
基于卷积神经网络的手绘草图识别
2019-08-27 12:06:18印桂生王宇华
吉林大学学报(信息科学版) 2019年4期
印桂生, 严 雪, 王宇华, 张 震
(哈尔滨工程大学 计算机科学与技术学院, 哈尔滨 150001)
0 引 言
手绘草图是人类进行交流的一种有效的方式, 近几年随着各种电子设备及触摸屏的发展, 手绘图像已经变得随处可见, 人们可以在手机、 iPad及电子手表等产品上通过手指触动屏幕画出想要表达的内容, 也因此带动了对于手绘草图的研究和发展, 包括手绘草图识别[1], 手绘草图检索[2]和基于手绘草图的3D模型检索[3-4]等。其中手绘草图识别是目前广大学者研究的重点也是这一领域的基础。
手绘草图识别是一项有挑战性的任务, 主要因为相比于有颜色有纹理等信息因子的自然图像而言, 手绘草图有以下几个明显的特征: 1) 具有高度的抽象性和夸张性。2) 大部分的手绘图像都是由非专业人士绘制的, 因此由于不同人的绘画能力和风格不同导致同画一个自然物体产生的手绘图像之间的差异很大。3) 绘画过程中会产生笔画的停断。4) 手绘图像缺乏纹理和颜色等要素, 一般为二值图像或灰度图像[5]。这些挑战使目前对手绘草图的识别精确度仍然较低, 且经过实验验证, 准确识别手绘图像的类别也具有一定的难度[1]。
研究以前的工作发现, 手绘草图的识别方法和传统的自然图像识别方法非常相似, 即先进行手工特征提取, 然后将提取到的特征传给分类器进行分类识别。手工提取特征一般采用方向梯度直方图(HOG: Histogram of Oriented Gradient)[6]和尺度不变特征变换(SIFT: Scale-Invariant Feature Transform)[7]等并结合词袋模型BOW(Bag-Of-Words)[4]形成最后的K维统计直方图, 而后使用相应分类器进行分类[8]。但这种方法存在的问题是训练精度不高且忽略了手绘草图本身的固有特征, 例如忽略了其自身存在的笔画顺序信息。最近随着卷积神经网络在图像处理领域的显著优势, 不少学者尝试使用经典CNN(Convolutional Neural Networks)进行手绘草图的识别, 结果发现即使目前性能最好的CNN, 也是为彩色图像识别而设计, 在解决手绘图像识别的工作中性能却并不突出[9], 因此, 有学者尝试设计专门的手绘图像识别CNN网络, 解决了上述问题, 且取得了超人类的性能[5]。
笔者提出了一种深度神经网络DCSN(Deeper-CNN-Sketch-Net), 主要针对手绘图像的特殊性进行设计。考虑到手绘草图都没有颜色和纹理信息, 只是由简单的黑色线条勾勒而成的图像, 因此存在很多空白区域, 如果使用太小的卷积核, 会导致一些区域学习不到特征, 增加一些不必要的计算和开销, 所以DCSN首层采用大的卷积核, 以保证每个卷积核都可以提取到有用的特征, 且大的卷积核便于提取手绘草图的空间结构特征。考虑到小的步长可以保留手绘草图更多的特征信息, DCSN首层卷积层采用更小的步长。最后, 通过增加网络层数加深网络深度从而学习更多特征提高网络的识别准确率。在利用CNN进行网络训练时发现, 过拟合是一个常见的问题, 在网络中可以利用Dropout技术[10]减少过拟合, 此外, 增加数据量也可以明显的改善过拟合问题。在常见的数据增强技术外, 笔者根据手绘图像的笔序信息, 提出了两种新的数据增强算法, 即小图形缩减策略和尾部移除策略。小图形缩减策略可以选取面积小于某个阈值的图形进行不同比例的缩减, 这也符合不同人对于同一个物体的某一部分可能画的偏大或偏小的特点, 表示了不同人不同的绘画风格。尾部移除策略主要考虑大部分人进行绘画通常会先画外部轮廓, 最后去描细节的特点, 所以每次从最后几笔去移除笔画, 即不会影响图像的整体表达含义而且使图片具有差异性。通过这两种方法丰富了训练数据集, 有效改善了过拟合问题。
笔者提出的算法主要思路如下。
