
临近最优主动学习的藏语语音识别方法研究
2018-11-17 02:50李要嫱徐晓娜吴立成
计算机工程与应用 2018年22期
赵 悦,李要嫱,徐晓娜,吴立成
中央民族大学 信息工程学院,北京 100081
1 引言
藏语是一种非常重要的中国少数民族语种,在我国使用藏语的人数500多万,其中主要分布在我国的西藏自治区以及青海、甘肃、四川和云南等藏族聚集区。藏语语音识别技术的发展,不仅可以有效地解决藏族地区和我国其他区域之间的语言障碍问题,促进民族间的相互交流,而且可以推动藏区经济、科技、文化等领域的发展,促进民族团结统一,增强民族凝聚力。
在语音识别领域,语音识别算法(如隐马尔科夫模型和深度神经网络等)采用监督式学习方式建立语音识别模型[1]。为了建立高准确的语音识别模型,这种学习方式需要大量的带标注的语音语料,而标注语音语料是一件非常费时费力的工作。通常以词为语音识别单位的标注工作所花费的时间是实际音频语句时间的10倍,以音素为识别单位的语音标注工作将会达到语音语句时间长度的400倍[2]。藏语作为小语种,其语音标注专家十分匮乏,人工标注语音语料更加耗时耗力。目前,带标注的藏语连续语音数据量还远远不能满足实际语音识别系统建模的需要[3-5]。
然而,在大量未标记的数据集中,有许多较为相似的信息,如果能够选择较少的数据给语音专家去标注,那么同样会获得具有较高精度的识别器,这便是主动学习的原理。
主动学习的过程如图1所示,其基于少量的带标注训练样本建立初始识别器,在每次迭代学习中,根据目标函数的设定,在候选样本集中选择最具有价值的样本交给用户标记,然后将标记后的样本加入到当前训练集中,更新识别器,直到识别器达到满意的精度[6]。主动学习通常被用来减少人工标注的数据量,解决标注工作繁琐冗长的问题。它可以从大量未标注的数据中挑选一些具有价值的样本交给用户进行标注,以便利用少量高质量的训练样本构建与大数据量训练方式一样精准的识别模型[7]。

图1 主动学习过程
本文针对藏语拉萨话连续语音识别目标,构造了语音语料的评价函数和语料批量选择的目标函数,通过临近最优选择算法,实现了语音数据的挑选。实验结果显示,通过使用主动学习方法挑选的少量样本进行建模,所构建的语音识别模型识别精度可以达到与使用全部数据进行建模的精度。本文提出的基于主动学习的藏语语音语料选择方法,可以加快藏语连续语音识别工作,为识别建模提供充分、可信的训练数据。
2 语料评价函数构造
主动学习方法首先通过样本评价函数对候选数据集中的样本进行打分,因此,对已标注的样本集进行了数据统计,通过当前的数据分布情况和语音识别目标,构造藏语拉萨话语音语料的评价函数。
本文对现有训练数据集中单音素出现的频数进行了统计,如图2所示。将出现频数低于50次的音素定义为稀疏音素。本文稀疏音素频数分布图如图3所示。
考虑到构建的训练数据集应该尽量涵盖全部藏语拉萨话音素,并且各个音素数据分布要均衡,同时结合提高语音识别准确率的目标,在构造主动学习的样本评价函数时,主要考虑以下三个因素:
(1)句子中识别音子的覆盖度Xk,即语音句子中包含识别音子的个数;

