
基于LSTM-CNNS情感增强模型的微博情感分类方法
2019-02-19 11:49段宇翔张仰森张益兴段瑞雪
北京信息科技大学学报(自然科学版) 2019年6期
段宇翔,张仰森,2,张益兴,段瑞雪,2
(1. 北京信息科技大学 智能信息处理研究所,北京 100101; 2. 国家经济安全预警工程北京实验室,北京 100044)
0 引言
随着计算机与互联网技术的蓬勃发展,信息出现了井喷式的增长,越来越多的人将互联网视为获取信息的最佳平台。其中,新浪微博作为一个新兴的信息传播平台和社交网络平台,因为其特有的即时交互和自由开放特性,在中国引领了新媒体的浪潮。中国互联网络信息中心发布的《中国互联网发展状况统计报告》显示,截止到2018年6月,中国有3.37亿人使用微博,较2017年增加了2140万人,使用微博的用户总量占全国总网民数的42.1%。数以亿计的用户在微博平台上使用文字和其他各种方式发表自己对热点事件的关注和看法。通过对海量用户微博中蕴含的情感信息进行分析,可以得到微博用户对相关社会热点事件的态度倾向,有利于政府机构对事态变化做出精确的判断,并采取相应的措施引导民众情绪的正向发展。学术界出现了大量关于微博文本情感分析的相关研究,微博情感分析也逐渐成为自然语言处理和文本挖掘的重要研究方向之一。
1 国内外研究现状
目前使用率较高的情感分析方法主要有基于机器学习和基于深度学习两种。
1.1 基于机器学习的情感分析方法
基于机器学习的情感分析方法就是使用机器学习领域的有关算法分析文本特征,建立情感分析模型对未标注文本的情感进行分析。
Pang等[1]首先在情感分类任务中使用有监督学习算法;Hruschka等[2]在Pang研究的基础上提高了在Twitter情感分析任务中的准确率;Prusa等[3]验证了集成算法bagging与boosting在Twitter情感分析任务上的优势。