
基于转录组测序技术挖掘大豆蛋白质合成相关基因
2019-03-08 05:49郭静文史晓蕾赵青松刘兵强王凤敏张孟臣赵宝华杨春燕
华北农学报 2019年1期
郭静文,史晓蕾,刘 茜,赵青松,邸 锐,刘兵强,闫 龙,王凤敏,张孟臣,赵宝华,杨春燕
(1.河北省农林科学院 粮油作物研究所,国家大豆改良中心石家庄分中心,农业部黄淮海大豆生物学与遗传育种重点实验室,河北省遗传育种重点实验室,河北 石家庄 050035; 2.河北师范大学 生命科学学院,河北 石家庄 050024)
大豆(Glycinemax(L.) Merrill)起源于中国[1],大豆籽粒中蛋白质含量约占干质量的40%左右,是人类重要的植物蛋白来源。21世纪以来,品质性状改良成为大豆育种的主要目标之一,而提高大豆籽粒蛋白质含量也成为国内外品质育种的重要指标[2-3]。目前,通过常规杂交育种方法培育高蛋白大豆品种难度较大,而已发表的QTL定位结果有时也难以用于指导作物育种实践。因此,如何利用大豆资源中的优异基因,从分子水平揭示复杂的蛋白质合成代谢机制,是进行分子育种的重要前提。
国内外关于大豆蛋白质含量的研究有诸多报道。普遍认为大豆蛋白质合成受微效多基因调控,是数量性状遗传,加性效应明显[4]。试验材料的不同,环境条件的差异对蛋白质的含量也均有较大的影响。目前,在大豆所有的20个染色体上均发现有相关的QTL位点,共有298个QTL,详细信息可参考公共网站(http://soybase.org/)。连锁分析和关联分析均显示20号染色体检测到的大豆籽粒蛋白质合成相关QTL的频率最高[5-7],且在该染色体上有一个QTL区段(A688~Satt239)在多个环境和群体中均被检测到[8]。同时,大量研究表明,蛋白质含量与油分含量、单株产量、株高、主茎节数、主茎分枝数、开花期、成熟期均呈负相关[9-11],而蛋白质与脂肪两性状很难通过染色体片段重组的方法分开,因此,推测这2个性状紧密连锁或一因多效[12]。
对于蛋白质合成积累的研究,早期主要集中在阐述蛋白质构成因子、物质积累过程和环境条件几个方面。蛋白质的基本组成单位是氨基酸,氨基酸通过脱水缩合形成肽链。蛋白质是由1条或多条多肽链组成的生物大分子,每一条多肽链有20至数百个氨基酸残基不等。关于蛋白质合成的调控,前人研究发现,磷酸烯醇式丙酮酸羧化酶(PEPC)是控制种子中蛋白质和脂肪酸合成的重要调控基因,广泛分布于高等植物的细胞质中。Chen等[13]发现利用反义PEP基因转化油菜籽粒后,检测到蛋白质含量降低,同时含油量比对照增加了15%以上,该研究证明了底物竞争调控籽粒蛋白质、脂肪比率的理论。转录因子是一类蛋白质合成的重要调控因子,它们在蛋白质代谢中发挥着重要作用。大豆转录因子GmDof4和GmDof11转化拟南芥后,抑制了蛋白质合成相关基因的表达[14]。近些年来,研究人员通过比较不同物种间蛋白质合成相关的基因,从中发现一些共性的调控基因:LEC1、LEC2、ABI3、FUS3,这些关键的转录因子调控着胚胎发生和种子的成熟。LEC1是ABI3、FUS3上游的正向调控因子,而ABI3、FUS3、LEC1 基因协同作用以控制种子发育过程中的多个基本过程,当其中某个基因发生突变后,不仅贮藏蛋白的含量降低,同时也降低了对ABA的敏感性[15]。