
一种同步语言多线程代码自动生成工具*
2019-08-13 05:06杨志斌袁胜浩JeanPaulBODEVEIXMamounFILALI
软件学报 2019年7期
杨志斌 , 袁胜浩 , 谢 健 , 周 勇 , 陈 哲 , 薛 垒 , Jean-Paul BODEVEIX, Mamoun FILALI
1(南京航空航天大学 计算机科学与技术学院,江苏 南京 211106)
2(软件新技术与产业化协同创新中心,江苏 南京 210093)
3(上海航天电子技术研究所,上海 201109)
4(IRIT-University of Toulouse, Toulouse 31062, France)
安全关键软件(safety-critical software)[1]是指应用于航空、航天、交通、能源等领域的安全关键系统中,且其运行情况可能引起系统处于危险状态,从而导致财产损失、环境破坏或者人员伤害的一类软件.随着功能需求的发展,能够提供更强计算能力而又能减少电子设备的体积、重量和功耗(size,weight and power,即SWaP特性)的多核处理器将在安全关键领域得到广泛应用.例如,在航空领域,风河公司(WindRiver)提出了支持多核处理器的 Vxworks 653操作系统 V3.0版本[2];而为了满足将来航天应用的复杂需求,欧空局(European Space Agency,简称ESA)开发了基于四核LEON4的下一代微处理器试验板(LEON4-N2X)[3].
近年来,模型驱动(model-driven),尤其是采用形式化模型驱动的安全关键软件设计与开发方法逐渐受到重视,并被工业界认为是切实可行的重要手段.例如,国际民航领域使用的机载系统适航审定中的软件开发标准DO-178C[4]就将模型驱动和形式化方法(即 DO-331[5]和 DO-333[6])作为其核心标准的重要技术补充.模型驱动开发方法将模型作为整个软件开发过程的核心元素,在设计阶段就建立软件模型,并尽早进行验证和分析.同时,模型的重用以及基于模型的自动代码生成,都有助于降低软件开发时间和成本.
安全关键系统,是一类反应式系统(reactive system),它不断地和环境进行交互,即从环境中得到输入,经过计算,然后输出给环境,并重复这一过程.其中环境包括:被系统控制的物理设备、系统的操作人员或其他的反应式系统.同步语言基于同步假设理论(synchronous hypothesis)来表达系统的功能行为.目前,有 ESTEREL[7]、LUSTRE[8]、SCADE[9]、SIGNAL[10]、QUARTZ[11]等同步语言,这些同步语言可以看作是对同步假设理论的不同实现,而且同步语言在安全关键系统领域得到实际应用.例如,空客使用 SCADE对 A350、A380的飞控子系统[12]进行建模和代码生成.ESTEREL、LUSTRE和QUARTZ语言使用perfect synchrony模式(即纯同步模式),即存在一个全局时钟,而SIGNAL语言使用Polychrony模式(即多态同步模式),可能不存在一个全局时钟,可以更加自然地表达分布式系统.现有的SIGNAL编译器Polychrony目前主要支持串行代码生成和仿真分析,较少考虑在多核处理器上的多线程代码生成.
在同步语言多线程代码生成方面[13-15],目前研究主要考虑基于全局异步局部同步(globally asynchronous locally synchronous,简称GALS)的多线程代码生成,即系统由具有不同时钟的多个进程组成,而每个进程是单时钟的.然而,在同步语言模型中,单个进程内部也往往存在潜在的并行执行信息.尤其是可以自然表达分布式系统的SIGNAL语言,其语法的基本结构中包含多时钟操作,可以比较自然地支持在进程内部描述并行执行操作.
本文研究基于 SIGNAL语言表达的单进程程序的多线程代码生成方法,并给出一种基于函数式编程语言OCAML实现的同步语言 SIGNAL多线程代码生成工具.该工具是 SIGNAL串行代码生成工具 Min SIGNAL[16-18]在多线程代码生成方面的扩展.整个生成器分为前端和后端:首先,已有 MinSIGNAL编译器前端对输入的 SIGNAL程序进行用户程序标准化,转换为中间表达式即同步多时钟卫式动作(synchronous clocked guarded actions,简称S-CGA),并进行时钟演算,生成S-CGA中间程序.其次,基于扩展的代码生成器后端输出可执行的多线程C/Java代码.扩展的代码生成器后端延续MinSIGNAL的模块化设计思想,主要包括:构建时钟数据依赖图(clock data dependency graph,简称CDDG),以分析S-CGA程序中变量(全局的时钟变量和数据变量)之间的依赖关系;在使用拓扑排序划分算法分析CDDG的基础上,分别提出拓扑排序优化算法和基于流水线方式的任务划分方法以提高最终目标代码执行速度;基于划分结果生成虚拟多线程代码,进一步生成可执行多线程C/Java程序,并在多核处理器上进行实验.
本文第1节简要介绍SIGNAL语言的基本概念和我们的一些前期研究.第2节给出同步语言多线程代码生成方法的总体研究框架.第 3节介绍同步语言多线程代码生成方法和步骤,包括多线程代码生成器前端、构造时钟数据依赖图、任务划分算法和多线程代码生成.第 4节给出基于 OCAML的工具实现,并基于案例进行可执行多线程代码实验和分析.第5节给出相关工作比较.第6节是本文的总结和展望.
1 研究背景
1.1 同步语言SIGNAL
SIGNAL是由Le Guernic、Benveniste和Gautier等人提出的一种声明式数据流同步语言.基于同步假设理论,SIGNAL语言中定义了一类对象,称为信号(signal),是一种带类型的无限长的值序列.在给定逻辑时刻下,信号可以是“存在”状态并具有对应的数值,或者是“缺失”状态,记为⊥.信号处于存在状态对应逻辑时刻组成的集合构成信号对应的逻辑时钟(简称时钟).在SIGNAL中,两个信号同步当且仅当其逻辑时钟相同.
SIGNAL语言通过数据流等式进行建模,它提供 4类基本的数据流等式结构:(1) 瞬时函数(y:=f(x1,x2,…,xn));(2) 延迟(y:=x1$init c);(3) 条件采样(y:=x1whenx2);(4) 确定性合并(y:=x1defaultx2).
此外,按照时钟关系划分,4类基本结构可以被分为单时钟操作(瞬时函数和延迟)和多时钟操作(条件采样和确定性合并):前者要求所有信号都是同步的,而后者允许信号可以不同步.例如,在确定性合并中,给定逻辑时刻下x1或者x2处于存在状态即可以保证y处于存在状态.
SIGNAL不仅提供基本结构,还提供一些扩展结构以支持显式的时钟操作.例如,时钟同步:x1^=x2;时钟并运算x:=x1^+x2、时钟交运算x:=x1^*x2、时钟补运算x:=x1^-x2;时钟小于运算x1^
进程是SIGNAL的编程单元(programming unit),由输入、输出以及数据流等式组合起来构成.进程包含组合(composition)与局部声明(local declaration).
另外,SIGNAL语言具有多种形式语义,如基于踪迹的指称语义[19,20]、基于标签模型的指称语义[19]以及基于同步变迁系统[21]的操作语义等.在文献[22]中,我们基于定理证明器 Coq[23]证明了 SIGNAL语言的踪迹语义和标签模型语义的等价性.
