
基于线性隐藏的租户副本混淆模型
2018-11-17 02:49丁艳辉张永新赵晓晖
计算机工程与应用 2018年22期
李 琳,丁艳辉,张永新,赵晓晖
1.山东师范大学 数学与统计学院,济南 250358
2.山东师范大学 信息科学与工程学院,济南 250358
1 引言
软件即服务(Software as a Service,SaaS)模式下,成熟的服务运营商一般采用单实例多租赁的方式,使用同一个实例为多个不同租户同时提供服务。服务商需要建立租户副本来保证租户数据的访问效率和可靠性,租户可以根据需要定制副本数量并付费使用。因此租户需要能够确认系统是否可靠地存储了他们的数据副本。但是,采用明文存储的数据副本很容易受到服务提供商内部恶意员工的合谋攻击,比如为了节省存储空间,只存储租户的一个副本,严重破坏租户经济利益、访问效率与数据可靠性。
现阶段,针对服务提供商合谋欺诈的多副本存储方案主要采用的是对不同副本采用不同的随机数进行加密的方法[1-5],结合随机抽样模型防止服务提供商恶意删除租户数据,保证多个副本的可靠存储。但是加密后的数据需要进行解密才能使用,频繁的加解密对系统性能影响较大。同时,这些方法主要面向的是文件系统存储,通过对物理上的数据分块进行加密来生成不同的数据副本,不适用于基于SaaS模式的多租户共享存储。主要原因是多租户应用场景下同一物理分块数据可能包含多个租户数据,以物理上的数据分块为基础进行加解密,破坏了租户之间数据与性能隔离的需求。
针对上述问题,本文提出一种非加密的基于线性隐藏的多副本数据混淆存储(Tenant Duplicate Data Obfuscation,TDDO)模型。该模型可以利用不同的混淆密钥对租户的副本进行混淆,服务提供商存储混淆后的副本数据,结合文献[6]租户多副本抽样检查模型,可以有效防止服务提供商为节省存储空间,删除租户不常用副本问题。并且,为了提高混淆副本可用性,基于蒙特卡罗(Monte Carlo)随机单调函数[7]对TDDO模型进行拓展,制定查询关键字上的保序策略,实现混淆后租户副本数据关键字的保序,可以支持应用在混淆数据上的查询操作。通过实验分析证明了扩展TDDO模型中的混淆矩阵构造消耗、租户数据重构消耗以及混淆密钥存储代价等。
2 相关研究
目前,针对SaaS模式多副本的数据混淆存储的相关研究较少,但是相关数据发布、数据外包服务和数据分析领域针对数据保护的研究已经取得诸多研究成果,为SaaS模式多副本数据混淆提供了良好的借鉴。现有的数据保护方法主要有数据加密、数据扰动和数据分解等。
数据加密是安全的隐私保护方法,但是加密后数据可操作性大大降低,需要对密文解密后才能进行相关数据操作。因此,提高密文的检索效率成为当今研究的热点。在提高密文检索效率方面,文献[8]提出基于桶的索引分类机制,在明文索引上建立分组编号,通过桶分组方式来支持密文数据的快速查询。文献[9]提出保序加密(Order Preserving Encryption,OPE)算法,该算法给出了针对整数数据类型的保序加密方法,并进一步分析在数据元组上进行修改、查询等元组操作的支持性。以文献[9]为基础,文献[10]给出了针对数据库中的字符数据类型的保序加密方法,文献[11]提出可以支持查询中的比较算符的保序加密算法,并给出了查询优化方案。文献[12]针对文献[9]中的保序加密算法存在的安全性较弱问题,进一步提出模保序加密机制,与保序加密相比较,模保序方法具有更好的安全性。但是对于实时性要求较高的多租户应用来说,频繁地加解密数据对应用性能影响仍然比较大。
