
数字图像的设备溯源技术综述
2019-06-01 06:22韦世奎赵瑞珍杜雪涛
北京交通大学学报 2019年2期
蒋 翔,韦世奎,赵瑞珍,赵 耀,杜雪涛,杜 刚
(1.北京交通大学 信息科学研究所,北京 100044;2.中国移动通信集团设计院有限公司,北京 100080)
随着数字成像技术的发展和移动智能设备的普及,数字图像已经成为人们生活中的重要信息媒介,在军事、司法、新闻、社交、艺术等多个领域中扮演越来越重要的角色.相比较于传统图像,数字图像具有内容可编辑的特点.然而,数字图像处理及编辑技术的简便化将编辑图像内容的门槛变低,种类繁多的图像编辑工具使得修改图像内容变得极为方便.虽然这为艺术创作等领域提供了极大的便利,但是在司法、军事、新闻等领域中存在极大的安全隐患.在如今互联网飞速发展的时代背景下,海量的数字图像充斥网络,人们迫切希望通过技术手段来高效地认证图像内容的可靠性和权威性.因此,研究数字图像的来源取证刻不容缓,这对于打击网络犯罪和维护社会秩序具有重要的现实意义.
相机来源取证(Camera Source Identification,CSI)[1]是取证领域中的一个研究热点,其研究的核心问题是如何仅通过图像内容来确定图像的设备来源,而该问题的一个基本假设在于成像设备会在图像中隐含设备唯一性的信息.通常来说,在工艺生产和成像处理的过程中,会对图像内容造成一些不明显的痕迹,而这些信息则被视为对应设备特有的模式,是数字图像溯源取证中的重要依据.
在早期的数字图像溯源取证的研究中,研究者大多将问题定义为判断一张图像是否由特定的相机所拍摄,如图1左边所示.在此类研究中,通常通过比对设备特征来确定图像来源[2].此外,还有一些研究者将其建模为一个分类问题,即给定图像是由哪一部成像设备所获取,如图1中所示的基于有监督的机器学习技术,这类技术也同样得到了广泛的应用[3].但是,上述模型都有一个无法忽视的瓶颈——需要利用一定的先验知识,即需要首先获取一些设备来源已知的图像来建立模板.然而,在大部分的应用场景中,人们通常难以事先获取这些信息.因此,在这些先验知识受限的场景下,研究者提出了数字图像盲溯源[4].
