
多级细粒度特征融合的端到端车牌识别研究
2019-01-07 12:40张文超胡玉兰
沈阳理工大学学报 2018年5期
张文超,胡玉兰
(沈阳理工大学 信息科学与工程学院,沈阳 110159)
随着城市交通管理不断向智能化发展,汽车数量的迅速增长,车牌自动辨识技术可实现汽车身份的自动化登记和验证,可应用于泊车管控、交通梳理、公路稽察等多种情景。车牌辨识作为现代智能交通系统(ITS)的关键技术,引起了各国研究者的广泛关注[1]。文献[2]提出了一种首先通过边缘密度信息滤除背景噪声,然后依据车牌字符的空间分布进一步定位车牌的方法;该方法提高了对光照和运动位移模糊的鲁棒性,但对于适应车牌形变和误切割的灵活性较差。文献[3]利用形态学粗提取车牌位置的连通域,再通过Adaboost构造级联分类器,利用Harr-like特征筛选候选区域得到最终定位结果;但其不能应对复杂背景情况,且其分类结果对特征的选择具有较高的依赖性。文献[4]提出了利用坐标排序和连通分量进行字符切分的算法,但其未能适应汉字的不连通特性。文献[5]提出了一种基于像素点标记的字符分割方法,但其易受字符粘连和边框线条的影响,准确率较低。文献[6]提出了一种基于支持向量机(SVM)的字符辨识方法,通过提取字符的不同维度特征,构建级联的分类器对多个字符进行识别分类。传统的字符识别方法都要先对原始图片进行预处理,进行噪声滤波和图像增强,通过边缘检测结合分类的思想进行字符切分,最后训练模型对各个字符进行识别。本文通过改进Alexnet网络[7],采用卷积网络和全连接的方式集成特征提取和模式识别,将传统的预处理、车牌定位、字符分割和字符识别过程约减为输入-输出的单通道模型,减少算法流程间的衔接误差,实现端到端的车牌识别。
1 车牌定位
在建立未来无人值守的自动化智慧交通管理系统中,车牌识别将会越加重要。车牌识别技术需要能够自主检测处于监控区域内的车辆并追踪捕获其牌照内容进行后续处理。所以车牌识别首先需要以摄像机所拍摄的包含车辆元素的视频帧序列为对象进行车牌定位分析,然后进一步进行车牌字符识别。本文基于实时化目标检测算法Yolov2[8]训练车牌定位模型,并将其检测定位的车牌区域切割作为车牌字符处理系统的激励。
