
知识图谱数据管理研究综述*
2019-08-13 05:06王朝坤冯志勇
软件学报 2019年7期
王 鑫, 邹 磊, 王朝坤, 彭 鹏, 冯志勇
1(天津大学 智能与计算学部,天津 300350)
2(天津市认知计算与应用重点实验室,天津 300350)
3(北京大学 计算机科学技术研究所,北京 100871)
4(清华大学 软件学院,北京 100084)
5(湖南大学 信息科学与工程学院,湖南 长沙 410082)
知识图谱作为符号主义发展的最新成果,是人工智能的重要基石.随着知识图谱规模的日益扩大,其数据管理问题愈加重要.一方面,以文件形式保存知识图谱无法满足用户的查询、检索、推理、分析及各种应用需求;另一方面,传统数据库的关系模型与知识图谱的图模型之间存在显著差异,关系数据库无法有效管理大规模知识图谱数据.为了更好地管理知识图谱,语义 Web领域发展出专门存储 RDF数据的三元组库;数据库领域发展出用于管理属性图的图数据库.但是目前还没有一种数据库系统被公认为是具有主导地位的知识图谱数据库.
目前,规模为百万顶点(106)和上亿条边(108)的知识图谱数据集已经常见.链接开放数据2018年8月发布的LOD云图中很多知识图谱数据集规模超过10亿条三元组.例如,维基百科知识图谱DBpedia(>30亿条)、地理信息知识图谱LinkedGeoData(>30亿条)和蛋白质知识图谱UniProt(>130亿条)等.各领域大规模知识图谱的构建和发布对知识图谱数据管理提出了新的挑战.本文将遵循数据管理领域的良好传统,以数据模型的结构和操作两大要素为主线,对目前的知识图谱数据管理理论、方法、技术与系统等方面的研究与实践进行综述.
数据模型是任何数据管理领域的基础与核心.众所周知,数据模型包括数据的结构、操作和约束.由于知识图谱数据管理尚处于起步阶段,知识图谱数据模型的结构和操作方面还未发展完善,约束方面仅有尚在制定中的RDF Shapes约束语言[1]等少量研究工作,故而本文仅综述知识图谱数据模型中的结构和操作要素.本文首先介绍目前知识图谱的两种主流数据模型:RDF图模型和属性图模型;之后,作为知识图谱数据模型的操作,介绍5种知识图谱查询语言,包括SPARQL、Cypher、Gremlin、PGQL和G-CORE;接着,介绍如何使用各种存储管理方案实现知识图谱逻辑模型的物理存储,包括基于关系的知识图谱存储管理和原生知识图谱存储管理;然后,探讨知识图谱上 3种主要的查询操作类型,即图模式匹配、导航式和分析型查询;最后,介绍实现了知识图谱数据模型的主流数据库管理系统,包括RDF三元组库和原生图数据库,同时描述目前面向知识图谱的各种分布式系统与框架,并简要介绍知识图谱评测基准.本文最后对知识图谱数据管理的未来研究方向进行展望.作为阅读指导,图1给出了本综述各部分内容之间的总体路线图.
相关工作.目前,尚未发现与本文相同使用数据模型要素作为主线对知识图谱数据管理进行综述的文献.文献[2]对2002年之前的早期图数据模型进行了综述,但这些图数据模型由于结构复杂均未成为后来知识图谱的表示基础.文献[3]对2006年之前的图模式匹配查询算法进行了综述,图模式匹配查询是目前知识图谱的查询操作类型之一.文献[4]对 RDF图模式进行了形式化定义,对其上的基本图模式查询给出了若干理论结果.文献[5-7]是关于 RDF图数据管理的综述,包括单机和分布式系统.文献[8]是关于图数据管理的较新综述,但其内容与本综述差别较大,且没有按照数据模型结构与操作要素展开介绍.文献[9]着重在图数据查询处理方面进行综述,包括 RDF图和属性图上的图模式匹配和导航式查询,但内容上侧重理论结果,本文不仅涵盖了这些内容,而且还包括了知识图谱数据管理实现技术与系统,同时本文比文献[9]多介绍了PGQL和G-CORE两种查询语言.文献[10]综述了以顶点为中心的分布式图计算框架.文献[11]综述了分布式环境中的 RDF存储和查询处理.文献[12]使用真实与合成数据集对主要的分布式 SPARQL引擎进行了实验评估.文献[13]和文献[14]从分类体系和高层编程抽象角度综述了分布式图处理框架.文献[15]也是大规模图数据的分布式处理平台综述,但侧重于分析型处理任务.在中文文献中,文献[16]按照基于云计算平台、基于数据划分和联邦式系统的分类综述了RDF图分布式存储和查询方法,但没有涉及属性图数据管理.文献[17]从图存储、图索引、图分割、图计算模型、消息通信机制、图查询处理等方面综述了大规模图数据的分布式处理技术,但当时还未形成知识图谱数据模型.文献[18]仅就单机版本的图模式匹配查询进行了综述.最新的相关综述包括:文献[19]主要介绍了基于Pregel的分布式图处理框架的研究进展,而本文第5.3节会在更广的范围内介绍面向知识图谱数据管理的分布式系统与框架;文献[20]集中于讨论知识图谱上的推理方法与技术,而本文主题是知识图谱的数据管理,并在第 6节中将知识图谱数据管理对于本体和知识推理的支持作为未来研究方向之一.由于篇幅所限,本文不涉及知识图谱在时间维度上的变化,关于动态图的图模式匹配查询研究综述可参见文献[21].
1 知识图谱数据模型
数据模型定义了数据的逻辑组织结构(structure)、其上的操作(operation)和约束(constraint),决定了数据管理所采取的有效方法与策略,对于存储管理、查询处理、查询语言设计均至关重要.关系数据库长盛不衰的一个重要原因是关系数据模型(relational data model)中简洁而通用的关系结构,以及用具有严格数学定义的关系代数表达关系上的操作和约束[22].使用图结构刻画数据最早要追溯到层次数据模型(hierarchical data model)和网状数据模型(network data model):层次数据模型使用树结构表示数据,树是一种特殊的图;网状数据模型虽然支持图结构,但与后来的图数据模型有较大差异,也始终未能成为主流数据模型.早期的若干图数据模型基本上是以图论中的图结构(G=(V,E),其中,V是顶点集,E是边集)或其扩展作为数据结构[2];可以认为,知识图谱数据模型是图数据模型的继承和发展.知识图谱数据模型基于图结构,用顶点表示实体,用边表示实体间的联系,这种一般和通用的数据表示恰好能够自然地刻画现实世界中事物的广泛联系.目前,主流的知识图谱数据模型有两种: RDF图模型和属性图模型.下面分别进行介绍.
1.1 RDF图模型
RDF全称为资源描述框架(resource description framework),是万维网联盟(World Wide Web consortium,简称 W3C)制定的在语义 Web(semantic Web)上表示和交换机器可理解(machine-understandable)信息的标准数据模型[23].在RDF图中,每个资源具有一个HTTP URI作为其唯一id;RDF图定义为三元组(s,p,o)的有限集合;每个三元组表示是一个事实陈述句,其中,s是主语,p是谓语,o是宾语;(s,p,o)表示s与o之间具有联系p,或表示s具有属性p且其取值为o.下面给出RDF图的严格定义.
定义1(RDF图).设U、B和L为互不相交的无限集合,分别代表URI、空顶点(blank node)和字面量(literal).一个三元组(s,p,o)∈(U∪B)×U×(U∪B∪L)称为 RDF三元组,其中,s为主语,p为谓语,o为宾语.RDF图G是 RDF三元组的有限集合.
图 2所示的 RDF图示例描述了一个电影知识图谱,其中包括电影(movie)Titanic、导演(director)James_Cameron、演员(actor)Leonardo_DiCaprio和 Kate_Winslet等资源以及这些资源上的若干属性及资源之间的执导(direct)和出演(acts_in)联系.在RDF图示例中,用椭圆表示资源,用矩形表示字面量;一条有向边及其连接的两个顶点对应于一条三元组,尾顶点是主语,边标签是谓语,头顶点是宾语.资源所属的类型由 RDF内置谓语rdf:type指定,如三元组(James_Cameron,rdf:type,Director)表示James_Cameron是导演.为简便起见,本文RDF图中资源和谓语URI名称省略了命名空间前缀(RDF内置名称不省略,如rdf:type).对于本例中字面量的类型,字符串放在双引号中,整数 195是电影分钟数,定点数 1.79E9和 2.0E8分别是导演净资产和电影预算金额,日期1954-08-16、1974-11-11和1975-10-05分别是导演和两位演员的出生日期.由于空顶点的引入不会对RDF数据管理方法产生本质改变,本文将RDF图中的空顶点等同为URI.
例1:图2所示的RDF图的三元组集合形式为
导演在此片中也出演了角色,但图 2并没有包含出演(acts_in)的角色信息.实际上,RDF图模型没有对于顶点和边上属性的内置支持.顶点上的属性可表示为宾语是字面量的三元组;边上属性的表示需要使用额外的机制,最常见的是利用“具体化(reification)”方法[24],引入额外的顶点表示整个三元组,将边属性表示为以该顶点为主语的三元组.图3给出了如何使用“具体化”为acts_in边添加角色(role)属性;通过引入资源acts_in_1来表示三元组(James_Cameron,acts_in,Titanic),并使用 RDF内置谓语 rdf:subject、rdf:predicate和 rdf:object分别指明该条三元组的主语、谓语和宾语;三元组(acts_in_1,role,"Steerage Dancer")为 acts_in边添加了 role属性,即导演James_Cameron在影片 Titanic中扮演了“Steerage Dancer”这一角色.为了简洁起见,图 3中省略了三元组(acts_in_1,rdf:type,rdf:Statement),即指明新引入的资源 acts_in_1的类型是三元组(RDF内置类型 rdf:Statement表示一条三元组).
从数据模型角度看,RDF图是一种特殊的有向标签图(directed labeled graphs).与普通有向标签图相比,RDF图的特殊性在于,其三元组集合的本质使得一个三元组中的谓语也可作为另一个三元组的主语或宾语.反映在有向标签图中,即边亦可作为顶点(如图3中的边acts_in),顶点与边交集非空.在数学上,将这种图称为3-均匀超图(3-uniform hypergraph)[25].文献[4]给出了关于RDF图更加丰富的形式化定义,包括RDF模式(RDF schema)[26]、基于模型论的语义和基本推理系统.需要指出的是,W3C为 RDF图定义了基于描述逻辑(一阶谓词逻辑的可判定子集)的本体语言OWL[27],可描述概念之间更为复杂的逻辑关系,并给出了相应的逻辑推理规则.RDF图上的本体推理超出了本文的范围,感兴趣的读者可参见文献[28].
1.2 属性图模型
属性图是另一种管理知识图谱数据常用的数据模型.与RDF图模型相比,属性图模型对于顶点属性和边属性具备内置的支持.目前,属性图模型被图数据库业界广泛采用,包括著名的图数据库Neo4j[29].最近,由图数据管理领域学术界和工业界成员共同组成的关联数据基准委员会(Linked Data Benchmark Council,简称LDBC)也正在以属性图为基础对图数据模型和图查询语言进行标准化[30].下面给出属性图的形式化定义.
定义2(属性图).属性图G是5元组(V,E,ρ,λ,σ),其中,(1)V是顶点的有限集合;(2)E是边的有限集合且V∩E=Ø;(3) 函数ρ:E→(V×V)将边关联到顶点对,如ρ(e)=(v1,v2)表示e是从顶点v1到顶点v2的有向边;(4) 设Lab是标签集合,函数λ:(V∪E)→Lab为顶点或边赋予标签,如v∈V(或e∈E)且λ(v)=l(或λ(e)=l),则l为顶点v(或边e)的标签;(5) 设Prop是属性集合,Val是值集合,函数σ:(V∪E)×Prop→Val为顶点或边关联属性,如v∈V(或e∈E)、p∈Prop且σ(v,p)=val(或σ(e,p)=val),则顶点v(或边e)上属性p的值为val.
图4给出了图2中电影知识图谱的属性图示例.在属性图中,每个顶点和边都具有唯一id(如顶点v1、边e2);顶点和边均可具有标签(如顶点v1上的标签Director、边e2上的标签acts_in),其作用基本相当于RDF图中的资源类型;顶点和边上均可具有一组属性,每个属性由属性名和属性值组成(如顶点v1上的属性 name="James Cameron"、边e2上的属性role="Steerage Dancer").可以看出,利用边属性的定义,图4比图2增加了出演的角色信息,同时又没有改变属性图的整体结构(RDF图的“具体化”方法增加了顶点和边,改变了图结构).