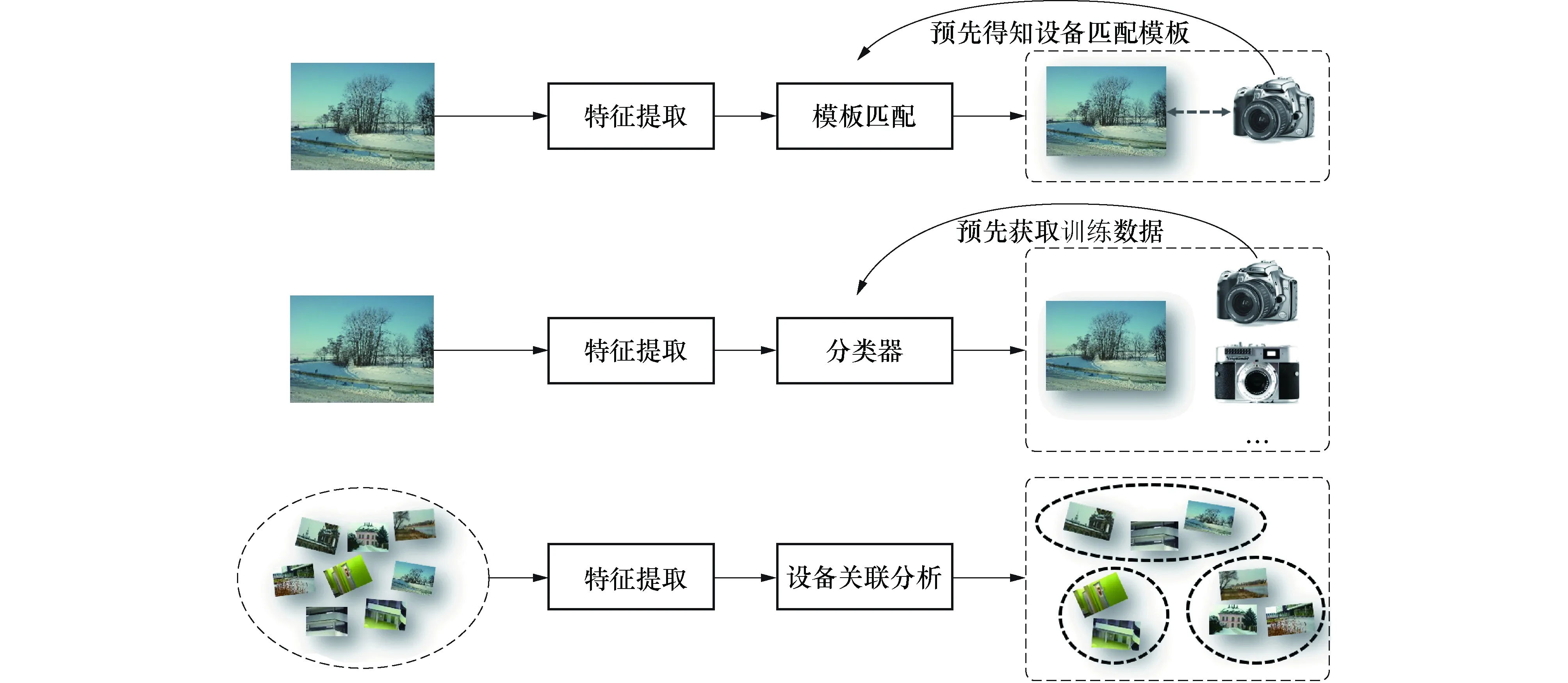
图1 数字图像溯源取证研究的三类典型模型Fig.1 Three typical models of digital images camera source identification
数字图像盲溯源是指在不依赖任何先验知识的情况下,获取图像间设备关联信息.相比于设备匹配模型和设备分类模型,数字图像盲溯源模型能够在信息受限的场景中得到良好的应用,如在社交网络中的去匿名化、用户识别等,进一步地拓展了数字图像取证技术的应用前景[5-8].
在本文中,作者聚焦于归纳和总结当前数字图像盲取证方法,并分析其面临的问题.对现有方法的主要框架特点进行了论述,阐述现有的设备特征提取方法,分析当前的设备关联算法的优势和不足.讨论当前数字图像盲取证方法在实际应用中所面临的问题,对所表现出来的发展趋势进行归纳并给出结论.
1 数字图像盲取证
数字图像盲取证,是指不依赖任何先验信息而发掘出一组来源未知的图像的设备关联信息[4].该问题包含了两个子问题:对于一组来源未知的图像集,其图像由多少成像设备所拍摄;在这些图像中,哪些是由同一部成像设备所获得.数字图像盲取证的研究历史并不久远,通常认为Bloy在2008年的工作[4]是首个基于模式噪声[1]的数字图像盲取证的研究.该研究提出了一种随机样本最近邻(Pairwise Nearest Neighbor,PNN)[12]聚合的方法,对两个图像集合进行设备盲取证实验,取得了良好的效果.随后,基于不同设备特征和不同设备关联算法的工作层出不穷,数字图像盲取证模型在图像取证研究领域得到了广泛关注.
纵观数字图像盲取证的研究,基本包含两个步骤,即设备特征提取和设备关联算法,如图1所示.虽然设备特征提取在不同的模型中都是必要的步骤,但是设备特征的表征能力对于数字图像盲取证算法的最终性能有着举足轻重的作用.而对于设备关联算法,通常被认为是一个聚类问题[13].好的算法能在一定程度上抑制由设备特征误差所引入的干扰,对于最终的数字图像盲取证的性能起到决定性作用.在本文中,将按照上述步骤,分别对设备特征提取和设备关联算法的主要研究工作进行介绍与分析.
