
PCANet下的遮挡定位人脸识别算法*
2019-12-19 17:25:08白文硕曲海成
计算机与生活 2019年12期
郭 伟,白文硕,曲海成
辽宁工程技术大学 软件学院,辽宁 葫芦岛 125000
1 引言
人脸识别的众多先进算法大多都是基于实验环境中,在可控的参数范围中进行一系列的研究,并且取得了非常好的效果,但是真实环境中遮挡的存在大大限制了人脸识别的精度,很多算法对于遮挡人脸并不具有很高的识别率。遮挡主要分为物理遮挡、光照遮挡、姿态遮挡等,由于人脸识别的大部分算法都是基于特征描述,因此物理遮挡成为了识别精度最大的挑战。要想使人脸识别技术在自然环境下也具有很高的效率及准确率,遮挡问题的解决是研究过程中不可避免的任务。
对于遮挡人脸的研究,国内外学者从未停止过脚步,最早的Oh和Lee等人[1]利用改进局部特征的方法将未遮挡区域形成新的投影空间,在此新的投影空间上进行人脸识别,但是这种方法的人脸特征容易随遮挡特征的舍弃而损失。而后,Wright等人[2]提出的基于稀疏表示的人脸识别方法(sparse representationbased classifier,SRC)是非常具有代表性的子空间回归方法。将稀疏表示应用于人脸识别,把不同人脸的训练样本组合得到训练样本字典。而此训练样本字典是稀疏的,通过求解稀疏表示,利用重构误差来判别测试样本的类别,但是此算法对于特征并不敏感,而是依赖于图像的维数。为此Wright等人进而提出鲁棒的SRC 模型(robust sparse representation-based classifier,RSRC)[2],但是此类方法对于遮挡外的非人脸因素影响很敏感,容易导致鲁棒分类器的混乱,引起局部混叠。SRC 和RSRC 都是建立在最小ℓ1范数基础上,因此对于维数过高时计算会很困难。胡正平等人[3]提出的Gabor特征集结合判别式字典学习的稀疏表示图像识别将不同方向、不同角度的Gabor,通过降维增广Gabor特征矩阵,学习该字典构成新的结构化字典,提高了对图像光照遮挡、表情遮挡的识别率,但是对于图像含有过多噪声的情况算法性能不太理想。Dai等人[4]提出了结构化稀疏误差编码的遮挡人脸识别算法,这类方法考虑了实际遮挡形状结构信息,提高了算法对于遮挡的鲁棒性,但是不足的是对于样本要求过高,要求训练字典中不能存在遮挡,而现实中的大量遮挡人脸样本无法利用。对于特征提取方面,主成分分析(principal components analysis,PCA)对于人脸特征的表示和提取以及在人脸复原方面有着很大的优势。Wei等人[5]提出的基于鲁棒主成分分析(PCA)给出了人脸图像训练字典的学习方法,以及Luan等人[6]的研究完成了遮挡人脸的复原,但是此类方法太过于依赖训练样本,过少的训练样本将不能“稀释”图片的遮挡信息[7]。近年来深度学习的发展[8]使人脸识别算法有了突破性进展,具有代表性的有DeepID[9]、FaceNet[10]等。栗科峰等人[11]的融合深度学习与最大间距准则的人脸识别方法使用深度学习降低线性判别的误差,最大间距准则获取更有代表性的高层特征描述,但是这种方法在小范围特征变化能够取得很好效果,一旦特征变化范围变大,算法并不能表现出很好的性能。很多学者致力于将深度学习应用到人脸识别中[12-13],研究发现[7]即使图像遮挡部分较多,使用深度学习浅层特征仍然能够有着非常好的效果,然而在遮挡存在位置不确定的情况下会严重影响算法性能,因此遮挡的存在比遮挡特征干扰对于算法有着更严重的影响,计算机视觉对遮挡的感知仍然是困难的,因此让深度学习模型能够以某种方法确定遮挡位置,势必会提高遮挡人脸的识别率。相比于传统算法,本文使用了简洁高效的PCANet 深度模型,PCANet 模型把卷积核的获取方式从手工设置改为自主学习,使之卷积之后即使只具有两层的简单结构,但是对于特征的表达仍有着非常好的效果。与此同时,本文为深度学习设计了遮挡存在判别,使深度模型提取特征时减少了遮挡特征的干扰,以此中心思想设计的算法能够有效提高遮挡人脸识别的准确率。
2 PCANet
随着人工神经网络的研究,深度学习的概念被提了出来,而Chan等人[14]于2015年底提出的PCANet最重要的贡献就是将子空间回归引入深度学习,为卷积神经网络卷积核的学习提供了新的思路,又将卷积神经网络(convolutional neural networks,CNN)的卷积层引入经典的“特征图(feature map)-模式图(pattern map)-柱状图(histogram)”的特征提取框架。本质上,PCANet 是一个基于CNN 的简化Deep Learning模型,具体结构如下。
(1)第一层(PCANet),如图1。
Fig.1 PCANet first layer structure图1 PCANet第一层结构
对于图像的每个像素都用k1×k2的块采样进行采样,然后级联表示第i张图片:

式(1)中,mn为图像的高宽数值,采样过后就变成了mn个k1×k2大小的Patch,将这些Patch去平均:

式(2)处理完了单张图片的特征提取,将训练集N张图片进行以上操作就得到了矩阵Χ:
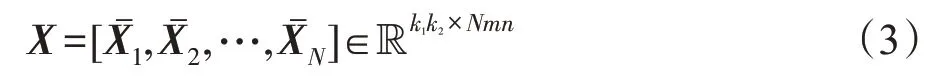
式(3)中,每列代表一个Patch,一共有Nmn列。对这个矩阵Χ进行PCA,假设滤波器的数量为L1个,寻找列的标准正交矩阵来最小化重构误差。

所对应的滤波器如式(5),输出图像如图2。


Fig.2 PCANet first layer image图2 PCANet第一层图像
(2)第二层(PCANet),如图3。

Fig.3 PCANet second layer structure图3 PCANet第二层结构
首先计算第一层的PCA映射输出:

需要注意的是在此需要进行边缘补零操作,以保证映射结果与原图像大小相同。下面的操作与第一层相同,都是对输入矩阵进行采样、级联、去平均,只不过这里的输入矩阵是第一层的映射输出,如式(7)。

所对应的第二层滤波器:
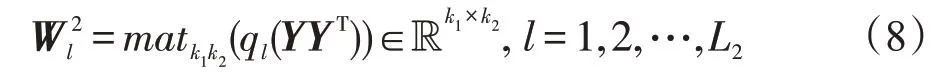
第一层具有L1个滤波器,产生L1个特征输出矩阵,第二层针对第一层的每个特征输出都会产生L2个特征输出矩阵,因此两层的PCANet最终对于每一个样本,会产生L1×L2的特征输出矩阵如式(9),输出图像如图4。


Fig.4 PCANet second layer image图4 PCANet第二层图像
(3)输出层
对第二层的每个输出矩阵进行二值化哈希编码,编码位数与第二层滤波器相同。

这里H()是跃阶函数,λ=1,2,…,L2是第二层的滤波器数目。
将第一层的每个输出矩阵分为B块,统计每个块的直方图信息,然后级联各个图的直方图特征如式(11),最终得到块扩展直方图特征,图像如图5所示,其中图(a)、(b)为部分直方图特征可视化图像,图(c)为级联所有直方图特征可视化图像:

由此,就完成了对于一张图片的特征提取。
3 PCANet下的遮挡定位人脸识别
本文针对人脸识别中的遮挡问题提出了一种PCANet 下的遮挡定位人脸识别算法,首先训练一个特征点检测分类器用于提取训练集中的特征点,根据检测结果截取人脸特征区块,对每一类特征区块分别进行PCANet特征提取,并根据现实中的主流遮挡情况进行特征拼接和补零操作,将操作之后的特征矩阵输入SVM 分类,形成模型。针对不同遮挡情况,选择不同特征区块生成模型,组成模型组,此模型组基本上包括了所有自然环境中的遮挡情况。训练一个遮挡检测分类器,用于判别某一个人脸特征区块是否属于遮挡,进行遮挡定位,根据判别情况选择调用相应的模型进行识别。简单算法流程如下:
Fig.5 Histogram feature图5 直方图特征
(1)对于训练集F(n)
含有n个样本:

将训练集进行特征点检测,分块:
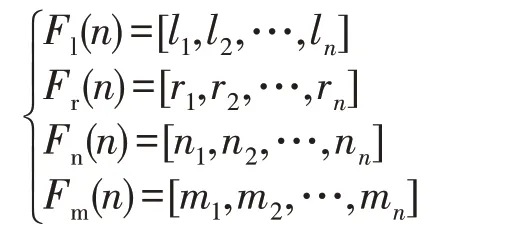
其中,Fl(n)、Fr(n)、Fn(n)、Fm(n)分别为左眼、右眼、鼻子、嘴的样本。此时为同一张人脸的不同特征区块打上相同的标签。
进行PCANet特征提取得到区块特征fleye、freye、fnose、fmouse。
根据实际遮挡类型将不同特征点组合拼接进行SVM训练:
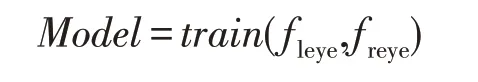
仅举一例,后文会有更详细叙述,Model为训练好的模型,train为训练过程,不同特征点组合训练形成模型组,以此模型进行之后的识别工作。
(2)对于测试集G(m)
含有m个样本:

进行特征点检测,同上文得到Gl(m)、Gr(m)、Gn(m)、Gm(m)。
将样本一一输入遮挡检测分类器,定位遮挡位置,并对于遮挡的区块特征置0,其他特征组合拼接,进行特征提取,得到测试集的fleye、freye、fnose、fmouse。
根据遮挡的位置,选择训练阶段不同的训练模型进行SVM标签预测。

其中,xLabel为预测到的标签,也就是样本最终归属类,predict为训练过程。
算法流程如图6所示。
3.1 预处理
本文使用AR数据集作为实验图片,对实验图片进行预处理,包括几何归一化,多余背景部分剪切,部分图片调整大小,保证最终的训练图片干净无遮挡,无大量多余背景,图片大小为165×120。
本文基于Viola-Jones 算法[15]训练了一个级联分类器,使用Haar特征对人脸特征进行检测提取,如图7所示。由于检测结果带有坐标,因此很容易截取到所检测的图像,截取时调整大小,实验后表明,各个特征点区块调整如表1大小可以在保证纹理特征不变性的情况下方便计算。
截取后的图像如图7。

Fig.6 Algorithm process diagram图6 算法过程简图

Fig.7 Intercepting each feature point image图7 截取各特征点图像

Table 1 Characteristic block size表1 特征区块大小
3.2 特征提取
本文使用PCANet深度学习模型进行特征提取,由于本文针对于人脸识别中的遮挡问题,以及涉及到后面特征对齐问题,对此深度学习模型进行如下的参数改动:
数据集输入图片大小调整为50×50;
直方图重叠区域调整为0;
滤波块大小长宽都调整为7。
以此参数为基础,将左眼、右眼、鼻子、嘴等四类训练数据集分别输入四个PCANet深度学习模型,进行特征提取,训练的每个模型对应一个特征点,每一类特征点数据集经过PCANet 第一层浅层纹理提取和第二层深层语义提取,最终输出特征f。

