
基于编解码卷积神经网络的单张图像深度估计
2019-09-09 03:21贾瑞明刘立强刘圣杰崔家礼
图学学报 2019年4期
贾瑞明,刘立强,刘圣杰,崔家礼
基于编解码卷积神经网络的单张图像深度估计
贾瑞明,刘立强,刘圣杰,崔家礼
(北方工业大学信息学院,北京 100144)
针对传统方法在单目视觉图像深度估计时存在鲁棒性差、精度低等问题,提出一种基于卷积神经网络(CNN)的单张图像深度估计方法。首先,提出层级融合编码器-解码器网络,该网络是对端到端的编码器-解码器网络结构的一种改进。编码器端引入层级融合模块,并通过对多层级特征进行融合,提升网络对多尺度信息的利用率。其次,提出多感受野残差模块,其作为解码器的主要组成部分,负责从高级语义信息中估计深度信息。同时,多感受野残差模块可灵活地调整网络感受野大小,提高网络对多尺度特征的提取能力。在NYUD v2数据集上完成网络模型有效性验证。实验结果表明,与多尺度卷积神经网络相比,该方法在精度<1.25上提高约4.4%,在平均相对误差指标上降低约8.2%。证明其在单张图像深度估计的可行性。
CNN;编码器-解码器;深度估计;单目视觉
随着人工智能技术的快速发展,虚拟现实[1]和自动驾驶[2]等技术对于三维重建需求巨大。准确的深度信息对于重建三维场景具有重要意义,其广泛应用于语义分割[3-4]、目标跟踪[5-6]和机器人控制系统[7]等任务。工业界多使用激光雷达或激光扫描仪获取深度图。前者可用于动态场景,但获取的深度图较为稀疏;后者获取的深度图稠密但成像耗时长,且一般用于静态场景。同时两者的成本较高,而单张图像获取成本较低。因此,研究通过单张图像进行深度估计具有较大的实用价值。然而,由于单张图像本身存在信息缺失,使用单张图像进行深度估计属于病态问题,具有较大的挑战。
传统图像估计深度的方法多基于双目视觉系统,其精度易受视差图质量的影响。实际场景中,受光照条件、图像纹理分布及观测视角的影响,难以获取高质量的视差图。因此,研究者们提出了多种算法用于获取较高质量的视差图[8-10]。然而,单目视觉算法着重解决如何估计物体间的相对位置关系。通过单张图像恢复深度的原理包括:①在实际场景中,物体间存在确定的相对关系及几何结构;②人的视觉形成过程中,可根据经验知识推断物体间的距离。与传统方法相比,深度神经网络具备较强的拟合能力,在经过大量训练后,可以拟合真实样本分布。本文提出基于卷积神经网络(convolution neural network, CNN)的单张图像深度估计网络:层级融合编码器-解码器网络(fused-layers encoder-decoder network, FLEDNet),具体贡献如下:
(1) 编码器端。提出层级融合模块(fused-layers block, FLB),该模块提升编码器网络对多尺度特征的利用率。
(2)解码器端。提出多感受野残差模块(multi-receptive field res-block, MRFRB)作为解码器主要组成部分。相较于Inception-ResNet网络[11],MRFRB可灵活增加网络的感受野,同时残差结构的引入改善了网络在加深时梯度消失的问题。
1 相关工作
从图像或视频中估计深度信息一直以来是研究热点,目前大量的研究工作多集中于基于深度神经网络与非深度神经网络方法的研究。
(1) 非深度神经网络方法。KARSCH等[12]提出基于最近邻(k-nearest neighbor, kNN)的搜索方法,从RGBD数据库中选取候选图像,通过SIFT Flow算法[13]对深度信息进行优化,实现图像深度估计。但该方法需要建立完善的数据库,计算量较大,在实际应用时局限性较大。TIAN等[14]基于马氏距离(Mahalanobis distance)和高斯加权函数(Gaussian weighting function)的深度信息采样方法,在Make3D数据集上取得较好的实验结果。HERRERA等[15]提出基于聚类的学习框架,通过在色彩空间分析结构相似性以及使用kNN搜索算法从图像中提取深度信息。LIU等[16]使用高阶离散-连续的条件随机场从单张图像获取深度。CHOI等[17]提出一种在梯度域建模的方法,是一种非参数模型。当输入图像纹理分布重复时,该方法失效。本文采用的深度卷积神经网络对输入图像的纹理分布较为鲁棒。
