
泛在学习环境下个性化导学模型的设计与实现
2019-01-21 08:54:10陈清华翁正秋李林锦
温州职业技术学院学报 2018年4期
陈清华,翁正秋,李林锦
(1.温州职业技术学院 信息技术系,浙江 温州 325035;2.温州市人民医院,浙江 温州 325000)
0 引 言
随着4G网络通讯技术的广泛应用,人类社会已从电脑互联时代跨入移动互联时代。智能移动终端不仅为人们提供了上网的便利,也为远程泛在学习的发展提供了更为便捷的途径[1]。现有学习系统大都实现了资源的共享,学习者可依据资源类别进行资源浏览或搜索学习。然而,在学习者学习目的不明确、资源分类不精确的情况下,盲目的浏览及简单的基于关键词的搜索式学习,难以充分有效地引导学习者进行学习,易造成资源本身及学习者个人精力的浪费,难以实现高效学习[2],存在课程信息过载、学习控制功能不全、学习者学习迷航等问题,导致大量水平不一的学习者学习兴趣、学习质量及学习效率的下降。个性化推荐技术通过分析学习者个体特征、动态学习行为及学习对象的特征,动态地产生个性化学习方案,为学习者量身定制学习路径,从而建立起一个充分体现交互性和灵活性的具有良好自适应性的智能化导学系统。本文针对移动泛在学习环境的新特点,提出个性化导学方案,以个性化服务技术[3]为依托,以动态社区[4]为核心,通过规范课程建模、采集用户多方位数据、全面分析用户行为等步骤,使学习者由资源被动浏览者转变为主动参与者,解决学习者普遍存在的孤独感、学习无序、学习迷航等问题,从而逐步提升学习者学习的积极性,实现高效学习。
1 泛在学习环境的优化
泛在学习常常被定义为使用各种无线网络、智能移动终端和情景感知技术等进行学习的教育系统[1]。区别于传统远程教育系统中的学习特性,泛在学习呈现出灵活性、及时性、无缝衔接性等新特点。移动泛在学习为学习者提供的学习环境主要包括学习资源、信息检索与查询工具、各种通信工具等。为准确实现个性化导学,对传统教学环境重新优化改造,建立个性化导学模型,体现在重构数据采集方案、细化在线课程、优化设计学习资源和改进通信工具四个方面。
1.1 重构数据采集方案
泛在学习环境中,学习者的学习交互行为更加频繁,数据采集覆盖范围更为宽广。为实现更优质、准确、高效的服务,将学习数据划分为个人基础信息、地理位置信息、用户行为数据等五类(见表1)。个人基础信息是指对用户采集的基本信息,主要包括用户性别、年龄、专业或专长等,此类信息稳定性好,主要用于用户特征分析;地理位置信息是指利用移动终端的位置传感器,对用户的地理位置变化进行采集,并使之服务于用户关联度分析;用户行为数据是学习者在使用平台时所留下的轨迹,是对登录时间、学习过程、交互与交流等行为结果的采集;交互性数据是指通过对此类数据进行过滤、分析,以用于用户关系挖掘和构建社区;社区关系是对每位用户在社区中的动态关系维护,社区关系随各类数据的变化而动态调整。

表1 学习者学习数据采集、分析与应用
1.2 细化在线课程
现代泛在学习具有碎片化的特点,学习行为随时发生,对原有网络课程的知识点划分粗细度[4]进行调整,将原有元知识点结构再度划分,建立细粒度更高的元知识点结构,所构建的课程知识点结构更为细致。
1.3 优化设计学习资源
基于移动资费的计算方式及知识点结构细粒度的变化,学习对象同样需要碎片化、小型化。结合泛在学习新特点,各知识点下挂的各种学习资源单位学习时长应进一步缩短。所对应的学习对象设计应遵循以下三个原则:一是学习对象与知识点相对应;二是单个知识点的学习耗费时长被重新规划,以5min为上限;三是每个知识点的学习对象至少应包含过程资源、测试试题两类。
1.4 改进通信工具
远程个体学习常常具有时空、地理位置的不一致性,学习者往往倍感孤独。个性化导学模型,建立以AGENT技术[4-5]为核心的智能虚拟学习社区,通过社区成员间的交流与互助解决突出的学习者孤独感问题(见图1)。智能学习社区系统基于用户基本特征、用户实时交互行为、用户评价结果等数据构建智能虚拟学习社区。用户通过自动构建的个性化学习社区实现与相似远程群体的高效互助学习。

