
基于词向量和远程监督学习的格萨尔领域知识发现方法研究
2019-07-11 02:43陈建龙
西藏大学学报(社会科学版) 2019年2期
陈 博 陈建龙
(北京大学信息管理系 北京 100871)
引言
知识是人们从实践经验中总结出来且被新的实践所证实的规律及经验的总结,是可以用于推理的规则。[1]在计算机、互联网、大数据等科技手段共同缔造的“信息爆炸”时代,日益凸显的“信息过载”和“信息迷航”现象揭示了人们知识获取相对困难的窘境,同时也引起了相关领域研究者的注意。当前的知识在数量规模、数据粒度、[2]数据结构、表示方式、更新速度等方面均处于前所未有的复杂环境,在此环境中的知识往往有密度低、关联多、[3]具有模糊性等特点,必然会影响知识发现的时间与效果。如何在海量的信息中高效发现目标知识,已成为大众与研究者共同关注的话题。
知识发现可分为数据库知识发现(Knowledge Discovery in Database)与基于文献的知识发现,分别针对结构化数据和非结构化数据展开。[4-5]知识发现需在知识抽取基础上进行。关系抽取作为知识抽取的重要组成部分,指自动从文本中检测和识别出实体之间具有的某种语义关系,在知识图谱自动构建、信息获取技术支撑等方面具有重要意义和广阔前景。[6]弱监督关系抽取方法是当前相关研究的一大热点,[7]为我们展示了一种通过机器学习,基于少量标注数据完成大规模知识抽取的有效方法,为相关知识发现提供了可能的途径。
本文以格萨尔学科领域为例展开知识发现研究。英雄史诗《格萨尔》被誉为“东方的荷马史诗”,以主人公征战立业为主线,构建了篇幅约2000万字的宏大史诗,对其文化辐射区域产生了深远的影响,相关研究从11世纪发展至今积累了大量领域知识并在多个细分领域取得成果。从人物领域来看,史诗中人物形象多达3000余个,[8]人物间关系错综复杂,相关研究对学科发展的重要性不言而喻。现有研究多从文学视角出发,对人物形象、性格等进行分析[9-10],也涉及人物体系[11]、王室发展[12]等方面,但尚未构建出成体系的人物关系网络。此外,由于格萨尔学科还未建立系统的结构化数据库,加之史诗具有的专业性领域知识、叙事性文本结构、文学性语言表达,对该学科领域人物的关系抽取和知识发现提出了更高要求。
对此,本研究拟运用机器学习技术,以词向量与远程监督学习为基础,将非结构化知识进行结构化表示,结合知识图谱训练,完成领域人物知识的抽取,并尝试在格萨尔学科领域自动发现人物关系,对新领域知识中的人物关系抽取方式进行探索,以期将其作为对传统基于规则的人物关系抽取方法的补充,优化人物之间隐含关系的发现效果。
一、相关研究
(一)词向量
词向量(Word Embedding)是一种自然语言处理(NLP)中的语言建模和特征学习技术的统称,核心思路是基于机器学习方法,将词汇表中的单词或短语从高维离散空间中映射到低维连续空间的实数向量。基于训练语料,被学习的词表征即可以词语在向量空间中的位置信息和词与词之间的相对位置表达出有意义的语法及语义规律。[13-14]
