
一种基于目标优化学习的车标识别方法
2019-09-09 03:27朱文佳陈宇红冯瑜瑾
图学学报 2019年4期
朱文佳,陈宇红,冯瑜瑾,王 俊,余 烨
一种基于目标优化学习的车标识别方法
朱文佳1,陈宇红2,冯瑜瑾2,王 俊3,余 烨3
(1. 安徽百诚慧通科技有限公司,安徽 合肥 230009;2. 云南省公安厅交通警察总队,云南 昆明 650224;3. 合肥工业大学计算机与信息学院,安徽 合肥 230009)
近年来,车标识别因其在智能交通系统中的重要作用,受到研究者的广泛关注。传统的车标识别算法多基于手工描述子,需要丰富的先验知识,且难以适应复杂多变的现实应用场景。相比手工描述子,特征学习方法在解决复杂场景的计算机视觉问题时具有更优性能。因此,提出一种基于目标优化学习的车标识别方法,基于从原图像中提取的像素梯度差矩阵,通过目标优化,自主学习特征参数。然后将像素梯度差矩阵映射为紧凑的二值矩阵,通过特征码本的方式对特征信息进行编码,生成鲁棒的特征向量。基于公开车标数据集HFUT-VL1和XMU进行实验,并与其他车标识别方法进行比较。实验结果表明,与基于传统特征描述子的方法相比,该算法识别率更高,与基于深度学习的方法相比,训练和测试时间更少。
车标识别;目标优化;特征学习;码本;像素梯度差矩阵
汽车保有量及驾驶人数量的快速增长给人类生活带来诸多便利,同时也带来了很多不容忽视的安全隐患,与车辆相关的交通事故、刑侦案件也越来越多。由于盗牌、无牌、污损车牌车辆的存在,使得基于车牌的相关识别方法[1-2]难以发挥应有的作用。而车标作为车辆制造商的标识,难以替换和伪装,因此车标识别作为交通管理部门的重要工具和手段,在车辆查询与跟踪、道路管理、收费站自动收费等方面具有广泛的应用价值。车标识别已成为智能交通系统领域的重要研究方向,受到越来越多研究者的关注。目前,车标识别的研究依然存在挑战,如复杂应用场景、夜晚光线不足等情况下车标特征不明显;实际应用中对车标的识别速度有较高要求,这些均增大了车标识别难度。
现有车标识别算法大多基于手工描述子,以LBP、HOG为代表的局部特征描述子在一些数据集上表现出良好的性能。文献[3]提出HOG和SVM相结合的车标识别方案,实验结果表明HOG特征对车标识别具有好良的性能。文献[4]利用SIFT特征的旋转、尺度不变性特征,以及反向传播算法的特性,提出了一种车标识别方法,其对于光照变化具有一定的鲁棒性。文献[5]将多尺度与SIFT特征相结合,提取到更加密集的SIFT关键点,通过密集关键点匹配,进而显著提高了算法的识别率。文献[6]提出一种增强的SIFT描述子(M-SIFT)算法,解决了车标识别当中的尺度问题。为了解决车标识别任务中的车标图像像素较低,难以提取到充足密集的特征信息或关键点问题,文献[7]提出一种基于图像明暗对比关系的点对特征;文献[8]提出一种车标图像前背景骨架区域随机点对特征,该方法将车标图像分割成前景和背景2个部分,并随机生成点对进行匹配进而提取图像的特征信息。