例 2:图 4 所示的属性图G=(V,E,ρ,λ,σ),其中,
在定义 2中,每个顶点或边上只能有一个标签,每个属性也只能具有一个值;如果允许顶点或边上具有多个标签,可将定义中的函数λ改为λ:(V∪E)→ℙ(Lab),如果允许属性对应多个值,可将函数σ改为σ:(V∪E)×Prop→ℙ(Val),其中,ℙ(X)表示集合X的幂集.在实际中,不同图数据库管理系统可能有不同规定,例如,在Neo4j实现的属性图模型中,顶点上可以有多个标签,边上只能有一个标签,每个属性只有一个值.
例3:图5给出了一个关系更为复杂的社交网络知识图谱的属性图模型,其中,顶点标签有3种:Person、Post和Tag;边标签有5种:knows、likes、dislikes、hasTag和follower.Person顶点上可有属性firstName、lastName、gender和country;Post顶点上可有属性text和lang;Tag顶点上可有属性label;likes和dislikes边上可有属性date.注意到图中存在回路(cycle),如v4e1v1e5v5e8和v2e3v3e4.
1.3 两种数据模型比较
表1给出了RDF图模型和属性图模型这两种主流知识图谱数据模型的比较,包括数据模型的结构、操作和约束3个方面.RDF图模型的表达力强于属性图模型,是因为RDF的超图本质,一条三元组的谓语可在另一条三元组中作主语或宾语,而属性图中顶点和边属性上却不能再定义属性[31].总体说来,由于 RDF图具有加强的逻辑理论背景,加之语义Web多年的标准化工作,其数据模型特性相对完善,但也正是因为理论性过强而影响了其在工业界的推广;属性图虽然在理论基础方面还不够完善,但是随着 Neo4j等图数据库的应用,其获得了较强的用户认可度.
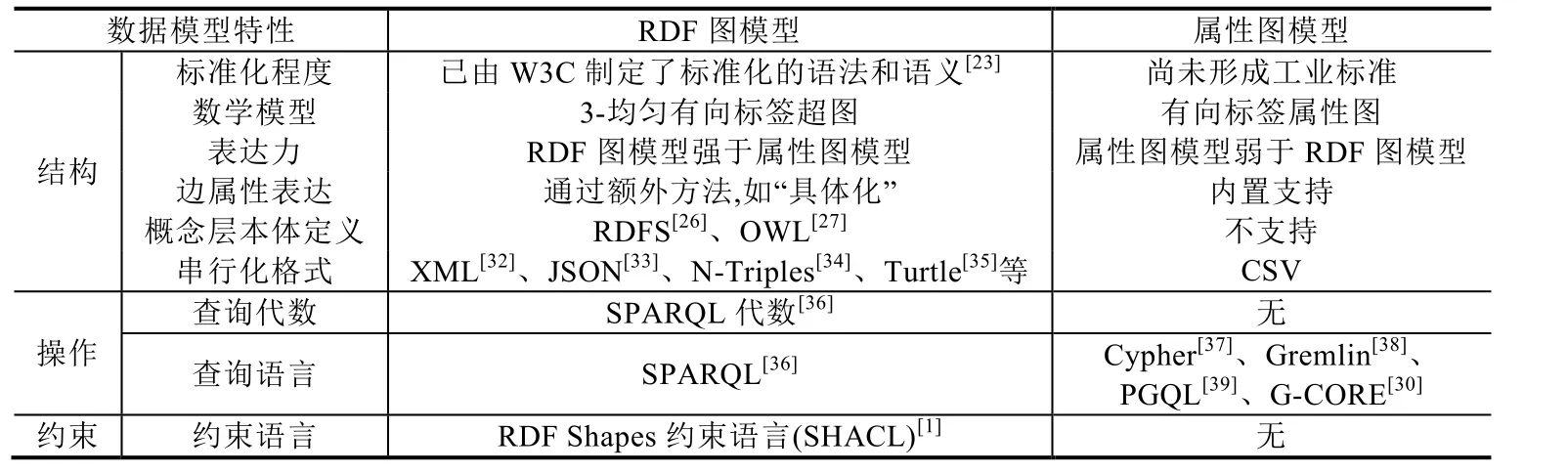
Table 1 The comparison of the RDF graph model and the property graph model表1 RDF图模型和属性图模型的比较
2 知识图谱查询语言
知识图谱查询语言主要实现了知识图谱数据模型的操作部分.目前,RDF图的标准查询语言是SPARQL;属性图查询语言主要有 Cypher、Gremlin、PGQL和 G-CORE.从查询语言的类型看,除了 Gremlin属于过程式(procedural)语言外,SPARQL、Cypher、PGQL和 G-CORE均属于声明式(declarative)语言.下面分别加以介绍.关于各种知识图谱查询语言的比较请参见后文的表5.
2.1 SPARQL
SPARQL是W3C制定的RDF知识图谱标准查询语言[36].SPARQL从语法上借鉴了SQL.SPARQL查询的基本单元是三元组模式(triple pattern),多个三元组模式可构成基本图模式(basic graph pattern).SPARQL支持多种运算符,将基本图模式扩展为复杂图模式(complex graph pattern).SPARQL 1.1版本引入了属性路径(property path)机制[40]以支持RDF图上的导航式查询.下面使用图2所示的电影知识图谱RDF图,通过示例介绍SPARQL语言的基本功能.
例4:查询1950年之后出生的资产大于1.0E9的导演执导的电影的出演演员.
查询结果:

?x4 ?x5 TitanicLeonardo_DiCaprio TitanicKate_Winslet TitanicJames_Cameron
SELECT子句指明要返回的结果变量;WHERE子句指明查询条件;“?x1 rdf:type Director.”是三元组模式,其中,rdf:type和Director是常量,?x1是变量(SPARQL中的变量以?开头),句点表示一条三元组模式的结束.图6给出了例 4对应的查询图,可以看出,每个三元组模式对应一条边,由 5个三元组模式构成了基本图模式;关键字FILTER用于指明过滤条件,对变量匹配结果按条件进行筛选;加上了FILTER过滤后基本图模式,最后构成复杂图模式查询.
例5:查询具有有限多步“合作距离(collaborative distance)”的两名演员.
查询结果:

?x1 ?x2 Leonardo_DiCaprioKate_Winslet Kate_Winslet Leonardo_DiCaprio
该查询用到了SPARQL 1.1中的属性路径功能实现导航式查询,实际上,(acts_in/^acts_in)*是正则表达式,匹配0步到多步“合作距离”,其中,运算符/表示路径连接(path concatenation),运算符^表示反向路径(inverse path),运算符*表示克林闭包(Kleene closure).使用FILTER将?x1和?x2匹配到同一演员的情况过滤掉.
SPARQL经过W3C的标准化过程,具有精确定义的语法和语义.完整的SPARQL 1.1语法与语义请参见文献[36](W3C推荐标准).文献[41]最早给出了SPARQL语义、复杂度和表达力相关的理论结果.W3C推荐标准中图模式是包语义(bag semantics),属性路径中的闭包算子(即*和+)是集合语义(set semantics).文献[42,43]的研究工作直接影响了SPARQL 1.1属性路径语义的确定,即用“存在式(existential)”的集合语义取代了之前草案中“数路径式(counting paths)”的包语义,从而降低了SPARQL属性路径的计算复杂度.同时,SPARQL 1.1中还包括专门用于RDF图数据更新和管理的子语言SPARQL 1.1 Update[44].
2.2 Cypher
Cypher最初是图数据库 Neo4j中实现的属性图数据查询语言.2015年,Neo4j公司发起开源项目 open Cypher(https://www.opencypher.org),旨在对Cypher进行标准化工作,为其他实现者提供语法和语义的参考标准.虽然 Cypher的发展目前仍由 Neo4j主导,但包括 SAP HANA Graph[45]、Redis Graph[46]、AgensGraph[47]和Memgraph[48]等在内的图数据库产品已经实现了 Cypher.Cypher的一个主要特点是使用“ASCII艺术(ASCII art)”语法表达图模式匹配.下面通过例子介绍Cypher语言的基本功能.使用的图数据是图4所示的电影知识图谱和图5所示的社交网络知识图谱.
例6:查询1950年之后出生的资产大于1.0E9的导演执导的电影的出演演员.
查询结果:

x2{"name":"Kate Winslet","birthDate":"1975-10-05"}{"name":"Leonardo DiCaprio","birthDate":"1974-11-11"}
本例与例4的SPARQL查询问题相同.MATCH子句用于指明要匹配的图模式,顶点信息写在圆括号“( )”中,边信息写在方括号“[ ]”中,属性信息写在花括号“{ }”中,用“:”分开顶点(或边)变量和标签.在本例中,“(x1:Director)”表示该图模式顶点要匹配的数据图顶点标签为 Director,且变量 x1会绑定到匹配结果顶点;“-[:directs]->”表示要匹配标签为directs的有向边;MATCH子句引导的图模式是一个以“(:Movie)”为中心、由两条边构成的星形图模式.这些语法说明了 Cypher如何使用 ASCII艺术形式表达图查询.WHERE关键字与MATCH子句配合使用,用于指定图模式匹配的约束条件.内置函数 date用于将字符串转化为日期类型.RETURN子句用于返回结果变量.本例等价于SPARQL基本图模式查询.
例7:查询San Zhang直接和间接认识的人.
查询结果:

x1 x2{"country":"China","firstName":"San","lastName":"Zhang"}{"firstName":"Si","lastName":"Li","country":"China"}{"country":"China","firstName":"San","lastName":"Zhang"}{"firstName":"Bob","lastName":"Smith","country":"US","gender":"male"}{"country":"China","firstName":"San","lastName":"Zhang"}{"firstName":"Si","lastName":"Li","country":"China"}
本例使用图 5作为知识图谱,展示了 Cypher的导航式查询功能.Cypher通过变长模式(variable-length pattern)匹配对导航式查询提供有限支持.不同于 SPARQL属性路径,Cypher变长模式仅实现了正则路径查询(regular path query)的一个子集,即传递闭包算子*只能作用在单独一个边标签上,如:knows*;对比例 5中SPARQL属性路径对正则表达式的完整支持.
同时,Cypher还提供了相应的语句进行属性图的数据更新操作,包括图结构更新和属性更新.Cypher语言的官方文档请参见文献[29].最新的文献[37]给出了 Cypher当前版本核心查询功能的形式语法和语义定义,并讨论了Cypher在下一版本将引入的新特性.
2.3 Gremlin
Gremlin是Apache TinkerPop图计算框架[38]提供的属性图查询语言.Gremlin是图遍历语言,其执行机制是在图中沿着有向边进行导航式的游走.这种执行方式决定了用户使用 Gremlin需要指明具体的导航步骤,所以Gremlin是过程式语言.与受到SQL影响的声明式语言SPARQL和Cypher不同,Gremlin更像一种函数式的编程语言接口.下面通过例子来介绍Gremlin语言的基本功能.使用的属性图是图4所示的电影知识图谱.
例8:查询1950年之后出生的资产大于1.0E9的导演执导的电影的出演演员名字.
查询结果:
Leonardo DiCaprio
Kate Winslet
本例使用Gremlin表达基本图模式查询.g是图遍历对象,即属性图.函数调用g.V()返回图中所有顶点集;接着施加3个过滤条件,函数hasLabel('Director')限定顶点标签为Director,函数has('birthDate',gte('1950-01-01'))限定顶点上属性birthDate值大于等于'1950-01-01',函数has('networth',gt(1.0E9))限定顶点上属性networth值大于1.0E9,其中,谓词gte和gt分别表示比较运算符≥和>;函数out('directs')返回由满足上述条件的顶点集出发,沿有向边directs能够到达的顶点集,即1950年之后出生的资产大于1.0E9的导演执导的电影顶点;函数in('acts_in')返回从这些电影顶点出发,沿着有向边acts_in的反方向能够到达的顶点集;函数 hasLabel('Actor')将不是Actor标签的顶点过滤掉,因此结果中不包括James Cameron(虽然v1到v2也有acts_in边e2);最后,函数values('name')返回这些顶点的name属性值.由本例可以看出Gremlin的图遍历、过程式和函数式风格.下面,我们来对比该查询的 SPARQL(例4)和 Cypher(例6)版本.
例9:列出演员“Leonardo DiCaprio”与距其有限多步“合作距离”演员之间的全部路径.
查询结果:
[v[3],v[2],v[3]]
[v[3],v[2],v[4]]
[v[3],v[2],v[3],v[2],v[3]]
[v[3],v[2],v[3],v[2],v[4]]
…
本例展示了Gremlin的导航式查询.使用函数repeat重复执行指定的导航操作;一步“合作距离”导航操作被执行了任意多次;使用emit()输出每次重复执行的求值结果;使用path()输出整条导航路径.可以看出操作后得到了无穷多个匹配路径,原因是 Gremlin默认语义是“任意路径”语义,对于路径中顶点和边的重复出现没有限制.路径查询的不同语义将在第4节中给出讨论.
要了解Gremlin的全面语法功能,请参见文献[38].目前,还未见关于Gremlin形式语义方面的研究工作.
