
基于知识图谱的软件平台知识表示方法研究
2022-07-07 02:41尚福华丁秋予蒋毅文曹茂俊杜睿山
计算机应用与软件 2022年5期
尚福华 丁秋予 蒋毅文 曹茂俊 杜睿山
(东北石油大学计算机与信息技术学院 黑龙江 大庆 163318)
Graph database
0 引 言
随着软件系统的开发规模不断扩大,软件需求日益增多与复杂化,大型软件平台的开发被提出了更高的要求[1-2]。在软件平台开发过程中知识起着重要的指导与借鉴作用,对知识的高效利用与循环使用能够有效提高软件开发的质量和效率[3]。
本项目组在对测井领域大型软件平台“一体化测井平台CIFLog”[4](下面简称为CIFLog)进行开发的过程中,发现在CIFLog软件平台生态中开发人员与软件平台之间的知识流动存在如下问题:软件开发人员要想直接获取代码知识需要不断地从软件平台的广泛代码信息中进行繁杂的数据查找与提取,并自行对其进行分析、凝练才能获取具有较大价值密度的知识。在发生人员流动时,以上现象则会带来更大的影响。
基于上述现象,本文调研了其他的大型平台,如Tencent Open Source、Alibaba Open Platform、DevCloud、GitHub等,虽然以上平台具有规范化的说明文档,对项目的关键性组成成分有所说明,但并未详尽地包含项目的所有组成成分,仅仅能满足开发人员对于关键性接口的检索需要,而无法帮助开发人员很好地对整个平台或项目进行理解,软件平台开发人员与项目之间的知识流动不顺畅的问题仍然存在。
目前国内外软件工程领域对于软件知识管理方面的研究主要分为用户需求表示、软件开发知识建模和软件开发知识管理等三个方面,如文献[1]对构建代码知识图谱方面进行了深入的研究,文献[5]提出了构建软件知识共享本体模型,文献[6]构建了Lucene-Core知识图谱,文献[7]设计并构建了以用户需求为驱动的知识管理模型,文献[8]介绍了KBSA(Knowledge-based software assistant)的研究进展等。然而目前有关软件知识管理方面的研究并未关注如何改善开发人员与软件平台或项目之间的知识流动,也没有对大型软件平台的知识抽取与形式化表示等进行深入研究与剖析。
通过以上研究和实际项目的驱动,本文对目前大型软件平台存在的问题总结如下:
1) 软件规模增长的同时带来的是软件知识激增[9],使得软件开发人员用来理解与掌握软件知识的学习成本增加;
2) 软件平台包含的数量庞大的实体数量与错综复杂的实体关系等知识[10]无法直接明了地提供给开发人员使用;
3) 软件平台中蕴含的深层次且关联关系复杂的知识无法难以被充分利用等。
基于上述问题,本文提出通过构建软件平台知识图谱改善开发人员与项目之间的知识传递,帮助开发人员了解软件平台,更好地基于软件平台进行开发工作。软件平台知识图谱由软件平台开发源码中的知识实体与关联关系组成,用于描述软件平台的知识体系。软件平台知识图谱中的知识实体是指源代码中具有语义且相互之间存在二元关联关系的个体单元。
1 基于软件平台知识图谱的知识传递
1.1 软件平台知识图谱的知识流动
如上所述,我们提倡通过构建软件平台知识图谱的方式来解决编程人员在需要知识或者信息时,需要亲自从广泛的代码中进行繁杂的查找的问题。软件平台知识图谱的目标是将项目中可能循环使用的软件平台知识抽取出来,并对其进行层次清晰地表示,以此帮助开发人员进行准确的知识定位与获取,并且帮助开发人员更好更快地了解软件平台,提高软件开发人员中对软件平台知识的利用率。
软件平台知识图谱实现的前提在于对软件平台知识的整理与表示,以由Java语言开发的CIFLog软件平台为例:软件平台开发中的最大单元为项目,其次是包,包中包含类,在类的内部定义与调用方法等。开发源代码中的知识层次清晰,知识图谱能够很好地将软件平台知识的层次性描述出来,更加贴近软件平台知识自身的条理,并且由于在软件平台中的知识不属于常识知识的范畴,有着编程规范的约束,意味着软件平台知识能够较好地支持关系梳理,且不容易产生歧义。
通过构建软件平台知识图谱,对软件平台知识进行了体系化的梳理,大幅减少了开发人员在进行知识检索时要做大量繁杂的跳转、关键字检索与筛选的工作。基于软件平台知识图谱,开发人员只需面向整理好的软件平台知识图谱发出数据请求,知识图谱则会进行相应知识节点与关系的检索。并且由于知识图谱的网状结构可以清晰地找到知识之间的关联关系,因此反馈的知识不仅仅局限于靶向知识,而有能力将开发人员可能需要的其他内容也传递出来供其使用,比如开发人员需要某种类,软件平台知识图谱则会返回指定类,并将其属性一并展示。
软件平台知识图谱的内部知识流动以及知识图谱与开发人员之间的知识流动如图1所示。首先从软件平台开发源代码中进行组件关联关系和代码结构的抽取,然后建立软件平台知识实体之间的关联关系,将软件平台知识实体有机组合在一起,形成软件平台知识图谱;软件平台知识存储在知识库中,与软件平台知识图谱建立关联,以实现知识更新;最后基于知识库与软件平台知识图谱建立检索机制,满足开发人员的文本检索和形式化检索两种检索需要。

