
一种基于数据挖掘的图书荐购模型研究
2019-01-12 04:07,,
浙江工业大学学报 2019年1期
, ,
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
随着当今时代社会政治、文化和经济的高速发展,各学科交叉融合,书目信息在不断的增长。据《2016年中国图书零售市场报告》显示,2016年,全国图书零售市场动销品种数1 725.09万种,新书品种数约为21.03万种。新书品种从2012年到2016年始终在20~21万种。面对种类繁杂的图书资源,高校图书馆如何选购到既符合质量要求,又符合读者需求的图书将面临着巨大的挑战。传统的文献采访[1]是当前图书馆收集图书荐购信息的主要方式,但该方式工作量大、效率低,很难及时把握读者多变的图书需求。通过查阅近5年国内外相关文献资料,发现基于计算机相关技术的面向读者的图书个性化推荐研究较多,面向图书馆的图书荐购研究相对较少。陈大莲[2]基于微薄平台对高校读者图书荐购进行了探析;孔云等[3]提出了面向“互联网+”图书荐购模型;刘华[4]介绍了读者决策采购在美国大学的实践及其对我国的启示。随着大数据[5]时代的到来,一些学者开展了基于数据挖掘技术的图书荐购研究。唐小新等[6]利用数据挖掘技术聚类分析法和分布式异构技术对荐购系统进行了设计与实现;周伟等[7]探讨了数据挖掘技术、PDA模式和混合推荐算法在高校图书馆荐购系统中的应用。概括起来,传统文献采访已经无法适应当前高校图书馆荐购需求,现有基于计算机技术支持的图书荐购方法研究较少,且因缺乏对读者借阅等行为数据的分析,难以准确把握读者需求,并未被高校图书馆广泛采用。
为此,笔者设计了一种基于读者行为数据挖掘的图书荐购模型,该模型以读者图书馆行为数据为基础,首先利用改进的k-means算法挖掘活跃书籍,然后对活跃书籍进行分词,提取其中的关键字,最后根据这些关键字与书商提供的书单或者荐购系统中的书单进行匹配,从而智能快速地给出荐购书单,大大提高了荐购的主动性、科学性、准确性和及时性。
1 基于读者行为数据挖掘的图书荐购模型
图书荐购模型主要包含挖掘活跃书籍、匹配荐购书单两个过程,具体如图1所示。

图1 图书荐购模型Fig.1 Book recommendation model
1.1 挖掘活跃书籍
挖掘活跃书籍是基于读者行为数据,通过聚类等算法,得到既符合质量要求又受读者欢迎的图书的过程。高校图书馆业务系统和自动化系统中记录了大量的读者行为数据,包括读者进馆数据、借阅数据、资源预定数据和检索数据等。结合图书馆馆藏数据、读者个人数据(如学籍等),可建立读者完整的图书馆读者行为数据库。这些数据隐藏着读者个体在图书馆中对阅读的偏好,但荐购是面向全体读者,所以需要数据挖掘技术对数据进行分析。活跃书籍挖掘的准确性决定着荐购书单的命中率,后续将着重讨论活跃书籍的挖掘过程。
1.2 匹配荐购书单
匹配荐购书单是活跃书籍与已有的荐购书单匹配的过程,是一个主动、自动化获得最终荐购书单的过程。目前高校图书馆荐购书单主要获得方式:1) 荐购系统中读者推荐的书单;2) 图书馆馆员以问卷调查等方式获得的书单;3) 书商提供的书单。虽然上述3种方式提供的书单有一定的荐购合理性,但荐购的片面性也是显而易见的,需要对书单进行再次精细化选择。匹配荐购书单过程首先利用Stanford CoreNLP分词工具[8],对活跃书籍书名进行分词处理,书名被分为名词、形容词、连接词、字符和数字等;然后去除分词中的数字、字符和连接词等无关词,获取书名关键字;最后,将提取的关键字与荐购书单进行字符串匹配,输出书名中含有关键字的书单,这些书单即为荐购书单。该过程相对较为简单,在此不作重点讨论。
2 活跃书籍的挖掘过程
挖掘活跃书籍是荐购模型的核心过程,具体挖掘过程如图2所示。