2.4 PGQL
PGQL是Oracle在2016年提出的属性图查询语言[39],支持图模式匹配查询和导航式查询.PGQL在语法结构上参照SQL设计,同时查询返回与SQL相同的结果集,可将其作为子查询嵌入到SQL查询中.PGQL从Cypher借鉴了ASCII艺术语法表示图模式;与Cypher相比,PGQL完整地支持正则路径查询语义;与SPARQL属性路径仅支持边标签构成的正则路径不同,PGQL通过路径模式(path pattern)表达式定义,还支持正则路径中含有顶点标签条件以及顶点(或边)属性值比较,在提高了属性图上正则路径查询表达力(expressiveness)的同时保持求值复杂度(complexity)不变.下面给出一个PGQL查询示例,请对比例5和例9.
例10:列出与演员“Leonardo DiCaprio”距离有限多步“合作距离”的演员姓名和生日.
查询结果:
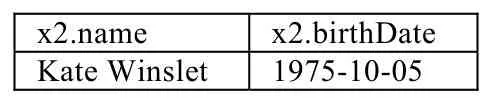
x2.name x2.birthDate Kate Winslet 1975-10-05
查询开头使用 PATH 关键字指定名为“collaborate”路径模式“()-[:acts_in]->(:Movie)<-[:acts_in]-()”;与 SQL一致,SELECT子句用于返回查询结果变量,FROM子句指明图数据,WHERE子句给出过滤条件,其中,PGQL内置函数id(x)返回顶点或边x的标识id;在MATCH子句中,“-/:collaborate*/->”表示匹配“collaborate”路径模式任意多次.通过这种方式可以表达出任意复杂的正则路径查询.
目前,PGQL仅有Oracle PGX一种实现版本[49].关于PGQL最新版本1.1的语法和语义请参见文献[50].
2.5 G-CORE
G-CORE是由LDBC图查询语言工作组(LDBC Graph Query Language Task Force)设计的属性图查询语言.G-CORE语言的设计目标是充分借鉴和融合各种已有图查询语言的优点,在查询表达力和求值复杂度之间寻求最佳平衡[30].G-CORE与已有图查询语言相比:(1) 查询的输入输出均是图,彻底实现了图查询语言的可组合性(composability);(2) 将路径作为与顶点和边同等重要的图查询处理基本元素.为此,G-CORE在属性图模型的基础上进行扩展,定义了路径属性图模型(path property graph model,简称PPG).
定义3(路径属性图).PPG是7元组G=(V,E,P,ρ,δ,λ,σ),其中,(1)V是顶点的有限集合,E是边的有限集合,P是路径的有限集合,V,E,P互不相交;(2) 函数ρ:E→(V×V)将边关联到顶点对,如ρ(e)=(v1,v2)表示e是从顶点v1到顶点v2的有向边;(3) 设Seq(X)表示集合X中元素组成的序列,函数δ:P→Seq(V∪E)将路径映射到顶点和边交替组成的序列,如p∈P,δ(p)=(v1,e1,v2,…,vn,en,vn+1),其中,(i)vi∈V(1≤i≤n+1);(ii)ei∈E,ρ(ei)=(vi,vi+1)或ρ(ei)=(vi+1,vi)(1≤i≤n);(4) 设Lab是标签集合,函数λ:(V∪E∪P)→Lab为顶点、边或路径赋予标签;(5) 设Prop是属性集合,Val是值集合,函数σ:(V∪E∪P)×Prop→Val为顶点、边或路径关联属性.
从PPG的定义可以看出,路径已与顶点和边同为图数据模型中的“一等公民”.与顶点和边相同,路径也可以有标签和属性,路径属性可以描述属于路径的信息,如路径长度、导航开销等.下面给出一个G-CORE查询示例,请对比例9和例10.
例11:列出演员“Leonardo DiCaprio”与距其有限多步“合作距离”演员之间的最短路径及路径长度.
查询结果:

@p(v3)-[e3]->(v2)<-[e4]-(v4) {distance = 2}
在G-CORE中,每个查询均使用CONSTRUCT子句返回图作为查询结果,这保证了查询的可组合性,即一个查询的输出可以直接作为另一个查询的输入.PATH关键字借鉴自 PGQL,用于定义路径模式,以构成任意复杂的正则路径查询,这里定义的路径模式 collaborate表示两名演员之间的合作关系,即共同出演一部电影.G-CORE中@前缀引导的变量p表示存储路径(stored path),即物化存储在图数据库中的路径;CONSTRUCT子句构建的图由存储路径@p组成,@p的标签为collaborate_distance,具有属性distance,由顶点x1导航到顶点x2.MATCH子句匹配由演员Leonardo DiCaprio与其他演员(变量x2,x1 !=x2表示不能是同一演员)之间的所有有限多步“合作距离”中的最短路径,即 p〈~collaborate*〉,其中,p是路径变量,~collaborate是对 PATH定义的路径模式的引用,*是克林闭包;COST c表示最短路径代价为 c,默认代价即路径长度,c作为属性值保存到存储路径@p的属性distance中.可见,查询结果是一条完整的路径信息.
目前,G-CORE仅有一个开源的语法解析器[51],还没有数据库系统实现.关于G-CORE的详细语法和语义请参见文献[52].
3 知识图谱存储管理
首先介绍基于关系的知识图谱存储机制,然后给出两种典型的原生知识图谱数据库的底层存储.
3.1 基于关系的知识图谱存储管理
关系数据库目前仍是使用最多的数据库管理系统.基于关系数据库的存储方案是目前知识图谱数据的一种主要存储方法.本小节将按照时间发展顺序依次介绍各种基于关系的知识图谱存储方案,包括:三元组表、水平表、属性表、垂直划分、六重索引和DB2RDF.
3.1.1 三元组表
三元组表(triple table)是将知识图谱存储到关系数据库的最简单、最直接的办法,就是在关系数据库中建立一张具有3列的表,该表的模式为
subject、predicate和 object这 3列分别表示主语、谓语和宾语;将知识图谱中的每条三元组存储为三元组表triple_table中的一行记录.
例12:图7是图2所示电影知识图谱对应的三元组表,一共有16行,限于篇幅,仅列出前7行.
三元组表存储方案虽然简单明了,但三元组表的行数与知识图谱的边数相等,其最大问题在于将知识图谱查询翻译为SQL查询后会产生三元组表的大量自连接操作.例如,例4的SPARQL查询翻译为等价的SQL查询后如例13所示.一般自连接的数量与SPARQL中三元组模式数量相当.当三元组表规模较大时,多个自连接操作将影响SQL查询性能.
采用三元组表存储方案的代表是RDF数据库系统3store[53].
例13:在三元组表存储方案中,将例4的SPARQL查询转化为等价的SQL查询.三元组表的表名为t.
3.1.2 水平表
水平表(horizontal table)存储方案同样非常简单.水平表的每行记录存储知识图谱中一个主语的所有谓语和宾语.实际上,水平表相当于知识图谱的邻接表.水平表的列数是知识图谱中不同谓语的数量,行数是知识图谱中不同主语的数量.
例14:图8是图2中电影知识图谱对应的水平表,共有4行、10列.
在水平表存储方案中,例4中的SPARQL查询可以等价地翻译为例15中的SQL查询.可见,与三元组表相比,水平表存储方案使得查询大为简化,自连接操作由4个减少到2个.
例15:在水平表存储方案中,将例4的SPARQL查询转化为等价的SQL查询.水平表的表名为t.
但是水平表的缺点在于:(1) 所需列的数目等于知识图谱中不同谓语数量,在真实知识图谱数据集中,不同谓语数量可能为几千个到上万个,很可能超出关系数据库所允许的表中列数目上限;(2) 对于一行来说,仅在极少数列上具有值,表中存在大量空值,空值过多会影响表的存储、索引和查询性能;(3) 在知识图谱中,同一主语和谓语可能具有多个不同宾语,即一对多联系或多值属性,而水平表的一行一列上只能存储一个值,无法应对这种情况(可以将多个值用分隔符连接存储为一个值,但这违反了关系数据库设计的第一范式);(4) 知识图谱的更新往往会引起谓语的增加、修改或删除,即水平表中列的增加、修改或删除,这是对于表结构的改变,成本很高.
采用水平表存储方案的代表是早期的RDF数据库系统DLDB[54].
3.1.3 属性表
属性表(property table)存储方案是对水平表的细分,将同类主语存到一个表中,解决了表中列数目过多的问题.例16给出了图2所示电影知识图谱对应的属性表存储方案,分为director(导演)、movie(电影)和actor(演员)3个表.
例16:图9是图2中电影知识图谱对应的属性表存储方案,共由3个表组成.
在属性表存储方案中,例4中的SPARQL查询可以等价地翻译为例17中的SQL查询.该查询与水平表上的等价查询(例15)相比,t1变为了director,t2变为了movie,t3变为了actor,由自连接转变为多表连接,而且每个表对应于一个类型,省去了类型(type列)的判断,提高了查询的可读性.
例17:在属性表存储方案中,将例4的SPARQL查询转化为等价的SQL查询.
属性表既克服了三元组表的自连接问题,又解决了水平表中列数目过多的问题.实际上,水平表就是属性表的一种极端情况,即水平表是将所有主语划归为一类,因此属性表中的空值问题得到很大的缓解.但属性表仍存在如下一些缺点:(1) 对于规模稍大的真实知识图谱数据,主语的类别可能有几千到上万个,需要建立几千到上万个表,这往往超过了关系数据库的限制;(2) 即使在同一类型中,不同主语具有的谓语集合也可能差异较大,会造成与水平表中类似的空值问题;(3) 水平表中存在的一对多联系或多值属性存储问题在属性表中仍然存在.
采用属性表存储方案的代表系统是RDF三元组库Jena[55].
3.1.4 垂直划分
垂直划分(vertical partitioning)存储方案是由美国麻省理工学院Abadi等人在2007年提出的RDF数据存储方法[56].该方法为每种谓语建立一张两列的表(subject,object),表中存放知识图谱中由该谓语连接的主语和宾语,表的总数量即知识图谱中不同谓语的数量.例18给出了图2所示电影知识图谱对应的垂直划分存储方案,9种谓语对应着9张表,每张表都只有主语和宾语列.
例18:图10是图2所示电影知识图谱对应的垂直划分存储方案,共由9个表组成.
在垂直划分存储方案中,例4中的SPARQL查询可以等价地翻译为例1中的SQL查询.该查询涉及到5张谓语表的连接操作,其中有3个“subject-subject”等值连接.由于表中的行都按subject列进行排序,可快速执行这种垂直划分方案中最常用的连接操作.
例19:在垂直划分存储方案中,将例4的SPARQL查询转化为等价的SQL查询.
与之前基于关系数据库的知识图谱存储方案相比,垂直划分有一些突出的优点:(1) 谓语表仅存储出现在知识图谱中的三元组,解决了空值问题;(2) 一个主语的一对多联系或多值属性存储在谓语表的多行中,解决了多值问题;(3) 每个谓语表都按主语列的值进行排序,能够使用归并排序连接(merge-sort join)快速执行不同谓语表的连接查询操作.
不过,垂直划分存储方案依然存在如下几个缺点:(1) 需要创建的表的数目与知识图谱中不同谓语数目相等,而大规模的真实知识图谱(如,DBpedia、YAGO、WikiData等)中谓语数目可能超过几千个,在关系数据库中维护如此规模的表需要花费很大开销;(2) 越是复杂的知识图谱查询操作,需要执行的表连接操作数量越多,而对于未指定谓语的三元组查询,将发生需要连接全部谓语表进行查询的极端情况;(3) 谓语表的数量越多,数据更新维护代价越大,对于一个主语的更新将涉及多张表,产生很高的更新时I/O开销.
采用垂直划分存储方案的代表数据库是SW-Store[57].
3.1.5 六重索引
六重索引(sextuple indexing)存储方案是对三元组表的扩展,是一种典型的“空间换时间”策略,其将三元组全部 6 种排列对应地建立为 6 张表,即 spo(主语,谓语,宾语)、pos(谓语,宾语,主语)、osp(宾语,主语,谓语)、sop(主语,宾语,谓语)、pso(谓语,主语,宾语)和 ops(宾语,谓语,主语).不难看出,其中 spo 表就是原来的三元组表.六重索引通过6张表的连接操作不仅缓解了三元组表的单表自连接问题,而且提高了某些典型知识图谱查询的效率.
六重索引方案的优点有:(1) 知识图谱查询中的每种三元组模式查询都可以直接使用相应的索引进行快速前缀范围查找,表2给出了全部8种三元组模式查询能够使用的索引;(2) 可以通过不同索引表之间的连接操作直接加速知识图谱上的连接查询.
