
基于Structure2vec算法的网络欺诈风险特征选择与评估
2019-06-10 01:01张宝明魏程益
软件导刊 2019年2期
张宝明 魏程益


摘 要:现有特征选择算法往往只能处理简单的拓扑结构图形,对复杂的拓扑结构图形无能为力,为此选择Structure2vec算法对网络欺诈风险进行研究。在梳理相关文献基础上,对Structure2vec的数学原理进行分析,给出其对应的卷积神经网络模型;选择网络用户的信用历史、身份特质、行为偏好、履约能力和社会关系等5种类型特征数据,构建Stucture2vec关系图;利用Structure2vec算法编写Python程序,对样本数据进行训练,获得模型;利用测试数据对模型进行测试,获得特征向量和对应的风险评估值。结果表明,利用Structure2vec算法对网络欺诈风险进行特征选择和评估,效果优于一般卷积神经网络。
关键词:Structure2vec算法;特征选择;特征向量;欺诈风险;神经网络;损失函数
DOI:10. 11907/rjdk. 181935
中图分类号:TP301文献标识码:A文章编号:1672-7800(2019)002-0028-06
Abstract: The existing algorithms of feature selection can only handle simple topological structures and are incapable of designing complex topological structures. Therefore, the Structure2vec algorithm is chosen to study the risk of network fraud. On the basis of combing the related literature, the mathematical principle of Structure2vec is analyzed, and the corresponding convolution neural network model is given. Then, the five types of characteristic data are selected to construct the relation diagram of Stucture2V, including the user's credit history, identity, behavior preference, performance and social relations. Next, the Structure2vec algorithm is used to write Python program, train the sample data and obtain the model. Finally, the model is tested with the test data to obtain the eigenvector and the corresponding risk assessment value. The results show that the Structure2vec algorithm is better than general convolution neural network for feature selection and evaluation of network fraud risk.
Key Words: structure2vec algorithm; feature selection; feature embedding; fraudulent risk; neural network; loss function
0 引言