(二)远程监督
远程监督(Distant Supervision)学习方法基于Mintz提出的假设,“如果两个实体在已知知识库中具有某种关系,那么所有提到这两个实体的句子都会以某种方式表达出这种关系”,[15]可利用少量标注数据对大规模数据进行训练,其主要思想是将已有知识库的知识对齐非结构化文本,由此生成大量标注数据,可在降低训练成本的同时保证训练效果,提升模型的可拓展性。
二、基于词向量和远程监督学习的格萨尔领域知识发现
(一)研究框架
格萨尔学科建设发展中的人物关系研究重要且不可回避,但该学科发展至今还未有完整的领域人物知识图谱和人物关系网络。弱监督关系抽取模型基于一定量的既有标注数据,可进行大规模拓展,从训练效果和可拓展性考虑是一高效方法,因此,我们提出一种基于分布式词向量表示与远程监督学习的新领域知识自动发现方法,以格萨尔领域人物关系知识为发现对象进行人物关系预测,并验证了该方法的可行性。
从实施流程来看,该知识发现方法包括数据采集与预处理、词向量模型训练、深度学习分类模型训练、关系预测四个环节。整体而言可分为词向量及深度学习分类模型训练阶段,以及格萨尔领域人物关系预测阶段两大阶段。各阶段流程分别见图1、图2所示。
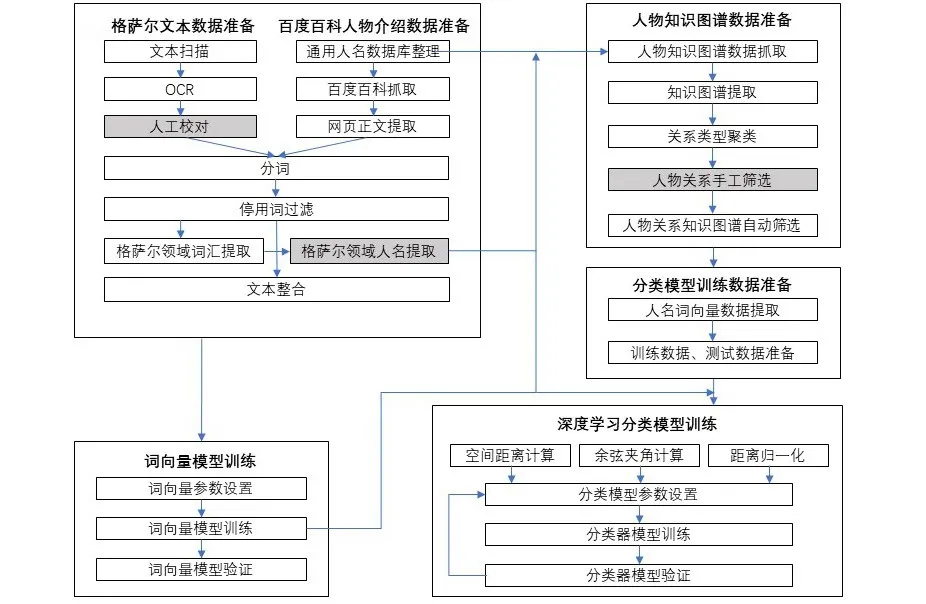
图1词向量及深度学习分类模型训练阶段
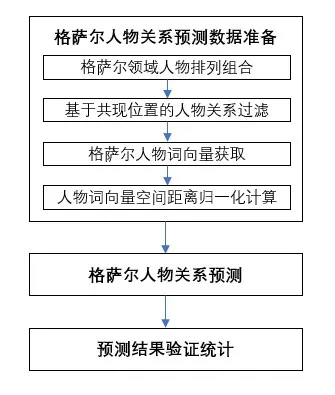
图2格萨尔人物关系预测阶段
第一阶段是词向量及深度学习分类模型训练阶段。由数据采集与预处理环节完成格萨尔文本、百度百科人物介绍和人物关系知识图谱三类数据的获取和预处理,然后基于人物相关文本数据训练出词向量模型,并利用人物关系知识图谱数据,进行基于深度学习的人物关系分类器训练,得到可进行人物关系预测的分类模型。
第二阶段是格萨尔领域人物关系预测阶段。通过训练好的人物关系分类器,对格萨尔领域可能有关系的人物组合进行逐一预测,并选出置信度较高的预测结果进行人工验证,完成格萨尔领域人物关系无专家标注的新知识发现。
(二)数据采集与预处理
此环节包括格萨尔文本、百度百科人物介绍、人物关系知识图谱三个方面的数据采集与预处理,基于上述数据准备可得到用于分类模型训练的训练数据和测试数据。
1.格萨尔文本数据获取
本文选用的格萨尔文本源于《英雄格萨尔》[16],该套书以降边嘉措藏文版《格萨尔》(40卷,2000多万字)为框架,参考扎巴和桑珠的说唱本并融合作者研究著成。作者降边嘉措长期从事格萨尔史诗领域的藏汉翻译和研究工作并取得了卓著的成果,是该领域学科牵头人。以此书作为领域文本数据源,可一定程度减少异构数据噪声干扰,并保障数据规模与置信度。
2.百度百科人物介绍数据获取