我们给出一个同步语言SIGNAL示例:Count进程.该进程的第2行、第3行声明输入信号y1,x1和x2;第4行声明输出信号y;第5行、第6行数据流等式属于扩展结构,第7行~第11行数据流等式属于基本结构;第13行是局部声明.我们将此程序贯穿全文用于介绍整个多线程代码生成器的工作过程.

Example 1 Count process in SIGNAL例1 Count进程
1.2 前期研究
在分析SIGNAL语言的已有编译器Polychrony的基础上,我们基于OCAML实现了一种新的SIGNAL串行代码生成工具MinSIGNAL[16-18],其编译步骤如图1所示.
相比Polychrony,MinSIGNAL具有的特征包括:
(1) MinSIGNAL支持的输入为SIGNAL的子集(称为MinSIGNAL),包括SIGNAL语言中的基本结构、扩展结构、组合、局部声明等,不包括Polychrony工具库;
(2) 考虑将来支持多种同步语言的集成,提出了一种新的中间表达式,即同步多时钟卫式动作S-CGA;
(3) 基于Coq完成代码生成器前端SIGNAL到S-CGA之间的语义保持证明.
本文是MinSIGNAL在多线程代码生成方面的扩展,而MinSIGNAL的最终目标是生成一个新的SIGNAL验证编译器(verified compiler),即在定理证明器 Coq中规约并证明编译规则的语义保持,然后从证明中自动抽取编译器的OCAML实现.目前基于OCAML的工具实现是在定理证明器Coq中进行规约的基础,并将和自动生成的验证编译器进行对比分析.
2 MinSIGNAL多线程代码生成研究框架
同步语言SIGNAL多线程代码生成器的总体框架如图2所示.整个生成器包括前端和后端两个部分:编译器前端对输入的SIGNAL程序进行用户程序标准化、转换为S-CGA程序、进行时钟演算等步骤生成S-CGA中间程序.其次,基于扩展的代码生成器后端输出可执行的多线程 C/Java代码.扩展的代码生成器后端延续MinSIGNAL的模块化设计思想,主要包括:
(1) 定义并构建时钟数据依赖图 CDDG,以分析 S-CGA程序中变量(全局的时钟变量和数据变量)之间的依赖关系;
(2) 在使用拓扑排序划分算法分析CDDG的基础上,分别提出拓扑排序优化算法和基于流水线方式的任务划分方法,以提高最终目标代码执行速度;
(3) 基于划分结果生成虚拟多线程代码(平台无关),进一步生成可执行多线程C/Java程序(平台相关).
串行代码生成过程主要由时钟树驱动完成,多线程代码生成过程主要由数据依赖图驱动完成.即在串行代码生成过程中,通过分析时钟树上包含的时钟关系得到串行代码的控制结构,分析数据依赖图中包含的数据依赖关系确定控制结构中语句的执行顺序;在多线程代码生成过程中,还需要定义CDDG以便同时显式地考虑时钟和数据之间的依赖关系.
3 MinSIGNAL多线程代码生成方法和步骤
MinSIGNAL多线程代码生成器由前端和后端两部分组成.首先简要介绍代码生成器前端,即已有 Min SIGNAL串行代码生成器前端及时钟演算.然后,按照编译步骤依次介绍时钟数据依赖图、任务划分和多线程代码生成.
3.1 多线程代码生成器前端
由于此代码生成器前端主要是重用已有的MinSIGNAL串行代码生成器前端(参见文献[16-18]),这里,我们仅简要给出其主要步骤:用户程序标准化、中间语言S-CGA和时钟演算.
(1) 用户程序标准化
如第1.1节和第1.2节所述,MinSIGNAL支持的输入为SIGNAL子集(称为MinSIGNAL),包括SIGNAL语言中的基本结构、扩展结构、组合、局部声明等,不包括Polychrony工具库.所谓用户程序标准化,即代码生成器在对用户程序进行词法和语法分析之后,将用户程序中使用的扩展结构转换为 SIGNAL语言的基本结构.我们称基本结构为kSIGNAL(kernel SIGNAL).kSIGNAL的抽象语法如下所示.
我们在文献[16-18]中给出了用户程序标准化的转换规则.这里,针对例1给出部分转换示例.
对于扩展结构,如时钟同步操作x1^=x2,首先分别定义x1和x2的时钟变量C___1和C___2,然后通过两个时钟变量相等表示时钟同步操作^=.

时钟同步操作 标准化后结果x1^=x2 C___1=x1==x1 C___2=x2==x2 C___3=C___1==C___2
另外,还需对复合的基本结构进行处理,目的是为了降低源程序到中间语言的转换难度.例如,y2:=(y1+1)$ init 2的标准化结构如下.
(2) 中间表达式S-CGA
随着同步语言的发展,学术界已提出多种同步语言,导致集成不同同步语言成为热点研究问题[24,25],因为这不仅可以更深刻地理解不同同步计算模型之间的区别,更重要的是,可以提供或重用统一的验证、仿真和代码生成工具.集成的解决方案主要是给出一种通用的中间表达式.例如,Polychrony中使用HCDG[26]、L2C项目中使用S-Lustre*AST[27,28]、QUARTZ编译器使用CGA[29,30]以及本文使用的S-CGA等中间语言.
定义1(同步多时钟卫式动作(S-CGA)). 在S-CGA中卫式动作的形式为γ⇒A,其中,γ为卫式,A为要执行的动作.其直观语义为,如果卫式γ为真,则执行动作A.γ⇒A主要包括5种形式,见表1.
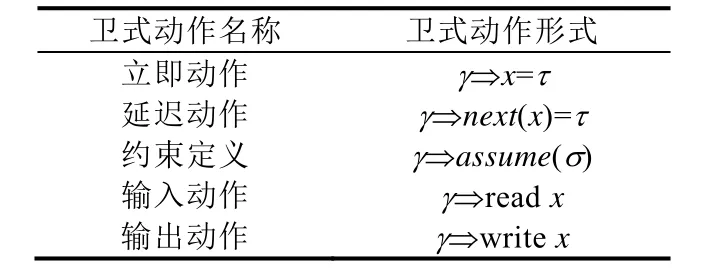
Table 1 Form of guarded actions表1 卫式动作形式
其中,
· 卫式γ是定义在信号变量X(源 SIGNAL中的输入、输出和局部变量)、X的逻辑时钟(x∈X,其时钟为ˆ)及其初始时钟(init(xˆ))之上的布尔条件.
· 动作A包括:立即赋值、延迟赋值、约束定义、输入动作和输出动作.其中,τ是定义在X上的表达式,σ则是定义在X及其逻辑时钟上的布尔表达式.
(1) 立即赋值,给定逻辑时刻t,当γ中所有信号变量都处于存在状态且γ为true、x和τ都处于存在状态时,则将τ的取值赋给x;
(2) 延迟赋值,给定逻辑时刻t1,γ中所有信号变量都处于存在状态,且γ为 true,x和τ在t1时刻都处于存在状态,在下一逻辑时刻t2中,如果x处于存在状态,则在t2时刻将t1时刻τ的取值赋值给当前时刻的x;
(3) 约束定义,如果γ中所有信号变量同时处于存在状态且γ为 true,那么σ处于存在状态并且为 true.所有S-CGA程序中的操作都需要满足约束定义;
(4) 输入动作,当γ=true时,从环境中读取输入变量x;
(5) 输出动作,当γ=true时,将计算结果x输出到环境.
多个 S-CGA组合采用同步组合操作||.因此,S-CGA具有与 SIGNAL语言一致的表达确定性并发行为的能力.
