
基于BP神经网络和遗传算法优化番茄红素发酵培养基
2019-04-25 07:29:12冯玲然余晓斌
食品与生物技术学报 2019年2期
王 强,冯玲然,余晓斌
(1.河南师范大学 生命科学学院,河南 新乡453007;2.江南大学 生物工程学院 江苏 无锡 214122)
番茄红素是一种重要的类胡萝卜素,在生物体中具有抗氧化、抗衰老、提高免疫力等生理功能[1-3]。目前,番茄红素市场尚处于发展阶段,主要体现在昂贵的价格和日益扩增的市场需求方面。根据Global Industrial Analysts公司的报告,类胡萝卜素的全球市场价值将在2017年达到13亿美元。天然提取法仍是目前获得番茄红素的主要途径,但也面临着植物中色素含量低和纯化工艺复杂等问题。尽管化学合成番茄红素成本低廉,但是其副产物多,产品难以达到食品安全的要求。近年来,随着生物技术的蓬勃发展,利用微生物发酵生产番茄红素受到越来越多人的关注[4]。然而,低产量带来的高成本仍然是发酵法生产番茄红素规模化生产的重要限制因素,虽然已经有部分企业实现了番茄红素的工业化生产,但番茄红素产量仍需进一步提升。
适宜的培养基可显著提高发酵产物的产量,不同菌株对发酵培养基的要求不同,同一菌株在诱变前后对发酵基质的要求往往也会发生改变。在已报道的文献中,番茄红素发酵培养基的组成成分及各组分的含量有较大差异,这说明三孢布拉霉的酶系丰富,可利用的碳氮源非常广泛[5-7]。然而,这也给之后的研究者造成了困惑,不得不重新优化培养基的组成,在培养基的选择上参考价值较低,通常需要重新优化,而合适的培养基优化方法就显得格外重要。番茄红素发酵培养基多数采用天然培养基,成分复杂,各因素之间相互影响,使试验因素与结果之间具有较强的离散型,培养基各组分与产量之间存在着非线性关系,常规方法建立的数学模型往往不能准确的描述这种关系,试验结果不尽如人意。人工神经网络技术(Artificial Neural Network,ANN)是对人类大脑的一种物理结构上的模拟。误差反向传播神经网络 (Error Back Propagation Neural Network,BPN)是人工神经网络中应用极广的重要模型之一,在拟合复杂的非线性关系方面具有显著优势,并且对输入输出端点数没有显著,已广泛应用于发酵工业,如培养基优化[8-9]、发酵过程控制[10]等。遗传算法(Genetic Algorithms,GA)是一种基于自然选择学说和遗传学原理的群体寻优算法,将繁殖、杂交、变异、竞争、选择等概念引入算法,非常适合与BP神经网络相结合寻求最优解[11-12]。