传统手工描述子虽然在某些数据集上有很好的识别率,或者在解决特定的问题上具有优势,但其仍存在很大的弊端。首先手工描述子需要丰富的先验知识,其次手工描述子在解决复杂场景下的识别问题缺乏鲁棒性。因此,越来越多的人通过特征学习的方法解决车标识别问题。特征学习方法能够通过监督、半监督和非监督的方式学习特征参数,提取特征信息,能够适用于不同场景下的车标识别任务。文献[9]通过学习一组图像滤波器和软采样矩阵来提取有效的人脸特征。文献[10]给出一种紧凑二值化人脸描述子(compact binary face descriptor, CBFD)的学习方法。CBFD通过学习特征参数将像素梯度差映射成紧凑有效二值化向量。文献[11]将核分析算法(kernel discriminant analysis, KDA)和稀疏表达分类器(sparse representation classifier, SRC)结合学习得到一个在人脸识别任务中性能鲁棒的核描述子。近年来以卷积神经网络(convoluted neural network, CNN)模型[12-13]为代表的深度学习方法在计算机视觉任务当中取得了巨大的成果,例如目标分类任务当中的VGG、Inception和ResNet系列方法,以及目标检测任务当中的R-CNN、Yolo和SSD系列方法。但是深度学习方法需要巨大的算力和海量的训练样本,这些弊端从一定程度上限制了深度学习方法在实际场景的应用。
本文提出了一种新的基于目标优化学习的车标识别方法,其通过目标优化,自主学习样本图像数据,进而提取样本图像的特征信息,避免了手工描述子需要先验知识的问题。此外,该方法需要拟合的特征参数少,仅需少量训练样本便能够快速拟合,避免了CNN模型计算量大、训练样本大、时间长的缺点,可以应用于实时车标识别系统之中。
1 基于目标优化学习的车标识别算法
本文给出了一组有效的目标函数和优化方法,通过自主学习,获取特征参数,提取特征向量,进行车标识别。
本文算法分为特征参数的学习和特征信息的提取2个部分。首先提取像素梯度差矩阵(pixel difference matrix, PDM),然后以为输入数据,通过对目标函数的学习优化,获取特征参数,以无监督学习的聚类算法生成特征码本;然后,基于学习好的特征参数和特征码本提取特征向量用于分类。分类算法采用经典的SVM来实现。整个算法流程如图1所示。
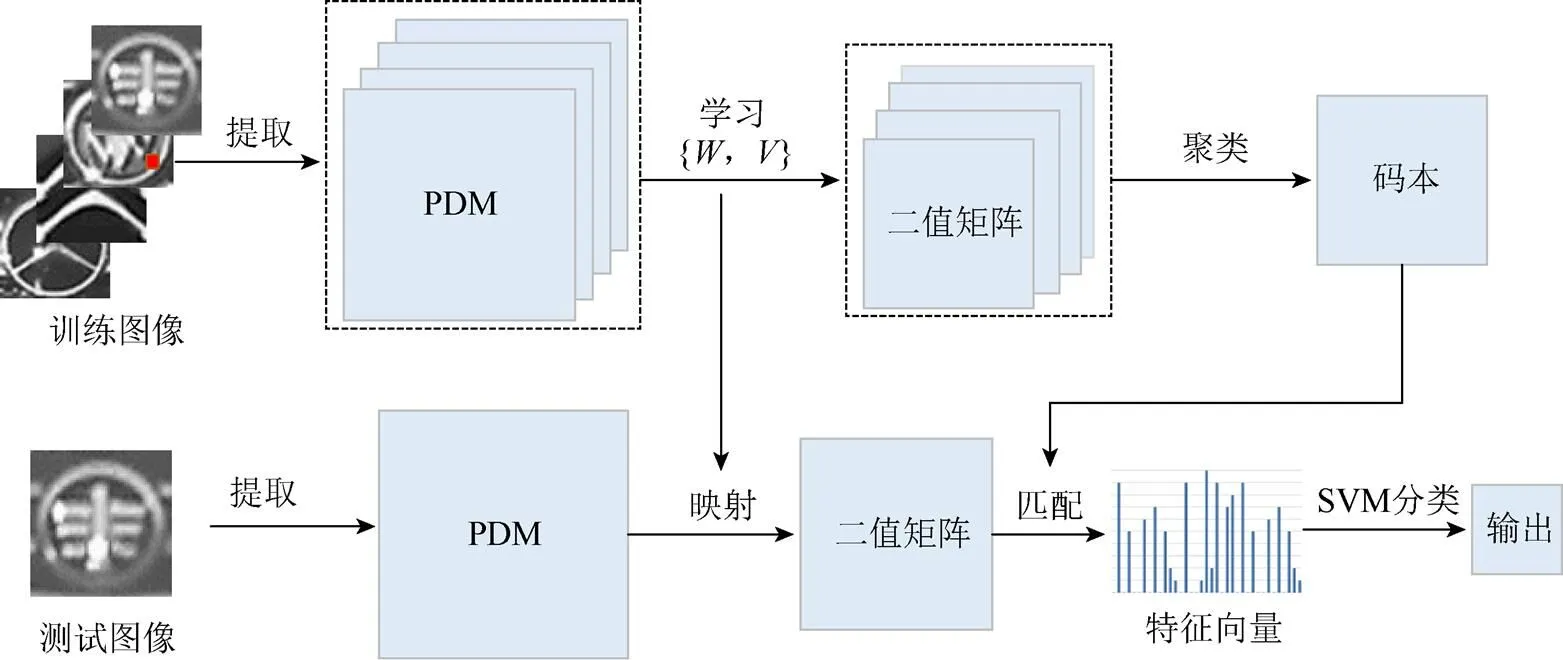
图1 本文算法流程图
1.1 像素梯度差矩阵(PDM)提取
与现有的大多数特征学习方法直接使用原像素值作为输入数据不同,本文使用作为学习的输入数据。相比原始像素值,能够更好地反映图像的梯度信息,对于车标识别而言,梯度信息尤为重要。
的提取过程如图2所示。首先将完整的车标图像分割成个区域块,每一个区域块对应一个;其次对区域块当中的任意一像素点提取像素梯度差向量(pixel difference vector, PDV)。以该像素点为中心,定义一个半径的邻域区间,邻域像素点为邻域区间((2×+1)×(2×+1))内除之外的所有像素点。按照顺时针方向,计算邻域像素点与中心像素点的差值,该差值序列即为。为邻域像素点与中心像素点的梯度差,包含了车标图像的梯度信息。相较于原素值,使用有助于特征信息提取,加速特征参数的学习,文献[9-10]也证明了其的有效性。最后将所有得到的连接生成。
因此,对于含有个像素点的区域块提取到的可表示为:(1,2,···,, ···,)。
对于包含类,且每类有张的车标图像训练集中,在位置的区域块则可以生成×个,记为=(11,12,···,1N,21,···,)。

