随机森林模型在重症手足口病预测中的应用价值
2018-12-12 08:50冯慧芬易佳音
郑州大学学报(医学版) 2018年6期
王 斌,冯慧芬,黄 平,赵 敬,易佳音
1)郑州大学第五附属医院消化内科 郑州450052 2)郑州大学第五附属医院感染科 郑州450052
手足口病(hand-foot-mouth disease,HFMD)是一种好发于5岁以下儿童的常见肠道传染病,以肠道病毒71型(EV71)和柯萨奇A组16型(CoxA16)多见[1]。HFMD在我国北方发病高峰主要集中在6月,而南方为0.5 a一次,集中在5月和9~10月[2]。大多数HFMD患儿发病后表现轻微,但临床上有极少数容易发展为重症,伴随各种严重并发症,如病毒性脑炎,甚至心肺衰竭等[3]。随机森林是机器学习中的一种集成学习算法,其基本单元为决策树,通过集成学习独立地训练一些相对弱的学习模型,最后整合结果,进而实现整体预测[4]。集成算法相比于其他算法,属于近年来发展起来的比较强大的算法,大致分为两大流派,Boosting技术和Bagging技术。Boosting技术的特点是不同弱的学习器之间存在依赖关系,而Bagging技术则不存在依赖关系,可以实现各个弱学习器之间的并行拟合。随机森林算法是在Bagging技术的基础上进化而来的,而与之类似的梯度提升树算法则起源于Boosting技术[5]。两种新型算法在近年来的机器学习中占有重要的地位,都具有很高的预测精度和许多普通算法不可比拟的优势。本研究旨在通过回顾性分析临床病例资料,来探究随机森林模型在预测和评估重症HFMD方面的应用价值。
1 资料与方法
1.1临床资料收集2016年8月至2017年11月郑州大学附属儿童医院感染科诊治的HFMD患儿病例资料,所有纳入病例的确诊均参考文献[6]的诊断标准。纳入标准:①初次发病的HFMD患儿,根据出院诊断结果来判定属于轻症或重症,对于入院时诊断为轻症的患儿,其进展为重症的时间限定为1周内。②从发病到就诊病程不超过半个月。排除标准:①病例资料不完整,缺失必要的病史信息及实验室检查结果。②入院前存在多种基础疾病或除HFMD外的其他传染病。③来医院诊治时,已经处于HFMD恢复期。
1.2数据收集通过复习文献及查询相关资料,结合病例资料,设计一个标准化的问卷调查表,用Epi-
Data 3.1对所有符合条件的HFMD患儿病例资料进行手动提取及录入,最后导出到Excel表格中,进行数据的分析和处理。
1.3统计学处理数据的处理和分析使用R 3.4.4软件。用到的主要R包有 “rattle”“stats”“randomForest”“ggplot2”“ROCR”等,其中“rattle”包是一个可视化的热门数据挖掘包,其使用时需先安装“GTK+”“GGobi”软件[7]。首先将Excel数据导入到R软件,对连续性变量进行重新编码。对数据进行相关质量分析,去除重复和缺失个案,同时绘制箱型图,去除离群值。轻症组、重症组年龄、发病时间的比较采用两独立样本的t检验,其他基本信息的比较采用χ2检验。将数据打乱,重新分割为70%的训练样本和30%的验证样本。构建随机森林模型和logistic回归模型;用验证样本进行预测,绘制ROC曲线,分析模型预测性能。当AUC<0.7时,诊断价值较低;0.7~0.9时,诊断价值为中等;>0.9时具有较高诊断价值。同时输出错分矩阵比较两者的整体预测精确度。检验水准α=0.05。