表2给出kSIGNAL2S-CGA的转换规则.基于转换规则,SIGNAL语言中的基本结构(即kSIGNAL)所表达的功能关系和时钟关系一一映射为S-CGA中的对应表示.SIGNAL到S-CGA之间具体的转换规则解释以及语义保持证明思路参考文献[16].

Table 2 Rules of kSIGNAL2S-CGA表2 kSIGNAL到S-CGA的转换规则
(3) 时钟演算
同步模型除显式地表达功能关系外,还隐式地表达了时钟关系.因此,在代码生成之前,一般同步语言编译器都需要经过时钟演算,从而确定该同步模型可执行,并优化生成后的代码.首先,根据S-CGA语义,从 S-CGA表达式中生成时钟关系等式集合,其基本产生规则见表3.

Table 3 Rules of S-CGA2Clock equations表3 S-CGA到时钟关系等式的转换规则
针对例1给出部分转换示例及其时钟关系等式如下.

SIGNAL 部分S-CGA 部分时钟关系等式s1:=y1 when x1 s2:=y2 when x2 x:= s1 default s2 sassume yx sassume yx xassume ss ˆ()ˆ ˆ()1 11 2 22 12⇒ˆ˄⇒˄ ˆ⇒ˆˆ(˅)xyxyx ˆˆˆ()()=˄˅˄ 1122......
等式左侧ˆx为时钟变量,而右边等式是对应的定义,时钟关系等式x→y和y→x可表示为x=y.在时钟关系等式集合中,需要对具有相同时钟的不同时钟关系等式进行优化以保证生成后的代码执行效率更高.时钟关系等式集合的消解原理为:将等式右侧中的时钟变量用其定义进行替换,并不断地迭代,最后检查不同时钟变量之间是否等价(基于BDD或SMT).如果等价,则归为同一个时钟等价类,时钟演算之后的程序中时钟等价类用于替代S-CGA对应的时钟变量.
针对例1,代码生成器前端生成的部分S-CGA程序如图3所示.S-CGA程序中包括输入动作、输出动作、立即动作和延迟动作.此外,约束定义只用于时钟演算,不参与之后的任务划分等步骤.
3.2 时钟数据依赖图
SIGNAL程序中的所有信号变量可具有各自的时钟,如果生成串行代码,即需要确定性的执行顺序,编译器基于时钟等式和时钟等价类,构造出一棵时钟树(clock hierarchy).能够构造时钟树,代表所有时钟都隶属于一个全局时钟(master clock),即可以给出一个确定性的串行执行顺序,在同步语言中,称其为Endochrony性质.在同步语言串行代码生成中,根据时钟等价类之间的时钟蕴含关系构建时钟树,基于遍历时钟树结构,生成串行代码的控制结构,并根据等式之间的读写依赖关系生成执行顺序,依次填写到对应的控制结构中.而在多线程代码生成中,需要进一步构造数据依赖图,从而分析出更多的并行信息.
首先,使用时钟等价类替换对应的所有时钟变量以简化程序.其次,基于 S-CGA表达式中的变量间读写依赖关系构建数据依赖图.例如,对于卫式动作γ⇒x=τ,只有当获得γ和τ中变量的取值后,才可以执行该卫式动作对x进行赋值,此时,γ和τ为读依赖变量,x为写依赖变量.RdVars/RdActs用于表示读依赖变量/动作集合,WrVars/WrActs用于表示写依赖变量/动作集合.
定义2(读写依赖).设FV(τ)为表达式τ中的自由变量的集合.S-CGA等式中的动作到变量的依赖定义为
·RdVars(γ⇒x=τ):=FV(γ)∪FV(τ)
·WrVars(γ⇒x=τ) :={x}
而变量到动作的读写依赖定义如下.
·RdActs(x):={γ⇒A|x∈RdVars(γ⇒A)}
·WrActs(x):={γ⇒A|x∈WrVars(γ⇒A)}
MinSIGNAL多线程代码生成器采用基于周期的目标代码执行方式:(1) 初始化程序;(2) 计算程序体;(3) 更新变量.然后进入下一个周期,迭代执行(2)和(3).我们主要分析程序体中的依赖关系.含有初始时钟值init(xˆ)的立即动作主要用于程序初始化,而延迟动作用于更新变量,γ⇒assume(σ)则主要用于定义时钟约束关系,因此,这3类卫式动作不用于构造数据依赖图.
在数据依赖图中,只有当一个动作的所有读变量都有取值时,该动作才可以被执行.类似地,只有当一个变量的所有写动作都已经完成计算后,该变量才能够有取值.例如,在上述 S-CGA 程序中,ID_4⇒ID_5=x1依赖于ID_4⇒readx1获得的x1值.
定义 3(时钟数据依赖图(CDDG)).时钟数据依赖图 CDDG 为一个有向图〈V,DR〉,V代表卫式动作集合,DR⊆V×V代表卫式动作之间的依赖关系集合.
时钟数据依赖图的构造规则如下.对任意的动作a∈A以及变量x∈RdVars(a),在WrActs(x)对应的卫式动作到a对应的卫式动作之间增加一条有向边.
图4为Count进程对应的S-CGA程序依据构造规则生成的时钟数据依赖图CDDG.
我们使用 S-CGA 程序中的行号表示对应的卫式动作,使用不同的形状区分卫式动作.其中,椭圆表示输入动作,矩形表示输出动作,圆形表示立即动作.而箭头→表示依赖关系,例如,22→23表示ID_4⇒ID_8=ID_4 andID_7依赖ID_4⇒ID_7=x2获得的ID_7值.
3.3 任务划分
任务划分用于分析CDDG中包含的并行执行信息,直接影响目标代码的并行度,是多线程代码生成器的核心步骤.首先,CDDG是一个有向图,根据拓扑排序思想对 CDDG进行任务划分;其次,基于划分结果分别提出优化算法和基于流水线方式的任务划分,其中前者用于处理划分结果中可能存在丢失依赖关系和线程数目过多的问题,后者用于尝试寻找划分中更大的并行度.
3.3.1 基于拓扑排序的任务划分
多线程代码生成是基于已经融合时钟关系的数据依赖图,并需要在数据依赖图中进行任务划分(partition).CDDG是有向无环图,我们基于拓扑排序方法对CDDG进行任务划分.
划分算法如图5所示:算法输入为时钟数据依赖图CDDG,输出为任务划分结果topoPartition.算法第1步分别对NodeSet、EdgeSet和topoPartition进行初始化(第4行~第6行),然后进入拓扑排序划分迭代(第7行).迭代过程包含以下步骤:首先从 NodeSet中计算出所有入度为0的点组成的集合Pi,i表示迭代次数(第8行);其次,如果Pi不为空,则将Pi加入到topoPartition的末尾.如果Pi为空,表明CDDG中存在环,则算法终止,输出异常信息“CDDG中存在环”(第9行);最后将Pi中出现的点从NodeSet中移除以及从EdgeSet中移除与这些点有关的边(第10行、第11行).当NodeSet为空时迭代终止.
例1对应的CDDG生成划分结果topoPartition如下所示.
其中,Pi=id1||id2…||idn为一个划分,表示id1,id2,…,idn可以并行执行,id代表CDDG中对应节点的行号.以P1为例,1||2||3||8表示卫式动作ID_4⇒ready1,ID_4⇒readx1,ID_4⇒readx2和ID_4⇒C___4=y2==y2彼此可以并行执行.Pi;Pi+1表示两者之间串行执行.即当Pi中卫式动作执行结束,开始执行Pi+1中卫式动作.
