
基于Bi-LSTM和Max Pooling的答案句抽取技术
2019-08-27 12:06:24万福成于洪志吴甜甜杨方韬
吉林大学学报(信息科学版) 2019年4期
王 策, 万福成, 于洪志, 马 宁, 吴甜甜, 杨方韬
(西北民族大学 中国民族语言文字信息技术教育部重点实验室, 兰州 730030)
0 引 言
自动问答系统是自然语言处理领域的重要任务之一, 旨在让用户使用自然语言直接与问答系统交互, 无需考虑使用什么样的关键词组合表达自己的意图; 问答系统能精确地返回问题答案, 用户无需从大量复杂的相关文档中自己寻找答案。传统自动问答系统主要由3部分组成: 问句分析、 信息检索和答案抽取[1]。多年来, 在候选答案句的抽取研究上, 国内外取得了不错的进展。随着技术发展, 方法也在不断更新。最早由Cui等[2]提出一种与之前使用的模式匹配方法不同的模糊关系匹配的方法, 其采用基于互信息和最大值期望的模糊关系匹配方法, 即基于统计模型的模糊关系匹配方法, 取得了当时最好的实验效果。该方法没有考虑到问句中关键词(非停用词)在候选答案句中存在的同义表达。
在传统机器学习方法的使用上, Huang等[3]通过SVM(Support Vector Machine)模型对原始句子进行分类, 虽然其主要任务不是做候选答案句抽取, 但其处理思路与候选答案句抽取任务十分相似, 都是通过对给定句子进行人工标记, 进行有监督学习, 最后学习到句子间语义关系。此外, Ding等[4]通过对CRF(Conditional Random Field)模型的研究, 提出了一种能获取上下文语义信息特征关系的方法, 用以抽取问句与答案句之间的语义关系。Yao等[5]在CRF模型的基础上对传统分类任务进行了创新, 将候选答案句抽取任务转换成序列标注任务。可见, CRF模型在答案句抽取上也取得了不错的效果。
随着深度学习方法兴起, 国内外学者将深度神经网络应用在自然语言处理领域, 各项性能得到了不错的提升。Wang等[6]使用长短时记忆网络进行问答系统的答案句抽取, 为了降低问答系统中句内语法特征和一些其他因素对结果的影响, 他们采用了将单向LSTM(Long Short-Term Memory)扩展为双向长短时记忆网络的方法。Gong等[7]将端到端指针网络应用于句子排序中, 该方法充分发挥了端到端网络的特点, 只需对句子进行词向量表示, 并输入到端到端网络中, 模型会通过指针网络对句子集合的特征进行学习, 最后直接输出句子排序。2016年, 在NLPCC组织的基于文档的中文问答评测(DBQA: Document Based Question Answer)的比赛中, Fu等[8]将额外的文本特征加入到CNN(Convolutional Neural Networks)网络中, 在效果上取得了小幅提升。但单独使用CNN网络的效果不是很好, 这说明传统方法的应用在中文语料上有一定的作用。随着注意力机制的提出, 熊雪[9]提出了引入注意力机制的答案选择模型, 其层叠注意力机制增强模型捕捉句间语义逻辑关系, 通过词匹配的方法增强模型对未登录词的匹配情况, 最终取得了不错的效果。