图1 知识图流动图
1.2 软件平台知识图谱的构建
软件平台开发项目中蕴含丰富的知识实体与复杂的关联关系,这些特性对软件平台知识图谱的构建提出了挑战。基于以上问题,本文选择了在对软件平台知识实体节点、实体间关联关系和属性的表示上具有更好表现力的属性图模型来完成软件平台知识图谱的构建。基于属性图模型对软件平台知识的表示如下:属性图中的节点对应着不同的软件平台知识实体,每个节点拥有唯一的标识符,节点与节点之间由有向边连接,每条边代表着一个语义关联且具有唯一标识符。
软件平台知识图谱的构建流程如图2所示,具体包括以下五个步骤:
1) 软件平台知识图谱Schema层的构建,本文采用自顶向下的方式构建软件平台知识图谱的Schema层;
2) 软件平台知识抽取,即从软件平台开发源码中进行知识实体、属性及关系的抽取;
3) 软件平台知识表示,在获取到新知识之后需要对其进行体系化的表示,本文使用属性图模型进行知识表示;
4) 软件平台知识融合,软件平台开发是一个阶段性的过程,软件平台更新升级时有新的知识产生,在获取到新知识后需要对其进行整合;
5) 软件平台知识存储,本文使用OrientDB图数据库完成对知识图谱的存储及形式化检索。

图2 软件平台知识图谱的构建流程
2 软件平台知识图谱的构建实例
2.1 Schema层的设计与构建
构建软件平台知识图谱需要首先构建Schema层。本文中采用自顶向下的方式应用本体技术构建软件平台知识图谱的概念层,并对其进行属性的定义与约束。本文定义了四大基本类:Project(项目)、Package(包)、Class_code(类)、Method(方法)。对四大基本类的属性定义如下:
Attribute Information
Project={(Name),(Location),(JRE),(Project layout)}
Pacakage={(Source folder),(Name)}
Class_code={(Source folder),(Package name),(Outer type),(Name),(Modifier),(Super class),(Interface),(Association)}
Method={(Class),(Access type),(Return type),(Name),(Method body),(Return value)(Association)}
根据四大基本类,定义了三种语义关系:
1) E_HasPackage(有包):指代项目与包之间的关系;
2) E_HasClass_Code(有类):指代包与类之间的关系;
3) E_HasMethod(有方法):指代类与方法之间的关系。
需要注意的是,在软件过程中,代码编写时的类间关系(Class_code Relationship)是较为重要的一部分,也是我们对编程人员进行知识反馈时的重要依据,根据人工智能的主要理论范式之一——联结主义[11],对概念之间的关系强弱程度进行标注,更便于后续推理与人工神经网络的学习,因此在本研究中将编程中的类间关系单独列举出来,分为Dependency relationship(依赖关系)、Association relationship(关联关系)、Aggregation relationship(聚合关系)、Composition relationship(组合关系)、Inheritance ship(继承关系)。这些关系的耦合度依次增强且在语义上有所区别,需要结合上下文环境进行分析。除此之外,本文还对方法参数(Method parameter)、调用关系(Call relationship)和返回值(Return value)等关系的属性进行了定义。
对于软件平台实体之间的关联关系定义如下:
Correlation Information
Dependency relationship={(Class,Class),(Class,Interface)}
Association relationship={(Class,Class),(Class,Interface),(Class,Interface),(Method,Method)}
Aggregation relationship={(Class,Class)}
Inheritance relationship={(Class,Class),(Interface,Interface)}
Realize relationship={(Class,Interface)}
Call relationship={(Method,Method)}
Inclusion relationship={(Package,Class),(Package,Interface),(Class,Method),(Interface,Method)}
Method parameter={(Method,Class),(Method,Interface)}
Return value={(Method,Class),(Method,Interface)}
2.2 知识抽取
本文使用QDox[12]工具从软件平台开发代码中抽取了类、接口和方法定义,在获取到以上信息的基础上再通过递归的方式进行剩余信息的获取。将java文件或者包含java文件的文件夹加载到QDox后执行迭代,采用不同的方法从源代码中提取不同种类的元数据,包括给定源中的包、包中的所有可用类、类中定义的方法、方法内的返回类型、方法可用的所有参数和返回方法的类型等。
QDox的输出信息以字符串的形式存储元数据,随后将抽取到的元数据根据Schema层定义的顶层框架进行相应的实体填充。本文面向CIFLog3的HWGeoModel模块抽取出的部分实体信息如表1、表2所示。

