
节点局部Fiedler向量中心性差值社区发现算法*
2019-12-19 17:24凤丽洲杨贵军
计算机与生活 2019年12期
凤丽洲,覃 悦,杨贵军
天津财经大学 统计学院,天津 300222
1 引言
现实世界中的大部分系统都能以网络的形式表示,如人际关系网、信息传播网、神经元网、蛋白质交互网等。这些网络往往具有很高的复杂性,被称为复杂网络。与随机网络不同,复杂网络普遍具有“同一社区内节点联系紧密,不同社区间节点联系稀疏”的特性,这一特性被称为社区结构[1]。复杂网络中的社区结构研究主要针对两个重要问题展开:(1)如何识别复杂网络中的社区结构,即社区发现;(2)如何识别连接不同社区的关键节点,即关键节点发掘。这两个问题的研究对于解决谣言传播、电网保护、抑制传染病扩散等现实问题具有重要的理论意义和广泛的应用前景。
2 相关工作
Girvan与Newman[1]最早于2002年提出了社区发现的概念。此后,围绕着社区发现问题,各领域学者们提出了大量有效的社区发现算法。这些算法大致可分为4类:
(1)基于模块度优化的社区发现算法,根据优化算法的思想,将一种用于度量社区发现结果优劣的指标——模块度[2-3](modularity)作为目标函数,旨在寻找一种使得模块度最大的社区划分方案,如快速Newman(fast Newman)算法[4]、鲁汶(Louvain)算法[5]、模拟退火(simulated annealing)算法[6]等。文献[7]在鲁汶算法的基础上加入了孤立节点分离策略,缩短了算法的运行时间;文献[8]针对网络变化对静态算法影响较大的问题,提出一种基于模块度的增量学习算法,保持了社区发现的实时性;文献[9]基于层次聚类的思想,利用拓扑势迭代地扩展社区,最终从各层的社区划分中选择一个模块度最大的作为划分结果。
(2)基于启发式规则的标签传播(lable propagation algorithm)算法[10-12]将社区划分视为节点标签预测问题,文献[13]针对标签传播算法存在的不必要更新问题,引入节点信息列表,提高了算法准确率;文献[14]基于度中心性设计了节点参与系数,解决了标签传播算法在节点更新时顺序的不确定性对社区发现结果的影响问题。
(3)基于动力学与仿生模拟的社区发现算法,如基于Markov动力学理论的Markov聚类算法[15]、基于自旋模型的社区发现算法[16]、蚁群算法[17]和遗传算法[18],文献[19]设计了一种节点对社区的隶属度计算方案,并将其与遗传算法结合,提出一种能够作用于大规模重叠网络的改进遗传算法。
(4)以图论作为理论支撑的聚类算法,如谱聚类(spectral clustering)算法[20]和基于节点中心性的社区发现算法[1,21]。其中基于节点中心性的社区发现算法是一种可同时进行关键节点发掘与社区发现的算法,其准确率与速度取决于中心性度量指标的选择。根据计算方式的不同,中心性度量指标可分为两类:①全局中心性,如介数中心性[1](betweenness centrality)、紧密度中心性[22](closeness centrality)、特征向量中心性[23](eigenvector centrality)等。文献[1]提出一种基于介数中心性的图分割社区发现算法(Girvan and Newman algorithm,GN);文献[24]提出了一种基于社区动态网络节点介数中心性的更新算法,提高了介数中心性的计算效率,并将其运用到CNM(Clauset,Newman and Moore algorithm)等社区发现算法中。全局中心性的计算需要预先获知图的全局拓扑结构信息,这使得基于全局中心性的社区发现算法往往具有较高的准确率。但由于其复杂度较高,对于大型网络的计算是不可行的。②局部中心性,如度中心性[23](degree centrality)、节点质量[25](node mass)等。文献[26]将节点的度中心性作为该节点的关键性度量指标,提出一种基于核心节点扩展的社区挖掘算法(community mining algorithm based on core nodes expansion,CNE);文献[27]将网络转化为边图,基于节点的度中心性,迭代地将边图中的节点加入到已有社区中。度中心性虽然计算较为简便,但只能反映出节点的局部特征,忽略了节点对于全局的影响,这会影响社区发现与关键节点发掘的结果。
为了解决上述节点中心性存在的缺陷,Chen 和Alfred[28]提出一种局部中心性度量指标——局部Fiedler向量中心性(local Fiedler vector centrality,LFVC),并提出了一种基于LFVC的贪心社区发现算法(greedy community detection algorithm by node-LFVC,GCDN)。然而,GCDN算法在关键节点与关键边的识别过程中经常出现错误识别问题,即将一些非关键节点误识别为关键节点,导致错误信息传递,给后续社区划分带来负面影响,降低社区划分的准确率。在图分割的过程中易划分出大量的孤立节点,破坏网络信息完整性,导致部分社区结构信息的损失。
本文深入分析了网络拓扑结构对节点LFVC 值的影响,提出一种节点LFVC 差值社区发现算法(community detection algorithm with difference of node-LFVC,CDDN)。该算法主要考虑了以下两条信息:(1)联系不同社区间的关键节点与关键边存在着的必然邻接关系;(2)关键节点的邻边并非都是关键边。CDDN 算法在图分割过程中综合利用这两条信息,设计了一种仅移除LFVC最大节点的部分关键邻边的边移除规则,可以有效解决GCDN 算法仅考虑节点LFVC、忽略边的LFVC 所造成的关键节点错误识别问题。此外,由于本文算法仅移除该节点部分关键邻边,可以规避GCDN 算法在图分割时不加区别地删除LFVC 最大的前q个节点的全部邻边所产生的大量孤立节点现象。
在真实网络上的对比实验结果表明,与已有算法相比,改进算法在各规模的网络上均保证了较好的时间效率,同时具有较高的准确性,性能明显优于已有算法。
3 基于LFVC的社区发现算法
3.1 局部Fiedler向量中心性
令G=(V,E)表示一个复杂网络构成的无向无权图,其中V、E分别表示节点集合与边集合。具有n个节点的图G可由其邻接矩阵An×n表示,其中:

令

表示节点i的度,Dn×n为G的度矩阵,其中:

矩阵L=D-A称为G的Laplace 矩阵,L是半正定矩阵,有[29]:

令λi(L)表示L的第i小特征值,其中λ1(L)=0。λ2(L)则有如下两个定义:
定义1(代数连通度)λ2(L) 称为G的代数连通度。
定义2(Fiedler向量与Fiedler值)λ2(L)对应的特征向量称为G的Fiedler向量,其第i个分量称为对应节点的Fiedler值。
令G′表示从图G中移除一条边(i,j)所得到的新图,G的Laplace矩阵增量表示为ΔL=ΔD-ΔA,其中ΔD和ΔA分别表示度矩阵D的增量和邻接矩阵A的增量。G′的Laplace矩阵表示为。令ei表示第i个元素为1,其余元素全为0的n维常向量,则G′的Laplace矩阵为:

根据Courant-Fischer定理,任意连接图的代数连通度可表示为:

令y表示L的Fiedler向量,则根据式(3)~式(5)有:

基于上述理论,将LFVC定义如下:
定义3(边LFVC)设(i,j)为图G=(V,E)中的一条边,即(i,j)∈E,y为G的Fiedler 向量,yi表示节点i在y中对应的分量,则边(i,j)的LFVC为:

定义4(节点LFVC)设i为图G=(V,E)中的一个节点,即i∈V,Ni表示i的邻接节点集,y为G的Fiedler向量,yi表示i在y中对应的分量,则节点i的LFVC为:

为了避免概念混淆,本文将连接着两个社区的边定义为关键边,将负责与不同社区进行联系的节点定义为关键节点。
3.2 基于LFVC的贪心社区发现算法
Chen 和Alfred[28]在2015年提出基于LFVC 的贪心社区发现算法(GCDN)。该算法的核心思想是依次移除LFVC最大的节点及其全部邻边,使图G的代数连通度以最快速度减小。GCDN 算法分为两步:(1)找到当前图的最大连通子图,计算其中每个节点的LFVC 值,给定常数q,依次删除LFVC 值最大的q个节点及其邻边,将该q个节点认定为关键节点,记为集合R;(2)将R中的所有节点加入到它们相应邻接节点最多的社区。
3.3 基于LFVC的贪心社区发现算法问题分析
GCDN 算法存在两个问题:(1)会将一些非关键节点与边错误地识别为关键节点与关键边;(2)会产生大量的孤立节点,且并未对这些孤立节点进行处理。这两个问题会降低社区发现算法的准确性,破坏网络的信息完整性,造成社区结构信息的损失。
如图1所示的网络由{1,2,3,4,5,6}、{7,8,9,10,11}、{12,13,14,15,16}3个社区构成。其中,{1,2,5,7,8,12,13}是7个联系不同社区的关键节点,称为边缘节点(margin nodes)。节点6和11的度为1,称为悬挂节点(dangling node),连接悬挂节点的边称为悬挂边(dangling edge)。为了将该网络划分为3个不相连的社区,最合理的策略是移除连接3个社区的6条关键边{(1,8),(1,12),(2,13),(5,7),(7,13),(8,12)}。