为了提高发酵生产水平,人们首先考虑的是优良菌种的选育。在完成菌种选育之后,发酵工艺的优化则是另一项基础而重要的任务。发酵工艺优化的实质是考察各变量对优化目标的影响,以获得影响因子与目标值之间的关系,进而确定最优发酵条件。本研究以诱变育种得到的番茄红素高产突变株B.trisporaI5(-)和正菌为发酵菌种,基于 BP(Back Propagation)神经网络模拟发酵培养基各组分含量与番茄红素产量之间的函数关系,再用遗传算法优化番茄红素发酵培养基的组成。
1 材料与方法
1.1 菌种
实验室保藏的三孢布拉霉菌Blakeslea trisporaNRRL 2895(+)和番茄红素高产突变株Blakeslea trisporaI5(-)。
1.2 培养基
1)固体培养基。 5°麦芽汁,琼脂 20 g/L,pH 自然,1×105Pa 灭菌 20 min。
2)种子培养基(g/L)。玉米粉 47,黄豆粉 23,KH2PO40.5,维生素 B10.002,蒸馏水 1 000 mL,pH 6.3,1×105Pa 灭菌 20 min[13]。
3)发酵培养基(g/L,优化前)。 玉米粉 19,黄豆粉 44, 大豆油 80,KH2PO41.5,MgSO4·7H2O 0.6,维生素 B10.002,蒸馏水 1 000 mL,pH 6.5,1×105Pa灭菌20 min[13]。
1.3 培养方法
1)固体培养。菌种涂布或划线接种于固体平板后,25 ℃培养 4~5 d。
2)种子培养。将生长4 d的孢子用无菌生理盐水洗下,调整B.trispora(+)和B.trispora(-)孢子浓度分别为105mL-1和106mL-1。各吸取正、负菌孢子1 mL分别接种于50 mL种子培养基,25℃、180 r/min培养48 h。
3)发酵培养。 将正、负菌种子液以 1∶5(v∶v)的比例混合后接种于发酵培养基,接种量为10%。25℃、180 r/min培养120 h,在发酵48 h时添加0.1 g/L的2-甲基咪唑(番茄红素环化酶抑制剂)。
1.4 BP神经网络模型设计
1.4.1 BP神经网络模型本试验以发酵培养基的组成作为BP神经网络的输入,番茄红素的体积产量作为输出,采用3层网络。一般输入层为多个变量,输出变量为一个或多个,但为了使模型更好,训练过程更方便,通常选一个输出变量。输入层包括碳源、氮源、植物油、磷酸二氢钾、硫酸镁,分别标记为X1、X2、X3、X4、X5;隐层的节点数n通过试验确定;输出层为番茄红素体积产量,标记为Y。模型的拓扑结构为5-n-1,见图1。隐层节点数的选择是影响BP网络模型性能的重要因素之一,但目前尚无理论方法确定隐层节点数,一般通过经验公式和试错法确定。为了保证足够高的模拟性能和泛化能力,通常在满足精度要求的情况下尽可能选择较少的节点数[14]。通过试错法确定隐层节点数,即通过试验,以模型预测值与实际测量值之间的误差大小为标准,选取合适的节点数。BP神经网络模型建模和遗传算法寻优均在Matlab R2012b软件中进行。