图2 PDM提取过程示意图
1.2 特征参数学习
特征参数的学习过程即为目标函数的优化过程,通过构建一个目标函数,并对其进行优化,进而学习特征参数。


其中,为映射矩阵,在基于映射转换之后,被映射为更紧凑和表达效果更好的,当将向量形式的拓展到矩阵形式的时,式(1)可以被重写为

为了有效去除冗余信息,加强有用特征信息的目的,特给出一个约束条件:映射转换之后,目标矩阵的类内散度最小化,类间散度最大化。这样保证了同类车标图像之间的特征信息距离更近,不同类车标图像的特征信息距离更远,进而有助于对车标图像进行分类识别。为此,给出目标函数



其中,1,2分别为类内散度和类间散度;为样本的类别数;为每类样本的数量;1,2分别为权重系数。
当使用式(2)进行替换时,式(3)~(5)可以重写为



通过对目标函数式(6)的最优化,可以学习得到特征参数×d,基于特征参数,可以将×D映射转换为更加紧凑有效的ʹ×d。
对于包含个像素点的区域块,通过邻域空间可以生成相对应的个,并将其连接起来生成。在特征提取过程中,每个所起的作用是不同的,为了提取到更加有效的特征信息,需给各赋予不同的权重。加强有用的权重,减弱或消除无用的权重。传统手工描述子中通常使用图像滤波来达到此目的,如LGBP使用了Gabor滤波器,但是手工设计出一个广泛且有效的图像滤波器十分困难。因此,本文希望通过特征学习的方式,学习得到一个广泛而有效的滤波器×p,将ʹ×d映射为ʺ×d即