百度百科录词条数逾千万,包含海量以半结构化的百科语言组织的人物相关信息,便于计算机提取使用。本文实验中百度百科通用人物介绍文本数据的准备,包括通用人名数据库整理、百度百科文本抓取、网页正文提取三部分。
3.文本数据分词处理
在完成上述数据获取后,基于分词效果和效率考虑,本次实验从多种常用中文分词器中选择Jieba分词器对所取得的文本数据进行分词,以供后续研究使用。
4.人物关系知识图谱数据获取及处理
为避免手工标注的巨大成本,本文研究从开放知识图谱数据源中获取人物关系知识,作为人物关系远程学习的标注数据进行标注。我们选择复旦大学开放知识图谱CN-DBpedia和故思通用开放知识图谱Ownthink为人物关系知识图谱数据源。从中获取人物关系知识图谱数据的过程包括人物相关的知识图谱数据抓取、三元组知识图谱信息提取、关系类型聚类、人物关系手工筛选、人物关系知识图谱自动筛选及数据处理,最终获取形式为(实体1,实体2,关系)的人物关系三元组。其中实体1为人名;部分实体2包括由多个人名组成的不规则表达方式,通过拆分处理可得到不同三元组中的人名2。
(三)词向量模型训练
词汇关系可用基于深度学习的神经网络训练出的分布式词向量来建模计算。在原始数据处理上,本文研究通过分词及词向量训练完成对数据的向量化表示,为后续的模型训练提供统一向量空间中的结构化数据库。本文实验选用CBOW模型,以Gensim工具完成词向量的训练。
(四)深度学习分类模型训练
完成对准备数据的词向量训练后,利用深度学习对向量化的数据进行向量关系计算与分类训练,不断优化出理想的分类器模型。
1.词向量关系计算
采用词向量预测人物对之间的关系,潜在假设为词向量的空间位置和人物之间的关系类型有潜在联系。基于该假设与远程监督学习理论,本文将向量化的人物关系实体对用作标注数据,以欧式距离(人名2-人名1)、词向量间余弦夹角、欧式距离归一化(人名2-人名1后归一化)三种方式训练格萨尔文本数据。欧氏距离是在m维空间中两个点之间的真实距离,或者向量的自然长度,但欧式距离度量会受指标不同单位刻度的影响,为了改进数据有效性,一般需要先进行标准化计算,将欧式距离归一化;在词向量间余弦夹角中,空间向量余弦夹角的相似度度量不会受指标刻度的影响,余弦值越大则差异越小。

图3三维空间距离示意图
若A、B两点在三维空间中,其欧式距离的表示即如图3中的dist(A,B)。同时,A、B两个向量之间的cos值也可用来表示二者的相似度或关系的远近。
2.分类模型构建
本文实验基于深度学习中的远程监督学习思想,利用基于TensorFlow的Keras高层神经网络API相关模块搭建深度神经网络分类网络模型并进行多轮优化与迭代训练,以通过无前期人工标注的方式,令模型在细分任务上取得不错的表现。
(五)格萨尔领域人物关系预测
