
加权特征融合的密集连接网络人脸识别算法*
2019-07-11 07:29王小玉韩昌林胡鑫豪
计算机与生活 2019年7期
王小玉,韩昌林,胡鑫豪
哈尔滨理工大学 计算机科学与技术学院,哈尔滨 150080
1 引言
当今世界人脸识别在各个领域都有着广泛且重要的应用。人脸识别是通过分析人脸并提取有效的特征信息来完成身份鉴别的过程,人脸识别总体上分为三个步骤:人脸检测、特征提取、人脸识别。人脸识别的算法大致有三种类型:
(1)基于统计学的分析方法,如独立成分分析(independent component analysis,ICA)[1]。
(2)基于特征的方法,如Turk等人[2]提出的主成分分析(principal component analysis,PCA)子空间理论,Belhumeur等人[3]提出的Fisherface理论。
(3)基于弹性匹配(elastic matching,EA)的方法[4-5],如Cabor变换[6]的弹性匹配法。
因为卷积神经网络(convolutional neural networks,CNN)对物体的旋转、倾斜、缩放、平移等空间变换具有高度的特征不变性,因此在人脸识别领域中拥有得天独厚的优势。目前各大研究机构都发布了自己的人脸识别技术。如旷视科技的Face++[7],Face Book公司的DeepFace[8],以及香港研究组的DeepID[9-10]系列都取得了不俗的表现。
实验证明增加网络层数可以提高图像的识别率,因此几乎所有框架都朝着更深的方向发展,如InceptionNet[11]通过使用Inception Module模块并开创性地使用了全局平均池化层代替含有大量参数的全连接层,从而有效保证了网络的深度,但实验证明这种方法增加的深度有限,随着层数的增加会出现梯度扩散或消失等问题。He团队提出的深度残差网络(deep residual network,ResNet)[12],通过使用跳跃式连接将原始的特征信息直接与高层输出特征进行叠加,从而有效解决了随着网络深度增加梯度急速扩散的问题。但ResNet是一种短连接,并没有充分地利用底层特征信息。而传统的Softmax损失函数不足以在分类任务上实现最大化类间差异,从而导致其在非约束条件下识别效率不佳,因此一些改进的损失函数相继被提出。如与Softmax损失函数相结合的Center Loss损失函数[13],虽然可以减少类内特征的差异,但是并没有考虑类间的特征距离,从而降低了其识别率。
针对上述问题,本文提出了如下的解决方案。首先使用高维局部二值模式[14](highdimensional local binary pattern,HLBP)获得人脸的局部特征,其特征对不同曝光、表情变化等具有一定的鲁棒性同时又有效地刻画了人脸面部表情的细节变化;使用密集连接卷积神经网络(densely connected convolutional network,DenseNet)来提取人脸的全局特征,其特征突出的是不同人脸之间的差异程度而不是曝光、表情等方向上的变化,密集连接卷积神经网络有效地利用各层之间的特征信息并且有效地解决了随着网络深度增加所带来的梯度扩散等问题。实验中使用了加权连接,使得网络能够充分地利用各部分特征来提高其识别率。针对Softmax损失函数的不足,提出了多损失函数,不仅有效地增加类间距离,还能进一步缩小类内差异,很好地解决了因不同曝光、表情变化引起的类内特征之间差异性较大和类间相互重叠所导致的识别效果不佳问题。
2 算法原理
2.1 算法结构
根据上述提出的解决方案,设计出了如图1所示的算法总体框架。
如图1所示分别对人脸面部进行高维LBP的特征提取并进行降维处理,同时利用密集连接卷积神经网络提取人脸的全局特征。Wh、Wt分别表示全局特征和局部特征进行加权特征融合的权重比,并通过改进的中心损失函数Center Loss+与Softmax组成的多损失函数,进一步提高人脸的识别效率。
2.2 多损失函数
Softmax交叉熵损失函数常用在卷积神经网络中的分类任务中,其定义如下:



其中,λ为平衡因子,Center Loss损失函数主要起微调作用,因此其值一般小于1。类中心cyi更新如下:

其中,δ(yi=j)当yi=j时,值为1;否则为0。a为类中心向量的学习率,能够有效避免一些样本被错误标记所带来的影响。虽然Center Loss与Softmax的结合可以使类内特征分布更加紧凑,但是并没有很好地解决类间局部重叠问题。
因此本文在中心损失函数中添加了类间特征距离,这样既缩小了类内差异,又增加了类间的距离,有效提高了识别效率。改进的中心损失函数Center Loss+如下:

其中,N是人脸标签集合,ci和cj分别表示第i个类和第j个类的类中心,||ci||2和||cj||2分别表示对应坐标与原点之间的距离,λs为平衡因子。因此新的多损失函数可以表示为:

第k个类的类中心更新如下:

其中,yi是样本i的类别标签,|N|是人脸标签个数。
2.3 高维局部二值模式
在深度学习未出现在图像领域之前,局部二值模式(local binary pattern,LBP)算法占主导地位。其主要体现出了图像中的局部区域特征和周围区域特征的区别,常用的算法有SIFT(scale-invariant feature transform)特征、Garbor小波特征、HOG(histogram of oriented gradient)特征,以及局部二值模式(LBP)特征等。LBP因为具有定义简单,预算速度快,鲁棒性强等优势,因此常用于局部特征的提取。LBP特征提取流程如图2,具体步骤如下:
(1)取图像中的某一像素点并以此为中心创建一个3×3大小窗口。
(2)将中心像素点周围的8个像素分别与其比较大小,小于中心像素点的记为0,否则记为1。
(3)将这8位二进制数按顺序排列组成一个0~255内的整数。
(4)这个整数就对应着中心像素点的LBP值。

Fig.2 LBP feature extraction flow chart图2 LBP特征提取流程图
但是LBP也有一些固有的缺点,当在光照不均匀的情况下,LBP所提取的特征值就会发生变化。Chen等[14]在2013年提出了高维LBP特征,结果表明高维的LBP特征比LBP特征具有更好的鲁棒性,可以大幅度提高人脸识别率,具体方式如图3所示。

Fig.3 Extraction of high-dimensional LBP features:multi-key point selection and multi-scale sampling图3 高维LBP特征的提取:多关键点选取与多尺度采样
首先使用监督下降方法[15](supervised descent method,SDM)对人脸的关键部位进行定位,如眉毛、眼睛、鼻子、嘴巴,然后在这些关键点的周围提取出多尺度的LBP特征。本次实验的多尺度LBP特征通过固定采样窗口缩放图像的大小来获得,本文的高维LBP用于提取人脸图像特征的方法如图3所示。用d表示图像的LBP特征维度,公式如下:

其中,n为实验所选取的关键点个数;size为窗口的尺寸,即表明窗口内含有size2个子窗口;s为对原图像进行缩放的次数;k为LBP值的位数。
通过多尺度与多关键点结合的方法提取的特征不仅包含了局部的细节特征,还包含了整体的纹理特征,进一步提升了特征表达能力。
上述提取的高维LBP特征,并不能直接进行特征融合,需要对特征进行降维处理,去除特征中的噪声以及相关冗余信息后,再进行特征融合,减少计算量的同时提高了识别率。本文采用主成分分析(PCA)方法进行特征降维。PCA通过正交变化将原来一组可能存在相关性的n维特征空间转化成一组线性无关的k维空间(k<n),同时保证其转化后的特征值更加分散,提高了特征的辨别性。
2.4 加权密集连接卷积网络
2.4.1 密集连接网络
为了提取出更深层次的人脸特征,本文选用了具有良好扩展性和参数更少的密集连接网络[16]。在密集连接网络中每个密集连接模块内通过使用短连接方式使得每一层都能与其他层之间相互连接,每个层在获得前面所有层附加输入的同时又将自身的特征信息传递给后面所有层,从而有效地保证了网络中信息的高速流动,使得整个网络更加易于训练。与ResNet不同,DenseNet并没有把多个特征通过求和的方式组合成一个新的特征,而是将它们连接起来形成一个新的组合特征。因此每层之间就不需要学习一些多余的特征,从而大幅度减少了网络中的学习参数,这样不仅易于网络的扩展,而且有效缩短了网络的训练时间。
图4是密集连接网络的结构图与密集连接模块详解,其主要包括密集连接模块以及过渡层。

