
面向动态数据发布的差分隐私保护研究综述
2019-02-19 13:46屈晶晶夏红科
北京信息科技大学学报(自然科学版) 2019年6期
屈晶晶,蔡 英,夏红科
(北京信息科技大学 计算机学院,北京 100101)
0 引言
伴随大数据和互联网信息技术的快速发展,各类数据的采集、存储、发布和分析变得方便快捷。在某些实际应用中,数据会持续更新并动态发布。例如,疾病控制中心根据流感疫情,动态发布病毒携带者数据;在线购物平台可以随时从成千上万的用户中收集购物数据,并定期在网站上发布统计结果。相关研究机构会利用这些数据资源,进行数据挖掘分析,从而作出更好的决策并提供高质量服务。但是这些数据可能包含有关个人的敏感信息,不断更新并发布数据可能会导致隐私信息泄露。如何保证所发布的数据既是可用的,又不会泄露数据中所包含的隐私信息,是数据发布隐私保护研究的重点。
基于k-匿名[1-2]及其扩展的一系列方法(如,l-多样性[3]、t-临近[4]、(α,k)-匿名[5])是实现数据发布隐私保护的主要方法,一般通过泛化、抑制、微聚集等方式实现对敏感信息的保护。这些方法可以针对数据细节进行保护,但均需要进行特殊攻击假设,在现实应用中存在局限性。针对上述隐私保护方法,还出现了许多攻击变体,如组合攻击[6]、前景知识攻击[7]等,对上述方法的有效性提出了挑战。
目前,以提供严格隐私证明的差分隐私模型得到学界广泛认可。2006年, Dwork提出了能够抵抗任意背景知识攻击的差分隐私保护模型[8]。相比于基于k-匿名及其改进的一系列隐私保护方法,差分隐私模型不需要特殊攻击假设,不在乎攻击者背景知识,即使攻击者知道除某一记录之外的所有记录,仍能保护用户隐私信息。Dwork提出该模型后,人们基于该模型开展了很多研究工作,内容涉及直方图发布、空间划分发布、采样-过滤发布、智能数据分析等。
到目前为止,大多数关于差分隐私数据发布的文献都集中在静态数据的一次性发布。本文则主要针对动态数据发布,对差分隐私保护算法进行分类研究。一方面,对差分隐私保护的原理和性质进行介绍;另一方面,重点研究动态数据发布的差分隐私保护技术,并从关键技术、效果等方面对实时数据流发布和连续数据发布进行综合对比分析。
1 差分隐私保护
1.1 差分隐私定义
在差分隐私保护技术中,一般通过向查询结果中添加定量噪声实现对数据的扰动,以确保在任一数据集中插入、更改、删除记录的操作不会影响查询结果,进而达到隐私保护的目的。
定义1(ε-差分隐私) 设有随机算法K,以及任何相邻数据集D1和D2。若算法K满足ε-差分隐私,则有
Pr[K(D1)∈S]≤exp(ε)Pr[K(D2)∈S]
(1)
式中:参数ε为隐私预算;Pr为隐私泄露风险。算法K的隐私保护等级可以通过ε推导出来。ε越小,则表明隐私保护程度越高;反之,ε越大,则表明隐私保护程度越低。在实际中,ε通常设定小于1,例如 0.1或ln 2。
1.2 噪音机制
实际中,常用的噪音机制分为Laplace机制与指数机制。噪声量会影响数据安全性和可用性,与全局敏感度[10]密切相关。
定义2(全局敏感度) 存在任意一个函数f:D→Rd,f的全局敏感度定义为
Δf=maxD1,D2‖f(D1)-f(D2)‖
(2)
式中:D1和D2为任何相邻的数据集;f为在数据集D上执行的查询函数。全局敏感度Δf由查询函数f决定。
定理1(Laplace机制) 对于任意数据集D和函数f:D→Rd,若算法K的输出结果满足