针对中文领域,张珊等[4]构建了结合中文微博情感库、信息熵和贝叶斯分类理论的情感分类器;李婷婷等[5]结合多种文本特征,设计出一种融合支持向量机模型和条件随机场模型的情感分类方法;樊振等[6]通过用户对评论的情感倾向评分,设计了一种基于评分的弱标注信息方法,与传统的情感词典方法结合后进行相关评论数据的情感分类;朱军等[7]使用Word2Vec提取目标语句的情感特征并使用SVM方法进行分类,在此基础上加入构建好的情感词典进行集成学习并最终用于情感分类;姜杰等[8]结合情感词典、汉语言结构和机器学习算法,在NLPCC标准情感分类测评数据语料中取得了良好的分类效果。
经过大量的研究发现,使用机器学习算法进行情感分析的效果通常都比较好,但是该方法的缺点在于需要研究者能够准确地对文本特征和分类器进行选择,这是基于机器学习方法研究的重点和难点。
1.2 基于深度学习的情感分析方法
深度学习方法通过对多隐藏层网络结构的训练,可以自动学习数据内部的结构关系,并广泛地应用于情感分析领域。
Socher等[9]提出一种基于张量递归神经网络的方法,通过引入张量的概念减少模型参数,极大地简化了模型规模;Dong等[10]面向Twitter数据集,提出了基于目标的自适应递归神经网络方法。国内将深度学习应用于情感分析的研究刚刚起步不久,朱少杰[11]将Socher利用自编码模型进行情感分析的研究应用于中文微博领域,取得了较好的实验结果;Cao等[12]结合卷积神经网络和支持向量机模型,提升了对非线性函数的描述能力,进而提升了微博文本的分类效果;梁军等[13]在递归神经网络的基础上,通过引入情感极性转移模型增强了对情感极性关联关系的捕捉,进一步提升了文本的情感强度以便于进行情感分析;蔡林森等[14]在卷积神经网络的基础上,结合词语多样化抽象特征,使网络模型可以充分提取文本中的情感信息;邓昌明等[15]以新浪微博的文本数据为研究对象,设计了一个应用于卷积神经网络的编码方法,并融合遗传算法对微博情感进行分析;孟威等[16]设计了一种使用CRT机制融合CNN(convolutional neural network,卷积神经网络)和LSTM(long short-term memory,长短期记忆网络)的情感分析方法,基于3个公开数据集的实验证明,该混合模型在特定领域的情感分析准确率较高;李洋等[17]一方面使用CNN获取文本的局部特征,另一方面使用前后向长短期记忆网络(bi-directional long short-term memory, BiLSTM)获取文本的全局特征,将上述两种特征融合后输入RNN网络进行文本情感分类。