图1 拓扑结构为5-n-1的BP神经网络图Fig.1 Topology of BP network 5-n-1
1.4.2 数据样本为了获得典型的数据样本,参照正交设计思想,设计49组试验,随机选取其中40组作为训练样本,另外9组作为检验样本,49组试验设计及结果如表1所示。其中,每组设置3个重复,番茄红素产量取平均值。将输入样本和输出样本的样本数值分别导入Matlab,分别赋予变量名inputdata和 outputdata,并保存为 sample.mat。

表1 BP网络的训练样本Table 1 Training sample of BP network g/L

续表1
1.4.3 BP神经网络程序代码将原始样本数据导入MATLAB后,随机分为训练样本(40个)和检验样本 (9个)。分别试验在1~20个隐层节点数情况下,预测结果与实际结果的误差绝对值之和,由此确定隐层节点数。之后,对样本建模,输入层向隐含层传递的函数用tansig(S型正切函数),隐含层向输出层传递的函数选用purelin(纯线性函数),训练函数选择traingdx。源程序如下
1)确定隐层节点数程序
load sample%导入原始样本
data=inputdata';%矩阵转置
result=outputdata';
n=randperm(49);%1-49 随机排列
p=data(:,n(1:40));%取 40 个样本用于训练
t=result(:,n(1:40));
test=data(:,n(41:49));%取剩余 9 个样本用于检验
b=result(:,n(41:49));
save bpdata%将上述变量保存于bpdata.mat
[pn,pp]=mapminmax(p);%归一化处理
minp=pp.ymin;
maxp=pp.ymax;
[tn,tt]=mapminmax(t);
mint=tt.ymin;
maxt=tt.ymax;
fori=1:20%循环
net =newff (pn,tn,i,{'tansig','purelin'},'traingdx');%构建神经网络
net.divideParam.trainRatio=100/100;%修改训练样本比例
net.divideParam.valRatio=0/100;
net.divideParam.testRatio=0/100;
net.trainParam.epochs=2000;%最大训练次数
net.trainParam.lr=0.05;%学习步长
net.trainParam.goal=0.00001;%学习目标
net=train(net,pn,tn);%训练函数
