
HOG内嵌模板匹配的车门夹人检测算法
2019-06-01 06:22苏建华薛栋娥刘传凯黄开启
北京交通大学学报 2019年2期
苏建华,薛栋娥,刘传凯,袁 磊,黄开启
(1.江西理工大学 电气工程与自动化学院,江西 赣州 341000;2.北京航天飞行控制中心,北京 100094; 3.北京交通大学 电子信息工程学院,北京 100044;4.中国科学院自动化研究所,北京 100080)
地铁是我国大中型城市公众市内出行的重要交通工具.为提高地铁列车的运营效率,新建地铁多采用屏蔽门设计,根据设计需求地铁列车门与屏蔽门之间需保留大约10~30 cm的间隙.容易将体型偏瘦的乘客或小孩卡在其中,酿成安全事故.近年来我国发生多起地铁屏蔽门夹人事件,造成了严重的人员伤亡,给乘客的安全出行带来了很大的危险系数.为解决屏蔽门安全隐患问题,利用辅助设备检测列车门和屏蔽门之间是否夹住乘客,成为预防事故发生的重要手段.
现阶段国内外基于列车车门与屏蔽门之间异物的检测技术,主要有人工检测法和自动检测法.人工检测法是指通过列车司机瞭望、观察车尾处的“光带”完整性来间接判断是否有异物滞留在车门与屏蔽门之间.这种通过人体肉眼观察的方法可靠性较差,会受到个人主观因素的影响,易出纰漏.自动检测方法主要有红外光幕检测技术、激光检测技术、机器视觉检测技术.红外光幕检测技术和激光检测技术都是通过各自发射器与接收器装置间接判断缝隙之间是否有异物存在.激光的聚光效果好,检测距离长,可以实现远距离异物检测.红外发射管发射出的光有较大的发射角,导致聚光效果差,需要多段接力才能完成对整个站台空间异物的自动检测.然而,以上两种自动检测方法在安装调试方面较为复杂、系统维护成本较高、抗振动性差,对于列车在隧道行驶过程中产生的粉尘和振动等因素容易产生误检[1].相比较而言,机器视觉检测技术具有信息量大、功能多、速度快等优点,且不受距离、空气质量、气流波动、站台曲率的影响,是屏蔽门夹人检测的重要研究方向.
目前,利用机器视觉检测地铁列车车门与屏蔽门间隙夹人夹物,主要从车头-车尾贯通性检测和各屏蔽门单独检测两个方面开展研究.文献[1]采用车头-车尾贯通性检测的思路,设计出了一种基于机器视觉的直线式站台异物自动检测方案,在地铁列车的车头安装两台摄像机,通过车门与屏蔽门间空隙拍摄车尾处光带长度的变化,判断车门与屏蔽门之间是否存在异物.以此为基础,文献[2]提出了一种无盲区的地铁站台异物自动检测设想,在车头和车尾方向的屏蔽门立柱上分别安装一台摄像机和一套光幕发射装置,将上下位置颠倒形成对角模式,实现空隙间无盲区的自动检测.但上述方法对曲线站台不适用.文献[3]研究了基于机器视觉的曲线站台列车车门与屏蔽门之间异物的检测,在地铁站台的滑动门顶部安装摄像机,从上往下俯视拍摄视频图像,利用背景差分技术来完成空隙间异物检测.该方法的摄像头安装在站台滑动门与车门之间的狭小区域,视场内光线较暗,从获取的图像中分辨目标较为困难,辨识度低.
为了能够以较宽广的视野获取包括地铁站台、屏蔽门和列车门的区域图像,克服现有视觉检测方案中的光线暗、辨识度低的问题,本文作者通过在列车屏蔽门斜上方安装摄像机,提出基于HOG(Histogram of Gradient)内嵌模板匹配的上下车乘客识别方法.首先采用HOG算子将列车车门与屏蔽门间隙之间的行人特征进行描述,提取所有的行人区域和背景中与行人特征相似的竖直块状区域;然后考虑摄像头、列车抖动、行人移动等因素的影响,设计自适应模板匹配策略,对图像中的移动目标和静止目标进行分离,从而实现屏蔽门和车门之间的行人状态检测.相比现有的方法,该方法拍摄视角宽、光照亮度强、直观性好、可以清晰辨别行人状态的优势,能够更准确、更稳定地实现乘客上下车状态的检测,为地铁乘车的安全性提供可靠保障.
