
智能配镜三维特征参数提取方法研究
2019-09-09 03:38侯增选李岩翔赵有航王军骅
图学学报 2019年4期
侯增选,李岩翔,杨 武,赵有航,王军骅
智能配镜三维特征参数提取方法研究
侯增选1,李岩翔1,杨 武2,赵有航1,王军骅1
(1. 大连理工大学机械工程学院,辽宁 大连 116024;2. 眼艺生活电子商务有限公司,广东 深圳 518000)
针对智能配镜中三维面部特征点提取算法复杂度较高的问题,提出一种将三维点云转换为映射图像定位特征点的方法。采用Voronoi方法计算面部三角网格各顶点处的高斯曲率、平均曲率。选取鼻尖、眼角等曲率特征明显的区域估计面部点云姿态。根据曲率旋转不变性,使用初选的点云方向向量简化旋转矩阵的计算,使面部点云正面朝向视点。将点云映射转换为图像,三维网格模型中三角面片一对一映射到图像中的三角形。搭建卷积神经网络,使用Texas 3DFRD数据集进行模型训练。进行人脸对齐,预测所得各面部特征点分别限制在图像某三角形中。根据图像中三角形映射查找三维网格模型中对应三角面片,通过三角面片顶点坐标计算配镜所需的面部特征点位置坐标,实现配镜特征参数的提取。
点云;人脸对齐;映射;特征提取;配镜
随着社会信息化、网络化程度的提高,线上配镜作为新零售方式方兴未艾,人们迫切需要一种快速、有效的自动人脸参数获取技术。面部特征点的定位为人脸识别、姿态估计与表情识别、面部特征提取与三维面部重建等后续领域的研究提供基础数据。使用几何面部归一化的人脸界标定位已经有了良好的效果,明显改善了识别结果[1]。
近年来,人脸特征点定位技术发展迅猛,KOWALSKI等[2]提出一种基于关键点热图的深度对齐网络(deep alignment network, DAN),网络输入整张面部图像,并引入关键点热图作为补充,级联检测关键点。此后,KUMAR和CHELLAPPA[3]在热图基础上,提出单一的树突状卷积神经网络(convolutional neural network, CNN),可以提高面部姿态估计与面部特征点对齐精度。DENG等[4]提出一种级联多视图沙漏模型,可以从二维图像估计三维的面部标定点。RANJAN等[5]采用多任务学习的方法,实现了利用多任务卷积神经网络(multi-task cascaded convolutional network,MTCNN)同时做人脸检测、关键点定位、姿态估计与性别判断。HONARI等[6]提出一种半监督学习改善关键点定位的方法,提高了关键点定位精度。WU等[7]使用面部边缘信息辅助关键点回归的方法,能够在室外环境、面部遮挡、夸张表情等情况下仍能保持较高的正确率。
上述方法均采用二维的RGB色彩信息或灰度信息进行特征点的定位,光照、面部姿态等条件对二维关键点的定位算法的鲁棒性影响较大。三维的点云含有比二维图像更丰富的信息,因此可以克服以上的缺陷。目前照相式扫描仪、三维激光扫描仪、深度传感器等相关设备技术已日趋成熟,三维的人脸对齐与人脸关键点检测的研究刚刚起步。GUO等[8]提出一种基于关键点和局部特征的三维人脸识别算法,根据有价值轮廓线和平均曲率检测关键点,但有价值轮廓线选取较为复杂、算法效率较低。冯超和陈清江[9]提出一种多特征相结合的三维人脸关键点检测方法,使用曲率与测地距离直接对三维点云上的特征点进行标记并训练模型,但该方法误差较大。MARCOLIN和VEZZETTI[10]运用三维人脸分析了105个描述符,并将其映射到面部深度图像,以此进行特征点的定位。胡阳明等[11]根据三维人脸柱面展开的二维纹理图进行自动特征定位并分片,以实现三维面部特征点对齐。该方法准确性好,但有赖于三维模型色彩信息贴图,不适用于三维激光扫描生成的点云。PAPAZOV等[12]提出通过深度图像计算三角面片描述符,实时获得头部姿势以及面部标定点的方法。
为了能够快速并且准确地获取与配镜有关的面部关键点位置,本文提出一种将点云姿态快速校正,并降维为映射图像的面部特征点定位方法。首先将点云姿态进行校正,随后获取校正姿态后的面部深度图像,训练深度图像的特征点定位模型,最终获得配镜有关面部参数。
1 离散点云曲率计算
对于任一点云而言,如果将相机、扫描仪等主轴方向设为轴,图像的横向与纵向分别为轴与轴,则点云构造的曲面为

