
基于并行化粒子群算法的组合测试用例生成
2019-03-13 05:23王曙燕张海清孙家泽
西安邮电大学学报 2019年5期
王曙燕, 张海清, 孙家泽
(西安邮电大学 计算机学院, 陕西 西安 710121)
组合测试[1]作为一种可以降低软件成本并提高其可靠性的测试方法,旨在从庞大的组合空间中选取少量而有效的测试用例集,使这些用例集覆盖所有组合集,从而完成软件测试任务[2]。
两两组合测试作为组合测试的一种,近年来已成为很多学者研究的热点,且已被证明是一种能有效解决组合用例爆炸问题的方法[3]。组合测试生成最小用例集是一个NP-hard问题[4],主要研究方法有遗传算法(genetic algorithm, GA)[5]、蚁群算法(ant colony algorithm, ACA)[6]、粒子群算法(particle swarm optimization, PSO)[7]和模拟退火(simulated annealing-based, SA)[8]等启发式算法,以及K-均值聚类算法(K-means clustering algorithm,K-means)和K-medoids聚类算法(K-medoids clustering algorithm,K-medoids)等聚类算法。目前,粒子群算法、遗传算法和K-均值聚类算法应用较为广泛。基于K-均值聚类的组合测试用例生成优化算法[9]、基于粒子群优化和交叉熵(cross entropy, CE)生成组合测试用例的方法[10]和基于岛模型并行化的遗传算法(island parallel genetic algorithm based on Spark, IPGAS )[11]生成组合测试用例时,虽然可以生成更小规模的测试用例集,但随着软件系统输入参数的不断增加,消耗时长也会成倍增长[12]。
为了改善粒子群算法生成测试用例消耗时间过长的问题,本文提出一种并行化粒子群算法用于生成两两组合测试用例的方法。该方法主要基于大数据平台Spark[13],采用one-test-at-a-time策略和自适应粒子群算法相结合的方式,将需要覆盖的所有两两组合测试用例集进行分组,并分发到集群中不同的节点上进行寻优操作;待所有节点寻优结束后,利用Spark的Collect()函数进行测试用例集的收集,并对收集后的测试用例集进行约简操作。
1 基础理论介绍
1.1 覆盖表
在生成两两组合测试用例集时,需要对待测软件系统(software under test, SUT)的输入空间进行建模,并生成参数集,而每个参数可能有多个取值,为了确保SUT在这些参数相互作用下正常运行,需要设计相应的测试用例检测出交互故障。两两组合测试就是从测试用例集中选出有限但有效的用例集,可通过覆盖表表示,具体定义如下[14]。

1.2 基本粒子群算法
PSO算法[15]是通过模拟鸟群觅食过程中的迁移和群聚行为而提出的一种基于智能全局随机搜索算法。在PSO算法中,每个优化问题的解都是粒子在n维搜索空间中的位置,速度值决定当前粒子的飞翔方向和距离,粒子i的速度和位置分别表示为
Vi=(vi,1,vi,2,…,vi,n),Xi=(xi,1,xi,2,…,xi,n)。
每一次迭代通过更新当前粒子的最优解pBest和种群的最优解gBest,进行不断搜索,直到搜索出最优解或达到最大迭代次数。PSO算法通过适应度函数判断粒子的优劣,判断的方法是粒子所能覆盖组合的数目。在第t+1次迭代中,更新粒子的速度和位置公式[14]分别为
vi,j(t+1)=wvi,j(t)+c2r2[pBest(t)-xi,j(t)]+c1r1[gBest(t)-xi,j(t)],
(1)
xi,j(t+1)=xi,j(t)+vi,j(t+1)。
(2)
式中:vi,j为第i个粒子在第j维的速度;xi,j为第i个j维的位置;w为惯性权重,影响粒子的速度;c1和c2为加速因子,分别表示对当前粒子的最优位置pBest和种群的最优位置gBest的影响;r1和r2取[0,1]范围内的两个随机数,目的是保证种群的多样性。