然而,这种划分方法得到的划分结果可能存在以下问题.
首先,划分结果可能导致在最后代码生成的线程调度时,增加多余的同步开销.以P2中卫式动作ID_4⇒C___1=x1==x1为例,根据 topoPartition,该卫式动作开始执行需要等待P1中所有卫式动作执行结束.但根据CDDG可知,ID_4⇒C___1=x1==x1开始执行依赖ID_4⇒readx1执行结束.划分结果导致生成的线程之间也存在多余的通信信息,增加了线程之间的同步开销时间.在实际执行目标代码过程中,原本可以执行的线程必须等待其他额外的线程执行结束才可以开始执行,从而可能影响目标代码的执行效率.
其次,由于使用基于拓扑排序的划分方法,划分结果中的每个卫式动作在代码生成时将对应转换为一个线程.以P4中17(对应图3中ID_6⇒s1=y1)为例,其转换对应生成的线程的步骤包括:17对应生成线程名Thread_17;卫式动作转换为线程的计算部分;该线程开始执行依赖获得P3对应的所有线程的执行结束信息;当该线程执行结束,则将结束信息通知P5对应的所有线程.因此,当卫式动作数目过多时,导致线程数目过多,可能会增加线程间的资源竞争,从而影响目标程序的执行效率.
3.3.2 划分优化
针对划分结果 topoPartition可能存在的问题,我们给出基于拓扑排序划分的优化算法,即记录时钟数据依赖图CDDG中的依赖关系以及尝试减少目标线程数目.
首先,我们给出如下定义.
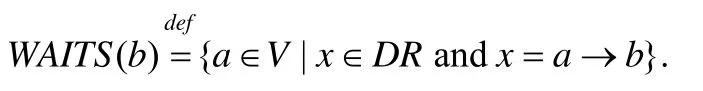
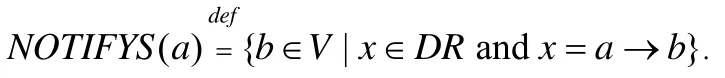
特别地,当WAITS(b)={a},即|WAITS(b)|=1 时,记为WAITS(b)={a}.同样地,当NOTIFYS(a)={b}时,记为NOTIFYS(a)={b}.根据定义4和定义5,遍历CDDG中依赖关系计算出所有卫式动作对应的等待和通知,并将其加入到优化划分结果topoOptimization中,从而在topoOptimization中记录时钟依赖图的依赖关系.此外,定义4和定义5也便于在后续步骤中找出可以合并的线程以及处理目标代码中线程之间的同步.
其次,给出尝试减少目标线程数目的方法.
如果卫式动作a和b满足WAIT(b)={a}&&NOTIFY(a)={b},则合并a和b为一个特殊的“卫式动作”,记为Ma=[a;b],其中,WAITS(Ma)=WAITS(a),NOTIFYS(Ma)=NOTIFYS(b).Ma表示卫式动作a和b在生成目标代码中将合并为一个线程.
图 6给出基于拓扑排序划分优化算法.首先,计算出所有卫式动作对应的等待和通知并加入到优化结果中(第4行~第6行);其次,在原有并行执行部分的基础上进行线程合并(第7行).
我们对第3.3.1节给出的划分结果进行优化,得到优化划分结果topoOptimization如下所示.
其中,划分P2的[15;16]、[22;23],P4的[17;18]和P6的[26;4]为合并后的卫式动作.例如,[17;18]表示在目标代码生成时,卫式动作ID_6⇒s1=y1和ID_6⇒x=s1将会被分配到一个线程中顺序执行.同时,等待和通知记录依赖关系,例如WAITS(22)={3}表示卫式动作ID_4⇒ID_7=x2依赖于输入动作ID_4⇒readx2得到的x2值.
3.3.3 基于流水线方式的任务划分
当基于拓扑排序获得的任务划分存在并行度不高(即大部分Pi中可并行执行的卫式动作数目都较少)的情况下,我们提出基于流水线方式(pipeline style)对划分结果进行再划分,尝试提高执行并行度.考虑一个特殊情况为划分结果中所有Pi中都只有一个卫式动作,则经过任务划分生成的多线程代码执行情况实际上“等同”于串行程序执行,而通过引入流水线方式划分支持多条流水线并行执行,从而提高目标程序的执行效率.
本文的流水线方式的任务划分算法(如图7所示)包括3个步骤:首先,根据划分结果定义流水线阶段;其次,针对各流水线阶段增加流水线中间变量;最后,针对不同流水线以及同一流水线下不同流水线阶段之间增加通信函数.
(1) 定义流水线阶段(算法第4行、第5行)
首先将划分结果topoPartition中每个划分Pi对应于一个流水线阶段Stage(i).由于topoPartition中并未考虑延迟动作γ⇒next(x)=τ,在确定流水线阶段的同时需要将所有延迟动作γ⇒next(x)=τ加入到相应的 Stage中,便于之后处理不同流水线间的通信,并保证不同流水线执行结果的正确性.例如,对于延迟动作ID_4⇒next(y2)=F___7,将其加入到ID_4⇒F___7=y1+K___8所在的Stage中.
每个Stage(i)有两种不同的状态:激活状态和阻塞状态.一个Stage(i)称为阻塞状态当且仅当该流水线阶段中存在需延迟动作写入的值未被更新.只有处于激活状态的流水线阶段才可以被执行.在定义流水线阶段时,每个流水线阶段默认为激活状态.
(2) 增加流水线中间变量(算法第6行~第9行)
得到流水线阶段后,需要考虑如何在每条流水线的各个流水线阶段之间加入流水线中间变量.因为每条流水线的每个阶段同时处理不同逻辑时刻的数据,所以需要一些中间变量来存储各个流水线阶段中生成的临时结果.为此,需要确定流水线中间变量在流水线阶段中加入的确切位置.
对Stage(i)中任意的卫式动作a,如果变量x∈WrVars(a),则在Stage(i)和Stage(i+1)之间,增加变量x对应的流水线中间变量.需要注意的是:一个流水线中间变量只适用于一条流水线.对于多条流水线,通过根据流水线条数N将流水线中间变量调整为一维流水线中间变量数组,从而保证各条流水线之间不产生数据冲突.例如,对于变量x以及流水线条数N,需要增加的流水线中间变量数组为m_x[N],其中,m_x[0]表示第0条流水线中x对应的流水线中间变量.
(3) 增加通信函数(算法第10行和第13行)
增加流水线中间变量后,需要在流水线中间变量与S-CGA变量之间建立起数据通信的映射关系,包括两种数据通信函数:数据输入函数inp_exchange,负责将流水线中间变量值传输到对应的S-CGA变量;数据输出函数outp_exchange,负责将已经更新的S-CGA变量值传输到对应的流水线中间变量中.例如,对于立即动作γ⇒(x)=τ,对γ、τ调用inp_exchange函数,当卫式动作执行结束,调用outp_exchange函数更新x.若变量x在某条流水线中需要的流水线中间变量为k个,设置N条流水线,则对于变量x来说,共需要中间变量为k×N个.