1 夹人检测方法框架
在基于视觉的夹人检测方案中,获取明亮、清晰的序列图像是后续图像处理和行人检测的先决条件.为了能够达到该要求,本文将摄像机安装在列车和屏蔽门的斜上方,从上到下进行斜视俯拍获取包括屏蔽门、车门和行人的监测区域内的序列图像,如图1所示.
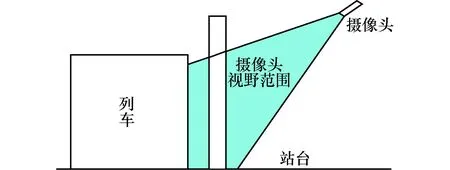
图1 目标区域与摄像头位置的侧面示意图 Fig.1 Side view of target area and camera position
考虑到摄像机的安装高度、倾角方向设置等因素,摄像机拍摄的图像中必然会包含一些目标区域(列车车门、屏蔽门间隙)之外的图像信息,这些信息如车门框、玻璃框等信息,呈竖直块状形态,与行人具有较大的相似性.针对该特点,本文提出两步法以实现行人目标的检测.首先利用HOG+SVM算法对监视区域内的行人目标进行提取,确定行人目标和背景中与行人目标相似的块状区域的位置;其次根据行人目标连续移动与周围物体不动或者轻微抖动的特性,设计一种动静目标分离的模板匹配算法,对目标行人进行检测.本文中所表达的动与静是对地铁屏蔽门及周围环境的场景变化情况的相对性分析,与通常视觉中关于动与静的理解有所区别.静是指场景中固定不变的目标,即列车范围之内的一个静态无人的背景环境,动是指整个列车场景中相对于静态背景而言发生变化的场景或目标.所以文中提取无行人状态下的背景图像作为静态参考背景,利用模板匹配的方法,将与行人目标相似的块状背景区域与行人目标区域进行区分,从而实现了行人目标的判别,算法过程如图2所示.
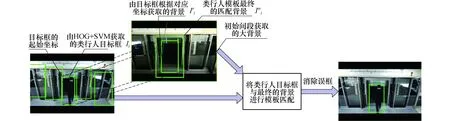
图2 模板匹配过程中有效背景区域的获取方法Fig.2 Method for obtaining effective background area in template matching process
实现步骤如下:
1)获取参考背景:由于不同时段光照亮度必然存在一定的差异,因此获取无人条件下各个时间段的背景图片进行均值化处理,作为后续模板匹配的参考背景.
2)提取行人目标区域和背景中与行人目标相似的块状区域,记为I=(I1,I2,…,In).
3)根据行人目标区域和块状区域Ii=(xi,yi,hi,wi)的像素位置,在步骤1)中获取的参考背景中寻找相对应的像素区域Ii′.
4)为了消除相机抖动的影响,将Ii′ 区域的上、下、左、右四个方向各拓展n个像素点,作为最终的背景区域Ii″.
5)将Ii与Ii″进行匹配,消除误框,准确获取列车缝隙之间的目标行人.
2 基于HOG与SVM行人检测算法
考虑HOG特征在形状边缘提取方面的准确性、独特性,本节利用HOG特征,对前景图像的局部梯度信息进行统计,构建HOG 特征描述子,作为线性SVM分类器的输入变量,进行分类判别[4],并利用非极大抑制操作,去除重叠、多余的内包含窗口,检测到最佳的类行人目标位置.
在HOG特征的提取阶段,为了有效降低局部阴影和光照对图像的干扰,框选出更加明确、可靠的类行人目标,首先对获取的图片进行gamma归一化处理,调节图像的对比度,并利用一维离散微分模板梯度算子[-1,0,1]、[-1,0,1]T对图像分别进行卷积运算,获取每个像素点的梯度信息.其次以每个cell单元格为基础,量化梯度方向(将统计区域的梯度方向平均划分为9个bins),构建相应的HOG特征描述子.考虑到角度之间的连续性和各cell区域之间的连通性,像素点其对相邻bins、相邻的cells必定存在一定的影响.因此本文在梯度幅值分配中,利用线性插值法对权值进行调整,将待处理的像素点的梯度幅值按规则加权累计到相邻cell单元的直方图上[5],采用空间梯度插值投影的方法,投影到相邻的bins中.最后累计 bins 中所有梯度幅值,将每个bin中的累计权值作为cell单元特征向量的元素值.这样一个cell单元格的外形就可以用一个 9 维特征向量的描述子表示,而每个block由相邻的四个cells串联组成,那么每个block的外形区域将由一个36维的特征向量进行表示[6].