2 设备特征提取
如前所述,在不同的成像设备中,生产工艺所带来的硬件瑕疵和不同图像处理算法所产生的特定模式都会在获取的数字图像中留下痕迹,而这些痕迹被认为是隐藏在图像内容中具有成像设备唯一性的重要模式.因此,在绝大部分的数字图像成像设备特征提取的研究中,研究者大都从数码成像设备的成像过程入手,针对性地对某一成像环节所产生的模式设计专有的特征提取算法.
真实场景到数字图像的成像过程见图2[14].
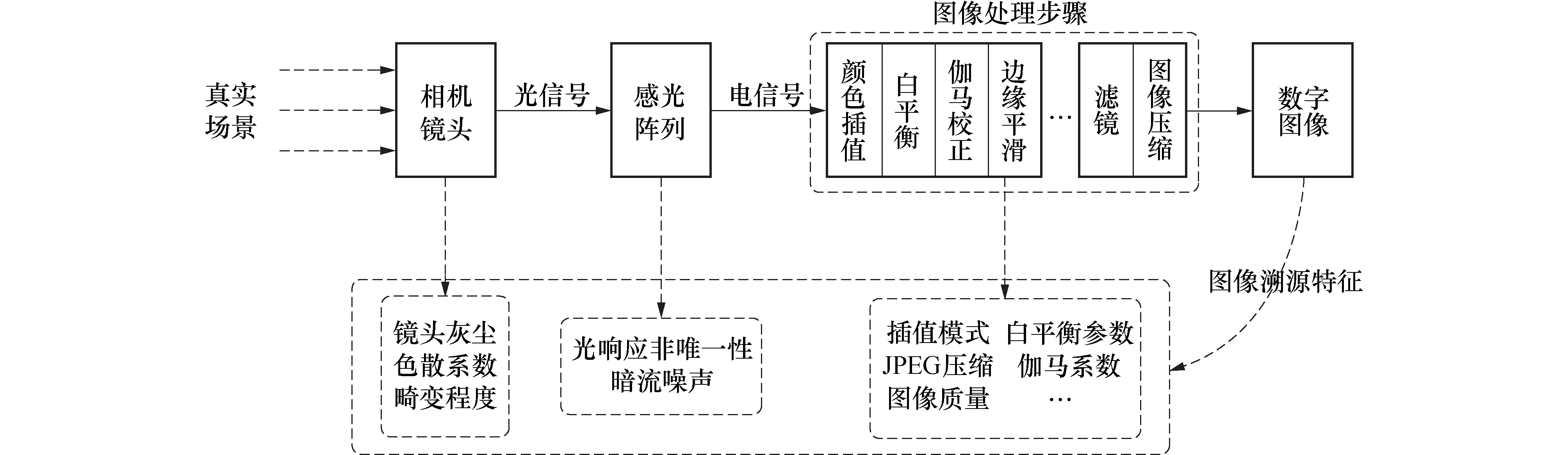
图2 数字图像成像过程Fig.2 Diagram of the digital imaging process
光信号首先进入设备镜头,经由感光元件所组成的感光阵列,转换为连续的电压信号.进而,由A/D转换、量化处理等过程,得到真实场景的灰度图像.之后,应用一系列的图像处理技术,其中包括将灰度图像转化为彩色图像的色彩插值,以及白平衡、伽马校正等.在一些厂商的设备中,图像还会经历边缘锐化、去模糊处理和JPEG压缩等步骤.在这些步骤中,或由元件生产工艺所带来的瑕疵,或由安装硬件过程中所带来的误差,或由不同的图像处理算法引入的特定模式,都会在图像内容中留下特定的痕迹.研究人员大多围绕这些硬件瑕疵,或从图像处理算法给图像内容带来的影响入手,寻找用于识别不同设备的特征模式.
在目前的研究方法中,按特征的辨别目标分类,大致可分为面向设备型号的特征[15]和面向设备个体的体征[16].
2.1 面向设备型号的特征
在面向设备型号的特征研究中,一部分研究者尝试从不同设备所配备的不同硬件元件来寻找特征.例如,Choi等[17-18]从数码相机的镜头畸变现象入手,尝试从像素强度和像元畸变程度来估计镜头的失真系数,而所得到的失真系数则作为典型的设备特征来区别配备不同镜头的设备.Van等[19]则针对成像过程中的色差现象[20]进行研究,估计出横向色差参数,并用来分辨不同设备的特征.