若将ʹ使用式(2)进行替换时,式(9)可以写为

当对滤波器给出同样的散度约束条件时,目标函数式(6)可以被改写为
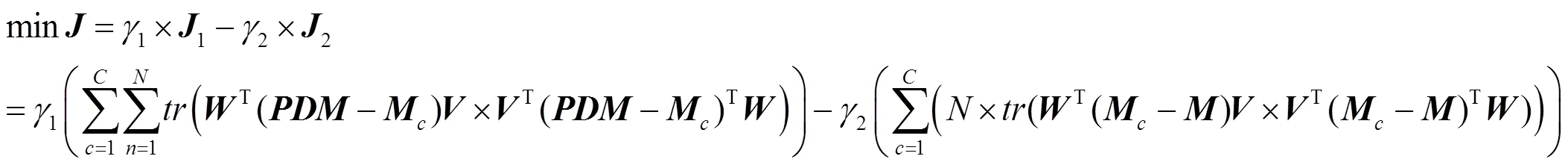
通过对式(11)的求解,可以学习得到一个特征参数对(),通过式(10),×D可以被映射为ʺ×d(<,<)。到ʺ不仅仅是维度被压缩的过程,更是特征提取的过程。
对式(11)的优化求解,首先需分别计算关于和的偏导


其中,
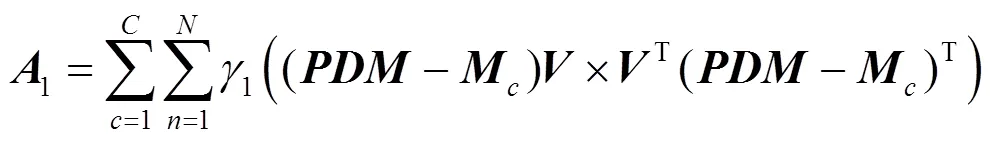



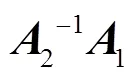

算法1. 输入:训练样本集(PDM11,···,PDM1N,PDM21,···, PDMcn,···, PDMCN),其中,C为类别数目;N为每个类别包含的数目;PDMcn=RP×D 输出:WRP×p和VRD×d 步骤1. (初始化)W=I,V=I,I为单位矩阵,基于式(11)计算J的值 步骤2.do: Jold=J 分别计算A1和A2,计算A2–1A1的前p个最大特征值对应的特征向量所组成的矩阵W0,令W=W0 分别计算Q1和Q2,计算Q2–1Q1的前d个最大特征值对应的特征向量所组成的矩阵V0,令V=V0 While (Jold>J),基于式(11)计算J的值 步骤3.返回W和V
通过算法1,可以学习得到特征参数(,),通过特征参数将映射成ʺ,进而将冗余信息去除,加强有用的信息。
1.3 特征码本生成与特征向量提取
为控制特征向量的维度,可采用聚类的方法生成特征码本(codebook),然后通过与特征码本的匹配生成特征向量。通过聚类方式生成特征码本的方法,被广泛地应用于LQP[14]、DFD[9]和CBFD[10]等特征学习算法之中,说明了该方法的有效性。
为降低聚类算法的计算和存储负担,提高算法的计算速度,可将学习得到的ʺ使用式(16)进行二值化映射,得到二值化矩阵,即

以矩阵的每一行作为无监督训练的输入数据,通过聚类算法生成个聚类中心,保存生成特征码本。
对于从测试图像提取生成的二值化矩阵,以其每一行为单位与特征码本进行最邻近匹配,获取特征码,过程如图3所示。对特征码进行频率统计,生成频率直方图。若测试图像被分割成个区域块,对应提取到个,进而对应生成个频率直方图 (1,2,···,h),将其连接则生成整张图片的特征向量。

图3 特征码生成过程
2 实验结果与分析
2.1 实验数据集
采用本团队自行构建的数据集HFUT-VL1[15],其包含16 000张采集于高速公路实时卡口系统的车标图像。HFUT-VL1共包含80类车标,每类200张,图像分辨率为64×64,如图4所示。此外,还采用了厦门大学公开车标数据集XMU[13]对本文算法进行评估。XMU数据集包含10类车标图像,每类1 150张,其中训练集图像1 000张,测试集图像150张,图像分辨率为70×70,如图5所示。