Block的移动步长为一个cell单元的长度,故在Block移动的过程中,相邻块之间将会包含有相互重叠的cell区域.受外界局部光照、阴影变化的干扰,使得局部区域梯度强度产生很大变化,造成了不同 Block 之间相同cell单元的特征值差距较大.因此需要对block内包含相同cell单元的区域做对比归一化处理[7],并以此作为最终的HOG特征.从而降低在局部区域由于特征值差距悬殊而导致分类器的分类能力下降[8],最后将所有Block的特征串联组合成一个检测窗口的HOG特征向量.
本文采用滑动窗口的检测方式,同样以一个cell单元像素宽度为步长,从上到下从左到右依次遍历整幅图像,获取不同尺度图像中的HOG特征描述子,然后在支持向量机(SVM)分类器中进行有效分类[9-10].HOG+SVM算法的整体流程见图3.
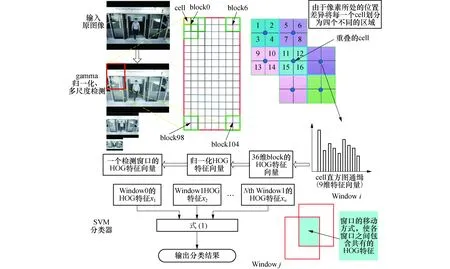
图3 HOG+SVM算法的整体流程图Fig.3 Overall flow chart of HOG+SVM algorithm
为了快速、有效的检测每一个窗口中提取的HOG特征向量,本文采用二分类线性分类器进行分类判别,找到最优分类面,使得所有被检测HOG特征向量能够被正确分类[9].即满足
yi[wTxi+b]>0,i=1,2,…,n
(1)
(2)
式中:yi为输入的HOG特征向量的一个类别标签;xi为根据采集的序列图像获取的HOG特征向量.
3 自适应模板匹配
HOG特征是基于梯度方向的分布直方图,其特征描述子可以很好地表征物体的边缘形状.但在地铁列车复杂背景中利用HOG与SVM检测算法仅能够获取目标区域的类行人目标.因为在HOG特征提取阶段,块内包含边缘部分的像素点的梯度值较大,对所属bins的加权贡献较大,从而导致特征幅值较大,在分类过程中很容易就会将检测窗口中非行人的边缘区域一同视为行人框出.并且在SVM的训练过程中,对于大多数行人库,如 INRIA,MIT等,其训练样本主要为侧视角的行人,故采用HOG+SVM算法对图像进行检测时,处于竖直状态的物体会比较敏感[11].根据本文的设计方案,所获取的图像除了人体形状为竖直以外,列车的门框、屏蔽门的门框及窗户等背景都为竖直且对称,很容易被误判为行人特征.针对该问题,设计了基于HOG内嵌模板匹配的行人判定方法,利用序列图像检测目标的动态变化特性,对移动行人和静止背景进行判定,消除列车门框、车窗等背景的干扰.同时我们考虑光线变化、摄像头和列车振动对成像亮度和抖动性的影响,设计了一种局部可调的自适应模版匹配方法,实现对移动目标的准确判定.自适应模版匹配方法主要包括背景图的构建和模板自适应匹配两个步骤.
3.1 自适应背景区域的构建
为适应不同时间段由光照亮度变化导致的背景的动态变化,选取每个时间段无人的背景图像进行均值化降噪处理,获取参考背景,从而最大限度地抑制背景模型在检测过程中产生的干扰[12].假设在每个设定的时间域选取N帧无人图像作为待选背景图像,依据选取的时间先后顺序进行排列,第i张图像的像素点用Ii(x,y)表示;其参考背景的获取方式如下
(3)
其次,在具体的模板匹配中,以现阶段HOG算法检测出的目标框为依据,将其框内图像作为目标图像,即动态模板.根据目标图像的坐标参数选择参考背景图像中对应的像素位置,作为自适应模板匹配的备选背景区域.在此基础上,考虑列车带动地面振动导致的相机抖动问题,将初始化背景图像上、下、左、右分别拓展n个像素点作为接下来模板匹配的背景图像.此外,在备选背景图片靠上、靠下、靠左、靠右的区域不足以扩展所设定的像素值时,可按照式(4)的方式进行处理,对应的背景示意图见图4.