情感分析和观点挖掘是一项实用价值很高的研究工作,其研究趋势主要表现为情感分析对象的不断细化、情感分析层次的不断深入、情感分析内容的不断丰富。采用的研究技术也逐步从传统机器学习向各种深度学习模型转变。
本文在参考了相关研究成果后,构建深度学习模型以实现情感分类。一方面将自注意力机制引入LSTM进行情感分类,另一方面提出情感增强模型应用于情感分类。
2 LSTM+Self-Attention分类模型
2.1 LSTM模型
循环神经网络(recurrent neural network,RNN)虽然解决了序列前后依赖的问题,但是当序列较长时,间隔较远的状态对当前状态的影响会变得微乎其微,这会导致RNN对历史状态学习的能力变差。LSTM的出现就是为了解决RNN的长期依赖问题。LSTM通过“门”对历史信息进行选择性的“遗忘”、“保存”和“输出”,最终实现对历史信息的保护。在文本情感分类的研究中,经常需要对长文本进行分析,所以使用LSTM可以增强对情感信息的保护。LSTM网络节点展开图如图1所示。
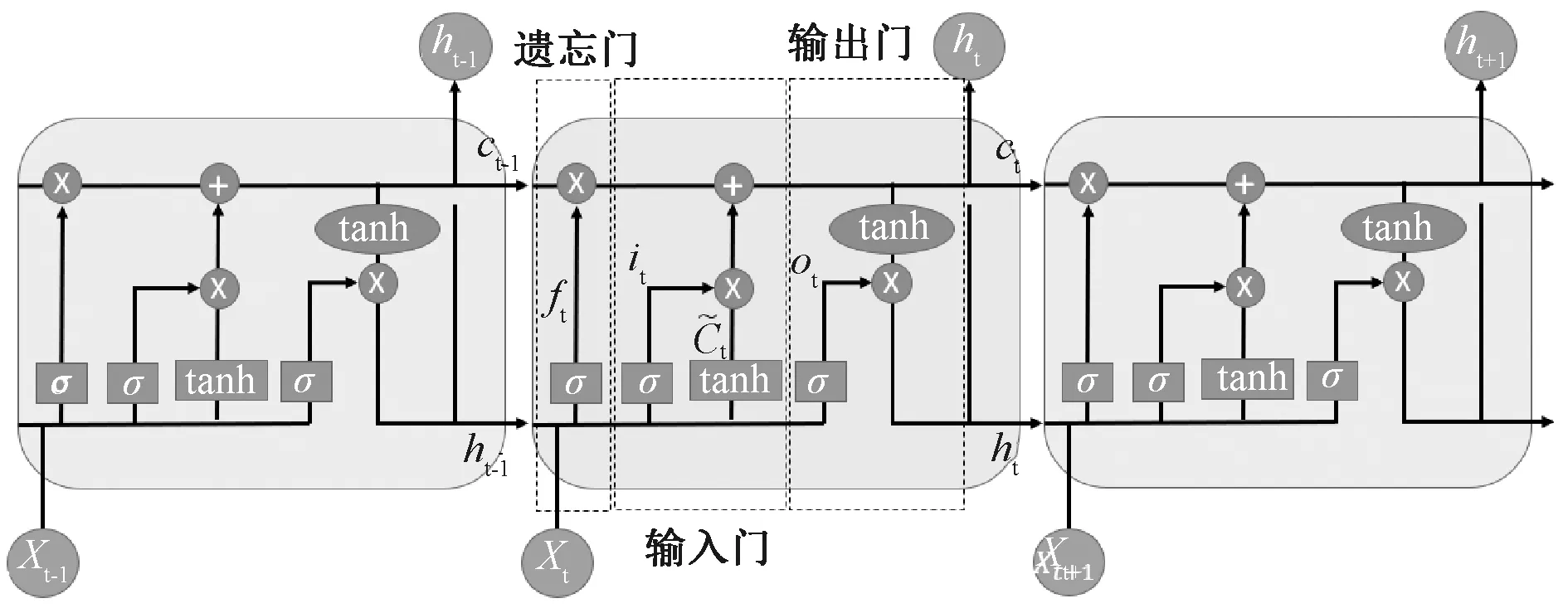
图1 LSTM网络节点展开图
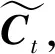
2.2 自注意力机制
LSTM在文本分类领域有广泛的应用,但LSTM的编解码器结构会将输入序列编码为固定长度的内部表征,这会严重制约输入序列的长度,并导致模型对长文本序列的分类性能变差。为了克服LSTM的缺点,本文引入注意力机制模型。考虑到深度学习每一层计算的时间复杂度以及对长距离的依赖关系,我们采用Google机器翻译团队于2017年6月在文献[18]中提出的自注意力机制Self-Attention,其有以下优点:1)能够学习到序列内部的联系;2)降低每层的计算复杂度;3)有效减少并行计算的最小单元数目,进而降低训练成本。自注意力机制结构如图2所示,x1,x2,…,xi,xj,…,xn为输入数据,d为输入数据的维度,z1,z2,…,zn是相对应的权重,y代表对应的查询,相似度的计算采用Additive注意力计算方法,然后将得到的相似值通过Softmax函数转化为0到1之间的权重值,最后的输出为输入数据和对应权重的加权和。