Fig.1 Network of 3 communities图1 由3个社区构成的示例网络
表1为图1网络中各节点的Fiedler值。由定义3和定义4可知,节点的LFVC值与其自身及其邻接节点的Fiedler 值有关。社区中的节点越接近边缘节点,其Fiedler值的绝对值越小[30]。若一个节点的邻点集包含悬挂节点,则该节点Fiedler 值的绝对值大于同级别节点。因此,悬挂边、悬挂节点及其邻点往往具有较高的LFVC 值。由表1可知,LFVC 最大的节点和边分别为节点3和边(3,6)。
采用GCDN 算法移除LFVC 最大的1个节点后所得社区划分结果如图2所示,其中红色节点表示算法识别出的关键节点,绿色节点和黑色节点分别代表划分后获得的两个社区。显然,这样的社区划分结果并不合理。

Table 1 Fiedler values of network depicted in Fig.1表1 图1中各节点对应的Fiedler值

Fig.2 Result of removing one node by GCDN图2 根据GCDN算法移除1个节点的结果

Fig.3 Result of removing 5 nodes by GCDN图3 根据GCDN算法移除5个节点的结果
采用GCDN算法移除图1网络LFVC最大的5个节点后所得的社区划分结果如图3所示。由图3可知,GCDN 算法将节点3误识别为关键节点,并且将悬挂节点6和11移除,导致形成两个孤立节点。同时由图论可知,给定连通图G,α(G)表示G的代数连通度,v为G中一个悬挂节点,有α(G)≤α(G-v)[31]。这表示从G中移除悬挂节点会增加其代数连通度,不符合GCDN算法“以最快速度减小代数连通度”的目的。
针对上述问题,本文改进GCDN社区发现算法,构建了新的关键节点识别与边移除规则。
4 节点LFVC差值社区发现算法
4.1 改进的关键节点识别与边移除策略
基于LFVC 的贪心社区发现算法的本质是依据节点LFVC移除网络的边。表2给出图1示例网络中关键节点与关键边的LFVC值。

Table 2 LFVC of key nodes and edges in Fig.1表2 图1网络中关键节点与边的LFVC
由图1和表2可知,节点1的度为6,(1,8)与(1,12)两条边的LFVC 占节点1的LFVC 的64.74%,其余4条边仅占35.26%。由此可见:LFVC 最大节点i*的邻边并非全都具有很高的LFVC 值,且i*的LFVC值由少数几条重要邻边的LFVC 值构成。移除非关键邻边无法有效减少图的代数连通度,还会产生大量孤立节点。为保证网络结构信息的完整性,提高社区发现的准确率,在进行边移除时,应当仅移除LFVC较大的边。此外,由于移除悬挂边并不符合使图G的代数连通度以最快速度减小的目的,在进行边移除操作时应保留悬挂边。
由于关键边必然是关键节点的邻边。在算法进行循环时,每移除一条边,都会引起网络中所有节点与边的LFVC 值的变化。若当前LFVC 最大节点i*是关键节点,在与其连接的全部关键边移除之前会保持较高的LFVC值,则该节点在之后的循环中容易被再次识别;若i*是非关键节点,则希望通过牺牲最少的网络结构信息,即移除最小数量的边来跳过此次循环,确保该节点在之后的循环中不易被识别,以寻找真正的关键节点。本文算法将LFVC 最大的两个节点的LFVC 值之差作为决定每一次循环中所移除边的数量的依据。
综上所述,本文为避免GCDN 算法因移除悬挂边与过多非关键边而导致的关键节点识别错误与效率低下问题,提出如下改进的关键节点识别与边移除策略:
当且仅当(i,j)*是i*的邻边,将i*识别为关键节点;计算LFVC 最大节点i*与LFVC 次大节点的差值,即,按LFVC 从大到小依次移除i*的k条邻边。k的计算公式如下:

其中,(i*,nj)表示i*的LFVC值第j大的邻边,,表示i*的邻接节点集;表示i*的度,din与dout分别表示与节点i*在同一个社区内部的邻边数目和不在同一个社区中的邻边数目,由于复杂网络普遍具有“同一社区内节点联系紧密,不同社区间节点联系稀疏”的特性,则有,因而。
若(i,j)*不是i*的邻边,则仅移除(i,j)*。
由于孤立节点是因图中悬挂边被移除而产生,上述边移除策略使得本文算法规避了产生孤立节点的情况。
4.2 算法设计
依据上述改进策略,本文提出节点局部Fiedler向量中心性差值社区发现算法(CDDN)。该算法分两个阶段:
阶段1计算LFVC。给定循环次数q,在每次循环中识别当前规模最大的连通子图,计算子图的Fiedler 向量和各节点与边的LFVC 值,找出LFVC 最大节点i*、LFVC次大节点和LFVC最大边(i,j)*,其中i,j∈(i,j)*,di≠1且dj≠1。
阶段2识别关键节点,依据边移除策略对图进行分割。
综合上述两个阶段,本文CDDN 算法的伪代码如下所示:
输入:图G,循环次数q。
输出:社区划分g。

4.3 算法分析
4.3.1 有效性分析
由于CDDN算法在进行边移除时主动忽略了悬挂边,因此可以有效避免孤立节点的生成。对图1网络,采用CDDN算法分别进行1次、6次循环的结果如图4、图5所示。其中,红色节点是CDDN算法识别出的关键节点,虚线边表示算法移除的关键边。CDDN算法识别出的关键节点与关键边均与实际相符,且不存在孤立节点。
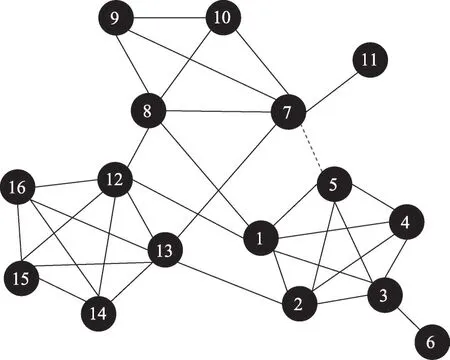
Fig.4 Result of one turn by CDDN图4 CDDN算法进行1次循环的结果
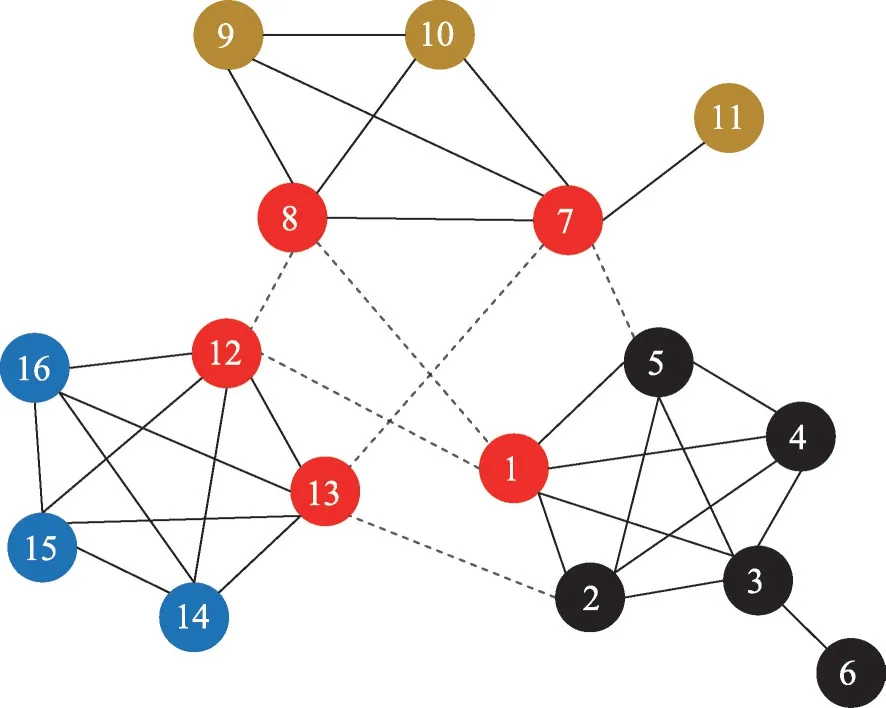
Fig.5 Result of 6 turns by CDDN图5 CDDN算法进行6次循环的结果
当网络中的节点较为稀疏时,CDDN算法在发现小粒度社区方面具有一定的优势。这是由于远离边缘节点的节点往往具有绝对值较大的LFVC,因而对于悬挂点较多,结构较为稀疏的网络,CDDN 算法的边移除策略倾向于为远离较大规模社区边缘并与悬挂点相连接的节点分配较大的LFVC,因此这些节点易被识别为LFVC最大点,它们的非悬挂邻边易被优先移除,使其及其悬挂邻点成为一个细粒度的小社区。
当网络中的节点较为紧密时,CDDN算法通常可以发现更多的社区。CDDN 算法与GCDN 算法往往通过增加循环次数以发现更多数目的社区。一方面,在迭代过程中,GCDN 算法移除的边大多为对图的代数连通度影响极小的边,而CDDN 算法在每一次循环中则是移除对图的代数连通度影响最大的1条或k条边。因而,在移除相同边数的情况下,CDDN 算法发现的社区数量通常多于GCDN 算法。另一方面,由于GCDN 存在节点合并阶段,导致GCDN 算法无法有效分割联系紧密的大型网络。相对而言由于CDDN 算法不需要节点合并的步骤,可以有效提升图分割效率,理论上能发现更多的社区。
4.3.2 时间复杂度分析
在CDDN 算法中,步骤1为图G的复制过程,其时间主要花费在对G中n个节点与m条边进行复制的过程中,时间复杂度为O(n+m)。步骤3为寻找G中最大连通子图的过程,最坏情况下其时间复杂度为O(n)。步骤4计算最大连通子图的Fiedler 向量,基于Lanczos算法计算Fiedler向量的时间复杂度为O(m1×n),其中m1为根据Lanczos 算法计算Laplace 矩阵的Fiedler向量的迭代次数,通常需要上百次。步骤5为计算G′中所有节点与边的LFVC 的过程,其时间复杂度为O(m+n)。步骤6与步骤7为寻找LFVC 最大、次大非悬挂节点的过程,时间复杂度分别为O(n)和O(m)。步骤8~10为判断并移除LFVC最大非悬挂边的过程,时间复杂度为O(m)。步骤12、13的时间复杂度均为O(1)。步骤14~17的时间复杂度为O(r×(m+1+m)),r为 从diff=0到LFVCremove<diff的循环次数。综上所述,常数r,q<<m,CDDN 算法的最终时间复杂度为O(m1n+m)。
5 实验结果与分析
为了验证CDDN算法与其他现有算法在准确率和效率方面的性能,实验用到的算法有:(1)基于全局中心性的GN算法[1];(2)基于局部中心性的CNE算法[26];(3)GCDN算法[28];(4)本文所提出的CDDN算法。
表3为4种算法的时间复杂度,其中m1为Lanczos算法计算Fiedler向量所需的迭代次数,通常需要上百次。因此对于小规模网络,CNE与GN算法可能拥有更高的效率。但对于大规模网络,CDDN算法与GCDN算法在效率上具有明显优势。