1.1 改进Yolov2模型训练
不同于R-CNN类算法需要先使用启发式方法得到候选区域,然后在候选区域上做分类和回归进行目标的定位和检测,Yolov2仅使用CNN网络一步预测待检测目标的位置和类别,提供车牌端到端的预测,如图1所示。
图1 车牌端到端预测
改进的车牌检测模型以Yolov2为基础,采用Darknet-19网络结构,包括19个卷积层和5个maxpooling层。Darknet-19与VGG16模型设计原则一致,主要采用3×3的卷积核,经过2×2的最大池化层后,特征维度降低2倍,同时将特征图的通道增加两倍。Yolov2的输入图片大小为416×416,经过5次最大池化层降采样后得到13×13的特征图,并以此特征图采用卷积做预测。网络输出的特征图对大物体的检测已经足够,但对于较小的待检物体则需要更细微的特征图。车牌的长宽之比近似于3∶1,且在整体检测图中所占比例较小,在深度学习网络中具有独特的结构化特征。卷积神经网络中的高层特征表现车牌的整体特征,中层特征表达车牌的局部特诊,可以通过结合不同的细粒度特征增加车牌检测的鲁棒性[9]。所以本文改进Yolov2网络结构,选取更符合车牌结构的中小型细粒度进行特征图重组,约减Darknet-19的最后5个卷积层,减少网络参数,其网络结构如图2所示。
图2中same表示卷积层保持原有特征图大小不变;Filter表示卷积核的数量;3Conv表示3个卷积层,将第1个卷积层记为第0层。由图2可知,经过特征重组后可得到13×13×1280大小的包含不同细粒度的特征输出张量。在车牌定位中改进的Yolov2网络结构借鉴了Faster R-CNN中RPN网络的先验框策略。RPN对CNN特征提取器得到的特征图进行卷积来预测每个位置的边界框及置信度[10],并且每个位置设置不同比例和标准的先验框。Yolov2将待分类图片经过32个下采样处理,获得固定大小特征图张量。车牌定位的网格划分如图3所示。