(3)
则算法K满足ε-差分隐私保护。
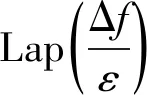
定理2(指数机制) 给定一个可用性函数u:(D,r)→R,若算法K满足
(4)
则K满足ε-差分隐私。
其中,Δu为u(D,r)的全局敏感度。指数机制的关键技术是如何设计可用性函数u(D,r) (r为从输出域中所选择的输出项),u(D,r)用来评估输出值r,u(D,r)越大,r被输出的概率越大。指数机制主要处理非数值型数据。
1.3 差分隐私的组合性质
差分隐私保护技术存在2个重要的组合性质:序列组合性和并行组合性。
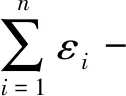
性质2(并行组合性) 给定数据库D,存在n个随机算法K,设Ki(1≤i≤n)满足εi-差分隐私,则Ki在D上的并行操作满足max (εi)-差分隐私。
2 动态数据发布的差分隐私保护算法
动态数据发布的表现形式通常包括2种:一种是实时数据流发布;另一种是连续数据发布,即数据以更新的形式出现,例如事务数据周期性地添加、修改及删除。
2.1 实时数据流发布
数据流是按照事先规定好的顺序进行一次读取的数据序列[9]。数据流具有快速、范围广、持续的特点,而且每次只能读取一次,随着时间推移不断更新。
作为一种实时动态数据类型,数据流存在于多种应用领域之中,例如疾病预防控制、在线商品销售等。数据流本身的动态性、连续性、不适合二次存取等特点给实时分析带来很多挑战。目前,直方图、采样是发布和分析数据流的常用技术。
2.1.1 基于直方图的数据流发布
文献[10-11]提出了针对一维动态数据流的直方图发布方法,将问题称为“持续观察下的差分隐私”,并提出了泛隐私概念。该方法在二进制只取0和1的背景下,对数据流相关统计信息发布进行研究。文献[12]设计了差分隐私连续计数器,假设输入二进制数据流σ∈{0,1}N,在固定时间节点,差分隐私保护机制输出截至目前统计的1的数量的近似计数,可在分布式环境下有效实现连续统计发布。
文献[13]设计了一种差分隐私连续统计发布算法PTDSS-SW(private two-dimensional data stream statistic based on sliding window),该算法使用滑动窗口机制,可实现面向任意长度二维数据流,但该方法相对误差波动范围较大。文献[14]提出W-事件差分隐私模型来合并数据流中事件级和用户级间的差距,在实用程序和隐私之间取得良好平衡,从而保护在时间戳的任何窗口内发生的任何事件序列。张啸剑[15]提出一种利用增强动态规划技术实现的直方图发布算法SHP(streaming histogram publication),可以节省整体隐私预算。
文献[16]设计了一个实时数据发布框架RescueDP(real-time spatio-temporal crowd-sourced data publishing with differential privacy),适用于社交网络无限数据流的W-事件隐私保护。RescueDP的设计包括自适应采样,自适应预算分配,动态分组,扰动和过滤,并将数据动态考虑在内,能应对数据稀疏性带来的挑战。同时提出了一种增强的RescueDP方案,利用神经网络准确预测每个区域的统计数据,并提出了一种新的基于采样机制和动态规划的分组机制,以寻找最优的分组策略,从而提高发布数据的准确性。