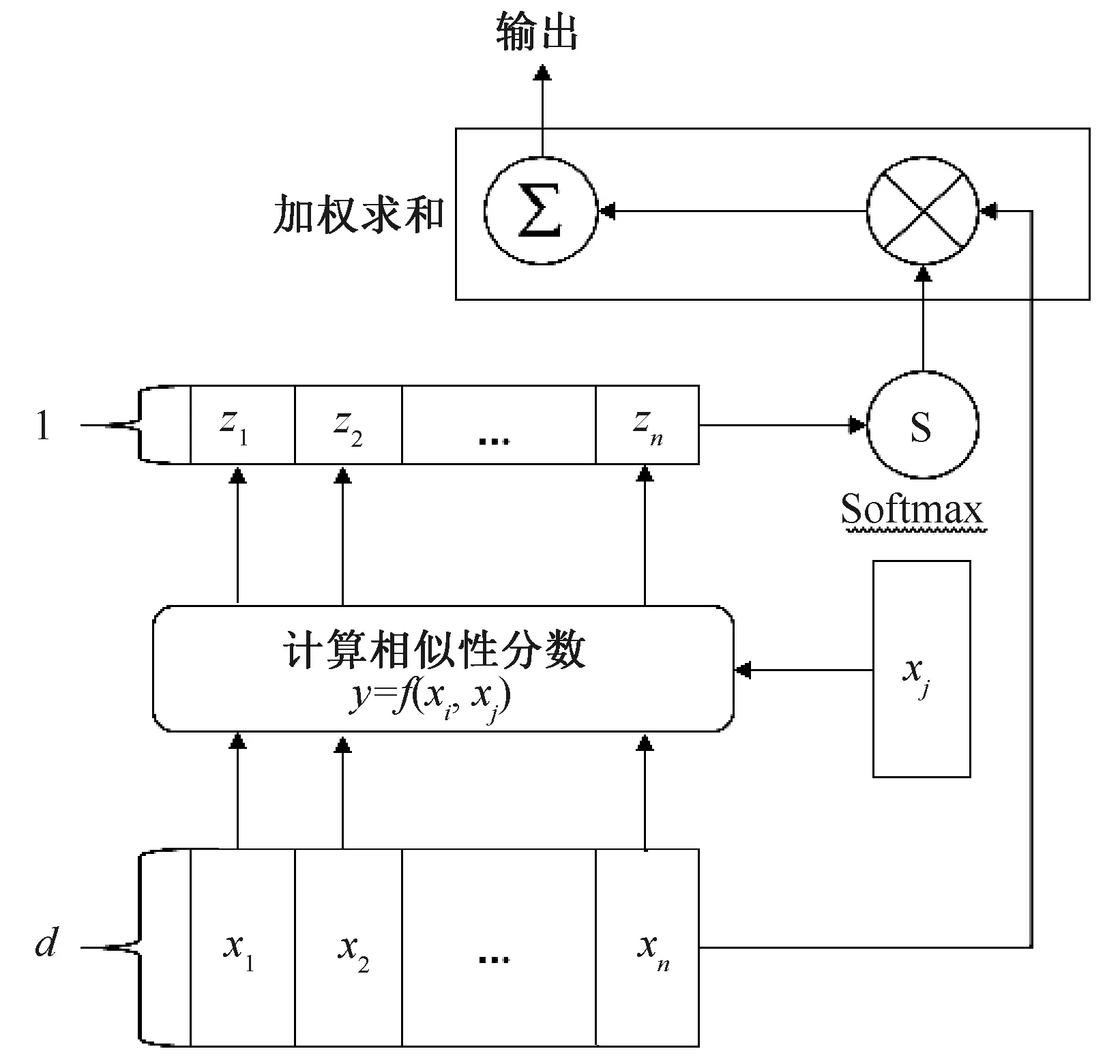
图2 自注意力机制结构
2.3 LSTM+ Self-Attention情感分类框架
本文结合Word2Vec、LSTM、自注意力机制,构建了一套中文微博情感分类框架,其结构如图3所示,其中x1,x2,…,xn表示分词后的词语,e1,e2,…,en表示经过Word2Vec训练后的词向量,A表示LSTM的训练过程,α1,α2,…,αn表示各部分在自注意力中的贡献程度,y表示最终的输出。具体实现步骤如下:
1)利用Word2Vec模型进行词嵌入,将分词完成后的微博数据转化为词向量;2)将词嵌入后的词向量与LSTM 进行连接;3)在LSTM层的输出后加入位置编码并融入自注意力机制,构建基于LSTM的自注意力机制情感分类模型;4)在加入自注意力之后,连接基础的全连接前馈神经网络;5)在全连接层的输出后连接Sigmoid层来实现概率输出。因为本文是面向中文微博的二分类,所以输出情感正负极性的概率即可。
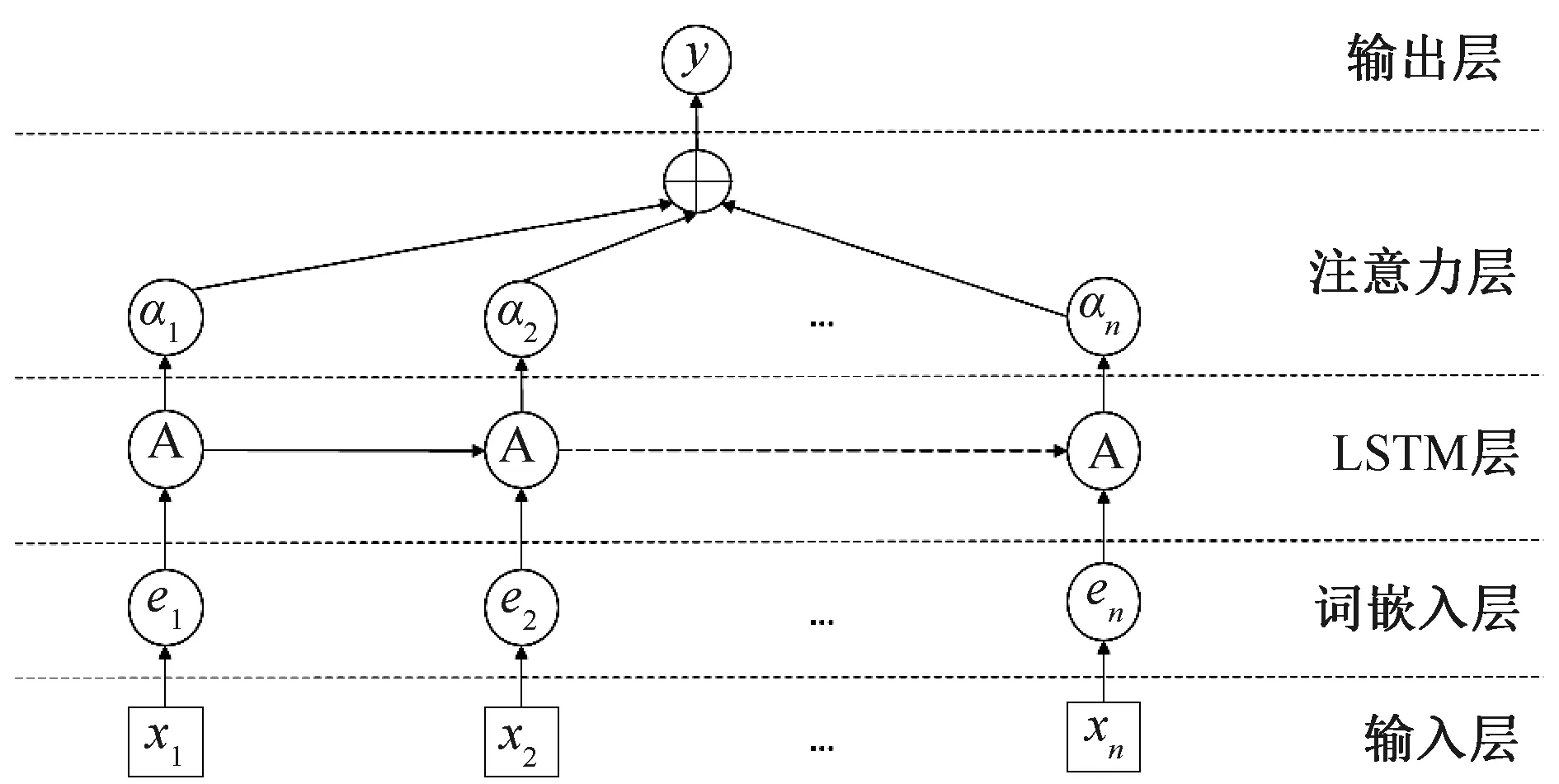
图3 LSTM+ Self-Attention情感分类框架
3 CNNS和LSTM-CNNS模型
3.1 CNNS模型
在微博短文本分类任务中,因为微博有长度短、结构紧凑、表意清晰的特点,所以可以利用CNN进行情感分类。其训练过程可以概括为以下4步:
1)词向量映射层。词向量建立在大规模语料库的基础上,是使用Word2Vec神经网络训练形成的词汇低维度的表示方法,能够对语义特征进行清晰的表达。如果一条句子有n个词,每个词的词向量维度是k,那么CNN网络的输入就是一个n×k的二维矩阵。
2)卷积层。通过卷积层中不同的核函数进行计算,可以得到多个特征图,进而可以挖掘文本中的不同特征。卷积层基本单位为N-gram,设窗口大小为d,则连续d个词的词向量可以构成N-gram向量ci,如式(1)所示。
ci=vi⊕vi+1⊕…⊕vi+d-1
(1)
式中⊕为连接操作,用于将词向量首尾连接。如果句子长度为N,则输入矩阵可以表示为