图4 HFUT-VL数据集样例

图5 XMU数据集样例
2.2 参数评估
从1.2节可以看出,影响算法效果的主要因素在于的维度,参数矩阵和的维度。本文对上述参数,做了相关实验以进行评估。
从图6(a)可以发现,随着邻域半径的增大,维度参数的值随之增大,算法的识别率也逐渐提升。该结果说明,在一定范围内,增大邻域半径可以提高识别效果,但也存在瓶颈。如图6(a),当邻域半径增加到4和5时,对识别率的提高并不明显,但是相比=3会使的维度增加,带来更大的计算负担,因此综合考虑选择=3。此外,当邻域半径一定,参数矩阵的维度参数存在一个峰值,当的大小为的3/4时,识别率达到最高。
从图6(b)可以看出,随着区域块半径的增大,区域块当中的像素值增加,算法效果呈下降趋势,综合考虑选择=3。当区域块半径一定,的大小为的3/4时,算法效果达到最好。
因此,当样本图像分辨率为64×64时,邻域半径与区域半径分别设置为3时,识别率达到最高。此时,参数矩阵和的维度参数和分别为和的3/4大小。

图6 参数对识别率的影响
2.3 实验结果比较
本文提出基于目标优化学习的车标识别方法的目标为:①在小样本训练时,能够保持较好的性能;②相比其他特征学习算法时间复杂度更低,满足车标识别任务的实时性。
为了验证小样本训练的效果,本文基于HFUT-VL1数据集,从80类车标中每类提取5张,共400张图像作为训练集,其余15 600张作为测试集,对本文算法的效果进行评估,实验结果见表1。手工描述子方法的优点在于小样本训练下性能优良,从表1可以看出,本文算法具有优异的识别效果,其识别率远远高于其他算法,表明本文算法适用于小样本训练情况下的车标识别任务。
近年来,CNN的相关算法在计算机视觉领域快速发展。本文也对经典的CNN分类算法进行了相关实验,以便更加全面地评估本文算法的效果。实验在HFUT-VL1数据集上进行,使用2个80类车标图像,每类100张,总计8 000张车标图像作为训练集及测试集进行实验。CNN算法直接调用了MXNet框架下的GluonCV库当中的标准模型,并且都使用了GPU加速,实验结果见表2。由表2可见,本文算法识别率达到了98.33%的效果,虽然略低于基于CNN的分类算法,但是本文算法的训练时间和测试时间远远低于其他算法,训练时间比CNN算法当中最快的MobileNet快了8.6倍,测试速度快了4.3倍,更加能够适应于车标识别任务的实时性要求。

