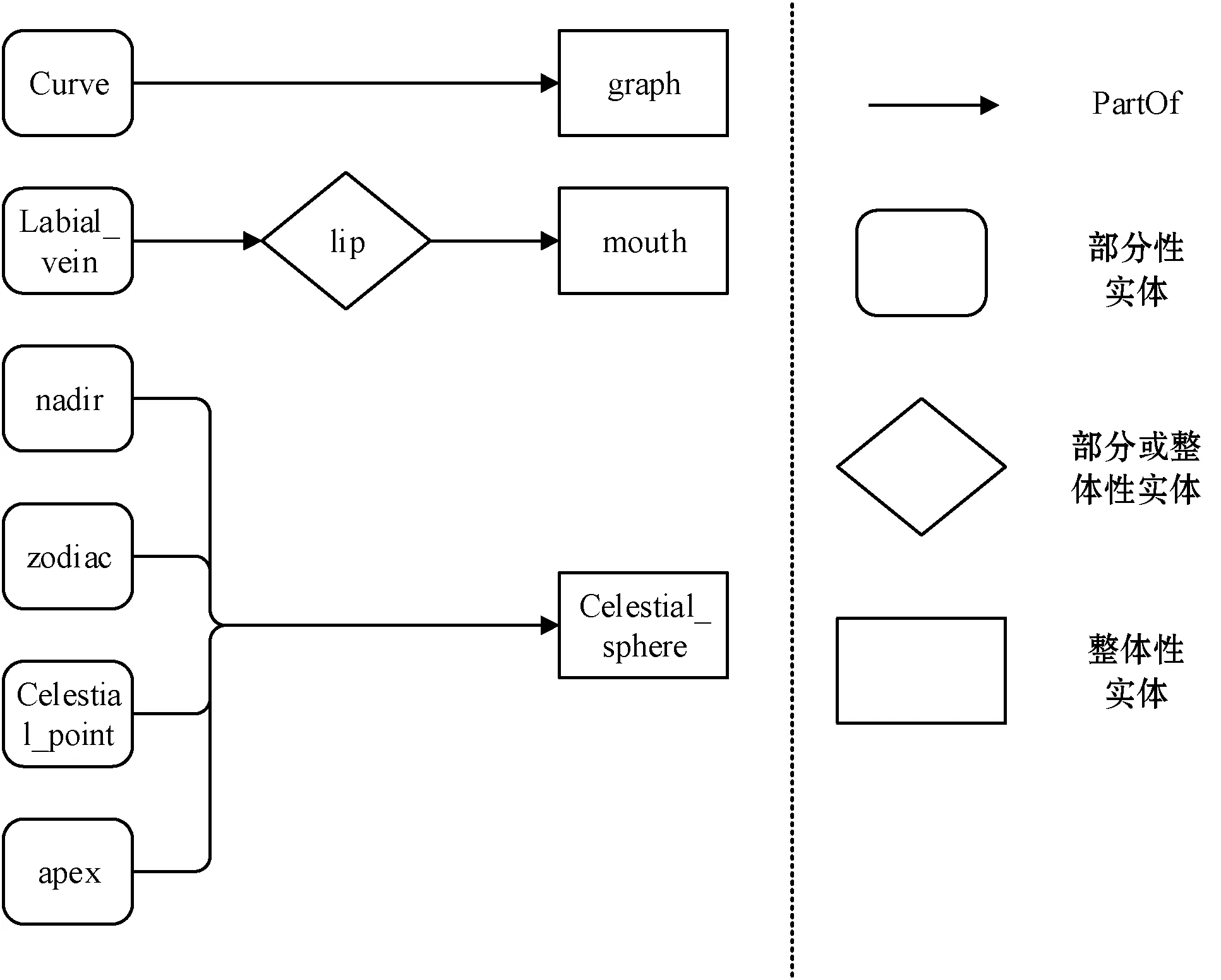
图1 关于WordNet中PartOf关系三元组的示意图
首先,将知识图谱KG定义为:KG={P,O,R,S},其中:P表示知识图谱中PartOf关系三元组中实体组成的集合;O表示知识图谱中组成其他关系三元组的实体集;R被定义为:R=Rp∪Ro,Rp是PartOf关系,Ro是知识图谱中其他关系的集合。基于此,三元组集S将被分为两个不相交的子集:
然后,给定知识图谱KG,TransP将在相同的空间Rk中学习PartOf关系三元组中实体、关系及其他关系三元组中实体、关系的嵌入。对于每个p∈P,建立一个球体模型s(q,m),q∈Rk表示球心,m表示半径。
2.2 模型介绍
TransP模型主要用于区分WordNet中PartOf关系三元组中的实体在嵌入时的不同。模型利用球体来表示PartOf关系三元组中的头实体和尾实体,然后利用两个球体之间的相对位置关系表示PartOf关系。模型定义不同的损失函数测量PartOf关系三元组中头、尾实体在嵌入空间中的相对位置,同时在模型中学习数据集中所有实体和关系的嵌入表示。
在2.1节中,三元组集合S被分为两个不相交的子集Sp和So,针对这两种三元组,模型分别定义不同损失函数。
1) PartOf三元组(Sp)表示。
对于给定的PartOf三元组实例(pi,rp,pj),将pi、pj编码为两个球体si(qi,mi)和sj(qj,mj),则两个球心之间的距离表示为:
d=‖qi-qj‖2
(7)
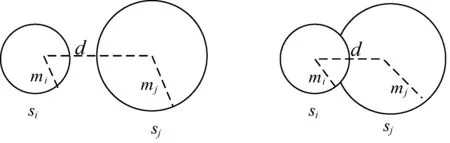
若给定的实例(pi,r,pj)是正确三元组,则球体si与球体sj是相分离的(如图2(a)所示),以此来表示整体部分的关系。此外,球体si与球体sj还存在其他三种位置关系。对此分别设置不同损失函数:
(1) 球体si与球体sj相交(如图2(b)所示)。在这种条件下,实体的嵌入仍需要优化,两个球体需要彼此远离,以达到图2(a)的形式。损失函数定义为:
fp(pi,pj)=‖qi-qj‖2-mi-mj