C=[c1,c2,…,cj,…,cN-d+1]
(2)
3)池化层。池化层采用Max Pooling over time操作,该池化方法对于过滤器抽取到的多个特征值并不是全部保留,而是将得分最高的特征值作为Pooling层的保留值,其他低分特征值全部舍弃。也就是说,Max Pooling over time池化方法只保留最突出的特征,同时删除其他全部特征。
4)全连接和Softmax层。该层的作用是进行相关分类操作,输出文本的情感正负极性。
在基于CNN的情感分类实验中,我们首先根据大连理工大学整理的《情感本体库》[19]和知网的《HowNet》,构建了一个包含27 467个情感词语的情感库。在对测评数据进行分词后,将其与构建好的情感词库进行匹配,如果测评数据中的词出现在情感库中,则将该词加入到该条数据的末尾,达到对该条数据的情感极性的加强,并把该模型称为CNN情感加强模型,简写为CNNS,其模型结构如图4所示。
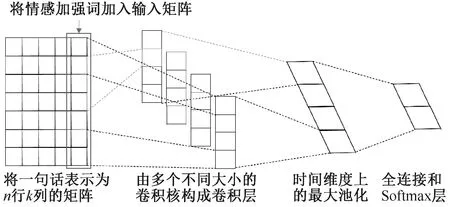
图4 CNNS模型
3.2 LSTM-CNNS的情感分类框架
LSTM-CNNS情感分类框架由长短记忆网络(LSTM)和情感增强的卷积神经网络(CNNS)组合而成。该框架第一层是词嵌入层,该层将分词后的数据变为词向量矩阵,矩阵的列为词向量的维度,矩阵的行为序列长度。该框架第二层是LSTM层,用于对语义特征进行提取,并将输出结果输入下一层。与LSTM层平行的是情感增强型卷积神经网络层,用于对文本特征的进一步提取。利用TensorFlow深度学习框架中的concat方法将CNNS的输出特征和LSTM的输出特征进行融合后,在最大池化层进行池化,对关键信息进行获取,对不重要的信息做出舍弃,并得到特征向量,对结果进行保存后输入到Softmax分类器并得到分类结果。其框架如图5所示。
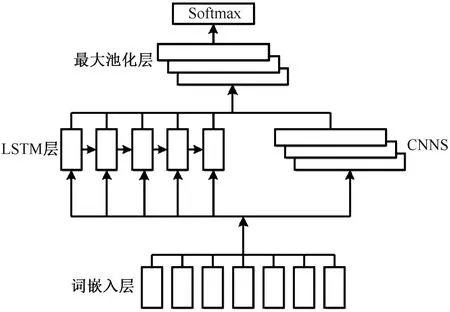
图5 LSTM-CNNS情感分类框架
4 实验与分析
4.1 数据集