(4)
式中:Rx、Ry、Rw、Rh分别为所选目标框的起始坐标、宽度和高度;Xw、Yh表示每一个目标框对应的终极背景区域的宽度与高度;W为图像的宽度;H为图像的高度.
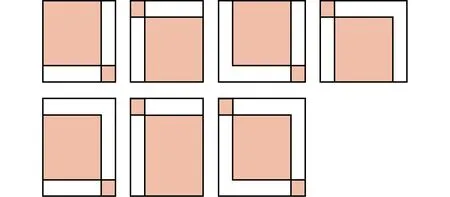
图4 背景扩展示意图Fig.4 Background extension diagram
3.2 模板自适应匹配
不同于传统的模板匹配算法,本文不是根据预先存储的目标图像与待检测图像进行匹配,而是基于现阶段采集的视频图像序列,利用HOG与SVM算法检测每一帧图像中的类行人目标,然后将所有的类行人目标区域作为目标模板.该方法获取的目标模板是动态的且不需要占用大量的存储空间.背景模板区域的获取由目标模板的像素点位置而确定,考虑到同一站台在不同时间段列车所停靠的位置会存在一定的偏差,以及摄像机轻微抖动等的影响,将背景区域适当进行扩展.这种通过背景模板区域约束方式,将避免目标模板在没有关联的背景中进行盲目的匹配,从而提高检测速度.
如图5所示,阴影表示通过HOG算法选取的目标模板,白色方块表示各自对应的背景区域.本文将选取的目标模板遍历整个对应的背景模板区域,寻求最优的匹配位置.图中分别展示了第i帧图像上的3个目标模板在对应背景模板中获取的最优匹配位置.然后利用最优匹配位置的匹配度与所设定的阈值进行比较.
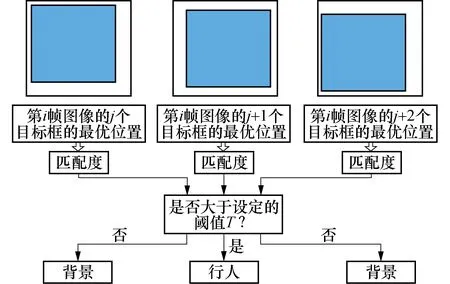
图5 模板匹配过程Fig.5 Template matching process
在模板匹配过程中,分别采用OpenCV中较为主流的归一化平方差匹配法、归一化相关匹配法和归一化相关系数匹配法进行匹配度计算[13].根据各自的匹配规则,判断两个图像块的相似性,从而设置相应的误框判定方式和阈值大小如表1所示.匹配度计算公式如下
R1(x,y)=
(5)
R2(x,y)=
(6)
R3(x,y)=
(7)
式中:R1(x,y),R2(x,y),R3(x,y)分别为归一化平方差匹配方法,归一化相关匹配法,归一化相关系数匹配法的匹配系数;T(x′,y′),I(x+x′,y+y′)分别为目标模板与背景图像区域对应坐标点的像素值,T′(x′,y′),I′(x+x′,y+y′)分别为模板与目标图像对其各自均值的像素值之差.
如果匹配系数小于(或大于)所设定的阈值,则表示为背景,否则目标区域为行人,定义为
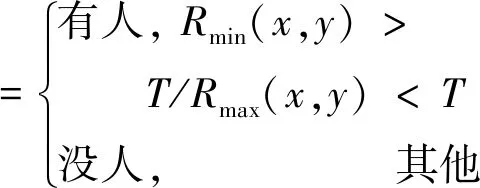
(8)
式中:Rmin(x,y)是归一化平方差匹配系数的最小值;Rmax(x,y)是归一化相关匹配法和归一化相关系数匹配法系数的最大值.

表1 匹配度的计算方法
4 试验对比与分析
为了验证本文算法的有效性,采用地铁列车模拟环境下获取的实验数据进行测试实验,实验设置如下:将摄像头安装于列车门和屏蔽门斜上方位置,对不同光线条件下列车停止状态进行图像采集,中途时而有乘客上下车穿梭走动;在Windows 7操作系统下,基于Visual Studio 2008开发平台和OpenCV2.44开发库,利用 C++编程语言开发软件,对采集的图像序列进行处理与上下车乘客检测.
