
植物属性文本的命名实体识别方法研究*
2019-12-19 17:24李冬梅
计算机与生活 2019年12期
李冬梅,檀 稳
北京林业大学 信息学院,北京 100083
1 引言
随着互联网的发展,人们对信息质量的要求越来越高,信息抽取、信息检索、机器翻译、知识图谱等领域成为研究的重点。其中,信息抽取的任务是识别并提取文档中特定的事实信息,以结构化、易理解的形式表示,以便用户查询和使用[1]。而命名实体识别(named entity recognition,NER)是信息抽取中一项重要的任务,其目的是识别出文本中表示命名实体的成分,是研究文本中语义知识的基础,对语义分析、智能检索、自动问答和意见挖掘等领域的研究有重要作用[2]。命名实体识别任务早期主要识别三大类实体,消息理解会议(message understanding conferences,MUC)规定三大类实体包括命名实体、时间表达式和数量表达式,其中命名实体分为人名、地名和机构名[3]。在各类评测会议和自然语言处理应用的推动下,命名实体识别任务的目标不断扩展。自动内容抽取(automatic content extraction,ACE)项目对地名和机构名实体进行了扩充,增加设施和地理-政治两种实体[4]。自然语言学习会议(conference on natural language learning,CoNLL)在MUC 定义的基础上,增加了其他命名实体[5]。随着命名实体识别技术的发展,在特定领域下的命名实体识别研究引起了研究者们的重视,对领域命名实体识别的研究逐渐深入,如军事领域[6]、农业领域[7]、商品领域[8]等。
2 相关工作
命名实体识别任务主要的方法包括两大类:一类是基于规则的方法,人工构建有限规则,并从文本中匹配符合这些规则的字符串;一类是基于统计机器学习的方法,一般先给定命名实体的多个类别,从而使用相应的模型对出现在文本中的实体进行分类。
早期的命名实体识别研究采用的一般为基于规则的方法,如Grishman 提出的Proteus 系统[9],Krupka等提出的NetOwl系统[10],Humphreys等提出的Lasie-Ⅱ系统[11]。Collins等则提出了DL-CoTrain方法,预定义种子规则集,接着在语料中对种子规则集进行无监督的训练迭代,从而得到更多的规则,再将得到的规则集应用于命名实体的分类,在人名、地名和机构名三类实体的分类准确率均超过了91%[12]。在中文命名实体识别任务中,孙茂松等根据人名用字、姓氏、人名称谓等信息研究规则集,从而进行人名的识别[13]。谭红叶等利用大规模地名库和文本中地名用字的统计信息,结合上下文信息和不同的规则在地名识别上取得较好的效果[14]。尼扎木丁等针对维吾尔语黏着性特点,从三个角度对单词进行拆分从而将其作为特征加入条件随机场模型中,实现了维吾尔语的人名识别,并且根据维吾尔语中汉族人的人名特点,提出了基于规则的汉族人名识别方法[15]。基于规则的方法虽然对于特定的语料有较好的效果,但是人工定义规则的难度较大,难以制定足够完善的规则来支撑相关应用,存在较多的限制。一方面,在基于规则的方法中,命名实体识别的效果跟规则集的复杂程度息息相关,依靠人工制定大量规则的可行性太低,相应的方法愈发显得笨重。另一方面,规则的领域依赖性太强,在不同领域之间的可移植性很差。
基于统计机器学习的方法不依赖于人工构建的规则,而是考虑文本的各类特征,利用各类机器学习模型实现命名实体的识别。随着机器学习技术在自然语言处理领域的广泛应用,基于统计机器学习的方法成为研究的主流。这类方法可以分为两种思路:一种是首先识别命名实体的边界,再对已识别的命名实体进行分类;另一种是序列化标注方法。Fleischman等综合考虑特征和模型的选择,分析了词频、主题词和WordNet等特征对命名实体分类的影响,并且研究了K近邻、朴素贝叶斯和神经网络等算法在命名实体分类任务中的适应性[16]。Chen等首先利用深度置信网络进行命名实体的检测,接着对检测出的命名实体进行分类,分类准确率能够达到91.46%[17]。上述方法的性能受限于命名实体边界识别的效果,尤其在汉语命名实体识别任务中,命名实体边界的识别准确率对模型整体的效果影响较大。因此,研究者们倾向于采用序列标注的方法进行命名实体识别。