除硬件部件不同之外,不同型号设备所采用的不同图像处理算法也会产生具有可分辨性的特征模式.例如,Choi等[21]将JPEG压缩参数作为识别相机型号的特征,而Kee等[22]则利用JPEG文件头的信息来区分不同设备型号.此外,Deng等[23]基于图像内容估计出白平衡参数,在分辨不同的设备型号中展现了良好的性能.
目前,色彩滤波阵列(Color Filter Array,CFA)[2]是最为广泛应用的设备型号特征.由于其区分度高、易于提取且不易破坏,被应用于大多数的设备型号识别的场景中.例如,Popescu等[24]认为,CFA插值使得图像局部产生相关性,从而利用期望最大化(Exceptation Maximization,EM)算法来检测插值痕迹.在此基础之上,Bayram等[2]则将概率图频谱中的幅值和坐标作为设备型号识别的依据.当前,大部分基于CFA的设备型号识别的研究聚焦于如何准确地估计和描述不同型号的插值系数和插值模式[25-27].
另一类研究则是将重点放在从数字图像的统计信息总结出设备型号唯一的特征方面.例如,Avcibas等[28]将图像质量指标作为分辨设备型号特征的描述.Holub等[29]提出DCT方法,被Roy等作为特征来识别不同的成像设备[30].类似的基于图像统计特征的工作可参见文献[31-33].
深度卷积神经网络(Convolutional Nenral Network,CNN)[34]在其他机器视觉领域的成功也同样吸引了图像取证研究人员的注意.例如,Baroffio等[35]首次将CNN应用在设备型号识别分类上,提出了一个7层的CNN模型来提取特征,在分类模型下达到了良好的准确率.之后,Tuama等[36]在模型中添加了一个固定参数的滤波器[37],以便进一步提升性能.而Yang等[38]则提出用多分支的网络结构来取代滤波层,进一步提升了准确率.在实际中,基于深度卷积神经网络的工作还有很多[39-41].需要说明的是,在上述工作中,为了获取足够的训练数据和统一尺寸的输入图像,都将一张图像切割成同样大小的图像块,并将这些图像块作为CNN的输入,而其网络中间层的输出向量则被作为区分不同设备型号的特征.
2.2 面向设备个体的特征
比面向设备型号的特征更进一步,面向设备个体的特征旨在区分出同一型号中的不同成像设备个体.考虑到成像设备的普及,在一些场景中,仅通过分辨不同的设备型号难以满足实际应用的需求,需要进一步辨别出不同成像设备个体.通常来说,由于数字图像的成像特点等原因,现阶段面向设备个体溯源取证的研究面临着更大的挑战和难点.
不同的设备个体之间,一个明显的区别在于其硬件设备存在一些差异.通常,这些差异由元件生产安装工艺的不同所导致,并在获得的图像中留下特有的模式.对此,研究人员提出了多种算法来提取其模式特征,并作为识别设备个体的重要特征.例如,Geradts等[42]把图像中暗点与坏点的分布作为设备个体特征,而Kurosawa等[43]则对暗电噪声展开研究,并提出可将无曝光图像的电流噪声作为设备个体特征.但是,上述特征往往只能在较为局限的场景下得到应用.例如,并非每一部成像设备都存在暗点和坏点,而暗电噪声只能从无曝光的图像中检测.因此,研究人员更期望找到一种能够从常规图像中检测出来的特征来分辨设备个体.
目前,应用最为广泛的面向设备个体的特征是由Fridrich团队所提出的光响应非唯一性(Photo-Response Non-Uniformity,PRNU)特征[1].由于生产工艺所限,导致成像设备的感光元件的光敏特性存在微小的差异,从而使得整个感光阵列存在固定误差分布,而这种分布则以乘性因子的形式隐含于图像之中.在研究工作中,Fridrich等将其形象地称为“相机指纹”,说明其如同指纹一般对于相机具有唯一性,可用于设备取证[44]和图像篡改检测[45]等场景.最早的PRNU检测算法由Lukas等[1]提出.通过对成像过程的建模和最大似然估计,得到了PRNU特征的近似数学表达.在具体实现中,利用小波变换算法[46]从图像中提取噪声残差作为PRNU特征,由于PRNU可直接从自然图像中提取,因此该工作具有较好的应用价值.而其又体现出较好的鲁棒性与稳定性,推动了相关研究工作的展开.