从20世纪60年代开始, 国外学者就已开始对问答技术进行研究, 但大多以英文为主要研究对象, 中文问答系统相比英文起步较晚。开放域问答系统与限定领域问答系统相比的最大障碍在于知识库的构建过程, 目前将非结构化或半结构化数据自动转化为结构化知识库的技术尚不成熟, 同时在大数据时代, 产生的数据量越来越庞大, 开放域问答系统的答案抽取工作变得更加困难。针对以上情况, 笔者将答案抽取过程分为两个步骤进行: 1) 答案句抽取, 即从答案片段中抽取包含答案的句子; 2) 从答案句中抽取答案。抽取到的答案句是否包含答案将直接影响最终结果的准确率。在目前公开的自动问答系统语料库中, 候选答案句数量一般在20句左右, 语句内容信息也会更加复杂。笔者主要研究计算机自动识别答案句, 并在传统方法的基础上进行改善, 提高答案句抽取的准确率。为此, 提出一种将Bi-LSTM(Bi-directional Long Short-Term Memory)网络与Max Pooling结合的方法进行答案句抽取。
1 答案句抽取模型建立
笔者主要讨论答案句的定位和抽取过程, 具体例子如表1所示。

表1 问题句与候选答案句对
由表1可见, 在8个候选答案句中, 只有第1句包含正确答案, 故将其定义为答案句。答案句抽取模型的核心原理是使用Bi-LSTM对问句和答案句进行特征提取, 然后使用CNN中的池化层对特征进行下采样, 剔除冗余的特征信息。
1.1 问题描述
对于问答系统中的答案抽取问题, 相对于传统的问句语义和证据片段语义关系匹配的方法, 笔者将其看作为一种信息检索和序列标注问题, 即将给定问题放入搜索引擎进行检索, 抓取证据片段并对其断句作为候选答案句, 通过答案句抽取模型标注出可能包含答案的句子。
1.2 答案句抽取模型
答案句抽取模型主要包含3层: 词向量层、 Bi-LSTM层和Max Pooling层。模型架构图如图1所示。
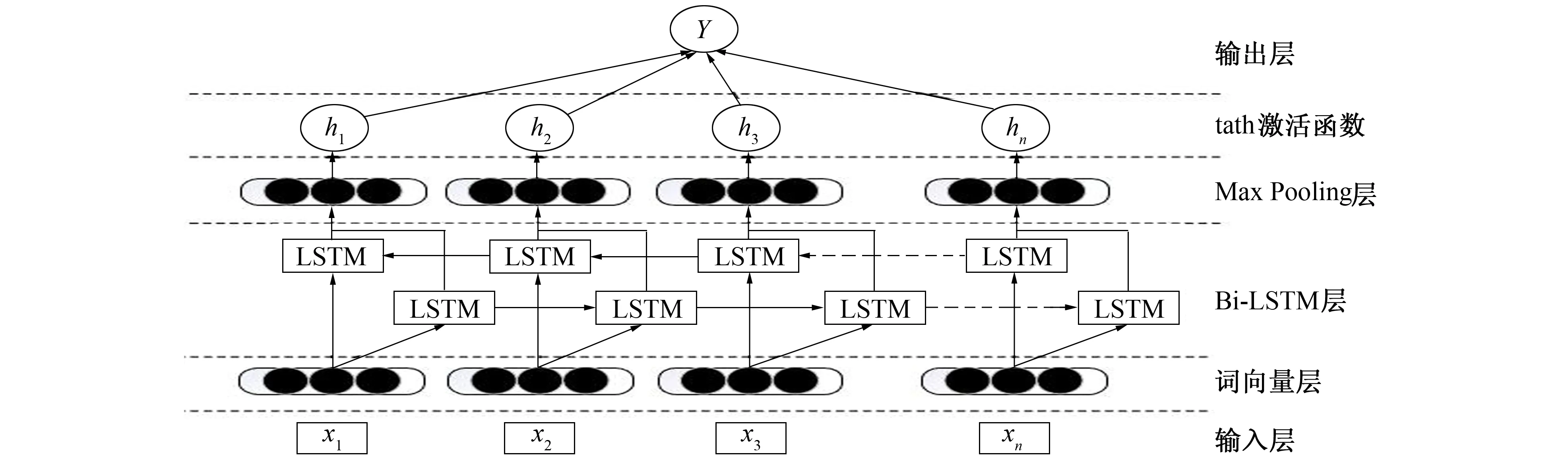
图1 基于Bi-LSTM和Max Pooling的答案句抽取方法架构图Fig.1 Architecture diagram of the answer sentence extraction method based on Bi-LSTM and Max Pooling
1.2.1 词向量层