通过对蛋白质合成基因启动子区域的顺式调控元件进行研究发现,贮藏蛋白基因的启动子区域具有2个保守的结构域 RY/G和B-box,其中RY/G结构域包括2个作用元件 RY(CATGCA)和G-box(CACGTG)分别与B3或bZIP、bHLH类转录因子结合,而B-box由DistB (GCCACTTGTC)和ProxB(CAAACACC)2个作用元件组成,分别与bZIP或MYB类转录因子结合,因此,推测这些转录因子对蛋白质的合成具有调控作用[16]。
转录组测序技术(RNA-Seq)的发展使得功能基因和蛋白的发现步伐大大加快。该技术将 RNA 进行反转录得到 cDNA,然后对 cDNA 文库进行测序,旨在快速全面的获取某物种在某状态的下的全部转录本[17]。其以速度快、准确性高、运行成本低等特性受到广泛关注。与基因芯片技术相比,RNA-Seq技术能够对特定细胞或组织在特定状态下的基因表达种类和丰度进行更精准的定性定量分析。近年来 RNA-Seq 技术在作物研究中被广泛应用于基因资源挖掘、揭示突变体变异机制、探究作物生理生化过程、研究抗病、抗逆的机制等方面,为不同生物的功能基因组学开展提供了新的思路与研究方法[18-19]。在基因资源的挖掘方面,Wang等[20]利用转录组测序技术对野生和突变型棉花的毛状体纤维细胞的分裂与延长过程进行探究;和小燕等[21]以含油量高及含油量低的2个花生品系为研究材料,构建了与油脂累积相关的2个发育时期的转录组测序文库,发现各类调控脂肪酸生物合成的基因在花生种子油脂合成初期十分活跃,并挖掘到油体固醇蛋白等基因可能参与了油脂的合成与代谢;除此之外,研究人员利用 454 平台从玉米[22]、羊草、油橄榄[23]等植物中发现了新基因。RNA-Seq技术对揭示突变体变异机制也具有一定的作用。栾海业等[24]以大麦白化颖壳突变体与野生型植株为研究材料进行转录组测序分析,结果表明,导致大麦白化颖壳突变体的出现,可能是因为叶绿体形成和发育的相关基因其表达受到了相关抑制,从而导致了光合作用的降低。在探究作物生理生化过程方面,陈静[25]利用 RNA-Seq 技术对花生种子休眠与解除休眠过程进行了研究,发现赤霉素 20 氧化酶、EREBP-like 因子热激蛋白等综合调控花生种子休眠解除以及萌发。在抗病虫害研究中,李海燕等[26]以抗病的五寨黑豆为材料,对大豆胞囊线虫侵染前与侵染后的转录组文库进行检测对比,发现苯丙烷类代谢途径及氧化磷酸化代谢通路对五寨黑豆的抗病有重要作用。黄启秀等[27]利用转录组测序技术对抗枯萎病抗性表现不同的7种材料进行研究,发现了可能与海岛棉枯萎病抗性相关的代谢通路-类黄酮代谢通路。除此之外,研究人员还应用转录组技术在水稻[28]、小麦[29-30]以及甘薯[31]等作物中进行了相关的抗病试验,取得了一定的结果。在抗逆境领域,任梦露等[32]利用转录组测序技术研究大豆茎秆对荫蔽胁迫的响应,发现南豆 12 在荫蔽胁迫下其细胞壁多糖的含量和木质素含量有明显提升,并对生长素发生响应,以此方式来增加植株茎的强度,从而保持茎的某种形态优势,并提升其抗倒伏性,最终实现提高对荫蔽环境的适应程度。孙爱清等[33]以强抗旱花生品种为材料,对干旱处理过的花生叶片进行 RNA-Seq 分析,旨在探究花生干旱胁迫下的植株响应,结果发现类黄酮代谢途径可能在该过程中有重要作用。目前,作物中利用转录组测序技术的应用十分广泛,但在挖掘大豆发育时期籽粒中蛋白质合成相关基因的研究鲜有报道。