(2) 深度神经网络方法。其在计算机视觉任务中表现出色,文献[18]提出多尺度CNN以及尺度不变的损失函数,实现对单张图像的深度、表面法线和语义标签的估计,但图像分辨率较低。文献[19]使用多孔卷积神经网络(atrous convolution neural network, ACNN)与条件随机场相结合的策略,获得了较好的单张图像深度估计效果。袁建中等[20]提出基于ResNet和DenseNet结合的深度卷积神经网络用于解决道路场景的单目视觉深度估计问题。JUNG等[21]使用条件生成对抗网络(conditional generative adversarial network)实现单张图像深度估计,采用基于编码器-解码器与精炼网络(refinement network)相结合的生成器网络,在客观数据集上达到了较好的实验结果。LAINA等[22]使用残差结构设计网络,并提出快速上卷积(up-convolution)网络,在NYUD v2[23]上有优异的表现。
2 深度估计网络
使用CNN从单张图像中估计深度信息属于密集预测任务,编码器-解码器网络广泛应用于密集预测任务中,例如语义分割[24]、图像风格转换[25]等。本文对传统编码器-解码器网络结构进行改进,提出端到端的FLEDNet。同时,针对深度预测问题,设计了MRFRB,进一步提升网络的深度信息预测能力。
2.1 层级融合编码器-解码器网络结构
针对单目视觉中,深度预测存在过程复杂、精度较低等问题,例如文献[16,19]依赖条件随机场对网络输出的深度图进行处理,以得到精度更高的深度图。本文提出FLEDNet,其输入为RGB彩色图像,网络直接输出的是估计的深度图,且无需任何后处理操作,实现了端到端的深度估计。本文采用监督方式训练FLEDNet,使用与输入图像对应的深度图作为监督信息,网络学习从二维彩色图像(RGB)到深度图的映射关系,完成密集预测任务。FLEDNet包括编码器网络、层级融合模块和解码器网络3个部分,如图1所示。

图1 FLEDNet网络结构图
(1) 编码器网络(encoder network)。ResNet[26]广泛用于密集预测任务中的基础网络,文献[22]提出基于ResNet的深度估计网络,取得了较好的效果。因此,FLEDNet编码器网络采用ResNet-50,对输入的彩色图像进行特征提取,但保留ResNet-50至block4(level-1)。同时,为利用不同尺度的特征图,从ResNet-50中引出block4(level-1)和block3(level-2)的输出作为层级融合模块的输入。
(2) 层级融合模块(fused-layers block, FLB)。传统编码器-解码器网络结构中,仅使用编码器的最后一层输出作为解码器的输入,该方式缺乏对多层级特征的利用。考虑到不同层级的特征图差异,例如,特征的抽象程度和特征图的空间分辨率,本文提出层级融合模块,以解决不同尺度特征的融合问题。
(3) 解码器网络(decoder network)。本文使用4个MRFRB和1个3×3卷积层构建解码器网络。MRFRB负责对编码器输出的特征图进行解码,每级MRFRB对输入特征图的宽高放大2倍。MRFRB-4输出特征图的空间分辨率较大,若继续使用MRFRB对特征图放大至输出尺寸,会大幅增加网络参数量且消耗大量的计算资源。因此,借鉴文献[27]的设计,本文在MRFRB-4后采用卷积核大小为3×3,步长为1的卷积层将输出特征图通道降为1,并采用双线性插值操作,将特征图放大至输出尺寸,以适应网络输出。
2.2 层级融合模块
随着网络的加深,编码器网络提取特征信息的抽象层次不断提高,特征图的空间分辨率不断缩小,但通道数较多,特征图含有更多的高级语义信息。多尺度思想广泛应用于语义分割、目标检测的任务中。本文提出的层级融合模块(图2)通过对不同层级的特征图进行融合,实现了多尺度思想,经实验验证,提升了网络深度估计的精度。

图2 层级融合模块结构示意图
FLB包括尺度调整、拼接层(concatenate)、dropout和1×1卷积层4个部分。其中,尺度调整用于将不同分辨率的输入统一至相同尺寸,以便进行拼接操作。例如,图1需通过使用步长为2的均值池化将level-2 (15×19)降至level-1 (8×10)的大小,以实现不同层级特征在通道维度上的拼接操作。实验中发现直接使用拼接不同层级得到的特征进行解码会造成网络收敛过慢,训练难的问题。因此,加入dropout操作,对拼接后的特征进行随机丢失操作(设dropout失活率为0.2),再使用1×1卷积降低通道数,以加速网络训练。
2.3 多感受野残差模块
考虑到编码器网络ResNet可通过最大值池化操作不断缩减特征图大小,即从多个尺度对输入图像进行特征提取,获得高级语义信息。因此,解码器网络应设计具有多个感受野的卷积层,以从不同尺度对高级语义信息进行解码。如何设计具有多感受野的网络结构成为研究重点。受Inception-ResNet启发,本文提出MRFRB,其作为FLEDNet解码器的主要组成部分,包括:缩减模块和多感受野模块2部分,如图3所示。