表1 HWGeoModel模块实体统计表
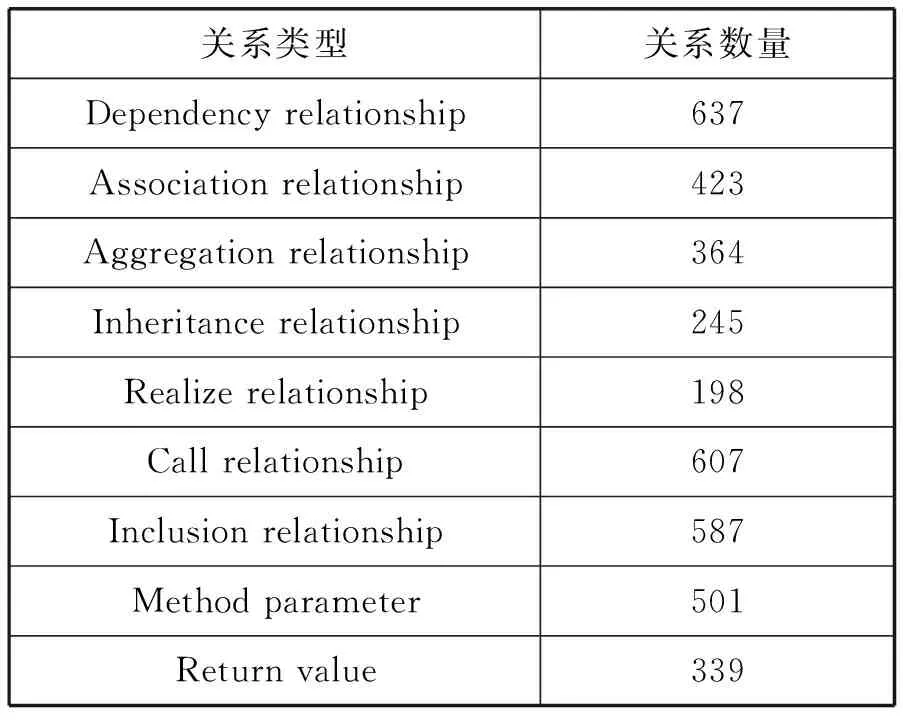
表2 HWGeoModel模块实体关联关系统计表
2.3 知识表示
知识图谱是一种图的网络结构,因此知识图谱模型可以使用W3C提出的RDF或者属性图来进行表示,本文选用支持图数据库的属性图模型来对软件平台知识进行形式化表示。
图3描述了一个OrientDB的属性图模型,开发代码中的类“GeoModelUtils”与方法“GetWgWell”之间的关系是“E_HasMethod”。其中:@rid是唯一标志符;@class是实体类型,也就是对应的概念类;out对应的是头节点即“Class_code”节点;in对应的是尾节点也就是“Method”节点;“Name”等键值对应的则是对于对应节点属性的描述。

图3 属性图实例
2.4 软件平台知识融合
知识融合是软件平台知识图谱必须考虑的重点。虽然本文中的数据源仅为软件平台本身,但由于软件平台需要不断更新,知识图谱的构建过程就避免不了直面知识之间的冲突与不一致性,因此在进行知识融合之前要进行知识评估的操作。本文采用基于模糊集理论的知识评估方法[13]对软件平台知识集合X={x1,x2,…,xN}进行评估,主要经历gλ模糊测量、知识融合和最优决策三个步骤。

gsp(Y)=P(Y|Y)
(1)