PRNU的相关研究工作围绕如何提升PRNU的性能展开.Li[47]对如何增强PRNU特征展开研究,通过构造一系列的响应函数,提升PRNU的设备个体识别效果.随后,Li等[48]则认为,色彩插值步骤会对PRNU的识别产生影响,因此提出了一种只对非插值像素提取PRNU的算法.此外,Chen等[49]对原有PRNU的提取算法进行改进,通过加入零均值滤波等步骤,进一步提升了PRNU的性能.同时,Cooper等[50]、Rosenfeld等[51]和Chierchia等[52]也都相继展开研究,并报告了良好的性能.除此之外,Valsesia等[53]则致力于对PRNU特征的改造,通过主成分分析(Principal Componer Analysis,PCA)和哈希映射等手段来对PRNU降维,从而提升了特征的识别效率.而Goljan[54]等针对如何更好地识别PRNU展开研究,提出了基于峰值相关能量的度量方法,使得PRNU的识别和度量更加鲁棒.
除了PRNU外,还有一部分研究人员尝试从其他的成像环节入手,寻找设备个体隐藏在数字图像中的痕迹.例如,Dirik等[55]提出了一种基于镜头灰尘的相机识别算法.由于镜头上难免沾染灰尘,这些灰尘颗粒会在图像中对应的位置留下特定的痕迹.利用图像的局部互相关性,研究人员将这些由灰尘引入的痕迹进行建模描述,并作为设备个体的取证特征.需要注意的是,基于灰尘的设备特征往往存在时效性,即设备特征会随着时间的推移和环境的变化而改变.但是在一些限定条件的场景中,该技术依然体现出良好的稳定性.
上述特征大多针对某一个成像环节来寻找痕迹,而另一类基于相机响应函数(Camera Response Function,CRF)的方法则将整个成像设备视为整体,并从中找出设备个体所特有的痕迹.例如,Mann等[56]基于一组来自特定设备个体的图像来总结出其对应的CRF,而Du等[57]提出了基于单张的CRF估计算法,Ng等[58]则利用图像内容的几何不变性来估计CRF参数,都取得了较好的效果.但是,此类方法在一些特定场景中具有较大的局限性.
3 设备关联模型
如前所述,设备特征通常被用于三类模型,即匹配模型、分类模型和关联模型,如图1所示.其中,关联模型无需任何先验信息,能在一些信息受限的场景中发挥作用,在取证领域受到广泛关注,而相关研究人员也围绕该模型提出了多种高效的算法.
从本质上来说,设备关联模型描述的是一个聚类问题,即如何对一组图像根据其设备来源进行聚类.它的最大挑战在于不能事先获取图像集的类别数量,即在类别数量未知的场景下进行聚类分析.该类模型的提出具有重要的现实意义,在一些信息受限的场景中可以得到较好的应用[6-8].Lukas等[1]在工作中获得了一个结论,即从足够多的同源图像(50张)中所提取的PRNU具有更好的设备特征表征性能.Bloy将其描述为一个“鸡生蛋”的问题:足够好的特征能够识别未知来源的图像,但需要从足够多的已知设备来源的图像中提取.因此,如果能够先对未知来源的图像进行准确的聚类,那么就能得到这些图像的设备来源伪标签(是或不是一类),那么聚类所得到的每个簇的图像中,就能够提取足够好的PRNU特征.随着研究的深入,人们发现这类无需先验知识的模型能够应对一些不适用匹配模型或分类模型的情形.