(1) 缩减模块。该模块的主要功能是放大特征图并降低通道数。编码器输出带有高级语义信息的特征图,其具有空间分辨率较小但通道数较大的特点。例如,图1中,ResNet-50中block4 (level-1)输出特征图的大小为8×10 (高×宽),但通道数高达2 048。与编码过程不同,解码操作需要不断放大特征图尺寸且减小通道数,本文采用双线性插值方法放大特征图,通过卷积层来降低通道数。考虑到随着网络加深,梯度易消失的问题,该模块采用残差结构。其中,2个3×3卷积层对输入特征图进行信息提取并降低通道数。在跳跃卷积连接上的1×1卷积层可负责调整特征图的通道数,以使其输出的通道数与3×3卷积层输出的特征图通道数一致。

图3 多感受野残差模块结构图
(2) 多感受野模块。该模块主要负责从高级语义信息中解码深度信息。人类的视觉系统中,估计深度信息并不仅仅只关注局部场景,通常需要使用场景中的参照物来估计距离。因此,设计具有多种感受野的解码器模块是能否较好地重建深度信息的关键。缩减模块中的结构具备一定的特征映射能力,但仅使用3×3卷积层,其感受野有限。Inception-ResNet中,Inception模块中使用了多种卷积,例如,卷积核大小为3×3、5×5、7×7等卷积层以使得网络具有多种感受野,提升特征提取的能力。其使用的大尺寸卷积核,例如尽管5×5卷积层可拆分为1×5和5×1卷积层进行等效,但参数量仍然较大,特别是当模块数量增多时,网络参数量巨大。故多感受野模块中,使用不同膨胀率(dilation rate)的空洞卷积(atrous convolution)[28]实现多感受野功能。空洞卷积优势包括:①可通过设置膨胀率,灵活的控制感受野大小;②同等大小的感受野条件下,相较于传统卷积,空洞卷积参数量大幅下降。多感受野模块中,使用了2个卷积核为3×3且有填充的空洞卷积,膨胀率=2时,空洞卷积可提供7×7的感受野;=4的空洞卷积可提供15×15的感受野。随着网络层数的增多,网络的表达能力随之提升,但易产生梯度消失现象,网络训练较为困难,故在多感受野模块中,加入了残差结构。为尽量避免卷积层对梯度传播的影响,多感受野中的跳跃连接中未使用1×1卷积,输入的特征图以恒等映射的方式与卷积层输出构成残差结构。多感受野残差模块中的卷积层均使用ReLU作为激活函数。
3 实验结果及分析
为验证FLEDNet及深度感知损失函数的有效性,本文使用公开数据集NYUD v2作为评估数据集。评估本文方法的性能。
3.1 实验设置及评价指标
本文实验环境为E5-2620 v4 处理器、NVIDIA Titan XP和16 GB内存。使用Tensorflow作为网络训练平台,Adam作为优化器,设初始学习率为0.001,batch size设置为16。本文使用准确率、平均相对误差、对数平均误差和均方根误差等指标评估方法的有效性,各指标表达式为:
其中,为真实的深度值;为预测的深度值。
3.2 NYUD v2数据集实验结果


表1 不同深度估计方法对比
(注:表现最好的指标均加粗)
本文提出的方法在大部分指标上均优于文献[12]、文献[16]和文献[18]的方法。与文献[18]方法相比,本文方法在<1.25指标上高了约4%,在平均相对误差(Abs rel)指标上高了约8%。另外,在<1.25指标上比文献[19]的方法高了约14%,且其方法需要CRF对CNN的输出做后处理,而本文不需要任何后处理步骤即可达到较好的深度估计效果。
从图4可以看出,文献[18]提出的方法在部分区域的深度预测结果误差较大。例如,图4第4行矩形框“1”标出的区域与真实深度值差异较大;本文的预测结果(矩形框“2”标出的区域)与真实深度值较为接近。表明本文方法具有一定的有效性。

(a) 彩色输 入图像(b) 文献[18] 结果(c) 本文 结果(d) 真实 深度
3.3 层级融合模块实验结果
FLB通过对不同抽象层级的特征图进行融合,使得解码器可利用具有多抽象层次的信息。为验证不同层级对网络性能的影响,需研究如何使用各层级特征,表2给出了层级组合与网络性能的实验结果。

表2 不同层级的网络性能指标
其中,“层级-1”表示FLB的输入只有ResNet50的block4(对应图1中的level-1);“层级-1,2”包括ResNet50的block4和block3(分别对应图1中的level-1和level-2);“层级-1,2,3”包括ResNet50的block4、 block3和block2(分别对应图1中的level-1、 level-2和level-3)。网络均使用FLEDNet,损失函数为L1,其他实验超参数均一致。
图5给出不同层级组合对准确率的影响,其中“level-1”,“level-1,2”和“level-1,2,3”分别对应表2中的“层级-1”、“层级-1,2”和“层级-1,2,3”。