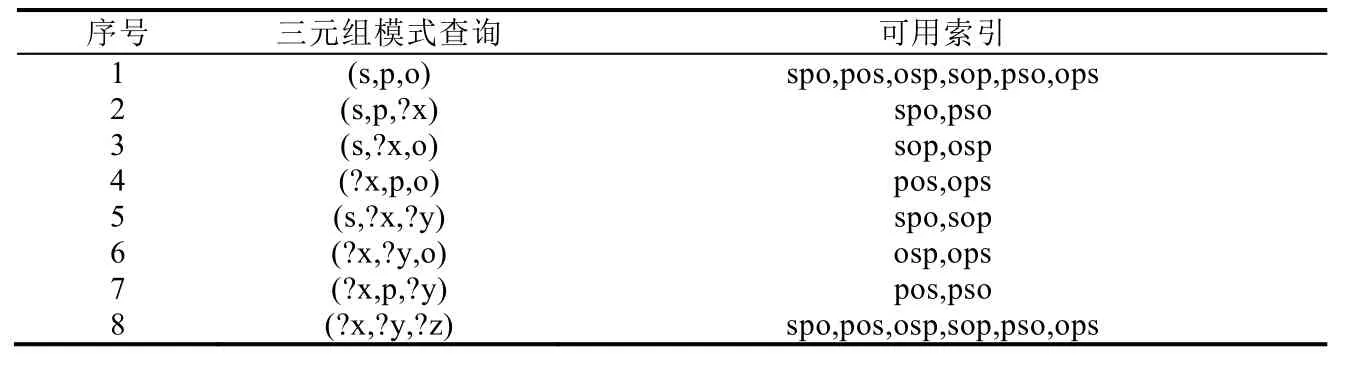
Table 2 Triple pattern queries and usable indexes in sextuple indexing表2 六重索引方案下三元组模式查询和可使用的索引表
六重索引存储方案存在的问题包括:(1) 虽然部分缓解了三元组表的单表自连接问题,但需要花费6倍的存储空间开销、索引维护代价和数据更新时的一致性维护代价,随着知识图谱规模的增大,该问题会愈加突出;(2) 当知识图谱查询变得复杂时,会产生大量的连接索引表查询操作,依然不可避免索引表的自连接.
使用六重索引方法的典型系统有RDF-3X[58]和Hexastore[59].
3.1.6 DB2RDF
DB2RDF是由IBM于2013年提出的一种面向实体的RDF知识图谱存储方案[60,61],该方案是以往RDF关系存储方案的一种权衡与折中,既具备了三元组表、属性表和垂直划分方案的部分优点,又克服了这些方案的部分缺点.三元组表的优势在于“行维度”上的灵活性,即存储模式不会随行的增加而变化;DB2RDF方案将这种灵活性扩展到“列维度”上,即将表的列作为谓语和宾语的存储位置,而不将列与谓语进行绑定.插入数据时,将谓语动态映射存储到某列;方案能够确保将相同谓语映射到同一组列上.
DB2RDF存储方案由4张表组成,即:dph表、rph表、ds表和rs表;例20给出了图2所示电影知识图谱对应的DB2RDF存储方案.dph(direct primary hash)是存储方案的主表,该表中一行存储一个主语(subject列)及其全部谓语(predi列)和宾语(vali列),0≤i≤k,k一般是关系数据库支持的表中最大列数目;如果一个主语的谓语数量大于k,则一行不足以容纳下一个实体,将在下一行存储第k+1到2k个谓语和宾语,以此类推,这种情况叫作溢出(spill);spill列是溢出标志,即对于一行能存储下的实体,该行 spill列为 0,对于溢出的实体,该实体所有行的spill列为1.例如,在例20的dph表中,实体James_Cameron溢出,其余实体均未溢出.
对于多值谓语的处理,引入ds(direct secondary hash)表.当dph表中遇到一个多值谓语时,则在相应的宾语处生成一个唯一的 id值;将该 id值和每个对应的宾语存储为 ds表的一行.例如,在图 2的基础上添加三元组(James_Cameron,directs,Avatar),这时,directs就成为多值谓语,在例20的dph表中,在其宾语列val2中存储id值lid:1;在ds表中存储lid:1关联的两个宾语Titanic和Avatar.
实际上,dph表实现了列的共享:一方面,不同实体的相同谓语总是会被分配到相同列上;另一方面,同一列中可以存储多个不同的谓语.比如,主语Leonardo_DiCaprio和Kate_Winslet的谓语acts_in都被分配到pred4列,同时,该列还存储了主语Titanic的谓语length.正是由于DB2RDF方案具备“列共享”机制,才使得在关系表中最大列数目上限的情况下可以存储远超出该上限的谓语数目,也能够有效地解决水平表方案中存在的谓语稀疏性空值问题.在真实的知识图谱中,不同主语往往具有不同的谓语集合,例如,谓语 birthDate只有人(person)才具有,谓语budget只有电影(movie)才具有,这也是能够实现列共享的原因所在.
例20:图11是图2所示电影知识图谱对应的DB2RDF存储方案(rs表示省略).
从知识图谱数据模型的角度来看,dph表和 ds表实际上存储了实体顶点(主语)的出边信息(从主语经谓语到宾语);为了提高查询处理效率,还需要存储实体顶点的入边信息(从宾语经谓语到主语).为此,DB2RDF方案提供了rph(reverse primary hash)表和rs(reverse secondary hash)表.
例21:在DB2RDF存储方案中,将例4的SPARQL查询转化为等价的SQL查询.
在DB2RDF方案中,谓语到列的映射是需要重点考虑的问题.因为关系表中最大列的数目是固定的,该映射的两个优化目标是:(1) 使用的列的数目不要超过某个值m;(2) 尽量减少将同一主语的两个不同谓语分配到同一列的情况,从而减少溢出现象,因为溢出会导致查询时自连接的发生.
谓语到列映射的一种方法是使用一组哈希函数,将谓语映射到一组列编号,并将谓语及其宾语存储到这组列中的第 1个空列上;在一个主语对应的一行中,如果存储某谓语(及其宾语)时,哈希函数计算得出的这组列中的所有列都被之前存储的该主语的谓语占用,则产生溢出,到下一行存储该谓语.例如,表3给出了谓语到列映射的哈希函数表,其中包括h1和h2两个哈希函数,映射了 5个谓语到列编号组.比如,当存储到三元组(James_Cameron,directs,Titanic)时,谓语directs被h1映射到列pred2,被h2映射到列pred3,但这两列都已被占用,这时产生溢出,将谓语directs溢出到下一行的列pred2中存储,如图11的dph表所示.
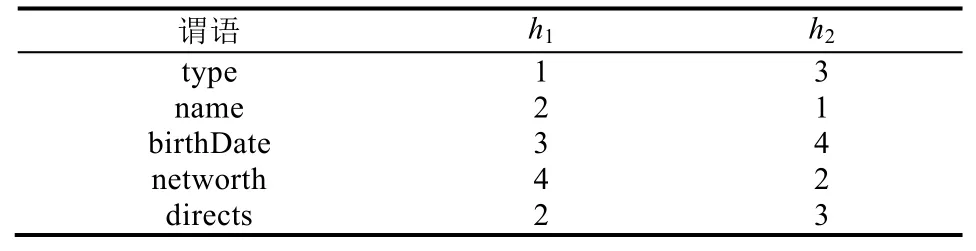
Table 3 Predicate-to-column hash function table表3 谓语到列映射的哈希函数表
如果可以事先获取知识图谱的一个子集,则可以利用知识图谱的内在结构优化谓语到列的映射.方法是将谓语到列的映射转化为图着色(graph coloring)问题.将一个主语上出现的不同谓语称为共现谓语(co-occurrence predicates),目标是让共现谓语着上不同颜色(映射到不同列中),非共现谓语可以着上相同颜色(映射到同一列中),并使所用颜色数最少.需要指出的是,虽然图着色是经典的 NP难问题,但即使是真实知识图谱,其不同谓语总数也是相对较少的(一般在几千个规模上).
如果在大规模真实知识图谱中(如DBpedia),图着色所需颜色数量超过了关系数据表的列数上限m,则根据某种策略(如最频繁使用的前k个谓语)选取一个谓语子集,使得该谓语子集到列的映射满足图着色要求;对于不在该子集中的谓语,再使用前面提到的哈希函数组策略进行映射.
DB2RDF存储方案已经实现到了最新的IBM DB2数据库系统中[61].
3.2 原生知识图谱存储管理
不同于基于关系的存储方案,原生知识图谱存储是指专门为知识图谱而设计的底层存储管理方案.不同原生知识图谱数据库的物理和逻辑存储层设计与实现也各有差异.本小节选取两种具有代表性的原生知识图谱存储管理方案进行介绍:一种是面向属性图的Neo4j存储;另一种是面向RDF图的gStore存储.
3.2.1 Neo4j
Neo4j是目前最流行的属性图数据库,其原生图存储层的最大特点是具有“无索引邻接(index-free adjacency)”特性.所谓“无索引邻接”是指,每个顶点维护着指向其邻接顶点的直接引用,相当于每个顶点都可看作是其邻接顶点的一个“局部索引”,用其查找邻接顶点比使用“全局索引”节省大量时间.这就意味着图导航操作代价与图大小无关,仅与图的遍历范围成正比.
为了实现“无索引邻接”,Neo4j将边也作为数据库的“一等公民”(即数据库中最基本、最核心的概念,如关系数据库中的“关系”),属性图的顶点、边、标签和属性被分开存储在不同文件中.正是这种将图结构与图上标签和属性分开存储的策略,使得Neo4j具有高效率的图遍历能力.图12给出了Neo4j 2.2版本中顶点和边记录的物理存储结构(其他版本可能有变化),其中每个顶点记录占用15字节,每个边记录占用34字节.
顶点记录的第0字节inUse是记录使用标志字节,表示该记录是正在使用中还是已经删除并可回收用来装载新记录;第1字节~第4字节nextRelId是与顶点相连的第1条边的id;第5字节~第8字节nextPropId是顶点的第1个属性的id;第9字节~第13字节labels是指向顶点标签存储的指针,若标签较少会直接存储在此处;第14字节extra用于存储一些内部使用的标志信息.
边记录第 0字节 inUse的含义与顶点记录相同,是表示是否正被数据库使用的标志;第 1字节~第 4字节firstNode和第 5字节~第8字节 secondNode分别是该边的起始顶点id和终止顶点id;第 9字节~第12字节relType是指向该边的关系类型的指针;第13字节~第16字节firstPrevRelId和第17字节~第20字节firstNext RelId分别为指向起始顶点上前一个和后一个边记录的指针;第21字节~第24字节secPrevRelId和第25字节~第28字节secNextRelId分别为指向终止顶点上前一个和后一个边记录的指针;指向前后边记录的4个指针形成了两个“关系双向链”;第 29字节~第 32字节 nextPropId是边上的第 1个属性的 id;第 33字节 firstInChain Marker是表示该边记录是否是“关系链”中第1条记录的标志.
Neo4j能够实现顶点和边快速定位的关键是“定长记录(fixed-size record)”存储方案,以及将具有定长记录的图结构与具有变长记录的属性数据分开存储.例如,一个顶点记录长度是15字节,如果要查找id为99的顶点记录所在位置(id从0开始),则可直接到顶点存储文件第1485(15×99)个字节处访问(存储文件从第0个字节开始).边记录也是“定长记录”,长度为34字节.这样,数据库已知记录id可以O(1)的代价直接计算其存储地址,从而避免了全局索引中O(logn)的查找代价.
图 13是图 5所示顶点v2和v3及其出边e3、e4、e6和e7的 Neo4j物理存储结构,展示了 Neo4j中各种存储文件之间是如何交互的.存储在顶点文件中的顶点v2和v3均有指针(nextPropId)指向存储在属性文件中各自的第1个属性记录;也有指针(nextRelId)指向存储在边文件中各自的第1条边,分别为边e3和e4.若要查找顶点属性,可由顶点找到其第1个属性记录,再沿着属性记录的单向链表进行查找;若要查找一个顶点上的边,可由顶点找到其第 1条边,再沿着边记录的双向链表进行查找;当找到了所需的边记录后,可由该边进一步找到边上的属性;还可由边记录出发访问该边连接的两个顶点记录(图 13所示虚线箭头).需要注意的是,每个边记录实际上维护着两个双向链表,一个是起始顶点上的边,一个是终止顶点上的边,可以将边记录想象为被起始顶点和终止顶点共同拥有,用双向链表的优势在于,不仅可在查找顶点上的边时进行双向扫描,而且支持在两个顶点间高效率地添加和删除边.这些操作除了记录字段的读取,就是定长记录地址的计算,均是O(1)时间的高效率操作.可见,正是由于将边作为“一等公民”、将图结构实现为定长记录的存储方案,赋予了 Neo4j作为原生图数据库的“无索引邻接”特性.