(8)
(2) 球体si在球体sj内部(如图2(c))所示,损失函数定义为:
fp(pi,pj)=‖qi-qj‖2-mi-mj
(9)
(3) 球体si与球体sj相离(如图2(d)所示)。此时与目标相反,即球体si的半径大于球体sj的半径,应该使mi减小,同时使mj增大。因此,损失函数定义为:
fp(pi,pj)=mi-mj
(10)
实验中,对损失函数加入限制条件:‖Q‖2≤1。
2) 普通三元组(So)表示。
给定三元组(h,r,t)∈So,TransP为每个实体和关系学习一个低维向量h,r,t∈Rk。然后使用TransE的损失函数训练此类三元组,因此损失函数为:
(11)
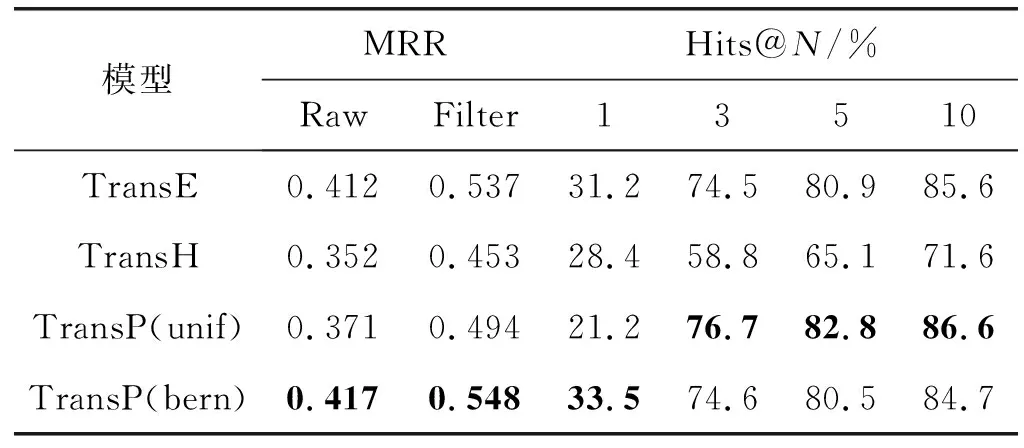
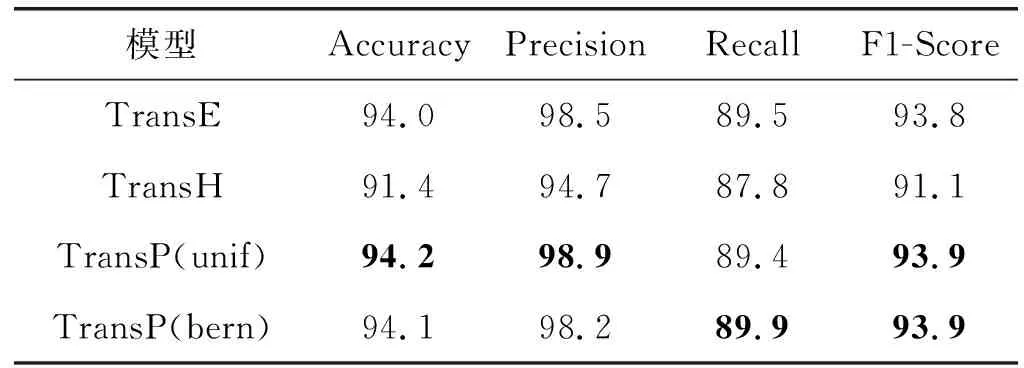
(a) d≥|mi+mj|∧mi (c) d<|mi-mj| (d) d≥|mi+mj|∧mi≥mj图2 球体si与球体sj之间的相对位置关系 (12) 式中:[x]+max(0,x),即max(0,x)函数用来得到模型的输出值0或x;γp为边际参数,用来控制正确元组与错误元组之间的距离。普通三元组的损失函数为: (13) 最后,将整体的损失函数定义为以上两个损失函数的线性组合: L=Lp+Lo (14) TransP的目标就是使得式(14)取得最小值,并且采用随机梯度下降的方法迭代更新PartOf关系三元组实体、普通三元组实体及关系的嵌入。 数据集中每个三元组都有一个标签,用来区分该三元组的正误。但是,知识图谱只包含正确的三元组,所以模型需要生成错误的三元组。对于一个普通的三元组(h,r,t),要替换头实体h或尾实体t来生成错误的三元组,即(h′,r,t)或(h,r,t′)。因此,可以将负例集合形式化地描述为: {(h,r,t′)|t′∈O,(h,r,t′)∉So} 同样地,PartOf三元组的负例集合也以相同方法生成。在替换整体性实体、部分性实体以及普通实体时,和TransH采用一样的策略,即“unif(等概率采样方法)”和“bern(伯努利采样方法)”。 