首先, 通过Word2Vec(Word to Vector)得到问句和候选答案句中每个词对应的词向量表示, 并输入Bi-LSTM层。向量表示了问句和候选答案句中所有信息, 这对实验结果影响重大。假设问句Q 包含n个词,Q={x1,x2,…,xn},xi代表问句中第i个词。如果问句中包含答案信息词, 则把该词加入答案词向量。例如, 对于问题Q“科比曾经效力哪只球队?”, 对应答案A“洛杉矶湖人队。”, 则用Q和A一起表示该问题。利用词向量矩阵Ew获得词向量, 用d表示向量的维度,vw表示词汇大小[10]。通过
ei=Ewvi
(1)
可将一个词xi转变为词向量。其中vi是向量vw的大小。笔者使用的词向量由wiki百科数据训练获得。通过以上处理, 问句将以词向量{e1,e2,…,en}的形式进入下一层网络。
1.2.2 Bi-LSTM层
Bi-LSTM为双向长短期记忆网络, 由前向LSTM与后向LSTM组合而成, 两者通常用于在自然语言处理任务中对上下文信息进行建模。
LSTM的全称是长短期记忆网络, 它是RNN(Recurrent Neural Network)的一种。由于其设计上的特点, LSTM非常适合用于建模时间序列数据, 如文本数据。但利用LSTM网络建模句子仍存在问题: 无法编码从后到前的信息。例如, “我饿得不行了”, 这里的“不”是对“饿”程度的描述。而Bi-LSTM是通过将正向LSTM和反向LSTM结合, 所以在效果上得到了提升。
1.2.2.1 LSTM
LSTM采用相加的方法将词向量组合成句子的向量表示, 即将所有词的向量表示进行加和, 或取平均, 但是该方法没有考虑到词语在句子中前后顺序关系。LSTM通过训练过程可学到记忆哪些信息和遗忘哪些信息, 使用LSTM模型可更好捕捉到较长距离的依赖关系。

图2 总体框架Fig.2 Overall framework
图3中实线部分为计算遗忘门, 选择要遗忘的信息过程如下。
输入: 前一时刻的隐藏层状态ht-1, 当前时刻的输入词Xt。
输出: 遗忘门的值
ft=σ(Wf[ht-1,Xt]+Bf)
(2)
图4中实线部分为计算记忆门, 选择要记忆的信息过程如下。
输入: 前一时刻的隐藏层状态ht-1, 当前时刻的输入词Xt。
输出: 记忆门的值it, 临时细胞状态
it=σ(Wi[ht-1,Xt]+bi)
(3)
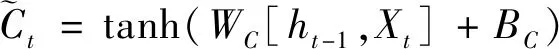
(4)
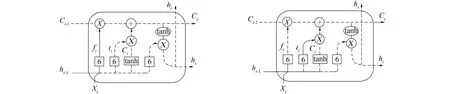
图3 计算遗忘门 图4 计算记忆门和临时细胞状态 Fig.3 Calculating forgetting gates Fig.4 Calculating memory gates and temporary cell states
图5中实线部分为计算当前时刻细胞状态过程, 具体如下。
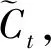
输出: 当前时刻细胞状态
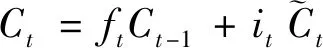
(5)
图6中实线部分为计算输出门和当前时刻隐藏层状态的过程, 具体如下。