本实验采用的数据来自于NLPCC 2013和NLPCC 2014的情感分析任务的测评数据。该测评数据来源于新浪微博,分为测试集和训练集两部分,每一条微博都标有一个主要情感标签和多个次要情感标签,同时微博下的多个分句也有一个主要情感标签和多个次要情感标签,如图6所示。情感标签总共分为8种:happiness、like、anger、sadness、fear、disgust、surprise、none。鉴于每条微博数据下面有多条分句,每条分句又可能有不同的情感标签,实验中只将与微博主要情感标签相同的微博语句作为有效数据进行抽取。区别于测评数据的8种情感标签,本实验仅仅是进行情感极性的正负极性分类,故将主情感标签是happiness、like的微博作为正向情感微博,将主情感标签是anger、sadness、fear、disgust、surprise的微博作为负向情感微博,将主情感标签为none的微博数据剔除。通过对XML的解析,得到正向数据14 085条,负向数据15 316条,正负数据均衡性良好。

图6 测评数据示例
微博数据的处理主要是对异常数据进行过滤,以实现数据的格式化和标准化。根据微博数据的语言特点和结构特点,我们使用以下3个方法进行预处理: 1)将测评数据中的重复字母、重复符号、重复汉字进行剔除; 2)删除测评数据中的非文本信息,如:URL链接、表情符号、特殊字符等; 3)构建一个面向微博的用户词表和停用词表,并基于jieba分词系统进行测评数据的切分和去除停用词。经过处理后的数据如图7所示。

图7 预处理后的测评数据
使用Scrapy框架对微博数据进行爬取,构建了一个包含40 292 997条微博,1 342 646 318个词语的Word2Vec词向量训练语料。使用Skip-gram模型进行词向量训练,模型中的相关参数均采用默认设置。通过对模型的训练,获得了一个包含850 599个词语的词向量空间,且每个词向量的维度是200。
4.2 实验参数设置
如果神经网络想要获得良好的情感分类效果,就需要选择出一组较为合适的超参数。在LSTM+ Self-Attention情感分类模型、CNNS情感分类模型和LSTM-CNNS情感分类模型中,学习率是重要的超参数,学习率过高过低都会影响学习效率,通过对0.1、0.01、0.001三种不同的学习率进行比较,发现当学习率为0.01时效果最好。