
多种表示的图像分类方法*
2019-12-19 17:25:06陈德运付立军张学松陈海龙
计算机与生活 2019年12期
陈德运,付立军+,张学松,于 梁,陈海龙,李 骜
1.哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080
2.北京兆芯集成电路有限公司,北京 100084
3.酒泉卫星发射中心,甘肃 敦煌 736200
1 引言
机器学习是图像分类、人工智能和计算机视觉方面重要技术[1]。图像分类是机器学习的一个重要应用。它已经被广泛地应用到国防、公安侦查、电商以及人脸识别等领域中[2]。
然而,图像分类技术在真实的应用中仍然面对诸多挑战,尤其是人脸识别技术,如:变化光照、不同程度的遮挡和多变的面部表情等。因此,如何更好表示图像和提高图像分类识别率成为学术界研究的热点话题[3]。近20年来,许多专家和学者提出大量不同方法来解决以上难题[4-5]。其中,人脸识别问题是图像识别的一个典型问题。利用嘴和眼睛等特征组合来识别个人身份,该方法被命名为几何方法,该方法是简单和容易实现的[6]。然而,它忽略了图像各个部分之间的联系,导致它在遮挡条件下识别个人身份是无效的。为了解决此问题,利用整张人脸全部信息来进行人脸识别,该方法被称为基于表象的方法[7]。其中,主成分分析(principal component analysis,PCA)是典型的基于表象的方法,它能用不同的向量来表示整张图像,并把求得协方差矩阵的特征作为图像的特征[8]。PCA 方法有效地保留图像的关键特征,同时在光照、变化表情上获取不错的效果。然而,PCA忽略了图像各个部分之间的关系;PCA用向量表示导致原图像的部分关键特征丢失;该算法具有较高的复杂度。为了弥补PCA的缺点,使PCA发挥出更好的效果,Yang等人[8]提出把整张图像用矩阵表示,并用协方差来获取图像特征,该方法被称为二维主成分分析(two-dimensional principal component analysis,2DPCA)。该方法不仅提升算法识别率,而且大大地提高了算法识别速度。
为了进一步提高图像分类的精确率,由感知理论得到的稀疏算法成功地应用到图像分类中[9]。最初的稀疏算法的原理是假设一个给定的测试样本可以由所有训练样本线性表示,并获得线性表示的系数。在分类时,利用每类的所有训练样本和系数来获得预测值,所有类的预测值与给定测试样本做差(2范式运算),差值最小的类别即给定测试样本的类别,这钟方法被称为一般稀疏算法。稀疏方法在图像分类上获得巨大成功。然而,最初的稀疏表示在获得线性表示的系数时用的1范式求解,增加了算法的复杂度,严重地降低算法的效率。Zhang 等人用2范式来求线性表示的解,有效地提高算法运算效率,该算法被称为协同表示方法[10]。1范式的一般稀疏算法比2范式的协同稀疏方法更加稀疏,但是协同稀疏比1范式的一般稀疏具有较低的时间复杂度。因此,结合它们各自优势运用在图像分类或图像识别上是一个趋势[11]。本文在第3章会详细介绍一般稀疏算法和协同表示方法。除此之外,逻辑回归方法也被用到图像分类并取得不错的效果[12]。Xu等人提出利用减少噪声方法来进行图像识别[13]。Qin等人利用加权核方法来抽取图像特征,进而进行图像分类[14]。单一的方法在图像特征提取过程中,在不同场景下会遗漏一些重要特征,因此利用多种方法来表示图像成为近年来的研究热点[15]。