1) 提出了一个深度卷积神经网络模型DCSN, DCSN在首层使用了更大的卷积核获取手绘草图的结构信息和更小的步长保留更多的特征信息, 并增加了网络层数加深网络深度, 通过这些方法提升网络的识别准确率;
2) 根据手绘图像的固有特征提出了两种数据增强算法, 小图形缩减策略和尾部移除策略, 增加了训练数据集, 减少了网络的过拟合。
笔者使用了TU-Berlin[1]数据集在GPU(Graphics Processing Unit)服务器上进行实验验证笔者所提方法的有效性。
1 目前工作
1.1 CNN用于手绘图像识别
从原始时期到现在, 手绘草图一直在人类生活交流中扮演着重要的角色, 随着科技和时代的发展, 人们开始对手绘草图重视起来并展开了一系列的相关研究, 比如手绘草图识别[1], 手绘草图检索[2]等并将相关技术应用到特定领域。很长一段时间, 人们普遍采用的方法是人工提取特征而后将得到的特征传给分类器进行分类。其中识别性能最好的是Tuytelaars等[11]提出的使用Fisher Vector进行手绘草图分类的方法, 取得了近人类的识别性能。近几年, 随着深度神经网络(DNN: Deep Neural Network)的发展[12], 人们发现, 它对特征的学习更加方便和有效, 不仅节省了人工提取特征所需要的人力且减少了对先验知识的依赖, 特别是卷积神经网络在近几年的视觉识别挑战赛[13]上的不断突破, 以及出现的一大批优秀的经典网络结构, 如AlexNet、 GoogleNet、 ResNet等[14], 显示了CNN在图像识别上的优势, 目前, 70%左右的CNN应用于图像处理领域。但现有的CNN网络架构大部分为更好的识别自然彩色图像而设计, 专门为只由黑白线条组成的手绘草图设计的网络相对较少。2015年, Yu等[4]提出了一种专门为识别手绘图像而设计的网络架构Sketch-a-Net, 并达到了超人类的性能, 进一步推动了手绘图像识别的发展。2016年, 赵鹏等[15]提出Deep-Sketch模型, 从整个网络架构设计适合手绘草图缺乏纹理和颜色信息、 高度抽象等特点的网络, 取得了很好的性能。2018年, 在文献[15]的基础上, 他们进行了改进, 提出了deep-CRNN-sketch模型[16], 将CNN与RNN(Recurrent Neural Network)进行结合, CNN用于提取各子图特征, 并按照时序将提取的子图特征图传给RNN, 生成最终的手绘草图特征, 最终输入到SVM(Support Vector Machine)分类器中进行分类识别, 相比之前Deep-Sketch网络提高了2.6%的识别准确率。
尽管很多工作已经在很大程度上设计了适合手绘草图识别的网络架构, 但是网络仍然存在很多问题, 例如目前的相关网络层数相对较少, 不能更深入的学习手绘草图的内在特征, 且目前的网络参数较多, 训练时间较长, 如何有效减少参数提高性能是人们应该努力的方向。笔者在经典AlexNet网络的基础上, 增加了网络的深度, 进行了相应的结构改进, 使之适合应用于手绘图像的识别。
1.2 深度学习数据增强技术
在深度学习图像识别任务中, 构建一个识别率高的网络除了需要一个好的网络结构外, 用于训练的数据也至关重要, 需要使用大量的数据进行网络训练, 而现存的很多数据集数据规模较小, 不能满足训练网络时对大量数据的要求, 且当训练数据集过小时, 网络很容易产生过拟合, 影响网络的性能。现存有很多的数据增强技术, 比如最基本的翻转、 旋转、 随机切割、 加噪等[17-18], 可以通过这些增强技术增加训练集, 提高训练模型的泛化能力。除了这些基本方法, 也存在一些特殊的数据增强技术, 如Inoue等[19]提出的一种高效数据增强方式SamplePairing, 从训练集随机抽取的两幅图像叠加合成一个新的样本(像素取平均值), 可以使训练集规模从N扩增到N×N。当然也存在对于要处理的特殊数据集的数据图片进行特殊处理, 比如笔者的手绘图像数据集, 可以针对这一类图像的特征设计专门的图像增强技术; 如Yu等[20]在2017年提出了针对手绘图像的多种数据增强技术, 可以根据手绘图像笔画的顺序和长度移除笔画生成更多的相似图像,也可以通过局部和全局的图像形变丰富训练数据, 数据集的扩充很好的提高了识别性能。笔者在此基础上根据手绘草图的笔画顺序信息提出了两种数据增强方法, 扩大了原有数据集, 将新增的数据应用于DCSN网络的训练中, 并取得了很好的效果。