式中,右式分别代表左眼、右眼、鼻子、嘴的PCANet训练后特征。此特征集合能够完整地表示出一张人脸的所有特征。部分特征提取输出如图8所示。

Fig.8 Feature extraction image of each feature point图8 各特征点的特征提取图像
3.3 遮挡检测分类器
本文使用多分类支持向量机(SVM)训练了一个遮挡检测分类器,用于定位遮挡位置,分类器使用RBF 核函数作为转换函数,使用参数寻优(SVMcg-ForClass)初步确定γ参数g和惩罚因子C,用十折交叉验证对比不同的Cg组合寻找到最优的参数C和g,使用所得最优参数训练SVM分类模型。细节数据在4.2节中具体叙述。
将图片分为眼睛类、鼻子类、嘴类和遮挡类。使用此遮挡检测分类器能够将输入的图片判断是属于特征类(眼睛、鼻子、嘴)还是属于遮挡类(遮挡、背景)。
分类器训练依照正负样本数量可以分为两类情况,由于共四类数据集,取其中一类作为正样本,其余类作为负样本,因此每个分类器聚类数为2。正负样本又有如下情况:
(1)正样本∶负样本=1∶1
确定正样本大小,将其余各类数据集平均抽取数据组合达到与正样本相同大小,这样做仅需一个惩罚因子C,并且在不丢失特征的情况下降低计算量,提高运存速度。
(2)正样本∶负样本=1∶n
将所有的正样本类外的数据作为负样本使用,这种情况为提高准确率应该为正负样本取不同的惩罚因子C。好处是完整地利用了各类样本集每一个样本特征,缺点是大大增加了计算时间。
本文使用未被遮挡的各类特征点图片、带有遮挡的特征点图片以及背景图片作为训练集,使输出结果能够明确区分某一特征点遮挡与否。例如,一张左眼的图片输入分类器,分类结果将其划入眼睛类,说明此左眼没有被遮挡,可以进行识别等操作。另一方面,如果某一数据分类结果划入遮挡类,说明此特征点区块存在遮挡,则不参与后续识别任务。具体如图9所示。

Fig.9 Block detection classifier classification diagram图9 遮挡检测分类器分类简图
经过遮挡检测分类器的判别,可以明确知道一张完整人脸哪个特征点区块被遮挡,哪些未被遮挡,这些信息是后面选择模型进行识别时的基础。
3.4 SVM模型组
本文使用线性支持向量机调用libsvm[16]库,为数据特征进行SVM模型训练。对于有遮挡人脸识别任务,由于每张测试数据遮挡位置的不同,识别它的模型也应做相应改变,如果每个数据都要根据具体遮挡情况进行模型训练,单张识别速度会变得极慢,效率也会急剧降低。
针对此情况,以及根据现实中实际人脸发生遮挡高频区域,将遮挡情况进行分类,分别训练模型,最后再组合,形成模型组。此模型组基本包括了自然环境中所有类型遮挡造成的特征差异情况。测试时,单张数据集在经过遮挡检测分类器后,确定遮挡位置,调用不同模型进行识别,大大增加了识别速度以及算法效率。
现实环境中高频发生的遮挡主要有面部上方遮挡,主要是长发、墨镜遮挡等;还有面部下半区遮挡,主要有围巾、口罩等。
将每类特征点区块提取的特征f集合,记为F,作为模型训练的输入。并在此部分对训练集进行添加标签处理,一张人脸的不同特征点图片添加为一类标签。
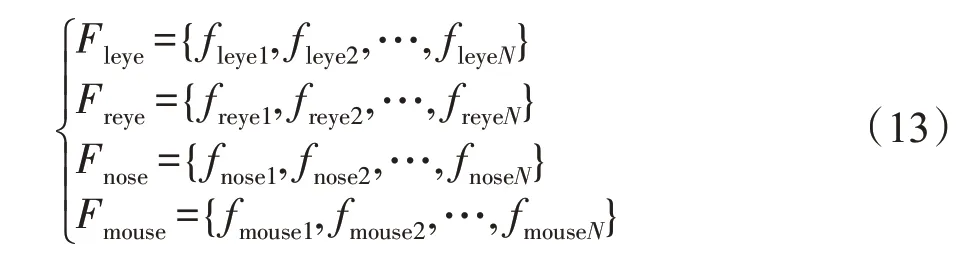
式中,F代表各类特征点的特征集合,N为训练集的数目。
对于面部上方遮挡类型,视为左眼、右眼被遮挡,意味着此部分不参与识别。将视为遮挡部分的特征置零,并用和该特征表示矩阵相同大小的零矩阵将其补齐,这样就保证了测试集识别过程中所提取的特征和进行模型训练的特征维数相同,将训练过后的特征进行拼接,如式(14)。