数据扰动方法主要通过对原始数据进行随机扰动实现数据保护,该方法在数据发布领域应用较多。主要使用匿名化[13]实现隐私保护,通用的方法包括扰动(Perturbation)[14]、随机(Randomization)[15]、置换(Swapping)[16]等。文献[17-18]提出了k-anonymity机制。文献[19]提出了l-diversity机制,文献[20]提出了t-closeness隐私保护机制。数据发布领域的数据混淆方法不需要考虑如何逆向推导明文问题,不适用于事务性应用。但是在数据恢复方面,相对于数据加密,匿名化方法在辅助信息足够的情况下,数据恢复的时间代价较小。以随机扰动方法为例,通过在原始数据中添加随机种子和私有随机数进行扰动来隐藏真实数据值,只要获取了随机种子和随机数就可以通过逆运算快速获取原始数据。
文献[21-22]提出了基于秘密共享的数据分解方法,通过对数据进行多项式分解为多个子数据,分散存储到多个不相关的数据服务器中来达到数据保护的目的,这种方法可以高效地支持选择、投影、连接以及聚合查询等多种数据操作。但是基于秘密共享的方法的一个重要应用前提是多个数据服务器间不能够进行串通,否则无法保证数据的安全性。并且基于数据分解方法对数据进行隐私保护后,任何数据的查询访问均需多方参与进行数据恢复,当数据规模大时,效率会急剧下降。
文献[23]在总结分析隐私保护方法的基础上,基于数据模式分解,深入研究了云环境下多租户数据隐私保护,给出了组合隐私保护机制,较好地解决了单个数据节点上的租户数据隐私保护问题,但是该研究没有针对云中租户多数据副本的应用场景进行研究。
综上,租户副本数据混淆解决方案可以借鉴随机扰动[14]方法的思想。假设数据库R中数据元组为rj=,基于随机扰动的副本混淆方法是对R中的每一个属性值aij,随机选取T个随机值产生T个扰动副本集合其中V为混淆密钥,并且对于攻击者而言,只能看到扰动后的副本数据,不同的租户副本有着不同的数据表达方式。
但是这种基于全随机数的副本混淆方案,使得每个租户需要保存T个混淆矩阵V存储对应每个的随机数,来满足数据恢复的需要。V中元素的多少与副本中所有属性值个数相同。假设随机值大小为,则密钥大小。这样混淆密钥V存储随着数据增多呈倍数增加。辅助信息存储代价比较大,灵活性差。
针对上述问题,本文根据线性隐藏[24]方案提出了一个租户数据副本混淆模型TDDO,然后基于Monte Carlo随机函数扩展TDDO模型来支持关键字上的保序,最后给出TDDO模型的安全性分析以及实验分析。
3 基于线性隐藏的租户数据副本混淆模型
定义1(副本混淆)针对租户数据进行混淆,获得T个不同的数据副本,分别存储在服务提供商T个不同的数据服务器上。
定义2(混淆算法EK)用来对租户副本进行混淆,对于租户的逻辑视图R,通过混淆算法,针对数据元组进行混淆获得T个不同的数据副本为混淆密钥,保存在可信第三方中。
定义3(重构算法E-1)通过重构算法,将混淆后的数据还原为原始数据R。
TDDO模型主要步骤包括:
(1)生成随机向量Vk。
根据租户定制副本数量T,生成T个随机向量集合 {Vk=(vki)1≤i≤n}1≤k≤T,Vik∈Z ,其中 vki与 R 中数据元组 rj={aij}1≤i≤n存在一一对应关系 ψ,即 rj←ψ(vki)。Vk为副本混淆的随机种子,Vk和ψ需要作为密钥保存在可信第三方上。