其中,深度为坐标与的函数。由微分几何学[12]可知,对于嵌入欧氏空间的二维曲面其曲率包括高斯曲率与平均曲率,即
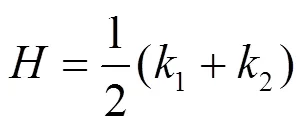
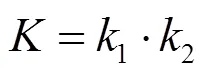
其中,1与2分别为曲率最大及最小值,称为主曲率,并称2个曲率极值所处的方向为主方向。且

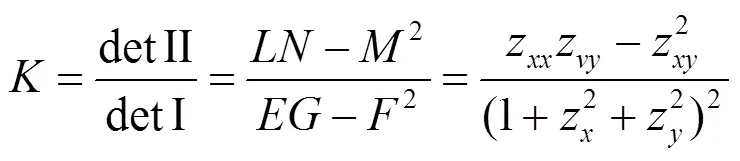
其中,detI与det II为曲面第一、二基本形式的行列式;,,是第一基本形式的系数;,,为第二基本形式的系数。
然而对于含有拓扑信息结构的点云,曲率计算需要构造离散点三角曲面[13]。对于任意点V,j,其临近三面片集合为{f,j}0,邻域内顶点集合为{V,j}1,临近三角形面片的法向量为{,j}0。点云三角网格化之后任意顶点V,j临近点的拓扑结构采用平面拟合如图1所示。

图1 顶点Vi,j与其邻域局部结构
各三角面片f,j中的法向量,j为

顶点V,j的法向量,j定义为环邻域三角面片的法向量加权和,定义|F|为V,j邻域三角面片个数,则V,j法向量为

根据文献[14-15]的方法,将光滑曲面看作是一簇三角网格的线性或极限逼近,则由拉普拉斯算子的性质可得平均曲率为

由Gauss-Bonnet定理可得高斯曲率为

其中,A为顶点V,j在拟合曲面的邻域三角面片为锐角或钝角三角形的混合面积,即

对于顶点为V,j,顶点相邻点V1,j与V1组成的三角面片来说,若此三角形为锐角三角形,则
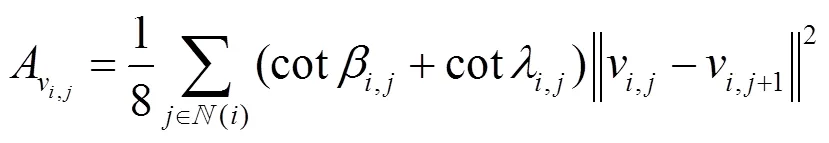
若此三角形中为钝角,此时
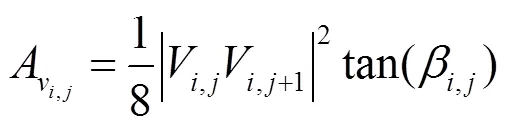
由以上公式可计算面部离散点云的与等参数值。点云各曲率如图2所示。
与可以在一定程度上反映曲面的不平坦程度,但其分别是曲率的内在与外在度量,因此有一定的局限性。例如其中一个主曲率为0时高斯曲率为0;而2个主曲率为相反数时,平均曲率为0,但不代表曲面某点在当前情况下完全平坦,对于曲面上的脊、谷、鞍形谷或是极小曲面来说,都有可能出现或为0的情况。所以还应当关注2个正交且共轭的最大、最小主曲率max与min。

(a) 高斯曲率K(b) 平均曲率H

由于与具有旋转不变性与平移不变性,可以分析出当前点的邻域曲面的结构,和的符号可以判断临近曲面的大致形状(表1)。

表1 平均曲率H、高斯曲率K的符号与对应曲面类型
考虑到人体面部眼角位置局部为凹,而鼻尖区域局部为凸,通过选取曲率较显著的3个点可确定面部点云朝向的基准平面。然后求得当前三维网格模型各顶点处的曲率,即可对点云姿态进行调整。
2 点云姿态校正
采集面部的特征参数,除了需要对点云进行预处理外,还需对面部模型进行姿态的矫正,以获得面部点云正视图投影信息。头部可以近似看作为刚体,假设任意姿态下的头部点云为1,面部朝向正前方的模板点云为0,1可以围绕,,3个坐标轴进行旋转,达到近似于模板点云0的姿态。
计算面部点云各处的曲率,其中面部曲率最为特殊的区域为:鼻尖与2个眼角点。其中,鼻尖处曲面为峰,其与均为正值且在某点达到极大值;而对于局部呈阱曲面的两眼角位置和来说,其高斯曲率为正值,平均曲率为负值。由此3个点可确定一个平面,其法向量方向即为当前点云方向。而对于正视前方的模板点云而言,同样由其2个眼角0和0与鼻尖0确定模板朝向0,则可以计算出2个法向量的夹角。由于已经得到目标方向矢量与当前面部点云的方向矢量,便可求出旋转矩阵,完成当前面部点云姿态旋转。对于2个空间向量、0,其夹角为