在对文本进行向量化表示,并在知识图谱数据的远程监督下完成数据训练的基础上,我们尝试于格萨尔领域进行人物的关系发现,即人物关系预测,其过程可分为领域人物组合、基于共现位置的人物关系过滤、领域人物关系预测与验证三步。首先,依据格萨尔领域人物列表将人物两两组合,得到格萨尔领域人物排列组合全集。其中包含大量无直接关联的无效人物组合,对此进行适度过滤以减小噪声干扰。此后,在词向量空间中检索人物组合对应的词向量数据,并经过空间距离归一化计算,通过上述远程监督分类模型预测,得到预测结果。不同人物关系类型下的预测置信度可反映两个人物之间存在关系的可能性。
三、实验设计与结果分析
(一)实验数据准备
1.实验数据提取
依据实验需求,基于格萨尔文本、百度百科人物介绍、人物关系知识图谱三类原始数据,采用OCR(Optical Character Recognition)、Scrapy爬虫等技术进行实验相关数据的准备。
格萨尔史诗领域数据方面,选择《英雄格萨尔》全书进行文本采集,提取非结构化的领域知识。通过对全书的高清晰度双面扫描,得到领域文本分页照片;通过OCR对文本正文区域进行文字识别,完成图片到文本的自动转换;最后由人工校对,得到全文文本数据,长度1410922字,文本大小为3.95MB。
百科数据方面,基于百度百科人物介绍,提取半结构化的通用领域人物介绍知识。将常用汉语人名库(含540万人名)作为人名数据字典,基于百度百科URL规则自动生成人名URL地址集,通过Scrapy爬虫框架自动抓取对应的百科网页。除去未被百科收录的人名数据,共抓取82万人物介绍网页,并提取到有效的人物介绍文本数据82万条,汇总后为2.6GB。
人物关系知识图谱数据方面,基于CN-DBpedia与Ownthink知识图谱,提取结构化的通用领域人物介绍知识图谱数据。同样根据知识图谱CNDBpedia和Ownthink的URL地址规则,用Scrapy自动抓取百科数据包含的人物对应的知识图谱数据,得到有效数据18万条。以宋武公为例,将从两个知识图谱中获取到的原始人物知识数据节选见图4。

图4两个知识图谱中获取到的原始人物知识数据
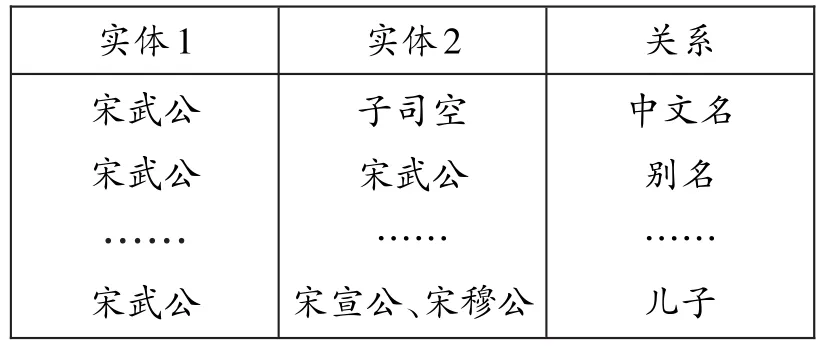
表1“宋武公”相关知识图谱
在知识图谱系统中,三元组数据分别在json格式返回数据的ret属性和avp属性中,通过Python的json模块自动提取、去重并保存知识,得到宋武公相关数据,节选如表1所示。
以上述方法处理18万人物知识图谱数据,得到包含三元组的知识图谱数据共计369万条,文本大小11.5MB。经验证,这一用作训练的知识图谱数据集中没有格萨尔领域人物相关数据,规避了集内数据对实验的影响。
2.实验数据处理
获取实验数据之后,需要对非结构化、半结构化的格萨尔文本数据、百度百科人物介绍数据进行分词;同时在知识图谱中提取人物关系,基于这些关系对知识图谱数据进行过滤。我们首先通过Jieba完成文本的分词,再用停用词表过滤掉无用词,经手工筛选后最终提取领域词汇1255条,最高频的10个词及其词频如表2所示。