2 笔者工作
在本节中笔者主要给出根据手绘草图特点而设计的用于手绘草图识别的DCSN网络, 并进行一系列的数据增强以训练网络, 提高所设计的网络的识别准确率。
2.1 CNN进行手绘草图识别
卷积神经网络主要包括卷积层和池化层, 卷积层进行图像特征提取, 池化层进行图像压缩, 卷积层中, 上一层的特征图会和当前卷积层的卷积核进行卷积运算, 卷积的结果加权求和后, 经过非线性函数处理得到这一层的特征图。卷积层的计算如下所示
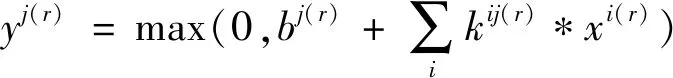
(1)
其中xi和yj表示第i个输入特征和第j个输出特征,kij表示xi和yj之间的卷积核, *表示卷积操作,bj表示第j个输入特征的偏置系数,r采用非线性函数ReLU作为激活函数, ReLU被证明比sigmoid函数的拟合效果要好。具体计算如图1所示。图中将6×6的原始图像输入或上一层的特征映射图经过中间的3×3卷积核, 生成4×4的特征映射图, 图中最右面的第1行不同颜色的框中的值是由左图中相同颜色3×3的框中的值同中间卷积核进行卷积操作求得的值。笔者所用的池化方法为最大池化, 它是选取某一个区域中的最大值代表选中的区域, 它的计算如式(2)所示。xi表示一个特征图上某个区域第i个数值,y是最后得到的代表值, 即所选区域的最大值。具体如图2所示, 图中将4×4的输入特征图进行最大池化降维处理后变为2×2的特征映射图。
y=max(x1,x2,x3,…,xn)
(2)

a 4×4的输出特征映射图 b 3×3的卷积核(权重) c 6×6的输入图1 卷积层计算过程示例图Fig.1 Example of convolutional layer calculation process
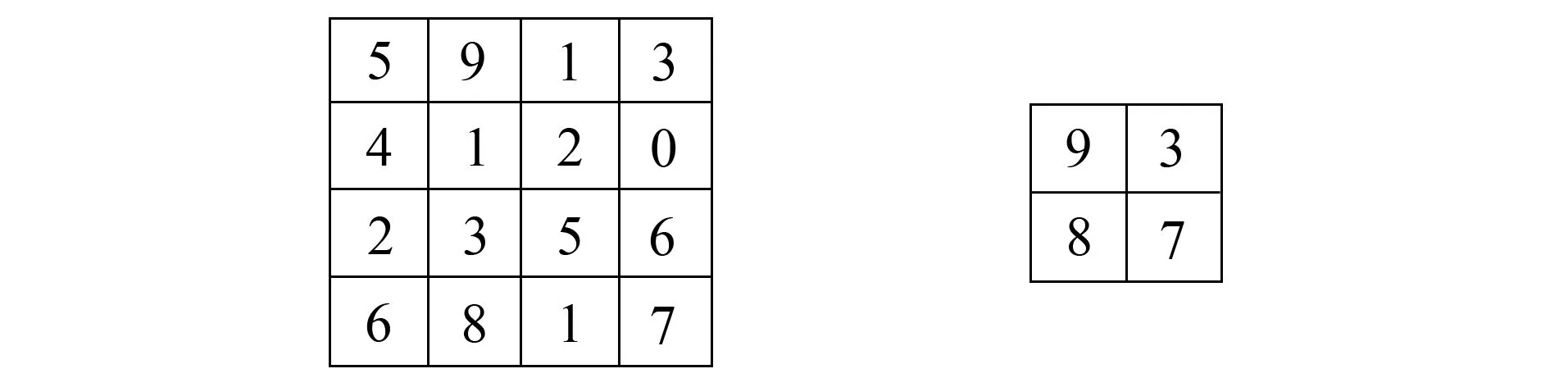
a 3×3的卷积核(权重) b 6×6的输入图2 池化层计算过程示例图Fig.2 Example of the pooling layer calculation process
笔者采用softmax进行多分类, 它将多分类的输出数值转化为相对概率, 通过概率值确定此样本所属的类别, 计算公式如下所示
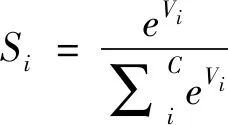
(3)
其中Vi是前一级输出单元的输出,i是类别索引,C为总类别数,Si表示当前元素的指数与所有元素指数和的比值。
卷积神经网络训练主要包括3部分, 初始化、 前向传播和反向传播。初始化主要是初始化网络权值和神经元的阈值, 初始化后通过前向传播逐层向前计算出输出值, 通过误差函数计算误差和反向传播更新网络的权值和阈值, 直到满足终止条件结束。笔者进行网络训练和测试过程如算法1, 算法2所示。
算法1
输入: 训练样本、 网络参数、 DCSN网络
输出: 已训练的DCSN网络
1) 初始化DCSN网络
2) while(未达到最大迭代次数或未满足训练误差)
3) for(每个训练样本X1)
4) 前向传播: 使用式(1)、 式(2)计算每层的输出
5) 通过误差函数计算误差, 求得误差和
6) 反向传播, 更新权值和阈值
7) 返回2)进行判断, 若满足条件继续3)~6), 直至跳出循环, 若不满足, 则跳出循环, 训练结束
8) end while
算法2