Fig.4 Weighted densely connected network图4 加权密集连接网络
密集连接模块:以Dense Block1为例。用X0表示输入图像,该模块一共包含3层,每一层在经过非线性变化Hs后得到下一层。Hs的执行顺序:首先对输入特征进行批量归一化(batch normalization,BN)[17]处理,使用参数修正线性单元(parametric rectified linear unit,PReLU)[18]激活函数后,对其进行1×1的卷积以此减少输入特征量,再对其进行PReLU激活以及3×3的卷积操作。若Xl为第l层的输出,则可用如下公式表示:

其中,xl-1表示模块的第l-1层特征的连接。若每层经过Hs处理后会生成k个特征图,那么第l层的输入特征有k×(l-1)+k0个,k0表示原始图像的通道数,其中k为超参数,用来控制网络宽度的增长。
过渡层:过渡层位于两个密集连接模块之间,主要是为了使不同模块之间的特征图尺寸能够进行匹配,一般执行顺序为批量归一化、PReLU激活、1×1卷积以及2×2的平均池化。
2.4.2 加权系数
在密集连接模块中层与层之间都是等价连接,但是在卷积神经网络中高层的特征往往比底层的特征更具有判别性,因此为了更加充分利用高层特征提高人脸识别率,本文分别对不同的特征层赋予权值,并且层数越深其权重越大。若一个密集连接模块共有S层,则第j层的权值设为:

上式中通过将前j层特征的权重进行叠加并除以连接模块中所有s层权重的和就得到了第j层的连接权重,从式中可以得出越是高层其所占的权重比越大。同时在式子中增加了权重系数μ(0<μ<1),训练前对μ进行随机初始化,在训练过程中不断地对μ进行调节。通过上述的加权连接进一步增加深层特征的连接强度,弱化底层的冗余特征。改进后第l层的输出用如下公式表示:
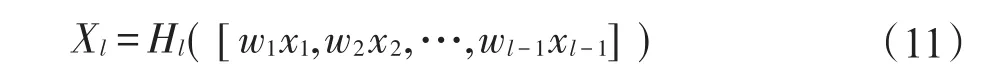
2.4.3 密集连接网络具体结构
为了验证随着网络深度的增加其对识别率的影响,本文分别设计了4种深度的密集连接网络结构,分别为46层、62层、78层、122层,具体结构如表1所示。
3 分析与讨论
3.1 加权密集连接网络结构
传统的卷积神经网络随着网络层数的增加网络性能会显著增强。但是在一定深度之后如果继续增加网络层数,则会因为参数过多导致训练时梯度扩散或消失,为了验证密集连接网络的有效性,本文在2.4.3小节4种不同深度的网络结构的基础上,设置了16和32两种模块宽度。表2就一些常见卷积网络模型及其参数量进行了对比。
由表2可知传统的AlexNet等神经网络,虽然网络层数较少,但是却包含了大量的参数,这也就进一步限制了其深度。通过对比可以发现22层的Google-Net和46层的DenseNet参数量相差并不大,目前研究发现152层RestNet拥有较好的识别效果,但其参数量却达到了61 MB,而122层的DenseNet参数量却只含有12 MB左右。因此密集连接网络的参数量远小于传统的卷积神经网络的参数量。
为了进一步探究密集连接网络结构对识别率的影响,按照表2的设计分别在4种网络层数上设置了两组宽度为16和32的网络结构。图5是不同宽度和深度的密集卷积连接网络在CASIA-WebFace上的识别率。从中可以得出,一方面识别率随着网络层数的增加而增加,另一方面在相同的网络层数下网络的宽度越宽,其正确识别率越高,尤其是在网络层数为62层时正确识别率提升得最多。通过本次实验可以得出增加密集连接卷积网络的宽度和深度,可以一定程度上提高其正确识别率。为了兼顾密集连接卷积神经网络的识别率和训练时间,没有特别说明本文一律使用宽度为32,深度为62的网络结构。