testn=mapminmax('apply',test,pp);%归一化测试样本
an=sim(net,testn);%预测
a=mapminmax('reverse',an,tt);%反归一化
sse=sum((b-a).^2) %误差平方和
r(i)=norm(sse);%输出不同隐层节点数下的误差平方和
end
2)BP神经网络建模程序
load bpdata
[pn,pp]=mapminmax(p);
minp=pp.ymin;
maxp=pp.ymax;
[tn,tt]=mapminmax(t);
mint=tt.ymin;
maxt=tt.ymax;
net=newff (pn,tn,12,{'tansig','purelin'},'traingdm');
net.divideParam.trainRatio=100/100;
net.divideParam.valRatio=0/100;
net.divideParam.testRatio=0/100;
net.trainParam.epochs=20000;
net.trainParam.lr=0.05;
net.trainParam.goal=0.00001;
net=train(net,pn,tn);
testn=mapminmax('apply',test,pp);
an=sim(net,testn);
a=mapminmax('reverse',an,tt);
figure(1)
plot(a,':og')
hold on
plot(b,'-*');
legend('预测产量 ','实际产量 ')
title('BP网络预测和实际产量')
xlabel('样本 ')
ylabel('番茄红素产量(g·L^{-1})')
save net
1.5 遗传算法的寻优设计
上述BP神经网络对发酵培养基组成与番茄红素体积产量之间的关系进行建模,预测培养基成分不同含量下番茄红素的产量。为了获得各组分的最优含量,本文采用遗传算法(Genetic Algorithm)进行寻优。
在MATLAB R2012b中输入命令optimtool打开优化工具箱,求解器选择GA-Genetic Algorithm,变量数选择5,变量上下限分别为[20 4 20 0.8 0.2]和[50 16 50 2 0.8],初始种群20,种群类型选双精度,种群选择方法选Roulette,交叉点选单点交叉,交叉概率为0.8,变异概率选0.05,进化代数为100,其他保持默认。适应度函数为@fit,函数代码如下
function fitness=fit(x)
load net
x=x';
xn=mapminmax('apply',x,pp);
yn=sim(net,xn);