其沿,,轴的夹角分别为2个空间向量在,,平面的投影向量的夹角,则相对于轴的旋转夹角,即

同理可求出相对于,轴的旋转夹角和。
因此,,,轴的旋转矩阵,,可表示为
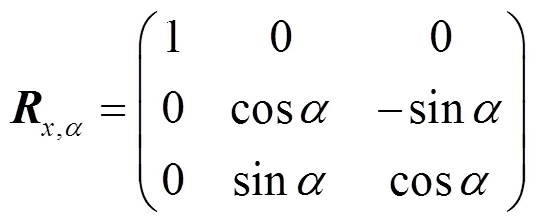

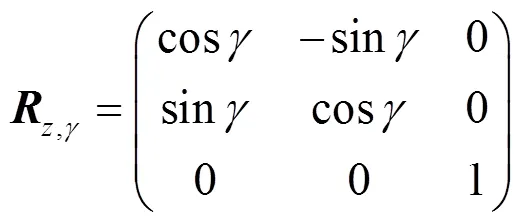
则总的旋转矩阵为

进行坐标旋转之后,原点云转换为点云T,即

各朝向点云与模板点云如图3所示。

(a) 偏左侧(b) 偏上方(c) 偏右侧
3 特征点定位
将面部点云姿态矫正为正视前方的角度后,为获得面部配镜所需的各参数,需要对面部的关键点进行标定,即进行人脸对齐(face alignment)。目前在二维的图像领域,通过神经网络进行深度学习等方法预测图像中面部的特征点已经非常的快捷和准确,所以本文采取将点云映射至正视的深度图后再进行关键点位置的获取。深度图(depth map)包含了场景对象的表面到视点的距离信息,通常至少为8位,即最少有256个灰度,每个像素都记录了从视点(viewpoint)到遮挡物表面的距离,8位深度图可以满足特征点识别的精度。
利用Texas3DFR数据库[16]作为数据集,标定面部配镜相关特征点,包括眼眶、眉毛、鼻梁、脸颊等位置。通过多任务卷积神经网络(multi-task cascaded convolutional network, MTCNN)寻找人脸边界并提取出面部图像,将面部纹理图像与深度图像归一化像素为150×150的图像。本文纹理-深度 (RGB-Depth, RGB-D)神经网络结构为(图4):输入层为2个3通道3×150×150;紧接着2个卷积结构单元,每个单元都在卷积计算之后采用ReLU层作为激活函数提高网络非线性拟合能力;并在每个结构单元的最后采用池化层以简化网络计算复杂度,并提取主要特征。其中,第1个单元卷积层conv1卷积核大小为5×5,池化层pool1大小为3×3;第2个单元卷积层conv2卷积核大小为3×3,池化层pool2大小为3×3。此后进行2个子网络的特征融合,输入第3个卷积层,第3单元卷积层conv_3卷积核大小为3×3,池化层pool3大小为3×3;第4个单元卷积层conv4卷积核大小为3×3,池化层大小为3×3。之后通过全连接层提取与综合之前计算出的特征向量,第1个全连接层含有1 536个节点,第2个全连接层含有500个节点,最后输出神经网络预测的特征点坐标。

图4 RGB-D神经网络结构图
4 实例验证与分析
为验证本文提出的自动配镜点云面部关键点定位方法的有效性,特开发了三维点云姿态估计与校正系统,并通过矫正之后的点云生成正视的深度图像与纹理图像。基于TensorFlow平台训练CNN模型,在映射图像上预测人体面部关键点的位置。本文通过三维激光扫描仪获取人体面部点云,在Intel i5 7500 CPU上处理点云并获取关键点坐标,以图5点云为例,共获取左、右侧眉毛特征点坐标各5个,鼻梁特征点坐标4个,左、右眼圈坐标各6个,脸颊坐标17个。

图5 深度图像面部特征点定位效果
对于三维网格模型,其表面由若干三角面片拼接而成。若将三维网格模型映射至平面,则其表面的空间三角形也将对应地映射为平面三角形,如图6(a)所示。
本文将以三角面片为单位,进行纹理信息的映射,效果如图6(c)所示。在投影的过程中,实际世界坐标系与坐标按照系数映射为图像像素坐标系中的位置。由此,投影生成的图像类似于一个映射表,通过图像中的像素坐标,可知该坐标位置所在的三角面片以及纹理和位置信息。