结合表2及图5可知,层级组合“level-1,2”表现最好。原因为:①层级组合“level-1”仅使用ResNet50 block4的输出,尺度单一,且特征的抽象层次单一;②层级组合“level-1,2,3”利用ResNet50的3个输出,FLB的输出包括多尺度信息及不同抽象程度高级语义信息,有利于解码器恢复深度信息。
理论上,“level-1,2,3”性能应超过层级组合“level-1,2”,但实验发现,其参数量比“level-1,2”高5.2% (表3),表明“level-1,2,3”的网络更难训练。因此,层级组合“level-1,2”不仅利用了多尺度信息且易于网络训练,故本文选择该层级组合作为层级模块的输入方式。

表3 不同层级组合的网络模型参数量
3.4 多感受野残差网络结构实验结果
3.4.1 MRFRB有效性验证
MRFRB作为解码器网络的核心组成部分,其性能直接影响输出结果的精度。本文分别使用反卷积deconv和文献[22]的up-Projection模块替换图1中的MRFRB,验证不同解码模块对网络造成的影响。其中,up-Projection模块结构如图6所示。
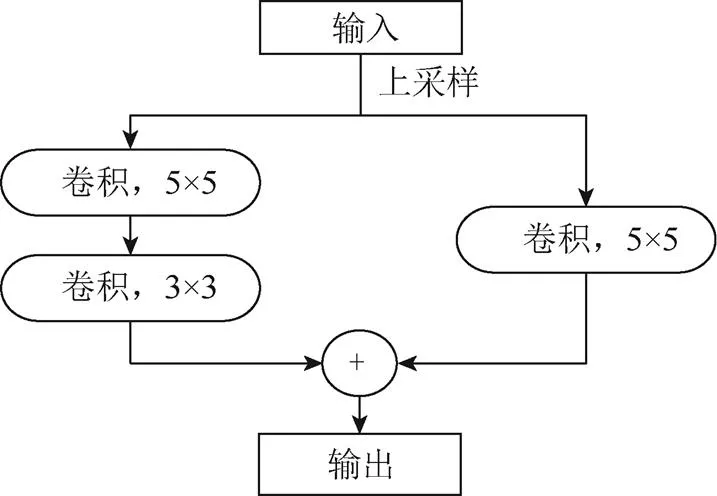
图6 up-Projection结构示意图
实验中,本文使用卷积核大小为3×3,步长为2的转置卷积实现反卷积deconv,损失函数使用L1。对比表4结果可知,本文提出的MRFRB模块在准确率和误差指标上均优于deconv和up-Projection[22]。原因如下:①MRFRB模块的多感受野设计有利于解码器网络从不同尺度恢复深度信息;②MRFRB使用空洞卷积,在相同感受野条件下,具有参数量小,易于训练的优点。

表4 不同解码器模块的实验结果
3.4.2 缩减模块实验
在MRFRB中,缩减模块负责提升特征图空间分辨率并降低通道数。该模块结构类似于残差结构,但因需调整通道数,跳跃连接中加入了一层卷积,称为跳跃卷积连接。为研究其对深度估计结果的影响,去掉该模块中的跳跃卷积连接,网络命名为FLEDNet-no-scc。实验结果见表5。

表5 Reduction模块实验结果
根据表5实验数据可知,若去掉跳跃卷积连接,则FLEDNet效果下降较大,表明其设计有利于提高网络对特征的利用率,同时可增强梯度的传播,有利于网络训练。
4 结 论
本文针对单目视觉深度估计问题提出一种基于编解码结构的FLEDNet模型:编码器端引入层级融合模块,该模块对来自不同层级的编码器输出进行特征融合,并作为解码器的输入,提高网络对多尺度特征信息的利用率。提出MRFRB,以构建解码器网络,使得网络“关注”的区域大小多样化,有利于提升精度。同时,残差结构的设计避免网络加深时,梯度消失问题,有利于网络训练。本文网络模型以ResNet50为编码器的主干网络,通过FLB利用其多个层级输出。解码器直接输出预测的深度图,实现了端到端的深度估计。与文献[19]等基于CRF做后处理的方法相比,本文方法无需任何后处理。实验结果表明,在NYUD v2数据集上,相较于多尺度卷积神经网络,本文提出的方法在精度<1.25上提高约4.4%;在平均相对误差指标上降低约8.2%。下一步将尝试对网络训练的损失函数进行改进,以提升深度估计的精度。
[1] 刘源, 陈杰, 龚国成, 等. 常用三维重建技术研究[J]. 电子技术与软件工程, 2018(11): 86-88.
[2] 叶语同, 李必军, 付黎明. 智能驾驶中点云目标快速检测与跟踪[J]. 武汉大学学报:信息科学版, 2019, 44(1): 139-144, 152.
[3] QI X J, LIAO R J, JIA J Y, et al. 3D graph neural networks for RGBD semantic segmentation [C]//2017 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2017: 5209-5218.
[4] GHAFARIANZADEH M, BLASCHKO M B, SIBLEY G. Efficient, dense, object-based segmentation from RGBD video [C]//2016 IEEE International Conference on Robotics and Automation (ICRA). New York: IEEE Press, 2016: 2310-2317.
[5] KIM J S. Object detection using RGBD data for interactive robotic manipulation [C]//2014 11th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI). New York: IEEE Press, 2014: 339-343.