近年来,网络金融迅猛发展,大数据金融、第三方支付、P2P、众筹、供应链金融等新业态、新方式不断涌现。然而,由于网络金融的网络性、虚拟性,产品的跟风性、缺陷性,加上人群的多样性、贪婪性以及信任管理的淡薄性、困难性,欺诈风险不断出现,返利套现、薅羊毛、贷款失踪、P2P跑路与ICO诈骗等乱象频繁发生。为此,利用机器学习、人工智能、大数据等方法,评估、跟踪、预警网络欺诈风险,并将其控制在一定范围内,显得尤为重要。基于此,以Structure2vec算法为例,分析了网络欺诈风险的特征选择与评估方法。
过去几年,随着Word2vec的盛行[1,2],相关专家学者已将机器学习与人工智能的焦点集中到特征选择上。特征选择对提高算法性能和预处理关键数据发挥了很大作用,已成为当前深度学习和模式识别的重要利器与核心主题之一,在声音处理、图像与视觉识别、风险控制等领域得到广泛应用。
国内文献[3-5]将特征选择称为特征子集选择(Feature Subset Selection,FSS )或属性选择,目的是通过一系列特征选择算法,对原始特征数据进行映射,去除一些不相关特征,保留一些有效特征,并在另外一个空间上生成新的表达——特征向量,从而有效降低数据维度。因此,特征向量是特征选择的结果,是一种数据表示方式。与原始特征数据相比,其在保存更多有用信息的同时,形式更简單,更易访问,泛化(generalization,是指对以前未观测到的数据表现良好)能力更强,更能将相似特征映射到一起,当然不可避免也会受到一些惩罚和限制。
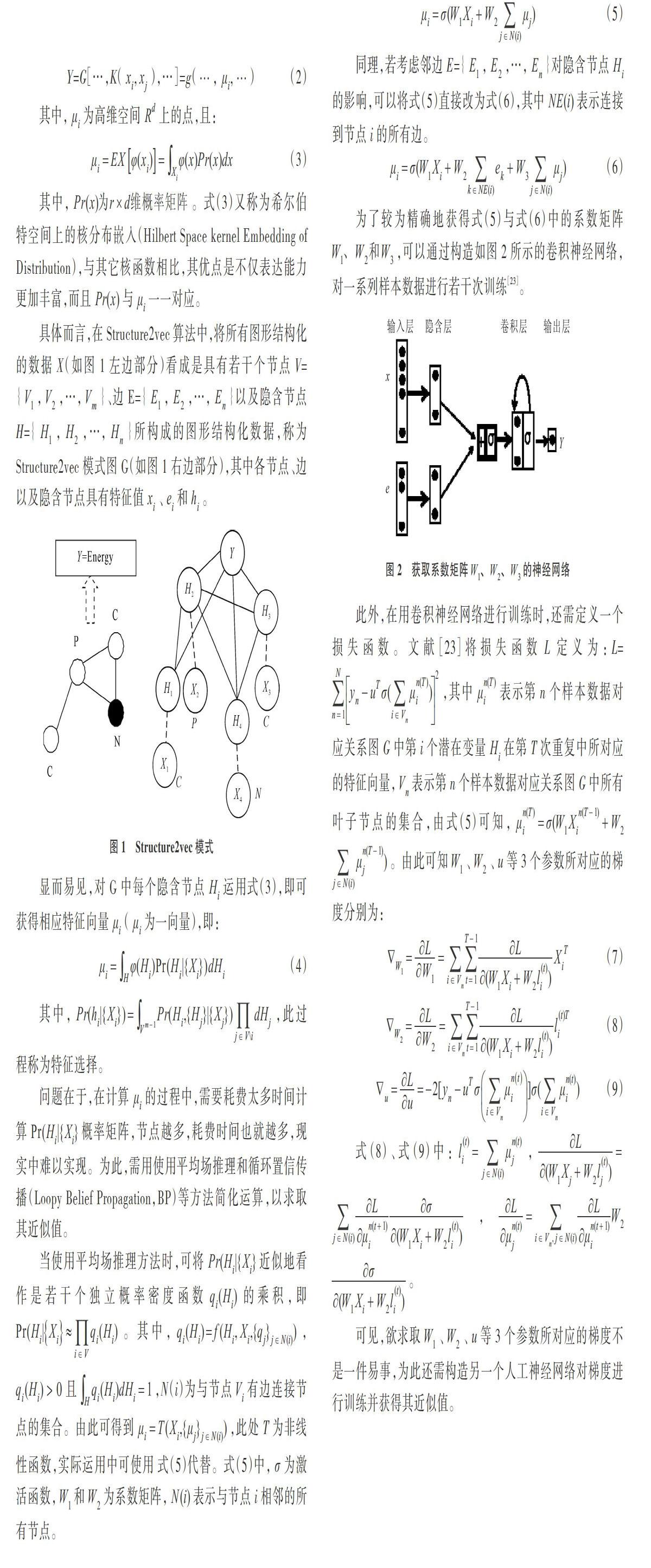
国外文献[6]将特征选择在数学上定义为一个映射,该映射满足单射性和结构保存性,前者意味着每个值域中的Y在定义域中只能有唯一的X与其对应,后者说明在X所属空间上若有[x1 过滤方法是指从原始特征中直接选择特征子集,用于后续机器学习算法[11-15]。由于过滤方法在选择特征子集时,并没有考虑后续机器学习算法模型,因而可能会导致选择出的特征子集不适合后续学习算法,从而影响学习性能(准确率)。包装方法使用一个预测模型对所有可能的特征子集进行评分,从而寻找到一个能使后续学习算法达到较高性能的子集。具体而言,即在特征子集的保持集上进行测试,计算出错次数并给出相应得分,最终获得最优特征子集。由于包装方法需要为每个子集训练一个新模型,因此计算量非常大[16,17]。而嵌入方法是通过学习自身以自动选择特征,其方法多种多样,主要包括正则化方法(如Lasso算法)、Ridge算法(岭回归数值计算)、支持向量机、决策树和深度学习等。Lasso算法是一种压缩估计,保留了子集收缩的优点,通过构造一个惩罚函数得到一个较为精炼的模型,同时压缩一些系数,将其设定为0,是一种处理具有复共线性数据的有偏估计算法,其改进算法包括Bolasso、Elastic Net、FeaLect等[18,19]。此外,利用深度学习,可以对包括文字和声音在内的序列数据进行特征化(典型方法如Word2vec),对包括图像在内的二维数据进行特征化(典型方法如CNN),对结构化数据进行特征化(典型方法如Structure2vec)。所有这些嵌入方法,其算法复杂度均介于过滤方法与包装方法之间。 Structure2Vec提供了一种能够同时整合节点特征、边特征、异构网络结构以及网络动态演化特征的深度学习和推理的嵌入技术,它不仅可以对网络中的节点和边进行推理,还可以对节点、边甚至子图进行嵌入(Embedding,又称向量化)。在Embedding算法中,普遍使用核的算法,将输入数据映射到一个高阶向量空间,从而能更好地解决分类或回归问题。 国外文献[20]将核方法(Kernel Methods,KMs)表述为一类模式识别算法,其目的是找出并学习一组数据中的相互关系。核方法的主要思想是基于如下假设:在低维空间中不能线性分割的点集,转化为高维空间中的点集时,很有可能变为线性可分的。