图1 智能虚拟学习社区系统功能设计
2 个性化导学模型的设计与实现
2.1 泛在学习系统功能
基于学习者学习需求和学习过程,设计泛在学习系统(见图2)。依据角色和功能,泛在学习系统分为5个子模块,分别为课程本体构建模块、用户数据采集模块、用户聚类分析模块、P2P社区自组织模块和学习计划生成模块。

图2 泛在学习系统
课程本体构建模块,主要根据先验建立知识点与知识点间、学习资源与知识点间的各种关系。用户数据采集模块,主要提供学习者进行用户信息维护、网络学习、测评的前台学习功能,通过实时数据采集,实现用户特征分析、学习社区构建与交流互动、个性化导学方案生成等功能。用户聚类分析模块,主要对系统采集的各类数据(包括用户基础特征信息、用户行为数据、资源特征及用户评价数据等)进行分析,推荐具有相似特征的学习者,并依情况变化进行动态调整,通过构建的社区将兴趣相似的学习者聚集在一起,彼此间相互交流、相互借鉴,并依据对推荐资源的评价值动态调整社区成员列表。P2P社区自组织模块,主要实现交流、资源评价、个性化引导、学习和测评功能。学习计划生成模块,根据学习者自身的学习行为,在课程体系和资源特征的基础上,推荐学习路径、学习资源和学习时长,完成个性化学习方案的动态生成。
2.2 个性化导学过程
导学方案是个性化学习模型的关键部分,在原有个性化方案的基础上,学习计划生成模块针对教学环境新需求,改进学习方案编排,提出基于社区数据、资源信息、时长估算的个性化导学过程(见图3)。
个性化导学过程根据社区内动态学习行为、基于课程信息的知识点结构和丰富的学习对象设计,通过推荐知识点学习顺序、规划基于知识点的学习资源、评估资源学习时间和时长等步骤,实现个性化学习方案的初步编排和动态调整。
2.3 改进个性化推荐方案
为应对数据采集宽度、广度的变化和学习方式的进一步变革,对个性化推荐方案进行改进。一是在虚拟学习社区关系构建过程中,学习者特征提取、分析维度增加了地理位置项。当两个学习者处于同一区域内时,学习者的社区聚类中将动态增加彼此。二是在基于社区内的学习路径推荐中,为更加明确元知识点的关系,减少计算量,不再考虑复合知识点间的关系。三是在保持原有基于学习路径的知识点推荐的基础上,对原导学方案生成算法进行改进和调整,添加学习时间间隔和学习时长估算的编排,生成的方案更加完善。四是对社区可能存在的抖动问题和成员间的信任危机问题,引入信任度因子,当计算得到的信任度因子未超过阈值时,则采纳相应的推荐与调整。
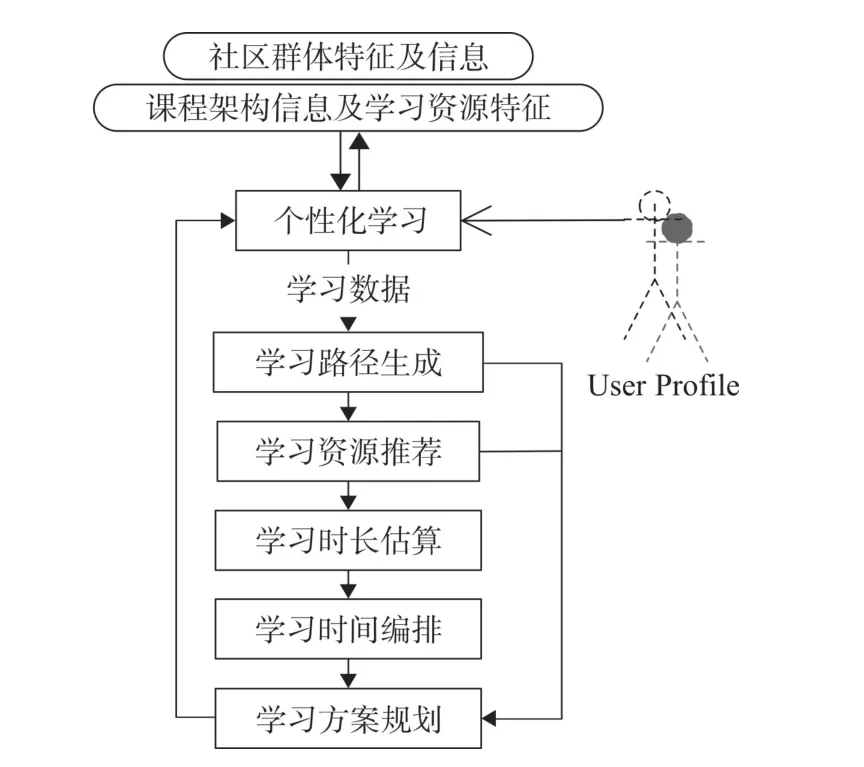
图3 个性化导学过程
资源相应学习时长的计算主要根据当前学习者相应社区内对该资源的使用时长加权平均值进行估算。学习者Lj对资源Oi的学习时长ljm)。其中,m表示学习者Lj的社区中使用资源Oi的采信人数,ljx表示学习者Lj与学习者Lx间的关系紧密程度,Tij表示学习者Lj对资源Oi的实际学习时长。当社区内成员数为0时,则Tij为系统设置的学习资源默认时长。学习资源学习时长的确定主要基于领域专家知识,并根据课程实时使用情况进行调整。是否采纳某学习者的使用实况以更新学习资源的推荐学习时长值,取决于判定阈值,当测评情况未超过阈值时,则按比例更新时长。学习间隔的确定同样采取加权平均的算法。
针对系统中资源评价、用户交流信息存在的信任危机问题,个性化导学模型引入信任度因子,构建用户信任度因子提取模型(见图4)。信任度因子提取模型设置为输入层、网络学习层和输出层三层网络结构。设定网络中的两个用户分别为用户i和用户j,利用输入层提取用户i与用户j间的位置距离d(i, j)、用户间隔度g(i, j)和通讯频次f(i, j),将提取到的3个值输入到网络学习层中,通过网络学习层的实时学习和运算,计算得出网络结构,最终计算得出用户信任度因子r(i, j)。