Ross等人[16]利用人脸、掌纹和头部几何来提高生物测量学系统的性能。Jain 等人[17]利用用户具体参数来提高多生物测量学系统的性能。Fei等人提出用低秩和自适应的距离惩罚方法来进行图像分类[18]。也有学者把主动学习和半监督学习结合来识别图像[19]。韩等人提出利用线性判别分析(linear discriminant analysis,LDA)进行图像分类[20]。此外,图像技术在雾霾和美颜相机方面也有很多应用[21-22]。因此,融合方法在模式识别、图像处理和计算机视觉领域研究中有重要的影响[23]。恰当的融合机制能在图像分类中获取好的性能。融合机制已经成功应用到视频检测[24]、图像识别[25]和语音识别[26]等实际应用中。现有的融合机制主要在以下三个水平上进行融合[16]:决策水平、特征水平和得分水平。本文分别介绍三种水平上的融合:决策水平融合是以上三种水平融合中最简单的一种。但它没有用样本的太多信息,导致融合效果不是太好。特征水平融合将原样本的不同特征进行融合,这增加了原样本特性的鲁棒性。但不同特征有时在特征融合过程中产生不兼容的现象。因此,得分融合和其他两种融合方法相比是效果最好的。现有的融合机制能将不同方法所获取到特征的得分进行融合,之后用新得分来进行分类。
基于以上理论支持,本文提出的基于多种表示的图像识别方法是合理的。其具体为:首先,本文利用2DPCA方法来提取图像的特征;其次,利用提取的特征进行图像重构(这里称为虚拟图像);然后,利用FFT(fast Fourier transform)来提取图像的频谱特征;接着,用虚拟脸、获得的频谱特征和原始图像分别利用一般稀疏算法或协同表示进行分类获得得分;最后,利用一种融合机制将获得的三个得分进行融合获得新的得分,同时利用新获得得分和一般稀疏算法或者协同表示进行分类。本文利用加权得分方法将获得的三种不同图像特征进行融合,这能提高图像分类的性能。另一方面,获得的三种不同图像特征是互补的,这使得提出算法享有更好的鲁棒性。本文提出的算法具有稀疏性,稀疏性有利于降低图像分类的出错率。此外,该算法能自动获取参数,无需手动设置,它是简单和容易实现的。本文在AR[27]、ORL[28]和GT[29]等不同场景的公开数据库上设计实验,实验表明,本文提出算法在图像识别上具有低的出错率和在不同场景下具有良好的灵活性与鲁棒性。
本文的主要贡献如下:
(1)从多视角来增强图像分类的性能,提出将频率特征(FFT)与降维特征2DPCA进行融合。
(2)融合FFT特征和2DPCA特征进行图像分类。
(3)采用巧妙的加权机制来融合(2)中特征。
本文组织结构如下:第2章说明多种方法的图像表示;第3章展现多种特征的得分获取、融合以及图像分类;第4章展示提出方法性能;第5章呈现AR、ORL和GT数据库上的提出方法与对比实验结果;第6章给出本文的结论。
2 多种方法的图像表示
2.1 虚拟特征图像的获取
PCA是一种经典的特征提取方法。它是通过把二维图像转化为向量来提取图像的特征。保留图像关键的特征,在图像分类上有较好的精确率。但它用向量表示图像,忽视图像像素点之间的关系,获得的特征可能丢失一些关键信息,同时用向量表示图像效率比较低。2DPCA 方法弥补了PCA 的缺点。2DPCA 主要是通过矩阵来表示图像,然后通过协方差矩阵来提取图像特征进而进行图像分类。2DPCA在图像分类上具有良好鲁棒性,同时还有较低的时间复杂度。本文利用2DPCA 来提取图像的特征,并重构图像(这里称为虚拟图像)来表示原图像[30]。下面具体介绍虚拟图像的构建过程:
这里假设每幅图像的大小为m×n,图像用矩阵A来表示,A的映射向量为m,矩阵A提取的特征向量为f,转化过程如式(1)所示:

当mTGtm取得最大时候,f能取得最优。其中,Gt为协方差矩阵。mTGtm最大的取值问题就能被转换为求协方差最大特征向量问题。此特征向量是最大特征值对应的特征向量。
通过式(2)和式(3)求出协方差矩阵Gt。

在式(2)中Aˉ代表所有矩阵的平均值,N代表矩阵的个数。假设协方差矩阵Gt的特征向量为v,本文能通过特征抽取来构建虚拟图像,具体如式(4)所示:

在式(4)中Y′代表虚拟图像。获得虚拟图像和原图像形成互补,提高图像分类的准确率。将在第4章展示虚拟图像。
2.2 频谱特征图像的获取
FFT 是机器学习、计算机视觉、人工智能的重要技术。本文用FFT来提取图像频谱特征[31],它表示原图像的流程如下:
FFT是高效和快速的离散傅里叶算法,即FFT算法是离散的傅里叶算法。下面先说明离散的傅里叶算法(discrete Fourier transform,DFT)的推导过程[31]。假设S(k)代表长度为L的有限序列。



根据式(7)中FFT 的奇偶性,这样能近一步转化式(8)。

然后,根据k的奇偶性来简化式(7)。当k是偶数,令能进一步简化式(7)。在式(7)中分别定义序列x(n)的奇数项x1(n)和偶数项x2(n)。

当k为奇数,令k=2r+1,能进一步简化式(7)为式(10)。在式(10)中

因为灰度图像是二维的,所以需要用二维FFT算法来提取图像特征。二维的FFT 算法以一维FFT 算法为基础。这里假设Ai代表大小为M×N和像素点为f(x,y)的图像。0 ≤x≤M-1,0 ≤y≤N-1,υ=0,1,…,M-1和υ=0,1,…,N-1。二维的FFT提取频谱特征如式(11)。
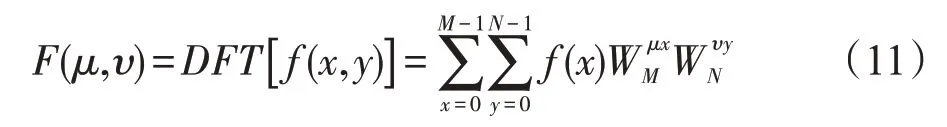
为了更直观地展示FFT特征抽取的过程,用下面伪代码[31]来表示它。

FFT算法用在稀疏表示上有稀疏性,这有利于图像分类,将在第3章展示其稀疏性。
3 多种特征的得分融合与图像分类
3.1 一般的稀疏表示分类方法
稀疏是解决图像分类的最佳方法之一,尤其在解决小样本问题上。稀疏方法是用所有的类别训练样本来线性表示测试样本,并求出线性组合的系数,然后用每类的所有训练样本和给定的测试样本来计算每类的残差,残差最小即测试样本就属于这类。
稀疏方法的具体流程如下[32-33]:假设c代表样本的个数,Ai代表第i类别的所有训练样本。令A=和y代表一个测试样本。这个测试样本y能被表示为y=Aw。系数w越稀疏,y的类别就越容易被划分。因此能获得稀疏解,如式(12)所示:

通过式(13)能求出线性表示的解,用每类的所有测试样本和获取的系数来重构预测的测试样本代表第i类预测出来的测试样本,如式(13)所示:

利用式(14)计算重构第i类的误差ri(y)。

由文献[31]可知,式(13)中稀疏解的具体表示形式如式(15)所示:

由式(16)可以量化式(15)表达式:

在式(16)中,1 ≤j≤M,a(j-1)n+i代表Ai第(j-1)n+i个元素。算出所有类别中最小的即为测试样本的类别,在3.3节中具体说明图像怎么得到类别。
3.2 协调的稀疏表示分类方法
一般稀疏表示在图像分类中有较好的效果,但它有高的算法复杂度。协同的系数表示能有效解决这个问题,求解部分几乎和3.1节的相同,只有在求解稀疏系统时候协同稀疏表示用的2范数求解,具体如下:

3.3 多种方法的图像得分融合和图像分类
根据前面介绍理论基础可知,得分融合是一种有效提高图像分类精确度的方法。本节利用一种新的融合机制[33]来融合2DPCA、FFT和原始图像的得分并利用稀疏方法进行分类。其实现原理如下:
利用一种新的融合机制[11,34-37]来融合它们得分,新获得的得分为r,具体如式(18):