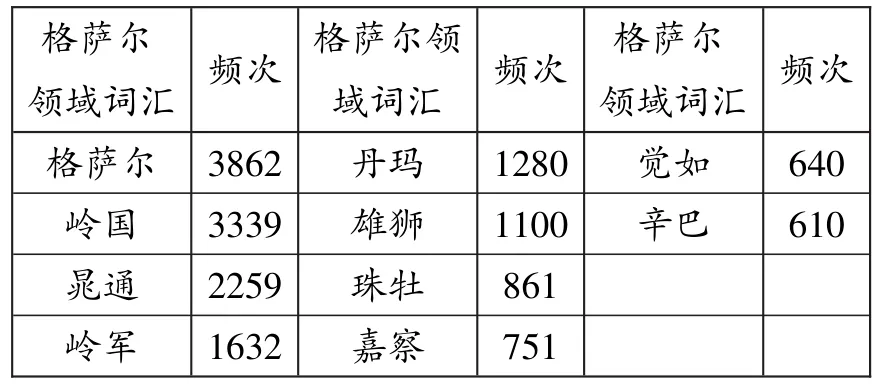
表2格萨尔领域词汇
从结构化的人物关系知识图谱数据中聚类并提取不同人物关系类型下的三元组知识图谱数据,主要包括以下三步。
(1)关系类型聚类
将所获知识图谱数据中的关系进行自动聚类,得到关系类型共19497种,按照关系出现频次由高到低排序,前10种关系及其频次如表3所示。
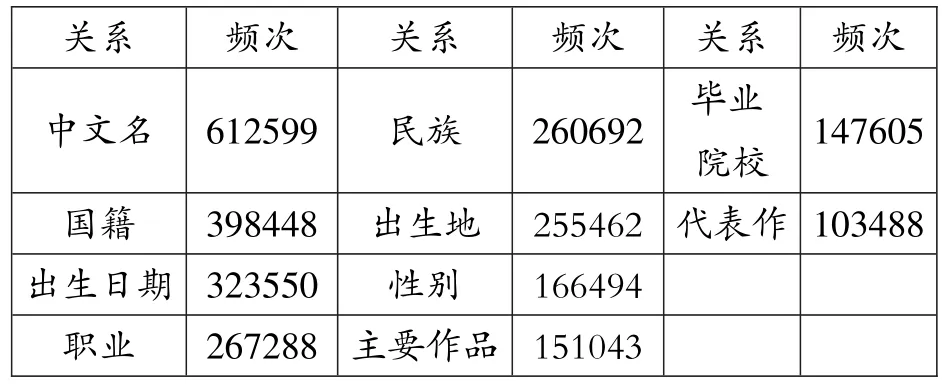
表3知识图谱中的关系类型
(2)人物关系手工筛选
手工筛选上述关系类型,得到人物相关的关系类型335种。考虑到领域文本数据量及史诗中人物关系类型有限,其中又没有复杂的远亲关系、现代职场人物关系等类型,因此从中选出“搭档、好友、父亲、妻子、儿子、母亲”这6种最高频的常见人物关系,并将其对应知识图谱数据用作人物关系分类训练的远程监督学习标注数据。根据出现频次以0-5为标签标记这6种关系,各类关系在前文提取的人物关系知识图谱中出现的频次数据如表4所示。
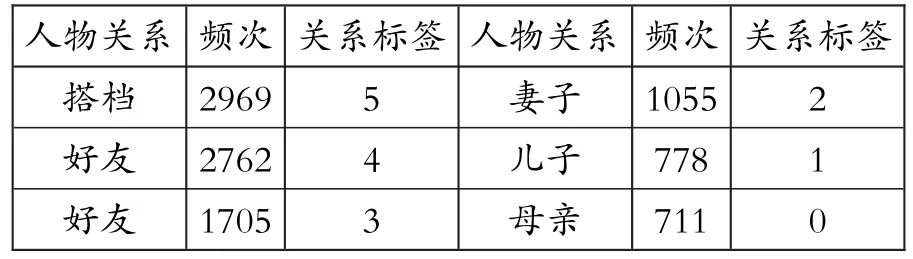
表4高频人物关系及其出现频次
(3)人物关系知识图谱自动筛选及数据处理
返回369万条三元组知识图谱数据库,从中自动提取这6种人物关系的知识图谱。由于三元组实体2大部分为独立人名,但少部分包括由多个人名组成的不规则表达方式,比如与“宋武公”关系为“儿子”的实体2内容为“宋宣公、宋穆公”。通过规则处理,将不规则实体2所在的知识图谱拆分并整理成多条由单个人名(命名为人名2)构成的三元组,如将(宋武公,宋宣公、宋穆公,儿子)拆分为(宋武公,宋宣公,儿子)和(宋武公,宋穆公,儿子)。
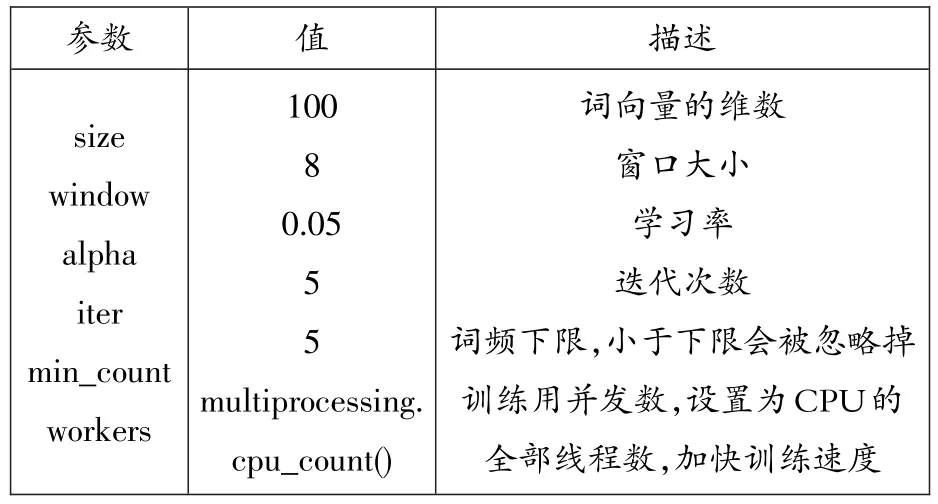
表5 Word2Vec模型的参数设置

表6词向量举例
经过上述人物关系的提取和人名拆分处理,最终得到9980条三元组知识图谱。
(二)实验模型训练
1.词向量模型训练
(1)Word2Vec模型训练
Gensim中Word2Vec的CBOW模型参数设置见表5。
整合分词后的格萨尔文本数据和百度百科人物介绍数据,用这一设置下的Word2Vec模型进行词向量训练,可得到维度为100的词向量模型。以实体“北京”“毛泽东”“格萨尔”为例,在训练好的词向量模型中,可获取三者的词向量表示如表6所示。
(2)Word2Vec模型验证
通过对通用领域常用词与常见人名、格萨尔学领域人名进行词语相关性验证来检验模型训练效果。通用领域常见词以词语“北京”为例,如表7所示,与其最为相关的10个词中,有9个为国内直辖市或省会城市,相关性在0.65以上,其中“上海”的相关性高于0.82。
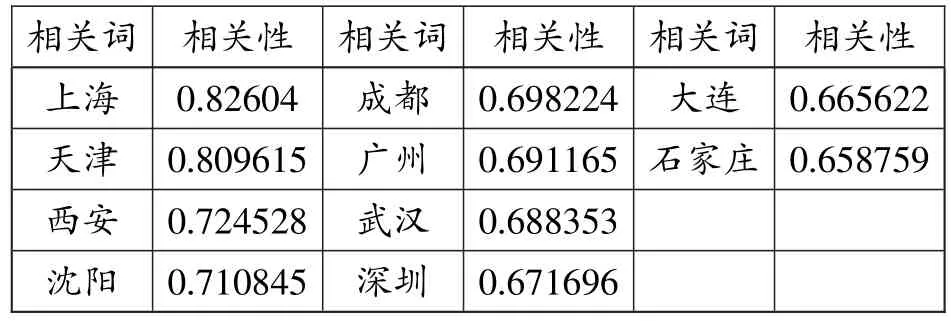
表7“北京”的部分相关词列表
