
基于数据挖掘算法的废旧物资处理系统设计与实现
2019-01-10 08:42:18杨振宇
鞍山师范学院学报 2018年6期
杨振宇
(安徽交通职业技术学院 信息工程系,安徽 合肥 230051)
废旧物资处理符合循环经济发展模式,废旧物资中很大一部分属于不可再生资源,做好这部分废旧物资的处理与回收工作显得尤为重要[1-3].各地政府越来越重视废旧物资处理工作,但由于没有形成完整统一的管理机制,缺乏信息化、一体化、系统化的管理系统,废旧物资处理过程中效率低下、信息化水平较低、专业人才缺失等问题凸显,很大程度上制约了我国废旧物资处理事业的良性发展[4-6];另一方面,由于没有重视废旧物资处理内在规律和潜在的数据支撑,相关政策的制定往往带有盲目性,不能很好地引导我国废旧物资处理事业向着良性循环方向发展.基于上述背景,以我国某三线中等城市为例,采用C4.5决策树算法对废旧物资进行精细化分类与处理,采用支持向量机(SVM)算法进行固定周期内废旧物资处理数据的潜在规律挖掘.在此基础上,遵循软件工程一般方法,设计并实现了一款基于数据挖掘算法的废旧物资处理系统.实际验证表明,系统整体运行稳定,实用性较好,抗压性等指标满足实际要求,可以较好地满足废旧物资处理对信息化的要求.
1 基于C4.5决策树算法的废旧物资精细化分类与处理算法设计
废旧物资种类繁多,处理价值和处理工艺各异,为了最大程度上利用废旧物资,需要对废旧物资进行精细化处理,基于此,提出了一种基于C4.5决策树算法的废旧物资精细化分类算法.该算法主要包括废旧物资的属性识别与分裂子算法、分裂子属性的离散化处理子算法、构造决策树并进行剪枝操作子算法、处理具有缺失属性值的训练数据子算法.如图1所示,属性识别与分裂子算法主要实现废旧物资的属性识别并分裂为若干个子属性;分裂子属性的离散化处理子算法主要实现若干个子属性的信息增益离散化并作为构建决策树的主要元素;构造决策树并进行剪枝操作子算法主要实现决策树的构建并依据PEP剪枝法进行剪枝操作;处理具有缺失属性值的训练数据子算法主要处理训练样本集中出现属性值缺失的情况和待分类样本.
废旧物资精细化分类与处理的运行流程如下:S1:创建并确定分类节点数N,根据录入的废旧物资信息进行属性识别与属性分裂;S2:判断废旧物资属性类型是否为连续型,如果是,则根据信息增益提取进行离散化处理;S3:根据数据样本离散化处理结果构建决策树,采用PEP剪枝法进行子树的修剪,确保较高的分类准确率;S4:训练样本集中有可能会出现一些样本缺失了一些属性值,待分类样本中也会出现这样的情况,为了确保分类数据的系统性,需要进行补充缺失操作.基于C++语言,在VS2012环境下实现的核心代码如下:
std::pair
optimal_attribute(datas,attributes,map_attr);
pTree->attribute = optimal_attrs.first;
for (auto aptimal_attr:optimal_attrs.second) %属性识别与子属性分裂
{
Node* new_node = new Node();
new_node->edgeValue = aptimal_attr;%构建决策树
}
if (!best_attribute.empty()) {
auto search = map_attr.find(best_attribute);%得出精细化分类结果
}

图1 基于C4.5决策树算法的废旧物资精细化分类与处理算法逻辑示意图
本文采用真实的数据集来对分类算法的精度进行研究,该数据集来源于对我国某三线中等城市某回收厂的废旧塑料瓶统计数据.我们将本文算法与线性分类器和二次型分类器进行对比,结果如表1所示.数据集中包括透明瓶(无色、绿色、黄色以及绿色)和不透明瓶(无色、绿色、黄色以及绿色)两大类别,由于篇幅有限,此处仅呈现部分实验结果.由表1可知,本文算法的分类精度较高.

表1 算法分类精度对比
2 基于支持向量机(SVM)算法的废旧物资处理潜在规律挖掘
基于上述背景,根据反馈数据类型,提出了一种基于支持向量机(SVM)算法的废旧物资处理潜在规律挖掘算法.该算法首先对数据点进行格式化处理并选定训练集和测试集,然后为每一个训练集和测试集选定标签集并得到model,最后根据model获取目标规律.选取我国中部某三线中等城市6个月的数据为例,应用本系统进行处理和分析.首先需要对数据进行预处理,采用SVM算法将低维线性不可分的数据映射到高维线性可分,最后采用显著差异评价对分类的准确性进行评估,最终分类结果如图2所示.为了提高编程效率,快捷地寻找最佳有效的模型函数,引进核函数把样本集映射到高维空间,核心代码如下:
% 分类废旧物资的分类标签集
train_set_labels=[lableset(1:5);lableset(11:15)];
% 将第一类的6-10,第二类的16-20,做为测试集
[dataset_scale,ps]=mapminmax(test_dataset’,0,1);
dataset_scale = dataset_scale’;
xlabel(’测试集样本’,’FontSize’,12);
ylabel(’类别标签’,’FontSize’,12);
legend(’实际测试集分类’,’预测测试集分类’);
title(’测试集的实际分类和预测分类图’,’FontSize’,12);%得出预测规律
grid on;

