
改进粒子群联合禁忌搜索的特征选择算法
2019-01-31 02:34张震魏鹏李玉峰兰巨龙徐萍陈博
通信学报 2018年12期
张震,魏鹏,李玉峰,兰巨龙,徐萍,陈博
(1. 国家数字交换系统工程技术研究中心,河南 郑州450002;2. 中国人民解放军战略支援部队信息工程大学,河南 郑州 450002)
1 引言
入侵检测技术利用数据挖掘、机器学习等方法对审计日志、安全日志或者网络上获取的信息进行分析处理,实现对入侵行为的检测[1]。瞬息万变的海量网络数据使入侵检测系统(IDS,intrusion detection system)面临巨大挑战,如检测速度低、检测效果差、计算负荷大等。其中,检测速度是入侵检测系统实时性要求的重要指标,如何在保证检测准确率的前提下提升入侵检测速度,成为当前入侵检测的研究热点。
特征选择是入侵检测中数据预处理的关键环节,能够在入侵检测数据集中筛选出对分类器的分类性能影响最重要的一组特征[2]。良好的特征选择算法能够降低网络数据的维度,减轻入侵检测系统的计算负荷,提高入侵检测系统的检测速度。本文针对原始数据集数据维度高的问题,提出了一种改进粒子群联合禁忌搜索(IPSO-TS, improved particle swarm optimization taboo search)的特征选择方法,通过降低入侵数据的维度,有效地提升了入侵检测效率。
2 研究现状
特征选择算法根据是否独立于分类算法可分为Filter方法和Wrapper方法。Filter方法独立于分类算法,首先衡量每个特征的重要性,然后根据重要性对所有特征进行排序,最后将前N个重要的特征作为特征子集。这种方法的优点是计算量较低,可以有效去除噪声特征,缺点是忽略了选择出的特征子集整体对分类效果的影响程度[3]。Wrapper方法通过分类算法的准确率评估特征子集的优劣,优点是考虑了整个特征子集对分类效果的影响,分类准确率较高,缺点是计算量较大[4]。从分类性能方面考虑,Wrapper方法比Filter方法更适合于网络数据的特征选择,故本文采用Wrapper方法。
搜索机制是Wrapper方法的核心,用来生成候选特征子集[5]。考虑到对庞大而复杂的搜索空间中的所有可能特征子集进行穷举搜索很难实现,粒子群算法(PSO, particle swarm optimization)为代表的演化计算[6]具有自然进化的属性,在特征选择中有利于优化搜索机制,提高搜索效率,故常被用来寻优特征子集。近年来,有许多结合改进粒子群进行特征选择的方法,本文从优化粒子群算法参数、优化粒子群表示方法、优化离散型或连续型特征、优化评价指标等方面引用相关参考文献进行分析。董跃华等[7]提出一种自适应粒子群联合禁忌搜索的特征选择算法,在PSO搜索过程中,对每一代全局优化粒子进行禁忌搜索,有利于保持粒子活力,增强搜索优化解的能力,但该方法中粒子群缺乏多样性且对每一代全局优化粒子进行禁忌搜索会极大增加算法的时间复杂度。