
融合深度学习与机器学习的在线评论情感分析
2019-06-10 01:01刘晓彤田大钢
软件导刊 2019年2期
刘晓彤 田大钢


摘 要:情感分析可以帮助商家了解客户喜好从而生产出满意度更高的商品,也可以监督网上舆论等。为此,基于传统机器学习方法,加入深度学习模块,对在线评论进行情感分析与对比。在词向量训练模块中引入Word2vec模型,用高维向量表示词语、句子,既可防止过度拟合问题,又可减少训练参数个数,提高训练效率。将得到的句向量作为输入代入机器学习模型(MLP、SVM、朴素贝叶斯等)与深度学习模型(CNN、LSTM、BILSTM等),比较实验结果,提出优化方向。结果表明,基于深度学习的情感分析模型准确率明显高于单一机器学习模型,但是深度学习需要大量语料,对实验机器要求也较高,很难完全展现其魅力。
关键词:情感分析;深度学习;机器学习;Word2vec模型
DOI:10. 11907/rjdk. 182576
中图分类号:TP301文献标识码:A文章编号:1672-7800(2019)002-0001-04
Abstract:Sentiment analysis is very important,it can help merchants understand the preferences of customers so that they can produce more satisfying goods, and it can also supervise online public opinion. This paper is mainly based on the traditional machine learning method to give the results and do the comparison by employing the deep learning module. A total of two modules can be divided. First, the word vector training module introduces the Word2vec model, and uses high-dimensional vectors to represent words and sentences. Here, the pre-trained Word2vec model is introduced, which not only prevents the over-fitting problem, but also reduces the number of training parameters and improves the training efficiency. The second is to enter the obtained sentence vector as the input into the machine learning model (MLP, SVM, Na?ve Bayes, etc), deep learning model (CNN, LSTM, BILSTM, etc), compare the experimental results, and propose the optimization direction. The accuracy of sentiment analysis models based on deep learning is significantly higher than that of a single machine learning model, but deep learning requires a large amount of corpus, and the requirements for experimental machines are relatively high. It is difficult to demonstrate its charm fully.
Key Words: sentiment analysis; deep learning; machine learing; Word2vec model
0 引言
情感分析又称意见挖掘、倾向分析,是自然语言处理领域的一个基础任务,其目的是利用机器提取人们对某人某物或者某事件的态度是正向支持还是反向反对,从而发现潜在问题并加以解决,或者进行预测以预防新问题产生。
近年来,互联网迅速发展,人们日常生活多方面都离不开网络,微博、电子商务平台等热门应用吸引了大量用户,由此产生大量用户参与的对于任务、事件、产品等有价值的评论信息。如此一来,也影响了社会信息传播格局[1]。这些评论信息大都包含了人们的情感色彩和情感倾向,如喜、怒、哀、乐以及批评、赞许。随着新兴社交平台的发展,网民数量呈爆炸式增长,大量评论信息迅速传播[2]。对在线评论进行情感分析,实施急需的网络安全监管有重大意义[3-4]。但是,面对如此海量的信息,仅仅依靠人工挖掘是不够的,因此如何高效地进行情感分析、意见挖掘变得至关重要。
目前中文文本情感分析主要分为三大类:第一类是基于词典的词典匹配法,需要很完备的高质量词典支持。常见的情感词典包括WordNet[5]、General Inquier(GI)等。Kim等[6-7]利用情感词典对种子情感词进行扩展,并得到对种子情感词分析影响较大的结论。第二类是基于机器学习的情感分析,机器学习极度依赖语料,将手机语料训练出来的分类器用来给书评分类注定要失敗,但是其整体准确率还是非常乐观的。第三类则是运用近来比较火热的深度学习算法,在有大量全面训练语料的情况下,深度学习在情感分析方面的成效非常可观。Bengio 等[8]提出采用神经网络构建分布式词向量,Mikolov等[9]提出了Word2ve模型,Kim等[10]提出采用 Word2vec预训练得到词向量。随后,梁军等[11]利用深度学习方法进行中文微博情感分析工作。