从研究历史来看,Bloy开启了关联模型盲取证研究的先河.具体而言,不断地聚合足够相似的样本至一类,并以新的类中心作为新样本继续合并剩余样本,直到当前类别的类中心与最相似样本的相似性超出了预设的阈值,当前类别聚合完成.该方法借鉴了PNN[10]的思想,能够在类别数量未知的情况下对数据进行聚类分析.Bloy的工作吸引了相当一部分研究人员的注意,他们在其基础之上围绕数字图像设备关联的问题展开了进一步的研究.例如,LUAN等[59]提出了一种基于层级聚类(Hieratical Clustering)[60]的方法来解决设备关联的问题,并引入了轮廓系数的机制来设定参数.Caldelli等[61]对轮廓系数的计算进行改进,通过综合考虑类内差与类间差的因素,进一步提升了算法性能.类似的工作还有许多,如Villalba[62]针对智能手机图像进行了设备关联分析,而Gislof等[63]优化了最近邻的计算框架,在提升准确率的同时,进一步提升了运算效率.Fahmy[64]则引入不变矩(moment invariants)[65]优化算法,获得了良好的性能.
虽然基于PNN的算法能够得到较好的准确性,但由于其计算量较大,在运算速度上效率不高.对此,有相当一部分的研究人员尝试将设备关联模型建模为图模型:将一组设备来源未知的图像建模为无向图网络,其中每个节点表示对应的样本图像,而两两间的相关性数值则作为对应节点之间的边.例如,Liu等[66]将一组设备来源未知的图像模型化为无向图网络,再利用图割算法对图像进行聚类分析,在损失少量精度的情况下,大幅地提升了运算速度.在此基础之上,Amerini等[67]则对算法进行改进,并提出一种自适应参数的标准化图割[68]算法,使性能得到进一步的提升.相比PNN及其变种算法,基于图模型的算法在运算性能上具有较大的优势.
在面向设备关联的聚类算法中,研究的重点围绕在提升聚类精度和提高运算速度两个方面.在一些研究工作中,分步聚类的方式取得了较好的效果.例如,Lin等[69]提出先对数据集进行粗略的分类,能够在较短的时间内获得大致的聚类结果;而后,再对每一个粗略的类进行精细化的处理,从而得到较好的聚类结果.综合上述方法的优势,Marra等[70]则提出了一种基于聚类融合的算法,取得了目前为止数字图像来源盲取证的最佳效果.基于运算时间的考虑,其首先利用图模型对图像集进行大致的聚合,得到若干组子集,每个子集中只包含了由一个成像设备所拍摄的图像.之后,将每个子集的类中心作为对象,利用加权证据累积聚类(Weighted Evidence Accumulation Clustering,WEAC)算法[71]对这些子集进行再聚合,从而得到较为准确的聚类结果.在其最近的工作中[72],对算法加入了再优化的步骤,从而进一步地提升了性能.
目前,Marra等[72]的算法具有较好的性能,但是在运算效率上,Amerini等[67]的方法仍然具有较大的优势.
4 未来发展趋势
由于数字图像盲取证无需任何先验知识,在信息受限的场景下具有较小的限制,其实际应用价值不言而喻.切实的应用前景促进了学术研究的进步,近年来各种性能良好的算法被不断提出.综合过去10年的发展历程,未来的发展趋势可归纳为两点,即面向开放环境下的数字图像盲取证研究和面向海量规模的数字图像设备关联研究.
4.1 面向开放环境下的数字图像盲取证研究
在目前的研究中,大部分的工作还是局限于实验室环境的数据,即不经过任何修改和编辑直接由成像设备所获取的数字图像.然而在实际应用中,特别是在互联网环境下,图片通常会经历一系列的再编辑过程,其中包括裁剪、比例缩放、下采样以及压缩解码等.这些操作会或多或少地对设备隐藏在图像内容中的痕迹产生破坏,从而导致现有的算法不能达到预期的性能.
对此,针对开放环境下的图像取证溯源方法成为当前的研究重点.例如,为解决图像裁剪导致的PRNU特征匹配方法失效的问题,Goljan等[54]提出了基于峰值相关能量的算法,能较为准确地度量被裁剪图像的设备特征间的相似程度.Liu等[73]针对经过二次压缩和人为处理后的图像展开研究,并提出了一种较为鲁棒的特征提取方法.同时,Alles等[74]提出了针对低分辨率图像的设备特征提取方法,而Houten等[75]则针对多次压缩后的网络视频进行设备识别,都取得了一定的效果.此外,Chierchia等[76]则致力于研究如何从小尺寸的图像中提取PRNU特征.