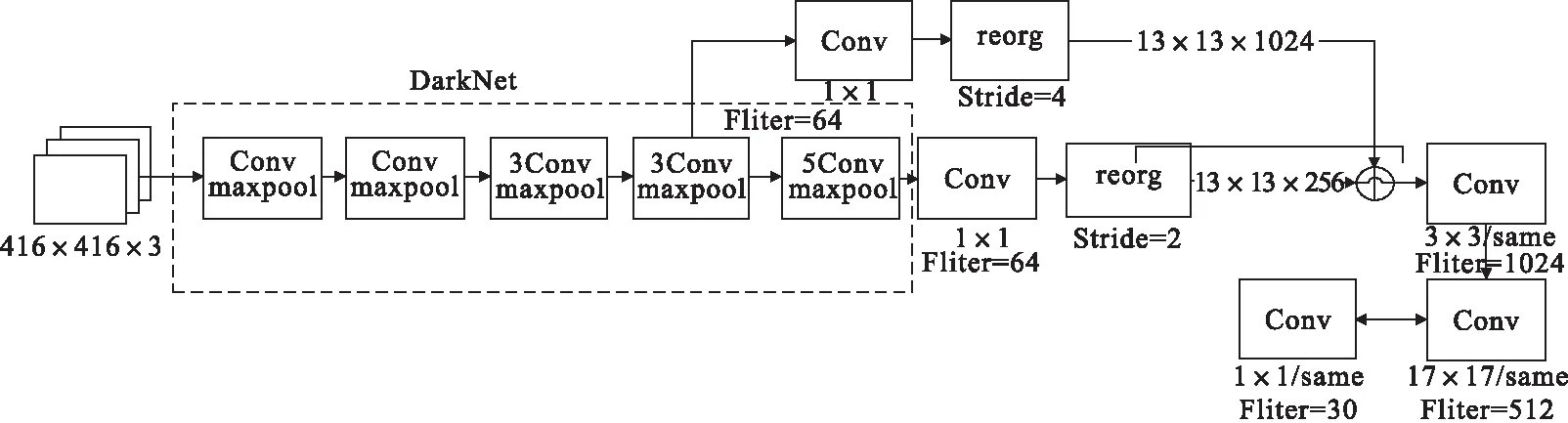
图2 车牌定位网络结构

图3 车牌定位网格划分
图3中每个单元格负责预测边界框的置信度c及边界框。边界框的大小可以由向量(bx,by,bw,bh)来表示;边界框的中心坐标(bx,by)代表相对于每个单元格左上角顶点坐标的偏移量,其大小是相对于单元格的比例。(bw,bh)是边界框的宽与高,其数值是相较于整个输入图片的宽和高大小。采用sigmoid函数处理偏移量,将边界框的中心点位置约束在当前单元格中,根据边界框预测的偏移量(tx,ty,tw,th),由式(1)~式(4)可计算出边界框相对于整张图片的位置和大小。
bx=(σ(tx)+cx)/W
(1)
by=(σ(ty)+cy)/H
(2)
bw=pwetw/W
(3)
bh=pheth/H
(4)
式中:W、H为特征图宽与高;pw和ph是先验框的宽度与高度。
1.2 候选框聚类
车牌定位采用自制的训练数据集,而Yolov2采用的是VOC 2007和VOC 2012数据集聚类得到的5个初始框。以上两个数据集中目标种类繁多,因此得到的初始框具有一定的普适性。为更好地适应车牌结构的特殊性,需要在自制的车牌数据集中重新进行聚类,选取合适的初始框。本文运用k-means++进行真实框的无监督聚类。
原始k-means算法随机选取数据集中k′个点作为聚类中心,该算法对初始选取的聚类中心点非常敏感,不同的随机种子点得到的聚类结果完全不同[11]。k-means++获取聚类中心的主体思想如下:假设已经得到前n个初始的聚类中心,当选择第n+1个聚类中心时,选择更远离当前n个聚类中心的点作为下一个中心。算法具体步骤如下:
1)随机从自制车牌数据标签中选取一个真实框边界样本作为聚类的初始中心C1;
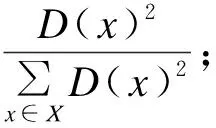
3)重复第二步直到选出共k′个聚类中心。