其中,F1表示眼睛遮挡模型训练的训练输入,放入SVM中进行模型训练,输出为Model1。Model1为完成针对眼睛遮挡测试数据的识别任务。
对于面部下方遮挡,与上文思想相同,针对围巾、口罩等遮挡进行SVM 模型训练。训练两个模型Model2、Model3,如式(15)、式(16)。

其中,F2表示嘴部遮挡后的模型训练输入,其输出为Model2。能够完成测试数据为嘴部遮挡的识别任务。

其中,F3表示嘴和鼻子遮挡的模型训练输入,输出为Model3,完成相应的遮挡识别任务。
以上模型都是保留两个以上的特征点,所遮挡的特征点也是自然环境中最容易发生遮挡的位置,另外一些极端情况下的识别效果,后文也会有提及。
3.5 复杂度分析
(1)时间复杂度:由于算法各功能部分采用顺序结构,因此分别估算部分重要代码的时间复杂度,采用加法则得到总时间复杂度。
特征点检测:T1(n)=O1(1)
特征提取:T2(n)=O(n4+n3+n2+3n+1)=O2(n4)
SVM训练:T3(n)=O3(n)
识别过程:T4(n)=O(n4+3n+1)=O4(n4)
总时间复杂度:T(n)=T1(n)+T2(n)+T3(n)+T4(n)=O(2n4+n+1)=O(n4)
(2)空间复杂度:算法耗费存储空间最大时是在训练和识别过程前预分配样本存储的存储空间。
空间复杂度:S(n)=O(2n)=O(n)
4 实验结果
4.1 特征点检测实验
本文的特征点检测实验数据取自AR数据集,取干净无遮挡特征点区块作为正样本,其他非特征点或者非特定特征点的图片作为负样本。例如,手动截取鼻子特征作为正样本,而其他如背景、遮挡以及其他特征点(眼睛、嘴)都作为负样本进行训练,生成不同的.xml 文件针对不同特征点的检测。抽取部分检测结果,如图10所示。

Fig.10 Part results of feature detection图10 特征检测部分结果
4.2 遮挡检测实验
本文遮挡检测实验的实验数据取自YaleB 人脸数据库,因为此数据库包含数据量大,可以更好地完成训练任务,有效防止欠拟合。使用传统二分类方法构造多分类器,例如对于眼睛的分类,将眼睛区块作为正样本,其余特征点和遮挡区块作为负样本,寻找最优平面来仅仅区分这两类,对于鼻子、嘴以及遮挡、背景同样适用这种方法,训练四个分类器组合成多分类分类器,测试数据分别输入四个分类器,会有四种结果,取其中值最大者作为分类结果。
SVMcgForClass设置参数如表2所示。

Table 2 Parameters of SVMcgForClass表2 SVMcgForClass参数
以眼睛类作为正样本,其余类作为负样本。
(1)正样本∶负样本=1∶1
经过参数寻优得到C=0.5,g=0.032,寻优过程如图11。
得到C和g之后,使用十折交叉验证得到稳定准确率,并在其取值范围左右与其他Cg取值组合进行对比。
不同g的取值(C=0.5),准确率如表3。

