
数据平面和控制平面相分离的网络入侵检测系统
2018-12-28 06:48王美荣
安庆师范大学学报(自然科学版) 2018年4期
王美荣
(安徽新华学院信息工程学院,安徽合肥230088)
公共服务、网上银行以及专门用于防御的系统等往往是攻击者的入侵目标[1],准确地检测恶意入侵尤为重要[2]。网络入侵检测系统是一种硬件/软件,用于在入侵者尝试入侵系统时发出警报。目前入侵检测方法主要有误用和异常检测[3]。误用检测系统为了分析数据流中的签名和信息,需要对数据包进行深度检查。该方法虽然有效,但受到一些限制,例如恶意数据包的签名可能过时或打开每个数据包会带来庞大的计算开销。数据挖掘的方法被广泛用于入侵检测[4-9],本文结合单分类支持向量机和软间隔支持向量机的优点,提出了一种基于增强支持向量机的分类方法。
1 系统架构及原理
本网络入侵检测系统结构如图1所示。系统主要由交换机、数据流分析模块以及恶意数据流数据库3个部分组成。交换机负责将互联网的数据包通过外部接口路由到内部的局域网。数据流分析模块负责周期性地收集数据流信息,并对其进行分析以得到统计信息(如表1所示)。恶意数据流数据库是用来储存已经经过分类的数据流特征以及系统的相关参数。数据流分析模块采用可配置的数据挖掘算法完成数据流的分类,本文选择了支持向量机作为分类算法。该模块加载利用支持向量机算法训练好的模型,结合数据流的统计信息,以此判断数据流是否属于恶意入侵数据流。结合分类结果,控制器可以决定如何处理数据流,例如,控制器可以立即阻止恶意数据流以防止可能的进一步感染,或将流量复制到检查器以进行分析。

图1 系统架构

表1 数据流统计信息
本系统工作原理如下:当数据流经过交换机时,如果交换机没有任何关于数据流的路由规则,它会向控制器请求转发规则。控制器获取该数据流的相关信息并计算路由规则,然后将规则发送回交换机,交换机再转发或管理相应的数据包。数据流的特征元组定义为源IP地址、目的IP地址、源TCP/UDP端口、目的TCP/UDP端口、协议类型,其特征都从该数据流中第一个数据包的IP、TCP/UDP头部进行抽取。交换机使用给定的规则检测数据流,对于每一个数据流的第一个数据包,交换机都会抽取该数据流的特征。经过一段时间之后,控制器会向交换机发送统计信息的请求,以便收集经过交换机的数据流统计信息(数据包数量、字节数、数据流的长度)。控制器会依据交换机发送的统计信息计算字节速率、数据包速率以及数据包平均长度,然后将每个数据流分类为恶意入侵数据流或正常数据流。
2 增强支持向量机
与正常数据流相比,恶意入侵数据流的数量相对较少。单分类支持向量机中的单个分类器不一定能最大化原点和离群点之间的距离。针对此缺点,通过修改软间隔支持向量机提出了一种能实现具有单分类支持向量机优势的增强支持向量机。增强支持向量机不仅比软间隔支持向量机具有更高的检测率和处理性能,而且具有单分类支持向量机无监督学习的特征。将软间隔支持向量机中的偏差项删除,可以得到以下的问题:

其中,w是可调的权重向量,b是偏差项,ξik是误差项,C是误差项的权重,xi、yi分别是训练数据集的横、纵坐标,‖w‖2=wTxi+b。在软间隔支持向量机中,偏差项通常与原点和超平面之间的距离有关。随着偏差项的减少,超平面会逼近单分类支持向量机分类器的原点。通过观察软间隔支持向量机和单分类支持向量机,可以得到以下的近似关系:

其中,l是数据集样本数量,v是异常值的权重参数,p是类似w的权重。在(2)式中,C用来调整训练误差以在原点和超平面之间获得最大距离。在单分类支持向量机中,为了使原点和超平面之间的距离最大化,参数‖w‖必须减小并且参数ρ必须增大与离群点有关,因此也必须减少。因此,可以通过控制软间隔支持向量机的参数C来将每个项近似为相似的值。在(3)式中,ρ是用于使原点和超平面之间的边缘最大化的参数,我们不需要最大化ρ值,因为异常数据可以通过靠近原点的超平面进行分类,可以把ρ值看作是一个很小的数字,最终得到一个增强支持向量机如下:
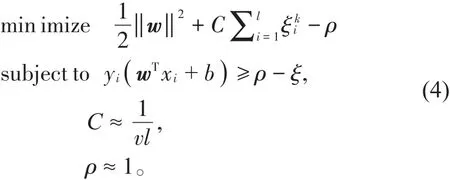
3 实验结果
使用图1所示的架构来评估本文算法的性能。为了调整和测试流量分析器,通过模拟网络的行为来生成数据流,以此作为实验的数据集。数据流中既包含恶意软件产生的恶意入侵数据流,也有正常数据流。
3.1 恶意数据流
实验数据集中的恶意入侵数据流是由表2列出的恶意软件所产生。

表2 产生恶意数据流的软件
3.2 正常数据流
正常数据流是实验室网络捕获的所有数据流。为了确保所捕获的数据流中不含有恶意数据流,在交换机上进行了相关配置,以便在特定物理端口上转发所有流量。将这个端口连接到一台配置了虚拟交换机的电脑上,该交换机将来自网卡的流量转发到与路由器相连的网卡;然后,将流量复制到与探测器相连的本地端口。
3.3 属性(统计信息)选择
性能分析的第一步是找出影响分类结果的相关属性,即统计信息。现有的研究已经提出了不同的特征排序和选择技术,本文使用信息增益(Information Gain,IG)作为选择属性的指标。信息增益的计算公式如下所示:
I G=H(Y ) -H( Y X ) =H(X ) -H( X Y),(5)其中,H( Y )是指属性Y的信息熵,H( Y X)是在X条件下Y的熵。观察X后获得的关于Y的信息等于观察Y后获得的关于X的信息,即H( Y X)=H( X Y)。通过信息增益,可以获得每个属性所蕴含的信息,在对这些属性进行排序后就可以得知属性的重要性。各种属性的信息增益均值如表3所示。本文系统所使用的属性(统计信息)以粗体显示,它们具有较高的平均值,因此选择这些属性(统计信息)进行入侵检测能提高算法的准确性和效率。

表3 各种统计信息的信息增益
3.4 分类性能
采用真阳性(将数据流分类给正确的类别)和假阳性(将数据流分类到错误的类别)两个指标将分类结果与实际情况进行比较,以评估分类器的性能。从数据集中提取不同百分比(33%和50%)作为训练样本来进行支持向量机训练。将本文提出的入侵检测系统与基于单分类支持向量机的系统、基于贝叶斯的系统进行比较,结果如表4所示。从表4可知,增强支持向量机分类器都可以获得超过98%的真阳性。
4 结 论
数据挖掘方法在解决网络安全问题(包括网络入侵检测)方面凸显了其重要性。为了准确高效地区分恶意入侵数据流和正常数据流,本文提出了一种基于增强支持向量机的入侵检测系统。本系统交换机负责收集从网络流中推断信息所需的特征,控制器包含一个可配置的机器学习模块,从交换机提取的功能开始,通过计算完成所需功能的数量,并确定数据流是否受到恶意软件的影响。本文提出的方案旨在阻止网络内部的恶意数据流泛滥,该系统将数据平面与控制平面分离,具有高扩展性。使用真实的数据流验证了本文系统是有效性。实验性能评估显示,本文的系统与单分类支持向量机以及贝叶斯方法相比具有一定的优越性。
猜你喜欢
计算机应用与软件(2022年4期)2022-06-24
网络安全与数据管理(2022年3期)2022-05-23
计算机应用与软件(2022年2期)2022-02-19
中北大学学报(自然科学版)(2021年5期)2021-11-15
汽车维修与保养(2020年10期)2021-01-22
数码世界(2020年11期)2020-11-23
汽车维修与保养(2020年11期)2020-06-09
计算机技术与发展(2020年5期)2020-05-22
网络安全和信息化(2019年7期)2019-07-10
电子制作(2019年24期)2019-02-23