Tran等[8]提出了基于势粒子群优化的特征选择方法,设计了一种新的粒子群表示方法,通过选取切点离散化原始特征,然后筛选出性能较好的优化特征子集,该方法仅适用于离散型特征,无法筛选出连续型特征中的优化特征。Nguyen等[9]提出了一种遗传算子优化 PSO的连续型特征选择算法,利用交叉、变异等遗传算子提高PSO的搜索能力,但该方法受群落初始分布影响较大,且遗传算子中交叉、变异概率固定不变,不利于搜寻到全局优化解。翟俊海等[10]提出了一种将粗糙集相对分类信息熵和粒子群算法相结合的特征选择方法,将分类信息熵作为适应度函数,结合改进粒子群算法得到优化的特征子集,但该方法的适应度评价指标结构较为单一,不利于选出分类性能较好的特征子集。
综上所述,目前大多数特征选择算法都有各自的局限性,例如,文献[8]中方法无法筛选出连续型特征中的优化特征;文献[9]中算法寻优效果受群落初始分布影响较大;文献[10]中方法的评价指标结构较为单一。本文以特征维度和分类准确率的优化配置为目标设计出评价标准,基于该标准提出了一种遗传算子改进粒子群联合禁忌搜索的特征选择(IPSO-TS)算法,通过遗传算子优化粒子群算法寻优特征子集,以期望生成更好的初始最优解。在此基础上,联合禁忌搜索(TS, taboo search)算法找到全局优化解。其中,粒子群算法具有快速收敛的特点;遗传算法增加了粒子群落多样性;TS算法有利于跳过局部最优值,实现全局优化搜索,提高特征子集搜索效率。
3 IPSO-TS特征选择算法
IPSO-TS特征选择算法的流程如图1所示,其中,搜索模块应用本文提出的改进粒子群联合 TS算法,实现搜寻候选特征子集的功能;评价模块应用本文提出的适应度函数,完成对候选特征子集的性能评价;判决模块根据判决条件选择数据集的最优特征子集,结束循环,并将该子集作为结果输出。
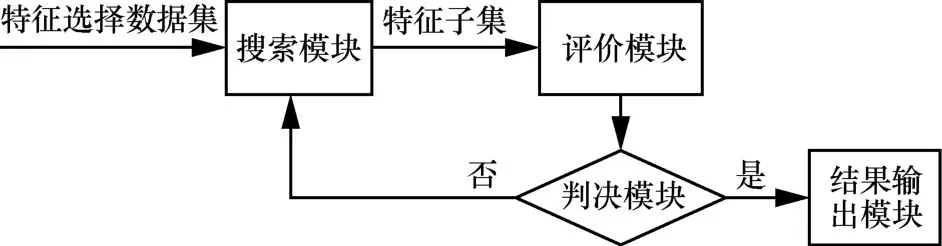
图1 IPSO-TS特征选择算法流程
针对图1中的评价模块,本文提出了一种新的适应度评价函数,如式(1)所示。
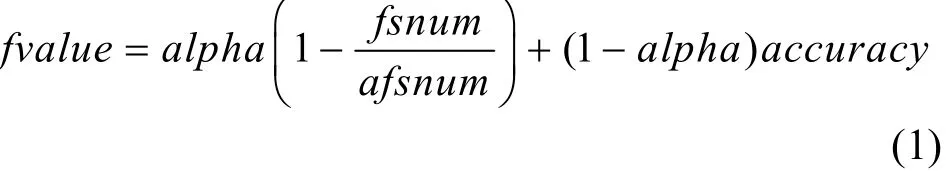
其中,fsnum表示特征选择后的特征数量,afsnum表示总特征数量,accuracy表示分类准确率,alpha和(1-alpha)都是权重参数。本文的目标是在保障分类准确率的条件下,降低特征维数,因此,选择了较高的accuracy权重参数,即accuracy=0.98,相应的alpha=0.02。
式(1)中适应度函数与传统特征选择方法相比,引入了分类准确率accuracy和特征选择后的特征数量fsnum作为参数,能够更准确对特征子集性能进行评估。其中,分类准确率越高,特征维数减少的比例越大,则适应度值越大,表明提取的特征子集性能越好。
本文通过K最近邻(KNN,k-nearest neighbor)分类算法得到分类准确率accuracy,如式(2)所示。