表1 本文算法与手工描述子算法识别效果对比*
(*:80类,训练张数每类5张,测试张数为每类195张)
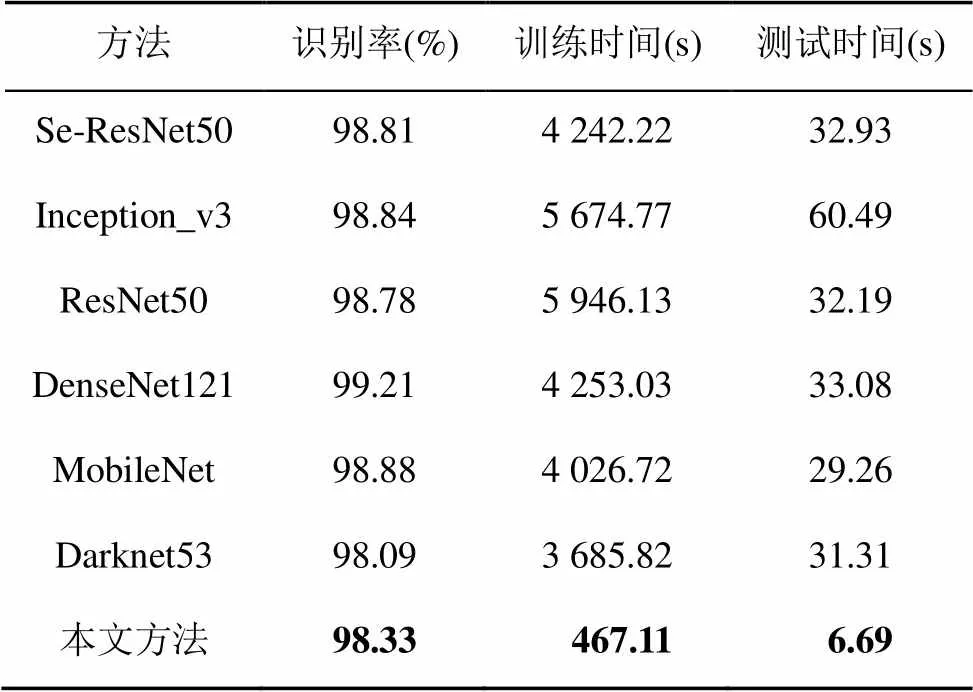
表2 本文算法与CNN算法性能比较*
(*:80类,训练张数每类100张,测试张数每类100张)
此外,为进一步将本文算法与其他车标识别算法进行比较,还在车标公开数据集,即XMU数据集进行了相关实验,该数据集近几年被车标识别算法广泛使用。XMU数据集有10类车标,每一类车标1 150张,其中1 000张作为训练集,150张作为测试集,实验结果见表3。表3中其他车标识别算法的识别率,如CNN-PT,CNN+ZCA等直接引用了原文给出的实验结果。从表3中可以发现,与其他车标识别算法相比,本文算法表现出了优异的性能,其识别率达到了99.92%,远远超过了其他车标识别算法的识别率,其中包括了2019年最新的CNN+ZCA车标识别算法。
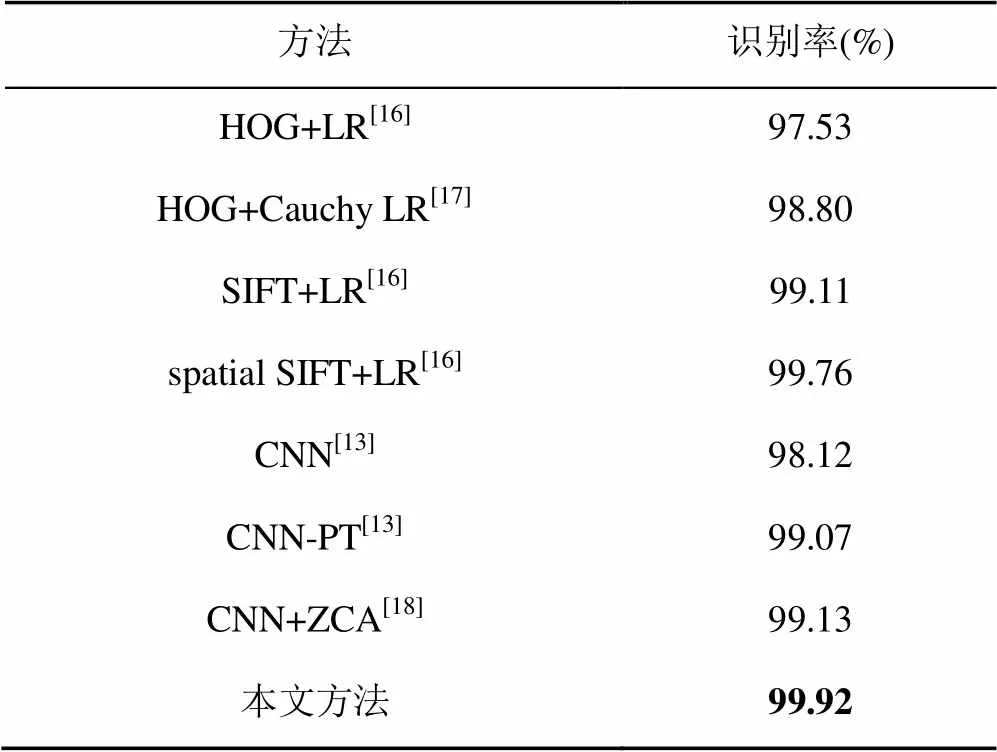
表3 本文算法与其他训练模型的识别效果对比*
(*:10类,每类1 000张训练,150张测试)
综上,在HFUT-VL1和XMU2个数据集对本文方法进行了评估。在HFUT-VL1数据集中的小样本训练情况下,本文算法识别率达到了96.07%,超过同样基于小样本训练的手工描述子,表明本文算法适用于小样本训练场景。此外,在HFUT-VL1数据集上进行大样本训练,本文算法虽然识别率不及CNN模型,但是训练速度和测试速度远超于CNN模型,更加适用于车标识别任务的实时性要求。在XMU数据集上,本文算法表现了优异效果,其99.92%的识别率远超于其他车标识别算法在XMU数据集上的识别率。
3 结束语
本文提出了一种基于目标优化学习的车标识别方法,该方法首先对车标图像提取作为输入数据,然后通过目标函数的优化,学习得到一组特征参数,基于此参数生成特征矩阵,通过K-Means聚类生成特征码本,提取特征向量,最后基于SVM分类器进行分类。实验结果表明,本文提出的基于目标优化学习的方法可以提取到丰富全面的特征信息,获得较好的识别效果。与基于传统描述子的方法相比,本文算法的识别率获得了很大的提升;与CNN分类算法相比,本文算法虽然识别率略低,但是算法的训练速度与测试速度远超于CNN相关分类算法,更加适用于车标识别任务。此外,与现存的车标识别相比,本文算法性能更好,识别率更高。因本文算法与CNN相关算法在识别率方面还是存在差距,未来将继续深度研究,进一步提高本文算法的识别率,提高算法的性能。
[1] 谢永祥, 董兰芳. 复杂背景下基于HSV空间和模板匹配的车牌识别方法研究[J]. 图学学报, 2014, 35(4): 585-589.
[2] 王晓群, 刘宏志. 基于自适应数学形态学的车牌定位研究[J]. 图学学报, 2017, 38(6): 843-850.
[3] LLORCA D F, ARROYO R, SOTELO M A. Vehicle logo recognition in traffic images using HOG features and SVM [C]//16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013). New York: IEEE Press, 2013: 2229-2234.
[4] LIPIKORN R, COOHAROJANANONE N, KIJSUPAPAISAN S, et al. Vehicle logo recognition based on interior structure using SIFT descriptor and neural network [C]//2014 International Conference on Information Science, Electronics and Electrical Engineering. New York: IEEE Press, 2014: 1595-1599.
[5] GU Q, YANG J Y, CUI G L, et al. Multi-scale vehicle logo recognition by directional dense SIFT flow parsing [C]//2016 IEEE International Conference on Image Processing. New York: IEEE Press, 2016: 3827-3831.
[6] PSYLLOS A, ANAGNOSTOPOULOS C N, KAYAFAS E. M-SIFT: A new method for vehicle logo recognition [C]//2012 IEEE International Conference on Vehicular Electronics and Safety. New York: IEEE Press, 2012: 261-266.