通用领域常见人名以“毛泽东”为例,与其最相关的10个词中,相关性最高的“毛主席”一词与“毛泽东”语义相同;其余9个词均为与其极为相关的其他共产党早期创始人,或者党和国家领导人,且相关性均在0.73以上(见表8)。
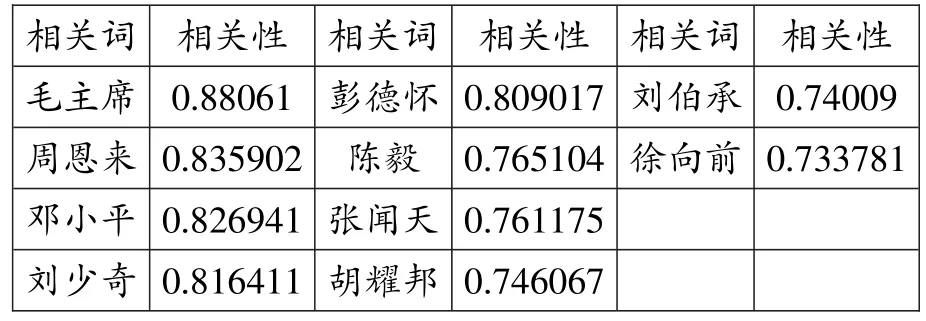
表8“毛泽东”的部分相关词列表
格萨尔学领域以“格萨尔”为例,相关性最高的“雄狮王”和排名第5的“觉如”均与“格萨尔”指向同一语义;其余8个词语中,除了“成吉思汗”,都是格萨尔学领域与格萨尔王具有重要关系的人物(见表9)。
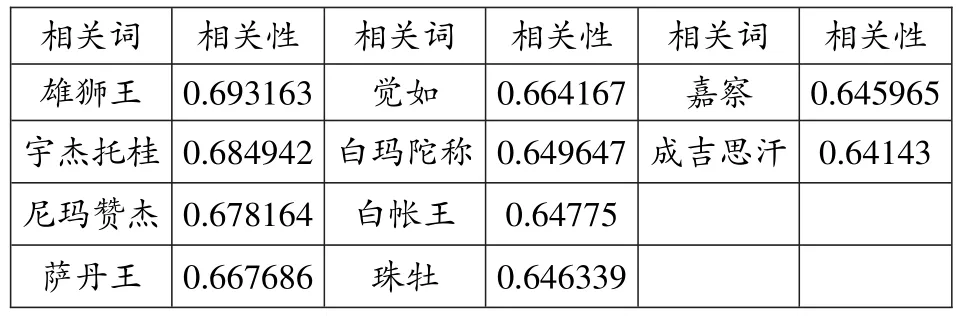
表9“格萨尔”的部分相关词列表
通过对以上三类词语的简要测试可基本证明CBOW词向量模型训练效果良好,经该训练的词向量可以作为后续远程监督训练的基础。
2.分类器模型训练
(1)分类模型训练数据准备
使用基于本文实验训练得到的词向量模型,遍历从知识图谱中提取并经过处理的9980条人物三元组知识图谱数据,并获取其中的人名1、人名2对应的词向量,过滤掉不存在词向量人名的三元组后,我们最终得到进行分类模型实验所需的9396条格式为(人名1 100维Word2Vec,人名2 100维Word2Vec,关系标签)的监督数据。将这些向量化的《格萨尔》领域人物数据进行欧式距离、词向量间余弦夹角、欧式距离归一化三种运算。运算结果显示,采用Python Numpy组件,先进行欧式距离归一化计算再训练深度神经网络的方法,能达到相对更好的训练效果,在训练数据中将正确率从原始的16.67%提升至52.65%(见表10)。
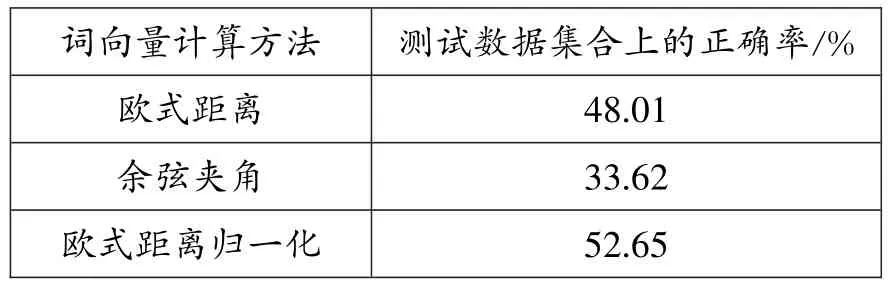
表10训练结果对比
确定词向量计算方法后,我们将实验数据按人物关系类型以19:1的比例(即5%作为测试数据)随机抽取为训练数据和测试数据,以进行格萨尔领域人物关系的预测。得到训练集数据8929条和测试集数据467条。
(2)基于TensorFlow的分类模型构建
本文利用深度学习技术,选用TensorFlow的Keras模块来实现一个深度神经网络分类网络模型。所用的TensorFlow版本为1.12.0,Keras模块的版本为2.1.6-tf。经过多次调参测试验证,测试效果较好的分类模型网络结构为包含四个Tensor-Flow.keras.layers.Dense层的序列,这些层是密集连接或全连接神经层。前三个Dense层具有1024个神经元,第四层(即最后一层)是具有6个节点的softmax层,该层会返回一个具有6个概率得分的数组,这些得分的总和为1。