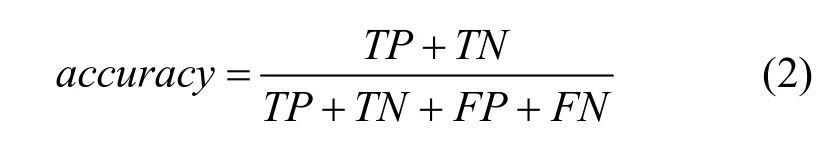
其中,TP和TN表示入侵检测中正确分类的正常数据和异常数据,FP和FN表示入侵检测中错误分类的正常数据和异常数据。
3.1 改进的PSO算法
3.1.1 PSO算法
PSO算法是根据鸟群捕食行为设计的一种群智能算法,基本思想是通过粒子群中粒子之间的协作和信息共享来搜寻最优解。PSO算法可以分为二进制PSO算法和连续PSO算法。连续PSO算法指为粒子赋值实数,二进制PSO算法则是为粒子赋值二进制数。由于连续PSO具有更广阔的应用前景,本文使用连续PSO算法进行特征选择,根据粒子个体极值和群体最优解进行寻优,寻优计算式如式(3)和式(4)所示。
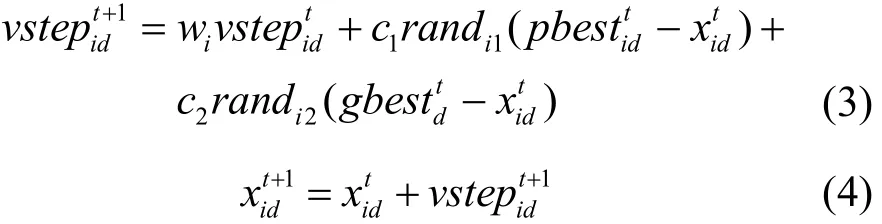
其中,t表示迭代次数,i=1,2,…,m(m表示所有粒子个数),d=1,2,…,n(n表示粒子总维数),randi1和randi2为[0,1]之间的随机数,表示粒子i的历史极值在第t次迭代中第d维最优位置,表示群体最优粒子在第t次迭代中第d维最优位置,c1和c2表示学习因子,表示粒子i在第t次迭代中第d维位置,表示粒子i在第t次迭代中第d维移动速度。
刘杨等[11]研究了线性函数、凹凸函数递减等4种PSO算法惯性权重w后发现,多峰函数寻优中凸函数递减惯性权重法收敛速度最快,效果最好。因此本文的惯性权重取值如式(5)所示。
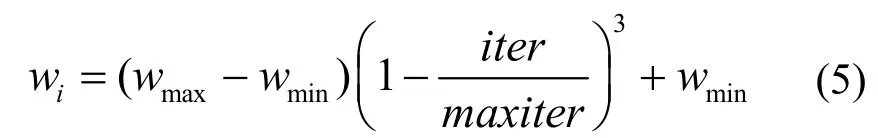
其中,wmax和wmin分别表示惯性权重的最大值和最小值,iter表示迭代次数,maxiter表示最大迭代次数。
在PSO算法中,c1体现了粒子对自身的学习能力,c2体现了粒子对群体的学习能力[12],c1数值递减和c2数值递增有利于发挥粒子初期探索和后期对群体的认知能力。因此本文学习因子c1和c2的赋值如式(6)和式(7)所示。
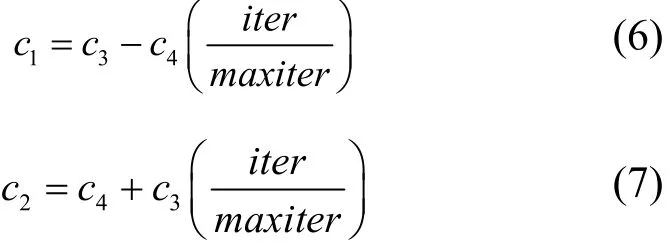
其中,c3和c4是常数,且c3>c4。
3.1.2 基于遗传算法对粒子群的改进
遗传算法是一种通过模拟自然进化过程寻找最优解的随机化搜索方法。遗传算法中的遗传算法交叉和突变对于PSO算法作用很大,可以增加粒子群落变化的多样性,产生出代表新解集的种群,克服粒子群易于陷入局部最优的问题。
为了避免粒子群过早收敛问题,本文中的粒子群算法每次迭代的时候对多对粒子进行交叉操作,利用基于适应度值的轮盘赌算法选择出多对母本粒子,将其进行交叉产生出多对下一代粒子,选择其中优良的下一代粒子替换群落中母本粒子和历史极值。其中交叉操作主要是将第 1个母本粒子与第 2个母本粒子维位置互相交换,其中,L表示粒子总维数。每次迭代进行交叉操作粒子的个数Pi如式(8)所示。其中,swarmsize表示所有粒子个数。根据粒子群的特性,遗传算法在搜索初期时粒子群的种类更加随机和多样,到了搜索后期,粒子群逐渐收敛,相似度增加,故交叉操作在前期作用大于后期作用。所以随着迭代次数增加,每次迭代的交叉操作粒子个数应该随之减少,且交叉概率应该随之降低,这样有利于减少计算成本。交叉概率更新如式(9)所示。