在式(18)中,r1代表2DPCA 方法在协同表示分类(collaborative representation classification,CRC)(fast iterative shrinkage thresholding algorithm,FISTA/L1 iterative soft thresholding algorithm,LISTA)上获得得分,r2代表FFT提取的频谱特征在CRC(FISTA/LISTA)上获得的得分,r3代表原始图像在CRC(FISTA/LISTA)上获得的得分。
前面的研究已经说明这种融合机制是合理的[11,16],用式(19)来分类。如果,本文提出方法认为测试样本y属于第g类[11]。

本文提出的方法有以下优点:(1)在不同情景下具有高的图像分类精确率。(2)获取的多特征和原始图像进行了互补,这使获得算法更具有鲁棒性。(3)提出方法具有稀疏性,提高了图像分类的性能。(4)它能自动获取参数,不需要手动调参。(5)本文方法是简单和容易实现的。
4 算法性能展示
本文有效地将2DPCA、FFT 提取的特征和原图像相结合来进行图像分类,为了使读者直观可视化了解本文的原理,在本章分别展示2DPCA 的虚拟图像、FFT和稀疏融合后的稀疏系数。
由于2DPCA 方法在图像处理、计算机视觉和模式识别上被广泛地应用,本文用2DPCA 方法[30]提取图像的特征,并通过特征抽取的方法重构虚拟图像。虚拟图像和原图像信息互补,虚拟图像有利于提高图像分类的准确率,虚拟图像[30]如图1所示。

Fig.1 5 original images and corresponding virtual images from ORL database图1 来自ORL数据库的5幅原始图像与对应虚拟图像
在图1中,上边5幅图是虚拟图像,下边5幅图像是ORL数据库的原人脸图像。
FFT 方法是快速和高效的DFT 方法。它在信号处理和图像处理上取得良好的性能。FFT 方法分为时间算法和频率算法,本文用到FFT频率算法,提取的频谱特征能有效表示原图像,它和稀疏方法融合具有稀疏性,稀疏性有利于提高图像分类的精确率。从图2中可以看出,FFT在CRC上向量解中大部分元素值都接近0,这再次说明本文方法具有稀疏性。
Fig.2 Sparse solution of FFT on CRC图2 FFT在CRC上的稀疏解
5 实验结果
为了测试本文方法的性能,用ORL、GT和AR数据库来设计实验。为了展示本文提出方法在图像分类上的高精确率,用快速迭代方法(fast iterative shrinkage thresholding algorithm,FISTA)[37]、协同表示分类(collaborative representation classifier,CRC)[35]、迭代收缩阀值方法(iterative shrink thresholding algorithm,ISTA)[38]和MPSR(multiple representations and sparse representation for image classification)[36]来制作对比实验。在表1~表3中,FFT+2DPCA+Original images+CRC(FISTA/LISTA)代表FFT、2DPCA 和原始图像利用CRC方法分类,之后进行得分融合。其得分在ORL、GT、AR数据中获得出错率。2DPCA+CRC(FISTA/LISTA)是2DPCA 在稀疏方法为CRC(FISTA/LISTA)时在不同数据集上的分类结果。Original images+CRC(FISTA/LISTA)代表原始图像在ORL、GT 和AR 数据集上用CRC(FISTA/LISTA)进行图像分类的结果。
5.1 在ORL数据集上实验
在本节,ORL数据集[28]被用来测试提出方法的性能。ORL数据库是于1992年4月到1994年4月剑桥大学采集的。该数据库采集于40个人,每个人采集10幅图像。该数据库是在不同的面部表情变化、光照和遮挡条件下采集的。每幅图像的大小为56×46,每幅图像的格式为“.bmp”。图3显示ORL的部分图像。