Table 3 Time complexity of 4 algorithms表3 4种算法的时间复杂度
5.1 数据集
如表4所示,本文采用了4个不同规模、不同结构的真实网络数据集(Karate、Dolphin、Football、Last.fm)进行对比实验。其中前3个网络已知其真实社区划分。Karate网络数据集[32]来自Zachary对某空手道俱乐部成员的社会关系研究。该俱乐部由于人事纠纷,最终分裂成了两个俱乐部。Dolphin 网络数据集[33]来自1994年至2001年期间,Lusseau及其团队对62只宽吻海豚的观察数据。Football网络数据集[1]来自于2000赛季美国12个大学橄榄球队联盟的比赛时间表,其中节点代表球队,边代表两个球队之间进行的常规赛。Last.fm 网络数据集来自文献[34]所提供的在线音乐系统Last.fm的交友状况数据。

Table 4 Real network dataset表4 真实网络数据集
5.2 评价指标
对于已知真实社区划分的数据集,由于对比实验的算法评价涉及孤立节点识别问题,本文采用标准化互信息(normalized mutual information,NMI)、准确率(Acc)以及忽略孤立节点时的准确率Accr、将孤立节点视为同一个社区时的准确率Accm作为社区发现算法的评价指标。给定网络中真实社区U以及算法划分的社区V,真实社区数为CU,划分的社区数为CV,4个指标计算方式如下:
标准化互信息NMI(U,V)定义为[35]:
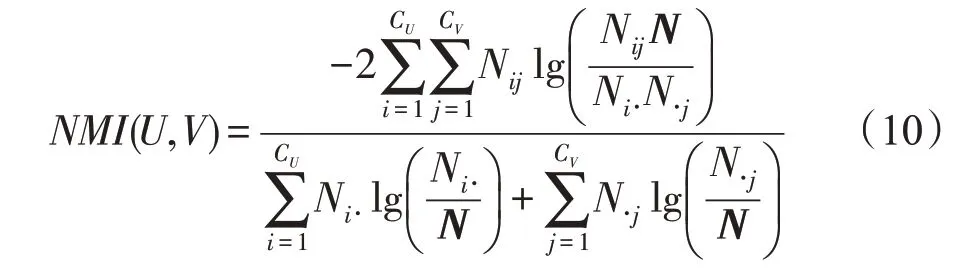
其中,N代表混淆矩阵,行表示真实社区,数目为CU,列表示划分社区,数目为CV。Ni∙表示矩阵N中第i行的和,N∙j表示矩阵N中第j列的和。
算法划分结果V的准确率(Acc)定义为:

其中,Interkt表示划分出的某一社区vk∈V,k=1,2,…,CV与某个真实社区ut∈U,t=1,2,…,CU的交集元素的个数。
划分的社区与真实社区的吻合程度越高,NMI和Acc的值越高。根据式(10)和式(11)可知,NMI与Acc对孤立节点具有偏好,即孤立节点的存在将提高划分结果的NMI与准确率Acc。因而,本文针对孤立节点采取了两种识别方式:(1)忽略所有孤立节点;(2)将所有孤立节点视为同一社区。分别计算两种识别方式下的准确率,记为Accr和Accm。
由于无法知晓Last.fm 网络的真实社区划分,本文利用最大社区节点数占总节点数之比(proportion of largest community size,Plcs)与发现的社区数(detected communities,DC)来比较两种算法在网络划分上的效果。
5.3 实验结果
5.3.1 Karate网络
该数据集包含34个节点,真实社区数为2,为了分析算法发现更小粒度社区的表现,图6~图8显示了4种算法分别发现2~5个社区时的NMI、忽略所有孤立节点时的算法准确率Accr、将孤立节点视为同一社区时的算法准确率Accm。CNE算法在该数据集上仅能发现两个社区,使用其发现两个社区时的数据对其发现3~5个社区时的数据进行填补。
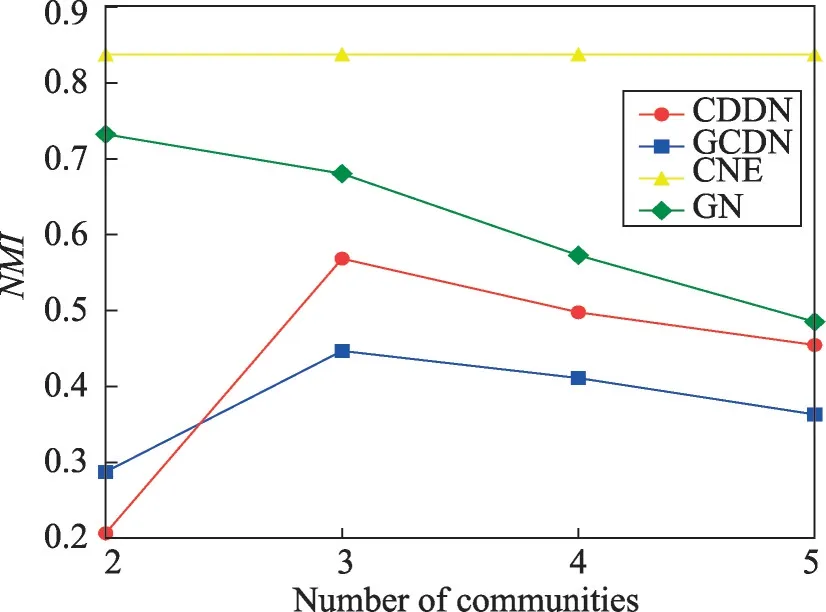
Fig.6 NMI on Karate network图6 在Karate网络上的NMI

Fig.7 Acc and Accr on Karate network图7 在Karate网络上的Acc与Accr
如图6所示,由于Karate 网络规模较小,在该数据集上GN 算法与CNE 算法的准确性均优于CDDN算法与GCDN 算法。将Karate 网络划分为两个社区时,CDDN算法的NMI略低于GCDN算法,当将网络划分为更多细粒度的社区时,CDDN 算法的NMI高于GCDN算法。由于NMI和准确率Acc对孤立节点具有偏好性,而GCDN 算法会随着划分社区数的增多产生越来越多的孤立节点,因而在图7、图8中,当不对孤立节点产生的影响进行处理时,GCDN算法的准确率Acc相对较高。而在考虑孤立节点带来的影响并进行相应处理之后,CDDN 算法所获得的Accr和Accm明显优于GCDN算法。