3.2.2 gStore
gStore将RDF数据图中每个资源的所有属性和属性值映射到一个二进制位串上.具体而言,对于每个属性或属性值,gStore都定义一个固定长度的位串并将位串中所有位置为 0.然后,利用若干个预先定义的字符串哈希函数将属性或属性值按照标识符映射到若干个小于位串长度的整数值,进而将位串上这些值所对应的位置置为1.图14给出了图2所示James_Cameron在gStore中所对应编码的示例,每个属性都对应一个8位的位串,每个属性值都对应一个12位的位串.每个属性都按照其标识符由2个字符串哈希函数映射到2个小于8的正整数.例如,type通过2个哈希函数分别被映射到3和8,然后ntype对应的位串第3位和第8位就被置为1.同理,每个属性值都按照其标识符由3个字符串哈希函数映射到3个小于12的正整数.如Director通过3个哈希函数分别被映射到3、8和10,然后Director所对应的位串相应位置就被置为1.
gStore将所有位串按照RDF图结构组织成一棵签章树(signature tree).在签章树的基础上,如果RDF知识图谱中两个实体之间有一条边,那么这两个实体所对应的签章树上的点也连上一条边,且这条边被赋上属性的编码.如此,gStore中所有实体的编码就被组织成一种新的树形索引——VS*树.VS*树被分为若干层,每一层都是RDF数据图的摘要.图15显示了一个VS*树的示例.基于VS*树,gStore可以完成高效率的数据存储、更新与查询操作.当进行SPARQL查询处理时,将每个查询中的变量在这个VS*树上进行检索,找到相应的候选解,然后再将这些候选解通过连接操作拼接起来.
3.3 知识图谱存储方案比较
表4给出了本节前面介绍的8种知识图谱存储方案的比较.
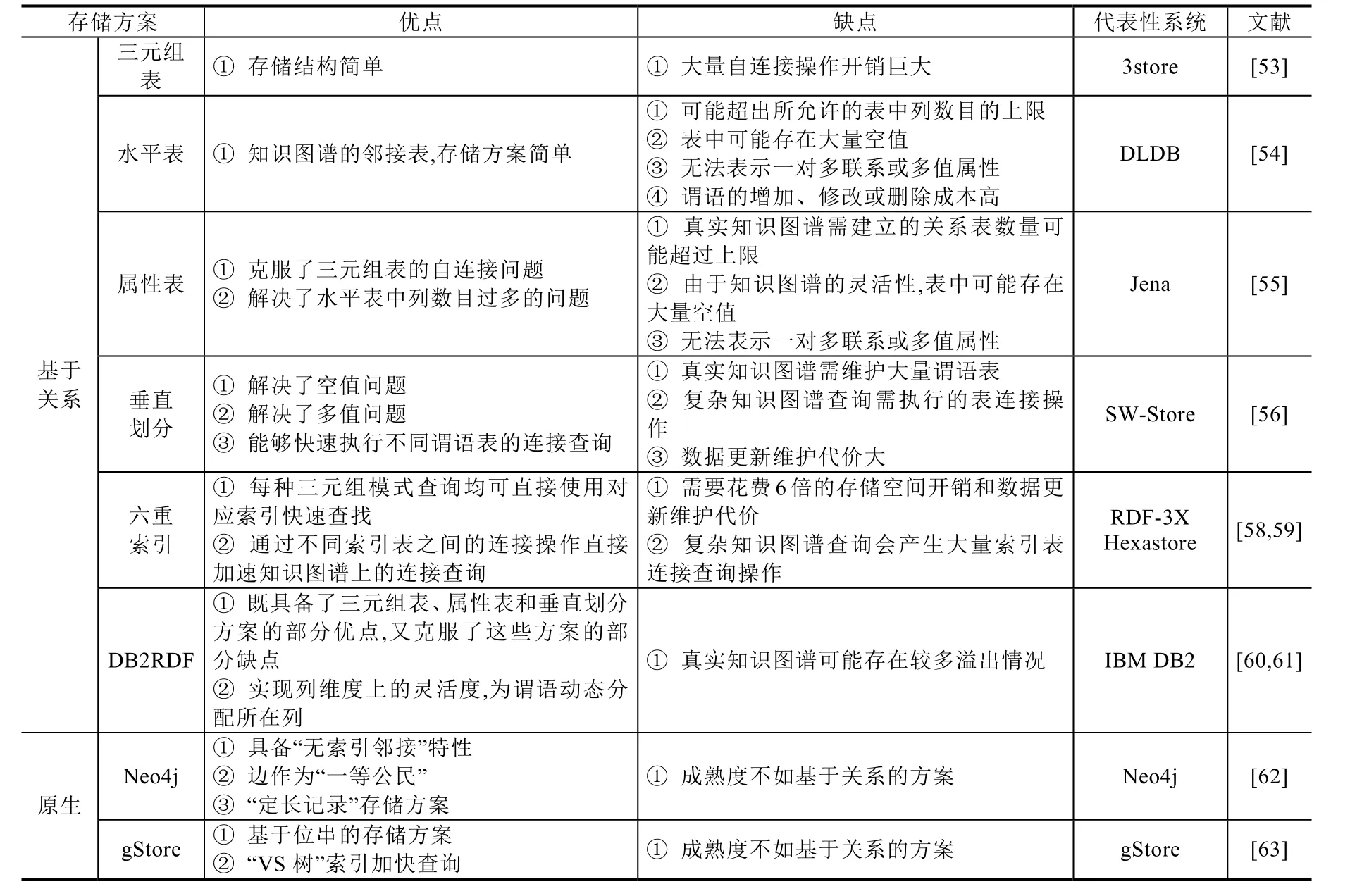
Table 4 The comparison of knowledge graph storage schemes表4 知识图谱存储方案的比较
4 知识图谱查询操作
虽然第 2节中介绍的各种知识图谱查询语言在语法和语义上有所差异,甚至风格迥然,但这些查询语言均具备两种基本的查询机制:图模式匹配(graph pattern matching)和图导航(graph navigation).此外,知识图谱的分析型查询是目前若干图处理框架的内置操作.
4.1 图模式匹配查询
图模式匹配查询是图查询语言中最基本、最重要的一类图查询操作;基本图模式(basic graph pattern,简称BGP)匹配又是图模式匹配查询的核心.下面给出基本图模式的定义,这里仅考虑RDF图和属性图的公共图结构部分,即知识图谱G=(V,E).
定义4(基本图模式(BGP)).给定知识图谱G,其上的基本图模式Q被定义为
其中,(1)si、pi和oi是常量或变量(1≤i≤m);(2) (si,pi,oi)是三元组模式(1≤i≤m);(3) ˄表示逻辑合取.
BGP实际上就是图上三元组模式的合取,因此也称为合取查询(conjunctive query).BGP匹配查询存在两种语义定义,即子图同态(subgraph homomorphism)和子图同构(subgraph isomorphism).
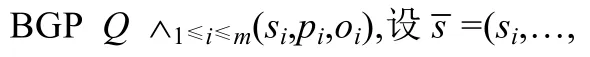
定义5给出的是BGP匹配的子图同态语义,Q中的不同变量可以映射到G中的同一顶点.另外,还有要求更为严格的子图同构语义.现将这两种语义归纳如下.
(1) 子图同态语义.该语义即是定义5对应的语义,找出G中与Q存在同构关系的全部子图,允许Q中多个不同变量映射到G中的同一个顶点上.BGP子图同态语义是定义其他更严格语义的基础,在数据库理论领域已有若干研究工作[64-68].目前,SPARQL语言中的 BGP采用的即为子图同态语义[36].例如,在例 5中,如果去掉FILTER (?x1 !=?x2),会新增两条匹配,即?x1和?x2都映射到顶点Leonardo_DiCaprio和Kate_Winslet.
(2) 子图同构语义.该语义在子图同态语义上增加限制,目的是使得G中的映射保持Q的结构.按照不同的严格程度,子图同构语义又分为全无重复语义(no-repeated-anything semantics)、顶点无重复语义(no-repeatedvertex semantics)和边无重复语义(no-repeated-edge semantics).
a) 全无重复语义.该语义是在定义5子图同构语义基础上加上σ是单射(injective)映射的限制,即BGPQ中的全部变量都映射到知识图谱的不同顶点或边上.虽然 SPARQL默认采用子图同态语义,但在例5中使用额外的条件FILTER (?x1 !=?x2)获得子图同构全无重复语义.
b) 顶点无重复语义.该语义只限制σ(si)和σ(oi)为单射映射,即BGPQ中的不同顶点变量映射到知识图谱的不同顶点上,允许不同边变量映射到知识图谱的相同边上.
c) 边无重复语义.该语义需要将定义5中的σ对顶点和边的映射加以区别对待,对于pi重新定义σ(pi)为单射映射,即BGPQ中的不同边变量映射到知识图谱的不同边上,允许不同顶点变量映射到知识图谱的相同顶点上.目前,Cypher语言采用该语义[29].
同态和同构语义的区别是考察一个匹配之内是否允许顶点或边的重复匹配,还需要考虑另一个维度上的语义区别,即知识图谱G的所有匹配结果Q(G)中是否允许重复.
(1) 集合语义(set semantics).Q(G)定义为匹配的集合,即Q(G)中不能包含重复的匹配.
(2) 包语义(bag semantics).Q(G)定义为匹配的包,即一个匹配重复出现的次数等于与该匹配对应的不同映射的数量.
实际上,单就BGP本身来讲,不会出现重复的匹配,集合和包语义是等价的.但当BGP扩展为复杂图模式后,重复匹配就会出现.下面讨论复杂图模式.
从关系数据管理角度来看,BGP对应于自然连接.在BGP的基础上扩展投影、过滤(选择)、连接、交、差和可选(左外连接)等其他关系操作,形成复杂图模式(complex graph pattern,简称CGP).
(1) 投影(projection).Q(G)返回的变量集合及其匹配值称为Q的输出变量.BGP默认输出变量为Q中所有变量.投影操作返回BGP中变量的指定子集作为输出变量.相当于关系代数中的投影操作.
(2) 过滤(filter).指定变量参与的条件表达式,过滤CGP匹配结果数量.相当于关系代数中的选择操作.
(3) 连接(join).CGPQ1和Q2通过连接操作组成更复杂的CGPQ3,Q3的输出变量是Q1和Q2输出变量的并集,Q3的匹配结果通过连接Q1和Q2的匹配结果获得,即当Q1和Q2输出变量的交集映射到相同常量时,Q1和Q2的匹配结果能够进行连接.相当于关系代数中的连接操作.
(4) 并(union)和差(difference).CGPQ1和Q2的并(差)构成CGPQ3,Q3的匹配结果是Q1和Q2的匹配结果的并(差)集.相当于关系代数中的并和差操作.
(5) 可选(optional).CGPQ1和Q2的可选操作构成CGPQ3,Q3的匹配结果中不仅包括Q1和Q2的连接结果,而且包括Q1中与Q2连接不上的结果,即Q3中包括Q1的全部结果.相当于关系代数中的左外连接操作.
已经证明BGP求值在各种语义下均为NP完全问题.文献[69]通过将图同态(graph homomorphism)问题规约到BGP子图同态语义证明了NP难;文献[70]通过将子图同构(subgraph isomorphism)问题规约到BGP子图同构语义证明了 NP难.按照查询语言求值复杂度分析传统[71],虽然 BGP的组合复杂度(combined complexity)是NP完全的,但如果将BGPQ固定,仅将知识图谱G作为输入,其数据复杂度(data complexity)不仅是多项式的,而且还能在对数空间复杂度内完成求值[72].
CGP求值的组合复杂度在SPARQL语言上有大量研究工作.在集合语义下,包含投影、过滤、连接和并操作的SPARQL CGP的组合复杂度仍然是NP完全的;如果CGP还包含差和可选操作,则其相当于关系代数的表达力,组合复杂度升到PSPACE完全[71];差操作(SPARQL中的MINUS关键字)已被证明可用可选、过滤和连接操作模拟,所以没有差操作的CGP仍然是PSPACE完全的[73];甚至仅包含连接和可选操作的CGP也是PSPACE完全的[74].可见,可选操作是造成 CGP高复杂度的根源.对于包语义下的 SPARQL,其求值问题的组合复杂度同样是PSPACE完全的[74].目前,尚缺少关于其他知识图谱查询语言CGP复杂度相关的理论研究工作.
在图模式匹配查询的求值算法方面,数据库领域对于BGP有着较长的研究历史,积累了大量工作.求值的经典方法有基于图遍历的Ullmann[70]、Nauty[75]和VF2[76],但这些方法的执行效率并不适用于大规模图数据.一般地,大规模图上BGP求值的策略有如下3种:(1) 采用基于相似度的不精确匹配(inexact matching)语义代替子图同态或同构语义,典型方法包括文献[77-79];(2) 采用近似解(approximate solutions)代替最优解(optimal solutions),典型方法包括文献[80-82];(3) 保持子图同态或同构的精确语义不变,基于“空间换时间”策略构建形式多样的图索引,采用索引削减子图匹配搜索空间,将该类方法按时间顺序列出,主要包括:GraphGrep[83]、gIndex[84]、Closure-tree[85]、FG-Index[86]、Tree+Delta[87]、TreePi[88]、GDI[89]、GCoding[90]、QuickSI[91]、GraphQL[92]、GADDI[93]、SPath[94]、SING[95]、GraphGrepSX[96]、Lindex[97]、PathIndex[98]和 SQBC[99].