知识图谱WordNet是由普林斯顿大学认知科学实验室与计算机系联合开发的一个英语词库,它包含超过十万个词汇的语义知识,涉及的词性有名词、动词、形容词和副词等[22]。WN18是WordNet的一个子集,大多数基于距离的翻译模型用它来验证其方法的有效性,本文也在WN18上进行TransP模型的验证实验。实验之前对WN18中的实体与关系进行重新划分,划分步骤如下: (1) 若WN18中的实体在PartOf关系三元组中出现,则属于集合P,同时将PartOf关系归入集合Rp。 (2) WN18中其他实体属于普通实体集O,实体之间的关系属于普通关系集Ro。 (3) 对于WN18中每个PartOf三元组(h,r,t),若pi∈P∧pj∈P∧rp∈Rp,则此三元组属于PartOf三元组集Sp。 (4) 将WN18中剩余三元组归入普通三元组集So。 (5) 最终的三元组集S=Sp∪So,关系集R=Rp∪Ro。 表2给出了WN18具体划分结果。 表2 数据集的统计信息 链接预测旨在预测普通三元组(h,r,t)丢失的头实体h或尾实体t。该任务需要从知识图谱中给出候选实体的排名列表,而并非给出一个最佳结果[23]。对于每一个用于测试的普通三元组(h,r,t),将从知识图谱所有实体中随机选取一个来替换其头实体h或尾实体t。然后,按照损失函数fr计算的距离对原给定的三元组和打乱的三元组进行升序排列。 该任务包含两个评估指标:(1) 所有正确三元组的平均倒数排名(MRR);(2) 排名不大于N的正确三元组的比例(Hits@N)。MRR和Hits@N的值越高,模型的效果越好。但是,若个别被破坏的三元组也存在于知识图谱中,则导致任务的评估指标降低,无法对模型进行有效预测。因此,在对每一个测试三元组进行排名之前,把这些被破坏的三元组从知识图谱中过滤掉,该过程称为“Filter”,过滤之前的数据集称为“Raw”。实验参数设置如下:随机梯度下降的学习率λ∈{0.1,0.01,0.001},边际参数γp,γo∈{0.1,0.3,1,2},实体向量和关系向量的维度n={20,50,100}。