图2 基于支持向量机(SVM)算法的废旧物资处理潜在规律挖掘效果图
3 系统设计
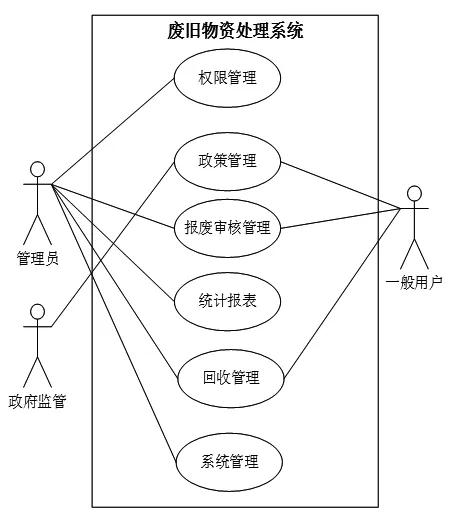
图3 废旧物资处理系统用例图
3.1 系统需求分析
在需求分析部分,对基于数据挖掘算法的废旧物资处理系统进行功能性需求分析和非功能性需求分析.图3给出了系统各个功能模块及其内在的逻辑关系,系统的非功能性需求分析需要满足这几个方面:
(1)系统应该具有初始信息,提升信息打理的便捷度.
(2)通过各种方式密切相关角色的联系,实现其交换信息的目的.
(3)系统应该有较强的并发处理能力,要保证系统的稳定性,它决定了信息的安全性.
(4)要保证数据真实可靠有效.
(5)系统应该有较强的可扩展性,便于后期的更新与维护.
(6)系统应该具有较强的抗压性,可以为多用户提供并发服务.
3.2 系统工作流模型设计
使用Java EE模块对废旧物资处理系统进行设计,可以更简便、轻易地实现系统模块.运用面向对象的方法对废旧物资处理系统软件实施封装,不但能减轻开发者的工作负担,也能提升系统的开发效率[7].
系统采用了视图模型控制器方案,用HTML页面构建视图层,HTML经由AJAX技术与内部的控制层面进行连接,并处理源于控制层的数据信息,再通过HTML页面进行显示.为了提高系统的易用性,采取jQuery技术,进一步加强用户界面的可操作性和体验感受.控制层对于业务流程的管控是通过相关模块实施的,它应用了工作流控制、权限和其他业务处理模块验证数据的合法化,模型层为这一系统方面的业务类,是经由DAO实施对数据库操控.基于上述工作,系统工作流模型示意图如图4所示.

图4 系统工作流模型示意图
3.3 系统组织模型设计
对于废旧物资处理系统,组织模型中人员组织关系的构成是通过组织元素与元素的内在联系来呈现.组织模型能够帮助系统管理人员对系统进行灵活组织和定义,使得过程模型能起到人性化、个性化的增益功能.这一系统内部的组织模型,是经由人员、角色、职务、部门、工作组共计5种个体组合而来.废旧物资处理系统组织模型逻辑示意图如图5所示.

图5 废旧物资处理系统组织模型逻辑示意图
4 系统实现与测试
基于上述工作,在vs2012环境下采用C++语言对系统分模块进行实现与测试,实现过程遵循软件工程的一般规律.本文利用的是Windows 7操作系统,采用的硬件设备 CPU为AMD公司的Ryzen 5系列处理器,主频3.4 GHz,动态加速频率为3.9 GHz,采用三级缓存工艺,容量大小为16 MB.系统运行内存为32 GB,存储空间4 TB,网络带宽15 M独享,系统对屏幕分辨率的要求为1 024*768,支持国内主流浏览器.系统实际运行界面如图6所示.

图6 系统登录界面示意图
为了进一步验证系统在某些非正常环境下的性能,基于系统性能测试工具LoadRunner,对系统的并发服务性能进行分析,并发性能测试主要包括负载和压力测试两方面,由于系统应用范围明确,负载较小,故侧重压力测试,方法如下:首先确定压力测试的上下限,然后按照规则递增的方式从下限递增到上限观察服务器性能,最后根据测试结果进行对应的优化.基于上述工作,以我国某三线中等城市标准化监控中心(服务器采用华硕公司的ESC500 G3服务器,运行Windows 7操作系统)为例进行测试,则实验结果如图7所示.测试结果表明,系统运行稳定,服务器端压力服务满足实际要求.

图7 服务器端压力服务测试结果示意图
5 结论
针对传统废旧物资处理过程中出现的诸多问题,采用C4.5决策树算法的废旧物资精细化分类与处理算法较好地解决了废旧物资的精细化分类问题,采用支持向量机(SVM)算法挖掘废旧物资处理数据潜在的规律,为后续政策的改善提供了数据依据.基于上述工作,设计并实现了一款基于数据挖掘算法的废旧物资处理系统,可以满足我国三线中等城市的相关需求,对提高我国废旧物资处理信息化水平具有积极意义.通过实际测试表明,系统运行稳定,实用性较好,抗压性等指标满足实际要求,可以较好地满足废旧物资处理对信息化的要求,具有一定的实际推广价值.
猜你喜欢
建材发展导向(2022年10期)2022-07-28 03:04:58
内蒙古科技与经济(2022年9期)2022-02-08 00:31:58
活力(2021年6期)2021-08-05 07:25:02
人大建设(2019年4期)2019-11-17 13:04:02
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
公民与法治(2016年7期)2016-05-17 04:11:03
中国资源综合利用(2016年10期)2016-01-22 08:36:16
中国资源综合利用(2016年9期)2016-01-22 08:35:16