按照上述参数设置好模型后,选择Adam算法的优化器,loss损失函数指定为sparse_categorical_crossentropy,即计算分类结果的交叉熵损失,然后进行模型编译。模型编译完成后,加载训练数据,进行20轮迭代训练。训练出的分类模型在测试集上表现较好,在测试集上正确率可达62.65%。由此可见,通过采用远程监督的方法,能以无前期人工标注的方式,通过较小的数据训练,也可以在人物关系分类这个细分任务上有相对较好的表现。
(三)关系预测实验与结果分析
1.实验准备
基于自动分词、规则处理及人工判别获取领域人名,可在保证人名词汇领域性的同时实现规模化抽取;提取《附录一〈英雄格萨尔〉主要人物》(以下简称《附录一》)中经过专家筛选与整理的领域主要人物人名,能较好地保障人物数据的完备性与高置信度。因此,我们对《英雄格萨尔》文本进行分词处理并从中提取人名,规模化获取领域主要人物名称,再融合《附录一》中高置信度的领域主要人物名单,得到较为完整的格萨尔领域主要人名列表。
首先,将格萨尔文本进行自动分词,经由人工判断过滤出主要人名。文本自动分词后得到51002个词汇数据,其中词频高于10的词汇6820个;在此基础上依据格萨尔文本内容对其进行过滤,获得1264个领域词汇;人工判断去除非人名词汇后得到格萨尔领域主要人名列表,共446个人名。然后,手工提取《附录一》中的人名,并对前文的人名数据抽取结果进行验证。《附录一》包含的161个人名中经过人工校对确认其中有82个词频高于10,其中76个出现在自动分词并过滤后的主要人名列表中,命中率达到92.68%。对未命中的其余6个人名进行原因分析,其中“娜噶卓玛”和“阿俄”包括在分词结果中,但词频统计次数不足10;“土地神、地方神、噶姆多吉”由于“土地”、“地方”和“多吉”是常见词,因此分词时被拆分为多个词汇;“达娃察琤”中存在生僻字“琤”,被OCR错误识别为“璋、睁、珍”,因而未被收录。最后,将分词并过滤后的人名数据与手工提取到的人名数据融合,获得较为完整的格萨尔领域主要人名列表,共计人名518个。
使用词向量模型从518个人名中过滤掉没有词向量表示的人名词汇,最后得到格萨尔领域有词向量表示的人名数据共344条,将其排列组合获得117992组(人名1,人名2)形式的数据对。根据人名共现位置过滤掉在全文中最近上下文距离超过20个词(停用词表里的词不计算)以上的人物组合,得到相对有效的人物组合(人名1,人名2)数据7010组,作为预测数据。
2.格萨尔领域人物关系预测实验及分析
在词向量空间中检索上述7010组格萨尔领域人物组合对应的词向量数据,并经过空间距离归一化计算,通过上述远程监督分类模型预测,得到7010组预测结果,如表11所示。
从中抽取部分置信度较高的预测数据进行手工验证,验证结果如表12所示。

表11格萨尔领域人物关系预测情况
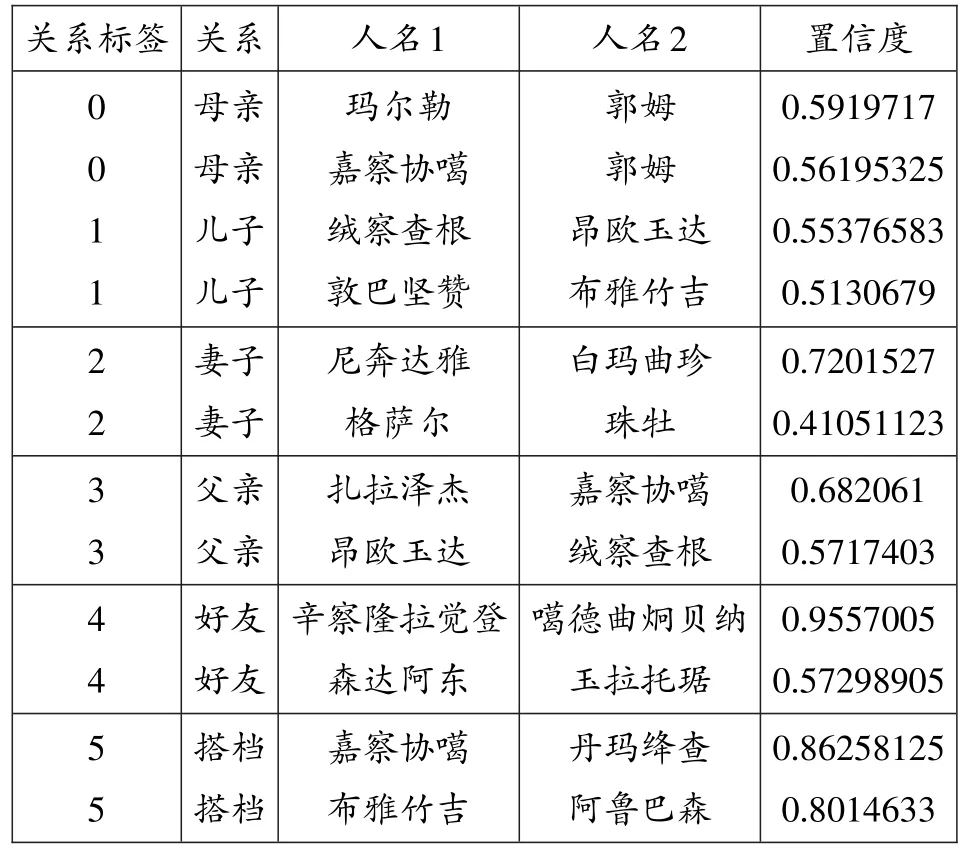
表12格萨尔领域人物关系预测结果验证