序列标注的方法假设文本中的每个词(汉语中一般为字),存在若干个候选的类别标签,并利用机器学习模型对文本中的每个词进行序列化的自动标注。典型的机器学习模型有隐马尔可夫模型[18](hidden Markov model,HMM)、支持向量机[19](support vector machine,SVM)、最大熵[20](maximum entropy,ME)、CRF(conditional random fields)[21]等。随着深度学习技术的发展,特别是使用词向量来表示词语的方法的出现,给命名实体识别带来强大的发展动力。Peng 等研究借鉴LSTM(long short term memory)在自动分词上较好的表现,提出一种LSTM与CRF相结合的模型,比之前方法的F值提高了5%[22]。Lample 等提出了基于BiLSTM-CRF(bi-directional long short term memory-CRF)和基于转换方法的两种神经网络模型,同时从标注语料和未标注语料中获取特征,在四种语言上均获得了较好的NER(named entity recognition)效果[23]。Dong 等利用深度学习技术,以卷积神经网络作为分类器进行电子病历命名实体的识别,取得不错的结果[24]。此外,先验的知识对命名实体识别任务有较好的促进作用,如知识图谱等。付宇新等利用开源的命名实体系统DBpedia Spotlight进行命名实体识别任务的优化[25]。在原有系统的基础上利用中文相关知识对候选集进行增量式扩展,且在对实体上下文进行特征选择时采用点互信息率的方法,最后通过基于主题向量的二次消歧方法提高了标注的准确率。
鉴于深度学习技术在命名实体识别任务中的良好表现,本文研究如何挖掘和利用植物属性文本中的隐含特征,提出BCC-P(BiLSTM-CNN-CRF model in plant)方法。该方法充分利用BiLSTM模型获取植物属性文本的上下文和时序等信息,并以CNN(convolutional neural network)模型进一步学习植物属性文本的隐含特征,其后经过CRF 模型进行优化得到最终的序列标注结果。本文的主要贡献有:提出了基于BiLSTM、CNN 和CRF 的命名实体识别方法BCC-P;研究了不同模型在植物属性文本命名实体识别任务中的适应性。
3 植物属性文本命名实体识别方法BCC-P
领域命名实体识别需要解决如何对领域命名实体进行建模的问题,通用的命名实体识别模型往往在该问题上存在不足。田家源等通过利用CRF模型和领域词典完成了面向互联网资源的医学命名实体的识别[26]。
中国植物志中的植物属性文本存在较为明显的特点:一是其文本描述方式类似,文本中相同的命名实体存在类似的上下文;二是文本的长度有限,且不同长度的文本分布较为均匀。本文提出的命名实体识别方法BCC-P首先根据现有植物本体和知识库实现语料的半自动化标注,大大减少人工标注的代价,模型结构图如图1所示。BCC-P 的核心部分由基于BiLSTM 的特征提取模块、基于CNN 的特征提取模块和基于CRF 的标注模块构成,实现对植物属性文本多层次的抽象建模。
对于植物属性文本,BCC-P 方法假设输入为一个句子,首先通过WordEmbedding 得到句子的分布式向量表示。接着利用BiLSTM 网络提取句子中的上下文等特征,学习得到句子的隐含特征表示。进一步利用卷积神经网络对句子的隐含特征进行抽象建模,得到句子的深度隐含特征。最后,利用CRF算法对植物属性文本进行序列标注,得到全局最优的标注结果。
BCC-P方法的步骤如下所示。
步骤1对植物属性文本语料进行标注,得到基于字的标注语料,构建算法的训练语料与测试语料。
步骤2对语料中的植物属性文本进行基于字的向量化表示,得到该文本的特征向量。