选出k′个聚类中心后的计算过程与k-means算法相同。因为卷积神经网络具有平移不变性,且初始框的位置被每个栅格固定,因此只需通过k-means计算出初始框的宽和高即可。Yolov2通过初始框直接预测边界框的坐标时,坐标是相对于单元格边长的比例,所以要将初始框的宽和高也转换为相对于单元格边长的比例。转换公式如下。
W=Wanchor_Box×Winput/ds
(5)
H=Hanchor_box×Hinput/ds
(6)
式中:Wanchor_Box和Hanchor_Box分别代表初始框的宽与高;Winput和Hinput分别代表输入图片的宽与高,在Yolov2中均为416;ds代表下采样倍率,其值为32。
车牌检测聚类若使用欧式距离会使较大的边界框相对于较小的边界框产生更多的损失,设置先验框的主要目的是使预测框与真实框的IOU更好,所以聚类分析时选用样本目标框与聚类中心目标框之间的IOU值作为距离指标。
d(box,centroid)=1-IOU(box,centroid)
(7)
式中:d代表距离指标;box代表样本目标框;centroid代表聚类中心目标框。由上述改进的网络结构可进行车牌的定位,并得到车牌位置的预测框,根据预测框坐标可在输入图片中利用opencv自动裁剪得到包含车牌信息的区域,并将此作为车牌字符识别的输入进行下一步的处理。
2 字符识别
在某些恶劣的复杂自然情况下,受角度、光线的影响,车牌字符的分割和识别十分困难,传统的预处理、分割、识别的方法并不能取得很好的结果,因此可采用卷积神经网络融合多任务分类进行端到端的车牌识别。
车牌识别的端到端模型借鉴Alexnet网络结构,将输入图片大小更改为30×120,并在卷积层采用3×3的卷积核,池化层采用2×2卷积核,采用Leaky ReLu激活函数。最后以Batch-Norm层替换归一化层,减少各层之间的耦合度[12];采用七个全连接层共享一组卷积层的网络结构如图4所示。