因此,本研究以遗传背景相近的大豆高蛋白品系冀HJ117及其回交亲本冀豆12为研究材料,利用测序技术检测两样本开花后14 d籽粒的表达谱。通过对差异表达基因进行功能注释、GO功能分类、富集代谢途径的分析以及荧光定量PCR分析,筛选出与蛋白质合成密切相关的基因,为揭示蛋白质合成代谢机制奠定理论基础。
1 材料和方法
1.1 试验材料
亲本组合冀豆12与茶秣食豆杂交后代与母本冀豆12(蛋白质含量46.48%)回交2次,得到高蛋白大豆冀HJ117(蛋白质含量52.99%)。冀HJ117和冀豆12由河北省农林科学院粮油作物研究所提供。将冀HJ117和冀豆12大豆籽粒种植于河北省农林科学院粮油作物研究所堤上试验站,当试验材料进入开花盛期时,分别对冀HJ117和冀豆12同一天开花的花朵进行标记,并对开花后14 d的籽粒进行取样,使用液氮速冻保存。
1.2 试验方法
1.2.1 RNA-Seq文库的构建及测序 RNA-Seq文库构建及测序工作由华大基因科技有限公司完成。
1.2.2 数据处理及差异表达基因的筛选 对测序得到的原始数据进行去杂处理得到有效序列(Clean reads),使用比对软件SOAPaligner/soap2将有效序列比对到参考基因组。利用唯一比对上基因的reads数目和比对上参考序列的总reads数来计算基因表达量,基因表达量的计算使用RPKM法[34],差异表达基因的筛选参照Audic等[35]发表在Genome Research上的基于测序的差异基因检测方法。基于差异基因的功能注释,对所有差异表达基因进行Gene Ontology(GO)功能显著性富集分析,分析将计算得到的P值(P-value)通过Bonferroni校正之后,以correctedP-value≤0.05为阈值,满足此条件的GO条目(GO term)定义为在差异表达基因中显著富集的GO term,以此确定差异表达基因行使的主要生物学功能。代谢通路(Pathway)显著性富集分析将Q值(Q value)≤0.05的Pathway定义为在差异表达基因中显著富集的Pathway,从而确定差异表达基因参与的最主要生化代谢途径和信号转导途径。
1.2.3 qRT-PCR检测候选基因的表达量 随机选取9个差异表达基因进行基因的表达量检测,使用北京天根公司的RNA prep pure Plant Kit试剂盒分别提取大豆冀HJ117及冀豆12 14 d籽粒的RNA,并使用TaKaRa RNA PCRTMKit(AMV) Ver.3.0反转录得到cDNA,进行荧光定量PCR分析,选用CYP2基因为内参基因。
试验所选基因及引物序列如表1,合成于生工生物工程(上海)股份有限公司。qRT-PCR试验参照TaKaRa Premix Ex TaqTMⅡ试剂盒,反应体系含SYBR Premix Ex Taq Ⅱ 10 μL、模板0.5 ng、PCR正向引物(10 μmol/L) 1 μL、PCR反向引物(10 μmol/L) 1 μL, 补水至总体积20 μL。扩增反应程序为:95 ℃孵育30 s;40个循环的95 ℃ 5 s,60 ℃ 30 s,55 ℃ 30 s。该反应使用美国Bio-Rad Lcycleri Q5荧光定量PCR仪进行扩增。