Fig.1 Structure of BCC-P model图1 BCC-P模型结构图
步骤3将步骤2得到的特征向量输入BiLSTM模块,分别利用LSTM 单元计算前向和后向的状态值,将两个状态值进行拼接得到最终的隐含状态表示h={h1,h2,…,hn}。
步骤4将步骤3获得的隐含状态h输入到CNN模块中,经过卷积层对h进行处理,再经过池化层和全连接层处理,得到植物属性文本的深度特征表示H。
步骤5将步骤4中植物属性文本的深度特征表示H作为输入数据传输到CRF 模块,计算在特征表示为H的状态下,文本在不同标签下的概率,得到得分最高的标签序列。
步骤6计算步骤5得到的标签序列与实际标注结果之间的误差,利用误差函数计算误差对各模块中神经元之间连接权值的影响,对其进行修正。
步骤7计算全局误差。
步骤8判断全局误差是否达到要求,当误差达到要求的精度时结束算法,否则进行步骤9。
步骤9判断学习次数是否达到设定的上限,若达到上限则结束算法,否则从语料中选择其余的植物属性文本以及对应的标注信息,重复进行步骤2到步骤9的学习过程。
BCC-P 方法先对植物属性文本进行建模,根据文本中命名实体与上下文之间的关联关系,提取文本中上下文依存的特征。进一步对该特征进行深度抽象,构建基于CNN的特征提取模块,得到植物属性文本的深度特征表示,并通过卷积和池化层在一定程度上降低了参数的规模。最后经过CRF模块完成最终的标注结果输出。在算法的空间复杂度方面,BCC-P方法的空间复杂度跟各模块的模型容量息息相关,可表示为O(N+M+Q),其中N表示BiLSTM模块中的参数数目,M表示CNN模块中的参数数目,Q表示CRF模块中的参数数目。由于模型复杂度和参数规模的限制,BCC-P方法整体的效率有待提高。
3.1 基于BiLSTM的特征提取模块
植物属性文本包含的是某种植物的属性描述信息,分析中国植物志中的植物属性文本可以发现,这些文本的描述方式较为统一和规范。另外,这些文本中上下文的依赖关系也较为明显,因此需要有效地提取文本中上下文包含的信息。
本文采用BiLSTM 模型对植物属性文本中的上下文信息进行建模,BiLSTM是属于循环神经网络的一种改进。循环神经网络是一种包含循环结构的网络,能够将之前的历史信息连接到当前信息,具有保持信息的能力。但是它存在两个问题:一是单向输入的结构无法利用未来的信息,Schuster等设计了双向循环神经网络,将序列数据从两个方向分别输入模型,且连接到相同的输出层,有效解决了第一个问题[27]。二是随着时间间隔的增长,循环神经网络很难学习跨度较大的信息之间的联系,Hochreiter 等提出的LSTM 单元可以解决这个问题[28]。BiLSTM 模型跟标准的双向循环神经网络结构类似,同时又在隐含层单元处采用LSTM 结构,其网络展开结构图如图2所示。
LSTM 单元的内部信息记忆功能由三个控制门实现。其中,ft表示遗忘门,it表示输入门,ot表示输出门,它们共同控制存储历史和未来信息的细胞状态Ct。对于输入的植物属性描述句子X=[word1,word2,…,wordn],得到它的分布式表示x=[x1,x2,…,xn]。xt和ht分别表示LSTM单元的输入信息和输出信息,则LSTM单元的输出可由式(1)计算得到。


