
搜索引擎的情报感知与刻画功能协同研究
2019-02-19 11:49张莹莹刘秀磊白雪瑞
北京信息科技大学学报(自然科学版) 2019年6期
张莹莹,刘秀磊,白雪瑞,尹 静
(1.北京信息科技大学 数据与科学情报分析实验室,北京 100101;2.中国科学院 前沿与教育局重点实验室,北京 100864;3.中铁科学研究院有限公司 科技情报中心,成都 611731)
0 引言
随着信息技术发展和互联网的普及,数据已渗透到各个领域和行业,数据优势逐渐成为企业提升核心竞争力的利器,数据分析对于决策制定的重要作用日益突显。目前许多国家已经意识到了将数据转化为知识的重要性[1],企业更期望综合利用各种知识处理工具,对数据进行加工和分析,进而能对企业未来发展趋势做出预测,最终增强企业竞争力。
目前情报研究学者都在探索企业在新的时代环境下如何构建情报竞争系统,以求全面分析数据,挖掘蕴含在数据里的潜在知识,提供具有关联性和延展性的情报数据,高效、经济、便捷地为企业开展情报工作提供便利。现有企业情报系统大多采用线性倒排索引,通过关键词匹配的方式进行检索,这种方式检索结果单一,事件不具有连续性,信息断片式呈现,缺乏对数据的整合和多维(如行业、企业、产品等角度)分析,较难提供具有关联性和延展性的情报数据,信息利用率较低。此外,现有检索系统通常采用全文索引技术,索引效率较低,信息处理速度较慢。
为了改善上述情报领域存在的问题,达到企业情报部门对海量互联网公开资讯数据检索全面、精准、快速的要求,本文提出了一种基于知识图谱的情报检索平台,将知识图谱应用在情报领域,通过知识抽取、知识挖掘和知识融合等技术将数据转化为知识,利用知识及知识之间的语义关系构成较为完备的领域知识图谱,从而能够使情报检索平台更好地理解用户检索的信息,使搜索结果更具有深度和广度,快速准确地找到用户最想要的信息,提供给用户更加全面、智能、人性化的检索结果。
1 系统整体设计框架
搜索引擎主要基于知识图谱,通过知识图谱刻画实体与实体之间的关系,使检索结果全面与精准,便于感知领域态势。系统整体设计框架如图1所示。首先,采用基于领域本体库的知识抽取方法对互联网中采取的多源海量异构数据进行知识抽取和挖掘,完成数据到知识的转变,构建知识图谱,建立实体间多样性关联,实现多维分析数据,解决现有系统数据整合和多维分析较弱的问题,提高实体间关联性和情报利用率;其次,结合索引对象是实体及实体关系的特点,提出了一种基于知识图谱的图式倒排索引机制,构建有关联的索引数据,解决索引间关联性较弱的问题;根据资讯情报数据量较大的特点,提出一种基于知识图谱的分布式索引机制,构建分布式检索平台,解决了索引及检索效率较低的问题;最后,在知识图谱的基础上,改进了原有打分机制,综合考虑检索词与实体匹配度以及实体间的关联关系,改善了传统搜索引擎检索结果彼此间无关联性和延展性的缺点,提高了数据的潜在价值。