(2)针对每个副本建立混淆矩阵VMk。
首先,利用m个简单多项式函数集合F={f1,f2,…,fm}建立中间向量 process vector[j],j=1,2,…,m,并且这m个多项式函数中至少有一个函数是可逆的,例如{f1(x)=c0x+c1,f2(x)=c2x2+c3,f3(x)=c4x3+c5},其中ci是常系数。使用m个函数 fj(x)(j=1,2,…,m),建立 process vector[j]为:
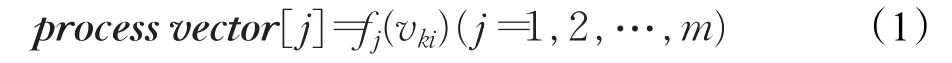
然后,根据生成的中间向量集合process vector[j],j=1,2,…,m,利用随机可逆矩阵M对 process vector[m]进行线性隐藏,得到对应vki的如下:

此时,M∈GLn(Z)是用来产生混淆向量的混淆密钥矩阵,假设并且这样针对副本的混淆矩阵每个副本的混淆密钥Kk=(Vk,F,M,ψ),包括随机种子Vk,函数集合F以及混淆密钥矩阵M。Kk是作为辅助混淆信息存储在可信第三方上的,服务提供商无法获得Kk的任何信息。
根据步骤(1)和步骤(2)建立生成混淆矩阵VMk后,对于R中的每个数据元组rj={aij}1≤i≤n,找到对应的vki,计算对应rj的混淆值,对副本中每个属性进行混淆,得到获得混淆后副本
TDDO模型中的副本混淆算法如下:
算法1副本混淆算法EK
输入:租户数据R,混淆密钥K(随机种子Vk,函数集合F,淆密钥矩阵M)。
输出:混淆副本Rˇ。

算法1的复杂度为O(mn),在实际应用中因为m<<n,所以算法1的近似复杂度为O(n)。对租户数据R进行混淆时,需要根据随机种子进行mn次计算获取混淆矩阵,租户只需要保存好n个随机值、T个函数集合、T个混淆矩阵以及对应关系ψ就能够生成混淆数值对租户数据进行混淆。设随机值大小为|I|,函数大小为密钥K的大小为则有在实际应用中因为m<<n,所以基于随机扰动的多副本混淆方案中密钥大小大约为TDDO模型中密钥大小的(T×m-2)×n倍。由此可见,TDDO模型大大减小了混淆密钥的存储空间。
TDDO模型中的副本重构算法,可以看做是混淆算法的逆过程E-1,重构副本原始数据的一个关键前提是确定vki与元组rj的对应关系ψ,否则重构无法实现。为此TDDO模型需要额外保存至少一个副本中的物理表GUID与vki的对应关系,否则无法重构副本原始数据。上述算法主要针对数值型数据,如果属性值为非数值型数据,可以将属性值转化为数值进行计算。
4 TDDO模型扩展
为了降低密钥复杂性,可以用租户数据主关键字代替随机向量Vk的方法,这样可以根据关键字以及混淆值快速定位租户副本数据,而不需要保存对应关系ψ,但是这样丧失了vki的随机性,如果攻击者获取了部分关键字明文信息,攻击者有可能根据混淆后的关键字反推出混淆信息。针对这个问题,本文使用Monte Carlo随机函数扩展TDDO模型,在这个模型中,利用元组关键字作为混淆向量,基于Monte Carlo随机函数构建在关键字属性上保序的扩展TDDO模型。
4.1 扩展TDDO模型中随机单调递增函数
Monte Carlo随机单调函数是一个随机产生的单调函数 y=f(x),其中 fl(x)≤f(x)≤fu(x),fl(x)和 fu(x)是给定的上下界函数,fl(x)和 fu(x)都是单调递增函数,并且它们之间的封闭区间(envelope)足够宽。