Table 1 Specific structure of weighted densely connected convolutional network表1 加权密集连接卷积网络的具体结构

Table 2 Different convolutional network models and parameter quantities表2 不同的卷积网络模型及其参数量

Fig.5 Recognition accuracy under different conditions on CASIA-WebFace图5 在CASIA-WebFace上不同条件下的识别准确率
3.2 PCA特征降维
本文参考文献[19]的方法,将人脸分别缩放至300、212、150、106四种不同尺度的像素大小。使用5×5的采样窗口对16个关键点依次进行采样,每个采样窗口的子窗口大小设置为12×12像素。为了解决二进制模式中维数过高问题,实验中采用“等价模式(uniform pattern,UP)”[20]来提高其统计性。对于3×3邻域内中的8个采样点,通过该方法计算将得到1个混合模式和58个等价模式。通过式(1)可以得出该方法提取的高维LBP特征的维数是94 400(59×16×4×52)维。
在特征融合过程中,局部特征与全局特征的权重比对最终得到的融合特征有着深远的影响,由于密集卷积网络模型所提取的特征识别效果要优于高维LBP特征,因此本次实验在CASIA-WebFace数据集上对待融合的高维LBP特征维数进行PCA降维,再对降维后的局部特征和全局特征进行权重分配,结果如表3和图6所示。

Table 3 Face recognition accuracy under different dimensions表3 不同维数下人脸识别正确率
表3实验将94 400维的高维特征通过PCA方法分别降至64 000维、32 000维、16 000维、9 600维、3 200维和1 600维,即将原来16个关键点中每个关键点的5 900维特征分别降至4 000维、2 000维、1 000维、600维、200维和100维。通过实验对比可以发现,降维后的高维LBP特征与不同深度的密集连接网络提取的特征进行特征融合,经过有分类的监督训练后,在识别效果上存在着一定的差异。在特征降至3 200时取得了比较好的识别率,再继续降低维数则会破坏特征的完整性。因此实验证明了在高维LBP特征降至3 200维时能够很好地保留原特征信息。