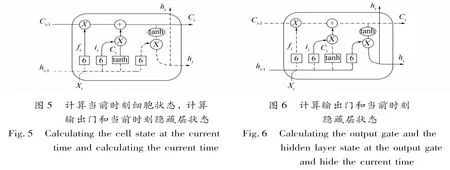
输入: 前一时刻的隐藏层状态ht-1, 当前时刻的输入词Xt和细胞状态Ct。
输出: 输出门的值Ot, 隐藏层状态ht:
Ot=σ(Wo[ht-1,Xt]+bo)
(6)
ht=Ottanh(Ct)
(7)
最终, 可得一系列与句子长度相同的隐藏层状态{h0,h1,…,hn-1}。
1.2.2.2 Bi-LSTM
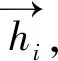
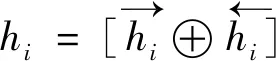
(8)
最后的输出是向前向后融合的结果。例如, 对“我爱足球”这句话进行编码, 模型如图7所示。
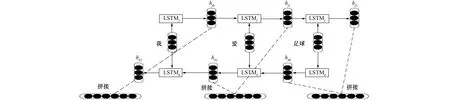
图7 Bi-LSTM编码句子的网络结构Fig.7 Network structure of Bi-LSTM encoded sentences
对于前向LSTMf, 按顺序输入“我”, “爱”, “足球”得3个向量{hf0,hf1,hf2}。对于后向LSTMb, 按顺序输入“足球”, “爱”, “我”得3个向量{hb0,hb1,hb2}。最后将前向和后向的隐向量进行拼接得{[hf0,hb2],[hf1,hb1],[hf2,hb0]}, 即{h0,h1,h2}。
1.2.3 Max Pooling
Max Pooling对于无论出现在什么位置的主要特征, 都可保持特征位置信息且具有旋转不变性, 因为无论主要特征出现在哪个位置, 都可把它提出。在NLP(Natural Language Processing)中, 特征位置信息至关重要, 比如主语一般位于句首, 宾语位于句尾等, 这些特征的位置信息对分类任务十分重要。
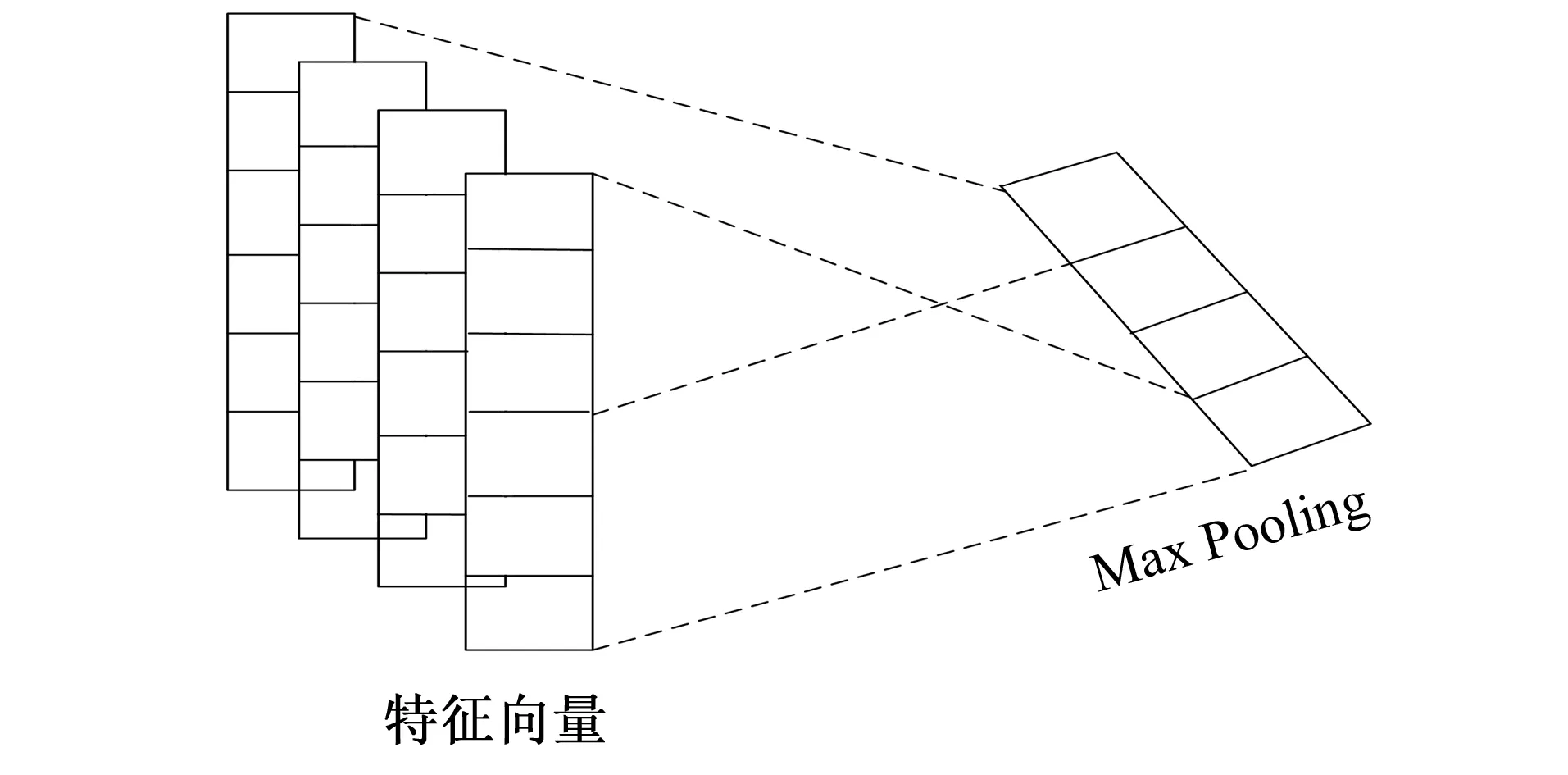
图8 Filter与神经元个数相对应Fig.8 Filter corresponding to the number of neurons
Max Pooling在卷积网络中主要用于减少网络参数, 降低网络复杂度, 减少运算量。在Max Pooling操作后, 2D或1D的数组通常被转换为单一数值, 以便之后使用在卷积层或全连接隐藏层中, 还能减少单个滤波器的参数数量或隐藏层神经元的数量。
对于NLP任务, Max Pooling能将变长输入处理为一个定长输入。因为CNN最终会连接到全连接层, 且需要预先确定神经元个数, 如果输入的长度不确定, 则难以设计其网络结构。综上所述, CNN模型的输入长度是不确定的, 并且每个Filter通过Max Pooling 操作只取1个值, 则有多少个Filter, Max Pooling层就有对应多少个神经元, 这样就可固定特征向量神经元个数(见图8), 这个优点也是非常重要的。