[7] PENG H Y, WANG X, WANG H Y, et al. Recognition of low-resolution logos in vehicle images based on statistical random sparse distribution [J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(2): 681-691.
[8] 余烨, 聂振兴, 金强, 等. 前背景骨架区域随机点对策略驱动下的车标识别方法[J]. 中国图象图形学报, 2016, 21(10): 1348-1356.
[9] LEI Z, PIETIKAINEN M, LI S Z. Learning discriminant face descriptor [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(2): 289-302.
[10] LU J W, LIONG V E, ZOU X Z, et al. Learning compact binary face descriptor for face recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(10): 2041-2056.
[11] HUANG K K, DAI D Q, REN C X, et al. Learning kernel extended dictionary for face recognition [J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(5): 1082-1094.
[12] 王海瑶, 唐娟, 沈振辉. 基于深度卷积神经网络的多任务细粒度车型识别[J]. 图学学报, 2018, 39(3): 485-492.
[13] HUANG Y, WU R W, SUN Y, et al. Vehicle logo recognition system based on convolutional neural networks with a pretraining strategy [J]. IEEE Transactions on Intelligent Transportation Systems, 2015, 16(4): 1951-1960.
[14] UL HUSSAIN S, TRIGGS B. Visual recognition using local quantized patterns [M]//ComputerVision– ECCV2012. Heidelberg: Springer, 2012: 716-729.
[15] YU Y, Wang J, Lu J T, et al. Vehicle logo recognition based on overlapping enhanced patterns of oriented edge magnitudes [J]. Computers and Electrical Engineering, 2018, 71: 273-283.
[16] CHEN R, HAWES M, MIHAYLOVA L, et al. Vehicle logo recognition by spatial-sift combined with logistic regression [C]// 19th International Conference on Information Fusion (FUSION). New York: IEEE Press, 2016: 1228-1235.
[17] CHEN R, HAWES M, ISUPOVA O, et al. Online vehicle logo recognition using Cauchy prior logistic regression [C]//2017 20th International Conference on Information Fusion (Fusion). New York: IEEE Press, 2017: 1-8.
[18] SOON F C, KHAW H Y, CHUAH J H, et al. Vehicle logo recognition using whitening transformation and deep learning [J]. Signal, Image and Video Processing, 2019, 13(1): 111-119.
A Vehicle Logo Recognition Method Based on Objective Optimization
ZHU Wen-jia1, CHEN Yu-hong2, FENG Yu-jin2, WANG Jun3, YU Ye3
(1. Anhui BaiChengHuiTong Science and Technology Co. Ltd, Hefei Anhui 230009, China; 2. Traffic Police Headquarters of Yunnan Public Security Department, Kunming Yunnan 650224, China; 3. School of Computer and Information, Hefei University of Technology, Hefei Anhui 230009, China)