图1 系统整体设计框架
2 情报感知与刻画的关键技术
2.1 基于本体库的知识抽取和知识图谱构建
知识图谱是指通过构建实体、实体属性及实体之间的语义关系而形成的知识网络[2]。图2为构建知识图谱的整体框架。首先,通过一系列自动或半自动的技术对半结构化数据和非结构化数据进行实体、实体关系及属性信息抽取;然后,将抽取的知识与结构化数据及第三方数据进行实体消歧、共指消解,进行知识融合;最后,对融合后得到的新知识进行质量评估,将合格的数据保存到知识库中。整个构建过程是一个迭代更新的过程,核心分为信息抽取、知识融合及知识加工3个阶段。
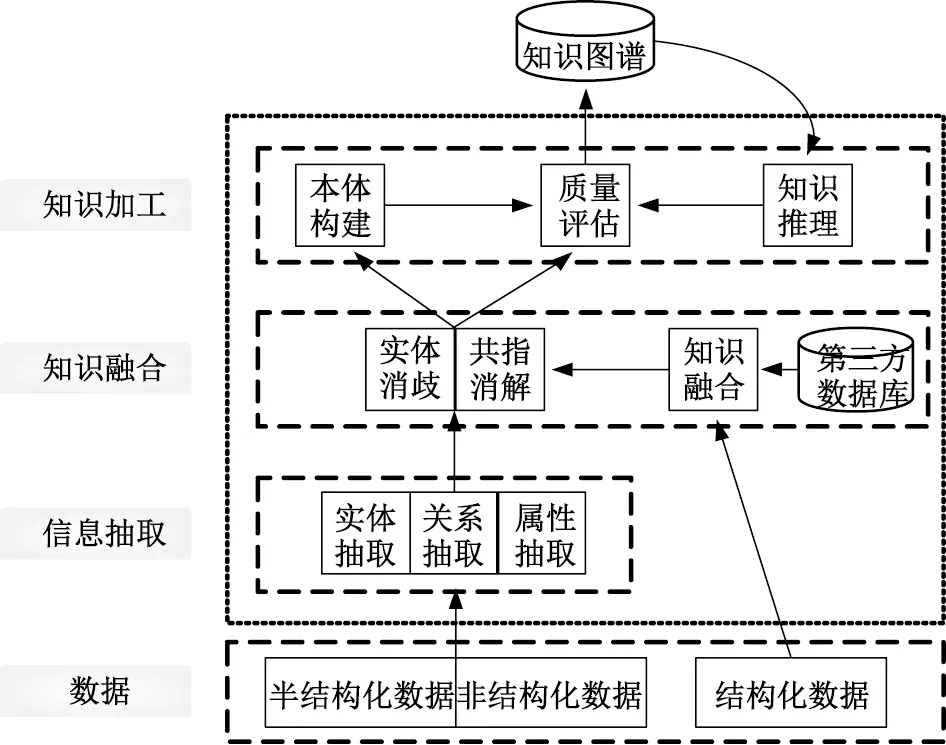
图2 知识图谱的构建框架
构建知识图谱,信息抽取是核心也是关键,利用领域本体库来判断抓取的数据是否是领域相关数据,并从数据中抽取出相关实体的知识碎片,最后将知识碎片进行融合形成领域知识。本文通过实验对比分析了5种知识抽取方法,如图3所示。

图3 五种抽取方法对比
从图3可看出基于本体库的知识抽取方法比传统的基于归纳学习[3-5]、基于自然语言处理[5]、基于视觉特征[6-8]和基于DOM树[9-10]的抽取方法更准确。本文通过本体库进行特征抽取得到的实体与实体间的关系以图4知识图谱的形式展示与存储,应用于搜索引擎,为搜索提供更全面更精准的检索结果。

图4 知识图谱实例
2.2 基于知识图谱的动态倒排索引构建
采用倒排索引(inverted index)的方式建立索引,倒排索引也被称为反向索引[11],相比于正向全文扫描索引和检索,倒排索引的速度更快。图5为传统倒排索引示例,主要由词典和倒排链表两部分构成,其中词典包括整个文档集合去停用词之后剩余的全部词汇,倒排链表包括整个文档集合中包含词典的全部文档。

图5 传统倒排索引机制
本文的索引数据是基于知识图谱的资讯情报数据,索引对象是以实体或者概念的形式存在的,因而实体或概念之间的语义关系是索引内容的重要部分。因而,图5所示的传统线性倒排索引机制已无法满足需求。如:当用户输入“字节跳动”时,检索结果为文章A、B、C,而含有字节跳动的CEO“张一鸣”的文章D并不能被检索出来。图6为基于知识图谱的倒排索引构建机制,是基于图式的,当用户输入“字节跳动”时,检索结果为文章A、B、C、D,其中含有字节跳动CEO“张一鸣”的文章D也能被检索出来。由此可见,基于知识图谱的倒排索引机制具有语义检索的能力,提高了信息的全面性和准确性。