策略(1)舍弃了精确子图匹配,策略(2)不能找到最优解,均无法满足知识图谱上对精确查询的需求.策略(3)虽然保持了查询语义,但现有方法存在 3个方面的问题:(1) 大多数方法针对由若干小图组成的图集合,每个图的顶点和边数为几十到几百,集合中小图的数量为几千到几万(如实验中普遍使用的AIDS数据集),这与知识图谱具有百万规模节点和上亿规模边的情形大不相同;(2) 即使是针对单个大图提出的 GraphQL、GADDI和SPath方法,其能够处理的数据规模仍无法满足知识图谱大图数据的要求(如文献[93]中规模最大的实验数据顶点和边数分别为6 410和53 844,文献[92,94]中使用的实验数据顶点和边数分别为3 112和12 519);(3) 构建索引的时间和空间复杂度均为超线性的(如最坏情况下SPath方法构建索引的时间和空间复杂度分别为O(nm)和O(n2),n和m分别为顶点和边数),使用这些方法对知识图谱构建索引并不现实.值得注意的是,Fan等人近年来提出了一系列 BGP查询新方法[100-103].这些方法的核心思想是使用比子图同态或同构约束更弱的图模拟(graph simulation)和有界模拟(bounded simulation)语义定义BGP求值,从而使所提算法的时间复杂度降为立方级.实际上,该类方法改变了精确BGP语义且没有使用任何索引结构,所以仍可归类为策略(1).
面向RDF图的图模式匹配查询方法集中于策略(3).(1) 以RDF-3X[58]和Hexastore[59]为代表的六重索引方法会创建 6种不同排列的三元组索引.其问题在于,需将图模式匹配拆分为较多的连接操作,大量中间结果的连接影响性能.(2) 以GRIN[104]和DOGMA[105]为代表的结构索引方法以结构相似度作为度量指标,将RDF图进行划分并建立结构索引,之后在结构索引而非原始 RDF图上执行图模式匹配,但索引维护代价较高.(3) 以BitMat[106]和 TirpleBit[107]为代表的位图存储方法虽然节省了存储空间,但数据更新维护代价较大,且进行查询优化的自由度在一定程度上受到了制约.(4) 以 gStore[63]和 chameleon-db[108]为代表的图索引与匹配方法,将SPARQL BGP查询分为过滤和匹配两个步骤,过滤基于图索引,匹配采用子图同构算法,避免使用连接操作.
4.2 导航式查询
在图模式匹配查询中,匹配结果是知识图谱的子图,其中的路径长度是固定的.知识图谱上另一种重要的查询方式是导航式查询,其匹配的路径结果不能事先确定,需要按照图的拓扑结构进行导航.例如,第3节中例5查询“具有有限多步合作距离”的两名演员,例 7查询“San Zhang直接和间接认识的人”,例9查询“演员Leonardo DiCaprio与距其有限多步合作距离演员之间的全部路径”等均为导航式查询.
最简单的导航式查询是判断两个顶点之间是否存在一条路径,即可达性查询(reachability query).已有大量研究工作求解可达性查询,相关综述请参见文献[109].在实际应用中,往往进一步要求结果路径满足某种约束,其中最常用的是正则路径查询(regular path query,简称RPQ).
定义2(正则路径查询(RPQ)).给定知识图谱G=(V,E),其边上标签集合为∑;在G中从顶点v0到vm的路径ρ为序列v0a0v1a1v2…vm-1am-1vm,其中,vi∈V,ai∈∑,(vi,ai,vi+1)∈E.路径ρ的标签为字符串λρ=a0...am-1∈∑*.G上的 RPQQ被定义为
其中,(1)x和y是常量或变量;(2)r是∑上的正则表达式,其递归定义为r::=ε|a|r/r|r|r|r*,a∈∑,/、|和*分别是串连接、并和克林闭包运算.
定义 7(RPQ的任意路径语义).给定知识图谱G=(V,E)和其上的RPQQ(x,r,y),Q的任意路径语义定义为:Q(G)是G中所有标签满足正则表达式r的路径集合,即Q(G)={ρ|λ(ρ)∈L(r)}.
由于知识图谱G中可以有环,Q(G)中的匹配路径集合可能是无穷的,这种情况下,RPQ的任意路径语义是不可计算的.在实际应用中,需要对该语义做出限制,使RPQ求值是可实现的.
(1) 任意路径语义(arbitrary path semantics).该语义即定义7给出的Q(G)返回全部满足正则表达式r的路径.当然,在该语义下,Q(G)可能包含无穷多条路径;即使是有限多条路径(没有环),枚举所有路径也是不可行的(复杂度已被证明是#P完全[42]).但基于该语义定义的“存在式”语义只关注两个顶点对之间是否存在一条满足条件的路径,即Q(G)={(x,y)|存在从x到y的路径ρ使得λ(ρ)∈L(r)},避免了引起高复杂度的“数路径”问题[42,43],在实际实现中是可行的.例如,SPARQL属性路径采取“存在式”语义[36].
(2) 最短路径语义(shortest path semantics).在该语义下,Q(G)返回满足正则表达式r的最短路径(或长度相等的若干最短路径).例如,G-CORE中的正则路径查询采取的是该语义[30].
(3) 无重复顶点语义(no-repeated-node semantics).在该语义下,Q(G)返回满足正则表达式r的路径且每条路径中无重复出现的顶点(每个顶点仅出现 1次).无重复顶点的路径称为简单路径(simple path).在一些实际场景中需要该语义,例如,在规划游览路线时,一般不希望访问一个地点多于1次.但该语义的求值复杂度早已被证明是NP完全的[110].
(4) 无重复边语义(no-repeated-edge semantics).在该语义下,Q(G)返回满足正则表达式r的路径且每条路径中无重复出现的边(每条边仅出现1次).这时,前面的例子变为允许访问一个地点多于1次,但是不能走重复的路线.目前,Cypher语言采用这种语义[29].
根据不同需求,RPQ的输出可以分为以下几种情况.
(1) 布尔值.判断在Q(G)中两个给定顶点之间是否存在一条满足正则表达式r的路径;(2) 顶点.返回Q(G)中路径的起点和终点对集合;(3) 路径.返回Q(G)中的一条、多条或全部路径;(4) 图.将Q(G)中的全部或部分路径整合为G的子图返回.
集合语义和包语义.对于 RPQ输出为顶点的情况,集合语义与包语义不同.在集合语义下,顶点对(u,v)仅输出1次,无论Q(G)中有多少条u到v的路径.在包语义下,顶点对(u,v)返回的次数等于Q(G)中u到v的路径条数.基于前面的讨论,包语义与任意路径语义的结合实际上也是不可行的,因为包语义蕴含了“数路径”,其复杂度已被证明是#P完全的[42].
RPQ与BGP可结合在一起形成CRPQ(conjunctive RPQ),其定义是BGP的扩展,即允许BGP中的边是RPQ.关于CRPQ的理论研究请参见文献[67,111,112].文献[113]已证明CRPQ的组合复杂度是NP完全的.实际上,由第2节已经看出,CRPQ是一般知识图谱语言的核心.在一些情况下,需要在查询中指定路径之间的某些关系(如比较路径标签是否相同),为此,文献[113]还提出了 ECRPQ(extended CRPQ)作为 CRPQ 的扩展,并且证明了ECRPQ的组合复杂度是PSPACE完全的.在RPQ基础上扩展的表达力更丰富的其他导航式查询形式包括:嵌套正则表达式NRE(nested regular expression)[114]、正则数据路径查询RDPQ(regular data path query)[115]和Datalog扩展[68].
RPQ的求值理论上可看作正则表达式r对应的自动机与知识图谱G对应的自动机的相乘操作,其复杂度为 PTIME[110].Koschmieder等人[116]提出使用“罕见标签(rare-label)”方法对 RPQ进行分解,然后进行分段求值.该方法实际上采取了分治策略,但需要通过预处理事先确定“罕见标签”,查询处理采用了导航式遍历方法.Fan等人[117]在基于模拟语义的子图匹配查询基础上引入了RPQ查询的一个子集,该工作对所提查询模型进行了完善的理论分析,并给出了相应的执行算法,其复杂度为立方级.Gubichev等人[118]基于RDF-3X中的FERRARI索引在可达性查询的基础上扩展实现了 RPQ查询处理.Dey等人[119]基于关系数据库实现了具有起源保障(provenance-aware)的RPQ查询.Wang等人[120]提出了大规模RDF图上的高效率起源保障RPQ求值算法.
4.3 分析型查询
不同于图模式匹配和导航式查询,分析型查询并不关心满足条件的图结构局部实例,而是面向于度量整个知识图谱的全局聚合信息.简单的分析型查询包括求知识图谱统计聚合信息(如顶点和边计数)、顶点的度、图中的最大/最小/平均度、图的直径等.较复杂的分析型查询主要是图上计算密集型的一些分析和挖掘算法,包括:
(1) 特征路径长度(characteristic path length).图中所有顶点对之间最短路径长度的平均值.刻画一个图中顶点之间的关联程度.
(2) 连通分量(connected components).返回图中所有顶点子集,这些集合中的顶点能够通过边相互达到.
(3) 社区发现(community detection).返回图中所有顶点子集,这些集合中的顶点以某种定义在同一社区中.
(4) 聚集系数(clustering coefficient).顶点的聚集系数是该顶点的邻居顶点相互连接的概率.图的聚集系数是图中所有顶点的平均聚集系数.
(5) PageRank.刻画了一个Web浏览者的随机游走行为.顶点的PageRank值表示Web浏览者访问到该顶点的概率.PageRank可作为图中顶点相对重要程度的度量指标.
有关图数据上分析与挖掘算法的详细介绍请参见文献[121].对于大规模知识图谱,分析型查询往往计算量巨大,需要使用分布式图处理框架实现并行计算,详见第5.3节.
4.4 知识图谱查询语言比较
表 5给出了 5种知识图谱查询语言的语法、语义及相关特性的详细比较信息,包括:图模式匹配查询和导航式查询的语法和语义、分析型查询的支持程度、查询可组合性、数据更新语言DML和数据定义语言DDL的支持程度以及实现系统等.关于SPARQL、Cypher和Gremlin的比较可进一步参见文献[9];关于Cypher、PGQL和G-CORE的比较可进一步参见文献[122].
5 知识图谱数据库管理系统
本节首先给出目前主要知识图谱数据库管理系统的简要介绍,包括:RDF三元组库和原生图数据库;然后,综述分布式图数据处理系统与框架;最后,介绍图数据管理系统的评测基准.
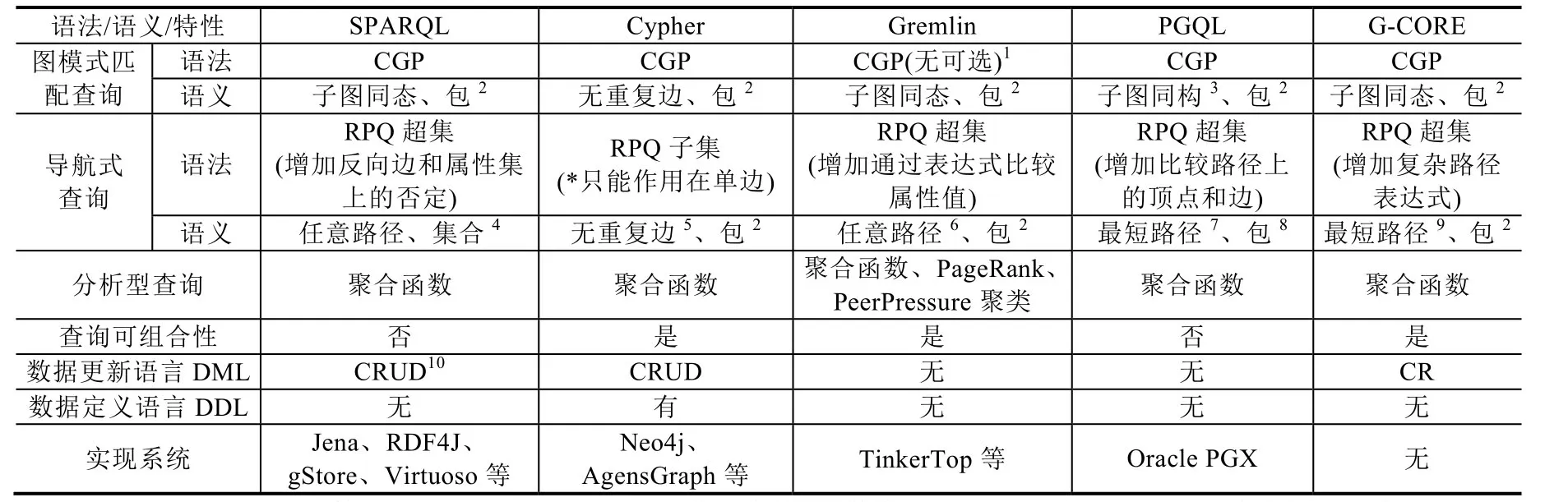
Table 5 The comparison of knowledge graph query languages表5 知识图谱查询语言比较
5.1 RDF三元组库
主要的开源RDF三元组数据库包括:Apache Jena、Eclipse RDF4J以及学术界的RDF-3X和gStore;主要的商业RDF三元组数据库包括:Virtuoso、AllegroGraph、GraphDB、BlazeGraph和Stardog[123].