最后,需要考虑不同流水线之间的数据延迟通信问题.在多条流水线中,S-CGA 程序中延迟动作γ⇒next(x)=τ会影响相邻两条流水线之间的数据通信.因此,为了保证基本流水线的正确信息流,对于那些由延迟动作写入的变量(称为更新值),在每个流水线中必须保证触发一个动作来完成延迟动作.如果当前流水线中具有延迟动作中的节点对应的所有卫式动作的卫式都为false,则需要增加一个卫式动作来保存更新值,使之保证:如果当前流水线相邻的下个流水线中需要使用延迟动作中的变量,则这个变量的值等于前个流水线中的对应的值.同时设置标志符update表示当前流水线中涉及更新值的阶段是否已被更新,update为真,表示更新值已被更新,否则,该阶段处于阻塞状态.假设更新值的个数为t,设置N条流水线,则一共需要t×(N-1)个通信函数,在实际情况下,通信函数的个数可能会小于上述数值.因为对于更新前后的值始终不变的更新值,即由源 SIGNAL程序中常量生成的变量,其对应的不同流水线之间的通信函数可以进行优化而被去掉.
这里,我们给出针对第3.3.2节中topoOptimization进行流水线方式的任务划分,默认采用3条流水线.首先定义流水线阶段并添加延迟动作,例如 Stage(2)中添加两个延迟动作(序号 12和序号 14);其次定义流水线中间变量,如图8所示,Stage(1)和Stage(2)之间增加流水线中间变量数组y1、x1、x2和C__4;最后添加通信函数,包括数据通信函数(outp_exchange/inp_exchange)和延迟通信函数(f_y2),如图9所示.
Pipeline1中Stage(4)的更新值y2默认由init函数激活,所以设置为激活状态,而Pipeline2和Pipeline3中Stage(4)分别由前一个Pipeline中的Stage(2)触发,所以后者设置为阻塞状态(灰色).此外,序号12和序号27对应的卫式动作ID_4⇒next(K___8)=K___8和ID_4⇒next(K___9)=K___9是根据源SIGNAL程序中的常量而生成,可以优化其对应的延迟通信函数,因此不需要修改更新值.
3.4 多线程代码生成
本文将多线程代码生成过程分为平台相关和平台无关两个层次:首先,根据划分结果生成基于 Wait/Notify机制的虚拟多线程VMT(virtual multi-thread)代码;其次,从虚拟多线程代码中生成具体的可执行多线程代码,如C或者Java.
3.4.1 虚拟多线程代码
优化划分中每个卫式动作或合并的卫式动作对应一个线程,如图10右侧线程所示,本文采用串行调度方式来确保线程间通信保持同步语义,根据优化划分结果中WAITS和NOTIFYS信息实现基于Wait/Notify机制的虚拟多线程代码.主函数首先执行初始化(例如,y2=2),然后进入主循环,等待所有线程完成执行,最后处理延迟赋值操作(更新y2取值).而在主循环中,每个线程(thread1,…,thread26)都执行一个循环:等待(wait)输入、测试卫式、产生输出、通知(notify)其他线程.
另外,针对基于流水线方式的任务划分结果生成虚拟多线程结构,则需要对图10所示结构做出如下调整.
(1) 保留虚拟多线程的通用结构,即初始化、主函数和线程组.主函数中的call_threads()函数修改为call_threads(PN),即在主循环中调用PN条流水线下的线程.延迟赋值操作从主函数转移到特定的线程中,具体线程是根据流水线阶段中延迟动作加入的位置加以确定.
(2) 增加数据交换和数据通信.数据交换用于处理单个流水线中线程与流水线中间变量的数据交换.数据通信用于处理不同流水线之间线程间的通信.
生成虚拟多线程代码的目的是方便对多线程代码进行形式化验证和仿真分析,如使用模型检测工具UPPAAL对多线程代码的无死锁性等性质进行验证,以及在仿真工具Simulink上进行仿真实验.同时,支持生成多种目标代码,增加代码生成器后端的可扩展性.
3.4.2 多线程C代码
在多线程C代码自动生成过程中,使用POSIX的同步机制来实现Wait/Notify.首先,所使用的同步结构由互斥量(pthread mutex)、条件变量(pthread condition variable)以及一个线程所等待事件的数量(value)组成.例如,thread13需要等待thread1的事件,因此,其value为1.
counter_wait用于表示 Wait机制,即,当前线程的value值大于 0(意味着该线程的一些等待事件还没有到达),则将当前线程设为等待.
counter_notify用于表示Notify机制,用于唤醒等待线程队列中的某个线程.
以图 10中虚拟多线程为例,我们给出对应多线程 C代码中部分线程:thread_15和thread_17,如图 11所示.thread_15开始执行需要等待thread_2的事件发生,即读取输入信号x1.条件语句中顺序执行语句ID_5=x1和ID_6=ID_4 &&ID_5是根据划分结果 topoOptimization中P2对应的[15;16]生成.当完成计算后,通知线程thread_17,thread_19和thread_21.如果thread_1已经执行完成,则下一步可以执行thread_17.
3.4.3 多线程Java代码
在生成多线程Java代码阶段,我们使用线程同步栅栏的方式完成线程之间的同步,生成的Java文件主要包括如下两个Java类.
(1) 输入输出类.对于 S-CGA中每一个输入动作,对应生成一个 read方法,每个输出动作则对应生成一个write方法.在线程类执行前,调用 read方法读取输入数据,在线程类执行结束后,调用 write方法写入输出数据.通过单独生成输入输出类,保证不同任务划分算法生成的线程类可以重用输入输出类.
(2) 线程类.线程类中包含了若干子类,如classthread_15等.子类实现了Runnable方法,对应于虚拟多线程中单个线程.在子类中重写run函数:等待所依赖的事件发生,执行条件语句,通知其他线程.
以图10中虚拟多线程为例,我们给出对应多线程Java代码中部分线程:thread_15和thread_17,如图12所示.首先thread_15调用Wait方法,进入阻塞状态,当所依赖的线程全部执行完之后,解除thread_15的阻塞状态.if语句执行结束后,调用countDown方法通知其他线程thread_15已执行结束.类似地,如果thread_1已经执行完成,则下一步可以执行thread_17.
4 工具和实例分析
MinSIGNAL多线程代码生成器基于OCAML编程实现,代码生成器采用模块化思想,包括已有串行代码生成器前端和扩展多线程代码生成器后端.本节将主要介绍MinSIGNAL多线程代码生成器的工具设计与实现以及多线程代码在多核处理器上的实验分析.
4.1 工具实现和分析
多线程代码生成器的主要编译步骤及其对应的OCAML代码数量统计见表4.