图6 基于知识图谱的倒排索引机制
2.3 基于知识图谱的分布式倒排索引构建
传统的分布式倒排索引划分机制与基于知识图谱的分布式倒排索引划分机制不同。传统的分布式倒排索引划分机制主要有基于词表(Term)的索引切分方式和基于文档(Document)的索引切分方式2种,其中基于词表的索引切分方式检索路由次数少,容易造成系统负载失衡;基于文档的索引切分方式并发性能和负载均衡较好,但每次检索每台服务器都要参与,从而降低了整个系统的检索性能。
本文在上述两种分布式索引划分方式的基础上,结合基于知识图谱的索引构建机制,采用聚类的方法将语义相关联的文档划分到一台索引服务器上,实现基于图谱的分布式倒排索引构建,解决了词表划分负载失衡和文档划分检索范围大的问题,减少了检索时间,提高了检索结果的精度。
本文分布式索引机制构建大致步骤为:①采用TF-IDF(term frequency-inverse document frequency)统计方法对文本特性作向量表示;②采用文本聚类的技术进行索引切分。 TF-IDF是信息检索和文本数据挖掘常用的一种加权技术,其主要思想是:某个词或短语在某一文档中出现的频率很高,且在语料库中其他文档中出现的次数很少,则认为该词或短语可以反映该文档的特征[21]。式(1)为TF(term frequency,词频)的计算公式,某个词条在一篇文档中出现的频率为
(1)

式(2)为IDF(inverse document frequency,逆向文件频率)的计算公式,用来衡量一个词或短语在整个语料库中的普遍重要性。
(2)
式中:Ii为逆向文本频率;|D|为语料库中所有文件的总数;|{j:ti∈dj}|为含有词语ti的文件数目。为了避免分母为0,因此常使用1+|{d∈D:t∈d}|作为分母。
TF-IDF是用来过滤掉常见词语,保留重要的词语,其计算公式为
Mi,j=Ti,j×Ij
(3)
本文采用K-means算法对文本进行聚类划分。通过K-means算法得出的距离来衡量文档之间的相似性,图7为具体计算流程。首先从语料库中随机任选K个文档作为质心;然后对数据集中剩余的文档计算其到各个质心的距离,将其归到最近的簇里;之后再重新计算各个簇的质心,确定新的质心;最后迭代直至质心的移动距离收敛且小于或等于某个阈值,此时所得的类簇即为聚类结果。

图7 K-means算法流程
文档之间的欧式距离为
(4)
式中D为文档含有的属性个数。
每次迭代的过程中需要重新计算的类簇质心为
(5)
式中:Mk为第k个类簇的质心;|Ck|为第k个类簇中文档的个数。
K-means算法通过迭代计算更新类簇,直至使用式(6)对本次迭代和上次迭代两次计算的差值小于或等于某一阈值时,即ΔJ<δ时,终止迭代,输出聚类结果。
(6)
式中:J为所有数据点到簇心的距离之和;K为类簇的个数。
2.4 基于知识图谱的智能检索及结果排序
本文基于知识图谱实现智能检索和结果智能排序。具体实现方法为:首先,根据词语相似度选择索引服务器;然后,采用Top-K算法查询模型,将检索结果进行二次智能排序。
本文索引的构建方式是按照文档聚类划分的,所以某一个类簇中必然有高频、核心主题词。因此可以通过计算查询关键词与高频主题词之间的相似度,来替换查询关键词与类簇集合之间的相似度,然后再根据词语在类簇中所占的比重给予一定的权值,最后加权得出查询关键词与类簇集合之间的相似度。利用式(7)来计算词语之间的相似度。对于两个词语W1、W2,记词语之间的相似度为S(W1,W2),词语之间的距离为dist(W1,W2),则
(7)
式中α为一个可调节的参数。
基于知识图谱的搜索引擎在对检索结果进行排序时不仅要考虑查询词与文档之间的相似度,还要考虑实体之间的关联。因而,本文在对检索结果进行智能排序时,首先,使用Top-K算法从每台索引服务器的检索结果中取出一定量的数据,然后,再利用领域特性对取出的结果按照一定的规则进行排序。
3 实验对比分析
本文实验过程中使用的硬件配置为Win10操作系统,4G运行内存,Intel(R) Core(TM)i5-7200U CPU @ 2.50 GHz处理器;软件开发工具和环境为IDEA、Neo4j、JDK1.8、Lucene6.0.0等。
本文使用的数据主要来源于北京信息科技大学数据科学与情报分析实验室所研发的“泛娱乐大数据情报分析平台”项目,该平台已为北京爱奇艺科技有限公司、北京网易传媒有限公司等互联网企业提供定制服务。该平台的数据主要由图8中所示的购买合作数据、企业自有数据、公开资讯数据3部分组成,共大约20 000多个种子,抓取近半年的8 414 866篇资讯文章,包括金融、文化娱乐、教育、智能硬件等多个领域的资讯数据。