Table 3 Accuracy of different g when C=0.5表3 C=0.5时不同g的准确率
由实验结果可知,g在0.010~0.039取值范围中识别率最高。
不同C的取值(g=0.032),准确率如表4。

Table 4 Accuracy of different C when g=0.032表4 g=0.032时不同C的准确率
结果可知,C在0.23以上取得最高准确率。但C不应取太高,容易发生过拟合。
(2)正样本∶负样本=1∶n
本文使用正样本∶负样本为1∶3,经过参数寻优得到C=1,g=0.032。寻优过程如图12。
由于正负样本数据量不同,根据正负样本数量比例,为正负样本分别设置不同的惩罚因子,为C1∶C-1=1∶3。
从以上C、g数值的左右范围取值进行十折交叉验证。

Fig.12 1∶3 parameter optimization process图12 1∶3参数寻优过程
不同g的取值(C1=1,C-1=3),准确率如表5。

Table 5 Accuracy under different g表5 不同g取值下的准确率
由表5可知,g取0.020时准确率达到100%,但是在0.020~0.032之间取值都是可以接受的。
不同C的取值(g=0.029),准确率如表6。
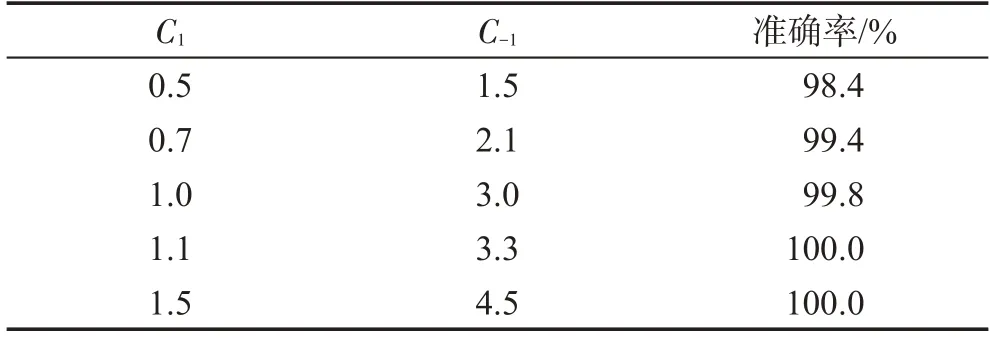
Table 6 Accuracy under different C1C-1表6 不同C1C-1取值下的准确率
由表6可知,C1取值范围在1.0以上时能够达到很高的识别率。还是预防过拟合问题,C1、C-1不应取值太高。
根据得到的最优C、g训练模型,进行模型预测,本文中使用800个样本作为训练样本,200个作为测试样本,进行多次实验,得到实验结果如表7。
综合以上实验可知,训练的遮挡检测分类器,无论样本集正负样本大小是否相同,只要参数选择合适,都能够达到非常好的分类效果。可以根据不同的实际样本情况灵活运用,而实验表明,参数C和g只在一定的取值范围中不敏感,除去上文所述范围,参数的变化都会影响分类器的性能。由于数据量的增大,以及分类器参数设置和本身性能的原因,无法达到100%的识别率,存在极小的误检,这种误检可能会对后面模型组的调用产生影响,但是因为误检率很低并且模型组是由两个以上的特征点特征训练组成,所以能够把特征点误检造成的错误识别降到最低。