文献[17]提出了一种针对实时数据流的数据发布算法DDHP(histogram publication of dynamic data),该算法采用滑动窗口对数据流建模,采用基于距离的相似度测量方法,将预置阈值T与距离d进行比较,决定是否向统计数据中添加Laplace噪声。这种选择性加噪机制既能保证数据安全性,还能提高数据可用性。
文献[18]提出了一种采用分形维数挖掘技术的差分隐私发布方法,设计了一个由数据分析模块和差分隐私模块组成的DP-FC(fractal-based c clustering of data streaming histogram publishing method with differential privacy)框架:数据分析模块用于通过基于分形的聚类算法分析多属性动态数据流;差分隐私模块选用Laplace机制,将Laplace噪音添加到统计结果并发布直方图,实现差分隐私保护。
本文分析了以上基于直方图的数据流发布算法,如表1所示。大部分方法采用滑动窗口模型对数据流进行建模,然后采用不同方法分配隐私预算,但均会产生采样误差和扰动误差过大等问题。因此在以均衡数据安全性和可用性为宗旨的前提下,如何设计合理的隐私预算分配策略,如何设置合适的ε值,来降低查询敏感度、减小误差并最大化数据效用将会是研究的重点。
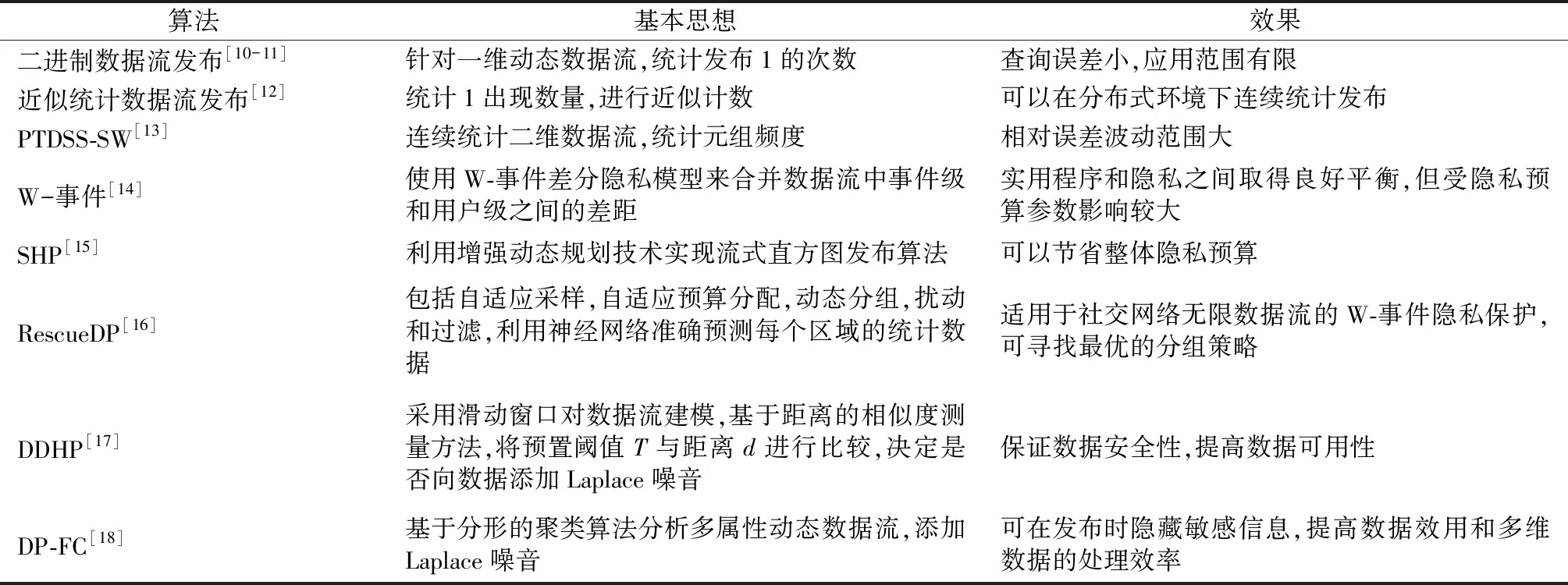
表1 基于直方图的数据流发布算法对比
2.1.2 基于采样的数据流发布
文献[19]重点讨论了在数据流滑动窗口上回答组合查询的问题。采用聚类滑动窗口技术,选择性地采样具有代表性滑动窗口查询的子集,通过以满足差分隐私的方式添加Laplace噪声来回答代表性查询,该方式能提高用户查询效率。文献[20]提出了一种基于过滤和自适应采样在差分隐私下发布实时聚合统计的新颖框架FAST(a real-time framework with filtering and adaptive sampling for differentially private time-series monitoring),它采用采样和过滤的方法,保护用户在整个时间序列中的隐私。但其不能应用于无限时间戳,因为FAST必须预先分配发布的最长时间,并且其采样机制只能在每个时间戳具有等效预算的条件下才能使用。
文献[21]将采样和随机响应这两种技术结合,直接计算采样数据集的子集,然后添加满足差分隐私保护的显式噪声,从而实现差分隐私保护。它实现了更强大的隐私保障,并且还提高了流分析的性能。
文献[22] 提出了基于距离的自适应采样方法,解决了实时发布差分隐私动态数据集出现的累计误差大等问题。其中,DSFT(distance-based sampling with fixed threshold)方法使用固定距离阈值,仅当距离大于预定阈值时才发布差分隐私直方图;DSAT(distance based sampling with adaptive threshold)方法使用由反馈控制机制自适应调整的动态阈值来捕获动态数据。
上述方法的对比分析如表2所示。上述方法大部分使用自适应采样技术发布动态数据流,可提高用户查询效率和单个时间戳下数据发布的准确性,但是如何设计高效的数据流采样模型,如何处理更多的统计查询,还需要进一步探索。

表2 基于采样的数据流发布算法对比
2.2 连续数据发布