[6] LIN D H, FIDLER S, URTASUN R. Holistic scene understanding for 3D object detection with RGBD cameras [C]//2013 IEEE International Conference on Computer Vision. New York: IEEE Press, 2013: 1417-1424.
[7] TUBMAN R, POTGIETER J, ARIF K M. Efficient robotic SLAM by fusion of RatSLAM and RGBD-SLAM [C]//2016 23rd International Conference on Mechatronics and Machine Vision in Practice (M2VIP). New York: IEEE Press, 2016: 1-6.
[8] ZAGORUYKO S, KOMODAKIS N. Learning to compare image patches via convolutional neural networks [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 4353-4361.
[9] ŽBONTAR J, LECUN Y. Computing the stereo matching cost with a convolutional neural network [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 1592-1599.
[10] LUO W J, SCHWING A G, URTASUN R. Efficient deep learning for stereo matching [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 5695-5703.
[11] SZEGEDY C, IOFFE S, VANHOUCKE V, et al. Inception-v4, Inception-ResNet and the impact of residual connections on learning [EB/OL].[2019-02-03]. https://arxiv.org/abs/1602.07261.
[12] KARSCH K, LIU C, KANG S B. Depth transfer: Depth extraction from video using non-parametric sampling [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(11): 2144-2158.
[13] LIU C, YUEN J, TORRALBA A. SIFT flow: Dense correspondence across scenes and its applications [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(5): 978-994.
[14] TIAN H, ZHUANG B J, HUA Y, et al. Depth extraction from a single image by sampling based on distance metric learning [C]//2014 IEEE International Conference on Image Processing (ICIP). New York: IEEE Press, 2015: 2017-202.
[15] HERRERA J L, DEL-BLANCO C R, GARCIA N. Automatic depth extraction from 2D images using a cluster-based learning framework [J]. IEEE Transactions on Image Processing, 2018, 27(7): 3288-3299.
[16] LIU M M, SALZMANN M, HE X M. Discrete-continuous depth estimation from a single image [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2014: 716-723.