图4中c代表通道数;k代表卷积核大小;s代表卷积步长;p代表扩充数。我国的车牌由7个字符组成,第一个为省份简写汉字,其余为数字或者大写字母。我国的车牌共包含31个省份名称简写,10个阿拉伯数字,24个大写英文字母(去除掉O和I),所以每个全连接层共有65个类,将7个全连接层经过通道连接层重组后由分类层做分类。Conv6的卷积核大小为5×26,卷积步长为2×3,在最后一个卷积层之后,对每一个输入图片计算,得到一个具有位置信息的64个通道的7×21大小的特征图张量,此特征图从左至右依次与7个车牌字符信息的网络高层抽象对应,经过随机失活层后,并列连接的7个全连接层分别对应7个车牌字符的分类任务。

图4 车牌字符端到端识别模型
3 仿真结果及分析
为检测车牌定位和识别算法的有效性进行仿真实验,实验平台为Inter Core i5-7500,8GB RAM,NVIDIA GeForce GTX 1060,采用CUDA8.0加速,车牌定位模型的实验数据为自制实验数据。本文采集2500张包含肉眼可辨别车牌的自然场景中的车辆图像,其图像场景涵盖了早晨、中午和傍晚不同时间段,晴天、雾天和阴雨天不同天气环境及运动模糊等干扰情况下各种条件。车牌识别模型因需要大量的数据集,所以采用通过opencv和车牌字体自动生成的有污迹、噪声和畸变等情况的车牌。车牌定位目的是获得车牌所在区域,为车牌字符识别做准备,所以车牌定位的精度直接影响着字符识别的效果,因此采用反映定位坐标准确度的IOU指标作为车牌定位的评价标准,IOU值越大表示定位的准确度越高;车牌字符识别模型采用准确率作为评价标准。
3.1 多级细粒度融合验证
在车牌定位模型中改进了Yolov2模型,重组了特征图,融合多级细粒度特征,以适应车牌在输入图片中的结构化特征。为验证其有效性,以上述自制数据集作为实验数据,比较Yolov2模型、Yolov2模型与不同特征图重组、及FAST RCNN所训练的检测器效果如图5所示,训练时为避免过拟合及提升速度,选用动量常数为0.9,学习率为动态衰减,初始值为0.001,衰减步长为10000,衰减率为0.1,批大小为10,共迭代10次,批迭代次数为5000,框架为Darknet。