Fig.3 Partial images of ORL图3 ORL的部分图像
表1显示在ORL 数据集上图像的出错率。在表1中,FFT、2DPCA和原始图像进行融合,在图像中获取低的出错率。在此表中协同表示分类方法用CRC表示。从表1中可知,本文提出方法在ORL 数据集上有低的出错率。如:当分类器为CRC时,本文方法在ORL数据集上每类训练样本的个数从2到5时,方法的出错率为8.13%、8.13%、7.86%、4.58%和6.00%。而原始图像在用CRC分类时,它在每类训练个数为2到5时,它的出错率为19.69%、19.69%、18.93%、14.58%和18.00%。通过表1可知,本文方法比目前主流的方法MPSR[36]和一般的融合方法如LISTA+Gabor[36]效果好,再次证明本文方法在图像识别上具有良好的效果。
本文提出方法明显优于其他经典算法,多种方法加权融合能提高图像分类的性能,具体信息请参考文献[11,16,34,36]。
5.2 在GT数据集上的实验
在本节,GT 数据集[29]被用来测试本文提出方法的性能。GT数据库是佐治亚理工学院在1999年6月1日到11月15日采集的。该数据库采集于50个人,每个人采集15幅图像。该数据库是在不同的表情变化和光照下采集的。每幅图像的大小为40×30,每幅图像的格式“.jpg”。GT数据集的10幅图片如图4所示。

Fig.4 Partial images of GT图4 GT的部分图像
据前面理论可知,提出方法在GT数据集上有低的出错率。如:当分类器为LISTA时,本文方法在GT数据集上每类训练样本的个数从10到14时,出错率为20.80%、21.50%、22.00%、18.00%和18.00%。而原始图像在用2DPCA+LISTA分类时,它在每类训练个数为10到14时,出错率为28.00%、27.00%、26.00%、23.00%和20.00%。本文提出方法明显优于其他经典算法。但是从表2中可知有时用CRC分类不如GT的部分图像FISTA和LISTA效果好,故在实验中要根据不同应用情景灵活运用CRC、FISTA以及LISTA。
在本部分,AR 数据集[27]被用来测试本文提出方法的性能。AR数据库是俄亥俄州立大学在1999年6月1日到11月15日采集的。该数据库采集于126个人,共超过4 000多幅图像。该数据库是在不同的表情变化、光照和遮挡下采集的。每幅图像的大小为50×40,每幅图像的格式为“.tif”,在本实验中训练数据用52个个体,每个个体26个图像。图5显示AR的部分图像。
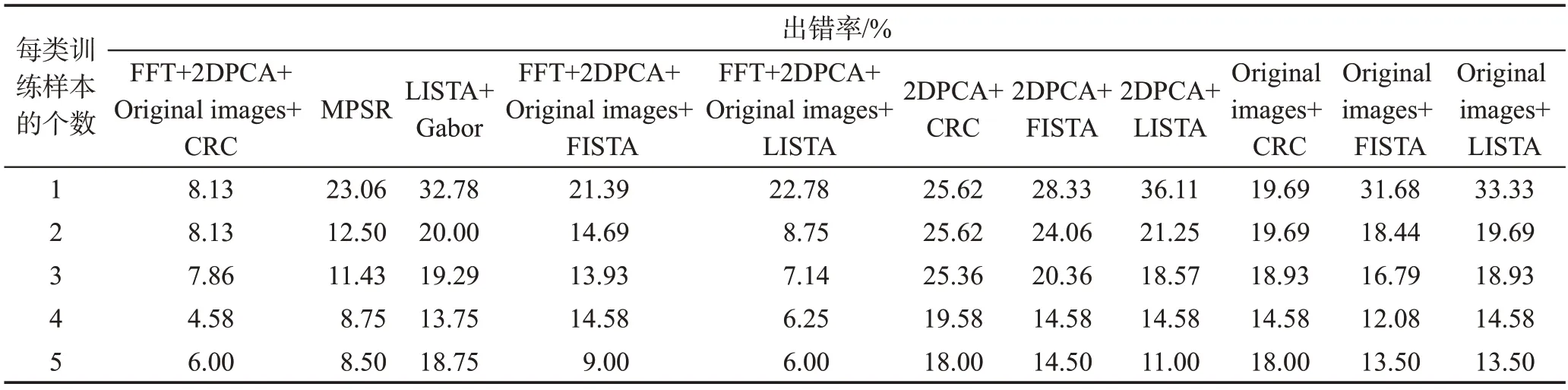
Table 1 Image error rate on ORL dataset表1 在ORL数据集上图像的出错率
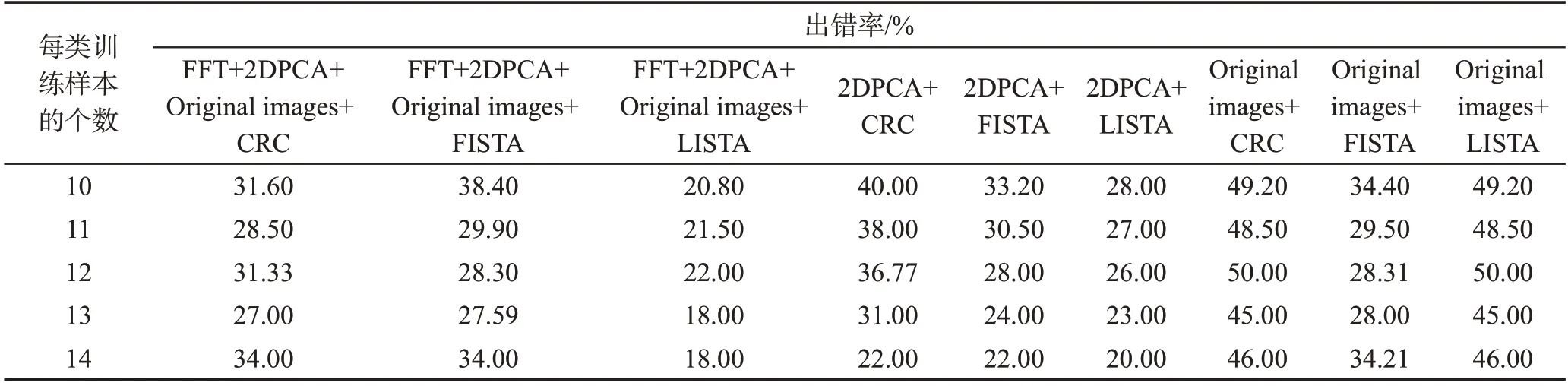
Table 2 Image error rate on GT dataset表2 在GT数据集上图像的出错率