图8 数据来源
以准确率(Precision)和召回率(Recall)两个指标来衡量检索结果的质量。式(8)为准确率的计算公式,是检索正确的结果占所有检索结果的比例;式(9)为召回率的计算公式,是检索正确的结果占所有正确结果的比例。
P=TP/(TP+FP)
(8)
R=TP/(TP+FN)
(9)
式中:TP为将正类预测为正类的数量;FP为将负类预测为正类的数量;FN为将正类预测为负类的数量。
通过对比分析传统搜索引擎和基于知识图谱的搜索引擎在检索领域核心关键词时的准确率、召回率及检索效率,衡量2种搜索引擎的效果。具体实验过程是首先由领域专家制定标准样本集;然后分别使用2种检索系统对领域核心关键词检索;最后根据检索结果集及式(8)、(9)计算2种检索平台的准确率和召回率。图9为2种搜索引擎在资讯情报领域内的准确率对比结果。由图9可看出,基于知识图谱的搜索引擎在资讯情报领域内的准确率比传统搜索引擎平均高出2%左右。
图10为2种搜索引擎在资讯情报领域内的召回率对比结果。由图10可发现传统搜索引擎的召回率很低,很多与关键字相关的文章很难被检索出来,比如在使用“字节跳动”关键词检索时,与该公司CEO“张一鸣”相关的文章并不会被检索出来。而基于知识图谱的搜索引擎正好可以解决上述问题,相关文章均会连带检索出来,从而为用户节省了大量的时间和精力,大大地减少了企业的投入。

图10 两种搜索引擎的检索结果召回率对比
从图11中可以看出随着被检索的数据量越来越多,基于知识图谱的搜索引擎要比传统的搜索引擎检索花费的时间更少。由此可见,在资讯情报领域内使用基于知识图谱的搜索引擎可以在保证检索效率的同时提升检索数据的全面性和精准性。

图11 两种搜索引擎检索数据花费时间对比
4 结束语
本文首先采用基于领域本体库的知识抽取及挖掘技术完成知识图谱的构建,将多源海量异构数据融合在一起,客观、全面地刻画同一实体及实体语义之间的关系;接着使用基于知识图谱的倒排索引动态构建、分布式倒排索引的检索机制和智能排序的构建技术,对用户检索内容和文档内容进行关联和计算,从而使企业用户能够感知最全面、最核心的知识;最后通过实验对比分析基于知识图谱的搜索引擎和传统搜索引擎检索结果的准确率、召回率以及检索效率,由实验结果可知基于知识图谱的搜索引擎检索结果更加全面、精准和高效。实现了情报的感知与刻画协同研究,形成智能科学的信息获取手段,有助于预测企业未来发展趋势,帮助企业获得发展先机。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
计算机与网络(2022年2期)2022-03-17
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
疯狂英语·新阅版(2020年11期)2020-12-21
新城乡(2018年6期)2018-07-09
电脑爱好者(2017年7期)2017-05-06
领导科学论坛(2016年9期)2016-06-05
科学导报·学术论坛(2013年5期)2013-06-26