y=mapminmax('reverse',yn,tt);
fitness=-y;
1.6 生物量和番茄红素产量的测定
发酵结束后,取10 mL发酵液,8 000 r/min离心10 min,蒸馏水洗涤3次。菌丝体干重的测定采用称重法,105℃烘干至恒重后称重。番茄红素的测定则将洗涤后的菌丝体在40℃真空干燥后研磨破壁,然后用石油醚萃取至菌丝体无色,合并萃取液用于番茄红素含量的测定。番茄红素的测定采用比色法,萃取液经适当稀释后在502 nm波长下测定吸光值,并用标准曲线计算番茄红素质量浓度[15]。见图2。

图2 番茄红素标准曲线Fig.2 Standard curve of lycopene
2 结果与分析
2.1 碳源种类对生物量和番茄红素产量的影响
碳源不仅是构成细胞和番茄红素的碳骨架,也是维持细胞生命活动的重要能量来源,常见的碳源包括糖类、有机酸、低级醇、油脂等。针对已有文献报道及B.trispora的生长特性,本文选取玉米粉、麦芽糊精、可溶性淀粉、葡萄糖、蔗糖这5中常见碳源,每种碳源3个浓度水平,考察其对B.trispora产番茄红素及生物量的影响。其中,碳源低、中、高质量浓度水平分别为20、30、40 g/L,结果如图3所示。由图可知,玉米粉对番茄红素产量和生物量的影响均明显优于其他碳源。因此,选择玉米粉作为碳源进行后续试验。
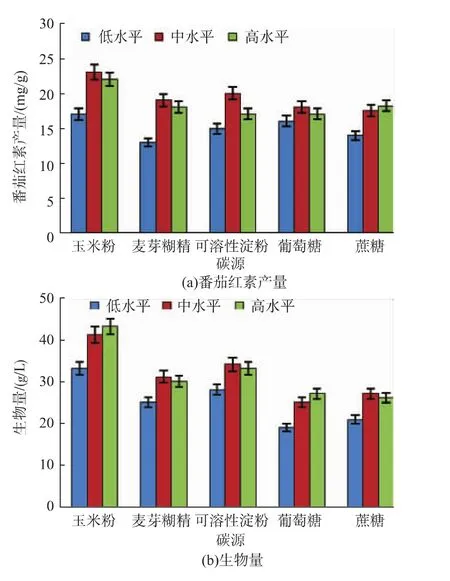
图3 不同碳源对番茄红素产量发酵的影响Fig.3 Effect of different carbon source on lycopene fermentation
2.2 氮源种类对生物量和番茄红素产量的影响
氮源用于细胞物质(如蛋白质、核酸等)和含氮代谢物的合成,常见的氮源可以分为有机氮源和无机氮源两类。无机氮源主要包括铵盐、硝酸盐、氨水等;有机氮源主要包括黄豆粉、玉米浆、黄豆饼粉、蛋白胨、棉籽饼粉、酵母粉等。本论文选取黄豆粉、玉米浆干粉、蛋白胨、硝酸钠、硫酸铵这五种常见氮源,每种氮源选取3个浓度水平,考察其对番茄红素产量和生物量的影响。由于黄豆粉中氮的利用率较低,其低、中、高浓度水平分别为 20、30、40 g/L;其它氮源的低、中、高浓度水平分别为 6、10、12 g/L,结果如图4所示。有机氮源对番茄红素产量和生物量的影响明显优于无机氮源,且玉米浆干粉的效果最佳。因此,玉米浆干粉被选为后续试验的氮源。
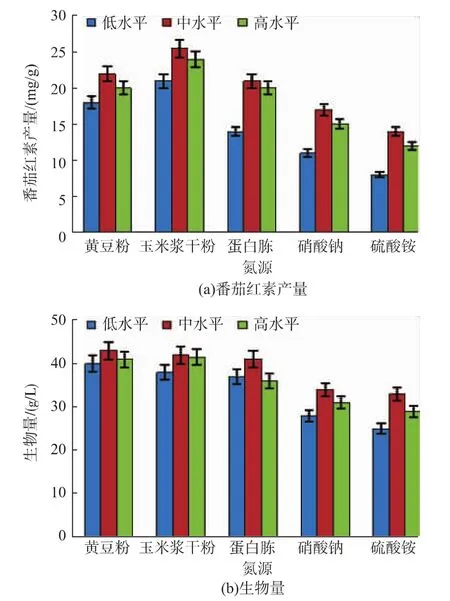
图4 不同氮源对番茄红素发酵的影响Fig.4 Effect of different nitrogen source on lycopene fermentation
2.3 不同植物油对生物量和番茄红素产量的影响