Fig.8 Acc and Accm on Karate network图8 在Karate网络上的Acc与Accm
5.3.2 Dolphin网络
该网络具有两个真实社区,图9展示了CDDN算法将该网络划分为两个社区时的结果。其中黄色代表划分错误的节点,红色代表算法发现的关键节点,蓝色与绿色节点分别代表两个不同的社区。与真实社区相比,CDDN 算法仅有一个节点划分错误,说明了使用CDDN算法进行社区划分的有效性。

Fig.9 Partition Dolphin network to 2 communities by CDDN图9 CDDN算法将Dolphin网络划分为两个社区的结果
图10~图12给出了4种算法在Dolphin网络上发现2~7个社区时的NMI、Accr和Accm。需要说明的是,由于GCDN 算法无法发现数量为5和7的社区,为了填补缺失值,绘图时分别用数量为4和6时的数据替代。由图10所示,CDDN 算法在发现2~7个社区时,所获得的NMI均大于其他3种算法。如图11、图12所示,CDDN算法与GN算法在发现两个社区时已经具有很高的准确率,当发现社区数目为2~7个时所获得的准确率Acc值均较高,且呈现稳定状态。而GCDN 算法和CNE 算法准确率不仅低于CDDN 和GN算法,而且曲线呈现一定波动性。当考虑孤立节点所带来的影响并进行相应处理之后,CDDN算法的优势更为明显。

Fig.10 NMI on Dolphin network图10 在Dolphin网络上的NMI
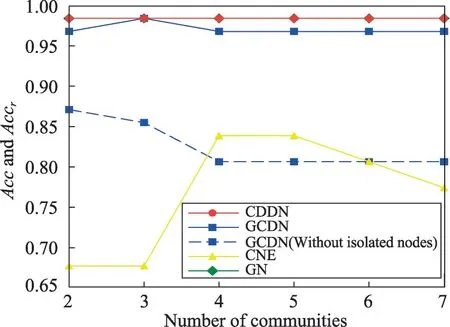
Fig.11 Acc and Accr on Dolphin network图11 在Dolphin网络上的Acc与Accr
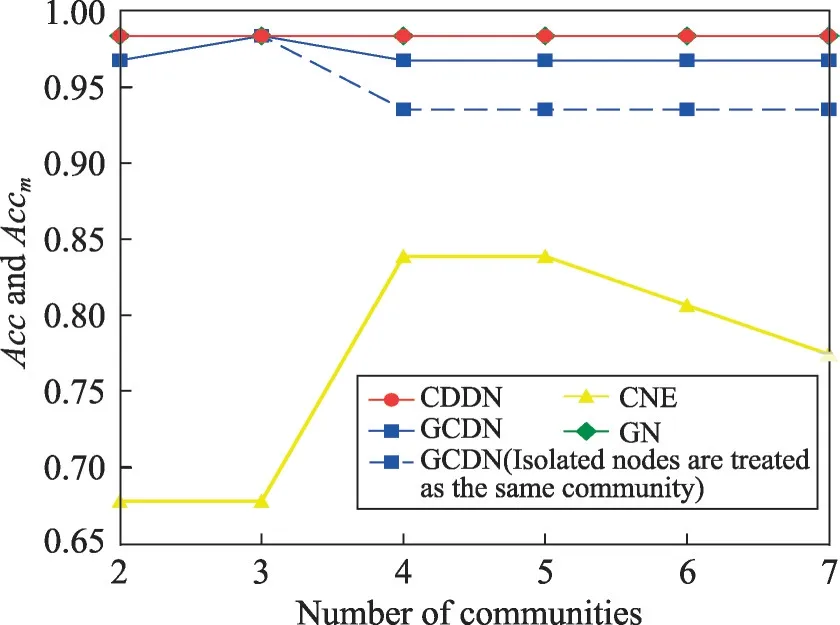
Fig.12 Acc and Accm on Dolphin network图12 在Dolphin网络上的Acc与Accm
5.3.3 Football网络
较前两个网络而言,Football网络规模更大,真实社区数更多。GCDN 算法对该网络进行划分没有产生孤立节点。表5展示了4种算法划分出同样数量社区时所需移除的最小边数。由表5可知,当划分出相同数量社区时,CDDN 算法所移除的边数略多于GN算法,且远远小于GCDN算法与CNE算法所移除的边数。这说明CDDN 算法显著提升了图分割效率。图13、图14给出了实验对比4种算法在发现4~12个社区时的NMI与Acc。表6给出了4种算法对Football 网络进行社区发现时,发现各个数量的社区所需的运算时间。由图13、图14可知,在发现各数量的社区时,CDDN 算法的NMI值和准确率Acc均明显优于GCDN 算法与CNE 算法,略优于GN 算法。结合表6可得,虽然CDDN算法的准确率与GN算法大致相同,但算法花费时间远少于GN 算法,效率上明显优于GN算法。此外值得注意的是,GCDN算法与CNE 算法至多只能发现该网络中的9个社区,无法发现全部社区,而CDDN与GN算法却可以获得全部社区结构。图15展示了使用CDDN 算法划分Football网络所获得的12个社区。