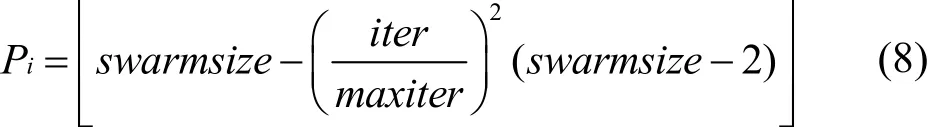
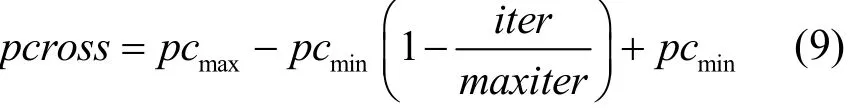
其中,pcmin和pcmax分别表示最小和最大交叉概率。
虽然交叉操作初期可以很好地探索搜索空间,但在粒子群后期收敛后作用较小[13]。变异操作和交叉操作恰好相反,在搜索初期效果不明显,但是在搜索后期有较好的搜索效果,于是引入变异操作以进一步提高空间搜索能力,且随着迭代次数增加变异概率随之提高,有利于进一步寻找到更优粒子。变异概率更新如式(10)所示,粒子中第d维位置的选择概率如式(11)所示。
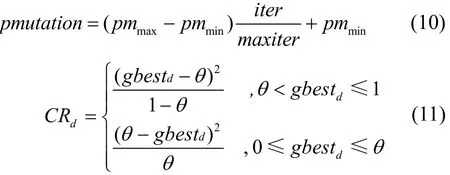
其中,pmmin和pmmax分别表示最小和最大变异概率,gbestd表示全局最优粒子第d维位置,θ表示选择阈值。当gbest第d维位置的值大于阈值θ时,若gbestd值越大,则CRd越大,否则CRd越小。当gbest第d维位置的值小于阈值θ时,若gbestd值越小,则CRd越大,否则CRd越小。然后生成[0,1]之间的随机数r,若r>CRd,执行相应的变异操作,如式(12)所示,否则将新粒子第d维位置childd赋值为gbestd。
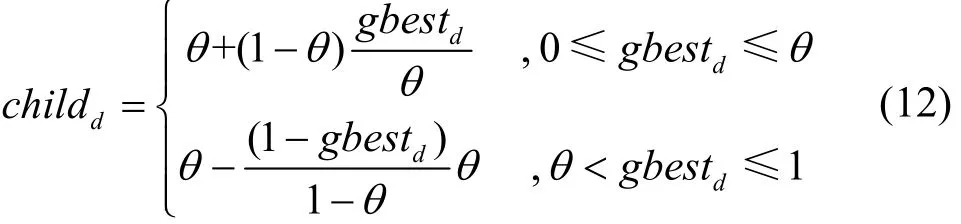
其中,若gbestd的值小于或等于选择阈值θ,则将childd的值映射到[θ,1]之间的实数,否则将childd的值映射到(0,θ]之间的实数,这有利于改变特征的选择属性。
本文中改进PSO算法通过不断进化,后期粒子群逐渐收敛,粒子群相似度大大增加,这导致很难搜寻到更好的优化解。由于TS算法不仅可以接受优解,还可以接受劣解,比PSO算法能获得更优解,因此本文通过引入TS算法解决了该问题。
3.2 TS算法
TS算法是一种亚启发式随机搜索全局寻优算法,主要包含初始解、邻域函数、禁忌表属性、候选集藐视准则等基本参数[14],以局部邻域搜索算法为基础,通过设置禁忌表停止已经进行过的操作或变换,再利用相应的藐视准则释放禁忌表中符合条件的元素[15]。
本文建立长度为L的禁忌表 (L表示总特征个数),设置迭代次数为,将通过改进粒子群算法得到的初始最优解作为TS算法的初始解。改变初始解2个随机位置特征元素的值,保持其他特征元素的值不变,将该过程作为邻域函数:设初始最优解为R={Ti,i=1,2,··,L},随机生成 2个不同整数随机数x和y,利用式(13)更新初始最优解中Tx和Ty的值,得到新的候选最优解。通过随机生成组不同随机数对x和y,对初始特征集进行变换,得到组候选解当作初始候选解集合。