图2 活跃书籍挖掘过程图Fig.2 Active book mining process
2.1 原始数据的采集
研究的原始数据来自于高校图书馆业务系统和相关自动化系统,包括读者数据表(readerinfo)、馆藏数据表(colinfo)、专家数据表(expscore)、借阅数据表(lendinfo)和检索数据表(searchinfo),其中,借阅数据表、检索数据表等记录着读者读书借阅行为,其他表构成了读者借阅行为的完整表达。其之间的关系如图3所示。


readerinforeader_idnamesexspecialtystatus…1张三男计算机本科生…

colinfobook_idnamecategorycopysublisherwriterpubyearprice…1java编程思想75机械工业出版社埃克尔2007128.00…

lendinforeader_idbook_idoperation(B/L/R)operation_time…11R2014/10/15…

searchinforeader_idbook_idcontentsearch_time…12java程序设计2014/11/15…

expscorepublisherso reputationp qualitysub valtech refer机械工业出版社92.595.69397
图3数据存储表关系及结构
Fig.3Therelationshipsandstructuresofdatastoragetable
2.2 数据处理
读者行为决定了书籍的活跃度。将图书借阅比率、待馆时长、检索次数、活跃出版社和读者身份占比等5个特征作为评价活跃书籍的主要依据,也是后续k-means算法重要的聚类特征,将聚类后特征值最大的簇作为活跃书籍。要获取上述5个特征,需要对原始数据进行分析计算。
2.2.1 借阅比率
借阅次数最直观的表现了读者对该书的需求。但图书馆馆藏复本数对借阅次数也有一定的影响。为了避免图书复本数不同对实验的影响,提出借阅比率计算式为
(1)
式中:BR为借阅比率;BN为借阅次数;CN为复本数。
2.2.2 待馆时长
待馆时长的值越小表示该书被频繁借阅。主要根据书号(book_id)、操作类型(operation)、操作时间(operation_time)和复本数(copy)计算每本书的平均待馆时长。涉及借阅数据表(lendinfo)和馆藏数据表(colinfo)。
2.2.3 检索次数
检索次数对于发现读者需求十分重要,检索信息表中的检索记录是读者行为的真实记录,能客观、全面地反应读者的潜在需求。检索次数根据读者编号(reader_id)、检索内容(content)和检索时间(search_time)统计获得。
2.2.4 活跃出版社
将出版量大、质量高、利用率较高和读者影响力较大图书的出版社称为活跃出版社。针对要挖掘的活跃书籍,结合全校师生的需求和图书馆的馆藏结构,综合考虑影响文献采访的诸多因素,从读者借阅、专家推荐和历史采购等角度,构建活跃出版社数据挖掘模型为
P=PA×wA+PB×wB+PC×wC
(2)
式中:P为某个出版社的综合评分;PA,PB,PC分别为读者借阅、专家推荐和历史采购信息对出版社的评分;wA,wB,wC分别为读者借阅、专家推荐和历史采购在活跃出版社评分挖掘中所设置的权重。根据P值的大小判断每本书的出版社是否为活跃出版社。
2.2.5 读者身份占比
读者身份占比表示借阅某本书的读者的身份不同,该书体现的价值也是不同的。教师、研究生和本科生代表着3个不同的身份,因此对不同身份的读者给予不同的考虑权重。读者身份占比计算式为
R=RT×wT+RG×wG+RU×wU
(3)
式中:R为读者身份占比的值;RT,RG,RU分别为借阅某本书的教师人数、研究生人数和本科生人数;wT,wG,wU分别为教师、研究生和本科生3种身份所占的权重。
2.3 数据挖掘
经数据处理后获得聚类特征集合,应用数据挖掘中的聚类算法对其进行聚类,得出活跃书籍。采用k-means[9-10]聚类算法进行聚类,传统的k-means算法准确率不高、稳定性不好,改进后的算法提高了准确率和稳定性。
3 改进的k-means算法
3.1 传统k-means算法的不足
聚类算法是数据挖掘中的一类重要技术,k-means是聚类算法中最常用的算法之一,具有算法简单、收敛速度快以及能有效处理大数据集等多方面的优点[11]。但是,k-means算法也存在一定的局限性,聚类结果受初始聚类中心的影响较大[12]。针对k-means算法的局限性,很多学者对k-means算法进行了改进研究,任培花等[13]引入不确定域对数据对象进行描述并对数据预处理后采用累积距离的方法确定初始聚类中心,但引入数据对象的不确定性因素会给算法带来复杂性问题;吕明磊等[14]提出了一种改进的k-means算法,它依据“两个对象距离越近,相似度越大”这一依据来确定初始类心,但对异常数据并不敏感。
3.2 改进的k-means算法的思想
基于样本点距离越大,相似度就越小这一原则,为了避免选取的初始聚类中心是个噪声点,设置了一个可调节的阈值,用以确定样本集中的噪声点。如果初始聚类中心分类的数目小于特定的阈值,则将这个分类中的初始聚类中心标记为噪声点,在重新选取初始聚类中心时,去除该噪声点;阈值大小取决于样本集个数、分类个数和阈值参数。
3.3 改进后k-means算法的具体流程
在传统k-means算法基础上,对初始聚类中心的选取进行了改进。改进后的k-means算法流程如图4所示。