图2 单音素频数分布图
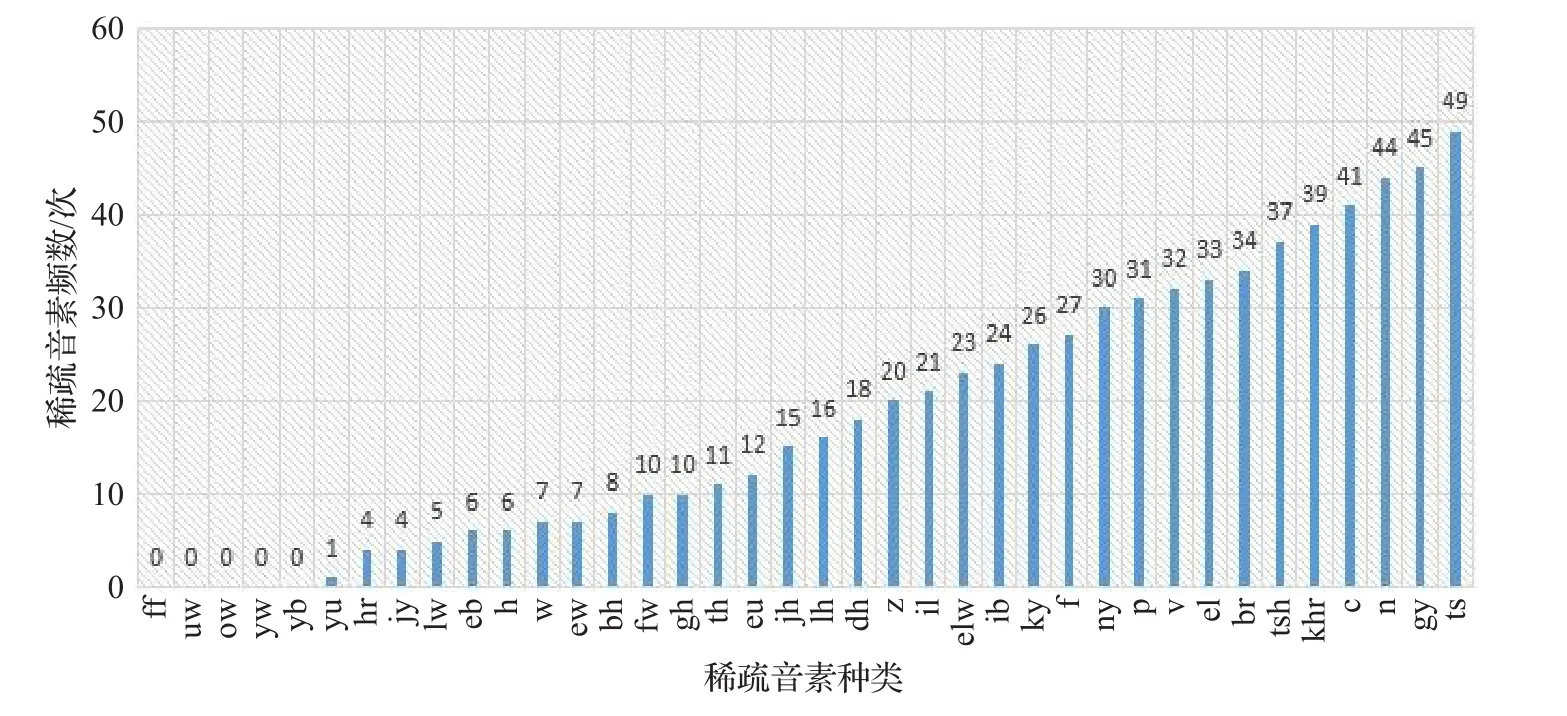
图3 稀疏音素频数分布图
(2)句子中稀疏音子的覆盖度Yk,即语音句子中包含稀疏音子的个数;
(3)句子对于语音识别精度提高的贡献度Zk,即每个语音句子加入到识别器中,语音识别精度的提高程度。
基于以上三个评价因素,语音语料的评价函数可以写成:


3 临近最优语料子集的目标函数构造
大多数的主动学习方法都是非批量的方法,它们一次只选择一个最有价值的样本去标注[8]。因为非批量的主动学习方法对每一个选出的数据都要进行识别器的重新训练,所以训练过程缓慢,并且不能进行多专家在线同时标注。
相反,批量主动学习方法允许一次选择多个未标注的样本[9-11]。但是如果只是把单一样本选择策略应用到批量主动学习选择样本过程中效果并不好,因为所选样本具有高度的信息相似性,例如N-best方法。为了选择能够代表整体数据集的全局最优子集样本,作者在文献[12]中利用submodular函数理论优化了样本选择问题。基于该工作,本文研究了临近最优语音样本集合的目标函数,并证明了该函数具有submodularity性质,这使得主动学习器可以利用greedy算法来获得临近最优的语料子集。
批量主动学习的一般过程是:基于少量的已标注训练样本建立初始识别器,在每次迭代学习中,根据目标函数的设定,在候选样本集中选择多个最具有价值的样本交给用户标注,然后将这些标注后的样本加入到当前的训练集中,更新识别器,直到识别器达到满意的精度。在每次迭代学习过程中,批量主动学习的目的就是从未标记的样本中选择一个最优子集S*,S*可以通过式(2)获得:

其中,O(S)为目标函数,S为样本数是N的子集。为得到O(S)的最优解,需要将O(S)构造为submodular函数,利用其函数性质,就可获得其临近最优解,也就是临近最优样本数据集S*。
一个函数是submodular函数的充分必要条件是:如果有且仅有A⊂B⊆V并且s∈VB,那么如果函数满足“回报递减(diminishing returns)”性质:


第2章阐述了单一样本评价函数基于三个考虑因素,在批量选择样本时,同样依据这三个评价因素,希望每次迭代能够选择出N个未标注样本,它们构成的样本子集涵盖最多的音素个数、最多的稀疏音子个数和具有最大的期望识别误差减少。因此,对于式(2)中的目标函数O(S),构造如下公式:

其中,X(S)代表样本集中音素出现的个数;Y(S)表示稀疏音子出现的次数;Z(S)表示样本集的期望识别误差减少;α、β、γ同式(1)中的定义一样,仍然分别是三个因素的预设系数。
下面来推导O(S)满足submodular函数的充分必要条件。让A⊂B⊆U且{s}⊂UB,则:

证明过程的第二步中,X(A⋃{s})-X(A)等于{s}中新出现的音素个数或等于0;Y(A⋃{s})-Y(A)等于{s}中稀疏音子出现次数;根据文献[6]中的证明,期望误差减少函数 Z(A⋃{s})-Z(A)等于为当前分类器在未标注数据集上的分类信息熵,即期望误差。同理,也可以推导出:


因为A⊂B⊆U,所以由式(7)得:

即
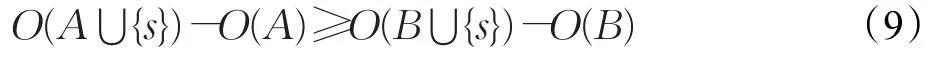
从而,O(⋅)满足式(3),其是submodular函数。
4 基于临近最优批量主动学习的藏语语音语料选择算法
正如文献[16]所示,如果目标函数为submodular函数,那么由S={}(此时O(S)=0)开始,使用greedy算法,迭代地选择未标注样本并加入到S中,直到有N个样本被加入为止,那么此时获得的集合S就是临近最优集合。根据第3章构造的语料子集目标函数公式(4),藏语语音语料选择算法描述如下。
算法1临近最优批量主动学习算法
1.随机从未标注样本集U中选择少量样本,为每个样本标注文本内容,形成初始训练数据集L;
2.基于L训练语音识别器C;
3.循环以下各步骤直到识别器精度满足设定的要求或选择了全部未标注样本;
3.1 greedy算法发现S;
3.2 用户标注S,并将标注后的S加入到L中;
3.3 重新训练识别器C,在测试集上获得C的识别精度。
算法2 greedy算法发现S 1.S={};
2.While|S|≤N
2.1 基于当前识别器C*(初始C*=C)预估数据集U(L⋃S)中每一个未标注样本的语音内容,即用音素表征的语音内容;
2.2 根据式(1)计算每一个未标注样本的Xk、Yk;
2.3 将每一个预标注的样本分别加入预训练集L*=,训练识别器Ck,得到期望误差ek;
2.4 对数据集U(L⋃S)中的每一个样本根据式(1)进行打分,得到sk;
2.5 选择sk得分最高的未标注样本加入S,即S=S+{xk};
2.6 用sk得分最高的预标注样本对应的识别器Ck替换 C*,即 C*=Ck
3.End
5 实验结果分析
本文使用自建的藏语拉萨话连续语音数据集对提出的语音语料选择方法进行评估。实验中,语料665句,选取其中57句作为测试数据,剩余608句中的564句作为主动学习的初始训练集,44句作为未标注语料。实验测得,用608句作为全部训练数据,句子识别率为75.07%。
在主动学习中,564句初始训练集的识别率为65.07%,根据临近最优主动学习算法进行实验,每次在未标注数据集中挑选N=2条语音语句添加到初始训练集中,并且式(1)和式(4)中的 α、β、γ 参数均设置为1。利用HTK进行识别模型建模,当进行8次迭代选择了16条语句后,识别器的识别率就达到75.73%。实验结果如表1所示,其折线图如图4所示。