2 结果
2.1纳入病例的基本信息共计纳入1 352例病例,其中轻症组760例,年龄(2.91±1.09)岁,发病时间(2.37±1.92) d;重症组592例,年龄(2.98±1.05)岁,发病时间(2.84±1.83) d,两组发病时间和性别构成比较,差异均无统计学意义。纳入病例的基本信息见表1。
2.2模型参数随机森林模型的相关模型参数设置如下:随机种子数为42,要构建的模型数量为500个,而每一棵树的节点分支处所选择的变量个数为3。对于logistic模型,使用逐步回归法和主效应建模参数。
2.3模型预测性能评价输出随机森林模型的预测变量重要性,见图1,其中一个图像为根据精确率平均减少值计算得出的重要值所绘制;另一个图像为根据节点不纯度(用基尼系数测量)减少平均值计算得出的重要值所绘制,其余两个则是分别从轻症和重症两个方面判断得出。绘制随机森林模型各
类别误判率图像,见图2,分别代表了重症的误判率、轻症的误判率以及根据袋外数据计算而得到的误判率。
使用相关函数,计算两个模型的总体预测正确率,其中随机森林模型为82.5%,logistic模型为77.3%。绘制ROC曲线,见图3,随机森林模型的AUC为0.87,敏感度65.9%,特异度94.5%;而logistic模型的AUC为0.75,敏感度67.3%,特异度83.7%。两种模型的提升图、精确率与召回率图分别见图4、5,从这些模型评估图中可以看出随机森林模型优于logistic模型。

表1 纳入病例的基本信息 例(%)
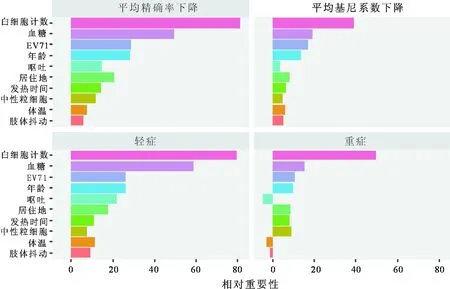
图1 随机森林模型的预测变量重要性
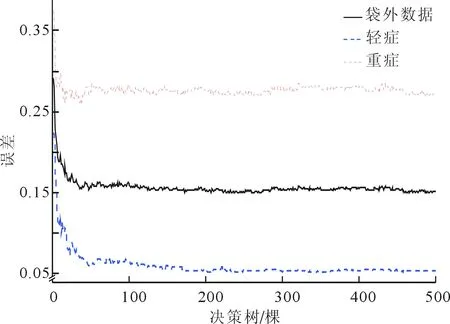
图2 随机森林模型各类别误判率
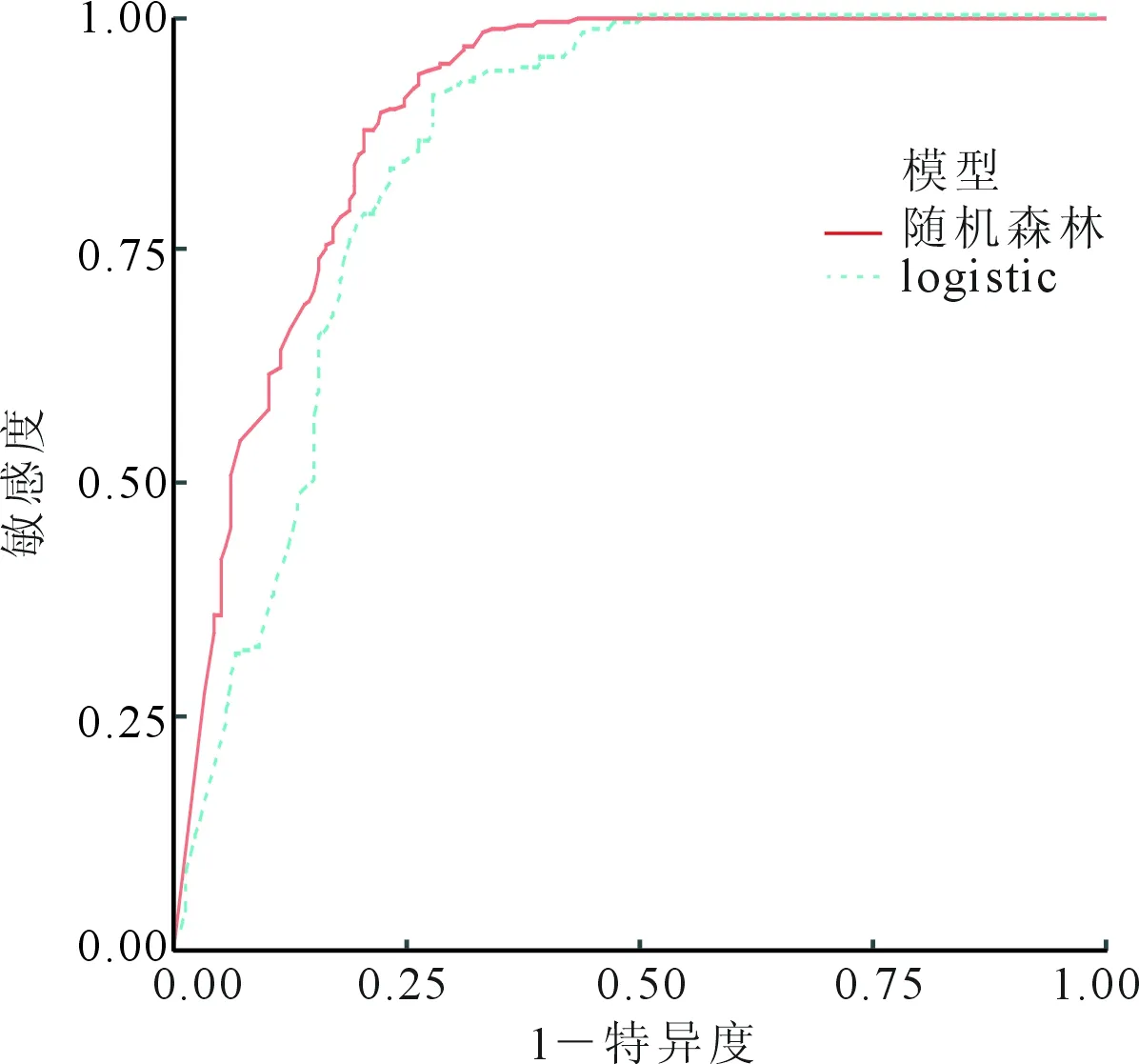
图3 两种模型的ROC曲线图
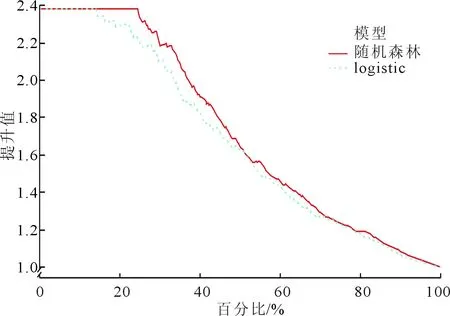
图4 两种模型的提升图
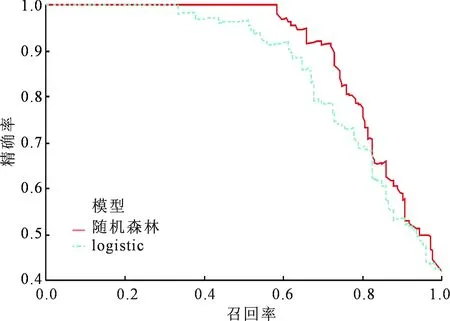
图5 两种模型的精确率与召回率
3 讨论
本研究通过回顾性分析HFMD的临床病例资料,使用较新的随机森林算法来构建一个可以用于重症HFMD预测的机器学习模型。既往在预测重症HFMD及探究预测变量方面,国内较多研究[8-10]都采用的是logistic模型。为了客观地对比两种模型优劣,本研究同时完成随机森林和logistic两个模型的构建,并通过多种性能指标,结合可视化图形来实现多方面对比。预测正确率是评估模型性能最常用的指标,通常追求更高的预测正确率来保证模型有较高的判断正确力,但是这个指标有一定的局限性,容易受样本比例的影响。虽然本研究中轻症和重症的比例差距不是很大,但是作者可能更关注样本中例数较少的分类,来评估模型对重症的预测能力,即常用的敏感度、特异度等指标。