Table 3 Image error rate on AR dataset表3 在AR数据集上图像的出错率

Fig.5 Partial images of AR database图5 AR数据库的部分图像
表3显示在AR数据集上图像的出错率。
在图像中获取低的出错率。在表3中协同表示分类方法用CRC 表示。从表3中可知,提出方法在AR 数据集上有低的出错率。如:当分类器为CRC时,本文方法在AR数据集上每类训练样本的个数从10到14时,本文方法的出错率为25.84%、17.05%、18.68%、19.97%和6.41%。而原始图像在用2DPCA+FISTA分类时,它在每类训练个数为10到14时,它的出错率为51.92%、51.92%、40.93%、39.79%和35.74%。本文提出方法明显优于其他经典算法。但是从表3中可知有时用CRC分类不如FISTA和LISTA效果好,故在实验中要根据不同应用情景灵活运用CRC、FISTA以及LISTA。但从表1、表2和表3可以看出提出的方法在遮挡、不同光照以及面部表情变化上表现出好的性能,因此本文方法具有较好的稳定性和鲁棒性。
6 结束语
本文提出多种方法来表示图像,该方法有效地将多种特征结合起来,这有利于不同情景下图像分类。同时该方法能自动设置参数,而不是手动设置。此外,该方法是简单的和容易实现的。本文提取的方法具有稀疏性,这也是提高图像分类精确率的一个重要原因。通过大量实验证明,该方法具有好的应用性。在今后的研究中,将把稀疏和深度学习相结合来进行图像分类。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
初中生世界·九年级(2020年10期)2020-11-30 09:12:20
学周刊(2019年21期)2019-07-08 03:26:39
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
数学学习与研究(2017年3期)2017-03-09 18:12:42
新高考·高一数学(2016年3期)2016-05-19 09:08:30