图4 改进的k-means算法流程图Fig.4 The flow of improved k-means algorithm
将数据处理后的聚类特征集合作为数据集输入该算法,并对数据进行归一化处理[15],将取值映射在区间[0,1]上。新建1个集合存放噪声点,在去除噪声点集合的样本集中选取k个初始聚类中心,利用欧式距离计算每个样本点与初始聚类中心的距离,将其划分至距离最小的初始聚类中心所在的簇。根据簇的大小判断其是否小于设定的阈值,若小于则将该初始聚类中心放入噪声点集合,重新选取聚类中心;否则计算每个簇的均值M1,根据均值产生新的质心,再根据欧式距离计算每个样本点与M1的距离产生新簇,计算新簇的均值M2,若|M2-M1|>1,继续调整簇,若|M2-M1|<1将得到的簇输出到文件,算法结束。
初始聚类中心选取是本算法的关键环节,具体步骤为

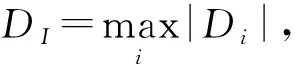
步骤3噪声点的确定。设噪声点阈值参数为t,根据初始聚类中心产生簇,判断是否每个簇中的个数大于阈值N/Kt,如果大于则继续算法下面的步骤,否则将这个簇中的初始聚类中心标记为噪声点,并在算法重新选取初始聚类中心时去除噪声点,直到每个簇的个数满足设定的阈值,才继续进行算法下面的步骤。
4 实验结果与分析
实验数据是某大学图书馆2014,2015年的借阅数据、馆藏数据、历史检索数据和读者信息数据等。其中读者借阅数据513 148条,馆藏1 552 591本,检索9 005 486条,涉及读者26 267人。基于前述所提荐购模型相关算法,获得借阅比率、待馆时长、检索次数和读者身份占比;基于计算评分后,取排在前20%的出版社为活跃出版社,最后获得影响书籍活跃度的5个特征项,如表1所示。

表1 书籍活跃特征集Table 1 Book active feature set
利用改进后的k-means算法对2014,2015年的31 215,29 136个样本集进行聚类,分别获得4 735,3 490本活跃书籍,最后利用分词工具对其书名进行分词,获得真正需要荐购的书单。例如:书号0000355067的书名为“学习MySQL:[英文本]”,根据改进k-means算法挖掘为活跃书籍,通过与荐购书单匹配,得到“高性能MySQL(第3版)”为最终荐购图书,荐购过程结束。
4.1 k-means算法改进的实验结果比较
采用传统k-means算法与改进的k-means算法对上述实验样本集进行准确率比较,聚类准确率指被正确分配到指定类的样本点个数与总样本点个数的比值。阈值的取值对改进算法的准确率有影响。在2014,2015年样本集和聚类个数一定的情况下,阈值参数t的取值对聚类准确率的影响如图5所示,横坐标代表t的取值,纵坐标代表准确率,经过大量的实验发现,当t取值为1.0时,每个类的个数都无法大于阈值N/K,所以t从1.5开始取值验证。当t取值为2.0时准确率最高,而随着t的增大,阈值变小,对分类个数的限制变小,准确率受t值的影响变小甚至不变。而t的最优值与输入数据和聚类个数K有关系,当输入数据一定,聚类个数变化时,最优值也会随之改变。