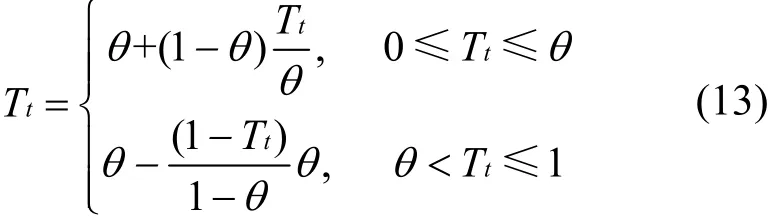
其中,t表示x或y。
本文中禁忌表使用队列结构,每次迭代时,添加禁忌对象到队首,队列溢出时,删除排在队尾的禁忌元素。藐视准则要满足2个要求:1) 将要解禁的解必须优于当前解[16];2) 为了避免陷入死循环,禁忌表队首的元素不能被解禁。
4 IPSO-TS特征选择方法的IDS应用实例
IDS流程如图2所示,其中,数据获取模块通过监控目标网络或系统来采集数据;数据预处理模块是对采集的数据进行数值化、标准化、特征选择等处理,本文IPSO-TS群算法用于选择入侵检测数据的特征子集;入侵检测模块利用训练数据来训练分类器,采用分类器对待检测的数据集进行分析,获得入侵检测的结果,通过检测指标评价结果,本文中的分类器由KNN算法构建;响应模块是IDS对检测结果的决策。

图2 IDS流程
在IPSO-TS算法中,若粒子位置元素大于阈值,表示选择该特征,否则放弃该特征。通过粒子群的移动产生不同位置向量,记录粒子搜索期间所有粒子历史极值和群落最优粒子,将收敛后的群落最优粒子当作TS算法的初始解。IPSO-TS算法的特征选择方法基本流程如图3所示,具体实现步骤如下。
步骤 1 设置相关参数。改进粒子群最大循环次数maxiter1=50,禁忌搜索次数maxiter2=30,粒子群规模swarmsize=30,最大适应度maxfit=0.9999,pcmin=0.7,pcmax=0.8,pmmin=0.02,pmmax=0.1。设置惯性权重w=0.7928,阈值threshold=0.7等推荐参数[4]。文中入侵检测数据集特征赋值为在[0,1]之间的不同实数,构成粒子位置向量,随机初始化粒子群位置和速度,求解适应度,初始化粒子群swarm、粒子历史极值pbest、群体最优解gbest及它们的适应度fswarm、fpbest、fgbest。其中,选择阈值threshold设置为0.7,目的是大概率筛选出30%的特征子集;
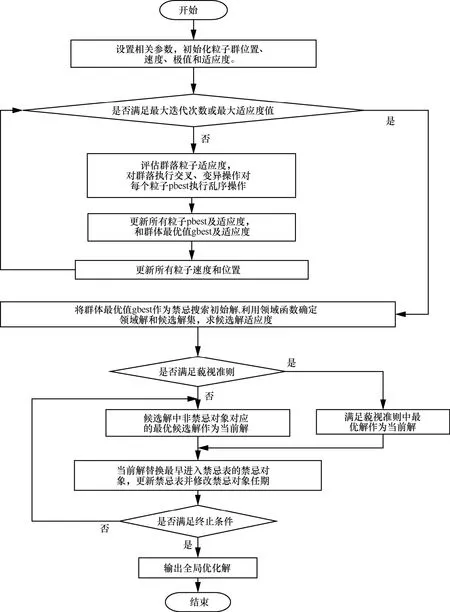
图3 IPSO-TS算法在IDS中应用流程
步骤 2判断是否满足iter>maxiter1或fgbest>maxfit,满足则执行步骤6,否则执行步骤3。
步骤3评估粒子群体适应度值,根据式(5)~式(7)更新惯性权重w、学习因子c1、c2,如式(9)和式(10)更新交叉、变异概率。第iter次迭代中,根据 3.1.2节对群落中粒子对执行交叉操作、对所有pbest执行随机乱序操作以及对gbest执行突变操作分别得到各自后代粒子,若后代粒子更优,则将父母粒子替换为后代粒子。其中,对pbest执行随机乱序操作目的是通过随机打乱所有粒子历史极值位置的顺序,以找到更优的粒子个体极值,有利于避免粒子个体极值过快陷入局部最优解。
步骤 4分别更新相应pbest、gbest及它们的适应度。
步骤 5更新粒子群体的速度和位置,然后执行步骤2。