Fig.2 Structure of BiLSTM network图2 BiLSTM网络结构图
其中,ot计算t时刻LSTM 单元的输出,可由式(2)得到。

Ct计算t时刻记忆单元的候选值,可由式(3)和式(4)得到。
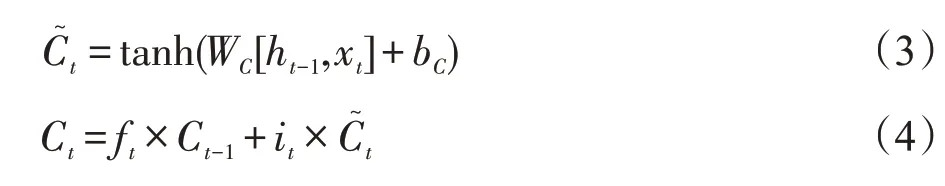
其中,ft计算t时刻之前的信息对当前细胞状态Ct的影响,由式(5)计算得到;it计算t时刻的信息对Ct的影响,由式(6)计算得到。

当输入句子信息经过该模块之后,得到BiLSTM模型学习的句子隐含特征h={h1,h2,…,hn}。
3.2 基于CNN的特征提取模块
提取植物属性文本的上下文特征能够有效表征其蕴含的语义化信息,然而对于句子中命名实体本身的特征表示也至关重要,如“一年生”表示的是Type 类型实体。因此,提取植物属性文本中命名实体相关的局部特征十分必要。对于BiLSTM 模型得到的隐含特征h,本文采用经典卷积神经网络对句子进行深层次的建模,得到更加抽象化的句子表示。基于CNN 的特征提取模块的结构采用卷积层、池化层和全连接层组合的方式。第一步将输入数据经过卷积层得到若干个feature map。第二步在池化层采用最大池化的方法,压缩输入的特征并保留数据中的有效信息,降低模型复杂度。最终使用全连接层进行调整正则化,得到输入句子的最终特征表示H。该模块的网络结构图如图3所示。
对于输入的特征h,是一个n×m的矩阵,其中n表示最大句子长度,m表示对句子中每个字进行WordEmbedding的维度。定义K个卷积核,每个卷积核的滑动窗口大小设置为s,则在卷积层中,每个卷积核以窗口s在输入特征h上以步长为1进行滑动,得到的特征图可由式(7)计算得到。

经过池化层处理之后,得到全局特征R,其中第i位元素可由式(8)计算得到。

其中,Wp为所有卷积核的权重,最后利用全连接层可得到最终特征表示H。
3.3 基于CRF的标注模块
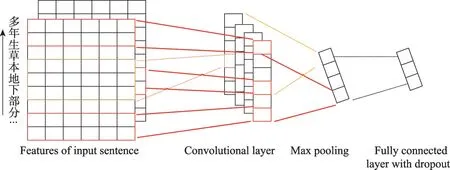
Fig.3 Structure of feature extraction module based on CNN图3 基于CNN的特征提取模块结构图
经过两个特征提取模块之后,得到了植物属性文本的深度隐含特征表示,进一步可得到其序列标注结果。在进行标注时,HMM模型假设观测序列之间是独立的,且当前状态仅依赖于先前的状态,从而对序列的转移概率和表现概率直接进行建模来统计共现概率。因此其对特征选择的要求比较高,不适用于BCC-P 方法。最大熵马尔可夫模型(maximum entropy Markov model,MEMM)克服了HMM输出独立性的问题,引入了特征函数使模型保留了更多的信息,通过计算条件状态转移概率和表现概率来得到局部最优的结果,因此容易陷入局部最优解,导致标签偏置的问题。此外,通过SVM 等分类模型也可进行序列标注,通过对序列中的数据进行单独分类得到标注结果,但是这种方法欠缺对序列上下文特征的考虑,需要引入复杂的操作且易出现误差传递的问题。CRF 模型则不存在上述问题,CRF 模型计算在当前特征下输出的条件概率,将同一个特征在不同位置求和,进行全局归一化处理,从而将局部的特征转化为全局的特征得到全局最优的解,避免了标签偏置的问题。本文采用CRF算法对特征提取模块的输出的特征表示H进行建模,得到植物属性文本的序列标注结果。在CRF模块中,通过对训练样本的学习,可得到一些隐含的约束,例如命名实体的第一个字一般以B-作为前缀,最后一个字以E-作为前缀。对于输入植物属性描述句子X,对应的实际标签序列为Y,并且得到特征提取模块的输出H。则可通过式(9)计算在特征H下,模型输出标签为Y=[y1,y2,…,yn]的概率。
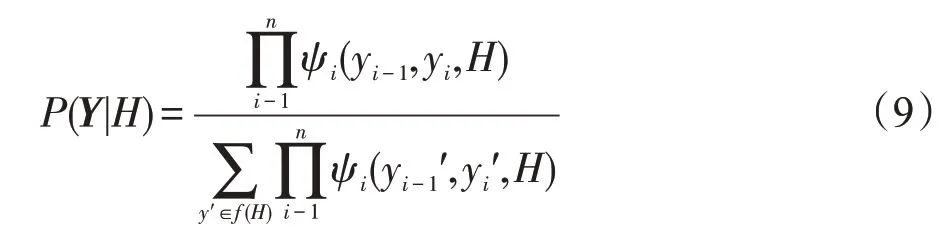
其中,ψi(yi-1,yi,H)表示CRF的势函数,′表示第i个预测标签值。
在模型训练过程中,将当前参数条件下概率最高的序列作为输出结果,并根据模型输出结果与实际标注结果的误差对模型参数进行调整优化。
4 实验结果与分析
4.1 数据集的构建与分析
本文采用的植物属性信息文本搜集自中国植物志[29],将无属性相关描述的文档去除后,得到有效文档集合作为最终的数据集。数据集的整体信息如表1所示。