随着神经网络深度不断增加,特征图的细粒度大小也不断递增,更能反映全局信息。重组层分别将Darknet中的第16、第10和第6层包含不同细粒度的特征图进行重组。从图5中可以看出,将Darknet-19中的第10层和第16层输出的特征图利用类似残差网络的短路连接重组后的平均IOU值均高于其它策略,相对于Yolov2模型由0.81增长到0.83。
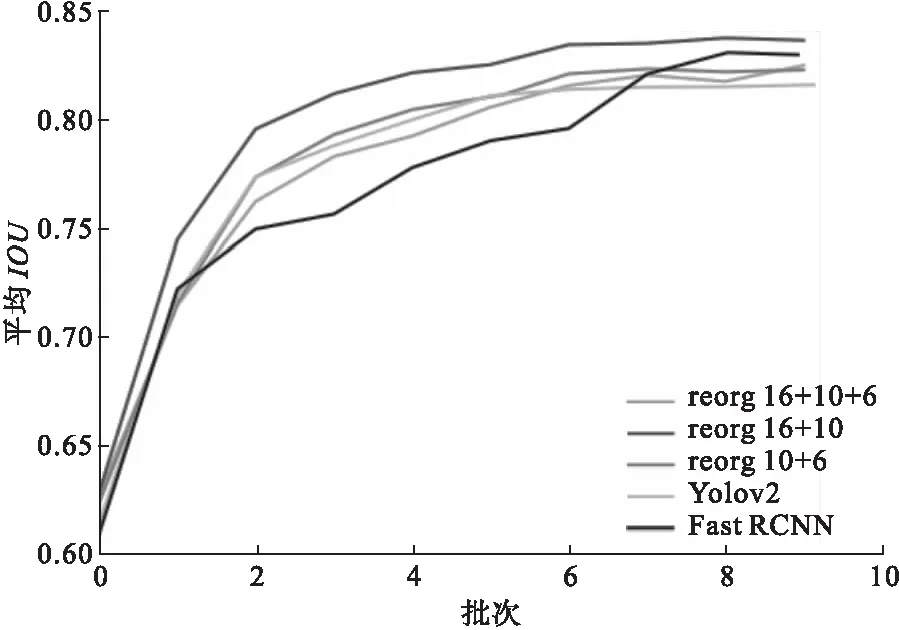
图5 检测器效果对比
网络各参数的收敛散点如图6所示。
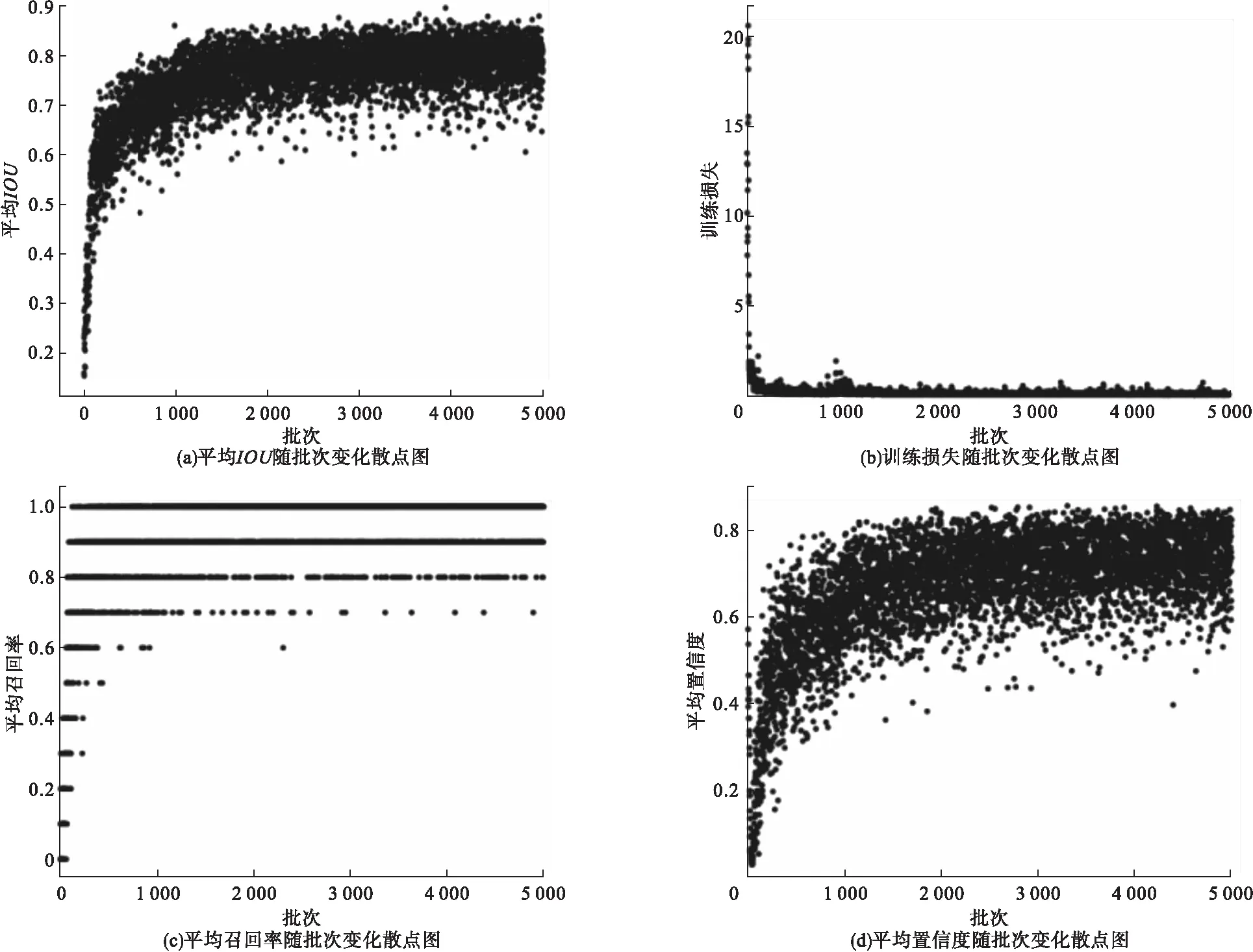
图6 网络训练参数收敛散点图
图6中的四个图反映了平均IOU、训练损失、平均召回率和物体真实检测的平均置信度随着迭代次数的变化。从图6中可以看出,经过5000次的批量迭代,各参数的变化已趋于稳定,其中平均IOU稳定在0.83;平均召回率逐渐趋近于1;损失值下降至0.05;物体真实检测的平均置信度逐渐收敛于0.82;各网络参数的收敛指数说明网络训练的结果较为理想。
3.2 聚类初始候选框验证
为验证使用k-means++聚类初始候选框的效果,对包含车牌信息的车辆数据集的真实框进行聚类,选用3.1节得到的改进后的网络结构,分别选取k′=[3,4,5,6]聚类,得到相应数目的初始框参数,并对应修改网络模型的配置文件,保证其它条件不变,分别训练网络得到k′个初始框的宽Wk和高Hk,如表1所示。
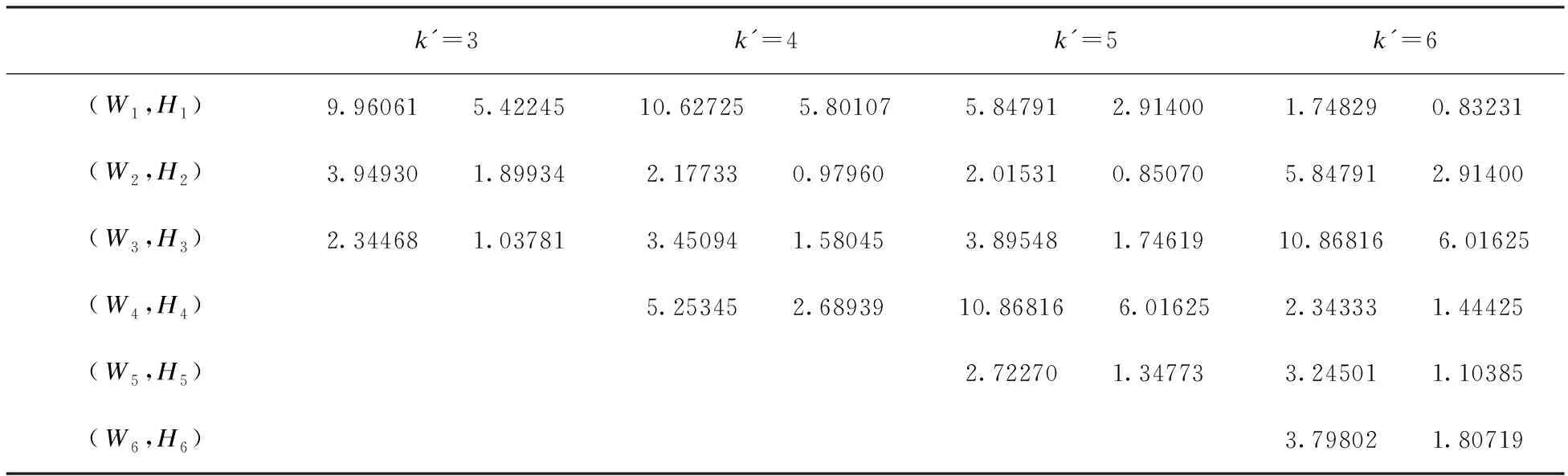
表1 车牌初始框宽和高
图7为不同聚类候选框IOU对比。
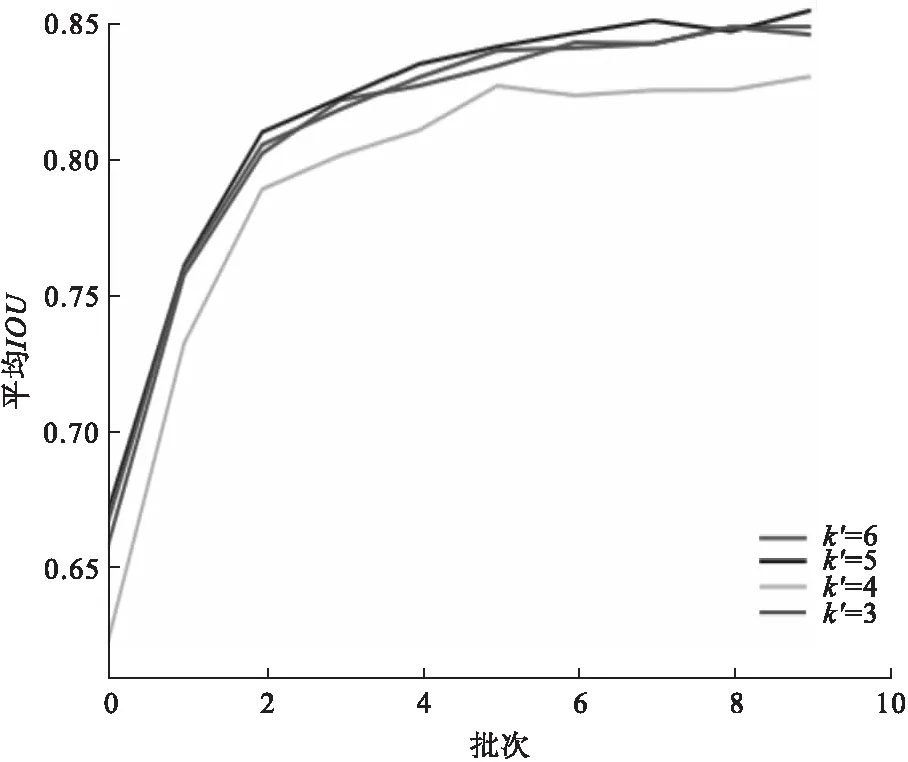
图7 不同聚类候选框IOU对比
由图7可知,当k′=5时,平均IOU和召回率可得到明显改善,相比3.1节平均IOU由0.83增长至0.85,因此选取5个初始框,其真实框聚类效果如图8所示。
图8的横轴、纵轴分别代表训练数据集中目标框的宽、高。从图8中可以看出训练集中车辆目标框的宽与高值近似,且小目标居多。