输入: 测试样本、 训练好的DCSN网络
输出: 识别准确率
1) for(每个测试样本X2)
2) 利用式(1)、 式(2)计算网络输出
3) 输入到softmax中使用式(3)计算概率并分类
4) 计算识别准确率
5) end for
在进行手绘草图识别的任务中, 首先要做的是构建一个CNN网络模型结构, 这个模型结构应该专门为我们的目标图像而设计, 即它的设计应该结合要识别的手绘草图图像的特征使训练出的网络更加适合完成对手绘草图的识别。因此, 笔者以AlexNet网络模型为基础, 在此基础上进行更进一步的改进, 完成了DCSN模型的构建, 使之更适合识别手绘草图。
DCSN网络专门为识别手绘草图而设计, 主要包括9层, 网络输入为225×225像素的经过预处理的草图图像, 共有6个卷积层和3个全连接层, 第1层卷积层中卷积核大小为15×15, 与为自然图像识别构建的卷积网络首层卷积层卷积核较小不同, 这里选取一个相对大的过滤器, 这是因为小的过滤器更能捕捉到颜色、 纹理等细节的信息, 因此更适合用于自然图像识别, 而手绘草图中笔画较为稀疏, 使用大的过滤器反而更容易捕捉到整个图片的结构信息。每个卷积层后面接着ReLU激活函数, 1,2,3层后面使用最大池化层进行降维处理, 缩小图像的尺寸, 卷积核的尺寸大致上由大到小, 卷积核的数量由64不断以倍数递增, 最高为512, 最后一层为250个, 对应于分类数据集的类别数(这里250指的是TU-Berlin数据集共有250个分类), 卷积层步长除第1层为2外其余全部为1。池化层的尺寸有3×3、 2×2两种, 步长均为2。网络中第5层使用1进行填充, 其余使用0填充, 进行填充主要为了保证特征图按照整数尺寸大小输出, 使卷积计算有意义。跟以往识别自然图像的CNN和专门为识别手绘草图而设计的CNN一样, DCSN网络最后3层为全连接层, 7,8全连接层后面接着Dropout层, Dropout率为0.5, 这样的好处是缩减了参数的数量, 减少了过拟合和网络训练的时间。网络具体参数如表1所示。

表1 架构图
笔者的DCSN模型和经典的AlexNet模型的对比如下。两种网络模型的主要相同点如下。
1) 两者均是由卷积层、 池化层和全连接层组成的卷积神经网络。
2) 两者都使用Dropout解决全连接层参数多计算量大以及由此产生的过拟合问题。
3) 两种网络结构均采用ReLU激活函数解决非线性因素的, 提高模型解决复杂问题的能力。
两种网络模型的主要不同点如下。
1) DCSN网络层数更多, 共有9层, 而AlexNet只有8层。DCSN结构是在AlexNe前两层后增加了一个卷积层和一个池化层, 并去掉AlexNet第5层卷积层后的池化层。层数增多, 学习到的特征更细, 有利于提高识别准确率。
2) DCSN网络首层使用更大的15×15卷积核学习特征, 而AlexNet网络使用较小的11×11卷积核进行学习, 这主要是因为小的卷积核更容易学习到细节特征如颜色、 纹理特征等, 适合用于识别自然图像, 而大的卷积核更容易捕获到图像的结构信息, 适合识别没有颜色、 纹理特征的手绘草图。
3) DCSN网络首层卷积步长较小, 在AlexNet中首层步长为4, 而DCSN网络首层步长为2, 其余层步长均为1。首层使用较小的步长可以保留更多的特征信息, 学习到的特征越多, 分类越准确。
4) DCSN网络过滤器的数量除最后一层全连接层外, 其他层从64依次或稳定或成倍数递增, 而AlexNet网络则没有这种递增规律, 且没有倍数关系。
5) DCSN网络去掉了局部相应归一化(LRN: Local Response Normalization)操作。LRN的主要作用是提供亮度归一化, 而手绘草图中没有亮度特征, 增加LRN不仅不能提高识别准确率还会增加计算量, 所以在DCSN网络中去掉了LRN。
2.2 新的数据增强方法