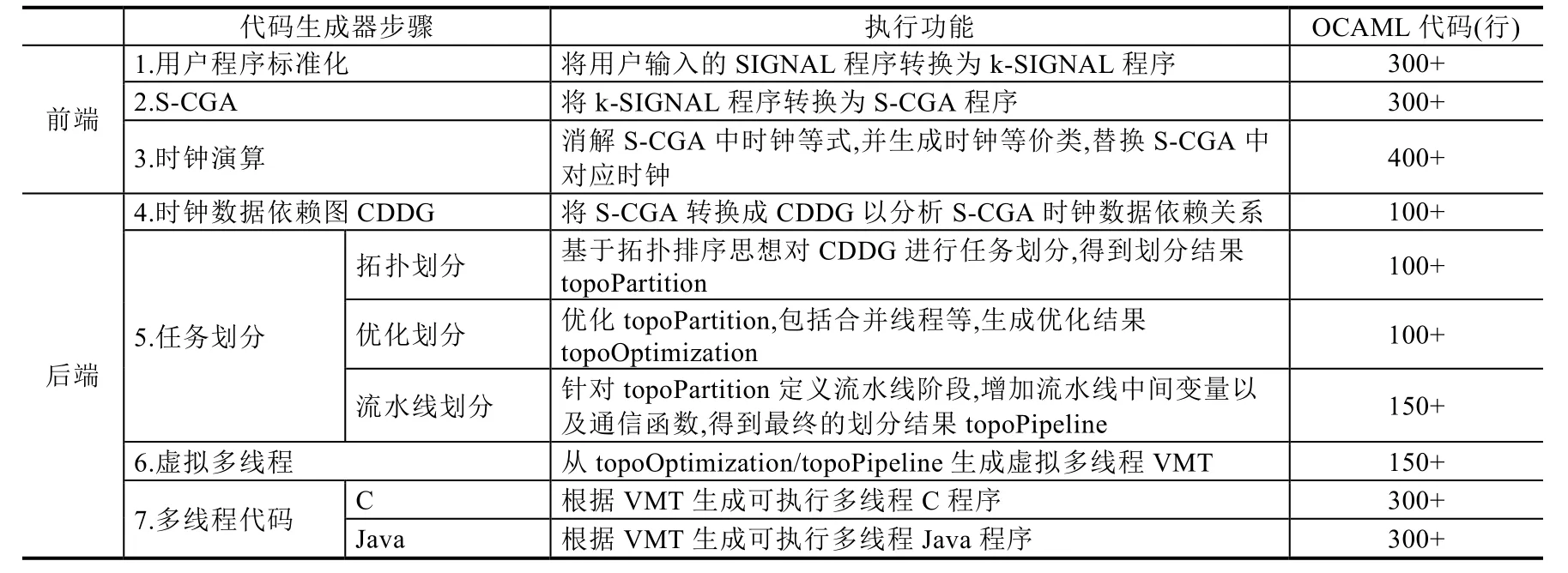
Table 4 Main steps of MinSIGNAL parallel code generator表4 MinSIGNAL多线程代码生成器主要步骤
工具开发环境为基于Eclipse平台的OcaIDE插件环境.如图13所示,左侧为文档结构,每个文件对应一个执行功能.我们在main.ml文件中配置MinSIGNAL代码生成器执行步骤,并通过配置文件设置同步语言源文件路径、代码生成器执行文件路径等参数,运行配置文件(如图14所示),从而生成多线程代码.
如图15所示,目标程序通过从输入信号对应的文件Input.txt中读取数据,执行计算结束后将输出信号保存到文件Output.txt中.
4.2 实验与分析
本实验的目的在于通过实验分析基于拓扑排序优化算法和基于流水线方式的任务划分是否提高目标代码的执行效率,以支持比较基于不同划分方法下自动生成的程序的质量.我们测试基于不同划分算法生成的多线程代码,具体包括:使用基于拓扑排序划分生成的多线程代码(C_1/JAVA_1),以及在拓扑排序划分的基础上分别使用基于优化拓扑排序划分生成的多线程代码(C_2/JAVA_2)和基于流水线划分方式的多线程代码(C_3_i/JAVA_3_i),其中,流水线条数i分别设置为 3/4/6/12条.C_1/JAVA_1的运行结果作为基准,用于和后两种划分方式进行比较.整个测试环境参数包括操作系统Win10 64bit、8核core i7-6700 CPU 3.40GHz、8G RAM、C编译环境Dev_C++(TDM-GCC 4.8.1)和Java编译环境Eclipse Oxygen(JDK1.8).
实验选取3个SIGNAL测试程序:测试程序1为例1中Count程序;测试程序2为数学中幂运算计算程序,输入两个整型(integer)参数分别是底数和指数,输出幂运算的结果;测试程序 3为模拟采样,对输入的波形(整型值序列),根据设置不同的采样要求(假设有两种布尔条件),分别输出对应的波形.实验通过在不同CPU核数下运行不同SIGNAL测试程序生成的多线程C和Java代码,计算其循环执行1 000次的平均执行时间,见表5.
平均执行时间反映多线程代码执行效率.图16给出表5((1)~(3),共3张表)对应的折线图,横轴为CPU核数,纵轴为不同目标代码在给定CPU核数下的平均执行时间.如图16所示,在CPU核心数相同的情况下,基于流水线方式的划分算法生成的多线程代码(C/Java)执行效率最高,而采用基于拓扑排序划分优化算法次之,但仍比基于拓扑排序划分算法对应的执行效率要高.同时,由图16可知,在给定任务划分算法和CPU核数的情况下,生成的多线程C程序的执行效率高于生成的多线程Java程序.这可能是因为二者的多线程机制存在差异,C程序直接调用Windows底层程序,而Java程序是借助于JVM实现多线程机制.因此,不同目标语言的选取也会影响多线程代码自动生成方法所生成目标程序的执行效率.
此外,通过分析四核CPU和八核CPU下对应的平均执行时间可知,四核CPU对应的执行时间更快,即并不是 CPU核心数越高,程序执行速度越快.这可能是由于随着 CPU核数的提升,不同核之间调度和数据交换花费的时间更多,并且Cache访问冲突也会造成执行时间的增加.因此,在嵌入式系统的设计过程中,在考虑软件建模的同时,也需要考虑适配硬件平台,避免造成资源浪费.