表1 三种方法的语音识别率实验数据比较 %
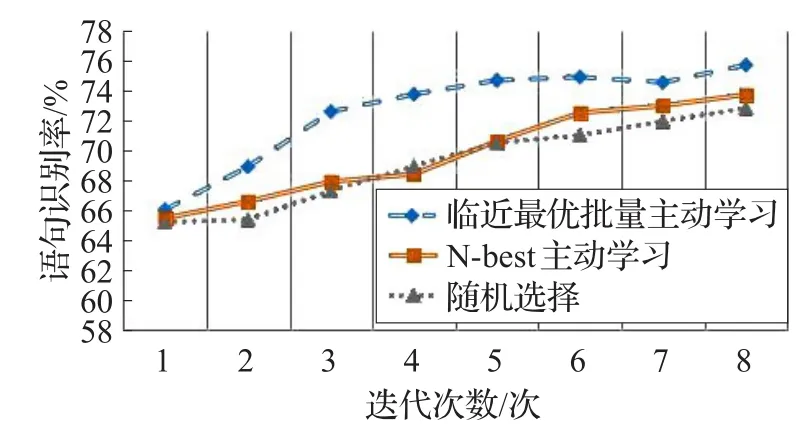
图4 三种方法的语音识别率折线图比较
正如实验结果显示,第8次迭代学习后,临近最优批量主动学习方法选择大约1/3的未标注语料,就可以使识别器的识别精度与全部语料训练的结果相当,其表现好于N-best和随机数据选择两种方法。本文提出的语音语料选择方法,明显减少了语音标注的工作量,不需要标注全部语音语料就可以达到全部语音语料的识别率,甚至高于全部训练语句的识别率。
6 总结
本文研究了基于临近最优主动学习的藏语语音语料选择方法,提出了语料样本评价函数和临近最优批量样本选择的目标函数,并证明了后者具有submodular函数性质。该函数性质保证了基于greedy算法实现的藏语语料选择是临近最优样本集,该样本集包含了最有价值的样本参与人工标注和识别器训练,减少了冗余样本的标注,极大地提高了语音识别器构建的工作效率。
猜你喜欢
客联(2022年2期)2022-04-29
科学家(2021年24期)2021-04-25
北京教育·普教版(2020年9期)2020-10-09
制造技术与机床(2019年11期)2019-12-04
校园英语·中旬(2019年11期)2019-11-26
广西教育·D版(2019年6期)2019-07-11
速读·中旬(2018年8期)2018-10-23
西藏研究(2017年3期)2017-09-05
西藏研究(2016年5期)2016-06-15
制造技术与机床(2015年10期)2015-04-09