试验数据分析采用 2-ΔΔCt法进行相对定量分析,计算过程如下:先分别计算出每组的ΔΔCt=(Ct目的基因1-Ct内参基因)-(Ct目的基因2-Ct内参基因),再根据ΔΔCt 求出 2-ΔΔCt以及标准误。使用Microsoft Excel 2007 软件处理数据并作图。
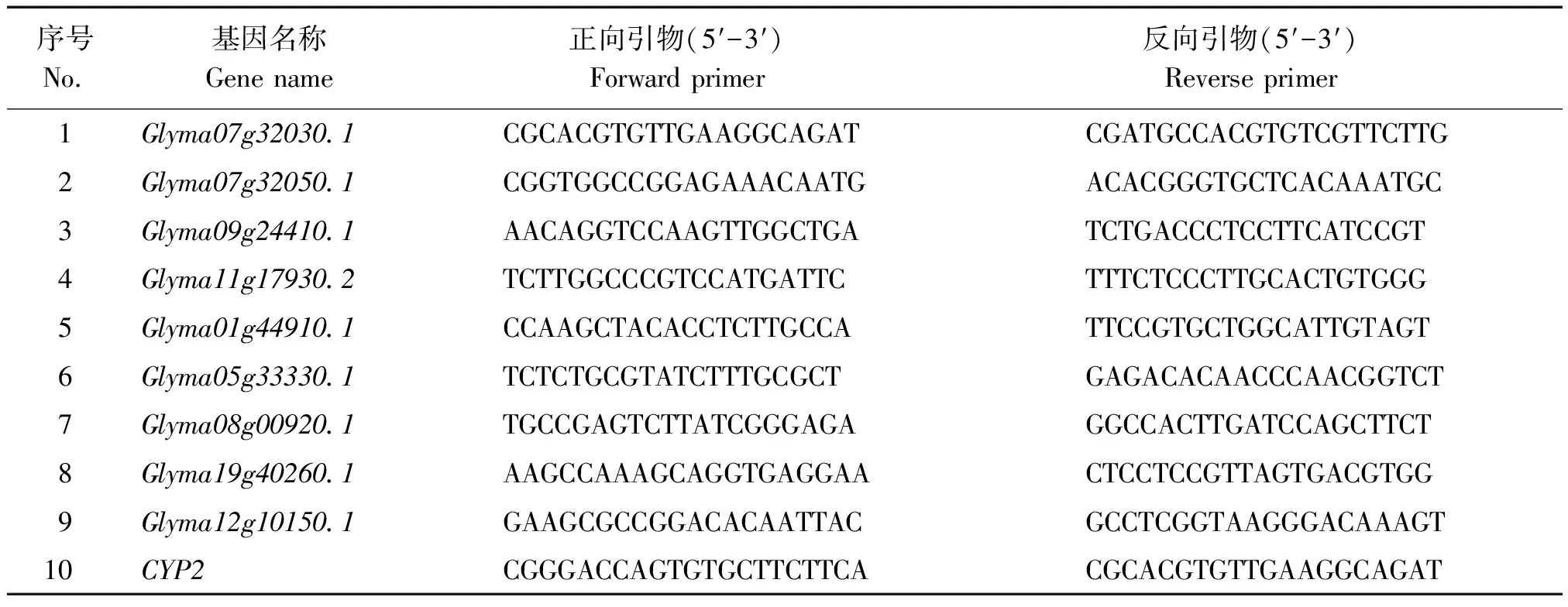
表1 基因名称及引物序列Tab.1 Genes and primers for qRT-PCR
2 结果与分析
2.1 测序质量评估与数据比对统计
通过高通量测序仪Illumina HiSeqTM2000对冀豆12和冀HJ117 14 d籽粒的cDNA测序,分别得到原始序列8 747 900,8 486 919条。通过过滤,冀豆12得到有效序列8 684 049条,占原始序列的99.27%;冀HJ117得到有效序列8 410 499条,占原始序列的99.10%。表明测序质量较高,适合进行后续的生物信息分析。
将冀豆12与冀HJ117过滤得到的有效序列与大豆参考基因组进行比对,表2是各样品与参考基因组的数据比对统计。从比对结果看,两样本成功比对上的序列均在700万条以上,效率分别为85.75%,86.01%。
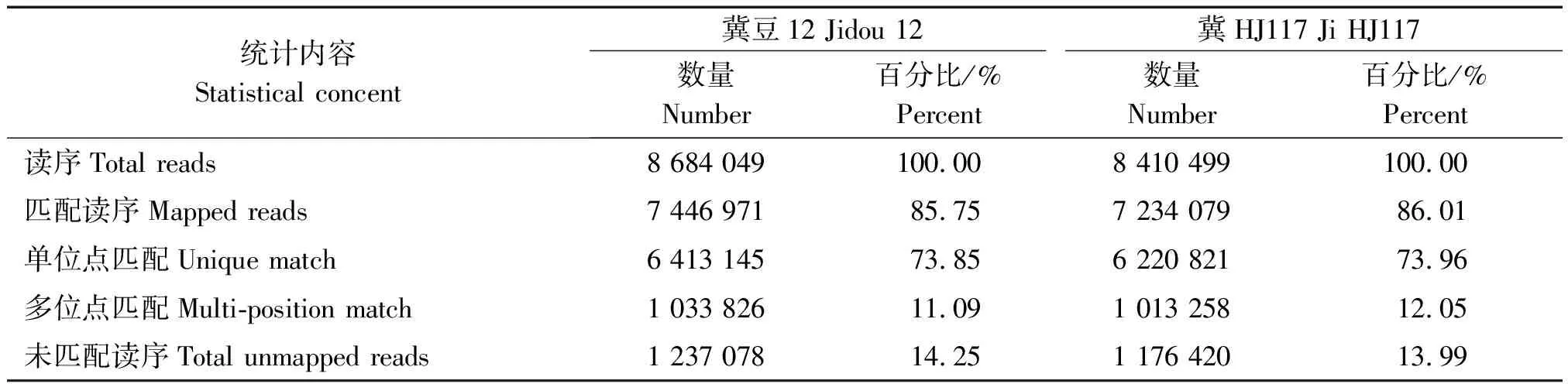
表2 有效序列与参考基因组比对结果统计Tab.2 Comparison between clear reads and reference genomes
2.2 cDNA片段随机性检验
由于不同参考基因有不同的长度,笔者把reads在参考基因上的位置标准化到相对位置(reads在基因上的位置与基因长度的比值),然后统计基因不同位置比对上的reads数量。从图1可以看出,2个样品的reads在参考基因上不同位置的分布相对比较均匀,表明cDNA片段化的随机性好,保证了测序质量。
2.3 差异表达基因的筛选
将两样本差异检验的P-value作多重假设检验(FDR)校正,并根据基因的表达量(RPKM值)计算该基因在不同样本间的差异表达倍数。将同时满足FDR≤0.001且倍数差异不低于2倍的基因定义为差异表达基因。经分析冀HJ117和冀豆12 2个转录组,共得到差异表达基因336个,其中冀HJ117较冀豆12上调表达基因195个,下调表达基因141个(图2-A)。
2.4 差异表达基因的功能注释
通过差异表达基因的筛选,获得差异表达基因的GO IDs。对冀豆12和冀HJ117的差异表达基因进行功能注释,在336个差异表达基因中,获得功能注释的基因为234个,未找到匹配信息的基因数为102个,2种情况占比分别为69.94%,30.36%(图2-B)。

A.冀豆12的reads在参考基因上的分布均匀性统计;B.冀HJ117的reads在参考基因上的分布均匀性统计。A.Distribution statistics of reads mapped to reference gene in Jidou 12; B. Distribution statistics of reads mapped to reference gene in Ji HJ117.