数据增强技术常被应用在原始的自然图像识别中, 用来丰富数据集, 常用的数据增强技术有图片翻转、 旋转、 裁剪、 高斯噪声等。这里根据所要识别的图像特征提出了两种增加数据量的方法, 在笔者使用的原始数据集TU-Berlin的基础上进行数据的扩充, 并将扩充的数据应用到网络的训练中。
2.2.1 小图形缩减策略
笔者提出小图形缩减策略的思想是先检测一幅图中的图像轮廓, 将里面的类似矩形、 圆形、 三角形的图形分别检测出来并标识, 将标识的图形进行面积判断, 这里会先设定一个面积阈值, 当检测到的图形面积小于该阈值时, 将这个图形按照原图75%、50%、25%的比例缩减为3幅图, 如果面积大于该阈值则保持原大小不变, 这是因为大面积图形对图像整体识别的影响大, 所以笔者对大面积的形状不做更改。这样将部分小图形做缩减得到3张新的图片, 便将原数据集扩大了3倍。提出此策略的依据是考虑了非专业人员的绘画水平和绘画风格不同, 所以对于相同的图形画的大小和形状会有所不同, 将小图形进行缩减可以想象为另一个人的绘画风格。
图3左侧为数据集原图, 右侧为经过小图形缩减策略之后生成的3幅图片, 可以发现新生成的3幅图片和原图片有些微的差别, 这种差别可以类比不同人的绘画风格不同产生的差异。通过这种方法可以有效的将数据集扩充3倍用于训练, 扩充后的数据集命名为S1,S2,S3,S1,S2,S3分别含有20 000张原图像做小图形缩减比例为75%、50%、25%后的对应图像。

a 原图 b 缩小25% c 缩小50% d 缩小75%图3 小图形缩减策略示例图Fig.3 Small graph reduction strategy example diagram
2.2.2 尾部移除策略
笔者提出的尾部移除策略是通过去掉原始图片最后几笔来完成数据的扩充。这里由一幅原图通过去掉最后一笔、 最后两笔、 最后3笔扩展了3幅图片, 用于训练。由于手绘草图实质是由一些笔画序列组成的一个笔画集合, 且经过研究表明, 大部分人的绘画都是先整体轮廓, 后进行细节方面的修饰, 因此, 对于一幅手绘草图, 最后几笔一般都是对细节的描绘, 对于手绘草图来说, 一个细节的描述并不能从整体上影响整幅图片所表达的含义, 也不会影响整体的识别。提出此策略的依据便是考虑到不同人的绘画风格和样式不同, 对于最后的细节描绘, 有的人选择去具体刻画, 而有的人却选择忽略, 笔者去掉最后几笔的想法来源于此, 将去掉最后几笔所生成的图像放入到训练数据集中, 增加了数据量, 提高了网络的泛化能力。
图4同理左侧为数据集原图, 右侧是经过尾部移除策略之后生成的3幅图片, 分别为由原图去掉最后一笔生成的图片, 去掉最后两笔生成的图片和去掉最后3笔生成的图片, 将后3张图片与原图进行对比发现, 只是在原图的基础上去掉了最后几个笔画, 并没有改变图片的其他地方, 将扩充后的数据集命名为W1,W2,W3,W1,W2,W3各含有20 000张原图像做一笔画、 两笔画、 三笔画尾部移除策略后的对应图像。

a 原图 b 去掉最后一笔 c 去掉最后两笔 d 去掉最后三笔图4 尾部移除策略示例图Fig.4 Example of tail removal strategy
3 实验与结果
使用笔者专为识别手绘草图设计的DCSN网络在TU-Berlin数据集和笔者新扩充的数据集上按照2.1节中算法1、 算法2的步骤进行实验训练DCSN网络并测试网络的性能, 并将准确率作为度量标准衡量笔者所提方法的有效性。
3.1 实验环境
笔者实验在Windows 7系统上进行, 系统内存为64 GByte, 使用Matlab2016a、 Visual Studio 2015平台, Matconvnet-1.0-beta25深度学习工具, GPU的CUDA版本为CUDA 8.0, 计算能力2.0。
3.2 数据集