植物油作为辅助碳源经常被用于工业发酵中,如抗生素的生产等,植物油可被微生物分泌的胞外脂肪酶分解,进而吸收利用。本试验选取棉籽油、大豆油、花生油、菜籽油、亚麻籽油和橄榄油这6中常见植物油,每种植物油选取低、中、高3个浓度水平,分别为30、40、50 g/L,考察其对生物量和番茄红素产量的影响,结果见图5。在添加大豆油或亚麻籽油的情况下,单位菌体番茄红素产量较其它试验组高,但亚麻籽试验组的生物量明显低于大豆油试验组。因此,综合考虑单位菌体番茄红素产量和生物量,选择大豆油作为辅助碳源进行后续试验。
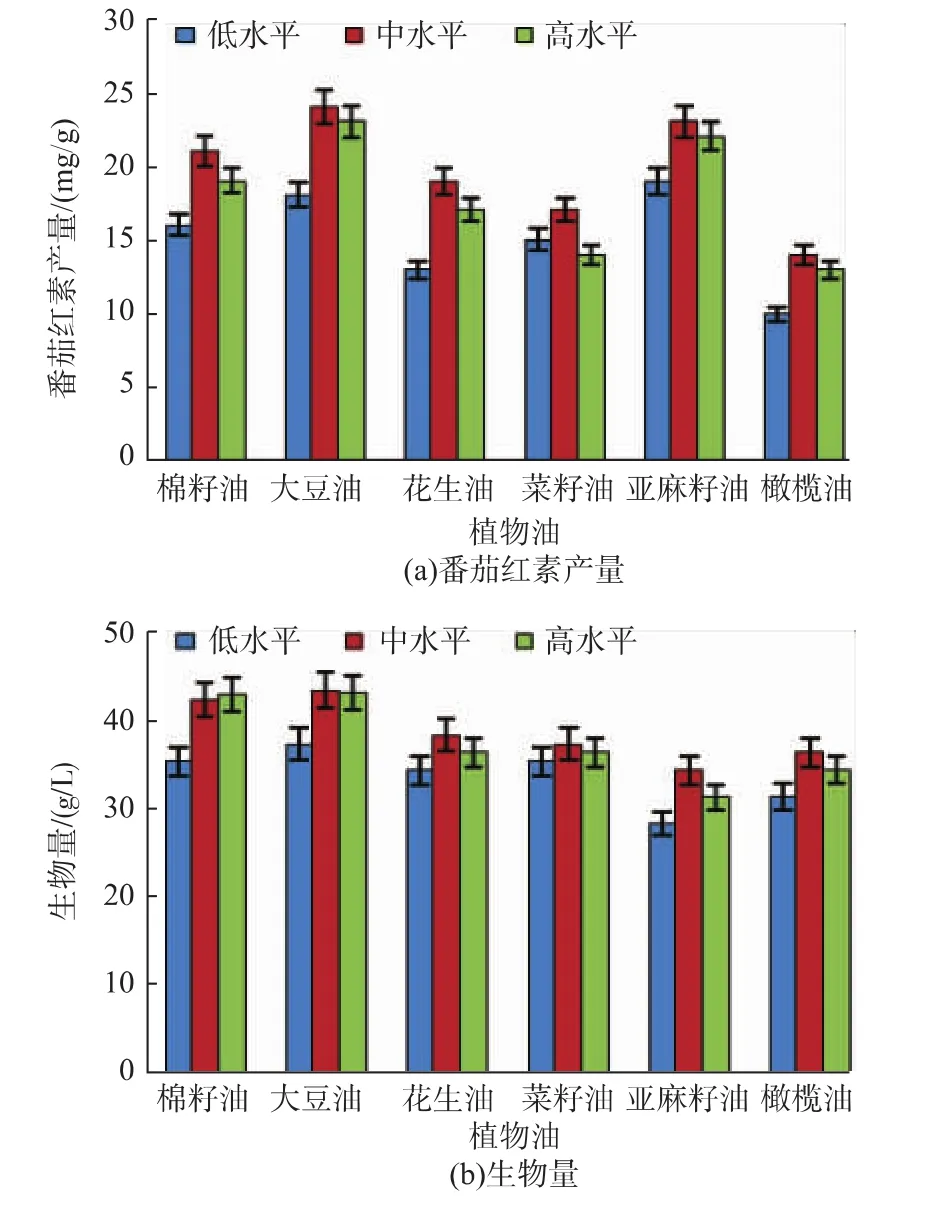
图5 不同植物油对番茄红素发酵的影响Fig.5 Effect of different plant oils on lycopene fermentation
2.4 BP神经网络模型的建立与检验
根据碳源、氮源、植物油种类的选择试验结果,本试验选取玉米粉、玉米浆干粉、大豆油、磷酸二氢钾、硫酸镁作为输入变量,变量的取值范围如表1所示。采用3层BP神经网络进行建模,输入层传递函数为tansig,输出层传递函数为purelin,训练函数为traingdx。由于确定了输入层节点数、输出层节点数、传递函数和层数等参数,所以隐层的节点数将在很大程度上决定网络性能。为了获得更好的网络性能,依次选择1~20个隐层节点数,经过2 000次训练后,得到相应的误差平方和,结果如图6所示。当隐层节点数为12和17时,误差平方和较小,选取这两个节点数做进一步训练,结果表明,隐层节点数为12时误差平方和最小。因此,选择12个隐层节点数对BP神经网络进行2万次的训练,训练目标为均方误差达到10-5,学习步长为0.05。网络经过19 848次迭代后均方误差达到目标值,网络性能达到稳定,训练曲线如图7所示。
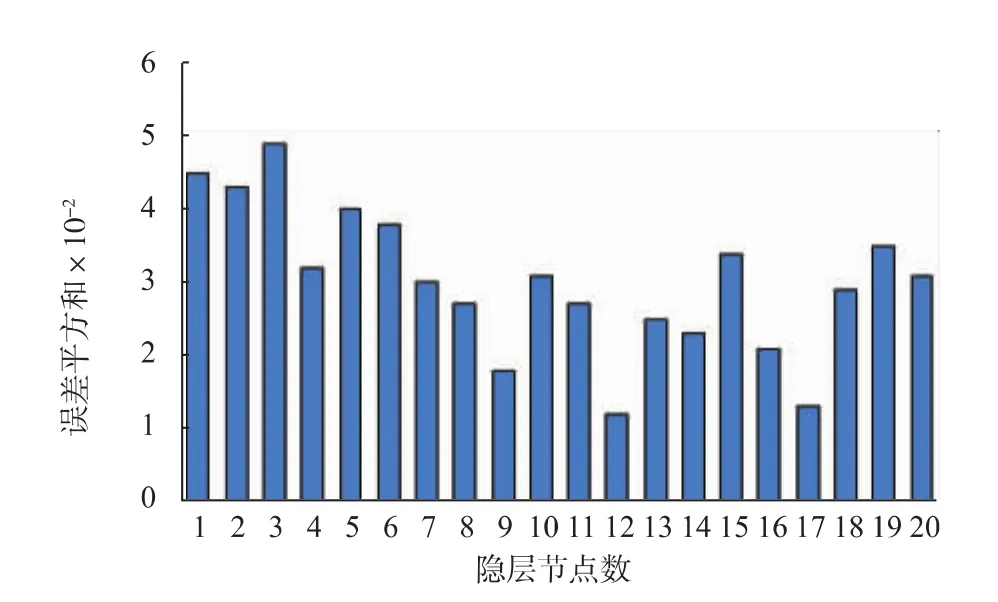
图6 不同隐层节点数下的BP神经网络的误差平方和Fig.6 Sum squared error of BP neural network in different hidden layer nodes
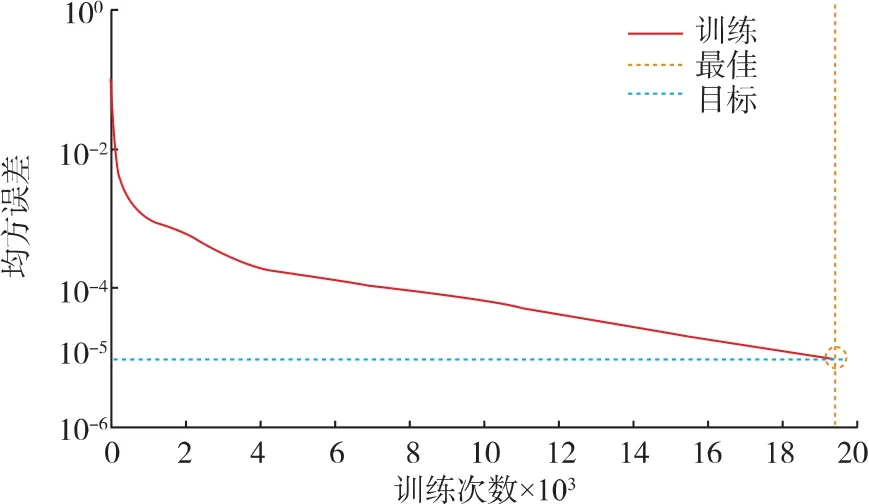
图7 BP网络训练曲线Fig.7 Training curve of BP network
为了进一步确定网络的模拟性能和泛化能力,将检验样本的自变量输入模型,经过模拟仿真后得到预测值,比较预测值与实际值的差别,结果如图8所示。
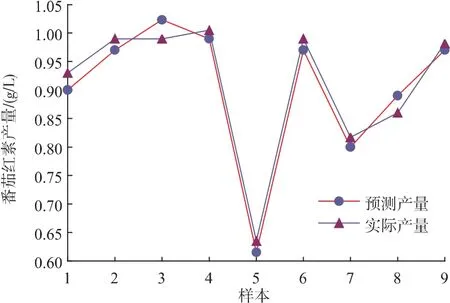
图8 检验样本预测产量与实际产量比较Fig.8 Comparison of simulation and actual production of test sample