首先,在Dom(A)上随机选择N个数据点 p,amin=p1<p2<…<pN=amax;然后,在的一些分布中随机选择ymin,方便起见,假设ymin=G(amin)=fl(amin),同样假设。接着,对每个 pi,在中随机选择 yi,建立N个随机数值对,并且y1<y2<…<yN。最后,在 (p1,y1),(p2,y2),…,(pN,yN)利用拉格朗日差法建立函数集合i=1,2,…,N-1。

扩展TDDO模型中的副本混淆算法EK与副本重构算法E-1与上节类似。扩展TDDO模型中混淆密钥Kk=(A,G(x),M,p)。
4.2 扩展TDDO模型中的保序策略
针对TDDO模型中混淆副本查询关键字属性上的保序问题,制定保序策略。本文主要给出了全保序策略和1-保序策略。
策略1全保序策略(Full Order-Preserving Strategy,FOS)。在FOS中,一个副本的混淆矩阵VMk中的每一混淆列都与关键字A的原始数据保持相同的顺序。可以通过控制混淆矩阵M中参数选择来实现FOS。最简单的方法为限制 ∀δij∈M,δij>0,并且所有 fi∈G(x)为Dom(A)上的单调递增函数。
推论1在FOS策略下,混淆矩阵VMk中的每一混淆列都与关键字A的原始数据保持相同的顺序。(证明过程略)
实现FOS较为简单,但是由于VMk中每一混淆列都保持原始数据的顺序,如果攻击者获取了部分副本明文信息,他有可能根据保序关系以及混淆后副本数据反推出部分混淆信息,从而推测出部分混淆密钥K。为了提高安全性,提出1-保序策略。1-保序策略中只有一个混淆列是保序的。

推论2在POS策略下,混淆矩阵VMk中的混淆列shadow(ai,1)与关键字A的原始数据保持相同的顺序,其余列不保序。(证明过程与证明1相似)
根据POS策略,在扩展TDDO模型中,租户数据可以随时进行更新、插入以及删除操作,只需要根据混淆密钥计算相对应属性的混淆值,就可以快速地计算对应混淆副本中的值,而不需要影响其他数据。
以插入数据为例,假设租户插入关键字为ap的数据rp,数据引擎收到更新请求后,对rp进行混淆,得到T个不同的,然后根据POS策略插入到相对应的混淆副本中,同时更新混淆密钥。相对于加密的副本混淆方法,TDDO模型具有更高的数据处理效率。
4.3 安全性分析
假设攻击模型为服务提供商端的恶意内部员工在租户数据不进行数据保护的情况下,可以获得租户所有副本的明文数据,这样恶意人员之间能够互相串通来删除租户整个数据副本,但是基于可信平台技术,恶意内部人员无法窥视租户应用运行过程,不能够获得租户应用过程中产生的任何中间结果和明文数据。TDDO模型通过对R不同的副本进行混淆处理,生成不同的副本数据,这样同一数据元组混淆后具有m种不同的存储内容。结合文献[6]抽样方法,当恶意内部人员串通勾结删除了租户的一个混淆副本后,在可信第三方针对该混淆副本进行抽样检查时,恶意内部人员无法通过伪造抽样数据元组的方法来达到欺骗验证者的目的。同时,由于对应同一租户应用逻辑视图的不同数据副本具有不同的混淆存储内容,攻击者无法利用别的数据节点上的混淆副本来取代本地存储的副本数据,从而可以有效地杜绝服务提供商恶意删除租户副本数据。

5 实验
本文通过实验来验证扩展TDDO模型的有效性。主要从混淆矩阵VMk的构造代价、密钥存储代价、副本重构代价、查询性能几方面来验证TDDO模型的性能。从平台租户数据中随机选取1×105个元组作为基础实验数据。