2 实验结果
2.1 语料库
近年来, 国内外专家学者在答案抽取这方面做了很多研究, 但是其中绝大多数都是在英文TREC(Text Retrieval Conference)语料的基础上做的研究和评测, 在中文语料上的研究很少。该实验使用的训练语料是使用搜索引擎将答案片段从百度百科中下载到本地数据库, 经清洗标注等处理后得到。训练语料共计18万多行, 测试语料1万多行。
由于语料库的准确性直接影响到实验结果, 笔者的语料标注采用人工标注方法, 使用将问句中的主干部分动词和名词与候选答案句内容进行匹配的方法。此方法对于事实类问句, 准确率基本接近100%。例如, 对于问句“孟加拉虎主要分布在哪里?”, 提取句子主干成分“孟加拉虎”和“主要分布”, 将这两部分在候选答案句中进行匹配, 标注同时包含这两部分的句子为答案句, 从百度百科爬取的候选答案句与问句相关性很强且格式相对规范, 有时仅需匹配一个主要成分即可。对部分需要简单推理类问句, 需要做些简单语义理解和近义词转换, 如问句“谦卑这个词语来自哪里?”, 即转换为“谦卑的词源是什么?”, 这样就很容易匹配到答案句且能保证准确率。
实验的训练数据格式规范, 使用〈问句, 候选答案句, 标签〉格式, 即每行为一个问句、 一个候选答案句、 一个标签, 分别用制表符分隔, 标签为0或1, 即是答案句标注为1, 不是为0, 同一问句一般有20句候选答案句, 候选答案句之间的排列是乱序的。具体语料格式如图9所示。

图9 语料格式Fig.9 Corpus format
实验中数据的格式如图9所示。训练集共有163 388对问句-答案句对, 测试集共有10 000对, 每个问句对应20多个候选答案句, 因此, 相当于训练集中的问题有8 000多个, 测试集中的问题有500多个。
2.2 评估标准
在通常情况下, 一般使用准确率、 召回率和F值评估模型的性能, 利用无序文档集合进行计算, 但是笔者针对答案句抽取模型, 使用平均倒数MRR(Mean Reciprocal Rank,MMRR)和平均准确率MAP(Mean Average Precision,MMAP)作为评价指标, 最常用的指标为MRR。在笔者的实验语料中, 大部分问句只有一个答案句与之对应, 极少部分有多个答案句或没有答案句, 所以在笔者实验结果中, MRR都会比MAP略高一些。
MRR和MAP的具体计算方式如下
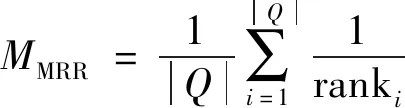
(9)
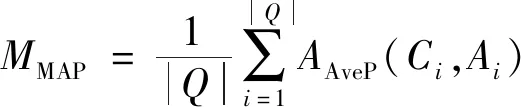
(10)
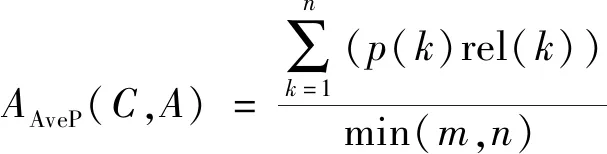
(11)
其中Q为测试集中所有问题的数目, ranki表示在生成的预测答案集合中第1个标准答案的位置,AAveP表示平均准确率;m为标准答案的数量;n为预测答案数量;k为候选答案句在模型返回的n个预测答案中排名。