Table 1 Statistics of dataset表1 数据集统计信息
得到最终数据集之后,本文将文档中的无效符号去除,例如HTML标签符号、无意义特殊符号、列表符号等。根据现有知识库和林业本体,对数据集进行自动化标注。采用BIOES 标注模式进行标注,B-前缀表示命名实体的第一个词,I-前缀表示命名实体中间的词,E-前缀表示命名实体的最后一个词,O表示其他无关字符,S-表示单个字符。标注后辅以人工抽样检查,确定标注效果,优化调整后得到最终的标注结果。对数据集中的命名实体进行分析,统计得到标注的实体总数达到2 518 007个,分析结果如表2所示。
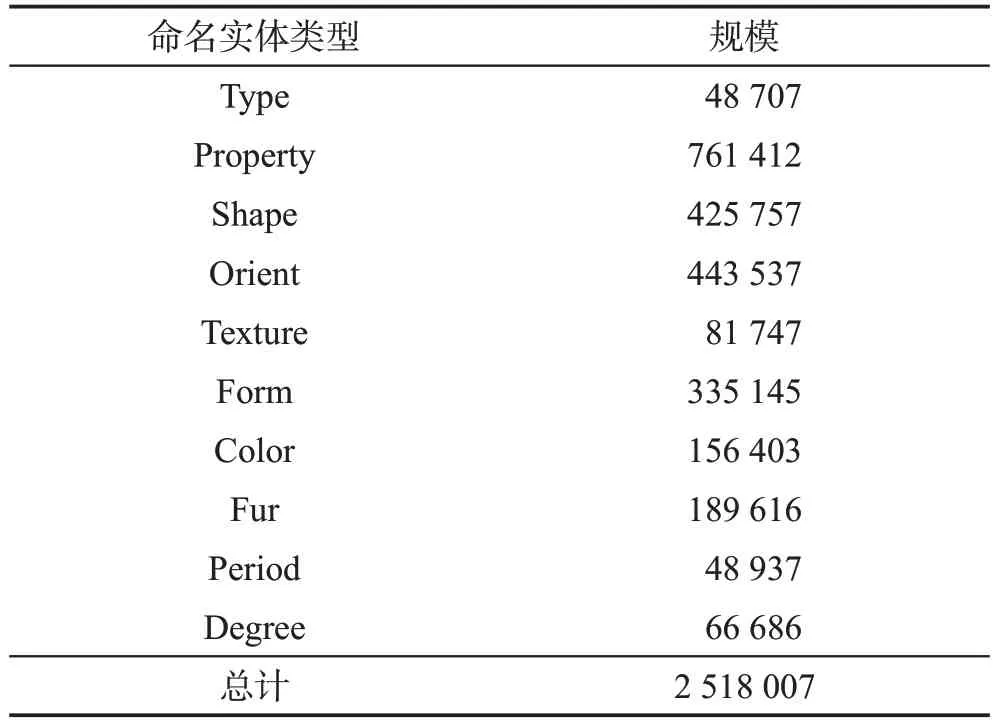
Table 2 Statistics of labeling result表2 标注结果统计
4.2 评价指标
本文采用准确率和F1值两个评价指标,综合对植物属性文本的命名实体识别效果进行评估。其中,F1值计算准确率和召回率的调和平均数,如式(10)所示。

式中,P表示准确率的值,R表示召回率的值。
4.3 实验分析
将数据集随机划分为两部分,分别作为训练集和测试集,训练集包含26 538篇文档,测试集包含6 594篇文档。首先考虑植物属性描述句子的向量表示对实验效果的影响,分别选择one-hot和Word2Vec对句子进行表示,结果如表3所示。从实验结果可以发现,使用Word2Vec 对句子进行分布式表示相对于传统的one-hot 表示方法有比较明显的优势,说明Word2Vec能够表示更丰富的信息。