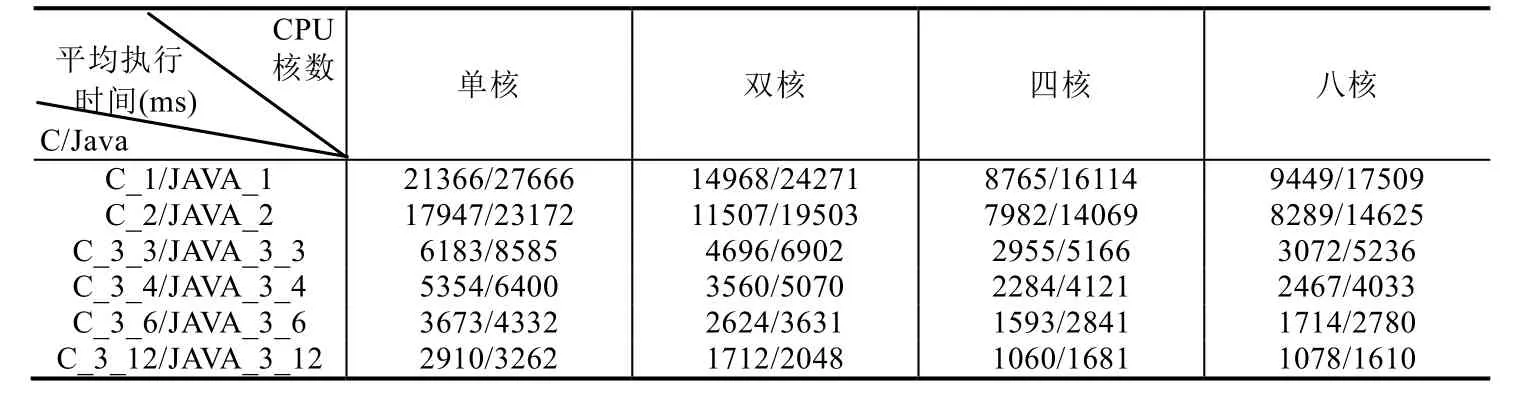
Table 5 Testing results on multi-core platform (1)表5 多核执行平台下的测试结果(1)
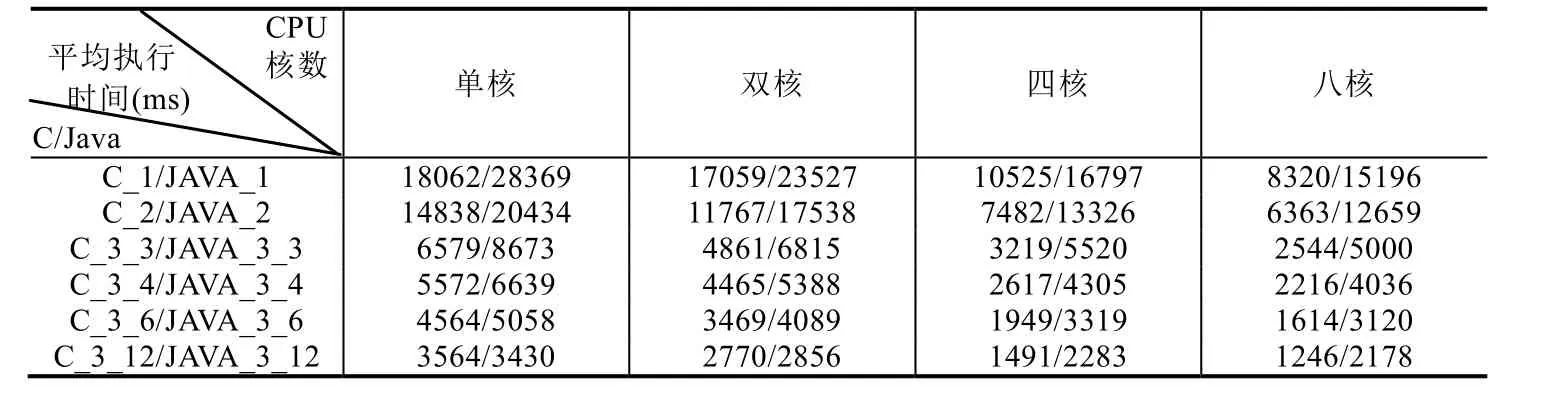
Table 5 Testing results on multi-core platform (2)表5 多核执行平台下的测试结果(2)
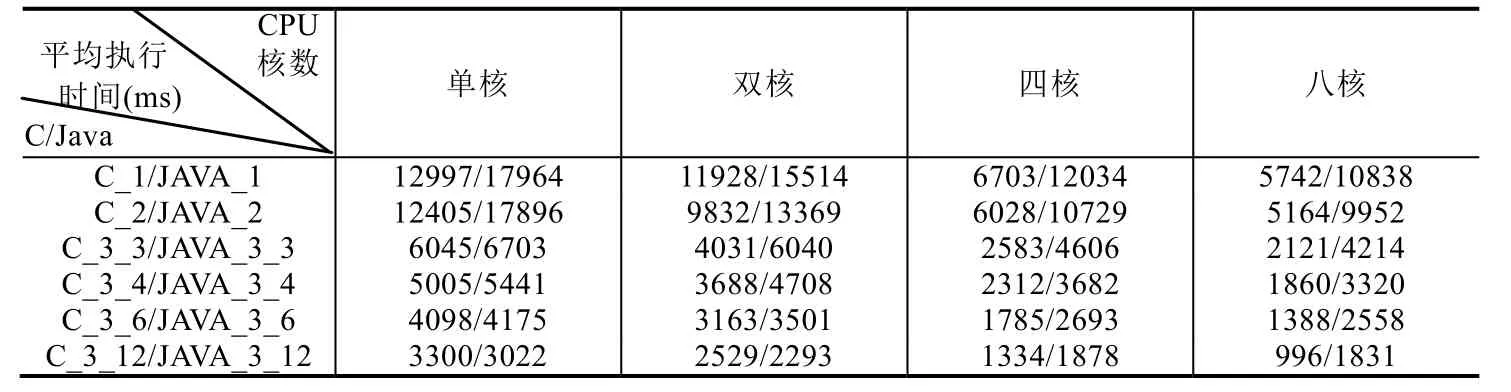
Table 5 Testing results on multi-core platform (3)表5 多核执行平台下的测试结果(3)
综上所述,通过分析基于不同划分算法生成的多线程 C/Java代码在多核平台上实验的数据,可以得出以下结论.
(1) 基于拓扑排序优化算法和基于流水线方式的任务划分算法缩短了目标代码执行时间,其中,流水线划分算法较为明显地提高了执行速度.
(2) 不同目标语言的多线程代码执行速度存在差异,在实际生成代码时需要综合考虑目标语言以及多线程机制等因素.
(3) 当考虑同步模型生成多线程代码时,需要考虑部署在哪种多核平台上,以保证资源的合理利用.
本文基于OCMAL实现同步语言SIGNAL的多线程代码自动生成工具.在已有SIGNAL编译器研究工作中:例如,与原有SIGNAL编译器Polychrony[26]相比,本文的S-CGA能够支持多种同步语言的集成;文献[14]主要考虑基于GALS的多线程代码生成,生成的线程粒度较大,本文主要考虑更细粒度的线程,以便寻找到更多的并行信息,目前已实现与体系结构分析和设计语言 AADL的混合建模;与文献[31]相比,该文献主要考虑同步语言的跨平台代码生成,在任务划分中仅使用拓扑排序划分算法,且时钟信息需要后期单独增加,相比而言,本文考虑多种划分算法,优化目标代码的执行效率.此外,本文的未来目标是基于Coq多线程代码生成器的验证工作.
5 相关工作
同步语言的串行代码生成研究已经比较成熟.随着多核处理器的发展,同步语言的多线程代码生成成为研究热点.已有研究大致可以分为如下3类.
· 基于 GALS的多线程代码生成,即系统由具有不同时钟的多个进程组成,而每个进程是单时钟的,目前所有同步语言基本都支持此类的多线程代码生成.
· 基于单进程的多线程代码生成,主要是针对 SIGNAL语言以及其他单时钟同步语言的扩展,这是由于单个进程中的所有信号变量也可以具有不同时钟.
· 考虑硬件平台特性,涉及到多核架构或时间可预测处理器的执行及程序最坏执行时间分析.
(1) 基于GALS的多线程代码生成
同步语言支持进程间的并发操作,例如 QUARTZ和 ESTEREL提供同步并发运算符‘||’以支持进程间的并发,LUSTRE使用‘;’表示不同节点的并行执行,SIGNAL中不同进程间的组合操作‘|’也隐含着并行执行[32].同时,在分布式系统上,由于进程间通信受到物理载体的影响而产生不可预测的延迟[13],导致不同进程间的时钟可能不满足同步关系,被称为全局异步局部同步GALS系统.
文献[14]提出一种非侵入式的多线程代码生成方法,即在不改变已有SINGAL编译器Polychrony结构的基础上,利用其串行编译功能生成多个独立的进程,并基于主控函数完成调度,实现进程之间的并行执行.文献[15]提出从实际工业需求中导出功能行为等价的Heptagon程序[33](一种类Lustre同步语言)并进一步生成多线程代码.与文献[14]所提方案类似,首先基于Heptagon编译器生成多个串行节点,然后在集成规约中描述任务间通信和同步.通过构建节点间的依赖图,利用串行调度来保证确定性并发语义.除功能需求外,该研究还考虑了非功能性需求(如周期等实时性质)的代码生成.