步骤 6根据 3.2节进行禁忌搜索,将经过上述步骤得到的群体最优解gbest作为TS算法的初始解,利用初始解产生相应的邻域解,得到组不同解当作初始候选集合及其适应度。
步骤 7判断候选解集中的解是否满足藐视准则,若满足则执行步骤8,否则执行步骤9。
步骤 8将候选解中非禁忌对象对应的最优候选解作为当前解,然后执行步骤10。
步骤 9将满足藐视准则中最优解作为当前解,然后执行步骤10。
步骤 10将最早进入禁忌表的禁忌对象作为当前解,更新禁忌表并修改禁忌对象任期。
步骤 11判断是否满足最大禁忌搜索次数或当前解适应度是否达到限定值,若满足则执行步骤8,否则执行步骤12。
步骤 12输出全局优化解作为入侵检测数据集全局优化特征子集。
5 IDS实验结果与分析
5.1 KDD CUP 99数据预处理
本文实验中使用的是KDD CUP 99数据集,它是网络入侵检测领域的标准数据集[17],选取其提供的10%训练子集和测试子集(corrected)进行实验,其中,训练子集包含 49万条网络连接记录,测试子集包含 31万条网络连接记录。每个网络连接被标记为正常类型和异常类型,异常类型被分为DoS(拒绝服务攻击)、Probe(扫描与探测)、R2L(未经授权的远程访问)、U2R(对本地超级用户的非法访问)等4类,共有39种异常类型。本文实验中分别针对4类异常类型数据和汇总数据,进行入侵攻击检测,样本数据集如表1所示。
数据集中每一条记录代表一条完整的会话,每条连接记录由4类特征集组成:基本特征集、内容特征集、基于时间特征集和基于主机特征集,共有41个特征,其中包含3个字符特征和38个数值特征,如表2所示。特征选择前需要对数据进行预处理,入侵检测中数据预处理主要分为字符特征数值化和数据归一化过程。字符特征数值化是指将符号特征映射到有序数字,例如protocol_type类型映射为tcp = 1,协议类型映射为udp = 2,协议类型映射为icmp = 3。
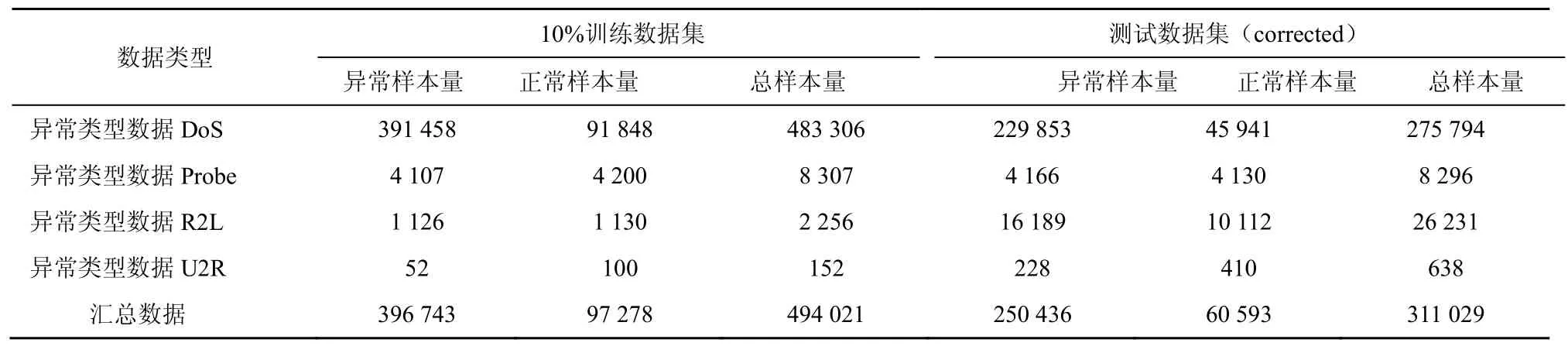
表1 KDD CUP 99样本数据集组成

表2 KDD CUP 99连接记录的特征集
以同样的方式,将service、flag和数据集中的类别特征映射到有序数字。对经过字符特征数值化后的数据进行归一化处理,使特征数值处于相同数量级,目的是消除因特征数值范围不同造成的影响。本文通过式(14)进行数据归一化处理。
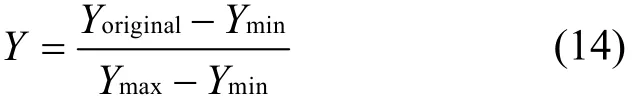
其中,在入侵检测数据集的同一维数据列中,Yoriginal表示该列原始数值,Ymin表示数据列中最小值,Ymax表示数据列中最大值。
5.2 实验结果及分析