21世纪初,情感分析就已经在自然语言处理领域研究中活跃起来,尤其是在数据挖掘、文本挖掘等方面表现极为突出。传统的无监督方面主要是以情感词典为代表,为了准确识别情感词,肖江等[12]构建了基准情感词典以及相关领域情感词典,其主要核心是采用相似度计算确定情感词的情感倾向。文献[13]也是基于词典的情感分析,采用的方法则是扩展点互信息So-PMI算法,该方法机械地将分好词后的文本信息与情感字典匹配从而确定其情感倾向,其结果虽然优化了,但是依然存在很大缺陷。比如:“好开心啊,我中了五百万!”情感词典匹配法会把此处的“好”和“开心”都标记为情感词,而实际上“好”不过是一个程度副词用来修饰“开心”而已。基于词典的情感会因为詞典匹配语义表达的丰富性而出现很大误差,而且分类准确率过于依赖词典,而新兴词语太多,对于词典的补充也太浪费时间人力。由此可见,传统的情感词典方法在情感分析中表现不是很理想。机器学习则需要大规模人工标注工作,并通过计算机进行训练求解,其分类结果过于依赖标注数据集。好的分类器就要依赖一个好的数据集,如此不但可大量减少人工工作,节省人力时间,而且分类结果上也较为可观。Catal等[14]采用朴素贝叶斯算法、支持向量机、Bagging算法等多种分类器进行情感分析,最终利用投票算法确定分类的最终结果。Liu等[15-16]将 Co-training 协同训练算法与 SVM 相结合进行推文的情感分析,Co-training 协同训练算法可以实现语料半自主标注,省时省力,再利用 SVM 算法实现推文的情感分类。但是机器学习模型在判断文档和句子的情感倾向时,跟情感词典法一样,极有可能忽略文本中不带感情色彩的情感词。卷积神经网络(CNN)是一种基于卷积运算的神经网络,随着研究深入,人们发现CNN也可以用于自然语言处理任务,尤其是分类任务,有人提出基于CNN模型的情感分析,其是使用CNN学习句子的向量表示,然后再进行分类任务。李阳辉等[17]提出基于深度学习的细粒度情感分析,分析对象来自不同语料,包括评价词典、微博、影评、知乎等,分析粒度从词语级别到篇章级别。 时至今日,在谷歌Word2vec工具开源后,词向量的学习方法多种多样,结合深度学习方法进行建模在自然语言处理多个领域取得了巨大突破[18-20]。目前最有效和流行的词向量表示方式依然是Word2vec,其训练方法简单,直接调用python工具中Gennsim的Word2vec方法即可,也是本文选择用来训练词向量的工具。
1 数据预处理
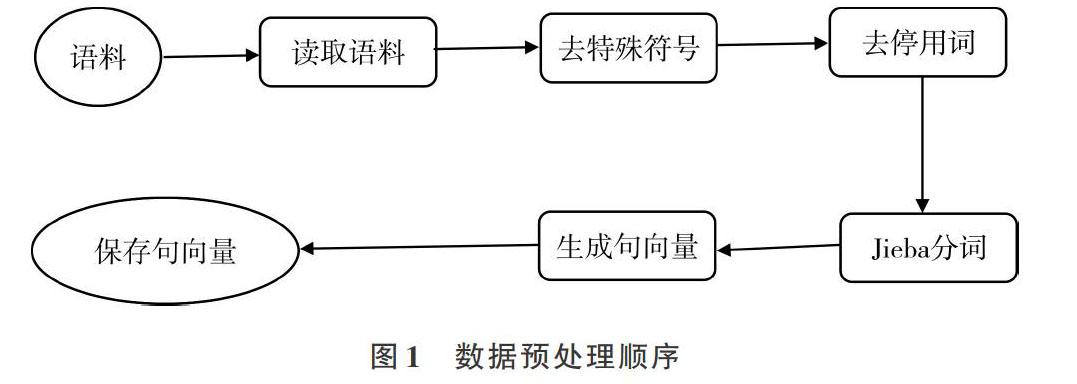
预处理主要是对数据进行标准化处理,并且训练词向量,数据预处理活动可大致表示如图1所示。
1.1 数据集
本文训练情感分析模型所用数据来自于网上各种新闻评论和商品评论(购买和爬虫获取),其中共11个大类,每类抽取2 000条数据,总计22 000条语料。格式如图2所示。
1.2 数据清洗及分词
数据清洗是指将收集到的数据集整理成后面实验可用的形式,其中工作主要包括繁简转化、停用词与特殊符号去除。中文繁简转换工作很容易实现,可以依靠Linux系统中自带的OpenCC工具,直接对数据集文件执行opencc命令即可。
命令行输入:opencc-i inputfile.txt-o outputfile.txt-c zht2zhs.ini
其中inputfile.txt是输入等待转换的数据集,outputfile.txt是转换好的输出文件名。对于数据集中的特殊符号则需用Python正则化方法,即re正则表达式。
数据清洗后即可以进行分词操作,本文采用的是分词工具是“结巴”分词,支持3种分词模式:一是精确模式,它试图将句子最精确地切开,适合文本分析;二是全模式,它把句子中所有可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;三是搜索引擎模式,在精确模式基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。举例如下:
1.3 情感词向量
建模环节中最重要一步是特征提取,在自然语言处理中也不例外。为了将一个句子转化成可以用数字表示的有效实现,有人提出,可以把每个词语都用一个对应数字表示,而且相近词语给予相近编号,该方法看似解决了问题,但事实结果并不乐观,因为忽略了语义因素。语义不是单一的,而应该是多维的,比如我们谈到“家园”,有人会想到近义词“家庭”,从“家庭”又会想到“亲人”,其都是有相近意思的词语;另外,有的人从“家园”会想到“地球”,从“地球”又会想到“火星”,换句话说,“亲人”、“火星”都可以看作是“家园”的二级近似,但是“亲人”跟“火星”本身没有什么明显联系。Word2vec正好解决了上述问题,简单说,Word2vec可以用高维向量表示词语,并把相近意思的词语放在相近位置,而且用的是实数向量(不局限于整数)。只需要有大量某语言的语料,就可以用来训练模型,获得词向量。实现Word2vec,读者可通过Google官方提供的C语言源代码自行编译,Python的Gensim库中也提供了现成的Word2vec作为子库。部分代码如下:
2 实验与对比
将上述整理好的数据按4∶1分成训练集与测试集,并输入各个分类器,采用情感分析模型进行实验对比,大致流程如图3所示。
2.1 模型代码与参数设置
根据不同算法构建不同分类器,用测试集检验各种算法分类器的准确度。传统的机器学习使用sklearn实践,深度学习则采用keras工具,其代码部分很相似,下面给出深度学习(LSTM、BILSTM)模型伪代码。
2.2 实验结果与对比
传统的机器学习选取朴素贝叶斯、SVM两个分类器进行实验与对比,而深度学习则用到了词向量表示方法Word2vec和深度网络CNN、LSTM(后面可以尝试其改进版BILSTM),最后将深度学习与机器学习相结合,构建Word2vec+SVM模型,并进行实验对比。实验主要模型结构和部分结果分别见图4、图5。
实验结果显示,LSTM 需要训练的参数个数远小于 CNN,但训练时间长于 CNN,LSTM的结果也不如其它分类器或模型好,是由训练数据不全、过少导致的,因此要想让 LSTM 优势得到发挥,首先要保证训练数据量。加入Word2vec模型后,结果都得到了优化,证明了其有效性。
各模型以及分类器准确率如表1所示。
3 结语