MRR即第1个结果匹配, 分数为1, 第2个匹配分数为0.5,…, 第n个匹配分数为1/n, 如果没有匹配的句子分数为0, 最终的分数为所有得分之和。这是国际上通用的对搜索类和问答类系统进行评价的指标。
MAP是每对〈问句, 答案句〉检索后的准确率的平均值。MAP反映系统在全部候选答案句上的性能指标。在该模型中, 抽取到的答案句与问句越相关(值越高, 即包含答案), MAP的值越高。若问答系统没有抽取到答案句, MAP则为0。
2.3 实验参数
实验使用双向长短期记忆递归神经网络(Bi-LSTM)提取句子间的特征属性, 将Bi-LSTM的隐藏层输出做Max Pooling操作, 得到Rmax。Rmax在输入到tanh激活函数出中输出最后判断结果
M=tanh(Rmax)
(12)
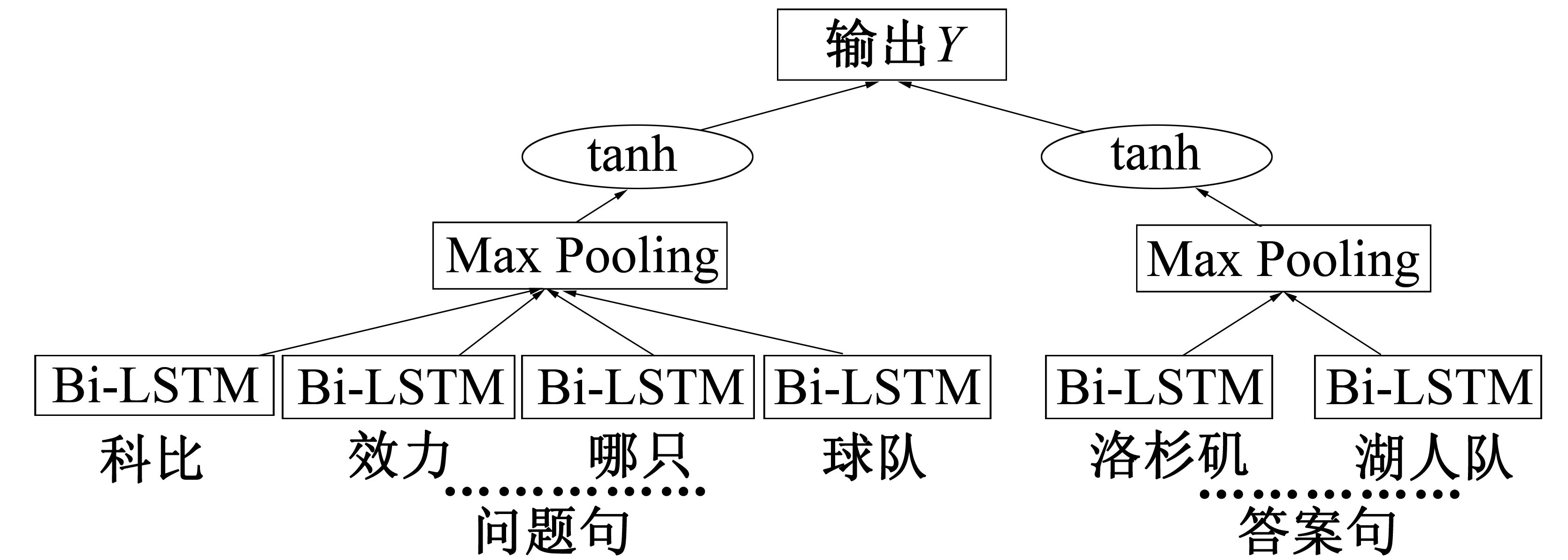
图10 基于Bi-LSTM的特征提取模型Fig.10 Feature extraction model based on Bi-LSTM
实验中各个参数设置如下: dropout设置为1, 词向量的维度设置为50, 学习率设置为0.3, 学习率下降速度设置为0.1, 学习速度下降次数设置为4, 每次学习速度指数下降前执行的完整epoch次数设置为100, LSTM cell中隐藏层神经元的个数设置为100, 句子中的最大词汇数目设置为100。
用Dropout防止网络在训练过程中出现过拟合的现象, 该实验中未发生过拟合现象, 故将dropout设置为1。若降低dropout值会使结果变差; epoch是训练的批次数, epoch也需设定在合理的范围内, epoch越大训练效果不一定越好, epoch过大, 也会发生过拟合的现象; 学习率、 学习率下降速度和学习下降次数3组数值相互影响, 3个值大小和epoch取值大小有直接关系, 笔者给出的数据是通过多次实验取得的最佳结果; 词向量的维度大小根据文献[11]和平时实验经验得到, 一般情况取值为50, 在该实验中词向量维度大小对实验结果影响不大。
2.4 结果分析
通过运行各个模型得实验结果如表2所示。

表2 各个模型在实验中的最优结果
将LSTM模型的实验结果作为参考, 在该语料中, 其MAP和MRR指数分别达到了0.339 5和0.339 4。
LSTM模型的优点是能在存取输入和输出序列的过程中, 映射上下文相关信息。但标准的LSTM在遇到较长句子时, 对下文文字的利用和对上文前部文字的记忆能力下降, 使隐藏层的输入对于网络输出的影响随着网络层数的增长而降低。