[17] CHOI S, MIN D B, HAM B, et al. Depth analogy: Data-driven approach for single image depth estimation using gradient samples [J]. IEEE Transactions on Image Processing, 2015, 24(12): 5953-5966.
[18] EIGEN D, FERGUS R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture [C]//2015 IEEE International Conference on Computer Vision (ICCV). New York: IEEE Press, 2015: 2650-2658.
[19] 廖斌, 李浩文.基于多孔卷积神经网络的图像深度估计模型[J/OL].计算机应用, 2018: 1-10. [2019-02-03]. http://kns.cnki.net/kcms/detail/51.1307.TP.20180926.1508.004.html.
[20] 袁建中, 周武杰, 潘婷, 等.基于深度卷积神经网络的道路场景深度估计[J/OL].激光与光电子学进展, 2018: 1-17. [2019-02-03]. http://kns.cnki.net/KCMS/detail/31.1690.TN.20181203.1637.048.html.
[21] JUNG H, KIM Y, MIN D B, et al. Depth prediction from a single image with conditional adversarial networks [C]//2017 IEEE International Conference on Image Processing (ICIP). New York: IEEE Press, 2017: 1717-1721.
[22] LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks [C]//2016 Fourth International Conference on 3D Vision (3DV). New York: IEEE Press, 2016: 239-248.
[23] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from RGBD images [M]//Computer Vision – ECCV 2012. Heidelberg: Springer, 2012: 746-760.
[24] RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional networks for biomedical image segmentation [M]//Lecture Notes in Computer Science. Cham: Springer International Publishing, 2015: 234-241.
[25] ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [EB/OL]. [2019-02-03]. https://arxiv.org/abs/1611.07004.
[26] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 770-778.
[27] MA F C, KARAMAN S. Sparse-to-dense: Depth prediction from sparse depth samples and a single image [C]//2018 IEEE International Conference on Robotics and Automation (ICRA)New York: IEEE Press, 2018:1-8.
[28] CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. [2019-02-03]. https://arxiv. org/abs/1706.05587.
[29] ZHUO W, SALZMANN M, HE X M, et al. Indoor scene structure analysis for single image depth estimation [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)New York: IEEE Press, 2015: 614-622.
[30] EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network [EB/OL]. [2019-02-03]. https://arxiv.org/ abs/1406.2283.
[31] LIU F Y, SHEN C H, LIN G S, et al. Learning depth from single monocular images using deep convolutional neural fields [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 2024-2039.
Single Image Depth Estimation Based on Encoder-Decoder Convolution Neural Network
JIA Rui-ming, LIU Li-qiang, LIU Sheng-jie, CUI Jia-li
(School of Information Science and Technology, North China University of Technology, Beijing 100144, China)
Focusing on the poor robustness and lower accuracy in traditional methods of estimating depth in monocular vision, a method based on convolution neural network (CNN) is proposed for predicting depth from a single image. At first, fused-layers encoder-decoder network is presented. This network is an improvement of the end-to-end encoder-decoder network structure. Fused-layers block is added to encoder network, and the network utilization of multi-scale information is improved by this block with fusing multi-layers feature. Then, a multi-receptive field res-block is proposed, which is the main component of the decoder and used for estimating depth from high-level semantic information. Meanwhile, the network capacity of multi-scale feature extraction is enhanced because the size of receptive field is flexible to change in multi-receptive field res-block. The validation of proposed network is conducted on NYUD v2 dataset, and compared with multi-scale convolution neural network, experimental results show that the accuracy of proposed method is improved by about 4.4% in<1.25 and average relative error is reduced by about 8.2%. The feasibility of proposed method in estimating depth from a single image is proved.
CNN; encoder-decoder; depth estimation; monocular vision
TP 391
10.11996/JG.j.2095-302X.2019040718
A
2095-302X(2019)04-0718-07
2019-02-14;
定稿日期:2019-03-18
北京市教委面上基金(KM201510009005);北方工业大学学生科技活动项目(110051360007)
贾瑞明(1978-),男,北京人,助研,博士,硕士生导师。主要研究方向为图像处理与智能识别等。E-mail:jiaruiming@ncut.edu.cn
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
小学生必读(低年级版)(2021年10期)2022-01-18
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
影像视觉(2020年4期)2020-05-09
家庭影院技术(2019年8期)2019-12-04
印刷技术·数字印艺(2016年11期)2016-12-06
印刷技术·数字印艺(2016年7期)2016-05-14