在现实生活中,除了发布动态实时数据流,一些研究机构通常会动态发布数据集来提供最新数据。文献[23]将此类动态数据发布分为3类:
1)多种数据发布。在这类发布中,同一数据会多次发布,每次发布给不同的数据接收者。例如,医院将数据表Ta(年龄,性别,工作,疾病)发布给需要对疾病特征进行分类的制药公司或将数据表Tb(年龄,性别,工作)中的个人特征数据用于统计模型。在这些版本中,所有数据都会发布一次。
2)顺序数据发布。在顺序发布中,数据发布者已经发布了数据表T1,T2,…,Tn-1,如果想要发布下一个数据表Tn,则Tn是相同基础表的投影,并且每个数据表都是单独发布而不是连续发布。
3)连续数据发布。在该版本中,数据发布者已经发布了数据表T1,T2,…,Tn-1,并且现在想要发布下一个版本Tn,其中Tn是插入、更新或删除数据的Tn-1的最新版本。
第一、二类数据虽经多次发布,但主要针对静态数据集;而第三类则是进行数据更新(插入、删除或更新)后,发布动态数据集。因此,动态数据发布中另一种数据体现是连续数据发布中的增量更新数据发布。它主要通过在原始数据集中添加、修改或者删除数据,然后不定期发布更新后的数据集。这类数据不同于数据流,不具备实时性。此类数据主要为集值型数据,包括事务数据、搜索日志以及序列数据等。文献[24-26]提出了一种可以实现静态集值型数据的隐私保护,但需要注意的是在增量更新环境下不能直接使用这些方法。这些方法虽然在某一时刻发布的数据满足差分隐私,但随着更新次数的增加,每次更新发布所需要的噪音量也越来越大,累积噪声不断增加,最终导致所发布数据失去可用性。一旦隐私预算被消耗殆尽,差分隐私保护将不再起作用。
解决连续数据发布问题的一种朴素解决方案[27]是直接在前一次发布的统计数据上加上此次新增的数据,然后再添加噪声使其满足差分隐私。但该方案中每一次发布数据的噪声的均方误差会线性累加,最终发布的数据会失去可用性。文献[28]针对该问题提出了一种基于二叉树的发布方法。该方法通过构建一棵叶节点数量为2m的完全二叉树,然后利用模拟二叉树统计发布的过程进行连续数据发布,通过调整二叉树各层节点的隐私预算分配来达到无限发布的效果;然而,此方法仅仅引入二叉树模拟发布,未对精确性提出有效优化。
文献[29]将矩阵机制引入差分隐私连续数据发布问题中,通过树状数组构造策略矩阵,利用对角矩阵提高发布数据的精确性。提出了快速对角阵优化算法FDA(fast diagonal matrix optimization algorithm),FDA算法极大地改善了现有的连续数据发布方法的精确性,并且具有发布大规模数据的能力。
文献[30]提出一种基于Diffpart的集值型数据发布算法,可以有效解决动态数据发布中噪音量大、运行效率低、数据可用性差的问题。文献[31]提出一种采用分类树与自顶向下划分方式相结合的隐私保护算法,主要针对动态集值型数据,可以满足差分隐私的要求。
文献[32]认为目前的连续数据发布方法忽略了各事件之间的关系(事件间关系被定义为耦合信息),耦合信息可能揭露比预期更多的隐私信息。因此提出了一种差分隐私保护机制,明确识别连续发布的数据集中的耦合信息,并开发了一种基于迭代的连续数据发布算法CCR(coupled continual release)。他们在理论上也证明了该方法的隐私保护性,并且经实验证明CCR优于传统的差异隐私机制。