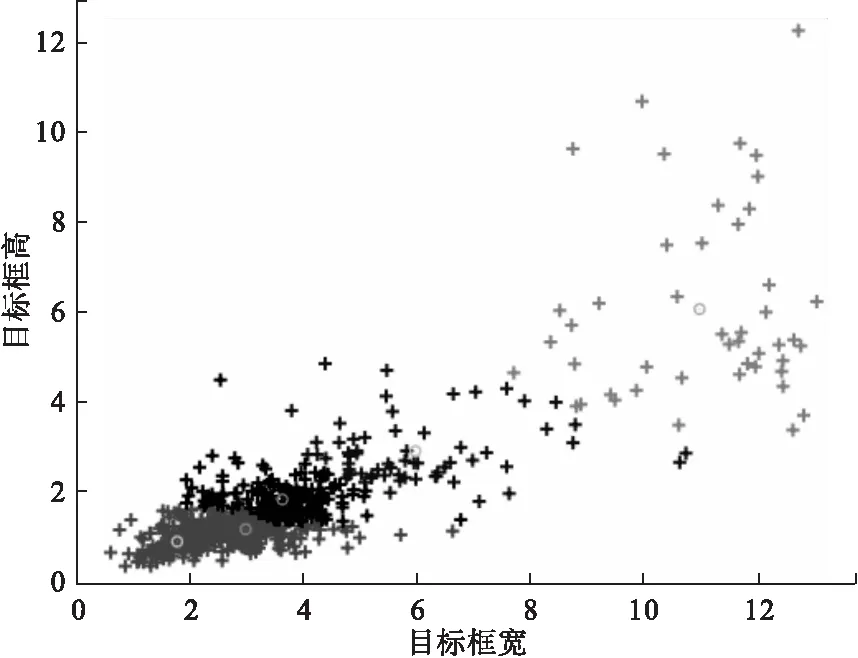
图8 k′=5时真实框聚类效果
3.3 车牌识别模型验证
端到端的车牌识别模型训练共使用了50万张图片,采用分步策略,批大小为64,将所有数据迭代10次。同时运用Adam优化梯度下降,学习率为动态衰减,初始值为0.0005,步长为5000,衰减因子为0.9,框架为mxnet;保证其它参数不变,与其它具有代表性的车牌识别方法进行比较,验证本文识别算法的有效性,结果见表2。
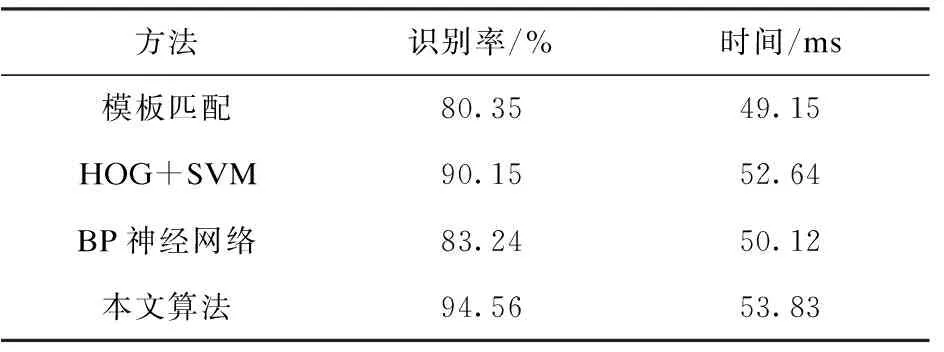
表2 算法识别效果比较
从表2可以看出,模板匹配和BP神经网络虽然用时较少,但其识别率相对于HOG+SVM较低;BP神经网络需人工选择特征,其识别效率可随网络深度的增加而提高,但其时间也会随着网络参数的增多而增加。本文算法相比较于其它算法在时间上略有增加,但识别率提升明显,适用于对识别精度要求较高的应用场景。
4 结论
针对传统的车牌识别方法具有较大的流程化误差,本文提出了定位-识别通道化模型,实现了端到端的车牌识别。在定位模型的构建过程中融合更符合车牌结构的局部特征图和初始化候选框来提高定位精度,在识别模型中共享卷积神经网络,实现字符的多任务分类,降低了对复杂背景环境敏感度;整体的模型效果良好,具有较高的识别率和可靠性。
猜你喜欢
红外技术(2022年11期)2022-11-25
安阳工学院学报(2020年2期)2020-06-05
电子制作(2019年12期)2019-07-16
现代电子技术(2018年1期)2018-01-20
电脑知识与技术(2017年26期)2017-11-20
小猕猴智力画刊(2017年5期)2017-05-25
电子制作(2017年22期)2017-02-02
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
科学与财富(2016年28期)2016-10-14