笔者使用目前存在的最大手绘图像数据集TU-Berlin数据集进行实验验证笔者所提方法的有效性。该数据集是在2012年, 由Eitz等组织收集的, 它一共包含250类, 每类含有80幅不同风格的手绘草图。原始图像共20 000张, 扩充数据集后共140 000张图像。原始数据集示例图如图5所示。
图5 TU-Berlin数据集草图样图Fig.5 TU-Berlin dataset sketch sample
3.3 度量标准
笔者使用的度量标准为网络的识别准确率。准确率是指所有样本中, 正确分类样本数量所占的比例。如式(4), 其中Aacc为实验的指标值(准确度),n为识别正确的图像数,N为总的测试样本数量。它是图像识别中最基本也是最重要的度量标准, 这里通过这个度量标准评价笔者所提出的DCSN网络的识别性能。
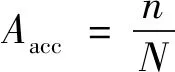
(4)
3.4 实验和结果
这里将笔者的实验结果与传统的手工提取特征的方法及已有的深度学习方法进行对比, 其中进行对比的传统方法包括: 1) 传统的HOG-SVM, 即使用HOG进行手工特征提取, 使用SVM进行分类。 2) 当前最新的FV-SP(Fisher Vector Spatial Pooling)方法。进行对比的深度学习方法包括 1)LeNet网络, 它在手写数字识别任务中有很好的性能。2) AlexNet网络, 笔者基于这个网络设计的DCSN网络。实验结果如表2所示。由表2可以看出, 笔者所提方法的识别准确率要高于其他几个对比的方法, 这说明笔者所提出的DCSN网络更加适合手绘草图的识别。另外, HOG-SVM和LeNet的识别准确率较低, 因为HOG-SVM是手工提取特征, 提取的特征相对较简单, 提取不到更高层次更抽象的特征, LeNet在手写数字识别中性能较好, 但由于其网络结构简单, 在手绘草图的识别中性能却很差。FV-SP和深度AlexNet网络的识别性能差不多, 但略好于AlexNet。笔者的DCSN网络是在原有的AlexNet网络的基础上进行改进, 改进后的识别准确率比原网络提高了4.3%。

表2 与已有手绘图像识别方法的对比结果
笔者为了更好的改善网络的过拟合问题, 提高识别准确率, 提出了两种数据增强策略, 小图形缩减策略和尾部移除策略。为了验证扩充数据集的作用, 分别进行了几组对比实验, 对比结果如表3所示。表3表明, 扩充数据集可以帮助提高识别的准确率, 且小图形缩减策略好于尾部移除策略, 并且同时使用两种策略可以达到最好的识别性能。

表3 数据集扩充对识别准确度的影响
4 结 语
笔者针对手绘草图的特点提出了一个新的CNN网络结构—DCSN。提出两种数据增强策略, 防止网络过拟合问题的产生, 最后使用扩充的数据集训练DCSN网络。实验证明, 笔者提出的网络模型在TU-Berlin数据集上有较高的识别准确率, 且进行数据扩充后可以减少网络的过拟合问题, 进一步提高网络的识别准确率。最后, 笔者的研究还有很多未解决的问题, 例如目前笔者进行的是类级即粗粒度的分类, 如何进行实例级即细粒度的分类等, 是未来的努力方向。另外, 训练一个网络需要大量的时间, 这种时间消耗是训练网络的一个关键瓶颈, 随着近几年加速硬件的发展和并行技术的广泛运用, 如何将并行计算加入到卷积神经网络的训练中以减少网络训练时间也是我们需要进一步研究的方向。
猜你喜欢
阅读(高年级)(2022年9期)2022-10-08 01:20:16
疯狂英语·初中天地(2021年5期)2021-07-21 02:24:38
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
神州学人(2016年9期)2016-10-20 17:37:31
福建中学数学(2016年4期)2016-10-19 05:09:02
中学生理科应试(2016年2期)2016-05-30 10:48:04
学苑创造·A版(2016年4期)2016-04-16 17:08:02