图5 阈值参数不同准确率的变化情况Fig.5 The change of accuracy with different threshold parameters
将阈值参数t为2.0时的改进的k-means算法与传统算法进行比较,实验结果如表2所示,传统算法由于初心每次都是随机选取的,所以每次的聚类结果都不同,导致准确率也不稳定;改进后的算法在相同的样本集中选取的初始质心是相同的,所以多次实验的聚类结果是相同的,准确率也稳定不变,而且每次实验的准确率都要比传统算法高,说明改进后的算法准确率和稳定性都要比传统算法好。
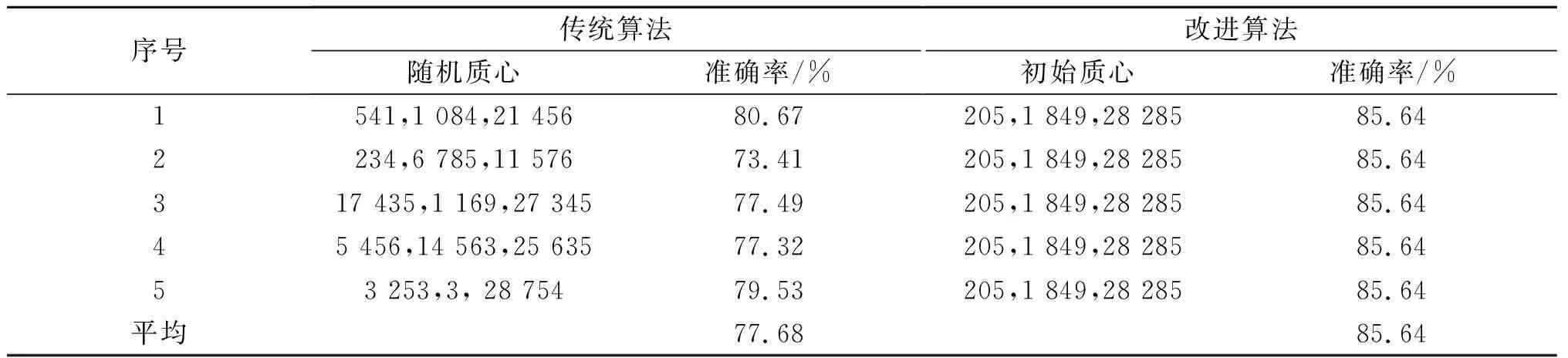
表2 两种算法对2015年样本集的测试结果Table 2 Two algorithms for the test results of the 2015 sample set
4.2 图书荐购模型验证与分析
最后,通过分析读者对图书需求量和活跃度的变化情况,对图书荐购模型的合理性进行验证。首先挖掘出2014年的活跃书籍,提取书名的关键字,将其与2015年的借阅书籍进行匹配,其中63.05%的图书的借阅次数高于2014年的图书借阅次数,这说明读者对含有该关键字的图书的需求量在不断增加;将从2014年的活跃书籍提取的关键字与2015年的活跃书籍匹配,匹配到的图书占2015年活跃书籍的71.43%,证明含有该关键字的图书在图书馆中非常活跃。两个实验结果证明了图书荐购模型方案科学可行。
5 结 论
设计了一种基于读者行为数据挖掘的高校图书荐购模型,包括活跃包括挖掘活跃书籍和匹配荐购书单两个过程;提出了一种基于改进的k-means算法的活跃书籍挖掘方法,同时给出了影响书籍活跃度的5个特征项的计算方法;然后将挖掘的活跃书籍处理后与荐购书单进行匹配,最终获得图书馆真正需要购买的图书。实验证明:图书荐购模型方案科学可行。由于荐购书单过程相对简单,而且考虑到篇幅限制,只重点讨论了挖掘活跃书籍。后续工作可以针对图书购买的复本数进行分析研究,并给出建议,使得图书荐购模型更具适用性。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
海峡姐妹(2019年8期)2019-09-03
小学生学习指导(中年级)(2018年11期)2018-12-04
东方少年·布老虎画刊(2018年7期)2018-05-14
Coco薇(2017年11期)2018-01-03
电子技术与软件工程(2016年24期)2017-02-23
物理(2009年7期)2009-09-05
证券导刊(2009年23期)2009-09-02