2 两两组合测试用例生成
2.1 并行化策略
并行化策略主要分为生成组合集S、对S进行分组、将分组下发到各个节点中进行优化和最后回收用例集并进行约简等4个阶段。具体框架如图1所示。
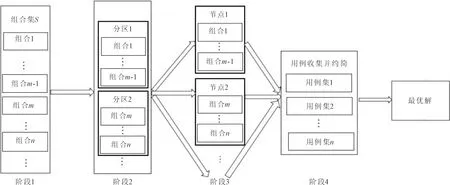
图1 并行化框架
2.1.1 组合集生成
通过分析实际问题,计算因素个数N以及每个因素的取值范围Di={1,2,…,Li},并根据因素的覆盖强度和约束条件,生成需被覆盖的二元组集合S。在生成组合集S后,为了增加每个节点上用于被覆盖二元组合的随机性,对组合集S进行重新排序,随机选取S中一半数量的粒子,并将选取的粒子再按随机方式插入到S中。
2.1.2 组合集分组
利用parallelize()将组合集S转换为弹性分布式数据集(resilient distributed dataset, RDD),并将该RDD划分为n个分区,其中每个分区是由若干个二元组集合组成的组合集Si(i=1,2,3,…,N)。
2.1.3 测试用例集生成
将分区后的RDD下发到集群中不同的节点进行寻优操作。在每个节点上采用one-test-at-a-time策略和自适应粒子群算法相结合的方式生成两两组合测试用例集T。
2.1.4 用例收集并约简
待所有节点寻优过程结束后,主节点利用Spark的Collect()函数对各个节点的用例集T进行收集,并对收集后的用例集进行约简操作[10],最后输出约简后的用例集。
2.2 生成测试用例集的过程描述
在集群的每个从节点上,基于Spark的并行化的粒子群优化算法 (parellel particle swarm optimization based on Spark,PPSOS)主要采用one-test-at-a-time策略和自适应粒子群算法相结合的方式生成两两组合测试用例集,一个节点上生成测试用例集的具体步骤如下。
步骤1生成一个空的测试用例集T。
步骤2判断需要被覆盖的二元组集合Si是否为空,若不为空,在Si中选取覆盖率最高的组合Q[16],生成代表迭代次数的累加器iterNums, 并置iterNums的初始值为0。
步骤3根据选取的组合Q生成初始种群P,而P中每个粒子即为当前粒子的初始位置,并将粒子的当前位置设置为该粒子的最佳位置pBest, 粒子中每个因素取(-1,1)区间内均匀分布的随机数[10]为粒子初始速度。
步骤4进入最优测试用例的生成阶段。更新种群中每个粒子的适应度值[10],适应度值越大代表粒子越优;通过粒子的优劣更新当前粒子的最佳位置pBest和当前种群的最优位置gBest。
步骤5自适应调整[17]式(1)中的惯性权重w,利用式(1)和式(2)更新种群中每个粒子的位置和速度值,并采用“回飞机制”校正更新后粒子位置不在可行域范围内的参数,并对该粒子中参数值不变的因素进行扰动操作[10]。
步骤6根据pBest更新种群P,并将累加器iterNums的迭代次数加1,至此,一次迭代寻优过程全部结束。
步骤7重复步骤4~步骤6,直到累加器iterNums达到迭代次数的上限,返回当前种群的最优位置gBest,即gBest为新生成的一条最优或近似最优的测试用例;反之则继续迭代。
步骤8剔除Si中已经被gBest覆盖的组合集,并将生成的最优测试用例gBest添加到T中。
步骤9重复步骤2~步骤8,直到Si为空,即该节点上的所有二元组集合已被覆盖完毕。至此,从一个节点上生成两两组合测试用例集的过程已全部结束。
待所有从节点寻优过程结束后,主节点利用Spark的collect()函数对各个从节点上生成的测试用例集T进行收集,并对收集后的用例集进行约简,最后输出约简后的两两组合测试用例集。
3 实验结果与分析