本文实验数据集主要分为检测样本数据集和特征选择数据集。入侵检测样本数据集采用表1中的训练和测试数据集。为了缩短寻优特征子集的时间,从表1的DoS、Probe、R2L和U2R的训练数据集和测试数据集中分别随机抽取10%、20%、20%和 100%的数据作为各自特征选择数据集中的训练和测试数据,并将上述特征选择数据集合并作为汇总数据的特征选择数据集。
本文实验的计算机操作系统为Windows 10,处理器为Intel(R) Core(TM) i5-3230M 2.60 GHz,内存为4 GB,测试环境为Matlab 2014b。本文所提IPSO-TS算法从特征选择时间和特征选择维数,检测时间和分类准确率,漏报率和误报率这6个方面,对比了PSO-TS算法[7]、PSO算法和CMPSO(co-evolutionary particle swarm optimization)算法[9],得到如下实验结果。
在特征选择数据集上比较4种特征算法得到特征子集的特征选择时间和特征选择维数,如表3所示。其中特征选择时间指对特征选择数据集进行特征选择的总用时,特征维数序号和表2相对应。
从表3中可以得到,通过与PSO-TS算法、CMPSO算法和 PSO算法得到的各个检测模型平均特征选择维数比较发现,本文所提IPSO-TS算法比其他特征选择方法减少了至少29.2%的特征。本文方法的特征选择时间比其他特征选择算法要长,主要是由于pbest随机乱序过程和TS过程增加了特征选择时间。
在表1检测样本数据集上比较所有特征情况下和上述4种特征选择算法后的入侵检测时间和分类准确率,其中入侵检测时间是指利用KNN算法[18]对表1检测样本数据集中的测试数据集进行分类预测的总用时,K取值为5。实验结果如下表4。
从表 4中可以得到,通过与 PSO-TS算法、CMPSO算法和PSO算法得到的特征子集作为分类样本的平均分类准确率比较发现,本文方法比其他特征选择方法提高了至少2.96%的平均分类准确率,缩短了至少 15%的平均检测时间;比所有特征情况提高了 0.27%的平均分类准确率,缩短了至少42.32%的平均检测时间。其中,本文方法特征选择时间相比其他特征选择算法更长,该时间主要耗费在特征选择算法寻优特征选择数据集的特征子集,而检测阶段仅指搜寻到特征子集后分类算法 KNN对检测样本数据集的检测时间,不包含寻优特征子集的时间。本文方法寻优到的特征子集维度更低、准确率更高,对检测样本数据集分类时处理的数据量也会更低,故可以降低分类算法的分类检测时间。
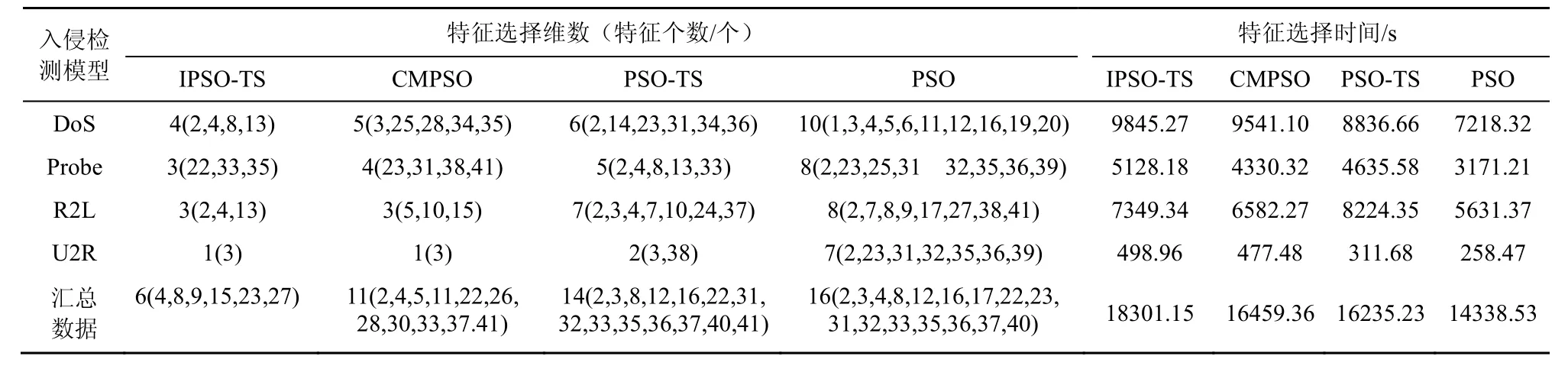
表3 4种特征选择算法的特征选择时间和特征选择维数
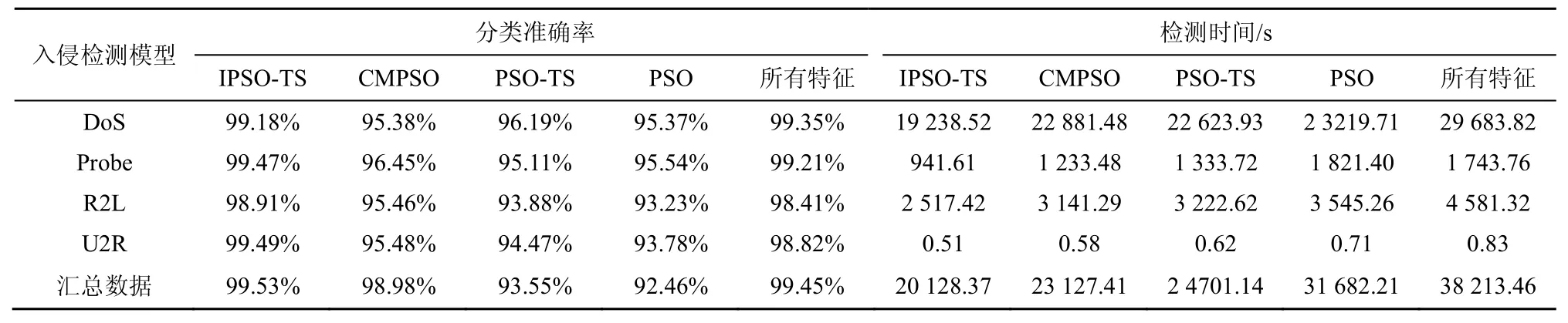
表4 4种特征选择算法及所有特征的检测时间和分类准确率
在表1检测样本数据集上比较上述4种特征选择算法后的漏报率和误报率,计算式如式(15)和式(16)所示,实验结果如表5所示。
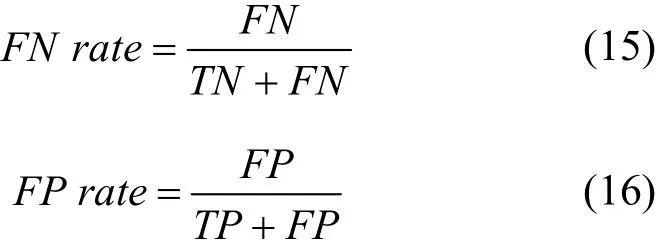