Fig.6 Face recognition accuracy under different local feature weight ratios图6 不同局部特征权重比下的人脸识别准确率
在确定最佳维度后,对局部和全局特征进行加权融合,从图6可以得出不同的特征权值其识别效果也有所差别,当局部特征的权值为0.2时整个网络达到最佳的识别效果。因此之后没有特别说明,则默认局部维数为3 200维,权重因子为0.2,即全局特征权重为0.8。
4 实验结果与分析
为了验证本文提出的加权特征融合密集连接网络的有效性,本文将在CASIA-WebFace人脸数据集上进行训练和验证,并在非约束条件下对LFW数据集和MegaFace数据集下进行测试。
4.1 CASIA-WebFace数据集实验
4.1.1 CASIA-WebFace数据集与相关预处理
CASIA-WebFace[21]是人脸识别领域中最重要的大规模数据集之一,它包含了10 575人的494 000多张带有标签的人脸图像,其训练集大小只有0.49 MB。本文先除去数据集中与LFW和MegaFace属于同一人的人脸图片,在余下中选取2 580人共122 875张人脸图片,并把这些图片按7∶2∶1的比例划分为训练集、验证集和测试集。并对训练集中的人脸图像进行预处理,具体步骤如下所示:
(1)获得人脸图像中最大人脸区域,去除人脸区域外干扰。
(2)在图像中设置关键点,根据鼻子和眼睛进行仿射变换,尽量使得双眼齐平,鼻子居中。
(3)再对人脸图像进行进一步处理使其大小为112×112。
(4)对读入图像的各个通道进行零均值化处理,加速模型的收敛。
在此基础上对输入的图形进行旋转平移操作,并对原258×258的图像进行随意裁剪使其变为112×112,这样可以成倍地提高样本的数量,进一步提升模型的鲁棒性。同时按照2.3节的方法提取高维LBP特征。
实验中使用宽度为32,深度为62的密集连接网络结构来提取人脸全局特征,网络具体配置见表1。使用等价模式提取出94 400维的高维局部特征,再经过PCA对其进行降维处理,通过表3的实验分析,最终选择将局部特征降为3 200维,局部权重因子设置为0.2。
实验采用随机梯度下降法进行训练,批处理大小设为32,初始学习率为0.1,每迭代1.2×104次,学习率调至原来的10%,平衡因子λ和λs都设置为0.005,密集连接模块的权重系数μ初始化为0.1,动量大小设为0.9,权重衰减为0.005,训练迭代到100万次结束时结束。
4.1.2 实验结果与分析
本次实验在CASIA-WebFace上对不同网络的识别效果进行了比较。测试过程中随机地对待测图片进行不同程度的遮挡和旋转处理。示例如图7所示,实验结果对比如表4所示。
通过表4的实验对比可以得出,基于本文所提出多损失函数以及局部与全局的加权特征融合所提取的特征相较于其他神经网络所提取的特征更加具有区分性。表中Fuse-Net(Yes)和Fuse-Net(No)分别表示加权特征融合和非加权特征融合。通过在正常图和旋转图下的识别率,可以发现虽然Center Face与DeepID的训练数据集大小与本文相当,但在各种条件下其识别率都有所下降,而且比在大数据集下训练的Deep FR和DeepFace的识别率都高。对于FaceNet这种拥有超大规模的训练数据集,在正常和旋转情况下其网络识别效率也仅仅相差0.45%和0.08%,而且在遮挡的条件下其识别率同FaceNet一样并没有明显下降,足以说明本文提出算法框架的优越性。在闭集条件下加权与非加权特征融合两者的识别率有细微的差距,但总体相当。

Fig.7 Test set example:normal,rotated,partially occluded图7 测试集示例:正常图、旋转图、部分遮挡图

Table 4 Correct recognition rate under different network structures表4 不同网络结构下的正确识别率
为了验证本文提出的损失函数的性能,在实验中保持其他设置完全相同的情况下分别对常用的损失函数进行了训练和测试。
通过表5的实验结果对比,本文提出的损失函数不仅在正常图集下拥有最好的正确识别率,而且在有部分遮挡的情况下其正确识别率仅下降了2.89%,远低于其他损失函数的下降幅度,足以体现出在中心损失函数中添加类间特征距离所带来的效果。
4.2 非约束条件下的实验结果与分析
为了验证本文提出的加权特征融合的有效性以及泛化能力,本次实验在非约束条件下的LFW数据集和MegaFace数据集上进行测试,在CASIAWebFace数据集的模型训练中已经去除了与LFW和MegaFace数据集中属于同一个人的人脸照片。