图4 用户信任度因子提取模型
3 仿真测试
2015年末,对温州职业技术学院软件服务专业所授基础课程“操作系统应用与实践”线上自学子课程“Linux实战”的87位学习者进行调查,结果表明,86%的学习者表示更喜欢增加了动态虚拟社区功能的平台。究其原因,在于其为互助学习和交流提供了强有力的工具支撑,有助于提高课程学习效率,可实现更高的推荐准确性和更强的用户粘度。
学生的认同是改造个性化导学过程的主要外在驱动源之一。为有效证明个性化导学方案的可行性和有效性,根据87位学习者的原始在线学习数据,对改进的个性化导学过程进行仿真测试。一是对数据源进行重塑。由于学习对象的低时长需求,仿真根据知识点结构对学习时间偏长的学习对象与相应的学习数据进行随机切割分片,产生了[2,5]的碎片化学习时长数据,并对课程结构和学习对象的对应关系进行重新关联,数据集由此扩充了10倍之多。另外,历史数据中缺乏对地理位置信息的采集,仿真则根据学习者的寝室信息对位置信息进行对应,量化后设置为地理位置信息维度,而用户间隔度、通讯频次则采用一致的度量(即忽略此项因素的影响)。二是对无用的噪声数据进行清洗,去除缺少相关数据项的人员与学习数据。通过显性分析不难发现,位置信息与学习对象在使用时序上有着惊人的关联关系。对推荐结果与原始数据的资源使用时序进行仿真比对,结果表明,信任度因子有助于提高推荐准确度。改进后的推荐方法匹配程度达81%,相较于原始推荐算法67%的准确度,提高了14%。
原始推荐算法与改进后的推荐算法区别在于采信的数据范围。原始推荐算法采信的是全部关联的数据;而改进后的推荐算法只采信具有相近地理位置的数据,基于位置条件的数据过滤,在一定程度上提高了准确度。然而,这些历史数据的不利因素在于,学习过程数据是人为参与指导的过程中发生的,数据本身具有很强的时序性和计划性,数据过于接近目标结果,使得结果数据匹配提高程度偏高,影响了仿真结果的准确性。同时,由于缺乏其他维度数据的支撑,并未全面体现信任度因子的作用结果。
4 结 语
个性化教学、因材施教一直都是教育界探索与追求的目标[6]。目前,基于数据挖掘、个性化推荐技术的智能化导学系统有着广阔的应用前景。个性化导学模型结合泛在学习新特点,提出改进的智能化学习方式,为学习者在新的学习环境中解决缺乏互动交流、有效引导等问题提供了一种方案。个性化导学模型对传统教学环境重新优化改造,以用户数据为基石,根据动态用户行为和交互信息,快速构建智能虚拟学习社区,精确生成个性化导学方案,并实时更新课程信息。然而,个性化导学过程的改进并未有效落在实处,缺乏真实实验数据和应用效果的支撑。在下一步研究中,需要根据实际情况对个性化导学模型进行开发与应用。同时根据反馈结果,不断调整算法模型与各类参数;根据大数据背景从算法的效率上改进个性化导学模型,以不断完善个性化导学过程的普适性和高效性。此外,现有泛在学习系统中仍存在监控、调节学习过程工具缺乏等问题,仍应从学习控制和监督出发,探讨结合督学技术的系统实现。
猜你喜欢
学生天地(2020年15期)2020-08-25 09:22:02
文苑(2020年4期)2020-05-30 12:35:12
中学生数理化·高一版(2020年3期)2020-04-21 08:03:20
中学生数理化·高一版(2020年3期)2020-04-21 08:03:18
意林·少年版(2020年2期)2020-02-18 11:14:52
新闻传播(2018年12期)2018-09-19 06:27:10
中学生数理化·高一版(2017年9期)2017-12-19 12:15:11
海外华文教育(2016年4期)2017-01-20 08:22:24
汽车与新动力(2016年6期)2017-01-04 10:50:48
中学历史教学(2016年1期)2016-11-11 07:10:06