A.差异表达基因的筛选;B.差异表达基因的功能注释统计。A.Screening of differential transcription genes; B. Functional annotation of differential transcription genes.
2.5 差异表达基因的GO分类
对样本冀HJ117与冀豆12的336个差异表达基因的GO功能注释进行统计分析,GO总共有3个类目,分别描述基因参与的生物过程、所处的细胞位置以及基因的分子功能。
图3是冀HJ117与冀豆12样品差异表达基因GO注释聚类图,从图中可知,在生物过程分组的差异表达基因注释到了15个GO条目中,其中新陈代谢过程有95个差异表达基因,占生物过程分类的22.9%,其中61个基因上调表达,34个基因下调表达;细胞过程有76个差异表达基因,占生物过程的18.4%,47个基因上调表达,29个基因下调表达;应激反应有58个差异表达基因,占14.0%,上调表达基因41个,下调表达基因17个;而生物过程正向调控所占比例最低,仅有2个差异表达基因下调表达,占比例0.5%。
在所处的细胞位置类目下差异表达基因共注释到6个GO条目中,其中细胞、细胞组分、细胞器3个条目的差异表达基因较多,分别有160,144,98个差异表达基因,占细胞位置的36.2%,32.7%,22.2%;封闭性膜和大分子复合物的差异表达基因数目最少,均为4个,占0.9%比例。
然而在分子功能分组中差异表达基因注释到5个GO条目,其中具有催化活性的差异表达基因有117个,占49.5%;具有连接活性的差异表达基因有101个,占42.8%;而酶调节活性和分子传感器活性均仅有2个差异表达基因,占该分组比例0.8%。
2.6 GO功能的显著性富集分析
GO功能显著性富集分析可以筛选出在差异表达基因中显著富集的GO功能条目,并筛选出差异表达基因与哪些生物学功能显著相关。结果如表3所示,参考基因在生物过程分组中有注释的基因共25 633个,本研究有注释的差异表达的基因共171个。在该分组中有3个条目显著富集,主要涉及应激反应、化学稳态以及离子稳态;在细胞位置分组,有注释的参考基因共27 869个,本研究注释到162个基因差异表达,并在高尔基堆,高尔基池2个条目达到显著富集;在分子功能分组,有注释的参考基因共29 635个,本研究有179个注释的差异表达基因,这些差异表达基因在氧化还原酶类、氧化金属离子、受体氧,氧化还原酶类、氧化金属离子,氧化还原酶类3个条目显著富集。
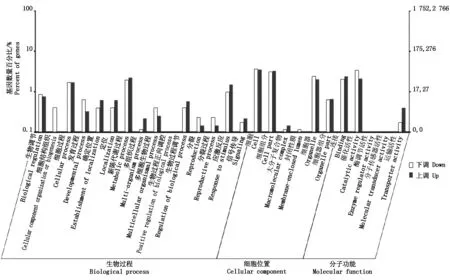