考虑不同的人、不同的性别所穿衣服颜色差异较大,对模板匹配中阈值的设置有一定的干扰,首先对匹配所需背景进行均值化降噪处理,降低不同时间段光照亮度对背景的影响,然后采用本文所述算法按照第2节的步骤进行处理和上下车乘客检测.分别对1、2、3人的上下车过程进行检测,检测效果如图6所示,若有人出现在缝隙中间,用绿框框出.图6中(a)、(b)、(c)、(d)的左图分别为基于HOG与SVM检测得到的上下车乘客检测结果,右图为在左图基础上进行自适应模版匹配后的判定结果.实验结果表明,对模拟环境下所采集的不同数量乘客的视频图像中,能够较准确地检测出所有的乘客目标.
在匹配度计算方面,本实验截取了735~750帧、1 050~1 065帧图像序列作为单、双人上下车通行时间窗口.利用平方差归一化匹配法、归一化相关匹配法和归一化相关系数匹配法分别获取图像中目标框的最优匹配位置,并计算各自的匹配度系数,然后将最优匹配位置的匹配度系数进行统计,如图7所示.图7中“+”表示利用HOG+SVM算法检测的对象是上下车乘客即目标行人,“*”表示利用算法检测的对象是列车车窗、车门等,即由于复杂背景、光照变化、相机抖动等影响而产生的误框.根据实验对比结果可知,3种匹配法均可以实现目标框与误框分离,但是归一化相关匹配法受光照变化影响较大,两类目标框匹配度系数的临界值差距较小,阈值设置范围较为局限,见表2.所以平方差归一化匹配法、归一化相关系数匹配法在HOG+SVM算法中的嵌套效果相对优于归一化相关匹配法.

图6 误框消除前后对比显示Fig.6 Comparison before and after the removal of false boxes
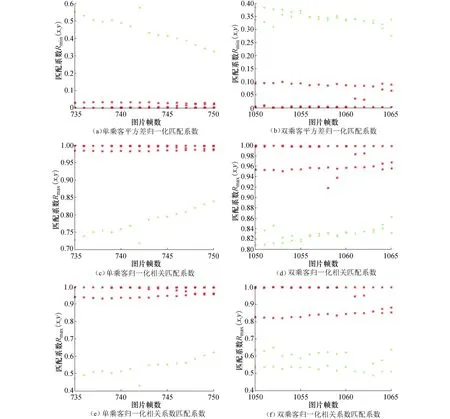
图7 3种用于误框消除的匹配系数对比Fig.7 Comparisons of three matching coefficients for frame error elimination

图像序列平方差归一化匹配法归一化相关匹配法归一化相关系数匹配法单乘客(735~750帧)(0.0323,0.3241)(0.8395,0.9838)(0.6228,0.9351)双乘客(1050~1065帧)(0.0988,0.2752)(0.8623,0.9376)(0.6498,0.8188)
表2中根据最优匹配设定方式,分别给出了3种匹配方式在测试序列中的有效框匹配系数最大值和误框匹配系数最小值(或者有效框匹配系数最大值和误框匹配系数最小值),作为阈值T设定的参考范围.考虑到匹配效果的准确性、稳定性和时效性,本文最终选用平方差归一化匹配法作为最终的匹配度计算方法.根据图6与图7中的对比实验结果可知,当阈值T=0.2时,在截取的测试段图像序列中可以达到100%的区分效果.因此HOG内嵌模板匹配方法可以有效的剔除误框,并对地铁列车缝隙之间的行人进行检测.
5 结论
1)针对地铁列车车门与屏蔽门缝隙之间存在的夹人安全隐患问题,提出了HOG内嵌模板匹配的视频帧夹人检测方法,一方面利用HOG与SVM算法对图像中的类行人目标进行检测;另一方面以类行人目标窗口的像素位置为依据在参考背景图像中寻找背景模板区域,然后进行自适应模板匹配.
2)将行人检测方面应用于较为成熟的HOG算法和模板匹配以及帧差法的思想结合为一体,使得在地铁列车的复杂背景下,达到很好的检测效果.实验表明本文所提方法可以很好的将处于缝隙之间的上下车乘客检测出来,为后续整个夹人检测系统的设计提供技术支撑.
猜你喜欢
建材发展导向(2022年20期)2022-11-03
建材发展导向(2022年12期)2022-08-19
恋爱婚姻家庭(2022年9期)2022-04-13
恋爱婚姻家庭·养生版(2022年3期)2022-04-11
建材发展导向(2021年20期)2021-11-20
科学家(2021年24期)2021-04-25
意林(2021年5期)2021-04-18
考试与评价·高二版(2020年2期)2020-09-10
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