链接预测任务中最优的参数配置为:γp=0.3,γo=1,λ=0.001,n=100,以及L1范式。 WN18上的实验结果如表3所示,表中加粗表示模型取得的最优结果。可以看出:(1) TransP在MRR、Hits@1、Hits@3、Hits@5和Hits@10的排名上均高于其他模型,这表明TransP能够得到实体与关系的更多嵌入信息内容,从而实现了更好的链接预测。(2) 在MRR上,对比TransE,TransP(bern)的结果相差不大,这可能因为训练过程中的三元组数量较少,使其性能不佳。(3) 在TransP的MRR上,“Filter”实验结果优于“Raw”,“bern”实验结果优于“unif”。 表3 WN18数据集上普通三元组的链接预测实验结果 三元组分类任务用于判断给定三元组的正误,即对一个三元组进行二分类任务。本文中,三元组分类包括普通三元组分类和PartOf三元组分类两种。首先,按照TransC中的构造方法生成实验需要的错误三元组。然后划分验证集和测试集,两者中的三元组数量相等。 该任务包括四个评估指标:准确率(Accuracy)、查准率(Precision)、查全率(Recall)和F1调和平均(F1-Score)。 本实验中,对于给定的测试三元组(h,r,t),若相异性得分(根据损失函数)低于一个特定关系的阈值σ,则预测为正确元组,否则为错误元组。特定关系的阈值σ根据最大化验证集的分类准确性确定。实验参数的选择与链接预测任务中相同,同时采用L1范式作为相似性度量,对所有训练的三元组设置迭代次数为1 000。在这个任务中,最佳参数配置为:γp=1,γo=1,λ=0.001,n=100以及L1范式。 普通三元组实验结果与PartOf关系三元组实验结果分别如表4、表5所示。由表4可得:(1) TransP在各项评估指标中均取得了较高的实验结果,这证明了TransP模型更好地学习了实体及关系的嵌入表示特征。(2) 在准确率(Accuracy)这项指标中TransP高于TransE,但是比较相近。这可能是在训练过程中采用了链接预测的参数最优配置,使得三元组分类实验的结果没有达到最优。