文献[33]提出了一种非平稳数据流的MiDiPSA(microaggregation-based differential private stream anonymization)算法,该算法同时满足k-匿名,递归(c,l)-多样性的约束,以及差分隐私保护,能最大限度地减少信息损失。该算法通过4个主要步骤实现:传入元组的增量聚类;根据预定义的聚合函数对每个集群中的元组进行增量聚合;使用非参数统计检验来监测流以检测可能的概念漂移;发布增量匿名元组。
本文对连续数据发布中的差分隐私保护技术进行了归纳总结,如表3所示。总体来看,大多数方法是采用分类树划分索引进行隐私数据发布,没有顾及怎样均衡噪声误差与假设误差,造成数据可用性较低。因此,如何合理分配隐私预算并有效控制误差累积是研究的重点。此外,现实中很多的数据之间是相互关联的,因此如何拓展差分隐私框架,保护具有关联性的数据也将会是未来的研究方向。

表3 连续数据发布算法对比
3 其他应用
目前差分隐私保护还应用在位置服务、推荐系统、社交网络等的数据发布方面。
1)位置服务下的差分隐私保护。位置定位服务技术是指服务提供商通过无线网络或外部定位方式确定用户位置,根据用户提出的服务请求为其提供相关的服务信息。位置数据主要来源于车联网、移动社交网络、新浪微博等网络平台。但仅考虑位置数据的隐私保护而忽略非位置数据的隐私保护,将无法估计数据动态发布带来的潜在安全风险。因此如何根据动态环境下数据的变化,提供安全的位置服务也将是研究的重点方向。
2)推荐系统下的差分隐私保护。推荐系统是建立在数据挖掘基础上,根据用户的购物行为、兴趣偏好及历史搜索记录为用户过滤冗余信息,精准地向用户提供有效信息。但同时也需要采集用户的个人信息和操作数据等,存在隐私泄露的安全隐患。目前差分隐私在推荐系统中已得到广泛应用,但现有推荐算法通常采取降低推荐精准度来提高隐私保护强度,从而导致算法推荐质量下降。因此在差分隐私保护和推荐质量之间寻找一个平衡是值得深入研究的课题。
3)社交网络中的差分隐私保护。在互联网中,社交网络强调以人与人关系为核心,因此被描述为图结构。社交网络中许多数据集的记录之间是存在相互关联的,目前的差分隐私对这类数据的保护程度很低,因此拓展差分隐私保护框架,保护好关联性数据间的敏感信息也是研究的一个重要方向。
4 结束语
本文主要针对动态数据发布中的差分隐私保护算法,从关键技术、效果等方面对实时数据流发布和连续数据发布进行综合对比分析,在此基础上提出了未来的研究方向;此外,还介绍了差分隐私技术在位置服务、推荐系统、社交网络等方面的应用。目前,差分隐私技术大多处于研究阶段,实际应用较少,因此,如何拓展差分隐私框架,将其应用在实际中将会是一个很大的挑战。
猜你喜欢
航空学报(2022年7期)2022-09-05
上海师范大学学报·自然科学版(2022年3期)2022-07-11
现代临床医学(2021年2期)2021-03-29
扬州大学学报(自然科学版)(2021年6期)2021-02-14
汽车维修与保养(2020年10期)2021-01-22
计算机应用(2020年11期)2020-11-30
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2020年5期)2020-05-22
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
计算机应用(2016年10期)2017-05-12