(a) 三角网格映射(b) 深度映射(c) 纹理信息映射
将映射成的纹理图像与深度图像输入神经网络,可以得到预测的特征点集,并且各特征点均散布在某个三角面片的映射三角形之内,如图7所示。由于面部三角网格模型在预处理时将点云进行降采样,其顶点个数的数量级在104~105,并且根据Delaunay三角剖分原理,三角面片的数量约为顶点数量的2~3倍。因此,使用三角面片顶点数据估计其包含的特征点位置满足配镜精度要求。

图7 面部特征点定位在三角网格之内
本文通过预测的特征点在世界坐标系中的几何坐标,求得配镜相关参数;并对14名被试者的面部参数使用游标卡尺进行手工测量,测量相对误差结果见表2。由表2可知本文提出的自动测量方法的大多数参数测量误差均在可接受范围内。
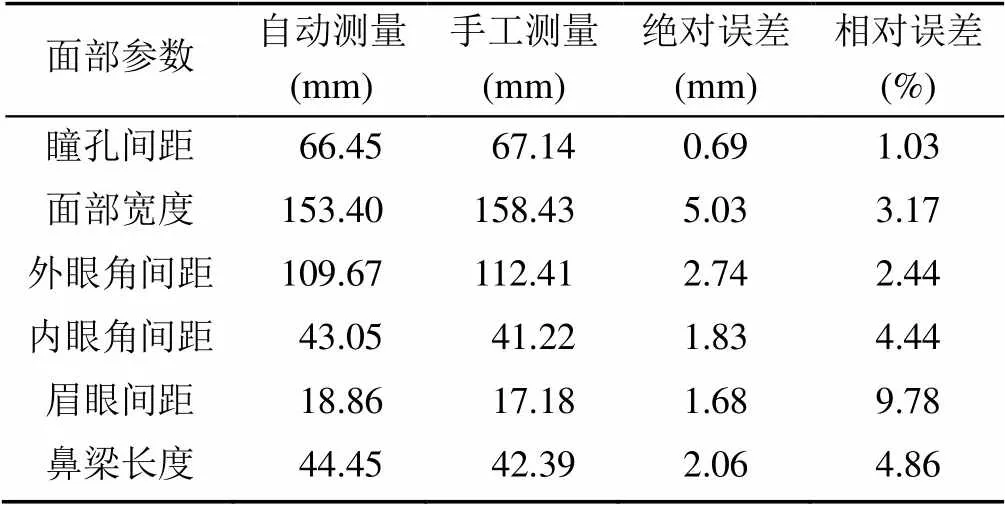
表2 平均测量值误差分析
进行特征参数提取后,进行眼镜架模型的参数化设计等后续配镜工作。本课题在UG二次开发基础上,利用Open Inventor三维图形软件开发包开发了智能配镜系统。智能配镜效果如图8所示。