从误差曲线可以看出,预测值与实际值之间的误差非常小,正负误差均在4%范围内,二者的吻合度非常高。因此,所建立的BP神经网络模型稳定且泛化能力较强,可用于估算培养基成分不同含量下番茄红素产量。
2.5 利用遗传算法优化培养基组成
在BP神经网络建模成功后,利用BP网络捕获的输入与输出之间的映射关系,作为遗传算法的适应度函数。再根据训练数据样本确定5种培养基组分的变化范围(搜索空间),在搜索空间内随机选择20种组合作为初始群里,经过不断的选择、交叉、变异操作,直到满足终止条件(见图 9(a))。最终,当玉米粉、玉米浆干粉、大豆油、磷酸二氢钾、硫酸镁的含量分别为 41.2、8.93、26.5、1.39、0.46 g/L 时, 获得番茄红素产量最大预测值1.27 g/L(见图9(b))。与初始培养基相比,变化较大的为玉米粉和大豆油的质量浓度,玉米粉的质量浓度从初始培养基的19 g/L增加到优化后的41.2 g/L,大豆油的质量浓度从初始培养基的80 g/L减少到优化后的26.5 g/L。二者均作为碳源,其中玉米粉是较易利用的碳源,在发酵过程前期,微生物将优先利用玉米粉快速生长,在发酵中后期,随着玉米粉的逐渐耗尽,微生物开始大量利用大豆油作为碳源维持生命活动。大豆油的添加虽然可以延长发酵周期,促进产物形成,但是过量的大豆油也会影响溶氧、pH等。为了验证预测结果的可靠性,以此组合作为培养基的配方,做3组重复试验,测定番茄红素的实际产量。结果表明,在此条件下,番茄红素的单位菌体番茄红素质量浓度和生物量分别为28.1 mg/g和44.4 g/L,体积产量为1.25±0.02 g/L,与预测值的相对误差不超过5%,较优化前(0.95±0.02 g/L)提高了 31.6%。因此,BP 神经网络模型可以很好的模拟发酵培养基各组分含量与番茄红素产量的关系,与遗传算法相结合,可以快速得到培养基的最优组成。
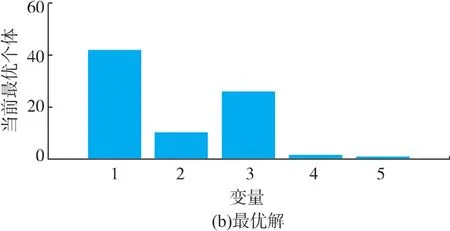
图9 遗传算法寻优轨迹Fig.9 Evolution of generations for lycopene production process optimization
3 讨论
在碳源的选择中,玉米粉固形物含量高,有利于丝状真菌的附着和蔓延,因此生物量较大。而其他可溶性碳源由于固形物含量低,菌丝体容易结团,严重影响传质和摄氧,从而影响菌丝体的生长和番茄红素的合成。此外,玉米粉不仅含有丰富的碳水化合物,还含有多种生长因子和微量元素,更有利于番茄红素的合成。在氮源的比较中,无机氮源质量稳定,但成分单一,缺乏营养物质,作为唯一氮源效果往往不好。