激活函数的选择影响着深度学习网络的学习难度,以及是否容易出现梯度下降问题。通过对比多个激活函数(relu、tanh、sigmoid等)发现,sigmoid是效果最好的激活函数。将数据集完整遍历一次称为一个Epoch,Epoch过少会导致无法学习到合适的参数,Epoch过多则会导致过拟合现象。经多次对比实验,当Epoch=50时的实验效果最好。优化算法可以在神经网络的构建过程中实现快速收敛和损失函数的最小化,在对比了常用的梯度下降、随机梯度下降、Adam优化算法后发现,Adam的优化效果最为明显。由于LSTM-CNNS模型中包含了CNNS模型,所以CNNS的参数值就不再重复列出了。相关参数值如表1所示。
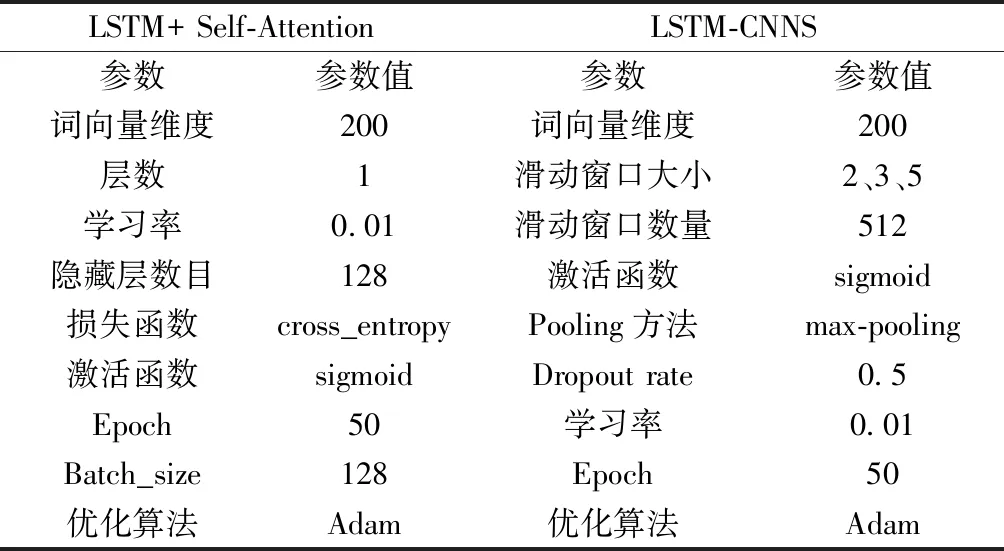
表1 参数值
4.3 实验结果与分析
本实验在NLPCC 2013和NLPCC 2014数据集的基础上,使用相关文献中的情感分类模型,设计了多组对比实验。将正确率作为模型好坏的评价指标,实验结果如图8所示。
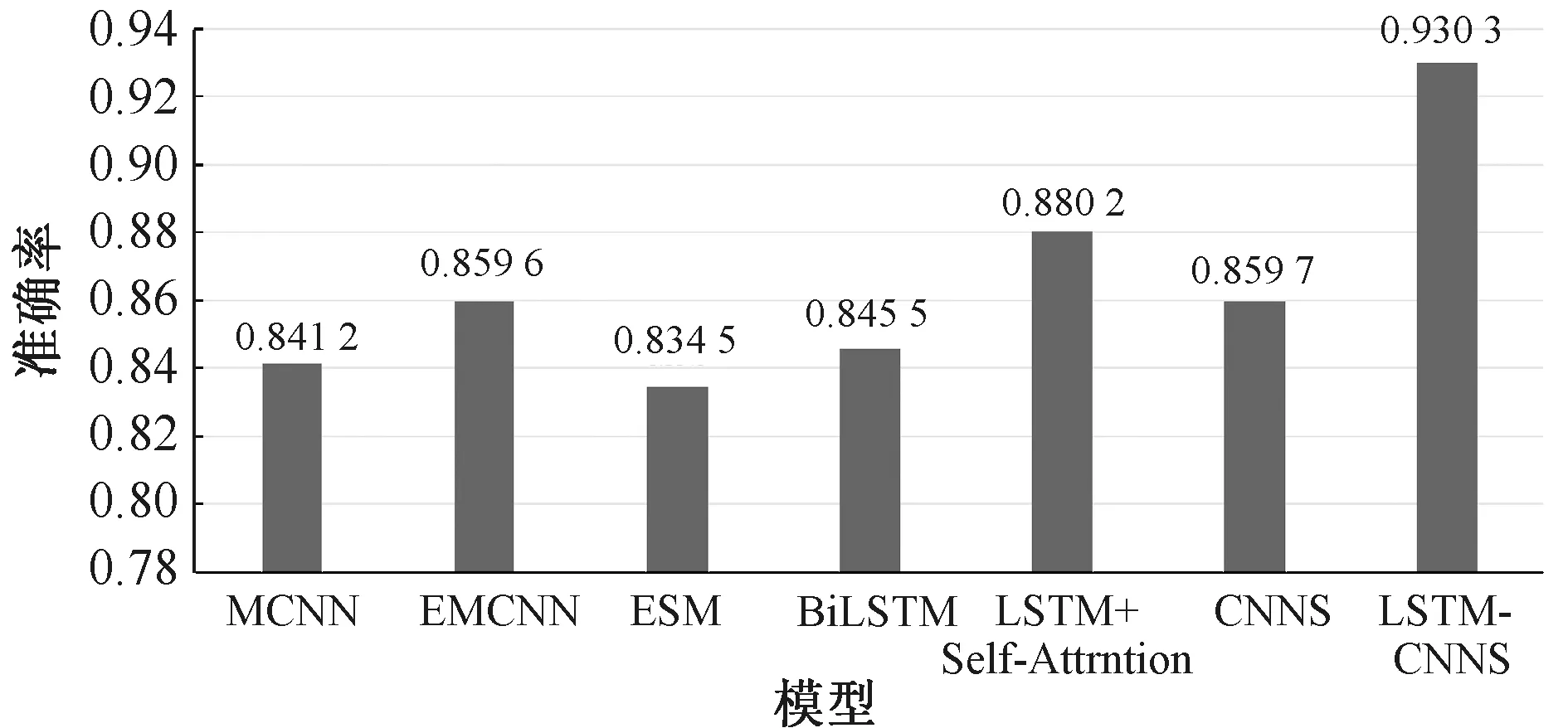
图8 实验结果对比
1)多通道卷积神经网络(multi-channel convolutional neural network,MCNN):使用多通道卷积神经网络对微博文本进行特征学习,进而构建语义表示模型,实现情感分类[20];2)情感多通道卷积神经网络(emotion multi-channel convolutional neural network,EMCNN):使用微博表情符号的语义特征表示矩阵进行文本情感增强,并通过多通道卷积神经网络进行特征学习,实现情感分类[21];3)情感空间模型(emoticon space model,ESM):计算微博文本中词语的词向量与微博表情符号向量的余弦函数值,实现词语到情感空间的映射,并采用SVM模型完成情感分类[22];4)BiLSTM:直接采用BiLSTM模型进行建模并进行情感分类,模型参数均按照默认参数值。本文没有进行基于BiLSTM的相关实验,而是参考了文献[23]中使用相同数据集、面向相同任务的实验数据;5)LSTM+Self-Attention:结合LSTM和自注意力机制进行建模并进行情感分类,模型参数如表1所示;6)CNNS:在CNN模型的基础上,对初始语料的情感强度进行加强,模型参数如表1所示;7)LSTM-CNNS:结合LSTM和CNNS搭建深度学习框架,模型参数如表1所示。