1. 开源RDF三元组数据库:Jena
Jena[55]是Apache顶级项目,其前身为惠普实验室开发的Jena工具包.Jena是语义Web领域主要的开源框架和RDF三元组库,较好地遵循了W3C标准,其功能包括:RDF数据管理、RDFS和OWL本体管理、SPARQL查询处理等.Jena具备一套原生存储引擎,可对 RDF三元组进行基于磁盘或内存的存储管理.同时,具有一套基于规则的推理引擎,用以执行RDFS和OWL本体推理任务.
2. 开源RDF三元组数据库:RDF4J
RDF4J[124]目前是Eclipse基金会旗下的开源孵化项目,其前身是荷兰软件公司Aduna开发的Sesame框架,功能包括:RDF数据的解析、存储、推理和查询等.RDF4J提供内存和磁盘两种RDF存储机制,支持SPARQL 1.1查询和更新语言.
3. 开源RDF三元组数据库:RDF-3X
RDF-3X是由德国马克斯-普朗克计算机科学研究所研发的 RDF三元组数据库系统,其最初成果发表于2008年的数据库国际会议VLDB[58],后经功能扩展和完善,最新版本是GH-RDF3X,源代码可以从GitHub上下载https://github.com/gh-rdf3x/gh-rdf3x.RDF-3X的最大特点在于其为RDF数据专门设计的压缩物理存储方案、查询处理和查询优化技术.
4. 开源RDF三元组数据库:gStore
gStore[63]是由北京大学、加拿大滑铁卢大学和香港科技大学联合研究项目开发的基于图的RDF三元组数据库.gStore的存储层使用RDF图对应的签章图(signature graph)并建立“VS*树”索引以加速查找.将RDF图G中的每个实体顶点及其邻居属性和属性值编码成一个二进制位串,由这些位串作为顶点组成一张与RDF图G对应的签章图G*;在执行SPARQL查询时,将查询图Q也转化为一张查询的签章图Q*.为了支持在G*上快速查找到Q*的匹配位置,gStore系统建立了“VS*树”索引,其基本思想是为签章图G*建立不同详细程度的摘要图(summary graph);利用“VS*”树索引提供的摘要图,gStore系统可以大幅度缩小SPARQL查询的搜索空间.
5. 商业RDF三元组数据库:Virtuoso
Virtuoso[125]是OpenLink公司开发的商业混合数据库产品,支持关系数据、对象-关系数据、RDF数据、XML数据和文本数据的统一管理,其同时发布商业版本Virtuoso Universal Server(Virtuoso统一服务器)和开源版本OpenLink Virtuoso.Virtuoso虽然是可以支持多种数据模型的混合数据库管理系统,但其基础源自开发了多年的传统关系型数据库管理系统,因此具备较为完善的事务管理、并发控制和完整性机制.因为Virtuoso可以较为完善地支持W3C的Linked Data系列协议,包括DBpedia在内的很多开放RDF知识图谱选择其作为后台存储系统.
6. 商业RDF三元组数据库:AllegroGraph
AllegroGraph[126]是Franz公司开发的RDF三元组数据库.AllegroGraph对语义推理功能具有较为完善的支持.除了三元组数据库的基本功能外,AllegroGraph还支持动态物化的 RDFS++推理机、OWL2 RL推理机、Prolog规则推理系统、时空推理机制、社会网络分析库、可视化RDF图浏览器等.
7. 商业RDF三元组数据库:GraphDB
GraphDB[127]是由Ontotext软件公司开发的RDF三元组数据库.GraphDB实现了RDF4J框架的SAIL层,可以使用RDF4J的RDF模型、解析器和查询引擎直接访问GraphDB.GraphDB的特色是对于RDF推理功能的良好支持,其使用内置的基于规则的“前向链(forward-chaining)”推理机,由显式(explicit)知识经过推理得到导出(inferred)知识,对这些导出知识进行优化存储;导出知识会在知识库更新后相应地同步更新.
8. 商业RDF三元组数据库:BlazeGraph
Blazegraph[128]是一个基于RDF三元组库的图数据库管理系统,在用户接口层同时支持RDF三元组和属性图模型,既实现了 SPARQL语言也实现了 Blueprints标准及 Gremlin语言.Blazegraph的内部实现技术是面向RDF三元组和SPARQL的,是“基于RDF三元组库的图数据库”.
9. 商业RDF三元组数据库:Stardog
Stardog[129]是由Stardog Union公司开发的RDF三元组数据库,其支持RDF图数据模型、SPARQL查询语言、属性图模型、Gremlin图遍历语言、OWL2标准、用户自定义的推理与数据分析规则、虚拟图、地理空间查询以及多用编程语言与网络接口支持.Stardog对 OWL2推理机制具有良好的支持,同时具备全文搜索、GraphQL查询、路径查询、融合机器学习任务等功能,能够支持多种不同编程语言和Web访问接口.
5.2 原生图数据库
目前主要的原生图数据库有Neo4j、JanusGraph、OrientDB和Cayley.
1. 最流行的图数据库:Neo4j
Neo4j[29]是由Neo技术公司开发的图数据库.可以说,Neo4j是目前流行程度最高的图数据库产品.Neo4j基于属性图模型,其存储管理层为属性图的节点、节点属性、边、边属性等元素设计了专门的存储方案.这使得Neo4j在存储层对于图数据的存取效率优于关系数据库.
2. 分布式图数据库:JanusGraph
JanusGraph[130]是在原有 Titan系统[131]基础上继续开发的开源分布式图数据库.JanusGraph的存储后端与查询引擎是分离的,可使用分布式Bigtable存储库Cassandra或HBase作为存储后端.JanusGraph借助第三方分布式索引库ElasticSearch、Solr和Lucene实现各类型数据的快速检索功能,包括地理信息数据、数值数据和全文搜索.JanusGraph还具备基于MapReduce的图分析引擎,可将Gremlin导航查询转化为MapReduce任务.
3. 图数据库:OrientDB
OrientDB[132]最初是由OrientDB公司开发的多模型数据库管理系统.OrientDB虽然支持图、文档、键值、对象、关系等多种数据模型,但其底层实现主要面向图和文档数据存储管理的需求设计.其存储层中数据记录之间的联系并不是像关系数据库那样通过主外键的引用,而是通过记录之前直接的物理指针.OrientDB对于数据模式的支持相对灵活,可以管理无模式数据(schema-less),也可以像关系数据库那样定义完整的模式(schema-full),还可以适应介于两者之间的混合模式(schema-mixed)数据.在查询语言方面,OrientDB支持扩展的SQL和Gremlin用于图上的导航式查询;OrientDB的MATCH语句实现了声明式的模式匹配,这类似于Cypher语言查询模式.
4. 图数据库:Cayley
Cayley[133]是由Google公司工程师开发的一款轻量级开源图数据库.Cayley的开发受到了Freebase知识图谱和 Google知识图谱背后的图数据存储的影响.Cayley使用 Go语言开发,可以作为 Go类库使用;对外提供REST API;具有内置的查询编辑器和可视化界面;支持多种查询语言,包括:基于Gremlin的Gizmo、GraphQL和MQL;支持多种存储后端,包括:键值数据库 Bolt、LevelDB,NoSQL数据库 MongoDB、CouchDB、PouchDB、ElasticSearch,关系数据库PostgreSQL、MySQL等.
其他原生图数据库还包括:构造在 Amazon云平台上的 Amazon Neptune[134]、多模型图数据库 Arango DB[135]、微软的 Azure CosmosDB[136]、DataStax的 Enterprise Graph[137]、Sparsity 的 Sparksee[138]以及TigerGraph[139]等.
5.3 分布式图数据处理系统与框架
在大数据时代,分布式/并行技术已成为大规模知识图谱数据管理不可或缺的工具.目前,规模为百万顶点(106)和上亿条边(108)的知识图谱数据集已不在少数[140].截至2019年1月LOD(linked open data,链接开放数据)知识图谱发布的RDF图数据集共计1 234个,其总规模目前虽没有准确的统计数据,但保守估计达上千亿条三元组[141].LOD中很多单个数据集的规模已超过10亿条三元组,例如,维基百科数据集DBpedia 2014为30亿条[142]、蛋白质数据集UniProt为90.2亿条[143]、地理信息数据集LinkedGeoData为200亿条[144].
近年来提出的面向大规模图数据的分布式系统与框架包括:基于分布式文件系统(如 GFS[145])或基于Bigtable模型[146]的图数据存储层和基于MapReduce[147]、Pregel[148]及GraphLab框架[149]的图数据处理层.现有分布式/并行图数据管理系统大多基于这些框架进行扩展,其中包括:(1) 基于 MapReduce的系统:YARS2[150]、SPIDER[151]、SHARD[152];(2) 基于 Bigtable的系统:Titan[131]、CumulusRDF[153];(3) 基于服务总线的系统:Blazegraph[128];(4) 基于内存存储的系统:Trinity[154]、Trinity.RDF[155].
大规模RDF图上的分布式查询处理方法引入了图分割和查询分解策略.文献[156]将RDF图划分为若干分片,每个分片的边界节点扩展到“n跳(n-hop)”邻居,同时将 SPARQL查询划分为若干子查询进行并行求值.文献[157]将顶点及其邻居定义为“顶点块”,采用启发式规则对顶点块进行分布式存储,同时将查询进行分解,达到增大并行度且减少通信开销的目的.文献[158]提出的 EAGRE方法基于边上的谓语信息对图和查询进行分解.文献[159]提出的TriAD方法采用METIS方法将RDF图分割为若干片段,每个片段在多个机器上存储,同时维护一个包含划分信息的摘要图,通过MPI框架的异步消息传递进行系统通信.文献[160]提出的DREAM系统只对查询进行分解并不分解RDF图,能够根据分解后子查询的复杂度自适应地分配执行查询所需的机器数量.
在分布式图查询处理上,基于部分求值(partial evaluation)技术[161]已提出了一系列有效方法.最近,Fan等人利用部分求值提出了图数据的可达性查询分布式版本[162];Ma和Fan等人利用部分求值提出了基于模拟语义的子图匹配的分布式版本[163,164];Peng等人利用部分求值提出了SPARQL查询的分布式版本[165];Wang等人提出了基于部分求值的RDF图上RPQ分布式算法[166].
此外,目前已有若干基于现有分布式计算框架的知识图谱查询处理工作.文献[167]展示的 H2RDF+系统基于 HBase分布式 Bigtable存储库构建了三元组的六重索引.文献[168]给出的 Sempala是基于分布式 SQL-on-Hadoop数据库Impala和Parquet分布式文件格式的RDF图数据查询引擎.Lai等人提出了基于TwinTwig结构分解的MapReduce分布式高效子图枚举算法,但该算法仅用于无向无标签图[169,170].Bi等人进一步给出了通过尽可能推迟笛卡尔积执行来提高子图匹配效率的技术[171].Schätzle等人提出的S2RDF系统将SPARQL查询转换为Spark分布式计算框架上的RDD操作,其离线建立了大量索引,用于加速在线查询,但对于大规模知识图谱,索引构建时间开销可能很高[172].文献[173]利用 RDF图的语义和结构作为启发信息将查询图进行星形分解,设计了一种基于MapReduce的分布式SPARQL BGP匹配算法.He等人提出的Stylus是一种利用强类型信息构建优化存储方案和查询处理的分布式RDF图存储库,其底层基于键值库[174].Peng等人在文献[175]中给出了一种能够根据查询负载优化图划分和存储的RDF图存储方案.Xin等人给出了基于Pregel图计算框架的起源保障RPQ分布式求值算法[176].开源项目Apache Rya是基于分布式列存储系统Accumulo开发的RDF三元组库[177].开源项目Cypher for Apache Spark[178]是Neo4j公司开发的用于将Cypher查询转换为Spark并行操作的模块.关于基于Pregel的分布式图处理框架的最新研究进展可参见文献[19].
5.4 知识图谱数据库管理系统比较
表6比较了常见的25种知识图谱数据库管理系统,包括许可证、数据模型、存储方案、查询语言、特点描述、最新版本和是否活跃.