CNN最初应用于图像领域, 目前在NLP领域的应用取得了不错的效果, 卷积核在句子中进行卷积, 每次只对两个词进行组合, 从中选出最有可能的一组, 即进行Max Pooling操作, 使用不同的滤波器得到不同的结果, 最终进行加权组合得到一个新的词。CNN这种卷积操作和池化操作同时使用的模型, 使句子空间特征消失, 这对于文本即不再考虑句子的语序关系, 而是将句子中的关键词提取出, 再通过训练好的网络进行新的排序, 组合成一个新的句子, 这会使句子的向量表征与原本的句子语义有所冲突。
针对这两种模型的优缺点, 分别取他们在文本处理中效果好的部分并加以修改, 最终建立了Bi-LSTM和Max pooling结合的模型。使用Bi-LSTM进行特征提取, 该方法既能改善单向LSTM网络对较长句子中开始部分文字的记忆能力, 又能避免卷积操作不能充分利用句子间时序关系提取语句特征关系的问题。保留了卷积神经网络中的Max Pooling层以降低提取的句子维度, 同时可以保留主要特征。在相对于基线LSTM方法和CNN方法, 笔者答案句抽取模型取得良好效果, MAR和MRR指数达到了0.747 5和0.749 7。
李超等[12]通过在长短时记忆神经网络中借助依存句法树分析句法结构特征, 构造深度学习网络进行答案抽取, MRR取得了0.71; 俞霖霖[13]通过将CNN与SVM进行融合, 将CNN模型自动学习到的特征加入到SVM中, 答案抽取结果得到了很好的效果, MAP和MRR指数达到了0.786和0.789。这两种方法都是将人工提取句子的语言学特征加入到神经网络中学习, 其中文献[12]选用NLPCC 2015 发布的QA 评测问题集, 候选答案句实验数据爬取于百度知道, 文献[13]使用从百度百科中爬取到数据构建, 与本实验的语料库来源相同, 故存在可比性。笔者实验结果和文献[12]的实验结果对比可知双向循环网络在时序问题中有更好的效果; 和文献[13]的实验结果对比可知, 在神经网络中加入人工提取的语句特征会有更好的效果。
3 结 语
笔者将问答系统中答案抽取任务分解为两个步骤进行: 第1步从证据片段中进行答案句抽取; 第2步从抽取到的答案句中抽取最终答案。使用Bi-LSTM和Max Pooling结合的方法构建答案句抽取模型, 提取问句与候选答案句之间的特征关系, 训练其抽取与标注的结果。实验结果证明, 在Bi-LSTM中加入CNN中的Max Pooling方法能有效提升答案句抽取的准确率。
笔者主要的创新点主要分为3点: 1) 将答案抽取任务分解为两步进行处理; 2) 对比传统的方法使用了深度神经网络结果建模处理候选答案句抽取任务; 3) 使用Bi-LSTM网络代替CNN中的卷积操作提取句子特征, 与Max Pooling融合构建了新的模型。
笔者方法对事实类问题有着较好的效果, 通过对比其他研究人员的实验发现, 虽然将语言学知识或人工提取的特征加入到神经网络训练中, 可使效果更好一些, 但会耗费人力和时间, 而笔者方法在此方面更具优势。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