图3 差异表达基因GO注释聚类图Fig.3 GO annotation of differentially expressed genes
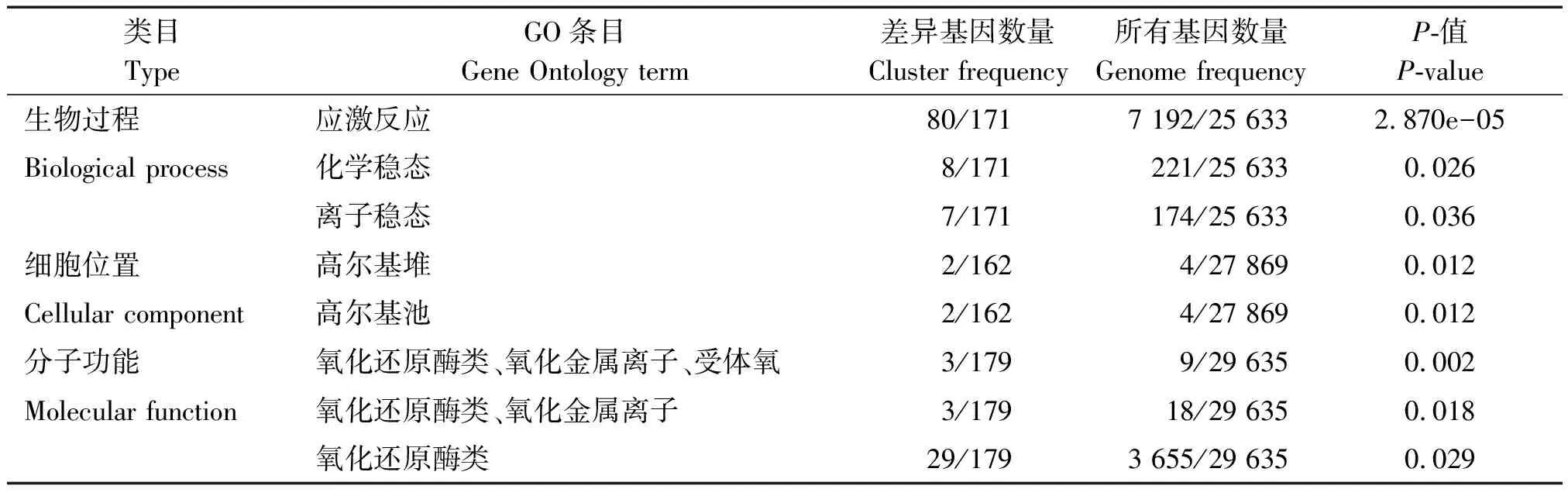
表3 差异表达基因中显著富集的GO termsTab.3 Significantly enriched GO items in DEGs
2.7 KEGG分析
将样本冀HJ117与冀豆12的表达基因与KEGG数据库比对,数据库中具有通路注释的基因共29 169个,本研究中注释到的差异表达的基因共有197个,参与了72个代谢通路。将Qvalue≤0.05的pathway定义为在差异表达基因中显著富集的Pathway。本试验的Pathway显著性富集分析结果发现,差异基因仅显著富集在蛋白质内质网合成途径中,该途径共有34个差异表达基因,占有注释的差异表达基因的17.26%,其中冀HJ117较冀豆12有33个基因上调表达,1个基因下调表达。
除此之外,差异表达基因还参与黄酮和黄酮醇的生物合成,丙氨酸、天门冬氨酸和谷氨酸代谢,脂肪酸生物合成,柠檬烯和蒎烯降解,类黄酮生物合成以及各类氨基酸的代谢和蛋白质输出途径等通路中,其详细信息统计于表4中。
图4为KEGG数据库中蛋白质内质网合成途径的详细信息,其中加粗方框为上调基因所在位置,虚线方框为同时存在上调基因和下调基因。差异表达基因推测的蛋白名称、所对应的KO号以及该基因的log2ratio值统计于表5中。从表中发现,差异表达基因所对应的表达蛋白主要有钙联蛋白(Calnexin,CNX)、结合免疫球蛋白(Binding immunoglobulin protein,Bip)、内质网膜结合连接酶(RING-finger protein with membrane anchor 1,RMA1)以及热激蛋白(Heat shoct proteins,Hsp20、Hsp40、Hsp70、Hsp90)。其中热激蛋白Hsp20的差异表达基因最多,共21个,其中20个基因上调表达,1个基因下调表达。

表4 Pathway显著性富集分析结果Tab.4 Pathway enrichment analysis of DEGs
注:**.达到极显著差异。
Note:**.The difference is significant at the 0.01 level.

加粗标记为上调基因所在位置;虚线标记为下调基因所在位置。The bold marker is the location of the up-regulated genes; The dotted marker is the location of the down-regulated gene.