Table 6 The comparison of knowledge graph database management systems表6 常见知识图谱数据库管理系统的比较
表6不仅包括本节介绍的RDF三元组库、原生图数据库和分布式图数据处理系统与框架,还纳入了第3.1节中介绍的基于关系的知识图谱存储方案的代表性系统.
5.5 评测基准
评测基准(benchmark)是客观评价数据库管理系统性能的标准工具.关系数据库有著名的TPC评测基准.知识图谱数据库管理系统的评测基准仍处于发展完善阶段.目前,链接数据评测基准委员会(Linked Data Benchmark Council,简称LDBC)是知识图谱数据管理系统评测基准开发的主要组织,其成员包括了主要的图数据库公司和研究机构[179].LDBC目前开发了两个评测基准:社会网络评测基准(social network benchmark,简称SNB)和语义出版评测基准(semantic publishing benchmark,简称SPB).SNB设计用于评测知识图谱数据库管理系统的事务查询负载、分析查询负载和图分析算法;SPB设计用于评测查询和更新混合负载并兼具一定的语义推理评测功能.不过,LDBC评测基准中的部分功能尚处于开发阶段.
此外,在LDBC成立之前,学术界已经开发了若干RDF数据库评测基准,包括:LUBM、SP2Bench、BSBM和DBPSB.LUBM[180]是最早的RDF评测基准,不支持SPARQL 1.1新特性,也不支持数据更新,具备一定的推理评测能力;SP2Bench[181]是基于DBLP数据集构建的SPARQL评测基准,不支持更新;BSBM[182]基于电子商务数据模式,是功能相对完善的 SPARQL评测基准,同时包括事务和分析型负载,但是,BSBM 数据集过于规整,以致于基于关系数据库的系统的评测结果均较优.DBPSB[183]使用基于 DBpedia的真实数据集,但其负载过于简单,只包括基本查询,同样不支持更新.WatDiv评测基准[184]的特点是能够支持用户自定义生成测试数据的模式,其查询负载根据数据模式图上的随机游走产生,分为线性查询、星形查询、雪花形查询和复杂查询 4类.Link Bench[185]是基于Facebook社交网络真实数据和负载开发的评测基准,能够模拟Facebook真实生产情景下的社交网络图数据库查询和更新操作,但该评测基准已不再被维护.
表7给出了本节介绍的8种知识图谱数据管理评测基准的比较,包括发布机构、生成数据特点、查询负载特点和活跃程度.
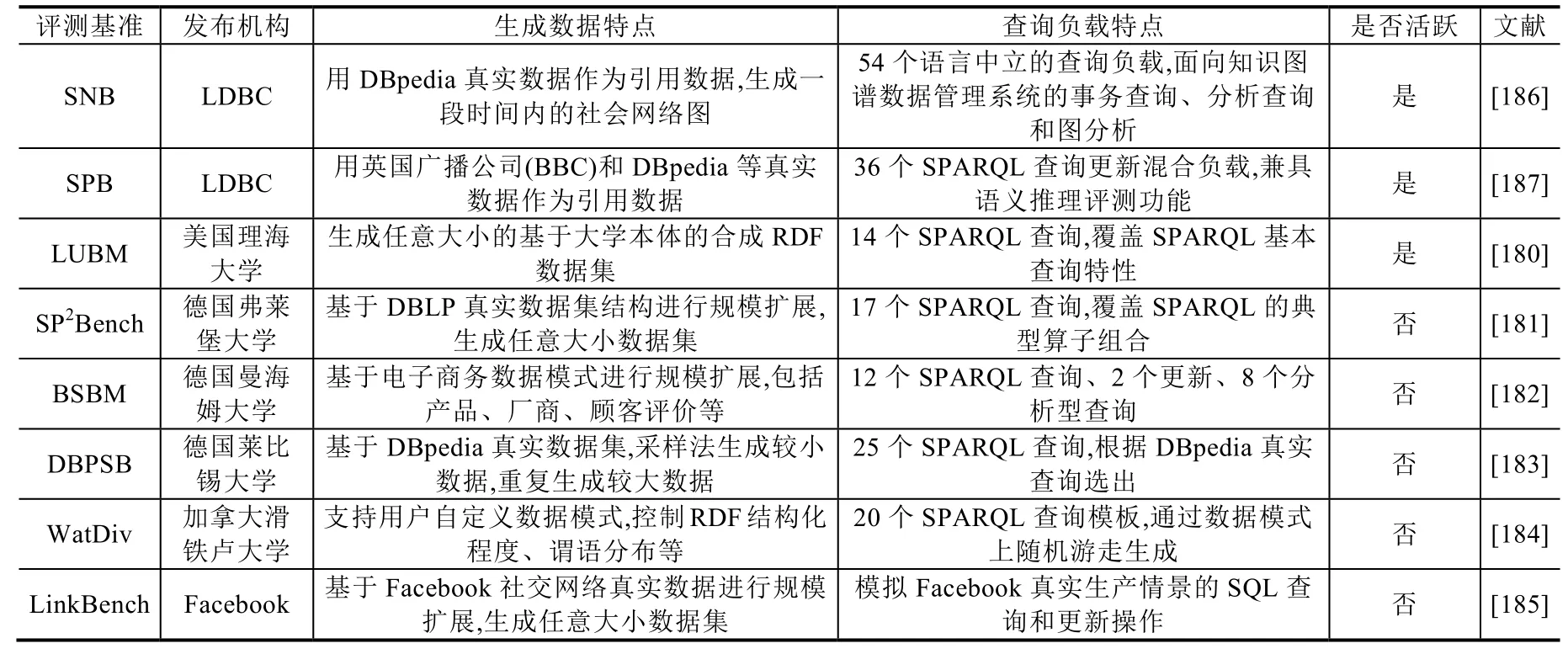
Table 7 The comparison of knowledge graph data management benchmarks表7 知识图谱数据管理评测基准的比较
6 未来研究方向
目前,知识图谱数据管理的理论、方法、技术与系统处于快速发展和开发完善阶段.数据库学术和产业界对知识图谱数据管理研发投入正在不断增加.本节将未来的研究方向归纳如下.
(1) 知识图谱数据模型与查询语言的统一
目前,知识图谱数据模型和查询语言尚不统一.考虑到关系数据库的兴起与发展流行,其中主要因素是具有精确定义的关系数据模型和统一的查询语言 SQL.统一的数据模型和查询语言不仅减轻了数据库管理系统的研发成本,而且降低了用户设计、构建、管理和维护数据库的代价,同时降低了新用户的学习难度.
但是,由于知识图谱的发展原因,其数据模型与查询语言的统一存在着一定难度.其一,RDF图源于语义Web的发展而产生,其在标准制定之初即面向Web上全局资源的表示、发布和集成,其上还基于描述逻辑定义了RDF模式(RDF schema)语言和Web本体语言(OWL),形成了一整套高级语义表示和推理机制;DBpedia、YAGO、WikiData等著名知识图谱实际上均是RDF格式.另一方面,属性图来自于图数据库领域,其顶点和边属性的方便表示机制弥补了RDF图的不足,但目前仍未形成一致公认的严格数学定义,比如,G-CORE语言为了提高路径的地位还定义了路径属性图.当前,亟需定义统一的知识图谱数据模型,既具有 RDF图面向 Web的优点(如使用URI唯一标识资源),又具备属性图上便于数据存储的优势,同时将已有RDF知识图谱数据映射转换为新数据模型格式,作为真实的大规模知识图谱数据集,提升统一数据模型的认可度.其二,统一现有知识图谱查询语言迫在眉睫.第2节列出的主要查询语言就有5种之多,SPARQL面向RDF图,其余4种均面向属性图.知识图谱数据模型统一后,必然需要制定统一的查询语言.目前,openCypher组织已经发出了“GQL宣言”[188],准备将 Cypher、PGQL和 G-CORE融合为属性图标准查询语言 GQL.但是,其中并未考虑 RDF图的SPARQL语言.面向上述统一知识图谱数据模型,研制统一知识图谱查询语言,定义精确语法和语义,是未来的一个重要研究方向.
(2) 大规模知识图谱数据的分布式存储方案
第 3节讨论的知识图谱存储管理方案,无论是基于关系的还是原生的,均是在单机系统上实现的.大规模知识图谱数据的分布式存储的研发目前尚处于起步阶段.知识图谱数据的分布式存储面临的第一个问题是大规模图数据的划分.图划分问题本身是一个经典的NP完全问题.即使使用公认最优的METIS图划分算法,对于大规模图数据在单机上执行划分也几乎是不可行的.所以,首先需要研究面向大规模知识图谱数据的分布式图划分算法,该算法既要考虑按照知识图谱的图结构和知识语义信息作为图划分标准,尽可能地有利于支持知识图谱查询的快速执行,又要避免算法复杂度过高.其次,在知识图谱划分的基础上,提出分布式存储方案.需要考虑:是面向 OLTP和 OLAP设计两种不同存储方案,还是设计可以平衡不同类型查询的统一存储;可选的物理层实现框架包括分布式关系数据库存储层、分布式文件系统、分布式Bigtable系统和分布式键值存储库;扩展单机版的RDF图或属性图存储方案,使其适应分布式物理存储底层是一种可选思路.再次,还需要面向知识图谱查询处理设计不同的索引方案,比如,面向图模式匹配查询的索引、面向导航式路径查询的索引和面向分析型查询的索引.
(3) 大规模知识图谱数据的分布式查询处理
虽然第5.3节介绍了现有的知识图谱分布式查询处理方法、框架与系统,但按照数据库系统的观点,目前还没有形成基于底层存储方案支撑的分布式查询处理完善机制.大部分已有方法均是为了解决某种特定查询问题而设计的专用算法,或者是基于MapReduce、Pregel、MPI等已有分布式处理框架而设计的算法.从分布式数据库管理系统的角度出发,需要形成具备一整套逻辑和物理算子的分布式查询处理高效算法,充分考虑存储和索引结构,同时考虑分布式通信开销,进而形成一套适合知识图谱分布式查询的代价模型.在此基础上,研究知识图谱分布式查询优化方法.
(4) 知识图谱数据管理对于本体和知识推理的支持
知识图谱数据与传统关系数据的一个最大区别是对本体的表示和内在的知识推理能力.例如,在RDF图数据之上,还有 RDF模式(RDFS)和 Web本体语言(OWL)的定义,可用于表示丰富的高级语义知识,同时定义了不同层面的推理功能,即从已有知识推导出隐含知识.目前的知识图谱数据管理还没有充分考虑到对于本体和知识推理的支持.如何在存储层和查询处理层支持知识图谱高层本体的有效管理和高效率的推理功能是非常有意义的研究方向.关于面向知识图谱的知识推理最新研究进展可参见文献[187].
(5) 大规模知识图谱的更新维护
真实的知识图谱数据随时间的推移会发生不断的更新变化.目前的知识图谱数据管理系统有很多假设知识是只读的和单向追加的,对于大规模知识图谱的更新维护基本没有考虑.首先,需要在知识图谱统一查询语言中专门为知识图谱更新设计数据更新子语言;其次,在知识更新过程中,往往会涉及到多版本控制、一致性约束和不一致消解等多种问题.这些问题在知识图谱数据管理系统中如何解决需要深入研究.
(6) 大规模知识图谱的数据集成
对于多个单独维护的知识图谱数据库或者历史遗留的知识图谱存在数据集成需求.目前,Linked Data技术[189]是RDF图上进行数据集成的规范方法,在多个符合Linked Data的RDF图上可以构建SPARQL联邦查询系统,进行跨知识图谱的集成查询.但在新型分布式知识图谱数据管理背景下,仍然存在着若干需要研究的问题,比如,分布式知识图谱数据库的不同集成方式、联邦查询的性能优化和效率提升、面向不一致知识图谱的数据集成等.
7 总 结
本文以数据模型的结构和操作要素为主线,对目前的知识图谱数据管理的理论、方法、技术与系统进行了研究综述:包括两种知识图谱数据模型和 5种知识图谱查询语言;介绍了基于关系的和原生的知识图谱存储管理;讨论了知识图谱上的图模式匹配、导航式和分析型查询操作;介绍了RDF三元组库和原生图数据库这两类知识图谱数据库管理系统,描述了目前面向知识图谱的分布式系统与框架的现状,给出了知识图谱评测基准的情况.最后,展望了知识图谱数据管理的未来研究方向.
猜你喜欢
计算机应用与软件(2022年5期)2022-07-07
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
现代信息科技(2021年21期)2021-05-07
计算机应用与软件(2021年4期)2021-04-15
河北科技大学学报(2020年4期)2020-09-10
计算机应用(2020年7期)2020-08-06
舰船科学技术(2020年2期)2020-04-17
党政干部学刊(2015年7期)2015-12-24
中学生数理化·高一版(2009年6期)2009-08-31