Table 7 Experimental results of feature point detection表7 特征点检测实验结果
4.3 有遮挡人脸识别实验
本文的实验数据取自AR 数据集,包括100个人脸(50男人、50女人),每个人包括无遮挡干净人脸、姿态变化、光照变化、各类遮挡变化等26张图片。训练集取每个人脸中没有遮挡的图片8张,这些图片里包括表情变化和光照变化的图片共4张,保证在特征点清晰干净的情况下,提高算法对于姿态、光照的鲁棒性。
对测试数据进行标签化处理,结合遮挡判别分类器进行实验,测试集使用训练好的PCANet深度学习模型提取特征,通过遮挡判别分类器确定特征点是否被遮挡,从而调用模型组中不同模型进行预测,由于测试数据样本数远远小于特征维数,因此使用线性核作为分类器核函数,惩罚因子C默认为1。使用基于最小二乘支持向量机的标签预测进行识别。本文实验取数据集中墨镜遮挡图片、围巾遮挡图片以及自添加遮挡图片(对围巾遮挡图片手动添加鼻子遮挡),并与传统PCANet算法、SRC和Gabor-SRC[17]进行对比。实验结果如表8所示。
围巾遮挡不同算法识别率如图13所示。
对算法进行十折交叉验证。使用crossvalind 函数为训练数据分包,对不同类型遮挡的数据集分为训练集和验证集,评价算法的稳定性和准确性。初始数据为400个样本,分包之后360个样本作为训练集,40个样本作为验证集。分别对上文遮挡类型进行十折交叉验证,并取其平均值,其中,围巾遮挡1次十折交叉验证如图14。

Table 8 Experimental results of facerecognition rate with occlusion表8 有遮挡人脸识别率实验结果 %
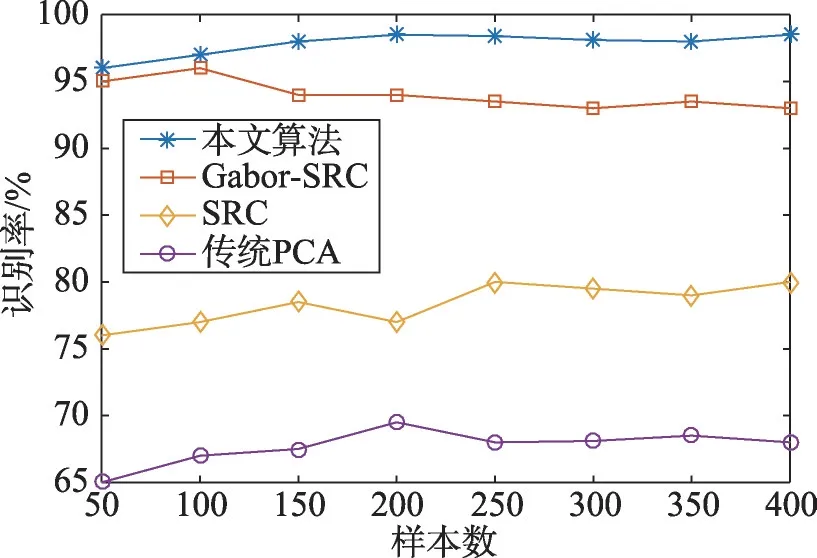
Fig.13 Recognition rate of different algorithms for scarf occlusion图13 围巾遮挡不同算法识别率

Fig.14 One time result of 10-fold cross-validation for scarf occlusion图14 围巾遮挡1次十折交叉验证结果
本文为不同遮挡类型分别作了10次十折交叉验证,取平均值如表9所示。
在交叉验证期间,出现的准确率最低为87.5%,最高为100.0%,算法在一定范围内准确率变化相对稳定,并且准确度比较高。
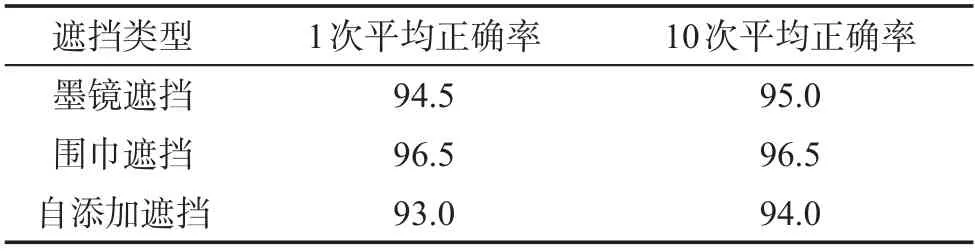
Table 9 Average accuracy of 10-fold cross-validation表9 十折交叉验证平均正确率 %
引入误识率(false acceptance rate,FAR)和拒识率(false rejection rate,FRR)作为算法性能评价指标。对于本文算法,通过调整惩罚因子C来达到调节相似度的目的,事实上,当C=1左右,算法性能基本能达到最优,以此参数调节的相似度作为阈值与其他算法比较,算法评价如表10所示。