Table 3 Influence of sentence representation on experimental results表3 句子表示对实验结果的影响
第二部分研究模型随着迭代次数和批处理大小变化的拟合情况,所得结果见图4。随着迭代次数的增加,模型的拟合效果逐渐提升,并且趋于稳定。而在选择批处理大小方面,批处理的数目越小,模型的命名实体识别效果越好。

Fig.4 Influence of iterations and batch size in BCC-P图4 BCC-P中迭代次数和批处理大小的影响
本文选择了CRF 模型、BiLSTM-CRF 模型和BiLSTM+CNN-CRF模型进行对比实验,三组模型均采用Word2Vec 作为句子的分布式表示,并在构建的数据集上进行训练和测试。其中,在BiLSTM-CRF模型的基础上,加入基于CNN 模型进行植物信息文本字信息的提取,并将BiLSTM 模型的结果和CNN模型的结果进行拼接,结合CRF 模型得到BiLSTM+CNN-CRF模型。实验结果如表4所示。

Table 4 Result of different models表4 模型的评估结果
由实验结果可以发现,CRF 模型取得了82.52%的准确率,说明其在植物属性文本命名实体识别任务上具有良好的适应性,能够有效对植物属性文本进行抽象建模。而BiLSTM-CRF模型的效果相对于CRF模型有明显的提升,在F1值上提高了6.5%,准确率上提高了7.16%。上述结果说明利用BiLSTM 网络提取句子中的上下文信息,从而对句子进行深层次建模的方法,可以有效挖掘植物属性文本中的语义特征。BiLSTM+CNN-CRF 模型在整体表现上优于BiLSTM-CRF 模型,说明利用CNN 模型提取的植物属性文本特征可作为上下文特征的补充,以提升命名实体识别的效果。此外,其与BCC-P 方法之间的差距很小,说明利用复杂的拼接特征在对文本的表示方面有优势,但是该方法由于自身的结构原因,在空间复杂度上相较于其他方法更高。本文提出的BCC-P 方法的命名实体识别效果在几种模型中最好,相对于BiLSTM-CRF 模型在F1值上提高了1.79%,在准确率上提高了2.12%,说明BCC-P方法对于句子隐含特征提取的效果更好,植物属性文本中命名实体本身的特征对识别效果有正向的影响。另外,从四组实验可以发现,F1值总是低于准确率,说明在植物属性文本的命名实体识别任务中,命名实体的召回率相较准确率稍低。原因可能是采用的BIOES标注方式较复杂,导致模型的识别效果受到影响。
5 结束语
本文致力于研究植物属性文本的命名实体识别任务,构建了植物属性文本命名实体识别的数据集,并在此基础上提出了基于深度神经网络的BCC-P方法。BCC-P方法充分考虑了植物属性文本中上下文之间的依存关系,利用深度神经网络挖掘句子中的隐含特征,从而完成对植物属性文本命名实体的识别。通过实验对比了模型在不同输入特征下的表现,验证了它们在植物属性文本命名实体识别任务中的有效性。其次,还将BCC-P 方法与CRF 模型、BiLSTMCRF模型和BiLSTM+CNN-CRF模型进行对比,结果表明BCC-P 方法在F1值和准确度上都有所提高,能够有效应用于植物属性文本的命名实体识别任务。实验结果验证了BiLSTM 网络在文本语义特征提取方面的有效性,以及CNN 在命名实体特征挖掘上的实用性。然而,本文的方法也存在着不足,相对于通用命名实体识别模型存在差距,识别效果还有提升的空间,可探索通用命名实体识别模型在领域语料上的迁移效果。此外,BCC-P 方法没有较好地利用文本的其他特征,例如语法特征、句法结构特征和聚类特征等,可在特征选择的多样性方面继续研究。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中国外汇(2019年18期)2019-11-25
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
当代陕西(2019年5期)2019-03-21
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
中国诗歌(2017年12期)2017-11-15
领导决策信息(2017年9期)2017-05-04