表5 蛋白质内质网合成途径差异表达基因详细信息Tab.5 Details of genes in protein processing in endoplasmic reticulum
2.8 调控表达的转录因子分析
在冀HJ117与冀豆12差异表达的336个差异表达基因中,共有6个调控表达的转录因子,分属在5个转录因子家族中,分别是MYB、AP2、HSF、B3、以及Trihelix。其中有4个转录因子在冀HJ117中表达量较高,有2个转录因子在冀豆12中表达量较高,表6是差异表达基因中的转录因子的详细信息。

表6 差异表达基因中的转录因子Tab.6 Transcription factors of differential transcription genes
2.9 实时荧光定量PCR验证
为验证转录组测序数据的可靠性,从蛋白质内质网合成途径的34个差异表达基因中随机挑选9个基因(表1)进行qRT-PCR检测,经检测候选基因扩增的引物熔解曲线均为单峰,表明该引物对基因的扩增具有特异性。
通过对9个基因分别在冀HJ117与冀豆12 14 d籽粒中的表达量分析发现,候选基因在冀HJ117中的表达量均高于在冀豆12中的表达量(图5),该结果与RNA-Seq的分析结果趋势相一致。

图5 候选基因在冀HJ117与冀豆12的表达量Fig.5 Expression of candidate genes in Ji HJ117 and Jidou12
3 结论与讨论
蛋白质的合成代谢是个复杂的过程,主要涉及两方面:一是氨基酸的生理合成,即碳素和氮素的调运,二是贮藏蛋白基因的转录翻译及加工。大豆作为固氮植物将大气中的氮气转化为氨,氨通过转氨作用为其他氨基酸提供氨基,其中谷氨酰胺合成酶是氨代谢中的一个主要调控点。对于氨基酸的生物合成机理,多数氨基酸有其各自的合成通路,并与众多基因和酶的参与有关,其发生作用的位点、启动功能的时期以及如何使细胞内的各组分发生变化目前尚无定论[36]。杜若琛[37]研究发现,大豆种子的发育可分为 3 个时期:开花后 10~30 d为前期,该时期为蛋白质合成阶段;30~80 d为中期,该时期蛋白质发生快速积累,并合成贮藏蛋白;80~100 d为后期,蛋白质积累缓慢。其中贮藏蛋白占种子总蛋白含量的80%左右[38],可分为白蛋白、球蛋白、谷蛋白和醇溶蛋白4类。在种子的胚发育过程中,醇溶蛋白在粗面内质网合成,而后形成蛋白质聚集体,直接形成蛋白体并于其中贮存。白蛋白、球蛋白和谷蛋白首先在粗面内质网上形成分子量较大的前体,经过高尔基体的受体分选,进入特定的运输囊泡,经由受依赖型运输或聚集体形式运输至蛋白质贮存液泡中,最后经过液泡加工酶等的剪接转换为成熟型贮藏蛋白质[39]。
在本研究中,冀HJ117与冀豆12的差异表达基因显著富集在蛋白质内质网合成途径中,其差异表达的基因主要为钙联蛋白(CNX)、结合免疫球蛋白(Bip)、内质网膜结合连接酶(RMA1)以及热激蛋白(Hsp20、Hsp40、Hsp70、Hsp90)。该途径中,差异表达的Hsp基因所占比例最高,尤其以Hsp20的差异表达基因最多,共有21个。Hsp是一类从细菌到高等真核生物中普遍存在且高度保守的蛋白,根据分子量的大小可以分为5个家族,即Hsp100、Hsp90、Hsp70、Hsp60和小分子热激蛋白(sHSF),因为sHSF的分子量普遍在20 ku左右,故也称为Hsp20[40]。许多研究表明,热激蛋白在细胞中可以作为“分子伴侣”参与合成中的多肽反应,使其正确折叠;它还能够帮助新生肽穿过细胞膜结构,使蛋白质运转到细胞的不同部位发生作用;在高温等胁迫环境中,热激蛋白可以组织热变性蛋白的聚集,阻止蛋白的不可逆变性或有利于蛋白质变性后的复性[41]。
钙联蛋白是内质网中的一种磷酸化的钙结合蛋白,在哺乳细胞中它会与单葡糖基化修饰的糖蛋白相连接,帮助其成熟[42]。对于那些需要更多加工的非天然蛋白质,将会被UDP葡萄糖糖蛋白葡萄糖基转移酶(Glycoprotein glucosyltransferase,GT)识别,并使其聚糖分子A分支重新葡萄糖基化,这样就可以再次与钙联接蛋白或钙网织蛋白相连,进行重新折叠,这就是钙联接蛋白-钙网织蛋白循环(Calnexin-calreticulin cycle)[43]。Bip属于Hsp70家族蛋白在内质网体中的成员,参与进入内质网体的分泌型蛋白质和膜蛋白的折叠、贮存和转运过程[44]。