从图8可以看出,CNNS模型的准确率要高于BiLSTM、MCNN、EMCNN、ESM模型,而LSTM+Self-Attention模型的准确率要高于CNNS模型,使用LSTM-CNNS模型的准确率最高。通过横向对比可以发现,CNN模型在本任务中表现突出,同时情感增强模型也在一定程度上提高了分类的准确率。
5 结束语
本文针对文本分析中重要的情感分类领域进行了深入研究,结合词向量模型、长短期记忆网络、注意力机制和卷积神经网络,创新性地构建了LSTM+Self-Attention模型、CNNS模型、LSTM-CNNS模型。根据NLPCC官方的情感分类测评数据进行实验,结果表明,在官方测评语料下的情感分类准确率为:LSTM-CNNS> LSTM+Self-Attention >CNNS,其中LSTM-CNNS模型的情感分类准确率高达93.03%,说明本文提出的LSTM-CNNS情感分类框架有一定的优越性。在下一步的工作中,有以下几点考虑:1)将自注意力机制换为其他的注意力机制进行对比实验,得到最优的LSTN+Attention分类框架; 2)更换训练集和测试集,检验本文提出的LSTM-CNNS的情感分类框架的普适性; 3)在LSTM+Attention分类框架的基础上添加其他文本要素作为新的注意力,构建双重甚至多重注意力机制下的LSTM情感分类框架。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
新高考·高一数学(2022年3期)2022-04-28
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
福州大学学报(自然科学版)(2021年6期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
高中生学习·高三版(2016年9期)2016-05-14