在对比中可看到随机森林模型的这两项指标也高于logistic模型,但值得注意的是随机森林模型的敏感度不到70%,模型仍有待改进优化参数。由于样本中轻症多于重症例数,因此轻症属于正性样本,重症属于负性样本,即敏感度为模型识别轻症的能力,特异度则为识别重症的能力。而临床中需要的是能正确识别出重症病例,因此作者对两个模型的特异度比较关注,而敏感度次之,因此随机森林模型可以更好地识别出重症。类似的,作者使用AUC来评估两个模型的诊断价值,此外还使用了其他指标,在对比中也可以发现,随机森林模型均优于传统logistic模型。通常随机森林模型有以下优点:①处理大样本数据方面有优势。②对缺失数据特征的不敏感。③可以克服过度拟合的问题[11]。Liu等[12]构建的随机森林模型,其预测精确性达到91.6%,AUC为0.916,同时论证了随机森林模型比儿科重症监护病房最常用的疾病严重程度评分系统,在识别临床重症HFMD方面更有效,再次证明了该模型的优越性。
通过随机森林模型筛选的预测变量,其重要性处于前3位的依次为白细胞计数、血糖和EV71。林克武等[13]研究认为血糖增高具有提示HFMD合并脑炎的价值,这与本研究结论一致。目前多认为,促炎因子参与了HFMD重症化的过程[14],当患儿合并有脑干等损伤时,可引起机体的一系列功能紊乱[15],进而导致外周血中白细胞及血糖的增高[16],但其具体机制仍待后续深入研究。相比于Liu等[12]构建的随机模型,该研究加入了病原学中EV71结果,可以看到其居预测变量重要性第3位。目前认为EV71是导致所有重症HFMD的重要原因,因此EV71变量的重要性比较符合临床实际,此外,提取的其他重要预测变量均与既往研究[17-18]较为一致。
本研究尚有以下不足:①研究只筛选了一些较为常见的预测变量来对模型进行拟合,由于样本量和预测变量的限制,对模型整体拟合效果有一定的影响,表现为构建的模型在敏感度方面较低,因此后续研究在筛选变量方面应注意兼顾模型的敏感度和特异度。②虽然在建模前进行了相关数据预处理,但是使用的异常值检查方法较为单一,相应地降低了模型预测性能。③在模型性能构建方面,涉及很多参数调整,本研究仅使用了相应函数的默认设置,尚未进行更深入的参数调试。
综上所述,随机森林模型在预测重症HFMD方面具有较大价值,其模型预测性能表现较佳。随着更多复杂算法的开发,同时结合流行病学大样本量数据的分析,更优秀的预测模型及其他一些潜在的预测指标有望被发现,从而为临床指南的修订及医学决策提供更充足的参考依据。
猜你喜欢
基层中医药(2022年4期)2022-07-22
环球时报(2022-04-15)2022-04-15
中华骨与关节外科杂志(2021年8期)2021-11-30
西安邮电大学学报(2021年6期)2021-05-10
中华养生保健(2020年8期)2021-01-14
海南金融(2021年12期)2021-01-06
中国医院院长(2020年14期)2020-01-03
中国社区医师(2019年8期)2019-09-07
医学信息(2017年5期)2017-03-18
医学研究杂志(2015年9期)2015-07-01