虽然围绕开放环境的数字图像取证研究得到了广泛关注,性能也在不断提升,但是仍然缺少足够鲁棒的特征提取手段和高效的设备关联算法.考虑到其具有迫切的实用需求,可以预见,面对被裁剪、缩放、下采样、重度压缩后的图像集,如何有效地对其进行设备取证,是未来一个重要的研究内容,也是走向实用必须要解决的问题之一.
4.2 面向海量数据的数字图像盲取证研究
得益于Flickr、Insgram等图片社交网站的兴起与流行,研究者可以较为容易地获取大量具有完整标签的图像,这为取证研究提供了有利条件,并促使研究者采用更大规模的数据集来验证其算法的有效性.
例如,Goljan等[77]从Flickr中获取了超过150万余张的图像,其中包含了150个不同的设备型号和7 000余部不同的设备个体.Valsesia等[53]从Flickr上获得了50万余张图片,包含1 000余部不同设备来源,用来测试其设备检索算法.此外,Meij等[78]则针对匿名网络社区WhatsApp中的图像展开研究.Sameer[79]等将原始图像上传Facebook后下载并作为新的数据集,从而来测试算法对于网络图像的性能.
在目前所发布的用于设备取证的数据集中,有两个较为权威的数据集,分别是Vision[80]和Dresden[81].Dresden数据集发布于2010年,其包含了74部相机的超过15 000张的图像.这些图像不仅全部是原始图像,而且其场景包含了各种潜在的干扰因素,如过曝光和欠曝光、不同的白平衡设置等.目前,Dresden是应用最为广泛的数据集.Vision数据集发布于2017年,其包含了11个型号的35部设备个体所拍摄的34 427张图像和1 914个视频.需要注意的是,这些数据包括由原始数据组成的原始版本和由网络图像组成的社交版本.这为设备取证的研究提供了极大的便利条件,可以作为全面评估图像取证算法的基准.值得一提的是,Sameer等[79]将Dresden上传至Facebook后下载,可以有效地扩充网络图像数据集.
在数字图像盲取证的研究中,测试集的规模不断扩大.在早期研究中,Bloy[4]分别使用了来自于4部相机的479张和来自于5部相机的695张图像的两个数据集,测试其算法性能.随后,Li等[48]的研究中数据集达到了1 100余张,而Amerini等[67]则使用了1 200张图像作为测试数据集.近期,Marra等[72]将Dresden数据集的图像进行重组,建立了一个包含9 538张图像的数据集来验证算法性能.
目前,大规模的数据集对图像盲取证算法所造成的主要困难在于计算复杂度的成倍增加.由于需要计算两两样本间的相关性,使数据规模增加,导致计算复杂度呈指数增长.而一些特征往往会占用较大空间,也导致在计算时占用大量内存.因此,如何应对海量数据,是数字图像盲取证研究在未来所必须要面对和解决的一个重要难题.
综合数字图像盲取证的研究历程可以预见,面向特征受损的网络图像的数字图像取证算法和面向海量数据的数字图像取证框架,是未来研究的两大难点,同时也是未来发展的必然趋势.
5 结论
本文对当前数字图像来源的盲取证研究进行综述.阐述了数字图像盲取证研究的基本框架,并将其分为设备特征提取和设备来源关联两个步骤,并对两个步骤的主要研究工作和方法分别进行了阐述.在此基础之上,认为开放环境下的图像设备特征提取和大规模的数字图像是目前盲取证算法所面临的主要瓶颈,也是从实验室中走向实际应用所必须要解决的难题.在分析了数字图像来源盲取证的研究发展历程后认为,在开放环境的图像集中获得鲁棒的性能,以及如何在大规模数据集下获得高效的取证,是今后研究发展的两个主要趋势.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
计算机仿真(2021年12期)2022-01-22
计算机应用与软件(2021年7期)2021-07-16
军民两用技术与产品(2021年12期)2021-03-09
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
航天工业管理(2020年11期)2021-01-04
航天工业管理(2020年9期)2020-12-28
航天工业管理(2020年4期)2020-06-16
互联网天地(2016年1期)2016-05-04
科教导刊·电子版(2016年1期)2016-03-14