由表5可得:(1) TransP在准确率(Accuracy)、查准率(Precision)、查全率(Recall)以及F1调和平均(F1-Score)四个评价指标上都优于TransE和TransH,表明了TransP在对PartOf关系三元组进行嵌入表示时的优势,所学习的实体及关系向量包含更为具体的属性信息。(2) 在TransP中“bern”采样方法优于“unif”。 表4 WN18数据集上普通三元组的实验对比结果(%) 表5 WN18数据集上PartOf关系三元组的实验对比结果(%) 本文主要提出一种新的知识图谱嵌入模型TransP。该模型将PartOf关系三元组与其他关系三元组区分开,然后将这两类三元组中的实体、关系以不同的方式嵌入到相同的空间,使得到的嵌入向量包含更丰富的语义信息。同时,本文重新划分了WN18数据集,并在链接预测和三元组分类两个任务上验证TransP的有效性。 下一步工作将继续改进TransP模型,使其性能得到更好的提升,主要研究方向分为以下两点:(1) 在WordNet中提取更多的PartOf关系三元组加入到训练数据集中,使模型得到更充分的训练;(2) 考虑在本模型的基础上加入更多的实体属性特征,提升模型性能。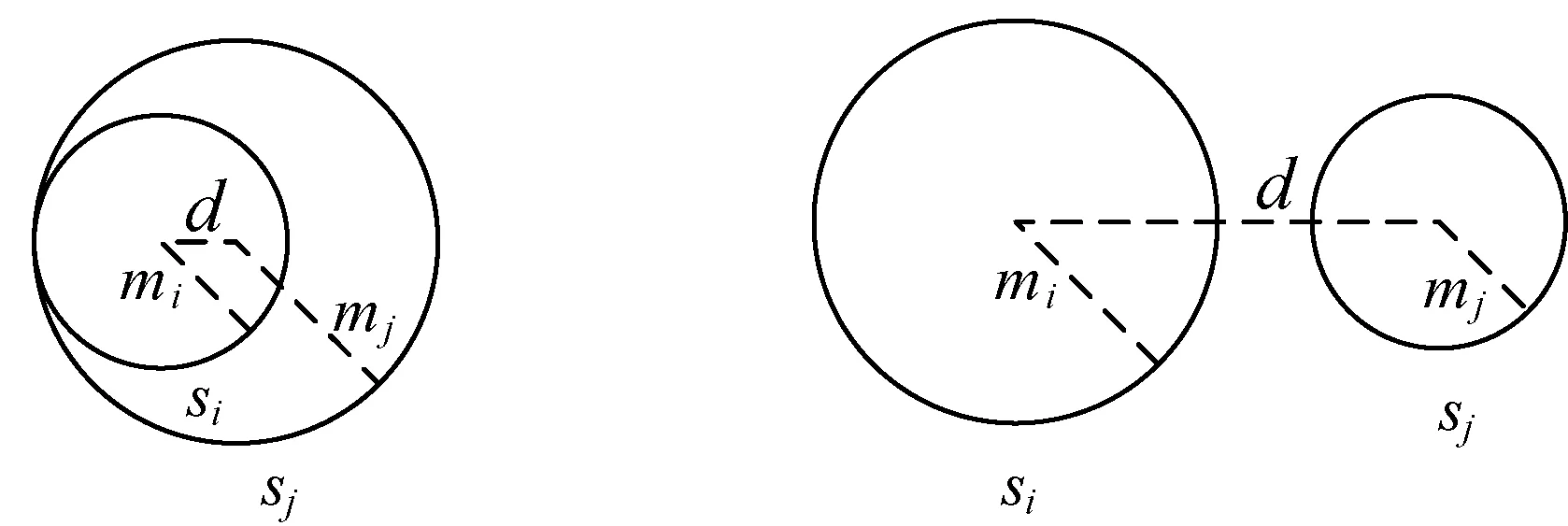
2.3 训练方法

3 实验及结果分析
3.1 数据集

3.2 链接预测
3.3 三元组分类

4 结 语
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
新高考·高一数学(2022年3期)2022-04-28
数学大王·低年级(2021年4期)2021-04-27
消费电子(2020年5期)2020-12-28
新城乡(2018年6期)2018-07-09
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中国报道(2009年12期)2009-01-15
初中生·博览(2004年3期)2004-03-07