Table 10 Each algorithm result of FAR and FRR表10 各算法FAR、FRR结果 %
正确接受正样本比率TAR(true acceptance rate)=1-FRR,一般使用FAR=0.001 00作为参考。由结果可知,算法的TAR=98%@FAR=0.001 00,Gabor-SRC 也能够达到不错的准确率,而传统PCANet方法在没有经过特征点检测分类模型去除遮挡特征的情况下只能达到80%左右。分析:由于传统算法只着重于深层次的特征来表达图像,但是这样对于遮挡特征在处理后很容易和人脸特征相混淆,而遮挡特征又具有一定的相似性,因此容易把遮挡特征当作关键特征进行分类,而本文在保留深层特征提取方式的前提下,把遮挡特征检测出来使之不会对人脸特征造成影响,这是在FAR较低的同时,TAR又能取得较好效果的原因。
上述实验证明,在具有3个特征点未被遮挡的情况下,算法具有非常高的识别精度,在具有两个特征点的情况下也具有很好的识别效果,并以十折交叉验证验证了算法的准确性。值得一提的是,在自添加遮挡的情况下,只有左眼、右眼作为特征进行识别,但是也取得了很好的效果,能够说明眼睛的纹理特征对于人脸更具有识别性。
4.4 极端情况下人脸识别实验
对于某些极端情况,即只保留了一个特征点,在自然环境中存在,但是出现不多,因此在此节单独进行实验,分别针对单个特征点进行PCANet特征提取以及模型训练,实验结果如表11所示。

Table 11 Experimental results of extreme face recognition rate表11 极端人脸识别率实验结果 %
4.5 表情、光照变化下人脸识别的实验
由于在模型训练阶段,刻意挑选具有表情变化以及光照变化的训练数据进行训练,本文算法对其具有一定的鲁棒性,本文对未使用表情、光照变化的样本也进行训练,通过对比得出算法对于具有上述变化的样本图片能够有效提高其识别率。实验结果如表12所示。

Table 12 Experimental results on recognition rate of images with light and expression changes表12 光照、表情变化图片识别率实验结果 %
在将光照、表情图片加入训练样本进行训练后,得到的分类器对光照、表情变化的人脸识别率有着部分提高,相比于着重提高光照表情变化鲁棒性的文献[11]算法虽然光照变化识别率稍低,但是表情变化图片的识别率并未相差太多。由于算法依赖于特征点特征,而将表情变化引起的特征变化作为训练数据输入,能够有效提高对于表情变化的识别率。而且基于PCANet 神经元本身对于光照具有很强的鲁棒性,因此总体上即使幅度较小,但是仍具有一定的鲁棒性。
5 结束语
本文提出一种PCANet 下的遮挡定位人脸识别算法,用深度学习模型结合遮挡检测来定位遮挡位置并进行特征提取,运用libSVM进行模型训练,形成模型组用于解决有遮挡人脸的识别任务。经过实验,本文算法对于自然环境中常见遮挡具有很高的识别率,对于一些极端遮挡也具有很好的效果,并对光照、表情具有一定的鲁棒性。
猜你喜欢
作文中学版(2022年1期)2022-04-14 08:00:34
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
学生天地(2020年31期)2020-06-01 02:32:06
动漫星空(2018年9期)2018-10-26 01:17:14
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
计算机工程(2015年8期)2015-07-03 12:19:07
发明与创新(2015年33期)2015-02-27 10:40:09
奇闻怪事(2014年5期)2014-05-13 21:43:01