混淆矩阵VMk的构造代价实验主要验证不同数据字段数目情况下,构造混淆矩阵VMk的时间代价消耗。假设租户数据集合为T,并且T中元组数目取值范围是(1×104,2×104,3×104,4×104,5×104),当 T 中数据字段数目为n=3,4,5时,构造混淆矩阵VMk的时间消耗如图1所示。从图中可知,混淆矩阵的构造时间随着租户数据字段和数据元组数目的增加而呈现线性增加。造成该现象的原因是要对租户数据中每个字段属性值进行覆盖,混淆矩阵的规模会随着租户数据的增多而增大,因此构造时间也相应变长。

图1 混淆矩阵VM k的构造代价
密钥存储代价实验主要对基于随机混淆方法、TDDO模型以及扩展TDDO模型的密钥存储代价进行比较。在实验中,租户数据集元组数目变化范围是(1×104~1×105),测试在租户逻辑视图数据字段数目n=3以及定制副本数目T=3的情况下,三种混淆方法的辅助密钥存储代价。从图2中可以看出,随着租户数据集内元组数目的增大,可信第三方辅助存储的密钥呈线性增长,其中扩展TDDO模型方法具有最小的辅助密钥存储空间代价,大约为随机混淆方法存储代价的1/3。造成该现象的主要原因是扩展TDDO模型只需要存储密钥构成规则函数,而随机混淆方法需要存储对应租户所有字段属性值的混淆矩阵。

图2 密钥存储代价
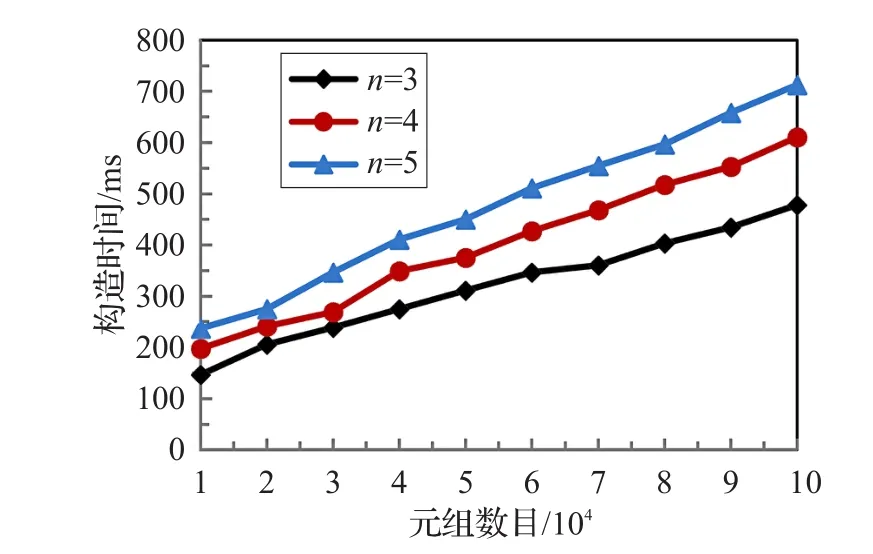
图3 副本重构代价
查询性能实验主要测试基于随机扰动方法、扩展TDDO模型在保序关键字上与直接在数据明文上进行范围查询的时间消耗。测试在T中数据字段数目n=3的情况下,分别在租户数据集元组数据集上对1×104,2×104,3×104个数据元组随机进行100次范围查询的平均时间消耗,如图4所示。

图4 索引验证方法对多租户查询性能的影响
从图4中可以看出,扩展TDDO模型在保序关键字上的范围数据查询操作,相对于直接在明文数据上进行操作处理开销略大,性能接近。查询性能远高于基于随机扰动的方法,主要原因是如果混淆后的查询关键字与关键字明文数据顺序保持一致,只需要计算两个边界值就可对混淆数据进行范围查询。而基于随机扰动的方法需要预先查找到对应明文关键字的所有随机值,并计算出所有的查询关键字进行查询,因此扩展TDDO模型在保序关键字上具有较好的查询性能。
6 结束语
本文针对租户多副本的存储安全问题,提出一种可以抵御服务提供商合谋欺诈的基于线性隐藏的多副本数据混淆存储TDDO模型。该模型可以有效防止服务提供商为节省存储空间删除租户不常用副本问题,保证租户副本完整性。为了提高混淆副本的可用性和查询效率,基于Mont Carlo随机函数对TDDO模型进行扩展,提出了查询关键字保序的混淆策略。最后,通过分析实验证明了TDDO模型的安全性和有效性。
猜你喜欢
华人时刊(2022年1期)2022-04-26
电脑报(2021年14期)2021-06-28
软件学报(2019年11期)2019-12-11
动漫界·幼教365(大班)(2019年10期)2019-10-28
网络安全和信息化(2019年8期)2019-08-28
计算机与生活(2019年5期)2019-07-18
计算机系统应用(2019年2期)2019-04-10
吉林大学学报(理学版)(2018年2期)2018-03-29
现代电子技术(2015年2期)2015-09-18
环球时报(2009-11-25)2009-11-25