本文情感分析方法是基于传统机器学习与深度学习的有监督模型,需要大量语料训练模型,但事实却是中文环境下有标签的数据太少,作者本身获取数据的能力也有限,所以整体实验结果没有达到预期。尤其是深度学习模型,受到数据的极大限制。所以,未来情感分析领域要加强对无监督或者半监督方法的研究,使大量有效的无标签数据派上用场。
参考文献:
[1] 丁兆云,贾焰,周斌. 微博数据挖掘研究综述[J]. 计算机研究与发展,2015,51(4):691-706.
[2] 李洋,陈毅恒,刘挺. 微博信息传播预测研究综述. 软件学报,2016,27(2):247-263.
[3] 陈晓宇. 我国网络监管制度初探[J]. 福建公安高等专科学校学报,2004(2):62-65.
[4] 王乐,王勇,王东安,等. 社交网络中信息传播预测的研究综述[J]. 信息网络安全,2015(5):47-55.
[5] MILLER G A,BECKWITH R,FELLBAUM C,et al. WordNet:an on-line lexical database[J]. International Journal of Lexicography,1990,3( 4):235-244.
[6] KIM S M,HOVY E. Automatic detection of opinion bearing words and sentences[C]. Berlin: Proceedings of the International Joint Conference on Natural Language Processing,2005.
[7] KIM S M ,HOVY E. Identifying and analyzing judgment opinions[C]. Proceedings of the Joint Human Language Technology/North American Chapter of the ACL Conference,2006:200-207.
[8] BENGIO Y,DUCHARME R,VINCENT P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research,2003,3:1137-1155.
[9] MIKOLOV T,SUTSKEVER I,CHEN K,et al. Distributed representations of words and phrases and their compositionality [C]. Proc of the NIPS,2013:3111-3119.
[10] KIM Y. Convolutional neural networks for sentence classification[C]. Proc of the EMNL,2014.
[11] 梁軍,柴玉梅,原慧斌,等. 基于深度学习的微博情感分析[J]. 中文信息学报, 2014,28(5):155-161.
[12] 肖江,丁星,何荣杰. 基于领域情感词典的中文微博情感分析[J]. 电子设计工程,2015 (12): 18-21.
[13] 陈晓东. 基于情感词典的中文微博情感倾向分析研究[D]. 武汉:华中科技大学,2012.
[14] CATAL C, NANGIR M. A sentiment classification model based on multiple classifiers[J]. Applied Soft Computing,2017(50): 135-141.
[15] LIU S, LI F, LI F, et al. Adaptive co-training SVM for sentiment classification on tweets[C]. Proc of ACM International Conference on Information & Knowledge Management, 2013: 2079-2088.
[16] LIU P,MENG H.SeemGo:conditional random fields labeling and maximum
entropy classification for aspect based sentiment analysis[C]. Proc of International Workshop on Semantic Evaluation,2014:527-531.
[17] 李阳辉,谢明,易阳. 基于深度学习的社交网络平台细粒度情感分析[J]. 计算机应用研究,2017,34(3):743-747.
[18] TURIAN J,RATINOV L,BENGIO Y. Word representations:a simple and general method for semi-supervised learning[C]. Proceedings of the Meeting of the Association for Computational Linguistics,2010:384-394.
[19] COLLOBERT R,WESTON J,BOTTOU L,et al. Natural language processing (almost) from scratch[J]. Journal of Machine Learning Research,2011,12(1):2493-2537.
[20] HUANG E H,SOCHER R,MANNIng C D,et al. Improving word representations via global context and multiple word prototypes[C]. Meeting of the Association for Computational Linguistics,2012:873-882.
(责任编辑:何 丽)
猜你喜欢
预测(2016年5期)2016-12-26
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