在有机氮源中,玉米浆干粉不仅氨基酸含量丰富,还含有多种微量元素、生物素等,而且较玉米浆成分更加稳定,有利于菌体的生长和番茄红素的合成。当快速利用碳源消耗殆尽时,植物油可为微生物的生长提供碳骨架和能量来源,延长发酵周期。在番茄红素的发酵生产过程中,植物油的分解产物乙酰辅酶A不仅可进入三羧酸循环,为细胞生长提供能量,还可作为脂肪和番茄红素合成的共同前体物质。因此,植物油的添加不仅可明显提高生物量,还可以显著促进番茄红素的合成。
单因素试验忽略了不同培养基成分之间的交互作用,可能会错过最优条件,而且试验次数很多;响应面优化法通常用的模型是二次多项式,在实际应用中,只能用到2~3个水平;正交设计和均匀设计都会受到因素的限制。遗传算法已被证实非常适用于多因素多水平、非线性优化的问题,但遗传算法存在容易丢失历史数据的问题。人工神经网络能很好的捕获和训练数据,它允许用户直接用一种稳定的形式来访问历史数据,这正好弥补了遗传算法的缺点。因此,人工神经网络可以帮助研究者处理历史数据,获得培养基组分与产物之间的一种隐函数关系,遗传算法可利用这种函数关系作为适应度函数,从而快速搜索得到最优解。利用人工神经网络和遗传算法相结合优化培养基组成的报道很多,Nagata等[16]利用人工神经网路和遗传算法优化海因酶发酵培养基组成,获得的最大产量比多项式优化结果高出14%;Weuster-botz等[17]利用遗传算法优化甲酸脱氢酶发酵培养基,甲酸脱氢酶的产量提高了50%;Sivapathasekaran等[18]采用人工神经网络和遗传算法相结合优化生物表面活性剂的发酵培养基,其产量提高了约70%。
4 结 语
本研究采用拓扑结构为5-12-1的BP神经网络建立培养基各组分含量与番茄红素产量的网络模型,很好的模拟了它们之间关系,与遗传算法相结合,快速得到了培养基的最优组成,经验证,番茄红素产量较优化前提高了31.6%。因此,BP神经网络结合遗传算法是番茄红素乃至其它代谢产物发酵培养基优化的有力工具。
猜你喜欢
食品安全导刊(2021年20期)2021-08-30 06:40:36
人民珠江(2019年4期)2019-04-20 02:32:00
新疆农垦科技(2016年10期)2016-06-15 20:29:33
中国酿造(2016年12期)2016-03-01 03:08:11
计算机工程(2014年9期)2014-06-06 10:46:47
机械工程与自动化(2014年3期)2014-05-07 12:49:22
中国酿造(2014年9期)2014-03-11 20:21:03
食品工业科技(2014年9期)2014-03-11 18:15:28
食品与生物技术学报(2013年1期)2013-11-09 00:45:04
食品科学(2013年19期)2013-03-11 18:27:50