Table 5 Number of edges removed by 4 algorithms on Football network表5 在Football网络上4种算法移除的边数

Fig.13 NMI on Football network图13 在Football网络上的NMI
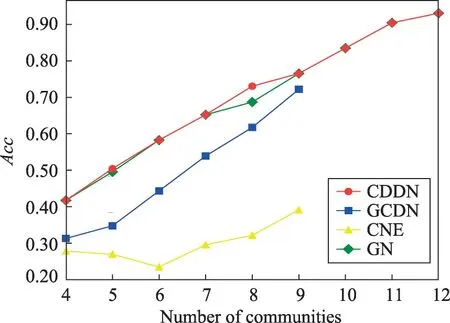
Fig.14 Acc on Football network图14 在Football网络上的准确率Acc

Table 6 Running time of 4 algorithms on Football network表6 在Football网络上4种算法的运行时间
5.3.4 Last.fm网络
表7展示了4种算法对Last.fm 网络进行划分所需的时间,由于GN算法需要将网络中的每一条边均移除后才可得出结果,故只有一个时间数据;CNE算法无法在限定时间内运行完毕,导致了数据的缺失。从表7中可看出,CDDN算法在处理大规模网络时,效率明显优于其余3种算法。此处仅用运行时间与本文提出的CDDN算法相近的GCDN算法进行社区发现结果的比较。图16展示了CDDN 算法与GCDN算法在移除相同边数时,网络中最大社区规模占总规模之比Plcs。如图16所示,相对于GCDN 算法,CDDN 算法对应的曲线下降速度更快,说明CDDN 算法可以在移除较少边数的情况下就达到GCDN算法的社区划分效果,其分割网络的效率高于GCDN算法。图17展示了两种算法在移除相同边数时发现的社区数量的对比结果。如图17所示,CDDN 与GCDN 算法在移除相同边时,CDDN 算法发现社区数目明显多于GCDN 算法,且能发现更多细粒度的社区,说明CDDN 算法的社区发现能力优于GCDN 算法,同时也印证了相对于GCDN 算法,CDDN算法在社区划分效率上更具优势。

Table 7 Running time of 4 algorithms on Last.fm network表7 在Last.fm网络上4种算法的运行时间

Fig.15 Partition Football network to 12 communities by CDDN图15 CDDN算法将Football网络划分为12个社区
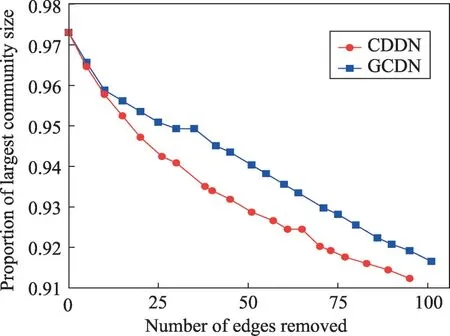
Fig.16 Proportion of largest community size to total size(Plcs)图16 最大社区规模占总规模之比(Plcs)

Fig.17 Number of detected communities(DC)图17 发现的社区数量(DC)
6 结束语
本文通过分析复杂网络拓扑结构对局部Fiedler向量中心性的影响,提出了节点局部Fiedler 向量中心性差值社区发现算法,有效解决了GCDN 算法中存在的关键节点和关键边的识别失误问题以及孤立节点问题。在Karate、Dolphin、Football、Last.fm 四个真实网络上的对比实验表明,相对于其他三种相关算法,本文算法的效率与准确率均有显著提升。
猜你喜欢
吉林大学学报(理学版)(2022年4期)2022-08-04
中学生数理化·高一版(2022年2期)2022-04-05
密码学报(2021年4期)2021-09-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
成都信息工程大学学报(2021年6期)2021-02-12
健康体检与管理(2021年10期)2021-01-03
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