相对于使用通用非线性学习器直接对原始数据进行分析,核方法具有明显优势:首先,通用非线性学习器很难反映具体应用问题的特性,而核方法由于面向具体应用问题进行设计,反而便于集成相关问题的先验知识;其次,核方法的线性学习器相对于通用非线性学习器,有更好的过拟合控制,从而可以更好地保证泛化性能;第三,更重要的是,核方法还是实现高效计算的途径,它能利用核函数将非线性映射隐含在线性学习器中进行同步计算,从而使得计算复杂度与高维特征空间的维数无关。常见的核函数有费舍尔内核、图形内核、核平滑、多项式核函数、径向基函数核(Radial basis function kernel,RBF)、字符串核等。相关算法包括支持向量机(Support Vector Machine,SVM)、径向基函数(Radial Basis Function,RBF)、线性判别分析(Linear Discriminate Analysis,LDA)以及高斯过程等, 这些算法通过对凸优化问题[21]或者特征值问题进行求解获得结果[22]。 总之,Structure2Vec是一种新的特征选择算法,其中使用了核方法。与前人研究相比,本文系统地阐明了其算法原理,改正并重写了其算法程序,并将其应用于网络欺诈风险评估,通过与一般卷积神经网络效果对比,进一步验证了算法的有效性。 1 Structure2vec算法原理 鉴于文献[23]对Structure2vec算法的数学原理分析含糊不清,在使用Structure2vec算法进行网络欺诈风险评估之前,笔者先对其数学原理进行阐述。 1.1 相关数学基础 1.2 Structure2vec算法描述 其中,[Pr(x)为r×d维概率矩阵]。式(3)又称为希尔伯特空间上的核分布嵌入(Hilbert Space kernel Embedding of Distribution),与其它核函数相比,其优点是不仅表达能力更加丰富,而且[Pr(x)]与[μi]一一对应。 具体而言,在Structure2vec算法中,将所有图形结构化的数据X(如图1左边部分)看成是具有若干个节点V={[V1],[V2],…,[Vm]}、边E={[E1],[E2],…,[En]}以及隐含节点H={[H1],[H2],…,[Hn]}所构成的图形结构化数据,称为Structure2vec模式图G(如图1右边部分),其中各节点、边以及隐含节点具有特征值[xi]、[ei]和[hi]。 问题在于,在计算[μi]的过程中,需要耗费太多时间计算[Pr(Hi|{Xi}]概率矩阵,节点越多,耗费时间也就越多,现实中难以实现。为此,需用使用平均场推理和循环置信传播(Loopy Belief Propagation,BP)等方法简化运算,以求取其近似值。 当使用平均场推理方法时,可将[Pr(Hi|{Xi}]近似地看作是若干個独立概率密度函数[qi(Hi)]的乘积,即[Pr(Hi|Xi≈i∈Vqi(Hi)]。其中,[qi(Hi)=f(Hi,Xi,{qj}j∈N(i))],[qi(Hi)]> 0且[H qi(Hi)dHi=1],N(i)为与节点[Vi]有边连接节点的集合。由此可得到[μi=T(Xi,{μj}j∈N(i))],此处T为非线性函数,实际运用中可使用 式(5)代替。式(5)中,[σ]为激活函数,[W1]和[W2]为系数矩阵,[N(i)]表示与节点i相邻的所有节点。 同理,若考虑邻边E={[E1],[E2],…,[En]}对隐含节点[Hi]的影响,可以将式(5)直接改为式(6),其中[NE(i)]表示连接到节点i的所有边。
猜你喜欢
眼科新进展(2023年9期)2023-08-31
眼科新进展(2022年12期)2022-12-29
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
中国外汇(2019年10期)2019-08-27
电子制作(2017年23期)2017-02-02
公民与法治(2016年24期)2016-05-17
西北工业大学学报(2015年4期)2016-01-19
振动工程学报(2014年4期)2014-03-01