基于大数据平台Spark,通过Scala语言,实现PPSOS算法。PPSOS运行在由4个节点组成的小集群上,该集群基于Standlone模式,将其中一个节点作为主节点Master,其余3个节点全部用作Slave。每个节点的硬件环境为3.40 GHz i3 3240 处理、2 G内存和160 G硬盘;软件环境为Centos 7.0、Java 1.8、Hadoop 2.7.1和Spark 2.1.2。PPSOS算法的参数r1=r2=0.5,c1=c2=1.49。
3.1 参数调整
选取46和53443122两个实例[10],分析PPSOS中的子种群规模m和最大迭代次数Imax对生成测试用例集规模的影响。实验在相同条件下进行30次,取其规模的平均值作为比较对象。
表1表示子种群规模m和迭代次数Imax分别取不同值时,生成组合测试用例集规模的具体情况,加粗标记的数据表示其最优值。

表1 不同m或Imax下测试用例集的规模/个
由表1可知,当m=100,Imax=10时,实例46和53443122生成的用例集规模分别为22.0和30.6,以及21.8和31.0,规模均为最小值,说明PPSOS可用于生成较小规模的两两组合测试测试用例集。
3.2 同类算法比较
分别将PPSOS与已有两两组合测试用例生成方法在测试数据集生成规模和所消耗时间上进行比较。每个实例执行了30次,取其最优值作为对比数据。
3.2.1 测试数据集规模的比较
将PPSOS分别与测试用例自动生成系统(automatic efficient test generator, AETG)[18]、基于参数顺序渐进扩充的两两组合覆盖测试数据生成方法 (an IPO-based test generation tool, PAIRTEST)[18]、Williams[18]、Kobayashi[18]、NetWork[18]、解空间树算法 (pair-testing using solution space tree, PSST)[18]、SA、GA、ACA、交叉熵 (cross entropy, CE)[10]方法和PSO[10]比较,结果如表2所示,加粗标记的数据表示其最优值。
由表2中数据可知,PPSOS在测试用例的生成规模上除实例41339235与最优值差距较大外,其余实例均与最优值相当。因此,PPSOS生成两两组合测试用例的方法是有效的。
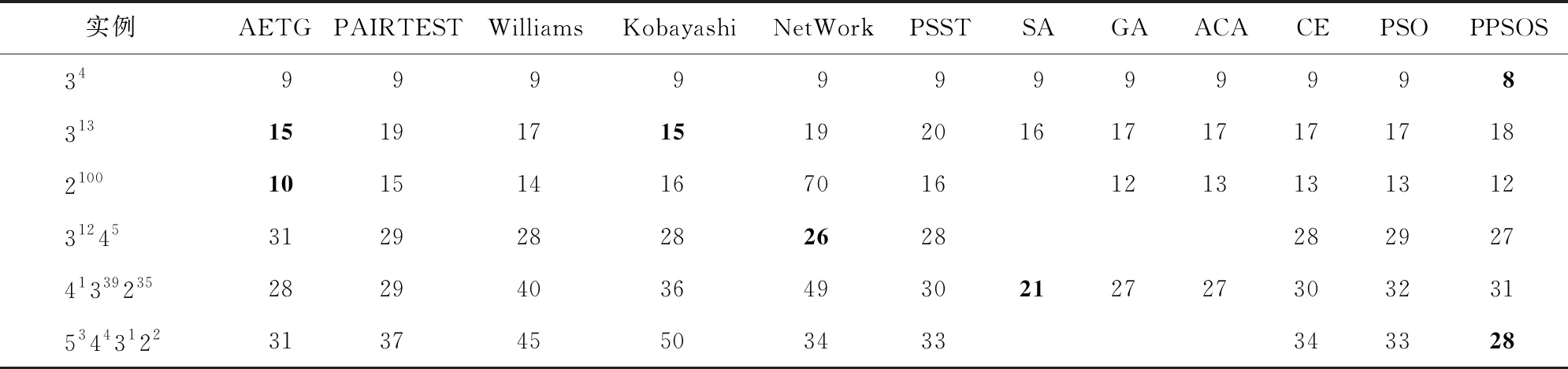
表2 不同实例各算法测试数据集规模/个
3.2.2 算法消耗时间的比较
将PPSOS在测试用例的生成时间上分别与SA[10]、GA[18]、ACA[10]、CE[10]、基于Spark的并行化遗传算法 ( parallel genetic algorithm based on Spark, PGAS)[14]、IPGAS[11]和PSO[10]进行比较,结果如表3所示。

表3 不同实例各算法运行时间/s
由表3中数据可知,除实例716151453823和6151463823的生成时间少于PPSOS外,其他算法的生成时间均大于PPSOS。因此,PPSOS可改善粒子群算法生成测试用例时间过长的问题。
4 结语
基于大数据平台Spark,PPSOS将需要被覆盖的全部二元组集合进行分组,并下发到集群中不同的节点上进行寻优操作,待所有节点寻优结束后再对所有用例集进行收集,并对收集到的用例集进行约简。实验结果表明,PPSOS生成两两组合测试用例集的规模和消耗的时间要少于SA、GA和ASA等算法,有效地减少了粒子群算法生成两两组合测试用例的消耗时间。
猜你喜欢
科学与信息化(2021年15期)2021-12-30
科学与信息化(2021年12期)2021-12-27
四川师范大学学报(自然科学版)(2021年6期)2021-11-15
科教导刊·电子版(2021年1期)2021-03-26
铁道通信信号(2020年6期)2020-09-21
成都信息工程大学学报(2019年2期)2019-08-28
铁道通信信号(2019年11期)2019-05-21
出土文献与古文字研究(2018年0期)2018-11-04
自动化学报(2018年2期)2018-04-12
智能系统学报(2017年3期)2017-08-01