此外,文献[34]提出从高层建模语言(AADL,SysML,SystemC等)转换为SIGNAL同步程序并进一步生成多线程代码的方法.其中,同步程序基于Weekly Endochronous理论[35]:即程序中允许多个根时钟.在多线程生成过程中,采用符号化原子表达式和合并分支条件的策略约减线程数目.不过,其同步程序中仅考虑有限的数据类型(事件、布尔和枚举类型)和布尔操作(相等和取反操作).
多个进程之间并行划分的“粒度”相对较大[14],但在同步语言模型中,单个进程内部也往往存在潜在的并行执行信息.尤其是可以自然表达分布式系统的SIGNAL语言,其语法的基本结构中包含多时钟操作,可以比较自然地支持在进程内部描述并行执行操作.
(2) 基于单进程的多线程代码生成
文献[26]中介绍了同步语言SIGNAL编译器Polychrony中的代码生成策略,在多线程生成方面分为静态调度和动态调度.静态调度下的分簇(多线程)代码生成:将生成的代码划分到簇中来模拟调度图的结构.分簇的原则是:将调度图划分为对那些依赖于完全相同的输入集合进行计算.只要一个簇的所有输入都有确定值,那么这个簇就可以被自动执行,一个簇的时钟取决于簇中所有信号在时钟树上的公共父节点.动态调度下的分簇(多线程)代码生成:按任务实现分簇,并生成任务之间的同步信息.任务由簇来生成,主要思想是使用信号量的方式并行执行各个任务.然而,这种方式下生成的多线程数目太多,并且使用特定的线程库来生成仿真代码.
文献[29,30]是对纯同步语言 Quartz编译过程的多线程代码的研究.文献[29]提出同步卫式动作(clocked guarded action,简称CGA)到基于OpenMP的多线程C程序的编译方案.作者提出“垂直划分”的概念,即从数据依赖图中抽取出独立的线程,并生成对应的 C代码.文献[30]引入软件流水线的概念,提到的软件流水线方法包含:分析卫式动作之间的依赖关系、创建流水线变量存储各阶段之间的中间结果以及卫式动作到流水线之间的转换.这种方法被称为“水平划分”.
文献[31]对 SIGNAL多线程代码生成进行了研究,提出基于方程依赖图(equation dependency graph,简称EDG)的OpenMP并行代码生成方法.其中的并行代码生成算法主要是对数据依赖图进行拓扑排序,生成多个链表:多个链表之间顺序执行、单个链表内部节点并行执行.不过,文献[31]使用拓扑排序作为任务划分算法,没有考虑优化工作,而且需要在划分之后对划分结果单独加入时钟信息.而本文使用的CDDG中包含时钟依赖关系,即在划分过程中已经考虑时钟信息.
本文主要考虑单进程的多线程代码生成方法,同时给出优化策略和流水线方式的任务划分方法,能够较好地约减线程数目以及提高目标多线程代码执行效率.
(3) 多核架构执行及WCET分析
ITEA 3计划中的(affordable safe & secure mobility evolution,简称ASSUME)项目[15,36]提出一种用于在多核/众核架构上提供可信的嵌入式软件工程方法,包括从LUSTRE同步模型到自动生成并行代码并在多核/众核平台上执行.ASSUME项目扩展了SCADE工具的KCG编译器,以支持生成面向MPPA众核架构[37]的并行代码,但是当前的并行信息是通过用户来驱动的,即用户指定程序中并行执行区域.此外,在代码生成过程中提供每个任务在实时调度期间所需的属性(如WCET、内存访问的最坏次数等).
法国国家航天航空研究中心ONERA的SchedMCore环境[38,39]为形式化多处理器调度分析和实验性多核运行时基础架构提供了一套验证和执行工具.SchedMCore将同步语言Prelude[40]编译生成一组相互通信的周期任务(包含信息有:任务的周期、WCET、首次到达时间和 Deadline),并基于工具自带的不同多核调度策略实现任务在多核架构上的调度.文献[41]中给出一个基于 SchedMCore设计并运行在多核/众核架构上的航空经度控制器案例.
德国Kaiserslautern工业大学嵌入式系统小组(http://es.cs.uni-kl.de/)基于同步语言QUARTZ开发了一个用于并行嵌入式系统的规约、验证和实现的框架AVEREST(http://www.averest.org/).该框架可同时生成硬件电路逻辑代码和多线程代码,并且支持软硬件分析[42].此外,他们还研究了基于指令集并行(instruction level parallelism,简称 ILP)的同步语言 SCAD 最优化代码生成,包括使用回答集编程(answer set programming,简称ASP)处理 SCAD代码生成过程中的最优资源/时间约束调度问题[43],以及利用 SMT求解器生成实现最大化指令级并行(给定处理器单元数目)的最优化代码[44]等.
综上所述,同步语言多线程代码生成涉及到多核硬件执行平台以及考虑WCET分析.我们在已有工作[18]中给出在同步语言代码生成过程中的时间可预测多核体系结构模型及软硬件映射方法.而本文主要侧重同步语言多线程代码生成方法及其实现,提出任务划分优化策略以及基于流水线方式的划分以提高目标代码的执行速度.
6 总结与展望
同步语言广泛用于安全关键嵌入式系统建模与验证,近年来,同步语言的多线程代码生成成为学术界的一个研究热点.本文提出一种基于OCAML的同步语言SIGNAL多线程代码生成方法和工具.首先将SIGNAL程序转换为经过时钟演算的 S-CGA中间程序;之后将S-CGA中间程序转换为时钟数据依赖图以分析依赖关系;然后对时钟数据依赖图进行拓扑排序划分,并针对划分结果提出优化算法和基于流水线方式的任务划分方法;最后将划分结果转换为虚拟多线程结构,然后进一步生成可执行多线程 C/Java代码.通过在多核处理器上的实验验证了本文提出方法的有效性.
编译器的形式化验证是一项重要工作,例如:CompCert编译器(C编译器)[45]、清华大学L2C项目(LUSTRE编译器)[27,28]以及Vélus编译器(LUSTRE编译器)[46].我们已经给出SIGNAL多线程代码生成器前端的语义保持证明,下一步工作将基于Coq完成代码生成器后端的语义保持证明.其次,扩展同步语言以支持描述实时性质,以及考虑在时间可预测多核处理器(如 Patmos[47])上执行多线程代码并进行 WCET分析也是未来一项重要工作;最后,针对复杂嵌入式系统,我们正在开展嵌入式实时系统体系结构分析与设计语言 AADL(描述系统架构)[48]和同步语言(描述AADL单构件内的功能)的混合建模方法研究.
致谢感谢匿名评审专家给予的宝贵意见.另外,感谢法国法国国家信息与自动化研究所(INRIA)Jean-Pierre Talpin教授给予了很多重要的建议.
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
小学生学习指导(低年级)(2020年10期)2020-11-09
当代工人(2020年4期)2020-05-11
儿童故事画报(2019年8期)2019-08-14
数学大王·低年级(2018年9期)2018-10-24
永善文学(2017年1期)2017-07-18
中国信息技术教育(2017年11期)2017-07-01
数学大王·中高年级(2017年2期)2017-02-08