图8 眼艺生活公司智能配镜效果图
5 结束语
综上,本文针对智能配镜中三维面部特征点提取算法复杂度较高的问题,提出一种将三维点云映射为图像,进行特征点定位的方法。计算面部三角网格模型各顶点处的高斯曲率、平均曲率。选取鼻尖、眼角等曲率特征明显区域估计面部姿态。使用面部姿态方向向量简化旋转矩阵的计算,使面部点云正面朝向视点,将点云映射转换为映射图像。搭建CNN,使用Texas 3DFRD数据集进行模型训练,进行人脸对齐,最终得到配镜所需的相关面部参数。并通过具体例证,对扫描的面部点云进行智能配镜面部参数的提取。结果表明,本文的面部参数提取方法可以达到智能配镜目的。
[1] BULAT A, TZIMIROPOULOS G. How far are we from solving the 2D & 3D face alignment problem? (and a dataset of 230,000 3Dfacial landmarks) [C]//2017 IEEE International Conference on Computer Vision (ICCV).New York: IEEE Press, 2017: 1021-1030.
[2] KOWALSKI M, NARUNIEC J, TRZCINSKI T. Deep alignment network: A convolutional neural network for robust face alignment [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2017: 88-97.
[3] KUMAR A, CHELLAPPA R. Disentangling 3Dpose in a dendritic CNN for unconstrained 2D face alignment [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2018: 430-439.
[4] DENG J K, ZHOU Y X, CHENG S Y, et al. Cascade multi-view hourglass model for robust 3D face alignment [C]//2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018). New York: IEEE Press, 2018: 399-403.
[5] RANJAN R, PATEL V M, CHELLAPPA R. HyperFace: A deep multi-task learning framework for face detection, landmark localization, Pose estimation, and gender recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 41(1): 121-135.
[6] HONARI S, MOLCHANOV P, TYREE S, et al. Improving landmark localization with semi-supervised learning [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).New York: IEEE Press, 2018: 1546-1555.
[7] WU W Y, QIAN C, YANG S, et al. Look at boundary: A boundary-aware face alignment algorithm [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2018: 2129-2138.
[8] GUO M L, DA F P, DENG X, et al. 3D face recognition based on keypoints and local feature [J]. Journal of ZheJiang University (Engineering Science), 2017, 51(3): 584-589.
[9] 冯超, 陈清江.一种多特征相结合的三维人脸关键点检测方法[J]. 液晶与显示,2018, 33(4): 306-316.
[10] MARCOLIN F, VEZZETTI E. Novel descriptors for geometrical 3D face analysis [J]. Multimedia Tools and Applications, 2017, 76(12): 13805-13834.
[11] 胡阳明, 周大可, 鹿乐, 等.基于改进ASM的三维人脸自动对齐算法[J]. 计算机工程, 2013, 39(3): 250-253.
[12] PAPAZOV C, MARKS T K, JONES M. Real-time 3D head pose and facial landmark estimation from depth images using triangular surface patch features [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2015: 4722-4730.
[13] Li Z Y, Bors A G. 3D mesh steganalysis using local shape features [C]//2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). New York: IEEE Press, 2016: 2144-2148.
[14] DE GOES F, DESBRUN M, MEYER M, et al. Subdivision exterior calculus for geometry processing [J]. ACM Transactions on Graphics, 2016, 35(4): 1-11.
[15] SU T Y, WANG W, LV Z, et al. Rapid delaunay triangulation for randomly distributed point cloud data using adaptive Hilbert curve[J]. Computers and Graphics, 2016, 54: 65-74.
[16] GUPTA S, CASTLEMAN K R, MARKEY M K, et al. Texas 3D face recognition database [C]//2010 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI). New York: IEEE Press, 2010: 97-100.
Feature Extraction of Facial Point Cloud Data for Intelligent Spectacle Frame Fitting
HOU Zeng-xuan1, LI Yan-xiang1, YANG Wu2, ZHAO You-hang1, WANG Jun-hua1
(1. School of Mechanical Engineering, Dalian University of Technology, Dalian Liaoning 116024, China; 2. Eye Art Life E-commerce Co. Ltd, Shenzhen Guangdong 518000, China)
In order to extract the 3D facial point cloud in the intelligent spectacle frame fitting, a method of converting triangulated 3D point cloud into a mapped image is proposed to locate feature points. Firstly, the Gaussian curvature and mean curvature of each vertex of the face triangular mesh are calculated by Voronoi method. Secondly, nasal tip and canthus regions with obvious curvature features are used to estimate the facial point cloud orientation. According to the rotation invariance of surface curvature, the calculation of rotation matrix is simplified by using the point cloud orientation vector, so that the face point cloud faces the viewpoint. Then, the point cloud is transformed into an image by mapping, and the triangular faces in the 3D mesh model are mapped to the biunique triangles. The convolutional neural network is built and the Texas 3D Face Recognition Database is used for model training. Finally, face alignment is carried out and the predicted facial feature points are limited to a certain triangle of the image. According to the triangle mapping in the image, the corresponding triangular faces in the 3D mesh model can be found, and the coordinates of the facial feature points required by the spectacle frame fitting are calculated through the vertex coordinates of the triangular faces. Through the above steps, the feature extraction of spectacle frame fitting parameter is implemented.
point cloud; face alignment; mapping; feature extraction; spectacle frame fitting
TP 391
10.11996/JG.j.2095-302X.2019040665
A
2095-302X(2019)04-0665-06
2019-02-26;
定稿日期:2019-04-21
侯增选(1964-),男,陕西岐山人,教授,博士,博士生导师。主要研究方向为计算机辅助设计技术、虚拟产品开发技术、产品创新设计理论与方法研究等。E-mail:hou@dlut.edu.cn
猜你喜欢
昆明医科大学学报(2022年1期)2022-02-28
图学学报(2021年2期)2021-05-13
汽车工程(2021年12期)2021-03-08
中国煤炭工业(2019年5期)2019-11-04
中山大学学报(自然科学版)(中英文)(2018年6期)2018-12-05
东方教育(2017年19期)2017-12-05
中国眼镜科技杂志(2017年13期)2017-08-16
中国眼镜科技杂志(2017年10期)2017-07-10
中国眼镜科技杂志(2017年10期)2017-07-10
幸福家庭(2016年3期)2016-04-05