2) 知识融合。知识融合通过式(2)的模糊积分实现[14-15],其计算不同知识源提供的知识的最大一致化程度,模糊积分中的隶属函数实现对知识源观测值的模糊化,隶属函数根据实际情况进行选取。设软件平台知识实体集合为X={x1,x2,…,xN},其Borel域为φ,h为软件平台知识的隶属函数,h:X→[0,1],则在A⊆X上的模糊积分的计算公式如下:
(2)
g需满足以下条件:


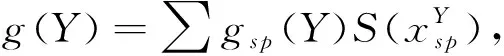
(3)
3) 最优决策。对于软件平台知识实体集合X={x1,x2,…,xN},最优决策是指通过融合处理后最优判断的估计结果。经过以上步骤,发现Y对g(Y)的值有着正向影响,因此有知识融入判别式:

(4)
经过以上有关模糊积分的计算就完成了软件平台知识质量评估,并找到置信度最高的知识作为正确知识,并对数据库中存储的知识实体进行知识节点的完善和更新。
2.5 知识存储
本研究选用OrientDB图数据库进行数据存储,选用它的原因在于其支持多种模式,可以对图形、文档、关系等进行较好的存储和形式化表示,也可以为图数据库的管理提供桥梁,同时它支持SQL语句和类SQL语句。应用OrientDB对从软件开发代码中获取到的实例层数据进行知识整合和存储时需要先创建模式,根据前面对Schema层的定义,创建概念类包括项目(C_Project)、包(C_Package)、代码类(C_Class)、方法(C_Method)、有包(E_HasPackage)、有类(E_HasClass_Code)、有方法(E_HasMethod)。
创建好模式之后则需要根据Schema层定义的类载入节点信息以及节点之间的关系。在导入数据信息时为了防止重复的节点信息和重复的关系,使用SQL查询语句进行是否重复的判断,并进行去重处理。
2.6 知识图谱可视化
OrientDB支持的图结构可以满足开发人员对知识的检索。在OrientDB上可以直接使用SQL语句进行知识查找,查找结果将以图形的形式表示出来,包括节点与关系,同时对不同的知识类别的展示有颜色上的区别。
图4列出了在CIFLog知识图谱中对水平井解释模块“HWGeoModel”的图形可视化检索结果,包括其下包含的包、其存储位置,以及与其有关联关系的其他模块。图4中间的三个节点代表CIFLog中的模块,从左到右分别是多井评价模块、水平井解释模块和数据管理模块,外圈颜色深浅不同的实体分别代表多井评价模块、水平井解释模块和数据管理模块下的包。

图4 “HWGeoModel”模块形式化检索结果
图5为编程人员对“GeoModelUtils类”的图形可视化查找结果,图中显示了与该类有关的其他元数据,如:所属包、调用的方法、属性(图中显示的是其存储路径),以及与“GeoModelUtils”调用了相同方法的类以及他们之间的关系。图中“wellData”、“getWgWellLog”和“getWgWellLog”三者之间的关系如下:“wellData”调用了“getWgWellLog”方法,然后将其返回值返回给“GeoModelUtils”继续使用。

图5 “GeoModelUtils类”形式化检索结果
图6为对水平井解释模块下的“cif.hwgeomodel.wizards”包的检索结果,图中列出了该包中包含的类(Class_code),以及其所属的项目。

图6 “cif.hwgeomodel.wizards”包形式化检索结果
3 结 语
本文针对软件平台开发过程开发人员难以直接利用软件平台知识的问题,提出构建软件平台知识图谱的方法,并构建了CIFLog软件平台知识图谱实例对该方法进行了验证。实验证明,构建软件平台知识图谱能够对软件平台开发知识进行体系化的表示,极大地提高了软件开发人员对平台结构知识的理解和使用,方便了开发人员基于软件平台的开发工作。
软件平台知识图谱的构建是一个阶段性的过程,随着软件平台的更新,知识图谱也应做出变化。软件平台知识图谱需要改进的地方还有很多,比如软件平台的知识获取方法、软件平台知识学习以及知识更新机制等。
猜你喜欢
军事文摘(2022年16期)2022-08-24
舰船科学技术(2022年11期)2022-07-15
技术与创新管理(2020年5期)2020-10-09
商情(2020年24期)2020-06-30
科学与财富(2019年27期)2019-10-25
中国信息化周报(2019年18期)2019-06-09
新城乡(2018年6期)2018-07-09
科学与财富(2017年28期)2017-10-14
电脑爱好者(2015年6期)2015-04-03
计算机世界(2009年32期)2009-09-30