本研究中对差异表达基因进行GO功能的显著性富集分析,显示差异表达基因在氧化还原酶类条目中显著富集。而有研究表明,当蛋白质经过内质网的时候,会有一套“质控”系统将折叠正确的蛋白质释放,对于发生错误的蛋白将通过内质网相关的降解途径(ER-associated degradation,ERAD)运出内质网并降解[45]。在该降解途径中,Hsp70伴侣蛋白会与非天然蛋白结合,并使其与内质网膜结合酶Doa10、RMA1、HRD相结合,防止其转运至高尔基体。Hsp70分子蛋白还可以与氧化还原酶类蛋白一起帮助构象不正确的蛋白重新折叠,改变其构象[46]。携带有膜锚定结构的RMA1存在于内质网中,该蛋白是一种在拟南芥到人类中都广泛存在、非常保守的泛素连接酶[32]。RMA1蛋白能与UBE2J1蛋白相互作用,如果过表达RMA1蛋白会降低细胞内囊性纤维化病跨膜传导调节蛋白(Cystic fibrosis transmembrane conductance regulator,CFTR)的水平[47]。RMA1蛋白最主要的作用是在CFTR蛋白翻译过程中或翻译刚刚完成之后检测CFTR蛋白N末端结构域的折叠情况。
本研究中还筛选到一些与蛋白质合成相关的转录因子,主要包括5个家族的转录因子,分别是MYB、AP2、Hsf、B3、以及Trihelix家族的转录因子。前人研究表明,热休克转录因子是一组结构及功能具有广泛同源性,普遍存在于真核生物细胞中的蛋白质,其结构高度保守[48]。植物中Hsfs分为A、 B、 C 3个家族,又分为16个亚族。前人研究表明,植物中存在的Hsfs,能够与Hsps的启动子区域的热机元件(HSEs)结合,从而启动热激反应,激活下游基因的表达,对提高植物的耐热性有重要的调控作用。大豆中有38个Hsfs基因,划分到3个家族,12个亚族中,其中GmHsf-34基因在拟南芥中的超量表达,提高了植株对干旱和热胁迫的耐受性[49]。Chauhan等[50]从小麦种子中克隆了TaHsfA2d,转TaHsfA2d拟南芥植株不仅表现耐高温,还表现出耐盐和抗旱性,同时转基因植株还表现出较高的产量和生物量积累。在黄淮海地区,大豆的生长季在6-10月之间,而大豆一般在7月下旬进入开花期,因此,大豆的开花期至鼓粒期是黄淮海地区最热的时期。本研究中检测到一个Hsf转录因子的高表达,推测该基因与提高大豆的耐热性有关,对蛋白质合成的影响还需进一步的研究。除此之外,在冀HJ117与冀豆12的差异表达基因中还检测到MYB和B3类转录因子,Ezcurra[18]和Reidt[15]等研究表明,该类转录因子对蛋白质的合成具有调控影响。因此,推测本研究筛选到的转录因子与蛋白质合成密切相关,但这些转录因子具体的作用机制还需深入的研究。
综合上述研究,本研究以遗传背景接近的冀HJ117与冀豆12为材料,对开花后14 d的籽粒进行了转录组测序,筛选到与蛋白质合成相关的基因。差异表达基因富集的GO分子功能条目与蛋白折叠有关,并且通过Pathway显著性富集分析发现差异表达基因富集在蛋白质内质网合成途径中,该途径中的钙联蛋白、结合免疫球蛋白、热激蛋白以及内质网膜结合连接酶均在蛋白质合成通路中起关键作用,因此,该途径是冀HJ117与冀豆12蛋白质含量产生差异的重要通路。
RNA-Seq分析获得了大豆中蛋白质合成相关的基因的基本信息及其可能的生物学功能。蛋白质内质网合成途径可能是冀豆12与冀HJ117蛋白含量产生差异的重要通路,因此,在该途径中富集的差异表达基因以及筛选到的差异表达的转录因子很可能是与蛋白合成密切相关的基因。
猜你喜欢
今日农业(2022年16期)2022-11-09
中国化肥信息(2022年5期)2022-08-30
临床肝胆病杂志(2021年7期)2021-12-26
今日农业(2021年20期)2021-11-26
今日农业(2021年14期)2021-10-14
科学导报(2021年29期)2021-06-03
现代临床医学(2021年1期)2021-01-26
中国生殖健康(2020年4期)2021-01-18
中国现代中药(2019年5期)2019-07-03
科海故事博览·下旬刊(2019年6期)2019-04-16