经检验,实验模型在1-5类人物关系预测中的置信度与正确率较高,表12中所示均为对领域人物关系的正确预测。以“搭档”关系中的人物对嘉察协噶与丹玛绛查为例,在窗口为20时,两人在文本中共现152次。“侄儿嘉察、大臣丹玛和我都去袭营成功”,“嘉察、达潘、丹玛、森达和司潘五个人,都要主动出门迎敌”等文本都明确体现了二者的搭档关系。
模型对标签0“母亲”关系下的人物关系预测结果在数量、置信度、正确率上较低于其他关系,但仍能得到大量具有解释性的预测结果。以“郭姆”为例,郭姆是格萨尔的生母,嘉察协噶与玛尔勒是格萨尔同父异母的兄弟,因此,相对其他关系类型而言,郭姆与嘉察协噶、玛尔勒的关系预测为“母亲”具有可解释性。
总体而言,实验所得预测模型对格萨尔领域人物关系进行预测可取得不错的效果。当模型在数据量较大、文本表述较为标准规范的数据集中进行预测时,预测结果置信度与正确率较高;对于训练数据量较小的关系类型,预测模型未必能做出精确判断,但在限定种类的关系预测中,预测结果解释性较强,一定程度上具有可信度。
结 语
本文提出了一种基于词向量和远程监督学习的新领域知识发现方法,并对其可行性进行验证,以期利用人工智能技术探索出一种可拓展的新领域知识发现方法,作为对基于规则的知识发现方法的补充。
传统的基于规则的关系抽取需要专家根据任务要求设置模式,而后从文本中找到与之匹配的实例推导出实体间的语义关系。[17]虽然在特定领域能取得较高的准确率,但需要在具有明确规则的前提下消耗大量人力成本,而且在移植效果和隐含知识发现方面存在不足。对专业领域,尤其是新领域的研究者而言,本文方法通过自动化技术减小了知识发现成本,并对细分领域的科研工作具有启发科研思路、提升科研效率的作用;通过这一方法所获的信息,能帮助相关工作人员更清晰准确地完成人名、主题的索引工作;本文方法基于高置信度的通用领域知识,并且在原始数据收集上具有领域无关性,因此能拓展到其他领域进行知识发现。
受实验数据的结构与规模、训练模型的特点与局限、自然语言本身的复杂性的制约,本文方法也存在一些不足之处。可考虑在扩大数据规模时增加不同版本出版物、专业研究文献、相似类型文本等,以获取更多的专业领域数据,选用LSTM等注重利用上下文数据关系的模型,结合基于远程监督学习与基于规则的知识图谱提取方式进行优化,以期通过多角度提升知识发现效果,以持续推动各领域知识图谱的构建和补全、各学科科研工作的创新与发展。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
少先队活动(2020年12期)2021-01-14
西藏艺术研究(2019年1期)2019-09-04
西藏艺术研究(2018年2期)2018-11-15
西藏艺术研究(2018年2期)2018-11-15
中成药(2017年3期)2017-05-17
西藏研究(2016年3期)2016-06-13
领导科学论坛(2016年9期)2016-06-05
高中生学习·高三版(2016年9期)2016-05-14