从表 5中可以得到,通过与 PSO-TS算法、CMPSO算法和PSO算法得到的特征子集作为分类样本的平均漏报率和误报率相比,本文所提IPSO-TS算法比CMPSO降低了0.79%的平均漏报率,降低了0.67%的平均误报率;比PSO-TS方法降低了1.74%的平均漏报率,降低了0.83%的平均误报率;比PSO方法降低了1.97%的平均漏报率,降低了1.72%的平均误报率。
本文方法以特征维数联合分类准确率构建的适应度函数作为特征筛选的评价指标,通过基于改进粒子群和禁忌搜索的二次特征选择找到全局优化特征子集。相比基于PSO算法或CMPSO算法的特征选择,本文方法首先利用改进粒子群特征选择方法找到初始优化特征子集,然后利用禁忌搜索的特征选择算法再次筛选特征子集,保证了所筛选出来的特征子集具备更高分类性能;而相比基于PSO-TS的特征选择方法,本文算法利用遗传算子改进了PSO算法,设计了适用于特征子集搜索的交叉和变异算子,实现了交叉概率和变异概率的自适应变化,有效提高了搜寻全局优化特征子集的效率。表3~表5的测试结果表明,在同样的测试环境下,相比其他算法,本文方法得到的特征子集具备更低的特征维数、误报率、漏报率和检测时间,及更高的分类准确率。
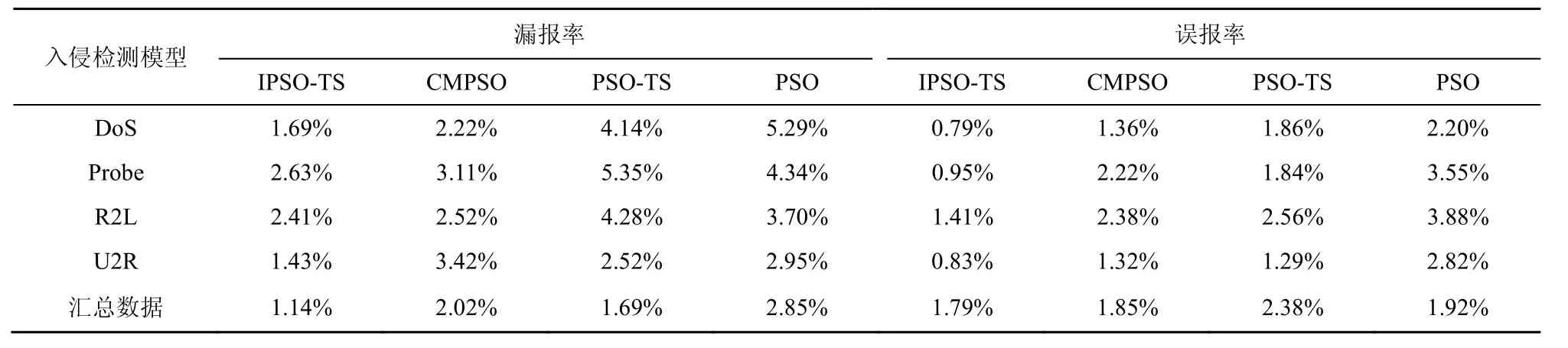
表5 4种特征选择算法的漏报率和误报率
5.3 实验结论
综合上述结果可以发现,本文提出的特征选择算法相比其他特征选择方法显著降低了入侵数据集的维度,提升了在线检测速度,提高了分类准确率,降低了漏报率和误报率。本文方法的主要问题是特征选择时间相比其他特征选择算法更长,但由于该时间属于离线训练阶段的处理时间,并不会增加系统的在线检测时间[19],反而能在筛选出性能更好的特征子集后,降低系统的在线检测时延。
6 结束语
针对入侵检测中数据维度高的问题,本文所提方法通过采用遗传算子对粒子群算法进行了改进,得到了特征选择初始最优解,进一步对该解进行禁忌搜索得到了特征子集的全局优化解。该方法不仅适用于入侵检测系统,还适应于其他类似系统,例如文本分类系统,基因数据分析系统等[20],在这些系统中,都存在对数据集进行离线特征降维和在线检测数据的需求,因此,本文方法具有一定的普适性。
猜你喜欢
昆明医科大学学报(2022年1期)2022-02-28
福州大学学报(自然科学版)(2022年1期)2022-01-21
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
河南科学(2021年3期)2021-05-06
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
合肥工业大学学报(自然科学版)(2020年2期)2020-03-23
南京大学学报(数学半年刊)(2020年1期)2020-03-19
浙江工业大学学报(2017年5期)2018-01-22
自动化学报(2017年5期)2017-05-14