Vehicle logo recognition plays a more and more important role in intelligent transportation systems and has attracted extensive attention of researchers. Most traditional VLR methods are based on hand-crafted descriptors for which much heuristic knowledge is required, and thus are hard to adapt to complex and changeable realistic scenarios. Compared with hand-crafted descriptors, the feature learned methods perform betterin solving computer vision problems in complex environments. In the present study, a logo recognition method based on objective optimization learning is proposed to solve the VLR problem in this paper. First, feature parameters are automatically learned from pixel different matrix (PDM) extracted from raw images. Then, the PDMs are mapped into compact binary matrices with the learned feature parameters, and then the codebooks are learned from binary matrices with supervised learning. Finally, the feature vectors are extracted from test images with the learned feature parameters and codebooks. Experiments are carried out on open datasets HFUT-VL and XMU, and the results are analyzed and compared with other state-of-the-art methods. Experimental results show that our method can obtain higher recognition accuracy than hand-crafted descriptor based methods, and less training and testing time is required than deep learning based methods.
vehicle logo recognition; objective optimization; feature learning; codebook; pixel difference matrix
TP
10.11996/JG.j.2095-302X.2019040689
A
2095-302X(2019)04-0689-08
2019-02-28;
定稿日期:2019-05-10
安徽省重点研究和开发计划项目(201904d07020010);安徽省自然科学基金项目(1708085MF158);合肥工业大学智能制造技术研究院科技成果转化及产业化重点项目(IMICZ2017010)
朱文佳(1980-),男,安徽安庆人,工程师,硕士,技术总监。主要研究方向为智慧交通。E-mail:zwjnet@163.com
余 烨(1982-),女,安徽合肥人,副教授,博士,硕士生导师。主要研究方向为计算机视觉。E-mail:yuye@hfut.edu.cn
猜你喜欢
世界汽车(2022年3期)2022-05-23
空间科学学报(2020年1期)2021-01-14
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
中国交通信息化(2019年12期)2019-08-13
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫界·幼教365(中班)(2019年3期)2019-06-11
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2017年8期)2017-06-06
中国高新技术企业(2017年5期)2017-05-05
物联网技术(2016年11期)2017-01-12