Table 5 Correct recognition rate under different loss functions表5 不同损失函数下的正确识别率 %
4.2.1 数据集与相关预处理
实验中使用4.1.1小节的人脸图像预处理方法,然后通过密集卷积神经网络提取出其深度特征,并同时提取其对应的高维LBP特征。
4.2.2 实验评估与测试流程
人脸验证即判断两个图片是否是同一个人,其本质上就是一个二分类问题。在进行验证测试时,首先从全连接层中获得用于人脸验证对里每张人脸的输出特征。然后图片对之间的相似性通过余弦距离来计算,把得到的余弦距离作为图片对的特征值,是否匹配作为其标签。最后采用十折交叉验证法对支持向量机[23](support vector machine,SVM)分类器进行训练并获得最终的验证准确率。
4.2.3 LFW数据集实验
4.2.3.1 LFW数据集
LFW[24]数据集包含了5 749个人超过13 000多张自然环境下的人脸图片。由于在自然环境下人脸常常受到光照、表情以及遮挡等因素的影响,给识别带来了巨大的挑战。
实验中使用包含6 000对人脸的View2测试集,一共包含十折,每折各包括300对匹配的人脸和不匹配的人脸。如图8所示。
4.2.3.2 实验结果与分析
在本次的开集实验测试中,将分别验证上述网络在非限制条件下的泛化能力。

Fig.8 Example of View2 face pairs in LFW图8 LFW中的View2人脸对示例
通过表6的实验对比可以发现,本文所提出的加权特征融合的密集连接网络在FLW数据集下取得了相当好的识别效果,比同样小数据集下的Center Face高出3.89%。即使在大数据训练集下识别效率也高于Deep Face和Deep FR,与超大训练数据下的FaceNet的准确率相当,体现出了本文算法框架具有很好的泛化能力。在表4中的闭集测试条件下,可以得出加权特征融合和非加权特征融合其识别率几乎一样,但是在本次开集的实验条件下可以看出,加权特征融合拥有更高的准确率,说明本文提出的加权特征融合网络所提取的特征拥有更好的区分度。

Table 6 Verification accuracy of different networks under LFW dataset表6 不同网络在LFW数据集下的验证准确率
4.2.4 MegaFace数据集实验
4.2.4.1 MegaFace数据集
MegaFace[25]是一个加入了百万级干扰项的公开人脸测试数据集。MegaFace数据集包含了人脸验证、人脸训练、人脸确认等多个应用场景。
MegaFace规定训练集在0.5 MB以下的为小数据集,0.5 MB以上的为大数据集,而本文提出的网络是在小数据集下进行训练和评估的。
4.2.4.2 实验结果与分析
通过表7的实验对比可以发现,同样是在Mega-Face小数据集下的测试结果,本文提出的加权特征融合的密集连接网络比Deepsense-Small的识别率高出4.64%,并超过了大规模数据下DeepFace的识别率。但是与超大规模数据集FaceNet和Deepsense-Large相比还存在一些微小的差距,但足以体现出本文算法在非约束条件下具有良好鲁棒性。

Table 7 Verification accuracy of different networks under MegaFace dataset表7 不同网络在MegaFace数据集下的验证准确率
5 结束语
本文提出加权特征融合的密集连接卷积神经网络,通过使用加权密集连接网络一方面可以有效地减少网络的参数量,从而降低因层数增加而导致的训练过程中梯度扩散或消失等问题;另一方面层与层之间通过加权连接可以使特征更加高效地传递。并对提取出的全局与局部特征进行加权融合,在全局特征的基础上增加了具有判别性的局部特征,通过在Center Loss中添加距离类间特征距离,减少了类与类之间的重叠,使得特征之间更加具有区分性,进一步强化其非约束条件下的识别效果。本文算法后续将致力于损失函数的改进,使其在训练过程中更快地收敛,减少训练时间。
猜你喜欢
计算技术与自动化(2022年1期)2022-04-15
今日农业(2021年9期)2021-11-26
英语文摘(2021年2期)2021-07-22
计算机技术与发展(2020年2期)2020-04-15
世界知识画报·艺术视界(2017年7期)2017-07-27
中国高新技术企业(2017年5期)2017-05-05
今日中国(2017年3期)2017-03-31
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
电脑知识与技术(2016年24期)2016-11-14
